¿Qué es una estructura de datos?En pocas palabras, una estructura de datos es un contenedor en el que los datos se almacenan en un diseño específico (formato o la forma en que se organiza en la memoria). Este "diseño" permite que la estructura de datos sea efectiva en algunas operaciones e ineficaz en otras. Su objetivo es comprender las estructuras de datos para que pueda elegir la estructura de datos que sea más óptima para el problema en cuestión.¿Por qué necesitamos estructuras de datos?Debido a que las estructuras de datos se utilizan para almacenar datos de manera organizada, y dado que los datos son el elemento más importante de la informática, el verdadero valor de las estructuras de datos es obvio.Independientemente del problema que resuelva, debe manejar los datos de una forma u otra, ya sea el salario de un empleado, el precio de las acciones, la lista de compras o incluso una simple guía telefónica.Basado en diferentes escenarios, los datos deben almacenarse en un formato específico. Tenemos varias estructuras de datos que cubren la necesidad de almacenar datos en diferentes formatos.Estructuras de datos de uso comúnPrimero enumeremos las estructuras de datos de uso más común y luego las veremos una por una:- Arreglos - Arreglos
- Pilas - Pilas
- Colas - Colas
- Listas vinculadas - Listas relacionadas
- Árboles - Árboles
- Gráficos - gráficos
- Intentos (son esencialmente árboles, pero aún así es bueno nombrarlos por separado). - prioridad
- Tablas hash - tablas hash
Matrices: matricesUna matriz es la estructura de datos más simple y más utilizada. Otras estructuras de datos, como pilas y colas, se derivan de matrices.Aquí hay una imagen de una matriz simple de tamaño 4 que contiene elementos (1, 2, 3 y 4).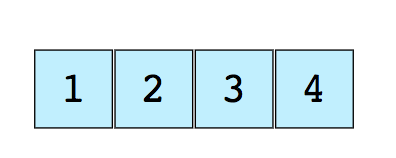 A cada elemento de datos se le asigna un valor numérico positivo llamado índice, que corresponde a la posición de este elemento en la matriz. La mayoría de los idiomas definen el índice inicial de una matriz como 0.Los siguientes son dos tipos de matrices:
A cada elemento de datos se le asigna un valor numérico positivo llamado índice, que corresponde a la posición de este elemento en la matriz. La mayoría de los idiomas definen el índice inicial de una matriz como 0.Los siguientes son dos tipos de matrices:- Matrices unidimensionales (como se muestra arriba)
- Matrices multidimensionales (matrices dentro de matrices) Matrices multidimensionales
Operaciones básicas en matrices.Insertar: inserta unelemento en un índice especificado.Eliminar (Eliminar): elimina un elemento en un índice especificado.Tamaño: obtener el número total de elementos en una matriz.Para el autoestudio:1 Encuentra el segundo elemento mínimo de la matriz.2. Los primeros enteros no repetitivos en la matriz.3. Combine dos matrices ordenadas.4. Reordenar los valores positivos y negativos en la matriz.PilasTodos estamos familiarizados con la famosa opción Deshacer (Cancelar), que está presente en casi todas las aplicaciones. ¿Alguna vez se preguntó cómo funciona esto? La esencia del mecanismo es que guarda los estados anteriores de su trabajo (que están limitados por un cierto número) en la memoria de tal manera que la última acción aparece primero. Esto no se puede hacer solo con matrices. ¡Ahí es donde la pila es útil!Un ejemplo real de una pila es una pila de libros dispuestos verticalmente. Para obtener un libro en algún lugar en el medio, debe eliminar todos los libros colocados encima. Así es como funciona el método LIFO (último en entrar, primero en salir) .Aquí hay una imagen de una pila que contiene tres elementos de datos (1, 2 y 3), donde 3 está en la parte superior y se eliminará primero: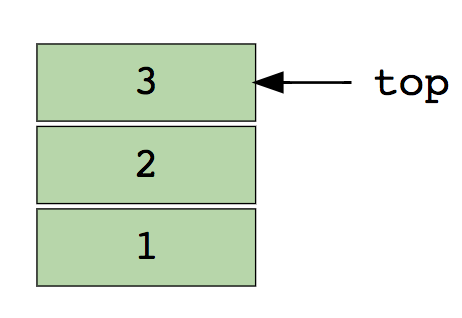 Las operaciones básicas con pilas:Push: inserta un elemento encima de otros.Pull (Pop): devuelve el elemento superior después de eliminarlo de la pila.¿Vacío? (IsEmpty): devuelve verdadero (verdadero) si la pila está vacía.Arriba (Arriba): devuelve el elemento superior sin eliminarlo de la pila.Para un estudio independiente:1. Evalúe la expresión postfix usando la pila.2. Ordenar valores en la pila.3. Verifique los corchetes balanceados en la expresión.ColasAl igual que una pila, una cola es otra estructura de datos lineal en la que los elementos se almacenan secuencialmente. La única diferencia significativa entre la pila y la cola es que, en lugar de usar el método LIFO, Queue implementa un métodoFIFO, que es la abreviatura de Primero en entrar, primero en salir .Un gran ejemplo real de una línea: una cantidad de personas que esperan en la taquilla. Si llega una nueva persona, se une a la línea desde el final, y no desde el principio, y la persona que se encuentre al frente será la primera en recibir un boleto y, por lo tanto, abandonará la línea.Aquí hay una imagen de una cola que contiene cuatro elementos de datos (1, 2, 3 y 4), donde 1 está en la parte superior y se eliminará primero:
Las operaciones básicas con pilas:Push: inserta un elemento encima de otros.Pull (Pop): devuelve el elemento superior después de eliminarlo de la pila.¿Vacío? (IsEmpty): devuelve verdadero (verdadero) si la pila está vacía.Arriba (Arriba): devuelve el elemento superior sin eliminarlo de la pila.Para un estudio independiente:1. Evalúe la expresión postfix usando la pila.2. Ordenar valores en la pila.3. Verifique los corchetes balanceados en la expresión.ColasAl igual que una pila, una cola es otra estructura de datos lineal en la que los elementos se almacenan secuencialmente. La única diferencia significativa entre la pila y la cola es que, en lugar de usar el método LIFO, Queue implementa un métodoFIFO, que es la abreviatura de Primero en entrar, primero en salir .Un gran ejemplo real de una línea: una cantidad de personas que esperan en la taquilla. Si llega una nueva persona, se une a la línea desde el final, y no desde el principio, y la persona que se encuentre al frente será la primera en recibir un boleto y, por lo tanto, abandonará la línea.Aquí hay una imagen de una cola que contiene cuatro elementos de datos (1, 2, 3 y 4), donde 1 está en la parte superior y se eliminará primero: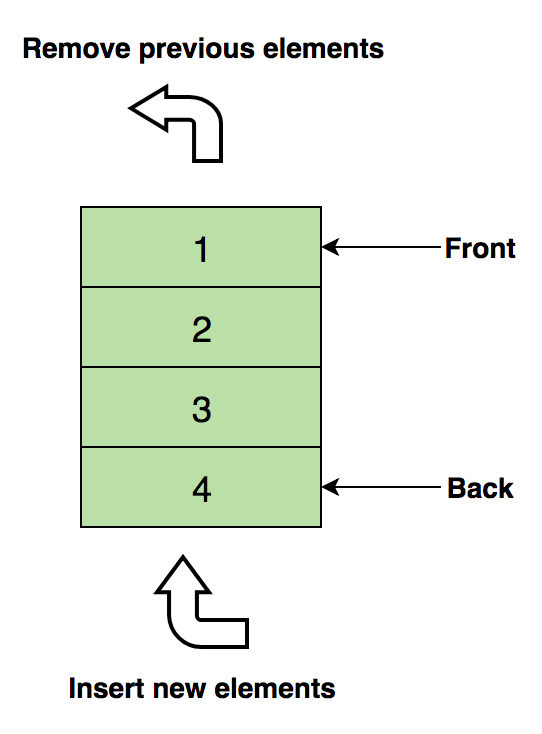 Operaciones básicas con la cola:Encola: inserta un elemento al final de la cola.Dequeue: elimina un elemento desde el comienzo de la cola.¿Vacío? (IsEmpty): devuelve verdadero (verdadero) si la cola está vacía.Arriba (Arriba): devuelve el primer elemento de la cola.Para estudio independiente:1. Implementación de la pila usando la cola.2. Los primeros k elementos inversos de la cola.3. Generación de números binarios del 1 al n usando la cola.Listavinculada Una lista vinculada es otra estructura de datos lineal importante que a primera vista puede parecer similar a las matrices, pero difiere en la asignación de memoria, la estructura interna y la forma en que se realizan las operaciones básicas de inserción y eliminación.Una lista vinculada es como una cadena de nodos, donde cada nodo contiene información como datos y un puntero al siguiente nodo de la cadena. Hay un puntero de encabezado que apunta al primer elemento de la lista vinculada, y si la lista está vacía, simplemente apunta a cero o nada.Las listas vinculadas se utilizan para implementar sistemas de archivos, tablas hash y listas de adyacencia.Aquí hay una representación visual de la estructura interna de una lista vinculada:
Operaciones básicas con la cola:Encola: inserta un elemento al final de la cola.Dequeue: elimina un elemento desde el comienzo de la cola.¿Vacío? (IsEmpty): devuelve verdadero (verdadero) si la cola está vacía.Arriba (Arriba): devuelve el primer elemento de la cola.Para estudio independiente:1. Implementación de la pila usando la cola.2. Los primeros k elementos inversos de la cola.3. Generación de números binarios del 1 al n usando la cola.Listavinculada Una lista vinculada es otra estructura de datos lineal importante que a primera vista puede parecer similar a las matrices, pero difiere en la asignación de memoria, la estructura interna y la forma en que se realizan las operaciones básicas de inserción y eliminación.Una lista vinculada es como una cadena de nodos, donde cada nodo contiene información como datos y un puntero al siguiente nodo de la cadena. Hay un puntero de encabezado que apunta al primer elemento de la lista vinculada, y si la lista está vacía, simplemente apunta a cero o nada.Las listas vinculadas se utilizan para implementar sistemas de archivos, tablas hash y listas de adyacencia.Aquí hay una representación visual de la estructura interna de una lista vinculada: Los siguientes son los tipos de listas vinculadas:
Los siguientes son los tipos de listas vinculadas:- Lista de enlace único (unidireccional)
- Lista doblemente vinculada (bidireccional)
Operaciones básicas en una lista vinculadaInsertAtEnd: inserta un elemento al final de una lista vinculada.InsertarB Inicio (InsertAtHead): inserta un elemento al comienzo de una lista vinculada.Eliminar: elimina este elemento de la lista vinculada.DeleteBeginning (DeleteAtHead): elimina el primer elemento de la lista vinculada.Buscar: devuelve el elemento encontrado de la lista vinculada.¿Vacío? (IsEmpty): devuelve verdadero (verdadero) si la lista vinculada está vacía.Para estudio independiente:1. Voltee la lista vinculada (Invertir, invertir, mostrar hacia atrás).2. Defina un bucle en una lista vinculada.3. Devuelva el enésimo nodo desde el final en la lista vinculada.4. Eliminar duplicados de la lista vinculada.Gráficos Losgráficos son una colección de nodos que están conectados entre sí en forma de red. Los nodos también se llaman vértices. El par (x, y) se llama borde, lo que indica que el vértice x está conectado con el vértice y. Una arista puede contener peso / costo, que muestra cuánto cuesta llevar el movimiento de x a y superior.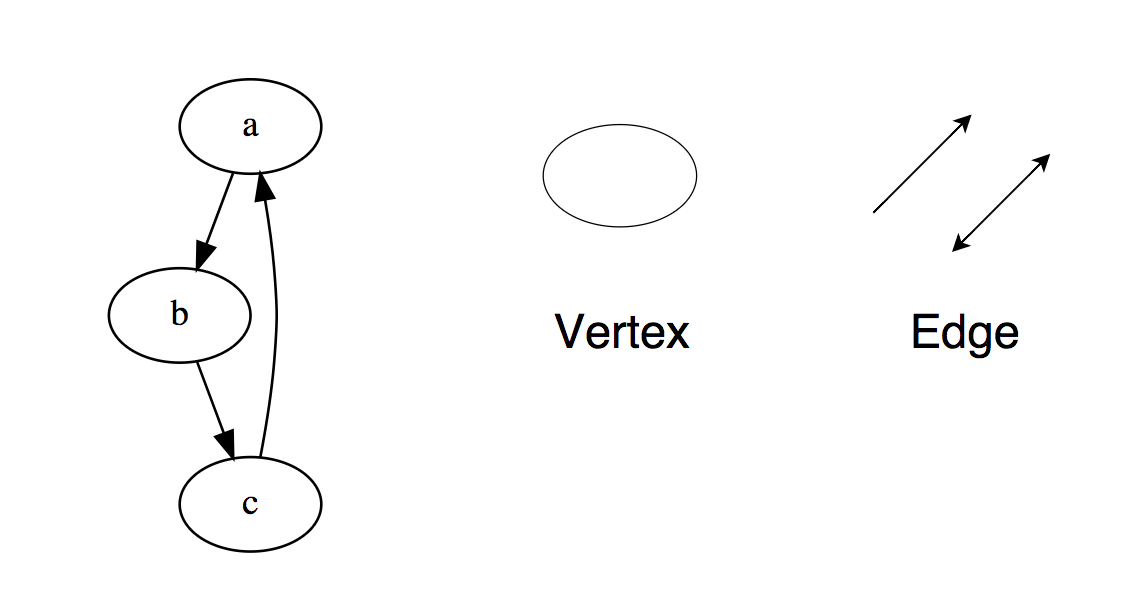 Tipos de gráficos:
Tipos de gráficos:- Gráfico no dirigido
- Gráfico dirigido
En los lenguajes de programación, los gráficos se representan en dos formas:El siguiente es un ejemplo de una Lista de adyacencia contigua (gráfico no dirigido).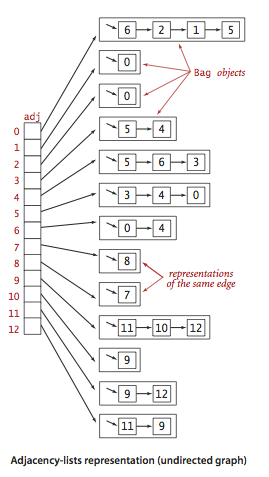 Ejemplos conocidos de algoritmos de movimiento a lo largo de gráficos:Para estudio independiente:1. Implementación de la búsqueda de Amplitud y Profundidad Primero2. Verifique si el gráfico es un árbol o no.3. Contando el número de aristas en el gráfico.4. Encuentra el camino más corto entre los picos.ÁrbolesUn árbol es una estructura de datos jerárquica que consta de vértices (nodos) y bordes que los conectan. Los árboles parecen gráficos, pero el punto clave que distingue un árbol de un gráfico es que no puede existir un bucle en un árbol. Un árbol es un gráfico desgarrado.Los árboles se usan ampliamente en inteligencia artificial y algoritmos complejos para proporcionar un mecanismo de almacenamiento eficiente para algoritmos de resolución de problemas.Aquí hay una imagen de un árbol simple y los términos básicos utilizados en la estructura de datos del árbol:
Ejemplos conocidos de algoritmos de movimiento a lo largo de gráficos:Para estudio independiente:1. Implementación de la búsqueda de Amplitud y Profundidad Primero2. Verifique si el gráfico es un árbol o no.3. Contando el número de aristas en el gráfico.4. Encuentra el camino más corto entre los picos.ÁrbolesUn árbol es una estructura de datos jerárquica que consta de vértices (nodos) y bordes que los conectan. Los árboles parecen gráficos, pero el punto clave que distingue un árbol de un gráfico es que no puede existir un bucle en un árbol. Un árbol es un gráfico desgarrado.Los árboles se usan ampliamente en inteligencia artificial y algoritmos complejos para proporcionar un mecanismo de almacenamiento eficiente para algoritmos de resolución de problemas.Aquí hay una imagen de un árbol simple y los términos básicos utilizados en la estructura de datos del árbol: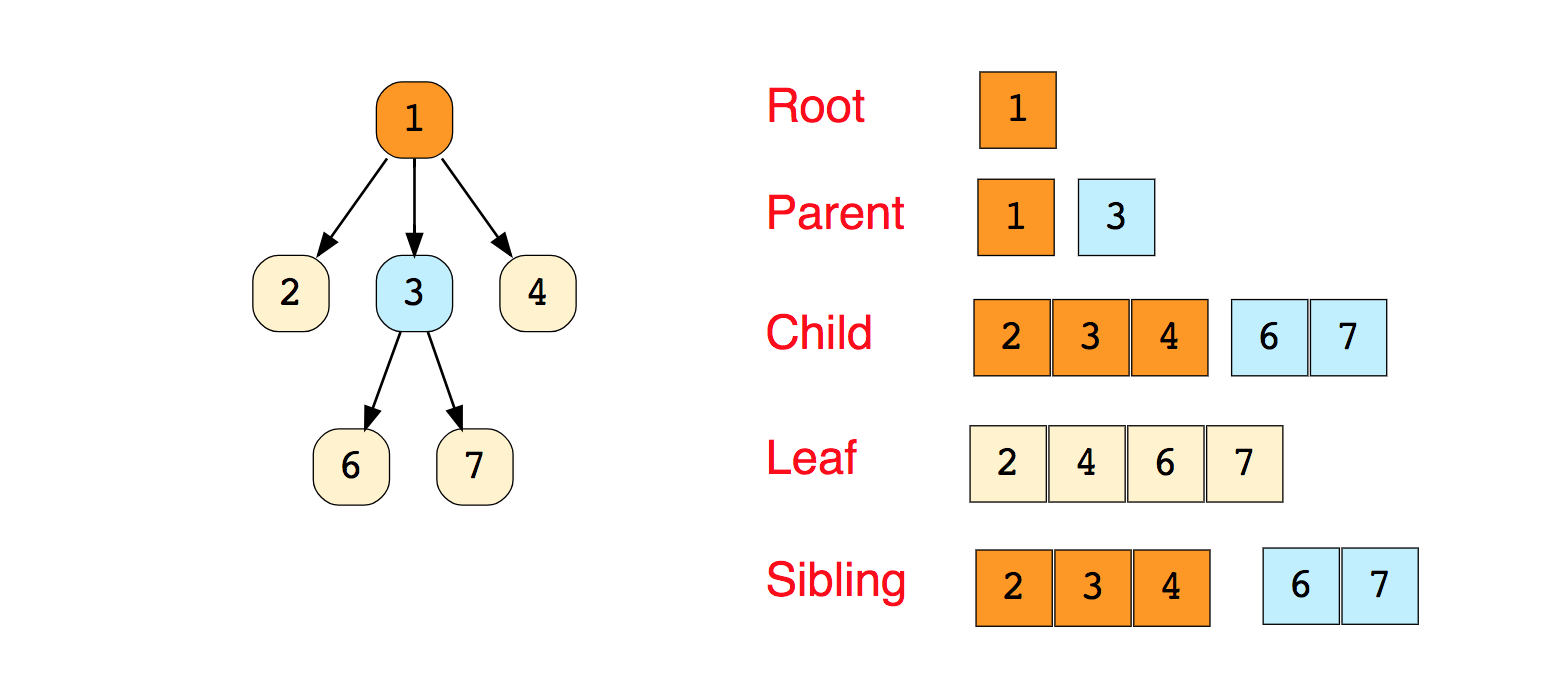 Hay tipos de árboles:
Hay tipos de árboles:- N-
- (Balanced Tree)
- (Binary Tree)
- (Binary Search Tree)
- AVL
- - (Red Black Tree)
- 2–3
De lo anterior, el árbol binario y el árbol de búsqueda binaria son los árboles más utilizados.Para estudio independiente:1. Encuentre la altura del árbol binario.2. Encuentre el kth valor máximo en el árbol de búsqueda binario.3. Encuentre los nodos a una distancia de "k" de la raíz.4. Encuentre los antepasados del nodo dado en el árbol binario.Ejemplos prácticos:1. Facebook: cada usuario es un vértice, y dos personas son amigos cuando hay un borde entre dos vértices. También las recomendaciones a amigos se calculan sobre la base de la teoría de grafos.2. Google Maps: las diferentes ubicaciones están representadas por picos y las carreteras están representadas por bordes, la teoría de gráficos se utiliza para encontrar el camino más corto entre dos picos.3. Redes de transporte: en ellas, los picos son intersecciones de carreteras y costillas; estos son segmentos de carretera entre sus intersecciones.4. Representación de estructuras moleculares donde los vértices son moléculas y los bordes son los enlaces entre las moléculas.5. Procesos de señalización discreta en gráficos. ( y también hay un buen artículo aquí, y este al mismo tiempo )6. Las observaciones empíricas muestran que la mayoría de los genes están regulados por un pequeño número de otros genes, generalmente menos de diez. Por lo tanto, una red genética puede considerarse como un gráfico disperso, es decir, un gráfico en el que un nodo está conectado a varios otros nodos. Si los gráficos orientados (acíclicos) o los gráficos no dirigidos están saturados de probabilidades, entonces el resultado son modelos gráficos orientados probabilísticamente y modelos gráficos no dirigidos probabilísticos, respectivamente.7. Teoría de la expansión del clúster de Mayer de la función de volatilidad .el gas (Z) en termodinámica requiere el cálculo de dos, tres, cuatro condiciones, etc. Hay una forma sistemática de hacer esto combinatoriamente con gráficos, y ayuda a descubrir la conectividad de dichos gráficos. Conocer la teoría de gráficos puede ser útil cuando desea resumir un subconjunto de estos diagramas.8. Coloración del mapa: el famoso teorema de los cuatro colores establece que siempre se pueden colorear correctamente las regiones del mapa, de modo que no se asignen dos regiones adyacentes del mismo color con no más de cuatro colores diferentes. En este modelo, las regiones con colores son nodos, y las adyacencias son bordes del gráfico.9. La tarea con tres cabañas es un acertijo matemático bien conocido. Se puede formular de la siguiente manera: tres cabañas en un avión (o esfera), cada una de las cuales debe estar conectada a compañías de gas, agua y electricidad. El problema se resuelve usando un gráfico en el plano .10. Busque el centro del gráfico: para cada vértice, encuentre la longitud del camino más corto hasta el vértice más lejano. El centro del gráfico es el vértice para el cual este valor es mínimo. Esto es importante para la planificación arquitectónica de los asentamientos en los que debe ubicarse un hospital, departamento de bomberos o estación de policía para que el punto más alejado esté lo más cerca posible.Para los amantes de C #, como yo, hay un enlace con ejemplos de código de gráficos de C # aquí. Para la biblioteca más avanzada con la implementación de gráficos en C ++ aquí . Para los fanáticos de AI y Skynet, pisa fuerte aquí .Secuencias (Trie) Lassecuencias, también conocidas como árboles con prefijos (Árboles de prefijos), son una estructura de datos similar a un árbol que es lo suficientemente eficaz como para resolver los problemas asociados con las cadenas. Proporcionan una búsqueda rápida y se utilizan principalmente para buscar palabras en un diccionario, oraciones automáticas en un motor de búsqueda e incluso para el enrutamiento IP.Aquí hay una ilustración de cómo se almacenan las tres palabras "arriba", "así" y "su" en la Prioridad: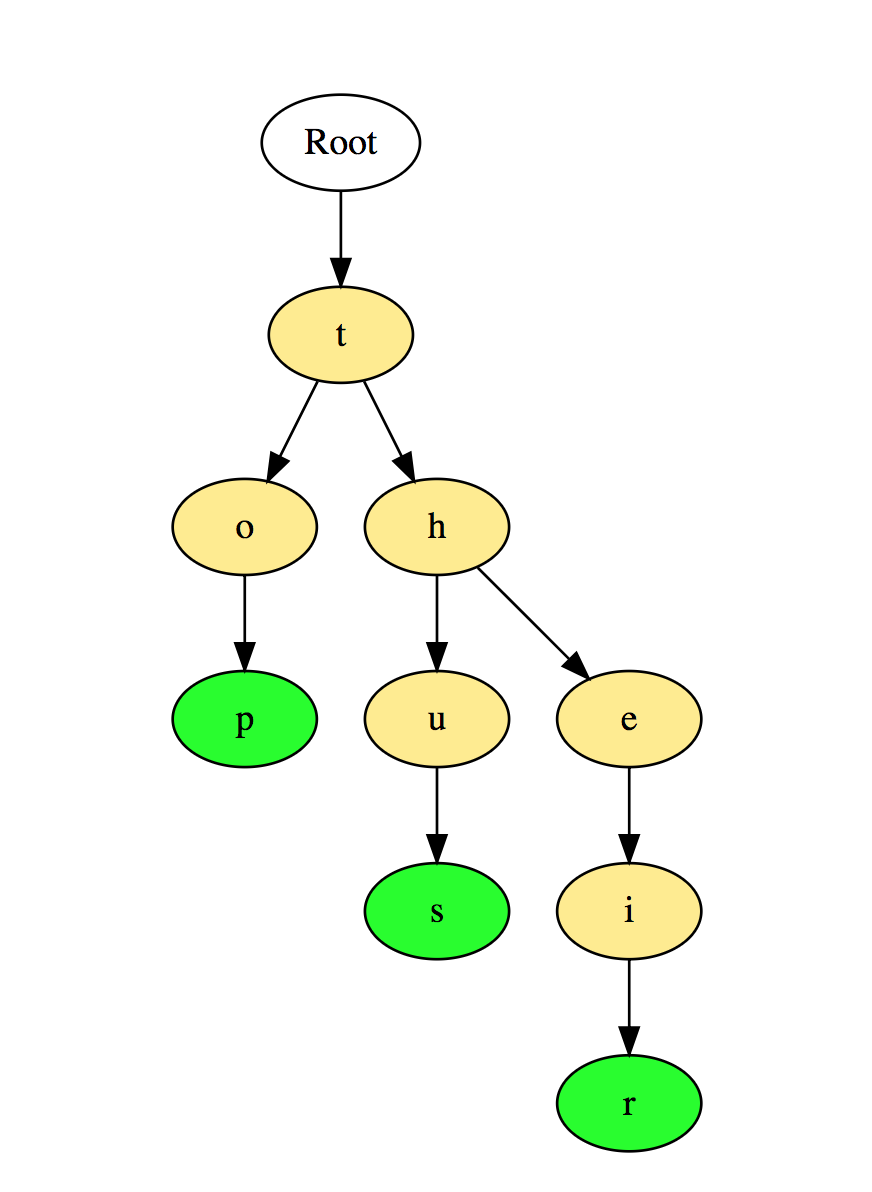 Las palabras se almacenan de arriba a abajo, donde los nodos verdes "p", "s" y "r" apuntan al final de "arriba", " así "y" su ", respectivamente.Para estudio independiente:1. Cuente el número total de palabras en la Prioridad.2. Imprima todas las palabras almacenadas en la Prioridad.3. Ordenar elementos de la matriz usando Prioridad.4. Genere palabras del diccionario usando Colas.5. Cree el diccionario T9.Ejemplos prácticos de uso:1. Selección del diccionario o finalización al escribir una palabra.2. Busque en los contactos en el teléfono o en el diccionario del teléfono.Tabla de picadilloEl hash es un proceso utilizado para identificar objetos de forma exclusiva y almacenar cada objeto mediante un índice único precalculado llamado "clave". Por lo tanto, el objeto se almacena en forma de un par clave-valor, y una colección de dichos elementos se denomina diccionario. Cada objeto se puede encontrar usando esta clave.Existen diferentes estructuras de datos basadas en hash, pero la tabla de hash es la estructura de datos más utilizada. Se usa una tabla hash cuando necesita acceder a elementos con una clave, y puede determinar el valor útil de la clave.Las tablas hash generalmente se implementan utilizando matrices.El rendimiento del hashing de una estructura de datos depende de estos tres factores:
Las palabras se almacenan de arriba a abajo, donde los nodos verdes "p", "s" y "r" apuntan al final de "arriba", " así "y" su ", respectivamente.Para estudio independiente:1. Cuente el número total de palabras en la Prioridad.2. Imprima todas las palabras almacenadas en la Prioridad.3. Ordenar elementos de la matriz usando Prioridad.4. Genere palabras del diccionario usando Colas.5. Cree el diccionario T9.Ejemplos prácticos de uso:1. Selección del diccionario o finalización al escribir una palabra.2. Busque en los contactos en el teléfono o en el diccionario del teléfono.Tabla de picadilloEl hash es un proceso utilizado para identificar objetos de forma exclusiva y almacenar cada objeto mediante un índice único precalculado llamado "clave". Por lo tanto, el objeto se almacena en forma de un par clave-valor, y una colección de dichos elementos se denomina diccionario. Cada objeto se puede encontrar usando esta clave.Existen diferentes estructuras de datos basadas en hash, pero la tabla de hash es la estructura de datos más utilizada. Se usa una tabla hash cuando necesita acceder a elementos con una clave, y puede determinar el valor útil de la clave.Las tablas hash generalmente se implementan utilizando matrices.El rendimiento del hashing de una estructura de datos depende de estos tres factores:- Función hash
- Tamaño de tabla hash
- Método de procesamiento de colisión
Aquí hay una ilustración de cómo se muestra un hash en una matriz. El índice de esta matriz se calcula utilizando una función hash.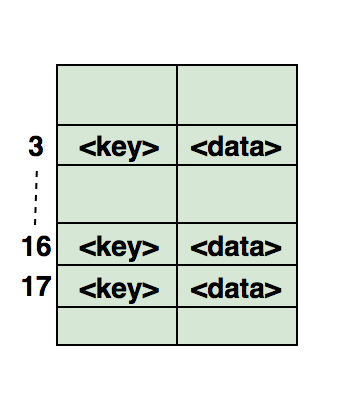 Para estudio independiente:1. Encuentre pares simétricos en la matriz.2. Siga la ruta de viaje completa.3. Encuentre si la matriz es un subconjunto de otra matriz.4. Compruebe si las matrices dadas son disjuntas.A continuación se muestra un ejemplo de código de uso de tabla hash en .Net
Para estudio independiente:1. Encuentre pares simétricos en la matriz.2. Siga la ruta de viaje completa.3. Encuentre si la matriz es un subconjunto de otra matriz.4. Compruebe si las matrices dadas son disjuntas.A continuación se muestra un ejemplo de código de uso de tabla hash en .Netstatic void Main(string[] args)
{
Hashtable ht = new Hashtable
{
{ "001", "Zara Ali" },
{ "002", "Abida Rehman" },
{ "003", "Joe Holzner" },
{ "004", "Mausam Benazir Nur" },
{ "005", "M. Amlan" },
{ "006", "M. Arif" },
{ "007", "Ritesh Saikia" }
};
if (ht.ContainsValue("Nuha Ali"))
{
Console.WriteLine(" !");
}
else
{
ht.Add("008", "Nuha Ali");
}
ICollection key = ht.Keys;
foreach (string k in key)
{
Console.WriteLine(k + ": " + ht[k]);
}
Console.ReadKey();
}
Ejemplos prácticos:1. El juego "Vida". En él, un hash es un conjunto de coordenadas de cada célula viva.2. Una versión primitiva del motor de búsqueda de Google podría asignar todas las palabras existentes en un conjunto de URL donde ocurran. En este caso, las tablas hash se usan dos veces: la primera vez para asignar palabras a conjuntos de URL y, la segunda vez, para guardar cada conjunto de URL.3. Al implementar la estructura / algoritmo de un árbol multidireccional (árbol de múltiples vías), las tablas hash se pueden usar para acceder rápidamente a cualquier elemento hijo del nodo interno.4. Al escribir un programa para jugar al ajedrez, es muy importante realizar un seguimiento de las posiciones que se evaluaron previamente, para que pueda volver cuando las necesite nuevamente si es necesario.5. Cualquier lenguaje de programación necesita asignar el nombre de la variable a su dirección en la memoria. De hecho, en los lenguajes de script como Javascript y Perl, los campos se pueden agregar al objeto dinámicamente, lo que significa que los objetos en sí son como mapas hash.