 Ilustración de melmagazine.com (Fuente: melmagazine.com/wp-content/uploads/2019/11/DNA-1280x533.jpg )Actualmente, las redes públicas con canales que no están protegidos del intruso se usan ampliamente para el intercambio de información. Los mensajes en una red de computadoras y usuarios tan conectados se ven obligados a protegerse. Como el usuario no puede proteger los canales de mensajes por sí mismo, protege el mensaje.¿Qué está protegido en el mensaje? En primer lugar, la sintaxis (integridad) para este propósito utiliza lacodificación(codificación y análisis de códigos) y, en segundo lugar, la semántica (confidencialidad) para la queseutiliza lacriptología.(criptografía y análisis criptográfico), en tercer lugar, indirectamente, el infractor puede limitar la disponibilidad del mensaje por ocultar el hecho de su transmisión, que utiliza steganology (esteganografía y steganalysis).Las posibilidades enumeradas se proporcionan teórica y prácticamente en diversos grados, y aunque cada dirección se ha desarrollado durante bastante tiempo, todavía están lejos de completarse. En el presente trabajo, abordaremos solo un tema en particular: el análisis de los códigos de mensajes.
Ilustración de melmagazine.com (Fuente: melmagazine.com/wp-content/uploads/2019/11/DNA-1280x533.jpg )Actualmente, las redes públicas con canales que no están protegidos del intruso se usan ampliamente para el intercambio de información. Los mensajes en una red de computadoras y usuarios tan conectados se ven obligados a protegerse. Como el usuario no puede proteger los canales de mensajes por sí mismo, protege el mensaje.¿Qué está protegido en el mensaje? En primer lugar, la sintaxis (integridad) para este propósito utiliza lacodificación(codificación y análisis de códigos) y, en segundo lugar, la semántica (confidencialidad) para la queseutiliza lacriptología.(criptografía y análisis criptográfico), en tercer lugar, indirectamente, el infractor puede limitar la disponibilidad del mensaje por ocultar el hecho de su transmisión, que utiliza steganology (esteganografía y steganalysis).Las posibilidades enumeradas se proporcionan teórica y prácticamente en diversos grados, y aunque cada dirección se ha desarrollado durante bastante tiempo, todavía están lejos de completarse. En el presente trabajo, abordaremos solo un tema en particular: el análisis de los códigos de mensajes.Introducción
El código genético (HA) fue elegido como el objeto de análisis. Puede familiarizarse con un curioso ejemplo del uso del Código Civil en el campo de la seguridad de la información (aparentemente no profesional y, por lo tanto, no exitoso) aquí.En la teoría de la codificación, se pueden distinguir dos direcciones importantes: la codificación de la fuente de información y la codificación del canal. El primero de ellos es implementado, por regla general, por la parte transmisora y tiene el objetivo de eliminar la redundancia de mensajes (por ejemplo, código Morse), el segundo propósito es detectar y eliminar errores en los mensajes. Antes de la aparición de los códigos correctores, el problema de eliminar errores se resolvió mediante la retransmisión del fragmento distorsionado del mensaje a petición del lado receptor.Aquí observamos el hecho de que es imposible para el lado receptor descifrar el cifrado correctamente si se producen errores en su texto. Los cifrados no permiten detectar errores, ni siquiera corregirlos. Por esta razón, en el lado de transmisión del sistema de comunicación, el cifrado del mensaje está codificado con un código de corrección, y en el lado de recepción, el decodificador en el mensaje recibido detecta (si lo hay) y corrige los errores.Después de eso, el sistema de cifrado entra en juego y el destinatario legítimo recibe un mensaje descifrado. Estos son, en términos generales, el funcionamiento de las redes que intercambian mensajes seguros.En este trabajo, analizaremos en detalle el código genético muy importante, que fue creado no por la mente humana, sino por la naturaleza misma (un caso raro).La historia de un descubrimiento y el premio Nobel
Nos preguntamos cómo, a nivel de la genética y el metabolismo de los organismos (células), ¿se implementa la naturaleza tales disposiciones de intercambio de información en la vida de las especies y sus representantes individuales?Antes de la Segunda Guerra Mundial, el mundo científico sabía que en los organismos vivos la transmisión de rasgos hereditarios de generación en generación se lleva a cabo a través de unidades químicas (genes) relativamente simples, que incluyen una gran cantidad de información necesaria para la continuación y reproducción de la vida.Todos los genes (no las proteínas) se unen en cadenas (cromosomas) y se materializan en ácido desoxirribonucleico (ADN). Los expertos no tenían claridad sobre cómo sucede todo y cómo se estructura el ADN en sí.Jóvenes investigadores, el físico británico F. Crick y el biólogo estadounidense J. Watson, en 1953 (25.4) publicaron un artículo en la revista Nature sobre la estructura del ácido desoxirribonucleico. Al comienzo de su trabajo en 1949, James Watson tenía 23 años, Francis Crick y Maurice Wilkins, 33 cada uno.En el artículo, los autores describieron un modelo de la estructura espacial del ADN en forma de una doble hélice, dos hilos de los cuales estaban torcidos a la derecha. Las hebras resultaron estar conectadas por "pasos" transversales formados a partir de nucleótidos.Definición . Los nucleótidos son compuestos que consisten en azúcar, bases que contienen nitrógeno (purina o pirimidina) y ácido fosfórico. Los nucleótidos son los "bloques de construcción" para el ADN y el ARN.
Esta hélice de ADN es el portador del código genético, el código de herencia de los rasgos de los organismos de animales y plantas. Este fue un nuevo trabajo completamente inusual sobre la estructura y las propiedades de una molécula de ácido desoxirribonucleico.El modelo de ADN de autores jóvenes se confirmó comparándolo con un patrón de difracción de rayos X de la estructura cristalina del ADN del biofísico inglés Maurice Wilkins. Más tarde, se descubrió un código genético que contiene y transmite información sobre la síntesis de la estructura y composición de las proteínas, los componentes principales de cada célula de organismos vivos que implementa el ciclo celular.Definición . El ciclo celular es la alternancia correcta de períodos de descanso relativo con períodos de división celular.
En el mismo año, los autores publicaron más tarde otro artículo que describía un posible mecanismo para copiar ADN mediante síntesis matricial en la división de las células vivas. La doble hélice del ADN se asemeja a un "rayo".Cada hilo de la espiral, después de "deshacer el bloqueo" y diluir los hilos, se convirtió en una matriz de síntesis y se completó con un segundo hilo de material del citoplasma de la célula de acuerdo con el principio de complementariedad para completar el ADN. También dijo que cierta secuencia de bases (codones, trillizos) es un código que contiene información genética.La idea de matematizar el código fue expresada por primera vez por G. Gamov en un artículo en 1954 como el problema de traducir palabras de un alfabeto (sistema) de cuatro letras a palabras de un alfabeto de veinte letras. Presentó el problema de codificar fenómenos de la vida no como un producto bioquímico, sino como un problema matemático combinatorio. Los esfuerzos preliminares duraderos de los autores de este trabajo están bien descritos en el libro de D. Watson, The Thread of Life.En 1962, Watson, Crick y Wilkins recibieron el Premio Nobel de Fisiología o Medicina "por sus descubrimientos en el campo de la estructura molecular de los ácidos nucleicos y por determinar su papel en la transferencia de información en la materia viva".Tenían información sobre los siguientes hechos:- En 1866, Gregor Mendel formuló las disposiciones de que los "elementos", más tarde llamados genes, determinan la herencia de las propiedades físicas de los individuos de la especie.
- , , () , , .
- 1869 . , . . () (). . 4- ( ): (), (), (G), (); (), (U) , (G), (), ( ) .
- , , – , .
- 1950 . , 4- .
- , , .
- , 20- , (), .
- 1944 « ? ». : « - , , ?».
- 1954 , () 4- 20- , , .
Los investigadores tuvieron que dar el siguiente paso, y se dio.No faltaron hipótesis y suposiciones, pero alguien tuvo que verificar su verdad.Códigos superpuestos (una letra de nucleótido es parte de más de un codón): triangular, mayor-menor y secuencial, propuesto por Gamov y colegas;códigos no superpuestos: combinación de Gamow e Ichas, el "código libre de comas" de Scream, Griffith y Orgel. En el código de combinación, los aminoácidos (20) están codificados por tripletes de 4 nucleótidos, pero su orden no es importante, pero solo su composición: los tripletes TTA, TAT, ATT codifican el mismo aminoácido en las proteínas.El código sin comas explica cómo se selecciona el "marco de lectura". Tal "ventana deslizante" a lo largo de la cadena de ADN, donde siguen las letras, una tras otra sin separadores (comas) en palabras, sugiere que las palabras son de alguna manera diferentes. De acuerdo con el modelo de F. Crick, se hizo una suposición: todos los trillizos se dividen en significativos, es decir, que corresponden a aminoácidos específicos y que no tienen significado.Si solo se forman trillizos significativos en el ADN, entonces en otro "marco de lectura" dichos trillizos resultarán sin sentido. Los autores de este código demostraron que es posible elegir tripletas que satisfagan tales requisitos y que hay exactamente 20. Por supuesto, los autores no tenían plena confianza en su corrección.De hecho, después de 1960, se demostró que los codones, considerados por Crick como insensatos, llevaban a cabo la síntesis de proteínas in vitro, y en 1965 se estableció el significado de los 64 codones tripletes. También resultó que varios aminoácidos están codificados por dos, tres, cuatro e incluso seis tripletes diferentes, es decir, hay una cierta redundancia, cuyo propósito queda por determinar.Código genético de la vida. Información heredada
. – , ( , G, C, T), , . ( ) – . . .
Para codificar cada uno de los 20 tipos de aminoácidos canónicos, a partir de los cuales se construyen casi todas las proteínas y la señal de parada terminal, un conjunto de tres nucleótidos (letras) llamado triplete (codón) es suficiente. La secuencia de codones forma un gen en la cadena cromosómica y determina la secuencia de aminoácidos en la cadena polipeptídica de la proteína codificada por este gen. Había un concepto de "un gen: una enzima".La presentación clásica de la información (linealidad de su grabación) son textos en un sentido amplio (discurso, letras, libros, imágenes, películas, música, etc.) de esta palabra en algún lenguaje natural (EY). El lenguaje incluye un vocabulario extenso (vocabulario), y si tiene un lenguaje escrito aparte del lenguaje hablado, entonces el alfabeto con una gramática.Para preservar la información durante mucho tiempo y transferir copias de ella, se requiere un sistema de escritura y memoria sólido y bien protegido. La información hereditaria de los organismos vivos está escrita por el EY de la naturaleza en textos largos con palabras en un cierto alfabeto "molecular", que se almacenan en forma de cromosomas en los núcleos de todas las células de los organismos vivos.F. Crick (1958) formula los procesos y formas de transferir información registrada en sus moléculas transportadoras naturales en forma del dogma central de la biología molecular . Tres procesos principales proporcionan el control de todos los demás procesos del funcionamiento celular y la vida de los organismos en su conjunto.Estos procesos son: replicación , transcripción y traducción.. Además, se discutirán con más detalle. La información en los organismos se transmite solo en una dirección desde los ácidos nucleicos (ADN → ARN → proteína) a una proteína; la transmisión inversa no existe. Son posibles casos especiales de ADN → proteína, ARN → ARN, ARN → ADN.La lectura de información a lo largo de cadenas moleculares es permisible en una sola dirección hacia adelante. Se utiliza el término "marco de lectura".Definición . Un marco de lectura (abierto) es una secuencia de codones no superpuestos capaces de sintetizar una proteína, comenzando con un codón de inicio y terminando con un codón de parada. La trama está determinada por el primer triplete desde el que comienza la transmisión.
Para comenzar a transmitir, un codón de inicio no es suficiente, también necesita un codón de iniciación (hay tres de ellos: AUG, GUG, UUG). Después de leerlo, la traducción se realiza leyendo secuencialmente los codones del ARNr ribosómico y uniendo los aminoácidos entre sí por el ribosoma hasta que se alcanza el codón de parada.Durante la traducción, los codones siempre se "leen" de algún símbolo de inicio (AUG) y no se superponen. La lectura después del inicio de triplete tras triplete va al codón de terminación de la finalización de la síntesis de la cadena de polipéptidos de proteínas.Estos hechos se resumen en una tabla de métodos para transmitir información genética.Tabla 1 - el dogma central de la biología molecular La historia del estudio de los textos de la herencia de los organismos, su comprensión, es larga, rica en descubrimientos, logros, delirios y decepciones. La lista de eventos en la historia de la comprensión (cognición) de los textos de la naturaleza es de indudable interés, tanto para la ciencia como para cada persona individual.Las palabras de los textos son muy largas, pero el alfabeto de la escritura "EYA nature" contiene solo cuatro letras: estas son bases moleculares: en ARN es A (adenina), C (citosina), G (guanina), U (uracilo) (en ADN, el uracilo se reemplaza en T (timina)). El lenguaje de la vida silvestre es el lenguaje de las moléculas.Los biólogos han establecido que cada palabra del texto de herencia está formada por una molécula de ADN de polímero (ácido desoxirribonucleico, descubierta en 1868 por el médico I.F. Misher), construida de 4 bases (nucleótidos - de nuclear - nuclear).Las bases están unidas (conectadas) entre sí en pares, A ← → T, T ← → A, G ← → C, C ← → G con enlaces de hidrógeno especiales que implementan el principio de complementariedad. Estos hechos fueron establecidos en diferentes momentos, por diferentes científicos y métodos de muchas ciencias (física, química, biología, citología, genética, etc.). Dificultades en la forma de conocer esta NJ se encontraron constantemente.Las moléculas de ADN no cristalizaron, pero cuando se hizo esto, la tarea de establecer la estructura del ADN se redujo a resolver el problema inverso del análisis de difracción de rayos X (transformada de Fourier del patrón de difracción del cristal creado en la pantalla por rayos X).El modelo calculado y ensamblado a mano por J. Watson y Francis Crick en 1953 es similar al juego de niños LEGO, donde los elementos eran bases moleculares y las distancias interatómicas y los ángulos de pivote se mantenían con mucha precisión, la estructura cromosómica se reproducía a gran escala.Este modelo prácticamente confirmó las diversas hipótesis de los teóricos y demostró de manera convincente la ausencia de discrepancias con los experimentos prácticos y los resultados del análisis de difracción de rayos X del ADN cristalino.Los datos detallados principales sobre la estructura química del ADN y las características numéricas del modelo fueron obtenidos por Rosalinda Franklin y M. Wilkins a principios de 1953 en el laboratorio de análisis de rayos X. El conflicto de los científicos se describe en la novela "Soledad en la red" de Janusz Leon Wisniewski.La presencia de la estructura visual del ADN y sus características cuantitativas impulsaron el desarrollo de la genética y todas las biociencias, de donde surgió la idea del proyecto del Genoma Humano en 2000. Watson se convirtió en el primer líder de este proyecto, el conjunto de cromosomas del Homo sapiens humano fue completamente descifrado dentro del proyecto. El mapa genético completo del primer cromosoma se completó en 2006. El mapa contiene 3141 genes y 991 pseudogenes.Desde el punto de vista de las matemáticas, cuatro elementos del alfabeto se pueden atribuir a cuatro elementos de un campo de Galois extendido finito GF (2 2 ) = ( 0, 1, α, β ), las operaciones con las que se realiza el módulo del polinomio irreducible p (x) = x 2 + x + 1 . Entonces α + β = 1, α ∙ β = 1y el mapeo de los elementos de campo a las letras toma la forma
La historia del estudio de los textos de la herencia de los organismos, su comprensión, es larga, rica en descubrimientos, logros, delirios y decepciones. La lista de eventos en la historia de la comprensión (cognición) de los textos de la naturaleza es de indudable interés, tanto para la ciencia como para cada persona individual.Las palabras de los textos son muy largas, pero el alfabeto de la escritura "EYA nature" contiene solo cuatro letras: estas son bases moleculares: en ARN es A (adenina), C (citosina), G (guanina), U (uracilo) (en ADN, el uracilo se reemplaza en T (timina)). El lenguaje de la vida silvestre es el lenguaje de las moléculas.Los biólogos han establecido que cada palabra del texto de herencia está formada por una molécula de ADN de polímero (ácido desoxirribonucleico, descubierta en 1868 por el médico I.F. Misher), construida de 4 bases (nucleótidos - de nuclear - nuclear).Las bases están unidas (conectadas) entre sí en pares, A ← → T, T ← → A, G ← → C, C ← → G con enlaces de hidrógeno especiales que implementan el principio de complementariedad. Estos hechos fueron establecidos en diferentes momentos, por diferentes científicos y métodos de muchas ciencias (física, química, biología, citología, genética, etc.). Dificultades en la forma de conocer esta NJ se encontraron constantemente.Las moléculas de ADN no cristalizaron, pero cuando se hizo esto, la tarea de establecer la estructura del ADN se redujo a resolver el problema inverso del análisis de difracción de rayos X (transformada de Fourier del patrón de difracción del cristal creado en la pantalla por rayos X).El modelo calculado y ensamblado a mano por J. Watson y Francis Crick en 1953 es similar al juego de niños LEGO, donde los elementos eran bases moleculares y las distancias interatómicas y los ángulos de pivote se mantenían con mucha precisión, la estructura cromosómica se reproducía a gran escala.Este modelo prácticamente confirmó las diversas hipótesis de los teóricos y demostró de manera convincente la ausencia de discrepancias con los experimentos prácticos y los resultados del análisis de difracción de rayos X del ADN cristalino.Los datos detallados principales sobre la estructura química del ADN y las características numéricas del modelo fueron obtenidos por Rosalinda Franklin y M. Wilkins a principios de 1953 en el laboratorio de análisis de rayos X. El conflicto de los científicos se describe en la novela "Soledad en la red" de Janusz Leon Wisniewski.La presencia de la estructura visual del ADN y sus características cuantitativas impulsaron el desarrollo de la genética y todas las biociencias, de donde surgió la idea del proyecto del Genoma Humano en 2000. Watson se convirtió en el primer líder de este proyecto, el conjunto de cromosomas del Homo sapiens humano fue completamente descifrado dentro del proyecto. El mapa genético completo del primer cromosoma se completó en 2006. El mapa contiene 3141 genes y 991 pseudogenes.Desde el punto de vista de las matemáticas, cuatro elementos del alfabeto se pueden atribuir a cuatro elementos de un campo de Galois extendido finito GF (2 2 ) = ( 0, 1, α, β ), las operaciones con las que se realiza el módulo del polinomio irreducible p (x) = x 2 + x + 1 . Entonces α + β = 1, α ∙ β = 1y el mapeo de los elementos de campo a las letras toma la forma , y el nucleótido adicional (complementario) se calcula de acuerdo con la regla ¬ → x + 1 , de donde T → A + 1, C → G + 1.Estructuralmente, el modelo de ADN representa dos cadenas poliméricas equidistantes de nucleótidos conectados por pares (por el principio de una escalera de cuerda) y torcido en una doble espiral derecha. A continuación, en el texto, los pares de letras escritos verticalmente corresponden a los pasos de la "escalera":T A GGTTCG T ...
, y el nucleótido adicional (complementario) se calcula de acuerdo con la regla ¬ → x + 1 , de donde T → A + 1, C → G + 1.Estructuralmente, el modelo de ADN representa dos cadenas poliméricas equidistantes de nucleótidos conectados por pares (por el principio de una escalera de cuerda) y torcido en una doble espiral derecha. A continuación, en el texto, los pares de letras escritos verticalmente corresponden a los pasos de la "escalera":T A GGTTCG T ...
ATCCAAGCA ...Dos cadenas repiten la secuencia de letras, pero el comienzo de una se encuentra enfrente del final de la otra. La información en las moléculas de ADN se registra con un alto grado de redundancia, lo que, por supuesto, proporciona un alto nivel de confiabilidad al leer la información y copiarla (replicación: ADN → ADN). Una palabra más se atribuye a la palabra original, pero en código adicional.Todos los cromosomas contienen genes en su composición y están contenidos en cada célula en un volumen muy pequeño (en el núcleo celular) y son cortos y muy largos. La distancia entre las cadenas de ADN es de 2 nm, entre los "pasos" - 0,31 nm, una revolución completa de la "hélice" cada 10 pares. La longitud total de todo el ADN estirado en una cadena alcanza los 2 m. La información hereditaria humana se registra en 23 cromosomas. La longitud del cromosoma es de aproximadamente 10 9nucleótidos, y el diámetro del núcleo es inferior a un micrómetro. Por lo tanto, el ADN en la célula se compacta.Definición . Gen (griego.γενοζ - género). La unidad estructural y funcional de la herencia de los organismos vivos. Los genes (más precisamente alelos) determinan los rasgos hereditarios de los organismos transmitidos de padres a hijos durante la reproducción.
En palabras del ADN, es posible aislar y considerar subpalabras individuales (genes) que llevan información integral sobre la estructura de una molécula de proteína o una molécula de ARN. Además, los genes se caracterizan por secuencias reguladoras (promotores).Los promotores se pueden ubicar muy cerca de un marco de lectura abierto que codifica una proteína o al comienzo de una secuencia de ARN, y a una distancia de muchos millones de pares de bases (nucleótidos), por ejemplo, en casos con potenciadores, aisladores y supresores.Cada gen está diseñado y es responsable de crear una proteína específica necesaria para la vida del cuerpo. El concepto de genotipo denota la constitución hereditaria de gametos (células germinales) y cigotos (células somáticas), en contraste con el fenotipo que describe los caracteres adquiridos que no se heredan.Códigos de bloque
El código es un concepto de múltiples valores. En primer lugar, un código puede llamarse un conjunto de códigos de palabras de código que forman el código en sí. Son estas palabras las que el decodificador reconoce en el lado receptor cuando transmite mensajes, y en el lado transmisor, el codificador los forma.Cuando se generan palabras de código, se utiliza un mapeo único de un conjunto de caracteres finitos ordenados que pertenecen a un determinado alfabeto finito a otro, no necesariamente ordenado, generalmente un conjunto de caracteres más extenso para codificar la transmisión, el almacenamiento o la transformación de información.Enumeramos las propiedades del código genético en consideración:- . . in Vitro ( ). () () .
- . , .
- . . ( ) – , , .
. . 4- , , 20 , , ( ) .
, (), 4; 2- (), 42 =16 ; () 43 = 64 > 20 . .
- . . , -, , - . .
. 64 1965 . , . , (). .
2 —

20 61 , . , . AUG – .
. . AGC, GCU, CUA,… , . , . .
- . - .
, . ( ) ( ) .
- . - , . : AUG ( ) , – .
- . . . 1961 . .
- – ;
- – ( ) .
Considere dos conjuntos discretos X y n que contienen respectivamente | X | y | n | elementos y mapeo φ : n → X . Al representar asignaciones arbitrarias de conjuntos con palabras en el alfabeto X, obtenemos un conjunto de X n palabras, cada una de n caracteres de longitud a partir de los q = | X | disponibles, que forman el alfabeto de los mensajes de texto. Es conveniente organizar todas las palabras X n en orden lexicográfico en una lista general.Nuestro objetivo en esta parte del trabajo es generar un código que proporcione la codificación (conversión) de los datos transmitidos en una forma conveniente para la transmisión en el espacio y el tiempo y la transmisión (traducción) de un idioma a otro, comprensible para el destinatario del mensaje.Generar un código implica elegir el alfabeto, determinar la regularidad y, al elegir un código regular, determinar la longitud de la palabra de código, determinar el número de palabras de código, determinar la composición letra por palabra de cada palabra.Tabla 3 - El código genético consta de 64 palabras de código de 3 letras cada una Tabla 4 - Valores inversos de la secuencia de código de tripletes de ARN
Tabla 4 - Valores inversos de la secuencia de código de tripletes de ARN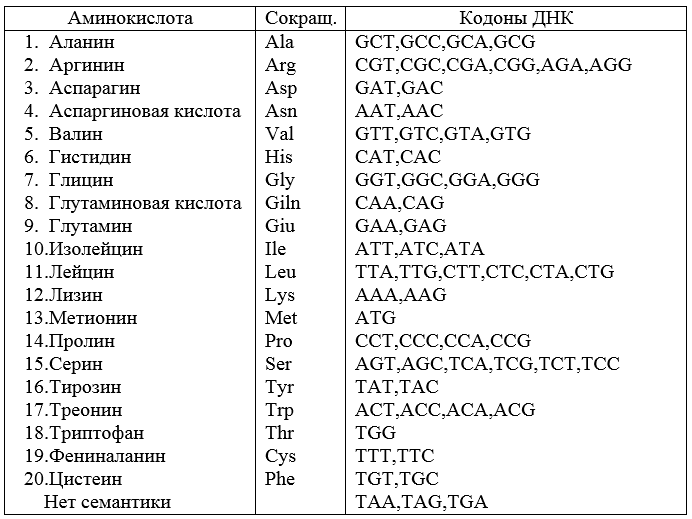 Las propiedades adicionales del código, por ejemplo, el código no debe tener una coma, están determinadas por requisitos más estrictos para los parámetros del código con nombre. Un código sin comas debe tener palabras con un período máximo. Dichos requisitos se centran en la conveniencia de la posterior síntesis del códec. Estrechamente relacionado con estas disposiciones de síntesis de código están los problemas de codificación de información y su decodificación.
Las propiedades adicionales del código, por ejemplo, el código no debe tener una coma, están determinadas por requisitos más estrictos para los parámetros del código con nombre. Un código sin comas debe tener palabras con un período máximo. Dichos requisitos se centran en la conveniencia de la posterior síntesis del códec. Estrechamente relacionado con estas disposiciones de síntesis de código están los problemas de codificación de información y su decodificación.Análisis de código
La tarea de análisis de código suena completamente diferente cuando el código ya existe y se usa, pero se sabe poco sobre él. Los mensajes codificados están disponibles para su visualización y estudio, pero son tan diversos y numerosos que el principio de su creación no es visible incluso con un análisis muy extenso.En realidad, el sistema de codificación en sí también está disponible para observación y estudio, pero el nivel de complejidad de su construcción y funcionamiento no permite obtener una descripción completa, cualitativa y confiable.La información (datos) es un mensaje, es decir una cadena de caracteres del alfabeto, que desde alguna posición inicial puede dividirse en segmentos (bloques) de longitud n caracteres, y cada segmento es una palabra de código. El código en este caso es bloque.En el lado receptor del canal de mensajes, el destinatario debe poder dividir correctamente la cadena continua de caracteres del mensaje en palabras separadas. El uso de delimitadores de palabras (comas) no es deseable ya que requiere recursos.Sincronización . Sin sincronización, la traducción correcta del mensaje es imposible. Esto implica uno de los requisitos para el código generado: el código debe diseñarse de modo que la sincronización se proporcione de manera única por los medios (propiedades) del código en sí y del dispositivo receptor de información.Definición . El proceso de establecer una posición que contiene el carácter inicial (inicial) de una palabra de código se llama sincronización.
La tarea de sincronización simplemente se resuelve si el alfabeto utiliza un carácter separador de palabras especial, por ejemplo, una coma. El marco de lectura de la siguiente palabra de código se establece inmediatamente después del separador.
Tal separador es conveniente, pero indeseable por varias razones.- En primer lugar, el código debe ser tal que en el punto de llegada del mensaje tenga exactamente la misma forma que en el punto de partida (asegurando la integridad);
- En segundo lugar, el tiempo de codificación, decodificación y transmisión debe ser lo más corto posible, ya que esto reduce la posibilidad de distorsionar las influencias ambientales en el texto del mensaje;
- En tercer lugar, es deseable tener una pequeña cantidad de soporte de mensajes, ya que requiere menos almacenamiento, protección y otros recursos.
Para una mejor distinción de las palabras de código, deben eliminarse unas de otras una cierta distancia en la lista completa de palabras posibles, es decir. difieren en la composición de los significados de los símbolos, ya que los vectores del espacio vectorial son componentes.Por lo tanto, las palabras de código no pueden ser todas y ninguna palabra del conjunto X n , sino solo un subconjunto de ellas D є X n . La elección de la composición simbólica de las palabras de código representa la tarea principal de su formación, ya que es la composición de las palabras de código la que debe garantizar la satisfacción de los requisitos formulados para el código. Por lo tanto, consideraremos más el código sin una coma.. , . = (1, 2, …, n) = (1, 2, …, n). || = (1, 2, …, n, 1, 2, …, n). n – 1 n n . .
. (2, …, n, 1), (3, …, n, 1, 2)…( n, 1,…, n-2, n-1), .
Si todas las superposiciones en concatenación para cualquier par de palabras de código no son palabras de código, entonces el mecanismo del lado receptor (decodificador) del canal de transmisión de información tiene la capacidad de establecer una posición de inicio única. Esto es posible si el decodificador de la lista D tiene todas las palabras de código y la posibilidad de unirlas con n caracteres leídos del mensaje recibido.Mostramos cómo se hace esto. Deje que un símbolo sea seleccionado y fijado en la secuencia de caracteres recibida. Habiendo contado n caracteres del fijo, el decodificador compara la palabra que resultó con las palabras en la lista de códigos. Si hay una coincidencia con una de las palabras en la lista de códigos, se establece la sincronización. El símbolo fijo y su posición están comenzando.Si no hay coincidencia con ninguna de las palabras en la lista de códigos, es decir, presionar la palabra superpuesta, esto significa que la posición inicial se encuentra a la izquierda de la posición fija.Nos movemos a la izquierda una posición desde la fija y repetimos las acciones del paso anterior hasta que en un paso coincidamos con una de las palabras de código. Este proceso necesariamente tiene una finalización exitosa en la posición inicial correcta, es decir, la sincronización se establece en promedio para el número de n / 2 pasos.. () D є n n , , єD .
Ya hemos establecido que dicho código garantiza una sincronización correcta en largas cadenas de palabras de código sin separadores entre ellas. ¿Qué palabras del conjunto X n están incluidas en el subconjunto D є X n ? Si la cardinalidad del conjunto X n se divide por enteros, entonces la cardinalidad D puede ser uno de estos divisores (el teorema del grupo de Lagrange) y el código se llama código de bloque de grupo sin un punto decimal ., , D. , D n ( n D), . , D.
Pasemos al tema del número de palabras en el código generado.El poder del código es sin una coma. Encontraremos el mayor número posible de palabras en el código D , que denotamos por | D | = W n ( q) . No es posible obtener el significado exacto, pero se puede obtener una estimación superior para el número de palabras usando el concepto del período de palabras. Denote por T k x el desplazamiento cíclico de una palabra de longitud n por k pasos, k < n .. d ( ) k, k = d ≤ n, d | n. d = n (). .
, = (1, 2, 3, 1, 2, 3 ) d < n. || . || = (1, 2, 3 ; 1, 2, 3 , 1, 2, 3 ; 1, 2, 3). , (;) , . , n.
n(q) q . D Wn(q) ≤ n(q)/n .


 Por lo tanto, para los datos de origen del ejemplo 1, a partir de un conjunto de 64 palabras arbitrarias con una longitud de 3 caracteres, puede crear un código que contenga 20 palabras y proporcione sincronización. Este código no está exento de defectos. Si se introduce un error en una de las palabras en un solo carácter, el código no se sincronizará. En otras palabras, el código es inestable contra errores.El ejemplo numérico dado puede usarse para ilustrar y explicar el código genético de los organismos vivos, que fue creado por la naturaleza en un largo camino de evolución y completamente descifrado por la ciencia moderna en 1966. Se establece que el código genético no se superpone y se revela el significado (interpretación) de cada codón.La tabla final es la siguiente (Fig. 2).De la tabla se deduce que el código está degenerado. Esto significa que hay sinónimos en el código, por ejemplo, GUU = GUC = Val, CGG = AGA = Arg , etc. Tres codones UAA, UAG, UGA no tienen sentido. Estos son codones de terminación; la aparición de cualquiera de ellos en una secuencia de caracteres significa el final de la traducción (transmisión). Un organismo muere si, como resultado de un error, la letra del codón semántico se cambia a un codón de terminación.Tales cambios son posibles y se llaman mutaciones.
Por lo tanto, para los datos de origen del ejemplo 1, a partir de un conjunto de 64 palabras arbitrarias con una longitud de 3 caracteres, puede crear un código que contenga 20 palabras y proporcione sincronización. Este código no está exento de defectos. Si se introduce un error en una de las palabras en un solo carácter, el código no se sincronizará. En otras palabras, el código es inestable contra errores.El ejemplo numérico dado puede usarse para ilustrar y explicar el código genético de los organismos vivos, que fue creado por la naturaleza en un largo camino de evolución y completamente descifrado por la ciencia moderna en 1966. Se establece que el código genético no se superpone y se revela el significado (interpretación) de cada codón.La tabla final es la siguiente (Fig. 2).De la tabla se deduce que el código está degenerado. Esto significa que hay sinónimos en el código, por ejemplo, GUU = GUC = Val, CGG = AGA = Arg , etc. Tres codones UAA, UAG, UGA no tienen sentido. Estos son codones de terminación; la aparición de cualquiera de ellos en una secuencia de caracteres significa el final de la traducción (transmisión). Un organismo muere si, como resultado de un error, la letra del codón semántico se cambia a un codón de terminación.Tales cambios son posibles y se llaman mutaciones.Definición . Las mutaciones son cambios relativamente estables en la sustancia hereditaria.
Cada cromosoma contiene los genes x1, x2, ..., xn , que forman un rasgo complejo X del cuerpo. Durante la reproducción se forma un par de cromosomas en una célula obtenida por la fusión de las células germinales paternas y maternas: un cromosoma se obtiene del padre, el otro de la madre (par diploide de cromosomas).En los cromosomas homólogos, todos los genes coinciden en su función, pero pueden diferir en varios nucleótidos. Tales diferencias son a menudo el resultado de mutaciones, que pueden ser causadas por químicos, radiación, exposición radiactiva, temperatura, radiación ionizante.Las enfermedades hereditarias son causadas por mutaciones similares, fijadas en el conjunto cromosómico de células germinales de uno de los padres. Un ejemplo conocido de un gen humano que codifica la hemoglobina. Al reemplazar la letra T con la letra A , aparece una forma alternativa de hemoglobina en una posición del gen. Esto se manifiesta en una enfermedad llamada anemia falciforme.Cuando el valor del rasgo coincide en ambos cromosomas homólogos, el individuo se llama homocigoto para este gen. En otros casos, se produce heterocigosidad. La homocigosidad se caracteriza por pares diploides de tipo a) y la heterocigosidad por pares de tipo b) (Fig. 3) Figura 3: pares diploides de homocigotos y heterocigotosEn lugar de un par diploide , se forman cuatro cromosomas homólogos A, A, a, a.y se distribuyen equitativamente entre los cuatro gametos formados. Cada gameto también recibe uno de los cromosomas B, B, b, b, correspondiente a un rasgo complejo. Esta distribución ocurre para los cromosomas independientemente entre cuatro gametos y entre diferentes personajes. Estos hechos fueron establecidos por Mendel y en 1865 publicó.La característica más impresionante del código genético es su versatilidad. El esquema dado (Fig. 1) puede usarse con éxito para decodificar ARN de animales y plantas. En 1979, aparecieron resultados en el código genético mitocondrial, que difiere de los valores de algunos codones en la tabla y con otras reglas de reconocimiento de codones.La traducción es realizada por el ribosoma, un órgano especial de la célula. La sincronización (configuración del marco de lectura) se lleva a cabo utilizando el prefijo AGGAGGU , que se denomina secuencia Shine-Dolgarno. Esta secuencia de purina está presente en la palabra en singular, y la probabilidad de su distorsión es pequeña. Pero si ocurre una distorsión, entonces el cuerpo estará en desastre.Figura 1 - Correspondencia de las palabras de código con los aminoácidos. Figura 2: ADN, ARNm y hélice de proteínas. La
Figura 3: pares diploides de homocigotos y heterocigotosEn lugar de un par diploide , se forman cuatro cromosomas homólogos A, A, a, a.y se distribuyen equitativamente entre los cuatro gametos formados. Cada gameto también recibe uno de los cromosomas B, B, b, b, correspondiente a un rasgo complejo. Esta distribución ocurre para los cromosomas independientemente entre cuatro gametos y entre diferentes personajes. Estos hechos fueron establecidos por Mendel y en 1865 publicó.La característica más impresionante del código genético es su versatilidad. El esquema dado (Fig. 1) puede usarse con éxito para decodificar ARN de animales y plantas. En 1979, aparecieron resultados en el código genético mitocondrial, que difiere de los valores de algunos codones en la tabla y con otras reglas de reconocimiento de codones.La traducción es realizada por el ribosoma, un órgano especial de la célula. La sincronización (configuración del marco de lectura) se lleva a cabo utilizando el prefijo AGGAGGU , que se denomina secuencia Shine-Dolgarno. Esta secuencia de purina está presente en la palabra en singular, y la probabilidad de su distorsión es pequeña. Pero si ocurre una distorsión, entonces el cuerpo estará en desastre.Figura 1 - Correspondencia de las palabras de código con los aminoácidos. Figura 2: ADN, ARNm y hélice de proteínas. La Figura 2 muestra cómo la secuencia de aminoácidos en una molécula de proteína está codificada por una secuencia de codones en una molécula de ADN. Aquí, el ARNm de matriz es una molécula intermedia. Sus cadenas divergen según el principio de "cremallera", en el que el papel de la cerradura es desempeñado por una enzima que rompe la molécula a través de enlaces de hidrógeno.En las células, el código genético se lleva a cabo mediante tres procesos matriciales: replicación (ocurre en el núcleo), transcripción y traducción .La transcripción (registro en letras de ADN → ARNm) es un proceso biológico en células eucariotas que tiene lugar en el núcleo celular (separado por una membrana nuclear del citoplasma) y es una síntesis de moléculas de i-ARN en las secciones correspondientes de ADN. La secuencia de nucleótidos de ADN se "reescribe" en la misma secuencia de ARN.La traducción (lectura y traducción de ARN → proteína) el proceso biológico en las células procariotas se combina con el proceso de transcripción, se produce en el citoplasma celular, en los ribosomas; La secuencia de nucleótidos de ARNm se transporta desde el núcleo y se traduce en la secuencia de aminoácidos (síntesis de la cadena de polipéptidos en la matriz de ARNm): esta etapa continúa con la participación del ARN de transporte (ARNt) y las enzimas correspondientes.Por lo tanto, la traducción es una síntesis de proteínas por el ribosoma basada en información registrada en el ARNm de la matriz. Para obtener 20 aminoácidos, así como una señal de stop, que significa el final de una secuencia de proteínas, son suficientes tres nucleótidos consecutivos, que se denominan triplete.Los organismos vivos se distribuyen entre plantas y animales por especie.
Figura 2 muestra cómo la secuencia de aminoácidos en una molécula de proteína está codificada por una secuencia de codones en una molécula de ADN. Aquí, el ARNm de matriz es una molécula intermedia. Sus cadenas divergen según el principio de "cremallera", en el que el papel de la cerradura es desempeñado por una enzima que rompe la molécula a través de enlaces de hidrógeno.En las células, el código genético se lleva a cabo mediante tres procesos matriciales: replicación (ocurre en el núcleo), transcripción y traducción .La transcripción (registro en letras de ADN → ARNm) es un proceso biológico en células eucariotas que tiene lugar en el núcleo celular (separado por una membrana nuclear del citoplasma) y es una síntesis de moléculas de i-ARN en las secciones correspondientes de ADN. La secuencia de nucleótidos de ADN se "reescribe" en la misma secuencia de ARN.La traducción (lectura y traducción de ARN → proteína) el proceso biológico en las células procariotas se combina con el proceso de transcripción, se produce en el citoplasma celular, en los ribosomas; La secuencia de nucleótidos de ARNm se transporta desde el núcleo y se traduce en la secuencia de aminoácidos (síntesis de la cadena de polipéptidos en la matriz de ARNm): esta etapa continúa con la participación del ARN de transporte (ARNt) y las enzimas correspondientes.Por lo tanto, la traducción es una síntesis de proteínas por el ribosoma basada en información registrada en el ARNm de la matriz. Para obtener 20 aminoácidos, así como una señal de stop, que significa el final de una secuencia de proteínas, son suficientes tres nucleótidos consecutivos, que se denominan triplete.Los organismos vivos se distribuyen entre plantas y animales por especie.. – , . , , .
La división celular es de dos tipos: una para la formación de células somáticas (células del cuerpo), la otra para la formación de células germinales (gametos). El tipo de organismo está determinado por la presencia, el número y la composición de los cromosomas en las células de los organismos que no cambian (constante). El crecimiento y desarrollo normal del cuerpo está garantizado por la formación y crecimiento de células somáticas como resultado de la mitosis. Durante la mitosis, todos los cromosomas ubicados en el núcleo celular se duplican antes del inicio de la división celular (replicación del ADN) y se distribuyen uniformemente entre dos células hijas. El conjunto de cromosomas 2n2c en cada célula somática es exactamente el mismo. La mitosis mantiene un número diploide constante de cromosomas en las células.Otro proceso de meiosis es la formación de gametos, que son necesarios para la continuación del género de organismos. En la meiosis, cada célula se divide dos veces, y el número de cromosomas se duplica una vez. La meiosis conduce a la formación de células diploides con gametos haploides con un conjunto de n2c . Con la posterior fertilización, los gametos forman un organismo de nueva generación con un cariotipo diploide (nc + nc = 2n2c) .Este mecanismo se realiza en todas las especies que se reproducen sexualmente. La meiosis garantiza la constancia de los conjuntos de cromosomas (cariotipos), herencia y la creación de nuevas combinaciones de genes paternos y maternos con variación genotípica.El trabajo propuesto abre la posibilidad de utilizar el código genético para resolver las tareas de protección de la información. Una comprensión correcta del fenómeno de la naturaleza y su uso solo es posible con el esfuerzo del investigador, que no se detiene por las dificultades en el camino del conocimiento profundo de la naturaleza que nos rodea y sus manifestaciones.
El crecimiento y desarrollo normal del cuerpo está garantizado por la formación y crecimiento de células somáticas como resultado de la mitosis. Durante la mitosis, todos los cromosomas ubicados en el núcleo celular se duplican antes del inicio de la división celular (replicación del ADN) y se distribuyen uniformemente entre dos células hijas. El conjunto de cromosomas 2n2c en cada célula somática es exactamente el mismo. La mitosis mantiene un número diploide constante de cromosomas en las células.Otro proceso de meiosis es la formación de gametos, que son necesarios para la continuación del género de organismos. En la meiosis, cada célula se divide dos veces, y el número de cromosomas se duplica una vez. La meiosis conduce a la formación de células diploides con gametos haploides con un conjunto de n2c . Con la posterior fertilización, los gametos forman un organismo de nueva generación con un cariotipo diploide (nc + nc = 2n2c) .Este mecanismo se realiza en todas las especies que se reproducen sexualmente. La meiosis garantiza la constancia de los conjuntos de cromosomas (cariotipos), herencia y la creación de nuevas combinaciones de genes paternos y maternos con variación genotípica.El trabajo propuesto abre la posibilidad de utilizar el código genético para resolver las tareas de protección de la información. Una comprensión correcta del fenómeno de la naturaleza y su uso solo es posible con el esfuerzo del investigador, que no se detiene por las dificultades en el camino del conocimiento profundo de la naturaleza que nos rodea y sus manifestaciones.