Este artículo describe algunos métodos para acelerar la carga de aplicaciones front-end para implementar una interfaz de usuario rápida y receptiva.Discutiremos la arquitectura general de la interfaz, cómo precargar los recursos necesarios y aumentar la probabilidad de que estén en la memoria caché. Discutiremos un poco cómo dar recursos desde el backend y cuándo es posible limitarnos a páginas estáticas en lugar de una aplicación cliente interactiva.El proceso de descarga se divide en tres etapas. Para cada etapa, formulamos estrategias generales para aumentar la productividad:- Representación inicial : cuánto tiempo le lleva al usuario ver al menos algo
- Reduce las solicitudes de bloqueo de representación
- Evitar cadenas secuenciales
- Reutilice las conexiones del servidor
- Trabajadores de servicio para renderizado instantáneo
- : ,
- :
Hasta la representación inicial, el usuario no ve nada en la pantalla. ¿Qué necesitamos para esta representación? Como mínimo, cargue un documento HTML y, en la mayoría de los casos, recursos adicionales, como archivos CSS y JavaScript. Una vez que están disponibles, el navegador puede comenzar algún tipo de representación. Loscuadros de WebPageTest se proporcionan a lo largo de este artículo . La secuencia de consulta para su sitio probablemente se verá así. El documento HTML carga un montón de archivos adicionales, y la página se representa después de que se descargan. Tenga en cuenta que los archivos CSS se cargan en paralelo entre sí, por lo que cada solicitud adicional no agrega un retraso significativo.(Nota: en la captura de pantalla, gov.uk es un ejemplo donde HTTP / 2 ahora está habilitadopara que el dominio de recursos pueda reutilizar una conexión existente. Consulte a continuación las conexiones del servidor).
El documento HTML carga un montón de archivos adicionales, y la página se representa después de que se descargan. Tenga en cuenta que los archivos CSS se cargan en paralelo entre sí, por lo que cada solicitud adicional no agrega un retraso significativo.(Nota: en la captura de pantalla, gov.uk es un ejemplo donde HTTP / 2 ahora está habilitadopara que el dominio de recursos pueda reutilizar una conexión existente. Consulte a continuación las conexiones del servidor).Reduce las solicitudes de bloqueo de representación
Las hojas de estilo y (por defecto) los scripts bloquean la representación de cualquier contenido debajo de ellos.Hay varias opciones para solucionar esto:- Mover etiquetas de script a la parte inferior del cuerpo
- Descargar scripts en modo asincrónico usando
async
- Si JS o CSS deben cargarse secuencialmente, es mejor incrustarlos con pequeños fragmentos
Evite conversaciones con solicitudes secuenciales que bloqueen la representación
El retraso en la representación del sitio no está necesariamente asociado con una gran cantidad de solicitudes que bloquean la representación. Más importante es el tamaño de cada recurso, así como el tiempo de inicio de su descarga. Es decir, el momento en que el navegador de repente se da cuenta de que este recurso necesita ser descargado.Si el navegador detecta la necesidad de descargar el archivo solo después de completar otra solicitud, entonces hay una cadena de solicitudes. Se puede formar por varias razones:- Reglas
@importCSS
- Fuentes web a las que hace referencia el archivo CSS
- JavaScript descargable o etiquetas de script
Eche un vistazo a este ejemplo: uno de los archivos CSS en este sitio carga la fuente de Google a través de la regla
uno de los archivos CSS en este sitio carga la fuente de Google a través de la regla @import. Esto significa que el navegador tiene que turnarse para ejecutar las siguientes solicitudes:- Documento HTML
- Aplicaciones CSS
- CSS para fuentes de Google
- Archivo de fuente de Google Woff (no se muestra en el diagrama)
Para solucionar esto, primero mueva la solicitud CSS de Google Fonts de la etiqueta @importal enlace en el documento HTML. Entonces acortamos la cadena por un enlace.Para acelerar aún más las cosas, incrusta CSS de Google Fonts directamente en tu archivo HTML o CSS.(Tenga en cuenta que la respuesta CSS del servidor de Google Fonts depende de la línea del agente de usuario. Si realiza una solicitud con IE8, el CSS se referirá al archivo EOT, IE11 recibirá el archivo woff y los navegadores modernos recibirán el archivo woff2. Si acepta que los navegadores antiguos se limitarán a las fuentes del sistema, simplemente puede copiar y pegar el contenido del archivo CSS para usted).Incluso después del inicio de la representación, es poco probable que el usuario pueda interactuar con la página, ya que la fuente debe cargarse para mostrar el texto. Este es un retraso de red adicional que me gustaría evitar. El parámetro de intercambio es útil aquí , le permite usarlo font-displaycon Google Fonts y almacenar fuentes localmente.A veces, la cadena de consulta no se puede resolver. En tales casos, es posible que desee considerar la etiqueta de precarga o preconexión . Por ejemplo, el sitio web en el ejemplo anterior puede conectarse fonts.googleapis.comantes de que llegue la solicitud CSS real.Reutilizando las conexiones del servidor para acelerar las solicitudes
Para establecer una nueva conexión con el servidor, generalmente se requieren tres intercambios de paquetes entre el navegador y el servidor:- Búsqueda de DNS
- Establecer una conexión TCP
- Establecer una conexión SSL
Una vez establecida la conexión, se requiere al menos un intercambio de paquetes más para enviar una solicitud y recibir una respuesta.La tabla a continuación muestra que iniciar una conexión con cuatro servidores diferentes: hostgator.com, optimizely.com, googletagmanager.com, y googelapis.com.Sin embargo, las solicitudes posteriores del servidor pueden reutilizar una conexión existente . La descarga base.csso bien index1.cssocurre más rápido ya que se encuentran en el mismo servidor hostgator.comcon el que ya se ha establecido una conexión.
Reduzca el tamaño del archivo y use CDN
Usted controla dos factores que afectan el tiempo de ejecución de la consulta: el tamaño de los archivos de recursos y la ubicación de los servidores.Envíe la menor cantidad de datos posible al usuario y asegúrese de que estén comprimidos (por ejemplo, usando brotli o gzip).Las redes de entrega de contenido (CDN) tienen servidores en todo el mundo. En lugar de conectarse a un servidor central, un usuario puede conectarse a un servidor CDN más cercano. Por lo tanto, el intercambio de paquetes será mucho más rápido. Esto es especialmente adecuado para recursos estáticos como CSS, JavaScript e imágenes, ya que son fáciles de distribuir a través de CDN.Elimine la latencia de la red con los trabajadores del servicio.
Los trabajadores de servicio le permiten interceptar solicitudes antes de enviarlas a la red. ¡Esto significa que la respuesta llega casi al instante !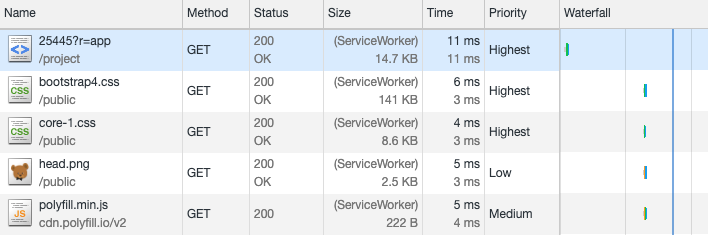 Por supuesto, esto solo funciona si realmente no necesita recibir datos de la red. La respuesta ya debe estar almacenada en caché, por lo que el beneficio aparecerá solo de la segunda descarga de la aplicación.El trabajador de servicio a continuación almacena en caché el HTML y CSS necesarios para representar la página. Cuando la aplicación se carga nuevamente, intenta emitir recursos en caché por sí misma, y accede a la red solo si no están disponibles.
Por supuesto, esto solo funciona si realmente no necesita recibir datos de la red. La respuesta ya debe estar almacenada en caché, por lo que el beneficio aparecerá solo de la segunda descarga de la aplicación.El trabajador de servicio a continuación almacena en caché el HTML y CSS necesarios para representar la página. Cuando la aplicación se carga nuevamente, intenta emitir recursos en caché por sí misma, y accede a la red solo si no están disponibles.self.addEventListener("install", async e => {
caches.open("v1").then(function (cache) {
return cache.addAll(["/app", "/app.css"]);
});
});
self.addEventListener("fetch", event => {
event.respondWith(
caches.match(event.request).then(cachedResponse => {
return cachedResponse || fetch(event.request);
})
);
});
En esta guía, se explica en detalle el uso de los trabajadores del servicio para precargar y almacenar en caché los recursos.Descargar aplicación
Entonces, el usuario ve algo en la pantalla. ¿Qué pasos adicionales son necesarios para que use la aplicación?- Descargar el código de la aplicación (JS y CSS)
- Descargue los datos requeridos para la página
- Descargar datos e imágenes adicionales
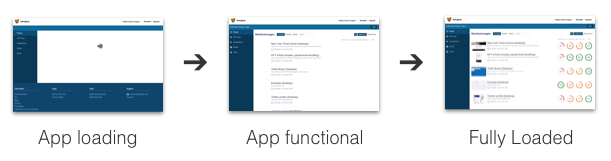 Tenga en cuenta que no solo descargar datos de la red puede retrasar el procesamiento. Una vez que se carga el código, el navegador debe analizarlo, compilarlo y ejecutarlo.
Tenga en cuenta que no solo descargar datos de la red puede retrasar el procesamiento. Una vez que se carga el código, el navegador debe analizarlo, compilarlo y ejecutarlo.Descargue solo el código necesario y maximice la cantidad de visitas en el caché
"Romper un paquete" significa descargar solo el código necesario para la página actual, no la aplicación completa. También significa que algunas partes del paquete pueden almacenarse en caché, incluso si otras partes han cambiado y deben volver a cargarse.Como regla general, el código se divide en las siguientes partes:- Código para una página específica (específica de la página)
- Código de aplicación común
- Módulos de terceros que rara vez cambian (¡excelente para el almacenamiento en caché!)
Webpack puede hacer esta optimización automáticamente, romper el código y reducir el peso total de la carga. El código se divide en pedazos usando el objeto optimization.splitChunks . Separe el tiempo de ejecución (tiempo de ejecución) en un archivo separado: de esta manera puede beneficiarse del almacenamiento en caché a largo plazo. Ivan Akulov escribió una guía detallada sobre cómo dividir un paquete en archivos separados y el almacenamiento en caché en Webpack .No es posible asignar código automáticamente para una página específica. Debe identificar manualmente las partes que se pueden descargar por separado. A menudo, esta es una ruta específica o un conjunto de páginas. Utilice las importaciones dinámicas para cargar este código de forma perezosa.Dividir el paquete general en partes aumentará el número de solicitudes para descargar su aplicación. Pero este no es un gran problema si las solicitudes se ejecutan en paralelo, especialmente si el sitio se carga utilizando el protocolo HTTP / 2. Puede ver esto para las primeras tres consultas en el siguiente diagrama: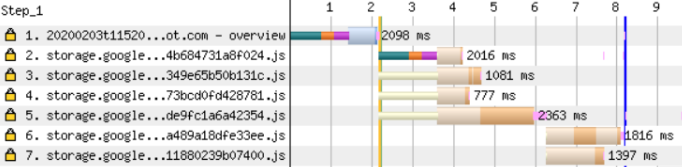 Sin embargo, dos consultas consecutivas también son visibles en el diagrama. Estos fragmentos son necesarios solo para esta página en particular y se cargan dinámicamente
Sin embargo, dos consultas consecutivas también son visibles en el diagrama. Estos fragmentos son necesarios solo para esta página en particular y se cargan dinámicamente import().Puede intentar solucionar el problema insertando una etiqueta preload preload .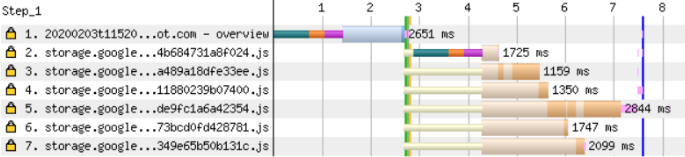 Pero vemos que el tiempo total de carga de la página ha aumentado.La precarga de recursos a veces es contraproducente ya que retrasa la carga de archivos más importantes. LeerEl artículo de Andy Davis sobre la precarga de fuentes y cómo este procedimiento bloquea el inicio de la representación de la página.
Pero vemos que el tiempo total de carga de la página ha aumentado.La precarga de recursos a veces es contraproducente ya que retrasa la carga de archivos más importantes. LeerEl artículo de Andy Davis sobre la precarga de fuentes y cómo este procedimiento bloquea el inicio de la representación de la página.Cargando datos para una página
Su aplicación probablemente debería mostrar algunos datos. Aquí hay algunos consejos que puede usar para descargar esta información antes de tiempo sin demoras innecesarias.No espere la descarga completa del paquete antes de comenzar a descargar los datos.
Aquí hay un caso especial de una cadena de solicitudes secuenciales: descarga el paquete completo de la aplicación y luego este código solicita los datos necesarios para la página.Hay dos formas de evitar esto:- Incrustar datos en un documento HTML
- Ejecute una solicitud de datos utilizando el script incorporado dentro del documento
Incrustar los datos en HTML garantiza que la aplicación no espere a que se cargue. También reduce la complejidad del sistema, ya que no necesita manejar el estado de arranque.Sin embargo, esta no es una buena idea si dicha técnica retrasa el renderizado inicial.En este caso, así como si está enviando un documento HTML en caché a través de un trabajador de servicios, puede usar el script incorporado para descargar estos datos como alternativa. Puede hacerlo disponible como un objeto global, aquí hay una promesa:window.userDataPromise = fetch("/me")
Si los datos están listos, y en tal situación, la aplicación puede comenzar a procesar de inmediato o esperar hasta que esté lista.Cuando utilice ambos métodos, debe saber de antemano qué datos cargará la página antes de que la aplicación comience a representarse. Esto suele ser obvio para los datos relacionados con el usuario (nombre de usuario, notificaciones, etc.), pero es más difícil con el contenido específico de una página en particular. Quizás tenga sentido resaltar las páginas más importantes y escribir su propia lógica para ellas.No bloquee el renderizado mientras espera datos irrelevantes
A veces, para generar datos, debe ejecutar una lógica compleja lenta en el back-end. En tales casos, puede intentar descargar primero una versión más simple de los datos, si es suficiente para que la aplicación sea funcional e interactiva.Por ejemplo, una herramienta de análisis puede descargar primero una lista de todos los gráficos antes de cargar los datos. Esto permite al usuario buscar de inmediato el diagrama que le interesa y también ayuda a distribuir las solicitudes de backend a diferentes servidores.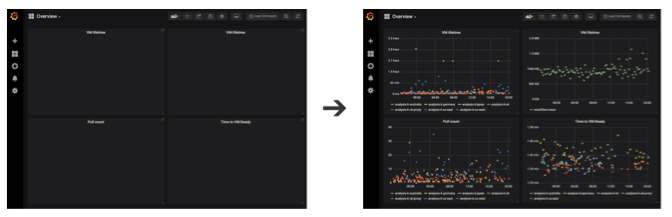
Evitar consultas de datos consecutivas
Esto puede contradecir el párrafo anterior de que es mejor publicar datos no esenciales en una solicitud por separado. Por lo tanto, debe aclararse: evite las cadenas con solicitudes de datos secuenciales, si cada solicitud completada no conduce al hecho de que se muestra más información al usuario .En lugar de consultar primero qué usuario ha iniciado sesión y luego solicitar una lista de sus grupos, devuelva inmediatamente la lista de grupos junto con la información del usuario en la primera consulta. Puede usar GraphQL para esto , pero el punto final user?includeTeams=truetambién funciona bien.Representación del lado del servidor
La representación del lado del servidor significa la representación previa de la aplicación, por lo que se devuelve un HTML de página completa a solicitud del cliente. ¡El cliente ve la página completamente renderizada, sin esperar a que se carguen códigos o datos adicionales!Como el servidor envía al cliente solo HTML estático, la aplicación no es interactiva en este momento. Debe descargar la aplicación en sí, iniciar la lógica de representación y luego conectar los oyentes de eventos necesarios al DOM.Utilice la representación del lado del servidor si ver contenido no interactivo es valioso en sí mismo. También es bueno almacenar HTML en caché en el servidor e inmediatamente devolverlo a todos los usuarios sin demora. Por ejemplo, la representación del lado del servidor es excelente cuando se usa React para mostrar publicaciones de blog.AEste artículo de Mikhail Yanashek describe cómo combinar los trabajadores de servicios y la representación del lado del servidor.Siguiente página
En algún momento, el usuario está a punto de presionar un botón e ir a la página siguiente. Desde el momento en que abre la página de inicio, controla lo que sucede en el navegador, por lo que puede prepararse para la próxima interacción.Precarga de recursos
Si precarga el código necesario para la página siguiente, el retraso desaparece cuando el usuario inicia la navegación. Utilice etiquetas de captación previa o webpackPrefetchpara importación dinámica:import(
"./TodoList"
)
Considere qué tipo de carga coloca en el usuario en términos de tráfico y ancho de banda, especialmente si está conectado a través de una conexión móvil. Si una persona descargó la versión móvil del sitio y el modo de almacenamiento de datos está activo, entonces es razonable precargar de manera menos agresiva.Considere estratégicamente qué partes de la aplicación necesitará el usuario antes.Reutilización de datos ya descargados
Caché los datos localmente en su aplicación y úselos para evitar futuras solicitudes. Si el usuario va de la lista de sus grupos a la página "Editar grupo", puede hacer la transición al instante, reutilizando los datos descargados previamente sobre el grupo.Tenga en cuenta que esto no funcionará si el objeto es editado a menudo por otros usuarios y los datos descargados pueden quedar desactualizados. En estos casos, hay una opción para mostrar primero los datos existentes de solo lectura mientras se ejecuta simultáneamente una solicitud de datos actualizados.Conclusión
Este artículo enumera una serie de factores que pueden ralentizar su página en diferentes etapas del proceso de carga. Herramientas como Chrome DevTools , WebPageTest y Lighthouse lo ayudarán a determinar cuáles de estos factores afectan su aplicación.En la práctica, rara vez la optimización se dirige inmediatamente en todas las direcciones. Necesitamos descubrir qué tiene el mayor impacto en los usuarios y centrarnos en ello.Mientras escribía el artículo, me di cuenta de una cosa importante: creía firmemente que muchas solicitudes de servidores individuales eran malas para el rendimiento. Este era el caso en el pasado, cuando cada solicitud requería una conexión separada, y los navegadores permitían solo unas pocas conexiones por dominio. Pero con HTTP / 2 y los navegadores modernos, este ya no es el caso.Hay buenos argumentos a favor de dividir la aplicación en partes (con consultas multiplicadas). Esto le permite descargar solo los recursos necesarios y es mejor usar el caché, ya que solo los archivos modificados tendrán que volver a cargarse.