Mi nombre es Pavel Parkhomenko, soy un desarrollador de ML. En este artículo, me gustaría hablar sobre el diseño del servicio Yandex.Zen y compartir mejoras técnicas, cuya introducción permitió aumentar la calidad de las recomendaciones. En la publicación aprenderá cómo encontrar lo más relevante para el usuario entre millones de documentos en solo unos pocos milisegundos; cómo hacer la descomposición continua de una matriz grande (que consta de millones de columnas y decenas de millones de filas) para que los nuevos documentos reciban su vector en decenas de minutos; cómo reutilizar la descomposición de la matriz del artículo del usuario para obtener una buena representación vectorial para el video. Nuestra base de datos de recomendaciones contiene millones de documentos de varios formatos: artículos de texto creados en nuestra plataforma y tomados de sitios externos, videos, narraciones y publicaciones cortas. El desarrollo de dicho servicio está asociado con una gran cantidad de desafíos técnicos. Éstos son algunos de ellos:
Nuestra base de datos de recomendaciones contiene millones de documentos de varios formatos: artículos de texto creados en nuestra plataforma y tomados de sitios externos, videos, narraciones y publicaciones cortas. El desarrollo de dicho servicio está asociado con una gran cantidad de desafíos técnicos. Éstos son algunos de ellos:- Tareas computacionales separadas: realice todas las operaciones pesadas fuera de línea y, en tiempo real, solo realice una aplicación rápida de modelos para ser responsable de 100-200 ms.
- Considere rápidamente las acciones del usuario. Para esto, es necesario que todos los eventos se envíen instantáneamente al recomendante y afecten el resultado de los modelos.
- Haga la cinta para que los nuevos usuarios se adapten rápidamente a su comportamiento. Las personas que acaban de ingresar al sistema deberían sentir que sus comentarios influyen en las recomendaciones.
- Comprenda rápidamente a quién recomendar un nuevo artículo.
- Responda rápidamente a la aparición constante de nuevos contenidos. Todos los días se publican decenas de miles de artículos, y muchos de ellos tienen una vida útil limitada (por ejemplo, noticias). Esta es su diferencia con las películas, la música y otras creaciones de contenido costosas y de larga duración.
- Transfiera conocimiento de un dominio de dominio a otro. Si el sistema de recomendaciones tiene modelos entrenados para artículos de texto y le agregamos video, puede reutilizar los modelos existentes para que el nuevo tipo de contenido esté mejor clasificado.
Te diré cómo resolvimos estos problemas.Selección de candidatos
¿Cómo en unos milisegundos reducir el conjunto de documentos bajo consideración en miles de veces, prácticamente sin comprometer la calidad de la clasificación?Supongamos que capacitamos a muchos modelos de ML, generamos atributos basados en ellos y capacitamos a otro modelo que clasifica los documentos para el usuario. Todo estaría bien, pero no puede simplemente tomar y contar todas las señales de todos los documentos en tiempo real, si hay millones de estos documentos, y las recomendaciones deben construirse en 100-200 ms. La tarea es elegir entre millones un determinado subconjunto que se clasificará para el usuario. Este paso se denomina comúnmente selección de candidatos. Tiene varios requisitos. En primer lugar, la selección debe realizarse muy rápidamente, de modo que quede el mayor tiempo posible en el ranking. En segundo lugar, al reducir en gran medida el número de documentos para la clasificación, debemos mantener los documentos relevantes para el usuario lo más completo posible.Nuestro principio de selección de candidatos ha evolucionado evolutivamente, y en este momento hemos llegado a un esquema de varias etapas: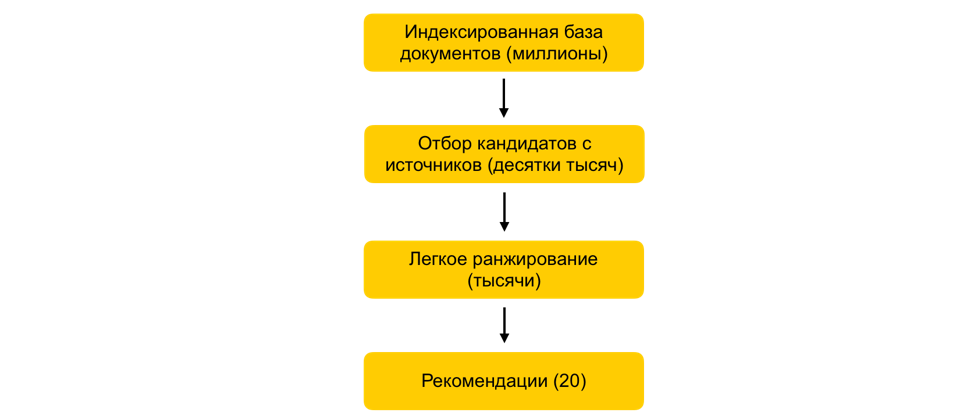 primero, todos los documentos se dividen en grupos, y los documentos más populares se toman de cada grupo. Los grupos pueden ser sitios, temas, grupos. Para cada usuario, según su historia, se seleccionan los grupos más cercanos a él y ya se les han quitado los mejores documentos. También utilizamos el índice kNN para seleccionar los documentos más cercanos al usuario en tiempo real. Existen varios métodos para construir el índice kNN, tenemos el HNSW mejor ganado(Gráficos jerárquicos del mundo pequeño navegable). Este es un modelo jerárquico que le permite encontrar N vectores más cercanos para un usuario a partir de una millonésima base de datos en unos pocos milisegundos. Anteriormente, indexamos sin conexión toda nuestra base de datos de documentos. Dado que la búsqueda en el índice funciona bastante rápido, si hay varias incrustaciones fuertes, puede hacer varios índices (un índice para cada incrustación) y acceder a cada uno de ellos en tiempo real.Todavía tenemos decenas de miles de documentos para cada usuario. Todavía es mucho para contar todos los atributos, por lo que en esta etapa aplicamos una clasificación fácil: un modelo de clasificación pesado ligero con menos atributos. La tarea es predecir qué documentos tendrá el modelo pesado en la parte superior. Los documentos con la predicción más alta se utilizarán en el modelo pesado, es decir, en la última etapa de la clasificación. Este enfoque permite que decenas de milisegundos reduzcan la base de datos de documentos considerados para el usuario de millones a miles.
primero, todos los documentos se dividen en grupos, y los documentos más populares se toman de cada grupo. Los grupos pueden ser sitios, temas, grupos. Para cada usuario, según su historia, se seleccionan los grupos más cercanos a él y ya se les han quitado los mejores documentos. También utilizamos el índice kNN para seleccionar los documentos más cercanos al usuario en tiempo real. Existen varios métodos para construir el índice kNN, tenemos el HNSW mejor ganado(Gráficos jerárquicos del mundo pequeño navegable). Este es un modelo jerárquico que le permite encontrar N vectores más cercanos para un usuario a partir de una millonésima base de datos en unos pocos milisegundos. Anteriormente, indexamos sin conexión toda nuestra base de datos de documentos. Dado que la búsqueda en el índice funciona bastante rápido, si hay varias incrustaciones fuertes, puede hacer varios índices (un índice para cada incrustación) y acceder a cada uno de ellos en tiempo real.Todavía tenemos decenas de miles de documentos para cada usuario. Todavía es mucho para contar todos los atributos, por lo que en esta etapa aplicamos una clasificación fácil: un modelo de clasificación pesado ligero con menos atributos. La tarea es predecir qué documentos tendrá el modelo pesado en la parte superior. Los documentos con la predicción más alta se utilizarán en el modelo pesado, es decir, en la última etapa de la clasificación. Este enfoque permite que decenas de milisegundos reduzcan la base de datos de documentos considerados para el usuario de millones a miles.Paso de ALS en tiempo de ejecución
¿Cómo tener en cuenta los comentarios del usuario inmediatamente después de un clic?Un factor importante en las recomendaciones es el tiempo de respuesta a los comentarios del usuario. Esto es especialmente importante para los nuevos usuarios: cuando una persona está comenzando a usar el sistema de recomendaciones, recibe una secuencia no personalizada de documentos sobre diversos temas. Tan pronto como haga el primer clic, debe tener esto en cuenta de inmediato y adaptarse a sus intereses. Si todos los factores se calculan fuera de línea, una respuesta rápida del sistema será imposible debido al retraso. Por lo tanto, debe procesar las acciones del usuario en tiempo real. Para estos fines, usamos el paso ALS en tiempo de ejecución para construir una representación vectorial del usuario.Supongamos que tenemos una representación vectorial para todos los documentos. Por ejemplo, podemos construir fuera de línea sobre la base de las incrustaciones de texto del artículo utilizando ELMo, BERT u otros modelos de aprendizaje automático. ¿Cómo se puede obtener una representación vectorial de los usuarios en el mismo espacio en función de su interacción en el sistema?El principio general de la formación y descomposición de la matriz del documento del usuario.m n . . m x n: , — . , ́ , . (, , ) - — , 1, –1.
: P (m x d) Q (d x n), d — ( ). d- ( — P, — Q). . , , .

Una de las posibles formas de descomposición de la matriz es ALS (Alternating Least Squares). Optimizaremos la siguiente función de pérdida:
Aquí r ui es la interacción del usuario u con el documento i, q i es el vector del documento i, p u es el vector del usuario u.Luego, el vector de usuario que es óptimo desde el punto de vista del error cuadrático medio (para vectores de documentos fijos) se encuentra analíticamente resolviendo la regresión lineal correspondiente.Esto se llama un paso ALS. Y el algoritmo ALS en sí consiste en el hecho de que alternativamente arreglamos una de las matrices (usuarios y artículos) y actualizamos la otra, encontrando la solución óptima.Afortunadamente, encontrar la representación vectorial de un usuario es una operación bastante rápida que se puede hacer en tiempo de ejecución utilizando instrucciones vectoriales. Este truco le permite tener en cuenta de inmediato los comentarios del usuario en el ranking. Se puede usar la misma incrustación en el índice kNN para mejorar la selección de candidatos.Filtrado colaborativo distribuido
¿Cómo hacer una factorización de matriz distribuida incremental y encontrar rápidamente una representación vectorial de nuevos artículos?El contenido no es la única fuente de señales para recomendaciones. La información colaborativa es otra fuente importante. Los buenos signos en la clasificación se pueden obtener tradicionalmente a partir de la descomposición de la matriz de documentos del usuario. Pero cuando intentamos hacer esta descomposición, nos encontramos con problemas:1. Tenemos millones de documentos y decenas de millones de usuarios. La matriz no cabe completamente en una máquina, y la descomposición será muy larga.2. La mayor parte del contenido en el sistema tiene una vida útil corta: los documentos siguen siendo relevantes por solo unas pocas horas. Por lo tanto, es necesario construir su representación vectorial lo más rápido posible.3. Si crea la descomposición inmediatamente después de la publicación del documento, un número suficiente de usuarios no tendrá tiempo para evaluarlo. Por lo tanto, es probable que su representación vectorial no sea muy buena.4. Si al usuario le gusta o no le gusta, no podremos tener esto en cuenta de inmediato en la expansión.Para resolver estos problemas, implementamos una descomposición distribuida de la matriz de documentos del usuario con una actualización incremental frecuente. ¿Cómo funciona exactamente?Supongamos que tenemos un grupo de N máquinas (N en los cientos) y queremos hacer una descomposición distribuida de la matriz en ellas, que no cabe en una máquina. La pregunta es cómo realizar esta descomposición para que, por un lado, haya suficientes datos en cada máquina y, por otro, para que los cálculos sean independientes.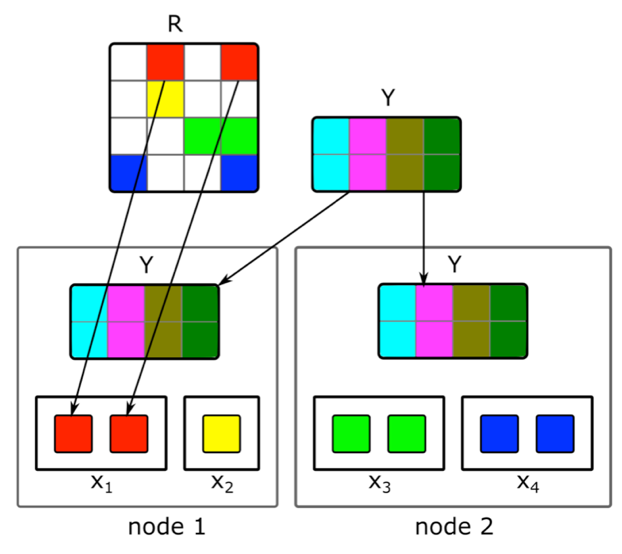 Utilizaremos el algoritmo de descomposición ALS descrito anteriormente. Considere cómo realizar un paso de ALS de manera distribuida; el resto de los pasos serán similares. Supongamos que tenemos una matriz fija de documentos y queremos construir una matriz de usuarios. Para hacer esto, lo dividimos en N partes en filas, cada parte contendrá aproximadamente el mismo número de filas. Enviaremos a cada máquina celdas no vacías de las líneas correspondientes, así como una matriz de incrustaciones de documentos (en su totalidad). Como no es muy grande y la matriz de documentos del usuario es generalmente muy escasa, estos datos se ajustarán en una máquina normal.Tal truco se puede repetir durante varias eras hasta que el modelo converja, cambiando alternativamente la matriz fija. Pero incluso entonces, la descomposición de la matriz puede durar varias horas. Y esto no resuelve el problema de la necesidad de recibir rápidamente incrustaciones de nuevos documentos y actualizar las incrustaciones de aquellos sobre los que había poca información al construir el modelo.La introducción de una actualización incremental rápida del modelo nos ayudó. Supongamos que tenemos un modelo entrenado actual. Desde su capacitación, han aparecido nuevos artículos con los que nuestros usuarios han interactuado, así como artículos que han tenido poca interacción con la capacitación. Para incrustar rápidamente dichos artículos, utilizamos las incrustaciones de usuarios obtenidas durante la primera gran capacitación del modelo y tomamos un paso de ALS para calcular la matriz de documentos con una matriz fija de usuarios. Esto le permite recibir incrustaciones bastante rápido, dentro de unos minutos después de la publicación de un documento, y a menudo actualizar las incrustaciones de documentos nuevos.Para tener en cuenta de inmediato las acciones humanas para recomendaciones, en tiempo de ejecución no utilizamos incrustaciones de usuario recibidas sin conexión. En cambio, tomamos el paso ALS y obtenemos el vector de usuario actual.
Utilizaremos el algoritmo de descomposición ALS descrito anteriormente. Considere cómo realizar un paso de ALS de manera distribuida; el resto de los pasos serán similares. Supongamos que tenemos una matriz fija de documentos y queremos construir una matriz de usuarios. Para hacer esto, lo dividimos en N partes en filas, cada parte contendrá aproximadamente el mismo número de filas. Enviaremos a cada máquina celdas no vacías de las líneas correspondientes, así como una matriz de incrustaciones de documentos (en su totalidad). Como no es muy grande y la matriz de documentos del usuario es generalmente muy escasa, estos datos se ajustarán en una máquina normal.Tal truco se puede repetir durante varias eras hasta que el modelo converja, cambiando alternativamente la matriz fija. Pero incluso entonces, la descomposición de la matriz puede durar varias horas. Y esto no resuelve el problema de la necesidad de recibir rápidamente incrustaciones de nuevos documentos y actualizar las incrustaciones de aquellos sobre los que había poca información al construir el modelo.La introducción de una actualización incremental rápida del modelo nos ayudó. Supongamos que tenemos un modelo entrenado actual. Desde su capacitación, han aparecido nuevos artículos con los que nuestros usuarios han interactuado, así como artículos que han tenido poca interacción con la capacitación. Para incrustar rápidamente dichos artículos, utilizamos las incrustaciones de usuarios obtenidas durante la primera gran capacitación del modelo y tomamos un paso de ALS para calcular la matriz de documentos con una matriz fija de usuarios. Esto le permite recibir incrustaciones bastante rápido, dentro de unos minutos después de la publicación de un documento, y a menudo actualizar las incrustaciones de documentos nuevos.Para tener en cuenta de inmediato las acciones humanas para recomendaciones, en tiempo de ejecución no utilizamos incrustaciones de usuario recibidas sin conexión. En cambio, tomamos el paso ALS y obtenemos el vector de usuario actual.Transferir a otra área de dominio
¿Cómo usar los comentarios de un usuario para enviar artículos de texto para construir una representación vectorial de un video?Inicialmente, solo recomendamos artículos de texto, por lo que muchos de nuestros algoritmos se centran en este tipo de contenido. Pero al agregar contenido de un tipo diferente, nos enfrentamos a la necesidad de adaptar modelos. ¿Cómo resolvimos este problema usando el video de ejemplo? Una opción es volver a capacitar a todos los modelos desde cero. Pero esto es mucho tiempo, además, algunos de los algoritmos exigen el volumen de la muestra de entrenamiento, que aún no está en la cantidad adecuada para un nuevo tipo de contenido en los primeros momentos de su vida en el servicio.Nos fuimos por el otro lado y reutilizamos modelos de texto para el video. Al crear representaciones vectoriales del video, el mismo truco con ALS nos ayudó. Tomamos una representación vectorial de los usuarios basada en artículos de texto y tomamos el paso de ALS usando información sobre las vistas de video. Así que obtuvimos fácilmente una representación vectorial del video. Y en tiempo de ejecución, simplemente calculamos la proximidad entre el vector de usuario obtenido de los artículos de texto y el vector de video.Conclusión
El desarrollo del núcleo de un sistema de recomendación en tiempo real está lleno de muchas tareas. Es necesario procesar rápidamente los datos y aplicar métodos de ML para usar estos datos de manera efectiva; Construya sistemas distribuidos complejos capaces de procesar señales de usuario y nuevas unidades de contenido en un tiempo mínimo; y muchas otras tareasEn el sistema actual, cuyo dispositivo describí, la calidad de las recomendaciones para el usuario aumenta con su actividad y la duración del servicio. Pero, por supuesto, aquí radica la principal dificultad: es difícil para el sistema comprender de inmediato los intereses de una persona que interactúa poco con el contenido. Mejorar las recomendaciones para nuevos usuarios es nuestra principal preocupación. Continuaremos optimizando los algoritmos para que el contenido relevante para la persona ingrese a su feed más rápido y lo irrelevante no aparezca.