Hola a todos. El 26 de febrero, las clases comenzaron en OTUS en un nuevo grupo en el curso "MS SQL Server Developer" . En este sentido, quiero compartir con ustedes mi publicación sobre las funciones de la ventana. Por cierto, en la próxima semana todavía puedes unirte al grupo ;-).
Las funciones de ventana están bien establecidas en nuestra práctica, pero pocas personas saben cómo funcionan los marcos RANGE y ROWS.Quizás es por eso que son algo menos comunes. El propósito de este artículo es proporcionar ejemplos de uso para que definitivamente no tenga preguntas "¿Quién es quién?" y "¿Cómo aplicarlo?". La pregunta "¿Por qué?" El artículo permanecerá apagado.Veamos qué es un marco y cómo lograr un efecto similar usando ORDER By en la cláusula OVER ().Para la demostración, utilizaremos una tabla simple para que pueda calcular ejemplos sin usar un compilador. En general, lo recomiendo encarecidamente: mire y piense cuál será el resultado de la ejecución, y luego verifíquese usted mismo, para que encuentre puntos blancos en la percepción de las funciones de la ventana, lo que puede no ser obvio cuando lee los resultados finales.MesaCreate table sales
(sales_id INT PRIMARY KEY, sales_dt DATETIME2 DEFAULT GETUTCDATE(), customer_id INT, item_id INT, cnt INT, price_per_item DECIMAL(19,4));
INSERT INTO sales
(sales_id, sales_dt, customer_id, item_id, cnt, price_per_item)
VALUES
(1, '2020-01-10T10:00:00', 100, 200, 2, 30.15),
(2, '2020-01-11T11:00:00', 100, 311, 1, 5.00),
(3, '2020-01-12T14:00:00', 100, 400, 1, 50.00),
(4, '2020-01-12T20:00:00', 100, 311, 5, 5.00),
(5, '2020-01-13T10:00:00', 150, 311, 1, 5.00),
(6, '2020-01-13T11:00:00', 100, 315, 1, 17.00),
(7, '2020-01-14T10:00:00', 150, 200, 2, 30.15),
(8, '2020-01-14T15:00:00', 100, 380, 1, 8.00),
(9, '2020-01-14T18:00:00', 170, 380, 3, 8.00),
(10, '2020-01-15T09:30:00', 100, 311, 1, 5.00),
(11, '2020-01-15T12:45:00', 150, 311, 5, 5.00),
(12, '2020-01-15T21:30:00', 170, 200, 1, 30.15);
Comencemos con un momento simple: las diferencias en la función SUMA con y sin ordenarSELECT sales_id, customer_id, count,
SUM(count) OVER () as total,
SUM(count) OVER (ORDER BY customer_id) AS cum,
SUM(count) OVER (ORDER BY customer_id, sales_id) AS cum_uniq
FROM sales
ORDER BY customer_id, sales_id;
 Veamos el primer rastrillo discreto, ¿cómo crees que cuántos desarrolladores piensan que cum y cum_uniq son iguales al leer el código? Pensar un poco? Quizás, pero porque aquí es obvio, y es tan obvio al leer el código en la aplicación, e incluso con la no tan obvia falta de uniformidad del campo de clasificación.Ahora abre nuestra maravillosa ventana.La ventana, o más bien el marco es de 2 tipos de FILAS y RANGO, primero debe conocer las FILAS.Opciones de restricción de trama:
Veamos el primer rastrillo discreto, ¿cómo crees que cuántos desarrolladores piensan que cum y cum_uniq son iguales al leer el código? Pensar un poco? Quizás, pero porque aquí es obvio, y es tan obvio al leer el código en la aplicación, e incluso con la no tan obvia falta de uniformidad del campo de clasificación.Ahora abre nuestra maravillosa ventana.La ventana, o más bien el marco es de 2 tipos de FILAS y RANGO, primero debe conocer las FILAS.Opciones de restricción de trama:- Todo antes de la fila / rango actual y el valor real de la fila actual
ENTRE PRECEDENTES SIN LÍMITES
ENTRE PRECEDENTES SIN PROCESAR Y FILA ACTUAL
- Fila / rango actual y todo lo demás,
ENTRE FILA ACTUAL Y SIGUIENTE SIN LÍMITES - Especificar cuántas líneas antes y después de incluir (no admitidas para RANGO)
ENTRE N Precediendo Y N Siguiendo
ENTRE FILA ACTUAL Y N Siguiendo
ENTRE N FILA ANTERIOR Y ACTUAL
Pero veamos el marco en acción.Abrimos la "ventana" en la línea actual y todas las anteriores, para la función SUMA, como puede ver, esto coincide con la clasificación ASCSELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id) AS cum_uniq,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_and_all_before2
FROM sales
ORDER BY customer_id, sales_id;
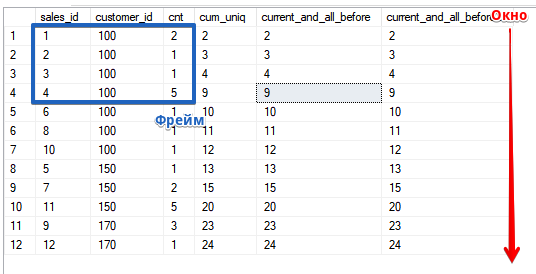 Al mismo tiempo, quiero recordarle que el orden de clasificación en la ventana (en la cláusula OVER ()) no está relacionado con el orden de clasificación en la consulta en sí, en el ejemplo es el mismo para simplificar el cálculo si decide verificar el cálculo y su comprensión de cómo funciona la función
Al mismo tiempo, quiero recordarle que el orden de clasificación en la ventana (en la cláusula OVER ()) no está relacionado con el orden de clasificación en la consulta en sí, en el ejemplo es el mismo para simplificar el cálculo si decide verificar el cálculo y su comprensión de cómo funciona la funciónSELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id) AS cum_uniq,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_and_all_before2
FROM sales
ORDER BY cnt;
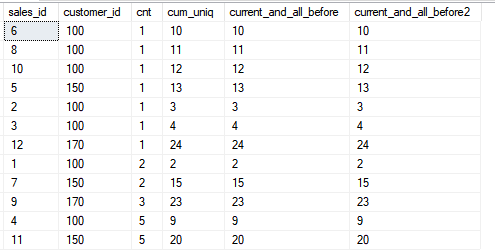 Ahora veamos la funcionalidad del marco cuando incluimos todas las líneas posteriores.
Ahora veamos la funcionalidad del marco cuando incluimos todas las líneas posteriores.SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_frame,
SUM(cnt) OVER (ORDER BY customer_id DESC, sales_id DESC) AS current_and_all_order_desc
FROM sales
ORDER BY customer_id, sales_id;
 Como puede ver aquí, también puede obtener el mismo resultado para una función agregada, si usa la clasificación inversa, pero ROWS es un poco más estable, porque si sus campos de clasificación no son únicos, puede obtener una sorpresa en la forma de los mismos valores.Y finalmente, una opción que ya no puede ser imitada por tipos, cuando especificamos un número específico de líneas que deben incluirse en el marco
Como puede ver aquí, también puede obtener el mismo resultado para una función agregada, si usa la clasificación inversa, pero ROWS es un poco más estable, porque si sus campos de clasificación no son únicos, puede obtener una sorpresa en la forma de los mismos valores.Y finalmente, una opción que ya no puede ser imitada por tipos, cuando especificamos un número específico de líneas que deben incluirse en el marcoSELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS before_and_current,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS current_and_1_next,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING) AS before2_and_2_next
FROM sales
ORDER BY customer_id, sales_id;
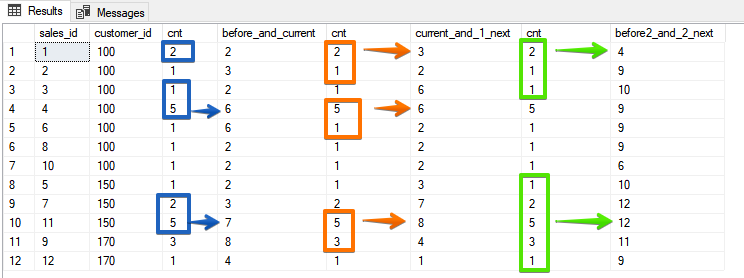 En esta opción, ya indica específicamente qué líneas están en el rango, y en mi opinión, es más obvio por los resultados.
En esta opción, ya indica específicamente qué líneas están en el rango, y en mi opinión, es más obvio por los resultados.La diferencia entre ROWS y RANGE
La diferencia es que ROWS opera en una fila y RANGE en un rango. Es cierto, esto es obvio por el nombre, pero explica poco en la práctica?Veamos la imagen (fuente en la parte inferior del artículo)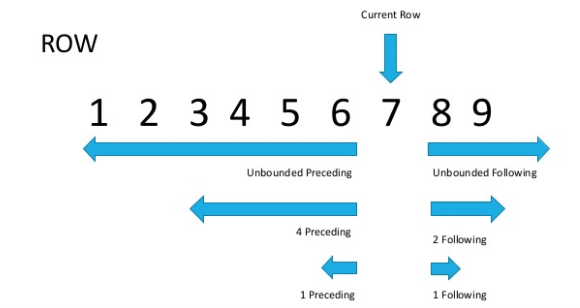
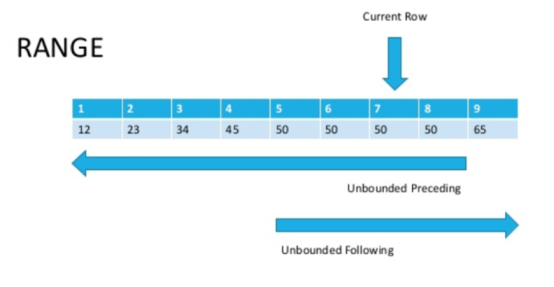 Ahora, si miramos cuidadosamente, será obvio que las filas con el mismo valor del parámetro de clasificación se denominan rango.Como ya se mencionó anteriormente, ROWS se limita a una cadena, mientras que RANGE captura todo el rango de valores coincidentes que especifique en la función de ventana ORDER BY.
Ahora, si miramos cuidadosamente, será obvio que las filas con el mismo valor del parámetro de clasificación se denominan rango.Como ya se mencionó anteriormente, ROWS se limita a una cadena, mientras que RANGE captura todo el rango de valores coincidentes que especifique en la función de ventana ORDER BY.SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id RANGE UNBOUNDED PRECEDING) AS current_and_all_before2
FROM sales
ORDER BY 2, sales_id;
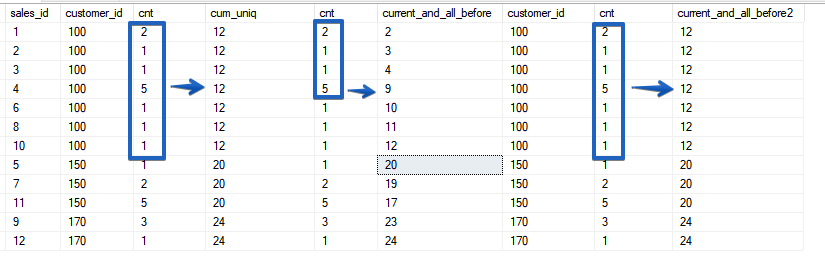 FILAS: siempre opera en una línea específica, incluso si la clasificación no es única, pero RANGO solo combina períodos en rangos con los valores coincidentes de los campos de clasificación. En este sentido, la funcionalidad es muy similar al comportamiento de la función SUM () con la clasificación por un campo no único. Veamos otro ejemplo.
FILAS: siempre opera en una línea específica, incluso si la clasificación no es única, pero RANGO solo combina períodos en rangos con los valores coincidentes de los campos de clasificación. En este sentido, la funcionalidad es muy similar al comportamiento de la función SUM () con la clasificación por un campo no único. Veamos otro ejemplo.SELECT sales_id, customer_id, price_per_item, cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item RANGE UNBOUNDED PRECEDING) AS current_and_all_before2
FROM sales
ORDER BY 2, price_per_item;
 Ya hay 2 campos y el rango está determinado por un rango con valores coincidentes para ambos campos,y la opción es cuando incluimos en el cálculo todas las líneas posteriores de la actual, que en el caso de la función SUMA coincide con el valor que se puede obtener mediante la ordenación inversa:
Ya hay 2 campos y el rango está determinado por un rango con valores coincidentes para ambos campos,y la opción es cuando incluimos en el cálculo todas las líneas posteriores de la actual, que en el caso de la función SUMA coincide con el valor que se puede obtener mediante la ordenación inversa:SELECT sales_id, customer_id, price_per_item, cnt,
SUM(cnt) OVER (ORDER BY customer_id DESC, price_per_item DESC) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_before2
FROM sales
ORDER BY 2, price_per_item, sales_id desc;
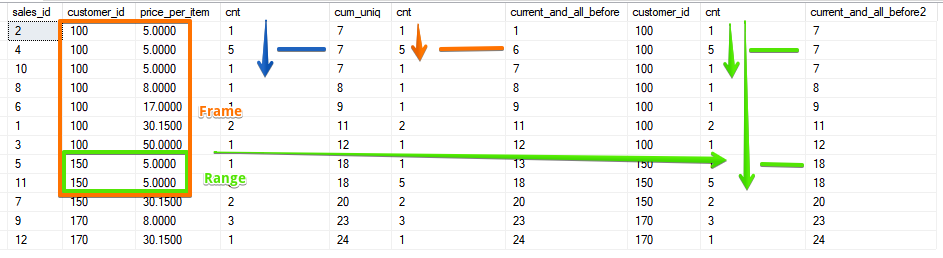 Como puede ver, RANGE nuevamente captura todo el rango de pares coincidentes.A pesar de que la funcionalidad de ROWS y RANGE está lejos de ser nueva cada vez, surgen preguntas sobre cómo usarla. Espero que este artículo haya agregado una comprensión de cómo ROWS y RANGE son diferentes, y ahora no dudará en qué caso se necesita este o aquel marco.Ilustración Fuente RANGO sobre la diferencia y las FILASlas funciones de la ventana Con el SQL Server 2016, Mark Tabladilloestará a tiempo para el curso
Como puede ver, RANGE nuevamente captura todo el rango de pares coincidentes.A pesar de que la funcionalidad de ROWS y RANGE está lejos de ser nueva cada vez, surgen preguntas sobre cómo usarla. Espero que este artículo haya agregado una comprensión de cómo ROWS y RANGE son diferentes, y ahora no dudará en qué caso se necesita este o aquel marco.Ilustración Fuente RANGO sobre la diferencia y las FILASlas funciones de la ventana Con el SQL Server 2016, Mark Tabladilloestará a tiempo para el curso