Una condición típica para implementar CI / CD en Kubernetes: la aplicación debe poder dejar de aceptar nuevas solicitudes de clientes antes de detenerse, y lo más importante, completar con éxito las existentes. El cumplimiento de esta condición le permite lograr un tiempo de inactividad cero durante la implementación. Sin embargo, incluso cuando se utilizan paquetes muy populares (como NGINX y PHP-FPM), puede encontrar dificultades que provocarán una oleada de errores con cada implementación ...
El cumplimiento de esta condición le permite lograr un tiempo de inactividad cero durante la implementación. Sin embargo, incluso cuando se utilizan paquetes muy populares (como NGINX y PHP-FPM), puede encontrar dificultades que provocarán una oleada de errores con cada implementación ...Teoría. Cómo vive la vaina
Ya hemos publicado este artículo en detalle sobre el ciclo de vida de la cápsula . En el contexto de este tema, estamos interesados en lo siguiente: en el momento en que el pod ingresa al estado de terminación , dejan de enviarse nuevas solicitudes (el pod se elimina de la lista de puntos finales para el servicio). Por lo tanto, para evitar el tiempo de inactividad durante la implementación, por nuestra parte, es suficiente para resolver el problema de detener correctamente la aplicación.También debe recordarse que el período de gracia es de 30 segundos de forma predeterminada : después de esto, el pod se cerrará y la aplicación debería procesar todas las solicitudes antes de este período. Nota: aunque cualquier solicitud que se ejecute durante más de 5-10 segundos ya es problemática, y el apagado correcto ya no lo ayudará ...Para comprender mejor lo que sucede cuando el pod finaliza su trabajo, es suficiente estudiar el siguiente esquema: A1, B1 - Obteniendo cambios sobre estado de
A1, B1 - Obteniendo cambios sobre estado de
A2: Enviar SIGTERM
B2 - Eliminar el pod de los puntos finales
B3 - Obtener cambios (la lista de puntos finales ha cambiado)
B4 - Actualizar las reglas de iptablesNota: eliminar el pod de puntos finales y enviar SIGTERM no se realiza de forma secuencial, sino en paralelo. Y debido al hecho de que Ingress no recibe una lista actualizada de Endpoints de inmediato, se enviarán nuevas solicitudes de los clientes al pod, lo que causará 500 errores durante la finalización del pod.(que traducido materiales más detallada sobre esta cuestión ) . Debe resolver este problema de las siguientes maneras:- Envíe los encabezados de la conexión: cierre la respuesta (si se trata de una aplicación HTTP).
- Si no hay forma de realizar cambios en el código, el artículo describe una solución que le permitirá procesar las solicitudes hasta el final del período de gracia.
Teoría. Cómo NGINX y PHP-FPM finalizan sus procesos
Nginx
Comencemos con NGINX, ya que todo es más o menos obvio con él. Inmersos en la teoría, aprendemos que NGINX tiene un proceso maestro y varios "trabajadores": estos son procesos secundarios que procesan las solicitudes de los clientes. Se proporciona una característica conveniente: usar el comando para nginx -s <SIGNAL>finalizar procesos en modo de apagado rápido o en apagado correcto. Obviamente, estamos interesados precisamente en la última opción.Entonces todo es simple: debe agregar un comando al gancho preStop que enviará una señal sobre el apagado correcto . Esto se puede hacer en Implementación, en el bloque contenedor: lifecycle:
preStop:
exec:
command:
- /usr/sbin/nginx
- -s
- quit
Ahora, en el momento en que la cápsula completa su trabajo en los registros del contenedor NGINX, veremos lo siguiente:2018/01/25 13:58:31 [notice] 1#1: signal 3 (SIGQUIT) received, shutting down
2018/01/25 13:58:31 [notice] 11#11: gracefully shutting down
Y eso significará lo que necesitamos: NGINX espera la finalización de las consultas y luego elimina el proceso. Sin embargo, se discutirá un problema común a continuación, debido a que, incluso si hay un comando, el nginx -s quitproceso no se completa correctamente.Y en esta etapa hemos terminado con NGINX: al menos puedes entender por los registros que todo funciona como debería.¿Qué pasa con PHP-FPM? ¿Cómo maneja el apagado elegante? Vamos a hacerlo bien.PHP-FPM
En el caso de PHP-FPM, un poco menos de información. Si se concentra en el manual oficial sobre PHP-FPM, le indicará que se reciben las siguientes señales POSIX:SIGINT, SIGTERM- apagado rápido;SIGQUIT - cierre elegante (lo que necesitamos).
El resto de las señales en este problema no son necesarias, por lo tanto, se omite su análisis. Para completar el proceso correctamente, deberá escribir el siguiente enlace preStop: lifecycle:
preStop:
exec:
command:
- /bin/kill
- -SIGQUIT
- "1"
A primera vista, esto es todo lo que se requiere para realizar un apagado correcto en ambos contenedores. Sin embargo, la tarea es más complicada de lo que parece. A continuación, examinamos dos casos en los que el cierre correcto no funcionó y causó una inaccesibilidad a corto plazo del proyecto durante la implementación.Práctica. Posibles problemas con el apagado elegante
Nginx
En primer lugar, es útil recordar: además de ejecutar el comando, nginx -s quithay otro paso al que debe prestar atención. Nos encontramos con un problema cuando NGINX en lugar de una señal SIGQUIT envió SIGTERM de todos modos, debido a que las solicitudes no se completaron correctamente. Se pueden encontrar casos similares, por ejemplo, aquí . Desafortunadamente, no pudimos establecer una razón específica para este comportamiento: había una sospecha de la versión NGINX, pero no se confirmó. La sintomatología fue que en los registros del contenedor NGINX se observaron los mensajes "abra el zócalo # 10 dejado en la conexión 5" , después de lo cual la cápsula se detuvo.Podemos observar este problema, por ejemplo, por las respuestas al Ingress que necesitamos: Indicadores de código de estado en el momento del despliegueEn este caso, obtenemos solo el código de error 503 del propio Ingress: no puede acceder al contenedor NGINX, ya que ya no está disponible. Si observa los registros del contenedor con NGINX, contienen lo siguiente:
Indicadores de código de estado en el momento del despliegueEn este caso, obtenemos solo el código de error 503 del propio Ingress: no puede acceder al contenedor NGINX, ya que ya no está disponible. Si observa los registros del contenedor con NGINX, contienen lo siguiente:[alert] 13939#0: *154 open socket #3 left in connection 16
[alert] 13939#0: *168 open socket #6 left in connection 13
Después de cambiar la señal de parada, el contenedor comienza a detenerse correctamente: esto se confirma por el hecho de que ya no se observa un error 503.Si encuentra un problema similar, tiene sentido averiguar qué señal de parada se usa en el contenedor y cómo se ve exactamente el gancho preStop. Es posible que la razón radique precisamente en esto.PHP-FPM ... y más
El problema con PHP-FPM se describe de manera trivial: no espera la finalización de los procesos secundarios, los finaliza, por lo que hay 502 errores durante la implementación y otras operaciones. Desde 2005 ha habido varios mensajes de error en bugs.php.net (por ejemplo, aquí y aquí ) que describen este problema. Pero probablemente no verá nada en los registros: PHP-FPM anunciará la finalización de su proceso sin errores ni notificaciones de terceros.Vale la pena aclarar que el problema en sí mismo puede, en mayor o menor medida, depender de la aplicación misma y puede no aparecer, por ejemplo, en el monitoreo. Si aún lo encuentra, le viene a la mente una solución simple: agregue un gancho preStop consleep(30). Se le permitirá completar todas las solicitudes que habían sido antes (no se aceptan los nuevos, ya que la vaina es que ya en la terminación del estado ), y después de 30 segundos la vaina sí terminará con una señal SIGTERM.Resulta que lifecyclepara el contenedor se verá así: lifecycle:
preStop:
exec:
command:
- /bin/sleep
- "30"
Sin embargo, debido a la indicación de 30 segundos, sleeptendremos significativamente aumentar el tiempo de implementación, ya que cada vaina se dará por terminado por al menos 30 segundos, lo que es malo. ¿Qué se puede hacer con esto?Pasemos a la parte responsable de la ejecución directa de la aplicación. En nuestro caso, se trata de PHP-FPM , que por defecto no supervisa la ejecución de sus procesos secundarios : el proceso maestro finaliza de inmediato. Este comportamiento se puede cambiar mediante una directiva process_control_timeoutque especifica los límites de tiempo para esperar las señales del maestro por parte de los procesos secundarios. Si establece el valor en 20 segundos, esto cubrirá la mayoría de las solicitudes que se ejecutan en el contenedor y, una vez completado, el proceso maestro se detendrá.Con este conocimiento, volveremos a nuestro último problema. Como ya se mencionó, Kubernetes no es una plataforma monolítica: lleva algún tiempo la interacción entre sus diversos componentes. Esto es especialmente cierto cuando consideramos el trabajo de Ingresss y otros componentes relacionados, porque debido a tal retraso en el momento de la implementación, es fácil obtener un aumento de 500 errores. Por ejemplo, puede producirse un error en la etapa de envío de una solicitud al flujo ascendente, pero el "intervalo de tiempo" de interacción entre los componentes es bastante corto, menos de un segundo.Por lo tanto, en conjunción con la directiva ya mencionada process_control_timeout, se puede utilizar la siguiente construcción para lifecycle:lifecycle:
preStop:
exec:
command: ["/bin/bash","-c","/bin/sleep 1; kill -QUIT 1"]
En este caso, compensamos la demora del equipo sleepy no aumentamos significativamente el tiempo de implementación: ¿hay una diferencia notable entre 30 segundos y uno? ... Esencialmente process_control_timeout, toma el "trabajo principal" , pero se lifecycleusa solo como una "red de seguridad" en caso de retraso.En términos generales, el comportamiento descrito y la solución alternativa correspondiente conciernen no solo a PHP-FPM . Una situación similar puede surgir de una forma u otra al usar otros lenguajes / marcos. Si no puede solucionar el apagado correcto de otras maneras, por ejemplo, reescriba el código para que la aplicación procese correctamente las señales de terminación, puede usar el método descrito. Puede que no sea la más hermosa, pero funciona.Práctica. Prueba de carga para verificar el rendimiento del pod
La prueba de carga es una forma de verificar cómo funciona el contenedor, ya que este procedimiento lo acerca a las condiciones reales de combate cuando los usuarios visitan el sitio. Puede usar Yandex.Tank para probar las recomendaciones anteriores : cubre perfectamente todas nuestras necesidades. Los siguientes son consejos y trucos para probar con claridad, gracias a los gráficos de Grafana y Yandex.Tank, un ejemplo de nuestra experiencia.Lo más importante aquí es verificar los cambios en las etapas.. Después de agregar una nueva solución, ejecute la prueba y vea si los resultados han cambiado en comparación con el lanzamiento anterior. De lo contrario, será difícil identificar soluciones ineficaces, y en el futuro solo puede hacer daño (por ejemplo, aumentar el tiempo de implementación).Otra advertencia: observe los registros del contenedor durante su finalización. ¿Se registra allí información graciosa de apagado? ¿Hay algún error en los registros al acceder a otros recursos (por ejemplo, un contenedor PHP-FPM vecino)? ¿Errores de la propia aplicación (como en el caso de NGINX descrito anteriormente)? Espero que la información introductoria de este artículo ayude a comprender mejor lo que le sucede al contenedor durante su finalización.Entonces, la primera prueba se realizó sin lifecycley sin directivas adicionales para el servidor de aplicaciones (process_control_timeouten PHP-FPM). El propósito de esta prueba fue identificar el número aproximado de errores (y si existen). Además, a partir de información adicional, se debe saber que el tiempo promedio de implementación de cada hogar fue de aproximadamente 5-10 segundos hasta el estado de plena preparación. Los resultados son los siguientes: en el panel de información de Yandex.Tank aparece un toque de 502 errores, que ocurrió en el momento del despliegue y duró hasta 5 segundos en promedio. Presumiblemente, esto finalizó las solicitudes existentes al antiguo pod cuando se finalizó. Después de eso, aparecieron 503 errores, que fueron el resultado de un contenedor NGINX detenido, que también se desconectó debido al backend (por lo que Ingress no pudo conectarse).Vamos a ver como
en el panel de información de Yandex.Tank aparece un toque de 502 errores, que ocurrió en el momento del despliegue y duró hasta 5 segundos en promedio. Presumiblemente, esto finalizó las solicitudes existentes al antiguo pod cuando se finalizó. Después de eso, aparecieron 503 errores, que fueron el resultado de un contenedor NGINX detenido, que también se desconectó debido al backend (por lo que Ingress no pudo conectarse).Vamos a ver comoprocess_control_timeouten PHP-FPM nos ayudará a esperar la finalización de los procesos secundarios, es decir Corregir tales errores. Despliegue repetido usando esta directiva: ¡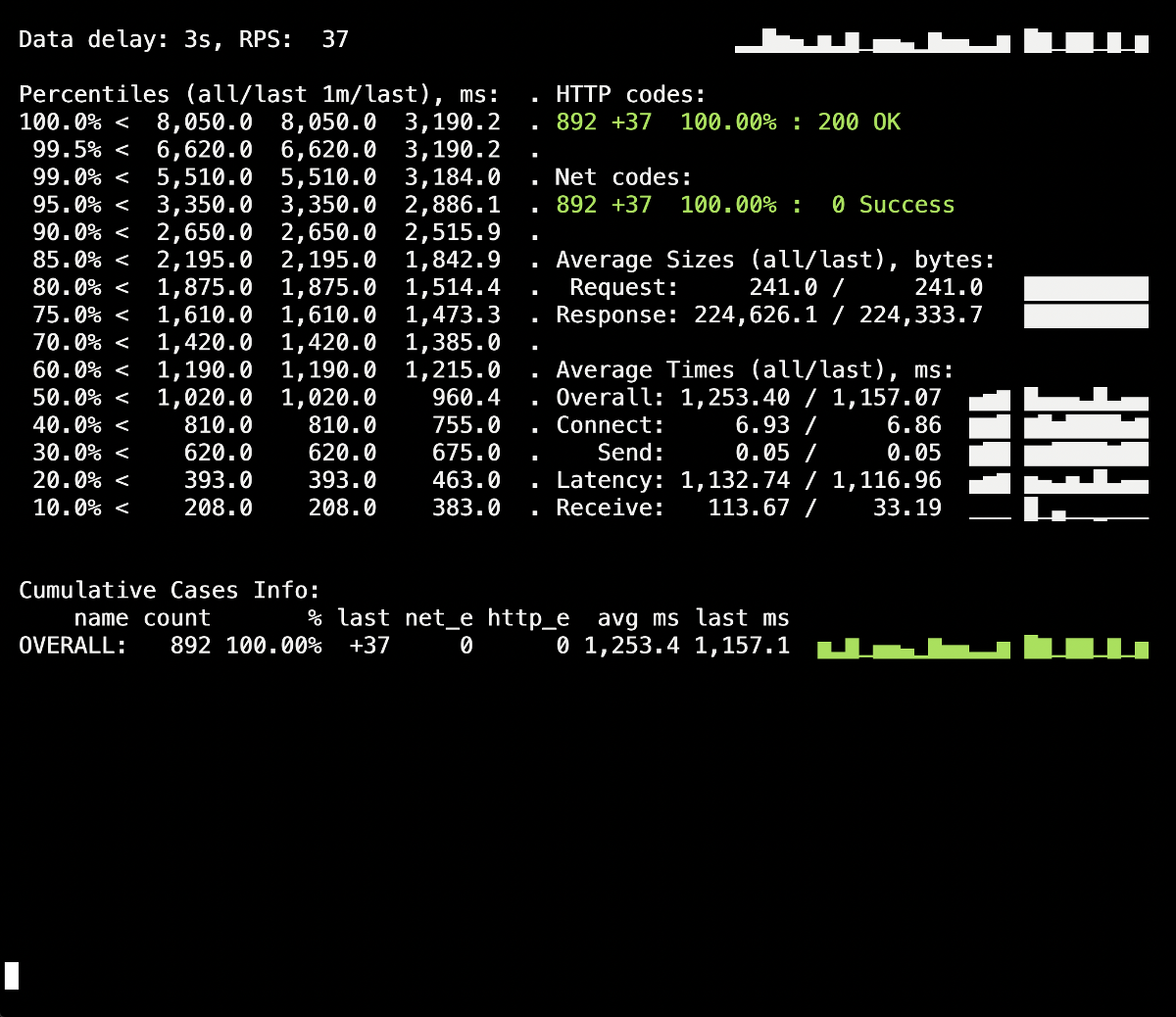 No hay más errores durante el despliegue de los 500! La implementación es exitosa, el cierre correcto funciona.Sin embargo, vale la pena recordar el momento con los contenedores de Ingress, un pequeño porcentaje de errores en los que podemos obtener debido a un retraso de tiempo. Para evitarlos, queda agregar la construcción
No hay más errores durante el despliegue de los 500! La implementación es exitosa, el cierre correcto funciona.Sin embargo, vale la pena recordar el momento con los contenedores de Ingress, un pequeño porcentaje de errores en los que podemos obtener debido a un retraso de tiempo. Para evitarlos, queda agregar la construcción sleepy repetir el despliegue. Sin embargo, en nuestro caso particular, no hubo cambios visibles (no hubo errores nuevamente).Conclusión
Para completar correctamente el proceso, esperamos el siguiente comportamiento de la aplicación:- Espere unos segundos, luego deje de aceptar nuevas conexiones.
- Espere a que se completen todas las solicitudes y cierre todas las conexiones de keepalive que no ejecutan solicitudes.
- Completa tu proceso.
Sin embargo, no todas las aplicaciones pueden funcionar de esta manera. Una solución al problema en las realidades de Kubernetes es:- Agregar un gancho previo a la parada que esperará unos segundos
- estudiando el archivo de configuración de nuestro backend para los parámetros relevantes.
El ejemplo de NGINX nos permite comprender que incluso una aplicación que inicialmente debe procesar correctamente las señales para su finalización puede no hacerlo, por lo que es fundamental verificar si hay 500 errores durante el despliegue de la aplicación. También le permite ver el problema de manera más amplia y no concentrarse en una cápsula o contenedor por separado, sino observar toda la infraestructura en su conjunto.Yandex.Tank se puede utilizar como herramienta de prueba junto con cualquier sistema de monitoreo (en nuestro caso, los datos de Grafana con un backend en forma de Prometheus se tomaron para la prueba). Los problemas con el apagado correcto son claramente visibles bajo cargas pesadas que el punto de referencia puede generar, y el monitoreo ayuda a analizar la situación con más detalle durante o después de la prueba.En respuesta a los comentarios sobre el artículo: vale la pena mencionar que los problemas y las soluciones se describen aquí en relación con NGINX Ingress. Para otros casos, existen otras soluciones que, quizás, consideraremos en los siguientes materiales del ciclo.PD
Otros del ciclo de consejos y trucos de K8s: