En previsión del inicio del curso de Ingeniero de datos, preparamos una traducción de un material pequeño pero interesante.
En este artículo, hablaré sobre cómo Parquet comprime grandes conjuntos de datos en un archivo de huella pequeña, y cómo podemos lograr un ancho de banda que supere con creces el ancho de banda del flujo de E / S mediante concurrencia (subprocesamiento múltiple).Apache Parquet: el mejor en datos de baja entropía
Como puede comprender por la especificación del formato Apache Parquet, contiene varios niveles de codificación que pueden lograr una reducción significativa en el tamaño del archivo, entre los cuales se encuentran:- Codificación (compresión) usando un diccionario (similar a los pandas. Forma categórica de presentar datos, pero los conceptos en sí mismos son diferentes);
- Compresión de páginas de datos (Snappy, Gzip, LZO o Brotli);
- Codificación de la longitud de ejecución (para punteros nulos e índices del diccionario) y empaquetado de bits enteros;
Para mostrarle cómo funciona esto, veamos un conjunto de datos:['banana', 'banana', 'banana', 'banana', 'banana', 'banana',
'banana', 'banana', 'apple', 'apple', 'apple']
Casi todas las implementaciones de Parquet usan el diccionario predeterminado para la compresión. Por lo tanto, los datos codificados son los siguientes:dictionary: ['banana', 'apple']
indices: [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1]
Los índices en el diccionario se comprimen adicionalmente por el algoritmo de codificación de repetición:dictionary: ['banana', 'apple']
indices (RLE): [(8, 0), (3, 1)]
Siguiendo la ruta de retorno, puede restaurar fácilmente la matriz original de cadenas.En mi artículo anterior , creé un conjunto de datos que se comprime muy bien de esta manera. Al trabajar con pyarrow, podemos habilitar y deshabilitar la codificación usando el diccionario (que está habilitado de forma predeterminada) para ver cómo esto afectará el tamaño del archivo:import pyarrow.parquet as pq
pq.write_table(dataset, out_path, use_dictionary=True,
compression='snappy)
Un conjunto de datos que ocupa 1 GB (1024 MB) pandas.DataFrame, con compresión Snappy y compresión usando un diccionario, toma solo 1.436 MB, es decir, incluso se puede escribir en un disquete. Sin compresión usando el diccionario, ocupará 44.4 MB.Lectura concurrente en parquet-cpp usando PyArrow
En la implementación de Apache Parquet en C ++ - parquet-cpp , que pusimos a disposición para Python en PyArrow, se agregó la capacidad de leer columnas en paralelo.Para probar esta característica, instale PyArrow desde conda-forge :conda install pyarrow -c conda-forge
Ahora, al leer el archivo Parquet, puede usar el argumento nthreads:import pyarrow.parquet as pq
table = pq.read_table(file_path, nthreads=4)
Para datos con baja entropía, la descompresión y la decodificación están fuertemente vinculadas al procesador. Dado que C ++ hace todo el trabajo por nosotros, no hay problemas con la simultaneidad de GIL y podemos lograr un aumento significativo en la velocidad. Vea lo que pude lograr al leer un conjunto de datos de 1 GB en un DataFrame de pandas en una computadora portátil de cuatro núcleos (Xeon E3-1505M, NVMe SSD):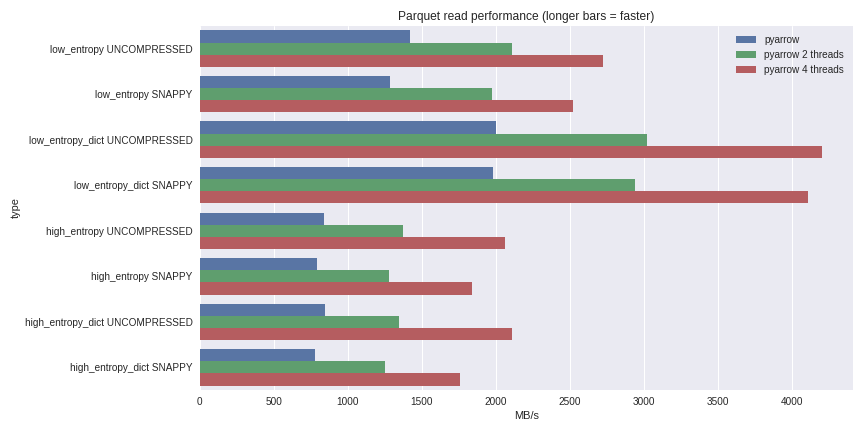 puede ver el escenario completo de evaluación comparativa aquí .He incluido el rendimiento aquí para ambos casos de compresión usando un diccionario y casos sin usar un diccionario. Para los datos con baja entropía, a pesar del hecho de que todos los archivos son pequeños (~ 1.5 MB usando diccionarios y ~ 45 MB sin), la compresión usando un diccionario afecta significativamente el rendimiento. Con 4 hilos, el rendimiento de lectura de pandas aumenta a 4 GB / s. Esto es mucho más rápido que el formato Feather o cualquier otro que conozca.
puede ver el escenario completo de evaluación comparativa aquí .He incluido el rendimiento aquí para ambos casos de compresión usando un diccionario y casos sin usar un diccionario. Para los datos con baja entropía, a pesar del hecho de que todos los archivos son pequeños (~ 1.5 MB usando diccionarios y ~ 45 MB sin), la compresión usando un diccionario afecta significativamente el rendimiento. Con 4 hilos, el rendimiento de lectura de pandas aumenta a 4 GB / s. Esto es mucho más rápido que el formato Feather o cualquier otro que conozca.Conclusión
Con el lanzamiento de la versión 1.0 parquet-cpp (Apache Parquet en C ++), puede ver por sí mismo el mayor rendimiento de E / S que ahora está disponible para los usuarios de Python.Como todos los mecanismos básicos se implementan en C ++, en otros lenguajes (por ejemplo, R), puede crear interfaces para Apache Arrow (estructuras de datos en columnas) y parquet-cpp . Python vinculante es un shell ligero de las bibliotecas principales libarrow y libparquet C ++.Eso es todo. Si desea obtener más información sobre nuestro curso, regístrese para una jornada de puertas abiertas , que se llevará a cabo hoy.