Cuando Facebook "miente", la gente piensa que se debe a piratas informáticos o ataques DDoS, pero no es así. Todas las "caídas" en los últimos años han sido causadas por cambios internos o fallas. Para enseñar a los nuevos empleados a no romper Facebook con ejemplos, todos los incidentes importantes tienen nombres, por ejemplo, "Call the Cops" o "CAPSLOCK". El primero fue nombrado porque cuando un día la red social cayó, los usuarios llamaron a la policía de Los Ángeles y pidieron que lo arreglaran, y el sheriff desesperado en Twitter pidió no molestarlos por esto. Durante el segundo incidente en las máquinas de caché, la interfaz de red se cayó y no aumentó, y todas las máquinas se reiniciaron a mano.Elina Lobanovaha estado trabajando en Facebook durante los últimos 4 años en el equipo de Web Foundation. Los miembros del equipo se llaman ingenieros de producción y monitorean la confiabilidad y el rendimiento de todo el backend, apagan Facebook cuando está encendido, escriben monitoreo y automatización para facilitarles la vida a ellos mismos y a los demás. En un artículo basado en el informe de Elina sobre HighLoad ++ 2019 , mostraremos cómo los ingenieros de producción monitorean el backend de Facebook, qué herramientas usan, cuáles son las principales fallas y cómo lidiar con ellas.Mi nombre es Elina, hace casi 5 años fui llamado a Facebook como desarrollador ordinario, donde encontré por primera vez sistemas muy cargados, esto no se enseña en los institutos. La compañía no contrata un equipo, sino una oficina, así que llegué a Londres, elegí un equipo que supervisa el trabajo de facebook.com y estaba entre los ingenieros de producción.
En un artículo basado en el informe de Elina sobre HighLoad ++ 2019 , mostraremos cómo los ingenieros de producción monitorean el backend de Facebook, qué herramientas usan, cuáles son las principales fallas y cómo lidiar con ellas.Mi nombre es Elina, hace casi 5 años fui llamado a Facebook como desarrollador ordinario, donde encontré por primera vez sistemas muy cargados, esto no se enseña en los institutos. La compañía no contrata un equipo, sino una oficina, así que llegué a Londres, elegí un equipo que supervisa el trabajo de facebook.com y estaba entre los ingenieros de producción.Ingenieros de produccion
Para comenzar, te diré lo que estamos haciendo y por qué nos llaman ingenieros de producción, y no SRE como Google, por ejemplo.2009. SRE
El modelo estándar que todavía se usa en muchas empresas es "desarrolladores - probadores - operación". A menudo están divididos: se sientan en diferentes pisos, a veces incluso en diferentes países, y no se comunican entre sí.En 2009, Facebook ya tenía SRE. En Google, SRE comenzó antes, saben cómo lograr DevOps y lo han escrito en su libro " Ingeniería de confiabilidad del sitio ". En Facebook en 2009, no había nada como esto. Nos llamaron SRE, pero hicimos el mismo trabajo que Ops en el resto del mundo: trabajo manual, sin automatización, implementación de todos los servicios con sus manos, monitoreo de alguna manera, llamada para todo, un conjunto de scripts de shell.
En Facebook en 2009, no había nada como esto. Nos llamaron SRE, pero hicimos el mismo trabajo que Ops en el resto del mundo: trabajo manual, sin automatización, implementación de todos los servicios con sus manos, monitoreo de alguna manera, llamada para todo, un conjunto de scripts de shell.2010. SRO y AppOps
Todo esto no escalaba, porque la cantidad de usuarios en ese momento estaba creciendo 3 veces al año, y la cantidad de servicios creció en consecuencia. En 2010, la decisión decidida Ops se dividió en dos grupos.El primer grupo es SRO , donde "O" son "operaciones", dedicadas al desarrollo, la automatización y el monitoreo del sitio.El segundo grupo es AppOps , se integraron en equipos, cada uno para grandes servicios. AppOps ya está cerca de la idea de DevOps.La separación por un tiempo salvó a todos.2012. Ingenieros de producción
En 2012, AppOps simplemente cambió el nombre de ingenieros de producción . Además del nombre, nada ha cambiado, pero se ha vuelto más cómodo. Como llamas a un yate, navegará, y no queríamos navegar como Ops.Las SRO todavía existían, Facebook estaba creciendo y monitorear todos los servicios a la vez era difícil. A una persona que estaba en la llamada ni siquiera se le permitía ir al baño: le pidió a alguien que lo reemplazara, porque se estaba quemando constantemente.2014. SRO de cierre
En un momento, las autoridades transfirieron a todos a la llamada. "Todos" significa que los desarrolladores también: escriban su código, ¡aquí están y respondan por este código!Los ingenieros de producción ya se han integrado en los equipos más importantes para obtener ayuda, y el resto no tiene suerte. Comenzamos con equipos grandes y en un par de años transferimos a todos en Facebook a oncall. Entre los desarrolladores hubo una gran emoción: alguien renunció, alguien escribió publicaciones malas. Pero todo se calmó, y en 2014 el SRO se cerró porque ya no eran necesarios. Entonces vivimos hasta el día de hoy.La palabra "SRE" en la empresa es notoria, pero parecemos SRE en Google. Hay diferencias.- Siempre estamos integrados en equipos. No tenemos búsqueda SRE en general, como en Google, es para cada servicio de búsqueda por separado.
- No estamos en los productos , solo en la infraestructura que el producto administra por sí mismo.
- Estamos en llamada junto con los desarrolladores.
- Tenemos un poco más de experiencia en sistemas y redes, por lo que nos enfocamos en monitorear y extinguir los servicios cuando se queman brillantemente. Solucionamos los errores de antemano que podrían provocar bloqueos e influir en la arquitectura de los nuevos servicios desde el principio, para que luego funcionen sin problemas en la producción.
Supervisión
Es lo mas importante. Cómo hacemos esto? Como todos: sin magia negra, en su propio hogar. Pero el diablo, como siempre, te contará sobre ellos en detalle.ENCIMA
Comencemos desde abajo. Todos conocen TOP en Linux, y usamos ATOP, donde "A" es "avanzado": un monitor de rendimiento del sistema. El principal beneficio de ATOP es que almacena el historial: puede configurarlo para guardar instantáneas en el disco. Nuestro ATOP se ejecuta en todas las máquinas cada 5 segundos.Aquí hay un servidor de ejemplo que ejecuta el backend PHP para facebook.com. Escribimos nuestra máquina virtual para ejecutar código PHP, se llama HHVM (HipHop Virtual Machine). Según las métricas exportadas, encontramos que varias máquinas no procesaron casi una sola solicitud en un minuto. Veamos por qué, abra ATOP 30 segundos antes de que se cuelgue. Se puede ver que con los problemas del procesador, lo cargamos demasiado. También hay problemas con la memoria, solo quedan 1.5 GB en la memoria caché, y después de 5 segundos solo 800 MB.
Se puede ver que con los problemas del procesador, lo cargamos demasiado. También hay problemas con la memoria, solo quedan 1.5 GB en la memoria caché, y después de 5 segundos solo 800 MB. Después de otros 5 segundos, la CPU se libera, no se ejecuta nada. ATOP dice mira el resultado final, escribimos en el disco, pero ¿qué? Resulta que estamos escribiendo swap.
Después de otros 5 segundos, la CPU se libera, no se ejecuta nada. ATOP dice mira el resultado final, escribimos en el disco, pero ¿qué? Resulta que estamos escribiendo swap. ¿Quién está haciendo esto? Procesos que fueron tomados de la memoria de 0.5 GB y puestos en intercambio. En su lugar, aparecieron dos procesos sospechosos de Python, que luego se pueden ver como una línea de comando.
¿Quién está haciendo esto? Procesos que fueron tomados de la memoria de 0.5 GB y puestos en intercambio. En su lugar, aparecieron dos procesos sospechosos de Python, que luego se pueden ver como una línea de comando.
ATOP es hermoso, lo usamos constantemente.
Si no lo tiene, le recomiendo usarlo. No tenga miedo por la unidad, ATOP solo consume 200-300 MB por día cada 5 segundos.Malloc HTTP
A las Bahamas y los grandes incidentes, les damos nombres. Hay un error divertido relacionado con ATOP llamado Malloc HTTP. Lo presentamos con ATOP y strace.Usamos Thrift en todas partes como un RPC. En las primeras versiones de su analizador había un error sorprendente que funcionaba así: llegó un mensaje en el que los primeros 4 bytes son del tamaño de los datos, luego los datos en sí, y los primeros bytes se agregan al siguiente mensaje.Pero una vez que uno de los programas en lugar de ir al servicio Thrift, fui a HTTP, y recibió una respuesta «HTTP Malo la Solicitud»: HTTP/1.1 400.Después tomó HTTP y asignó usando malloc HTTP el número de bytes.Thrift message
HTTP/1.1 400
"HTTP" == 0x48545450
Está bien, tenemos un compromiso excesivo, ¡asignemos más memoria! Lo asignamos con malloc, y hasta que escribamos y leamos allí, no nos darán memoria real.¡Pero no estaba allí! Si queremos bifurcar, la bifurcación devolverá un error: no hay suficiente memoria.malloc("HTTP")
pid = fork(); // errno = ENOMEM
Pero, ¿por qué hay un recuerdo? Al comprender los manuales, descubrimos que todo es muy simple: la configuración actual de sobrecompromiso es tal que es una heurística mágica, y el núcleo en sí mismo decide cuándo y cuándo no:malloc("HTTP")
pid = fork(); // errno = ENOMEM
// 0: heuristic overcommit
vm.overcommit_memory = 0
Para un proceso de trabajo, esto es normal, puede seleccionar malloc hasta TB, pero para un nuevo proceso, no. Y parte del monitoreo en nosotros estuvo relacionado con el hecho de que el proceso principal bifurcó pequeños scripts para la recopilación de datos. Como resultado, nuestra parte de monitoreo se descompuso, porque ya no podíamos bifurcar.FB303
FB303 es nuestro sistema de monitoreo básico. Fue nombrado después del sintetizador de bajo estándar de 1982. El principio es simple, por lo tanto, todavía funciona: cada servicio implementa la interfaz Thrift getCounters.
El principio es simple, por lo tanto, todavía funciona: cada servicio implementa la interfaz Thrift getCounters.Service FacebookService {
map<string, i64> getCounters()
}
De hecho, no lo implementa, porque las bibliotecas ya están escritas, todo se hace en el código incremento set.incrementCounter(string& key);
setCounter(string& key, int64_t value);
Como resultado, cada servicio exporta contadores en el puerto que registra con Service Discovery. A continuación se muestra un ejemplo de una máquina que genera una fuente de noticias y exporta aproximadamente 5.5 mil pares (cadena, número): memoria, producción, cualquier cosa. Cada máquina ejecuta un proceso binario que pasa por todos los servicios, recopila estos contadores y los almacena.Así es como se ve la GUI de almacenamiento .
Cada máquina ejecuta un proceso binario que pasa por todos los servicios, recopila estos contadores y los almacena.Así es como se ve la GUI de almacenamiento . Muy similar a Prometeo y Grafana, pero no lo es. La primera entrada de FB303 en GitHub fue en 2009, y Prometheus en 2012. Esta es una explicación de todos los productos de Facebook "caseros": los hicimos cuando nada era normal en Open Source.Por ejemplo, hay una búsqueda de los nombres de los contadores.
Muy similar a Prometeo y Grafana, pero no lo es. La primera entrada de FB303 en GitHub fue en 2009, y Prometheus en 2012. Esta es una explicación de todos los productos de Facebook "caseros": los hicimos cuando nada era normal en Open Source.Por ejemplo, hay una búsqueda de los nombres de los contadores. Los gráficos en sí se parecen a esto.
Los gráficos en sí se parecen a esto. Una imagen del grupo interno en el que publicamos hermosos gráficos.Una diferencia importante entre nuestra pila de monitoreo y Prometheus y Grafana es que almacenamos datos para siempre . Nuestro monitoreo volverá a muestrear los datos, y después de 2 semanas tendremos un punto por cada 5 minutos, y después de un año por cada hora. Por lo tanto, se pueden almacenar tanto. Automáticamente esto no está configurado en ningún lado.Pero si hablamos de las características de monitorear Facebook, entonces lo describiría con una palabra en inglés " observabilidad" .
Una imagen del grupo interno en el que publicamos hermosos gráficos.Una diferencia importante entre nuestra pila de monitoreo y Prometheus y Grafana es que almacenamos datos para siempre . Nuestro monitoreo volverá a muestrear los datos, y después de 2 semanas tendremos un punto por cada 5 minutos, y después de un año por cada hora. Por lo tanto, se pueden almacenar tanto. Automáticamente esto no está configurado en ningún lado.Pero si hablamos de las características de monitorear Facebook, entonces lo describiría con una palabra en inglés " observabilidad" .Observabilidad
Hay una "caja negra", hay una "caja blanca", y tenemos una "caja" transparente de vidrio. Esto significa que cuando escribimos código, escribimos todo lo que es posible en los registros, y no selectivamente. El muestreo está bien ajustado en todas partes, por lo que el backend para almacenamiento, mostradores y todo lo demás vive bien.Al mismo tiempo, podemos construir nuestros paneles ya en los contadores existentes. En el caso de estudiar estos paneles, este no es el punto final con 10 gráficos, sino el inicial, desde el cual vamos a nuestra IU y encontramos todo lo que allí es posible.Escafandra autónoma
Este es el clímax de la idea de observabilidad. Esta es nuestra pila de ELK. El principio es el mismo: escribimos en JSON sin un esquema específico, luego solicitamos en forma de tabla , series temporales de datos o 10 opciones de visualización más.Los registros de buceo son del orden de cientos de gigabytes por segundo. Todo se solicita muy rápidamente, porque no es Elasticsearch, y todo está en la memoria en máquinas potentes. Sí, se gasta dinero, ¡pero qué maravilloso es!Por ejemplo, debajo de la interfaz de usuario de Scuba, se abre una de las tablas más populares, en la que todos los clientes de todos los servicios de Thrift escriben registros.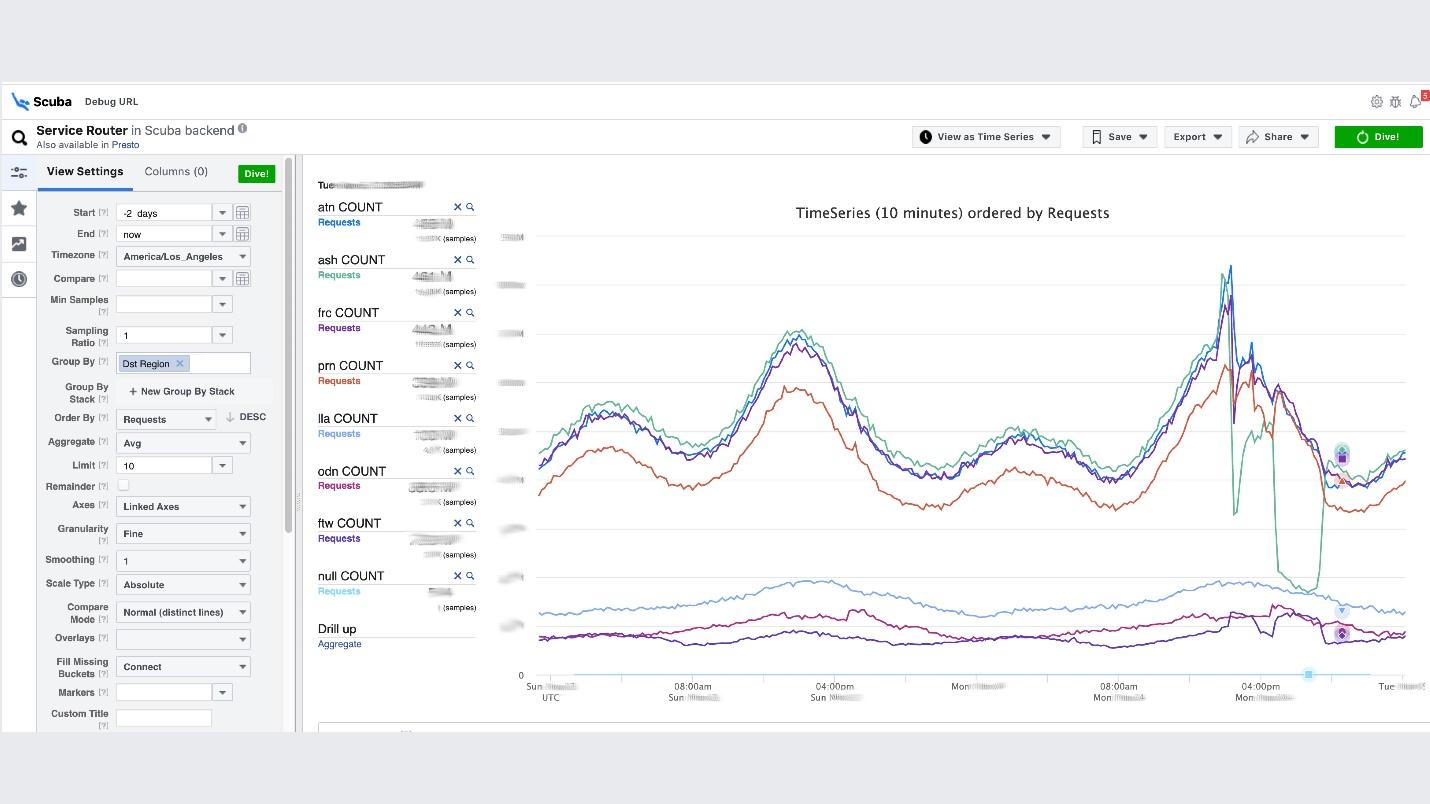 El gráfico muestra que al final, algo salió mal en el servicio. Para averiguar el retraso, vaya a la lista de contadores, seleccione el retraso, la agregación, haga clic en "Inmersión".
El gráfico muestra que al final, algo salió mal en el servicio. Para averiguar el retraso, vaya a la lista de contadores, seleccione el retraso, la agregación, haga clic en "Inmersión".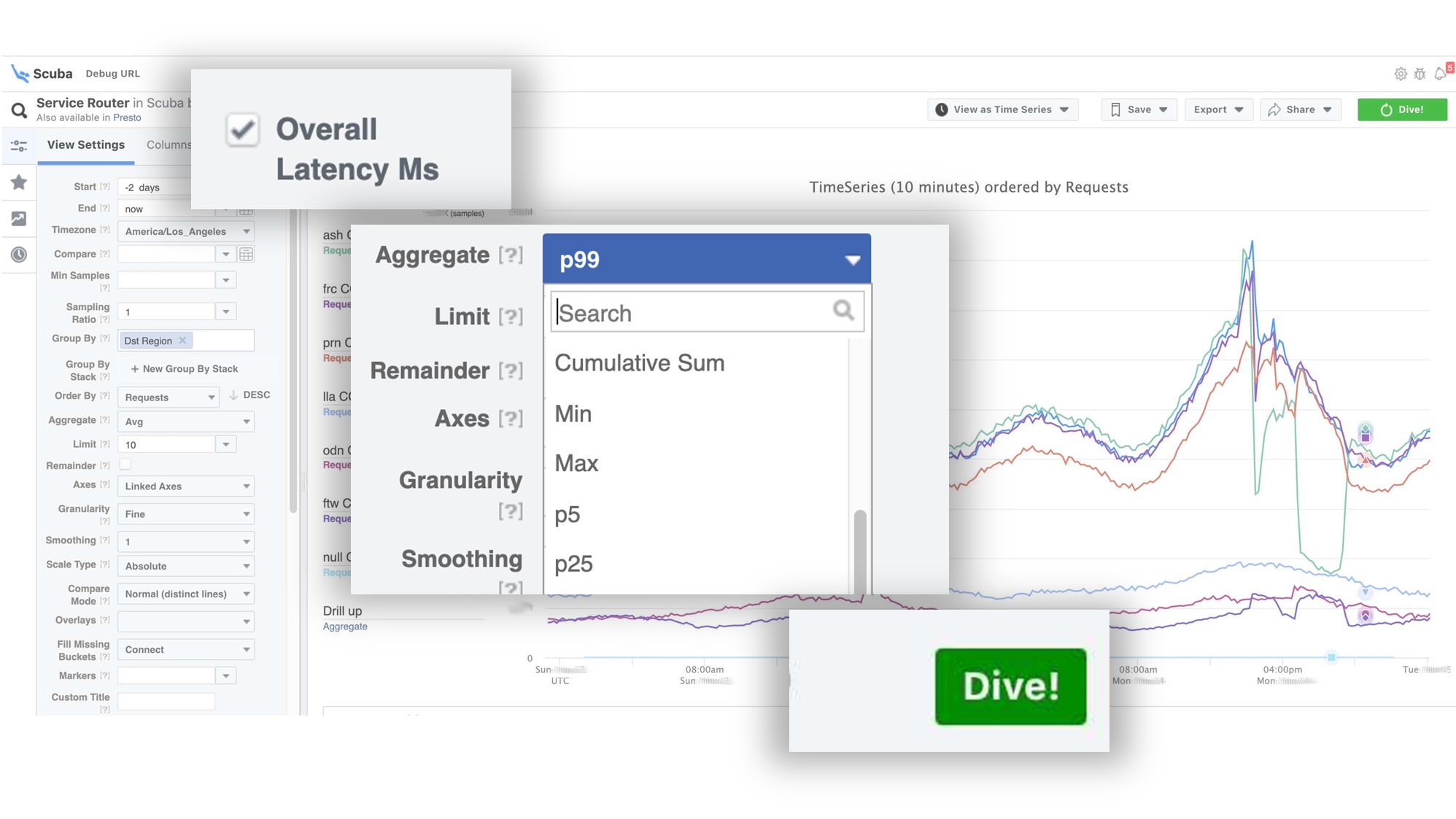 La respuesta llega en 2 segundos.
La respuesta llega en 2 segundos.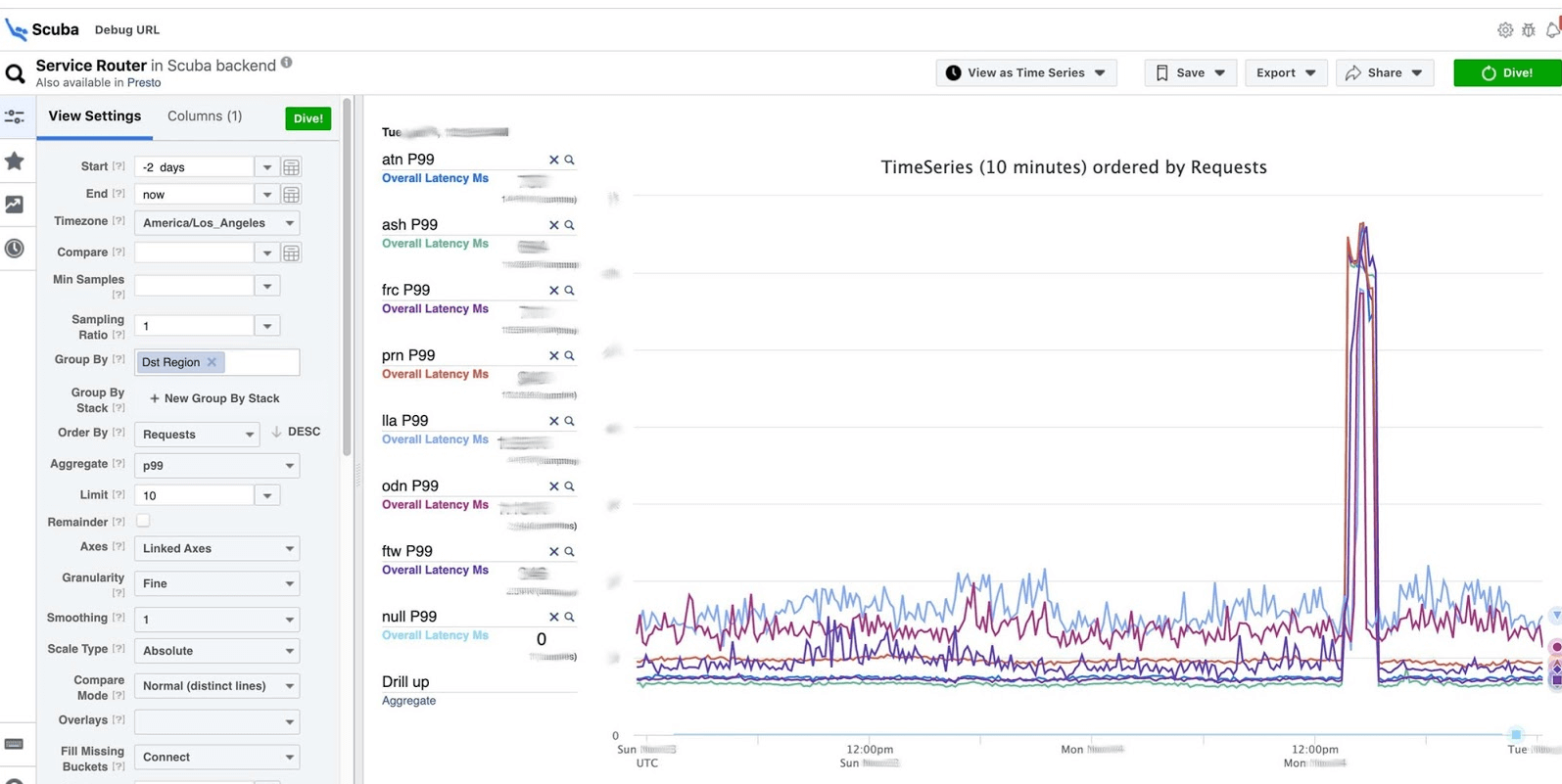 Se puede ver que en ese momento sucedió algo y la demora aumentó significativamente. Para obtener más información, puede agrupar por diferentes parámetros.Hay cientos de esas mesas.
Se puede ver que en ese momento sucedió algo y la demora aumentó significativamente. Para obtener más información, puede agrupar por diferentes parámetros.Hay cientos de esas mesas.- Una tabla que muestra las versiones de archivos binarios, paquetes, cuánta memoria se consume en millones de máquinas. En cada host, se realiza un PS una vez por hora y se envía a Scuba.
- Todos los dmesg, todos los volcados de memoria, se envían a otras tablas. Ejecutamos Perf una vez cada 10 minutos en cada máquina, por lo que sabemos qué rastros de pila tenemos en el núcleo y qué puede cargar la CPU global.
Depuración PHP
Scuba también proporciona un back-end para nuestra herramienta principal de depuración de PHP. Miles de ingenieros escriben código PHP, y de alguna manera necesitas salvar el repositorio global de cosas malas.¿Como funciona? PHP también escribe un seguimiento de pila en cada registro. Scuba (nuestro Elasticsearch) simplemente no puede acomodar el seguimiento de la pila de todos los registros de todas las máquinas. Antes de poner el registro en Scuba, convertimos la traza de la pila a un hash, la muestra por hash y los guardamos solo. Las trazas de la pila se envían a Memcached. Luego, en la herramienta interna, puede extraer un seguimiento de pila específico de Memcached lo suficientemente rápido. Visualización con agrupación hash de registros y seguimientos de pila.Depuramos el código usando el método de coincidencia de patrones : abra Scuba, vea cómo se ve el gráfico de error.
Visualización con agrupación hash de registros y seguimientos de pila.Depuramos el código usando el método de coincidencia de patrones : abra Scuba, vea cómo se ve el gráfico de error.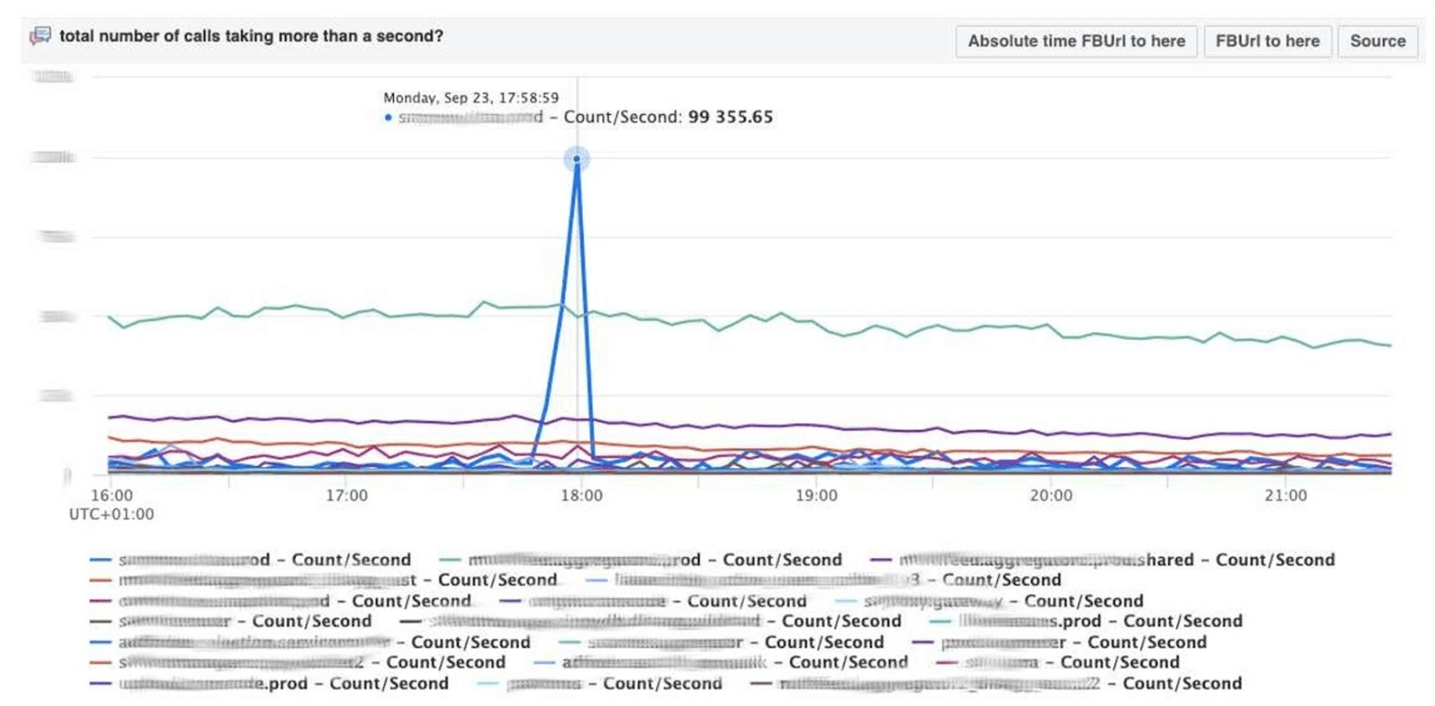 Vamos a LogView, allí los errores ya están agrupados por trazas de pila.
Vamos a LogView, allí los errores ya están agrupados por trazas de pila. Se carga un seguimiento de pila desde Memcached, y en él ya puede encontrar diff (commit en el repositorio de PHP), que se publicó aproximadamente al mismo tiempo, y revertirlo. Cualquiera puede retroceder y comprometerse con nosotros, no se necesitan permisos para esto.
Se carga un seguimiento de pila desde Memcached, y en él ya puede encontrar diff (commit en el repositorio de PHP), que se publicó aproximadamente al mismo tiempo, y revertirlo. Cualquiera puede retroceder y comprometerse con nosotros, no se necesitan permisos para esto.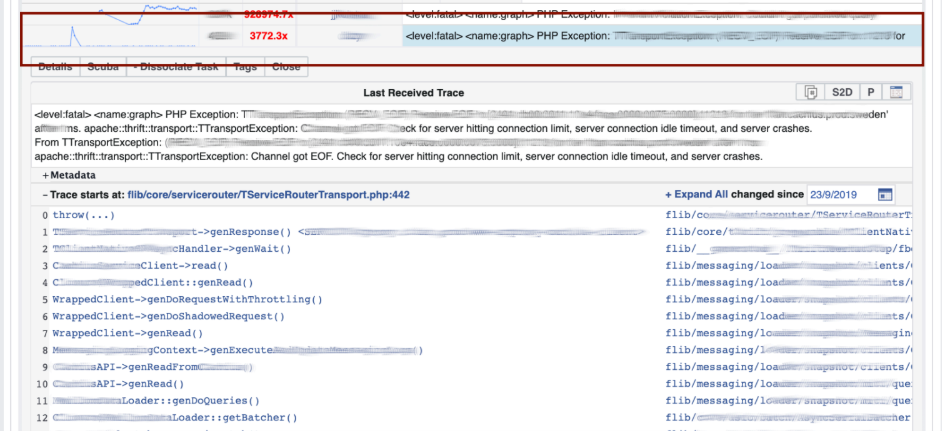
Tableros
Terminaré el tema de monitoreo con paneles. Tenemos pocos de ellos, solo dos de cada tres indicadores. El tablero en sí es bastante inusual. Me gustaría hablar más sobre él. A continuación se muestra un panel estándar con un conjunto de gráficos.Desafortunadamente, no es tan simple con él. El hecho es que la línea púrpura en un gráfico es el mismo servicio al que corresponde la línea azul en otro gráfico, y otro gráfico puede estar en un día y otro en un mes.Utilizamos nuestro panel de control basado en el cubismo , la biblioteca JS de código abierto. Fue escrito en Square y lanzado bajo la licencia Apache. Tienen soporte incorporado para grafito y cubo. Pero es fácil de expandir, lo que hemos hecho.El tablero a continuación muestra un día a un píxel por minuto. Cada línea es una región: centros de datos que están cerca. Muestran el número de registros que el backend de Facebook escribe en bytes por segundo. A continuación hay anotaciones para que los equipos en Estados Unidos vean lo que ya hemos solucionado de lo que sucedió durante el día. Es fácil buscar correlación en esta imagen.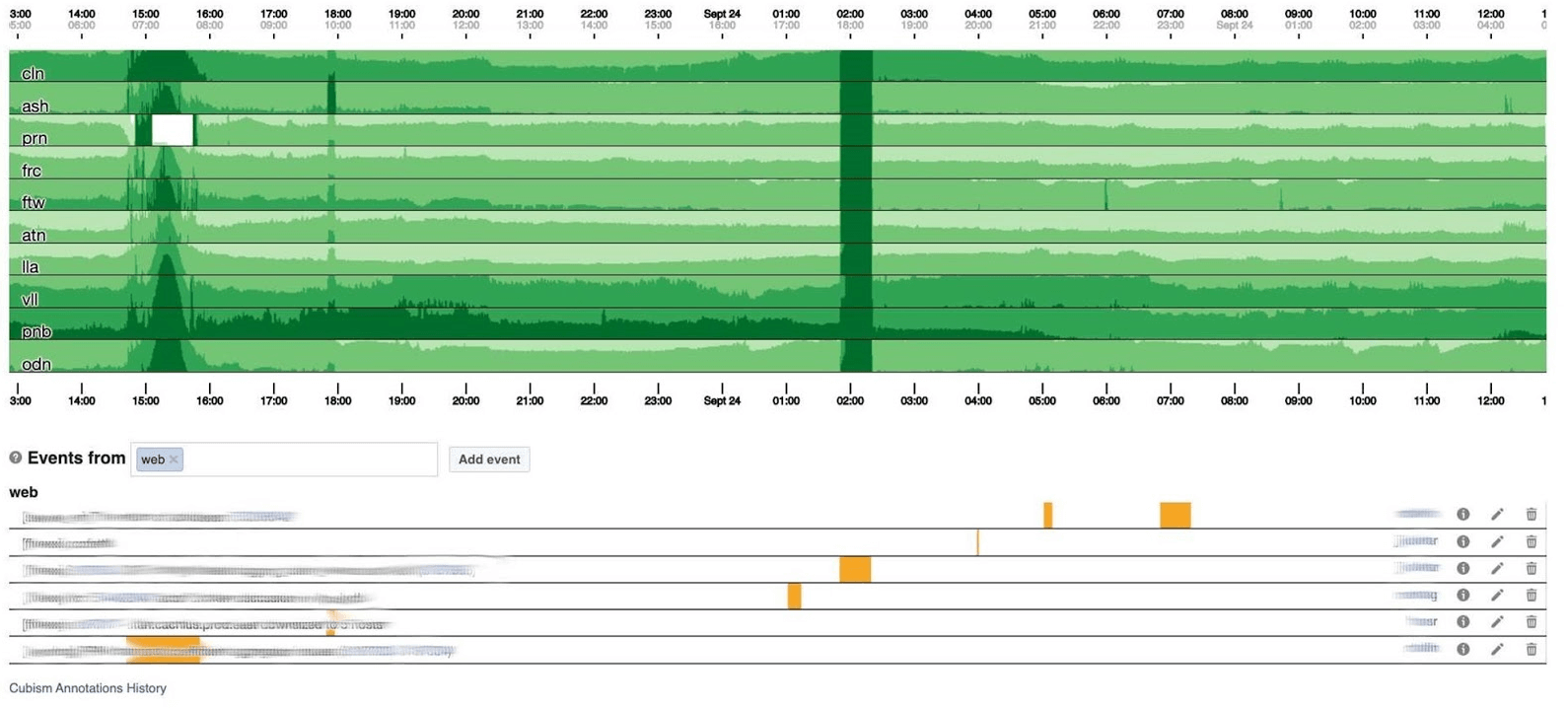 A continuación se muestra el número de errores 500. Lo que a la izquierda no les importaba a los usuarios, y obviamente no les gustaba la franja verde oscuro en el centro.
A continuación se muestra el número de errores 500. Lo que a la izquierda no les importaba a los usuarios, y obviamente no les gustaba la franja verde oscuro en el centro.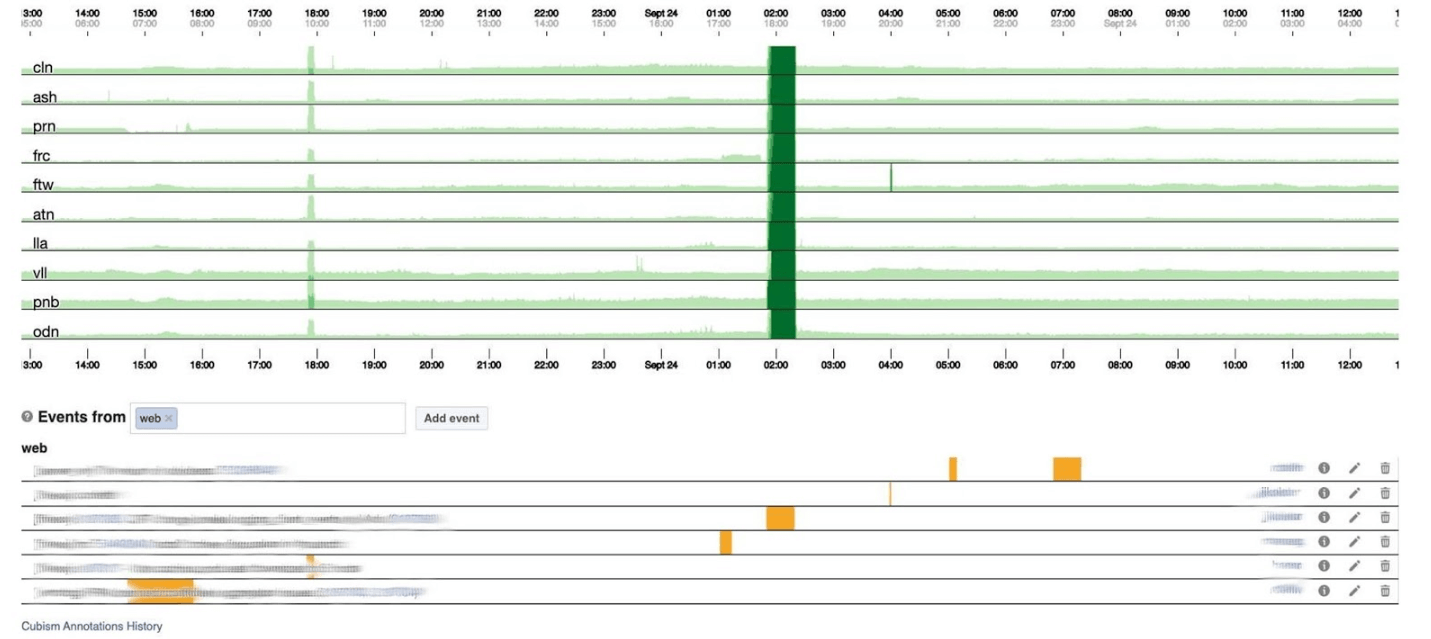 El siguiente es el 99% de latencia. Al mismo tiempo, como en el cuadro anterior, se puede ver que la latencia bajó. Para devolver un error, no es necesario pasar mucho tiempo.
El siguiente es el 99% de latencia. Al mismo tiempo, como en el cuadro anterior, se puede ver que la latencia bajó. Para devolver un error, no es necesario pasar mucho tiempo.
Cómo funciona
En un gráfico de 120 píxeles de altura, todo es visible. Pero muchos de estos no se pueden colocar en un tablero de instrumentos, por lo que nos exprimiremos hasta 30. Desafortunadamente, obtenemos algún tipo de boa constrictor. Volvamos y veamos qué hace el cubismo con él. Rompe el gráfico en 4 partes: cuanto más alto, más oscuro, y luego se derrumba.
Desafortunadamente, obtenemos algún tipo de boa constrictor. Volvamos y veamos qué hace el cubismo con él. Rompe el gráfico en 4 partes: cuanto más alto, más oscuro, y luego se derrumba. Ahora tenemos el mismo horario que antes, pero todo es claramente visible: cuanto más oscuro es el verde, peor. Ahora está mucho más claro lo que está sucediendo.A la izquierda puedes ver la ola mientras se eleva, y en el centro, donde es de color verde oscuro, todo está muy mal.
Ahora tenemos el mismo horario que antes, pero todo es claramente visible: cuanto más oscuro es el verde, peor. Ahora está mucho más claro lo que está sucediendo.A la izquierda puedes ver la ola mientras se eleva, y en el centro, donde es de color verde oscuro, todo está muy mal.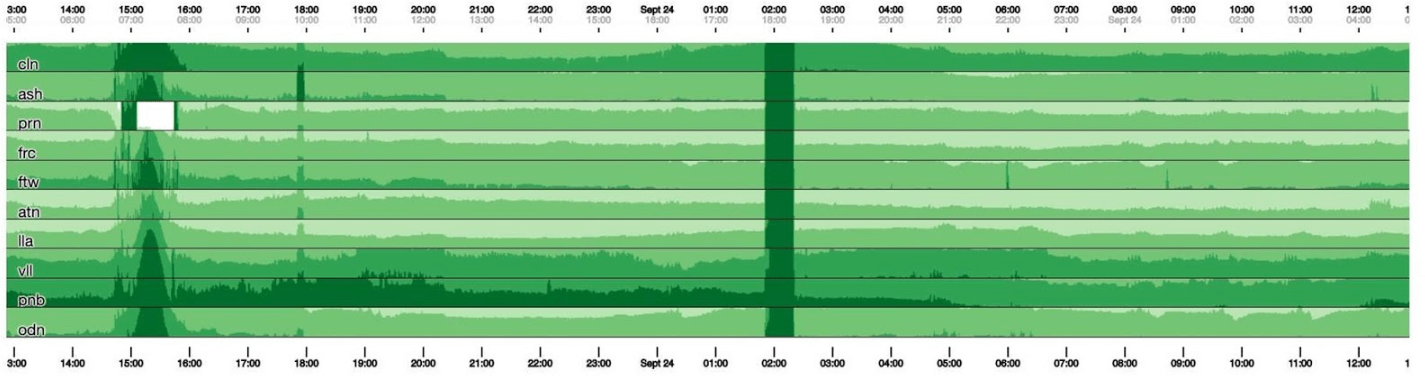 El cubismo es solo el comienzo. Es necesario para la visualización, para comprender si todo está mal ahora o no. Para cada tabla, ya hay paneles con gráficos detallados.
El cubismo es solo el comienzo. Es necesario para la visualización, para comprender si todo está mal ahora o no. Para cada tabla, ya hay paneles con gráficos detallados. El monitoreo por sí solo ayuda a comprender el estado del sistema y responder si se rompe. En Facebook, cada empleado de la llamada debe poder reparar todo. Si se quema intensamente, todo se enciende, pero especialmente los ingenieros de producción con la experiencia de un administrador de sistemas, porque saben cómo resolver el problema rápidamente.
El monitoreo por sí solo ayuda a comprender el estado del sistema y responder si se rompe. En Facebook, cada empleado de la llamada debe poder reparar todo. Si se quema intensamente, todo se enciende, pero especialmente los ingenieros de producción con la experiencia de un administrador de sistemas, porque saben cómo resolver el problema rápidamente.Cuando Facebook yacía
A veces ocurren incidentes y Facebook miente. Por lo general, la gente piensa que Facebook está mintiendo debido a ataques DDoS o hackers, pero en 5 años nunca ha sucedido. La razón siempre ha sido nuestros ingenieros. No son a propósito: los sistemas son muy complejos y pueden descomponerse donde no espera.Damos nombres a todos los incidentes importantes para que sea conveniente mencionarlos y contarles a los recién llegados sobre ellos para no repetir errores en el futuro. El campeón con el nombre más divertido es el incidente de Call the Cops . La gente llamó a la policía de Los Ángeles y pidió arreglar Facebook porque estaba mintiendo. El Sheriff de Los Ángeles estaba tan harto de eso que tuiteó: "¡Por favor no nos llames!" ¡No somos responsables de esto! " Mi incidente favorito en el que participé se llamó CAPSLOCK.. Es interesante porque muestra que cualquier cosa puede suceder. Y esto es lo que sucedió. Se obychnyyIP dirección:
Mi incidente favorito en el que participé se llamó CAPSLOCK.. Es interesante porque muestra que cualquier cosa puede suceder. Y esto es lo que sucedió. Se obychnyyIP dirección: fd3b:5679:92eb:9ce4::1.Facebook usa Chef para personalizar el sistema operativo. Service Inventory almacena la configuración del host en su base de datos y Chef recibe un archivo de configuración del servicio. Una vez que el servicio cambió su versión, comenzó a leer las direcciones IP de la base de datos inmediatamente en formato MySQL y las puso en un archivo. La nueva dirección se escribe ahora en la capital: FD3B:5679:92EB:9CE4::1.Shef mira el nuevo archivo y ve que la dirección IP ha "cambiado" porque se compara, no en forma binaria, sino con una cadena. La dirección IP es "nueva", lo que significa que debe bajar la interfaz y subirla. En todos los millones de automóviles en 15 minutos, la interfaz se fue arriba y abajo.Parece que está bien: la capacidad disminuyó mientras la red se encontraba en algunas máquinas. Pero de repente se abrió un error en el controlador de red de nuestras tarjetas de red personalizadas: al inicio, requerían 0,5 GB de memoria física secuencial. En las máquinas de caché, esos 0.5 GB desaparecieron mientras bajábamos y subíamos la interfaz. Por lo tanto, en las máquinas de caché, la interfaz de red se cayó y no aumentó, y nada funciona sin cachés. Nos sentamos y reiniciamos estas máquinas con nuestras manos. Fue divertido.Portal del administrador de incidentes
Cuando Facebook "arde", es necesario organizar el trabajo de la "brigada de bomberos" y, lo más importante, comprender dónde arde, porque en una gran empresa puede "oler a quemado" en un lugar, pero el problema estará en otro. La herramienta de interfaz de usuario llamada Incident Manager Portal nos ayuda con esto . Fue escrito por ingenieros de producción y está abierto a todos. Tan pronto como sucede algo, comenzamos un incidente allí: nombre, comienzo, descripción.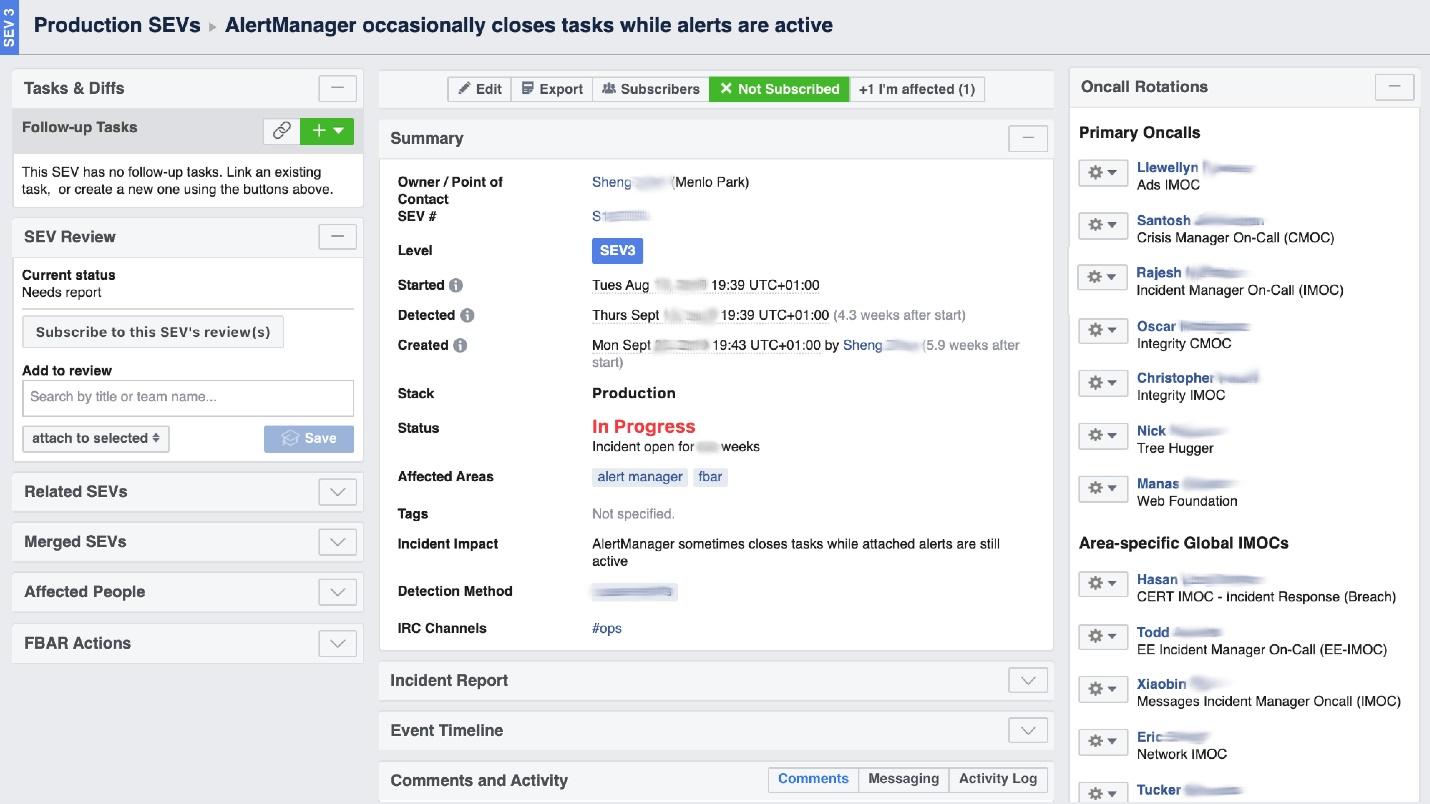 Tenemos una persona especialmente capacitada: Administrador de incidentes de guardia (IMOC). Esta no es una posición permanente; los gerentes cambian regularmente. En caso de grandes incendios, el IMOC organiza y coordina a las personas para su reparación, pero no tiene que repararlo ellos mismos. Tan pronto como se crea un incidente con un alto nivel de peligro, IMOC recibe SMS y comienza a ayudar a organizar todo. En un sistema grande, no se puede prescindir de esas personas.
Tenemos una persona especialmente capacitada: Administrador de incidentes de guardia (IMOC). Esta no es una posición permanente; los gerentes cambian regularmente. En caso de grandes incendios, el IMOC organiza y coordina a las personas para su reparación, pero no tiene que repararlo ellos mismos. Tan pronto como se crea un incidente con un alto nivel de peligro, IMOC recibe SMS y comienza a ayudar a organizar todo. En un sistema grande, no se puede prescindir de esas personas.Prevención
Facebook no es tan común. La mayoría de las veces no apagamos incendios y no reiniciamos las máquinas de caché, pero arreglamos los errores de antemano y, si es posible, para todos a la vez.Una vez que encontramos y solucionamos el "problema de la cola". El número de solicitudes aumenta en un 50% y los errores en un 100%, porque nadie estrangula por adelantado, especialmente en servicios pequeños.Descubrimos un ejemplo de varios servicios y definimos aproximadamente un modelo de comportamiento.- Bajo carga normal, la solicitud llega, se procesa y se devuelve al cliente.
- Con una carga alta, las solicitudes están esperando en una cola porque todos los subprocesos para procesar solicitudes están ocupados. La demora está aumentando, pero hasta ahora todo está bien.
- La línea está creciendo, la carga está aumentando. En algún momento, todo lo que el servidor ejecuta en el cliente termina con un tiempo de espera de respuesta y el cliente se cae con un error. En este punto, el resultado del servidor simplemente puede desecharse.
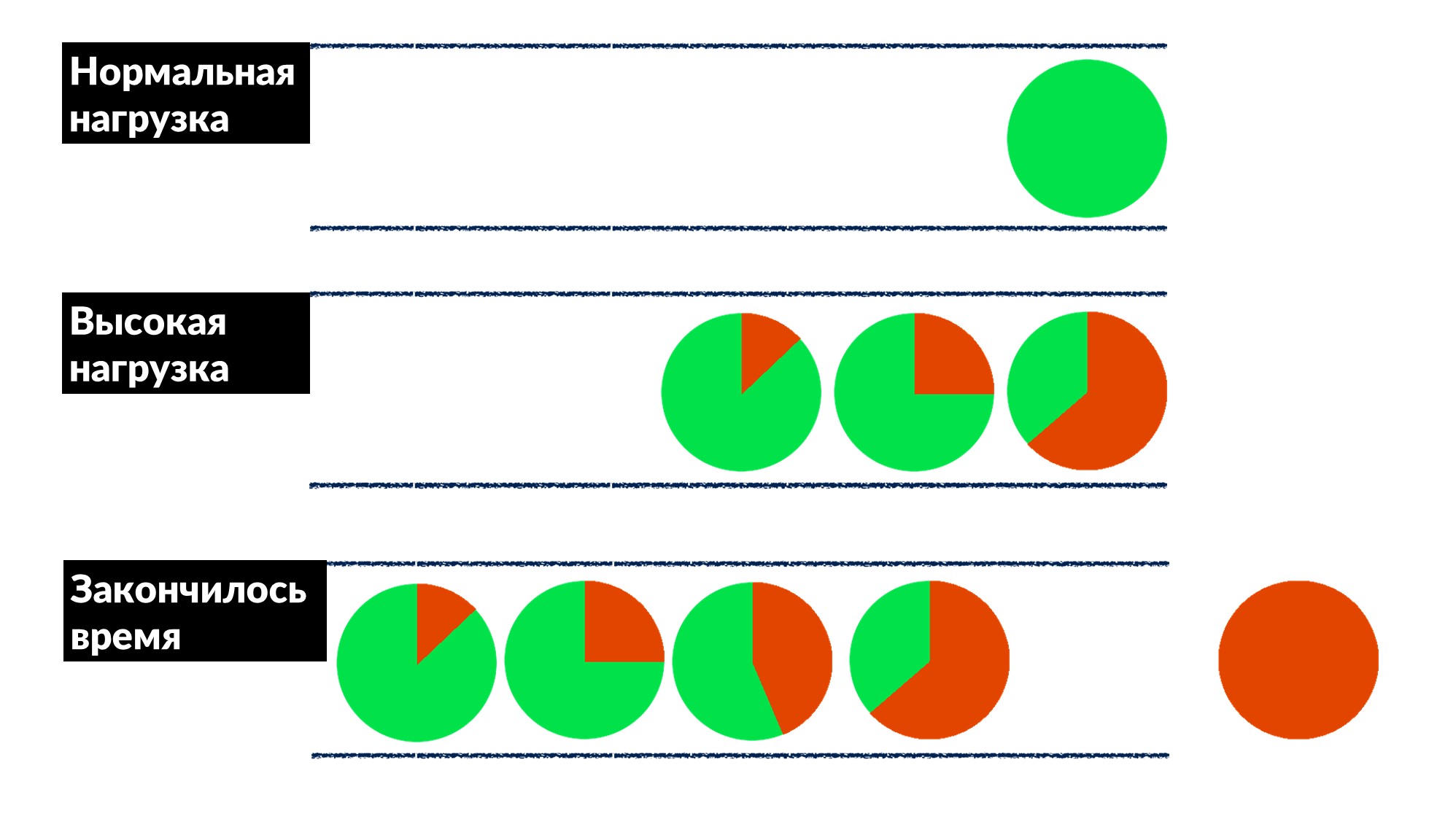 El tiempo de espera del cliente se resalta en rojo.¡Y el cliente repite de nuevo! Resulta que todas las solicitudes que ejecutamos se tiran a la basura y ya nadie las necesita.¿Cómo resolver este problema para todos a la vez? Introduzca un límite en el tiempo de espera en la cola. Si la solicitud está en la cola más de lo esperado, la descartamos y no la procesamos en el servidor, no desperdiciamos CPU en ella. Obtenemos un juego honesto: desechamos todo lo que no podemos procesar y todo lo que podemos procesar.La restricción hizo posible, mientras aumentaba la carga en un 50% por encima del máximo, procesar el 66% de las solicitudes y recibir solo el 33% de los errores. Los desarrolladores del marco para Dispatch implementaron esto en el lado del servidor, y nosotros, los ingenieros de producción, resolvimos suavemente el tiempo de espera de 100 ms en la cola para todos. Por lo tanto, todos los servicios obtuvieron inmediatamente una aceleración básica barata.
El tiempo de espera del cliente se resalta en rojo.¡Y el cliente repite de nuevo! Resulta que todas las solicitudes que ejecutamos se tiran a la basura y ya nadie las necesita.¿Cómo resolver este problema para todos a la vez? Introduzca un límite en el tiempo de espera en la cola. Si la solicitud está en la cola más de lo esperado, la descartamos y no la procesamos en el servidor, no desperdiciamos CPU en ella. Obtenemos un juego honesto: desechamos todo lo que no podemos procesar y todo lo que podemos procesar.La restricción hizo posible, mientras aumentaba la carga en un 50% por encima del máximo, procesar el 66% de las solicitudes y recibir solo el 33% de los errores. Los desarrolladores del marco para Dispatch implementaron esto en el lado del servidor, y nosotros, los ingenieros de producción, resolvimos suavemente el tiempo de espera de 100 ms en la cola para todos. Por lo tanto, todos los servicios obtuvieron inmediatamente una aceleración básica barata.Herramientas
La ideología de SRE dice que si tiene una gran flota de automóviles, un montón de servicios y nada que ver con sus manos, entonces necesita automatizar. Por lo tanto, la mitad del tiempo escribimos código y construimos herramientas.- Cubismo integrado en el sistema.
- FBAR es un "caballo de batalla" que viene y repara, por lo que nadie se preocupa por un auto roto. Esta es la tarea principal de la FBAR, pero ahora tiene aún más tareas.
- Coredumper , que escribimos con dos colegas . Supervisa los coredumps en todas las máquinas y los deja caer en un solo lugar junto con los rastros de la pila con toda la información del host: dónde se encuentra, cómo encontrar qué tamaño. Pero lo más importante, los seguimientos de pila son gratuitos, sin iniciar GDB utilizando programas BPF.
Centro
Lo último que hacemos es hablar con las personas, entrevistarlas. Nos parece que esto es muy importante.Una encuesta útil es sobre la fiabilidad. Preguntamos acerca de los servicios que ya se están ejecutando en las citas clave de nuestro cuestionario:"La responsabilidad principal del software del sistema debe ser continuar ejecutándose. La prestación de servicios debe verse como un efecto secundario beneficioso de la operación continua »
Esto significa que el deber principal del sistema es continuar trabajando, y el hecho de que brinde algún tipo de servicio es una ventaja adicional.Las encuestas son solo para servicios medianos, los grandes también entienden. Damos un cuestionario en el que hacemos preguntas básicas sobre arquitectura, SLO, pruebas, por ejemplo.- "¿Qué sucede si su sistema obtiene el 10% de la carga?" Cuando la gente piensa: "¿Pero realmente, qué?" - aparecen ideas y muchos incluso gobiernan sus sistemas. Anteriormente, no lo pensaban, pero después de la pregunta hay una razón.
- "¿Quién es el primero en notar problemas con su servicio, usted o sus usuarios?" Los desarrolladores comienzan a recordar cuándo sucedió esto y: "... Tal vez necesites agregar alertas".
- "¿Cuál es tu mayor dolor en la llamada?" Esto es inusual para los desarrolladores, especialmente para los nuevos. Inmediatamente dicen: “¡Tenemos muchas alertas! Vamos a limpiarlos y eliminar aquellos que no son el caso ".
- "¿Qué tan frecuentes son sus lanzamientos?" Primero recuerdan que lo están lanzando con sus manos, y luego tienen su propia implementación personalizada.
No hay codificación en el cuestionario; está estandarizado y cambia cada seis meses. Este es un documento de dos páginas que ayudamos a completar en 2-3 semanas. Y luego organizamos una reunión de dos horas y encontramos soluciones a muchos dolores. Esta sencilla herramienta funciona bien con nosotros y puede ayudarlo.6-7 Saint HighLoad++, . (, , ).
telegram- . !