
Este trabajo está inspirado en el artículo "¿Sueñan las redes neuronales con el dinero eléctrico?" , donde el autor, sin exagerar, hábilmente en su claridad explica por qué el uso de redes neuronales artificiales en datos básicos no conduce al éxito. Aquí hay un pasaje particularmente exitoso, en mi opinión:
« … , . , , , 200 . .»
, , , , , . . . . - ? , , «» ?
« , ?» — . , , , -. .
, , . , — . , (, , , ..) . … . , .
, , . «»/« » «» , « » — , , , , . .
, — GitHub .
, , : « , ?»
— , . .
, , sentiment analisys, … «. « »?» — . , .
, , . — . — , ? « » ? , ?
, , , . , , «» — , , «» — , () , () - «», () . , , .
, , , , :
- ;
- -;
- ;
- TensorFlow + Keras — one love.
3 — , .
— . . , Google investing.com. CVS .
: Investing.com Bitcoin Index, Bitfinex Bitcoin US Dollar .
, . MIT, . .
, :
- bh.dat.gz — - . : (blockID), - (hash), (block_timestamp), (n_txs);
- tx.dat.xz — . : (txID), , (blockID), (n_inputs), (n_outputs);
- txout.dat.xz — . : (txID), (output_seq), , (addrID), (sum).
:
import pandas as pd
mit_data = pd.read_table('.../bh.dat',
header=None, names=['blockID', 'hash','block_timestamp', 'n_txs'])
mit_data['block_timestamp'] = pd.to_datetime(mit_data['block_timestamp'], unit='s')
out_txs_all = pd.read_table('.../txout.dat',header=None,
names=['txID', 'output_seq','addrID', 'sum'])
mapping_dataset = pd.read_table('.../tx.dat',
header=None, names=['txID', 'blockID','n_inputs', 'n_outputs'])
out_txs_all.drop('output_seq',axis=1,inplace=True)
out_txs_all.drop('addrID',axis=1,inplace=True)
out_txs_all = out_txs_all.groupby('txID').sum().reset_index()
mapping_dataset.drop('n_inputs', axis=1,inplace=True)
mapping_dataset.drop('n_outputs', axis=1,inplace=True)
mapping_dataset['sum_outs'] = out_txs_all['sum']
mapping_dataset.drop('txID', axis=1, inplace=True)
mapping_dataset=mapping_dataset.groupby('blockID').sum().reset_index()
mit_data.drop('hash', axis=1,inplace=True)
mit_data.drop('n_txs', axis=1,inplace=True)
mapping_dataset['Date'] = mit_data['block_timestamp']
mapping_dataset['sum_outs'] = mapping_dataset['sum_outs'].apply(lambda x: x/100000000)
mapping_dataset.to_csv('../filename.csv', index=False)
, 17.07.2010 08.02.2018. , , 08 2018 . , 2018 . — . — . API blockchain.com, .
:
API Blockchain.comimport requests
import json
limit_day = pd.to_datetime('2018-02-09')
datelist = pd.date_range(limit_day, periods=733).to_list()
date_series = pd.DataFrame(data=(datelist), columns=['Date'])
dt = pd.DatetimeIndex(date_series['Date']).astype(np.int64)//1000000
unix_mlseconds_lst = dt.to_list()
blocks_lst = []
for j in unix_mlseconds_lst:
request = requests.get('https://blockchain.info/blocks/'+str(j)+'?format=json')
parse_result = json.loads(request.content)
blocks_lst.append(parse_result['blocks'])
blockID = []
hashID = []
timestamp = []
for d_list in blocks_lst:
for dictionary in d_list:
blockID.append(dictionary['height'])
hashID.append(dictionary['hash'])
timestamp.append(dictionary['time'])
additional_bh = pd.DataFrame(data=(blockID,hashID,timestamp)).T
additional_bh.columns=['blockID','hash','timestamp']
additional_bh['timestamp']=pd.to_datetime(additional_bh['timestamp'], unit='s')
dates_out_sums = {}
for indx in range(len(additional_bh)):
request = requests.get('https://blockchain.info/rawblock/'+str(additional_bh['hash'][indx]))
parse_result = json.loads(request.content)
block_outs_sum=[]
for i in parse_result['tx']:
intermid_out_sum_values = []
for j in i['out']:
intermid_out_sum_values.append(j['value'])
block_outs_sum.append(sum(intermid_out_sum_values))
dates_out_sums[bh['timestamp'][indx]] = sum(block_outs_sum)
dates_out_sums_lst = dates_out_sums.items()
out_txs = pd.DataFrame(dates_out_sums_lst, columns=['Date', 'out_sums'])
out_txs['out_sums']=out_txs['out_sums'].apply(lambda x: x/100000000)
out_txs.to_csv('.../Data/additional_outs_dated(2018-02-09_2018-04-28).csv', index=False)
: blockchain.com , , . , , 11949 , . , .
, .
Data pre-processing
, , .
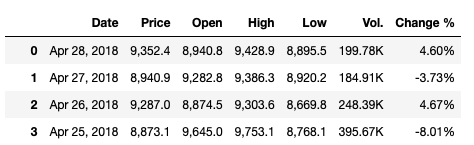
, , ‘K’, ‘M’ , float- . . . Python, !

str floatimport re
import pandas as pd
def strtofloatconvert(data):
price_lst = data['Price'].to_list()
open_lst = data['Open'].to_list()
high_lst = data['High'].to_list()
low_lst = data['Low'].to_list()
vol_lst = data['Vol.'].to_list()
change_lst = data['Change %'].to_list()
sprt_prices = []
sprt_open = []
sprt_high = []
sprt_low = []
sprt_p = []
sprt_o = []
sprt_h = []
sprt_l = []
for price in price_lst:
sprt_p = re.split(r',',price)
sprt_prices.append(sprt_p)
for open_p in open_lst:
sprt_o = re.split(r',',open_p)
sprt_open.append(sprt_o)
for high in high_lst:
sprt_h = re.split(r',',high)
sprt_high.append(sprt_h)
for low in low_lst:
sprt_l = re.split(r',',low)
sprt_low.append(sprt_l)
add_p = []
add_o = []
add_h = []
add_l = []
add_v = []
add_ch = []
for p in sprt_prices:
if len(p) == 2:
a = p[0]+p[1]
a = float(a)
add_p.append(a)
else:
a = p[0]
a = float(a)
add_p.append(a)
for o in sprt_open:
if len(o) == 2:
a = o[0]+o[1]
a = float(a)
add_o.append(a)
else:
a = o[0]
a = float(a)
add_o.append(a)
for h in sprt_high:
if len(h) == 2:
a = h[0]+h[1]
a = float(a)
add_h.append(a)
else:
a = h[0]
a = float(a)
add_h.append(a)
for l in sprt_low:
if len(l) == 2:
a = l[0]+l[1]
a = float(a)
add_l.append(a)
else:
a = l[0]
a = float(a)
add_l.append(a)
for v in vol_lst:
if v == '-':
add_v.append(0)
else:
exam = re.findall(r'K',v)
if len(exam)>0:
add = re.sub(r'K', '',v)
add = float(add)
add *= 1000
add_v.append(add)
else:
add = re.sub(r'M', '',v)
add = float(add)
add *= 1000000
add_v.append(add)
for i in change_lst:
add = re.sub(r'%', '',i)
add = float(add)
add_ch.append(add)
test_df = pd.DataFrame(data=(add_p, add_o, add_h, add_l,
add_v,add_ch)).T
test_df.columns = ['Price', 'Open', 'High', 'Low', 'Vol.', 'Change%']
return test_df
.
.
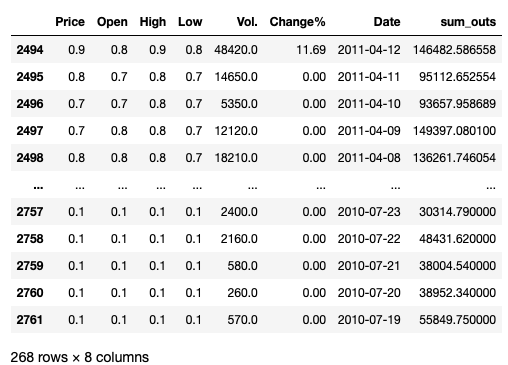
267 . .
, , , T-n, n — . . .
price = test_df.pop('Price')
price = price.drop(price.index[-1])
test_df = test_df.drop(test_df.index[0])
test_df.index = np.arange(len(test_df))
test_df = pd.concat((price,test_df), axis=1)
. , , , .
, - , , 45 .
PRACTICE_DS_SIZE = 45
later_testds_for_plot = test_df.iloc[:PRACTICE_DS_SIZE]
test_df = test_df.iloc[len(later_testds_for_plot):]
test_df = test_df.reset_index(drop=True)
, , . , , .
timestamps = test_df.pop('Date')
sum_outs = test_df.pop('out_sums')
— :
train = test_df.sample(frac=0.8, random_state=42)
test = test_df.drop(train.index)
train_labels = train.pop('Price')
test_labels = test.pop('Price')
.
def norm(train_data, data):
train_stats = train_data.describe()
train_stats = train_stats.transpose()
normalized_data = (data - train_stats['mean']) / train_stats['std']
return normalized_data
, .
, , , :
def build_model():
model = keras.Sequential([
layers.Dense(32, activation='relu', input_shape=[len(train.keys())]),
layers.Dense(32, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
model.summary()
EPOCHS = 500
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
model.fit(normed_train_data2, train_labels2, epochs=EPOCHS,
validation_split = 0.2, verbose=0, callbacks=[early_stop, PrintDot()])

PrintDot() — . TensorFlow. . :
class PrintDot2(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0: print('')
print('.', end='')
— , .
, .
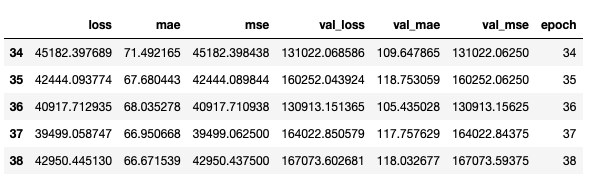
.
loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=2)
: 506/506 — 0s — loss: 36201.9241 — mae: 66.5216 — mse: 36201.9219
MSE 45430.1133 190.27 . .
, .
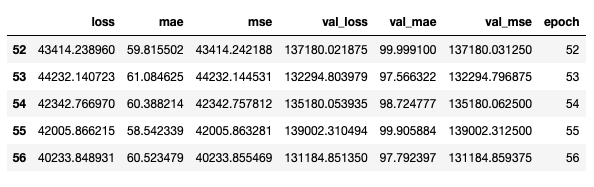
loss, mae, mse = model.evaluate(normed_test_data2, test_labels2, verbose=2)
: 506/506 — 0s — loss: 24382.0926 — mae: 48.5508 — mse: 24382.0918
MSE 24382.0918 , 156.15 , , , , .
. .
actual_price = later_testds_for_plot.pop('Price')
actual_dates = later_testds_for_plot.pop('Date')
normed_practice_data = norm(train, later_testds_for_plot)
practice_prediction = model.predict(normed_practice_data).flatten()
actual_price2 = later_testds_for_plot2.pop('Price')
actual_dates2 = later_testds_for_plot2.pop('Date')
normed_practice_data2 = norm(train2, later_testds_for_plot2)
practice_prediction2 = model.predict(normed_practice_data2).flatten()
fig = plt.figure(figsize=(15,6))
ax1 = fig.add_subplot(121)
ax2 = fig.add_subplot(122)
ax1.plot(actual_dates,actual_price, label ='actual btc price')
ax1.plot(actual_dates,practice_prediction, label ='predicted btc price')
ax1.set_title('BTC Close Price Prediction with only Exch Data')
ax1.legend()
ax2.plot(actual_dates2,actual_price2, label ='actual btc price')
ax2.plot(actual_dates2,practice_prediction2, label ='predicted btc price')
ax2.set_title('BTC Close Price Prediction with Outs')
ax2.legend()
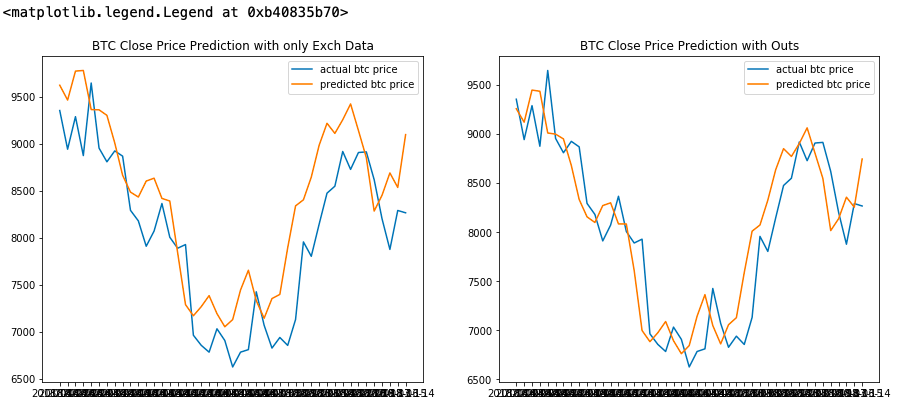
, , , . , , , , , .
, , . , , , .
, , « » ( - ), «».