Hola, trabajo en el equipo de proyecto del RRP KP (registro de datos distribuidos para monitorear el ciclo de vida de los juegos de ruedas). Aquí quiero compartir la experiencia de nuestro equipo en el desarrollo de una blockchain corporativa para este proyecto en las condiciones impuestas por la tecnología. En su mayor parte, hablaré sobre Hyperledger Fabric, pero el enfoque descrito aquí se puede extrapolar a cualquier blockchain autorizada. El objetivo final de nuestra investigación es preparar soluciones corporativas de blockchain para que el producto final sea agradable de usar y no demasiado difícil de mantener.No habrá descubrimientos, soluciones inesperadas y no se cubrirán desarrollos únicos aquí (porque no los tengo). Solo quiero compartir mi modesta experiencia, mostrar que "fue posible" y, tal vez, leer sobre las experiencias de otros al tomar decisiones buenas y no tan buenas en los comentarios.Problema: las cadenas de bloques aún no se escalan
Hoy en día, los esfuerzos de muchos desarrolladores tienen como objetivo hacer de blockchain una tecnología realmente conveniente, y no una bomba de tiempo en un envoltorio hermoso. Los canales estatales, el rollup optimista, el plasma y el fragmentación pueden volverse cotidianos. Algún día. O tal vez TON retrasará nuevamente el lanzamiento durante seis meses, y el próximo Grupo de Plasma dejará de existir. Podemos creer en otra hoja de ruta y leer libros blancos brillantes para la noche, pero aquí y ahora tenemos que hacer algo con lo que tenemos. Haz mierda.La tarea establecida para nuestro equipo en el proyecto actual se ve así en general: hay muchas entidades que alcanzan varios miles, que no desean construir relaciones de confianza; Es necesario construir una solución de este tipo en DLT que funcione en PC ordinarias sin requisitos especiales de rendimiento y proporcione una experiencia de usuario no peor que cualquier sistema de contabilidad centralizado. La tecnología subyacente a la solución debería minimizar la posibilidad de manipulación maliciosa de datos; es por eso que la cadena de bloques está aquí.Los lemas de los libros blancos y los medios de comunicación nos prometen que el próximo desarrollo le permitirá realizar millones de transacciones por segundo. ¿Qué es realmente?Mainnet Ethereum ahora se ejecuta a ~ 30 tps. Debido a esto, es difícil percibirlo como una cadena de bloques adecuada para las necesidades corporativas. Entre las soluciones autorizadas, se conocen puntos de referencia que muestran 2000 tps ( Quórum ) o 3000 tps ( Hyperledger Fabric , la publicación es un poco más pequeña, pero debe tener en cuenta que el punto de referencia se realizó en el viejo motor de consenso). Hubo un intento de revisar radicalmente Fabric , que no dio los peores resultados, 20,000 tps, pero hasta ahora esto es solo investigación académica esperando su implementación estable. Es poco probable que una corporación que pueda permitirse el lujo de mantener un departamento de desarrolladores de blockchain tolere tales indicadores. Pero el problema no es solo el rendimiento, también hay latencia.Latencia
El retraso desde el momento en que la transacción se inicia hasta su aprobación final por el sistema depende no solo de la velocidad del mensaje que pasa por todas las etapas de validación y pedido, sino también de los parámetros de la formación del bloque. Incluso si nuestra cadena de bloques nos permite comprometernos a una velocidad de 1,000,000 tps, pero lleva 10 minutos formar un bloque de 488 MB, ¿será más fácil para nosotros?Echemos un vistazo más de cerca al ciclo de vida de la transacción en Hyperledger Fabric para comprender en qué se dedica el tiempo y cómo se relaciona con los parámetros de formación de bloques.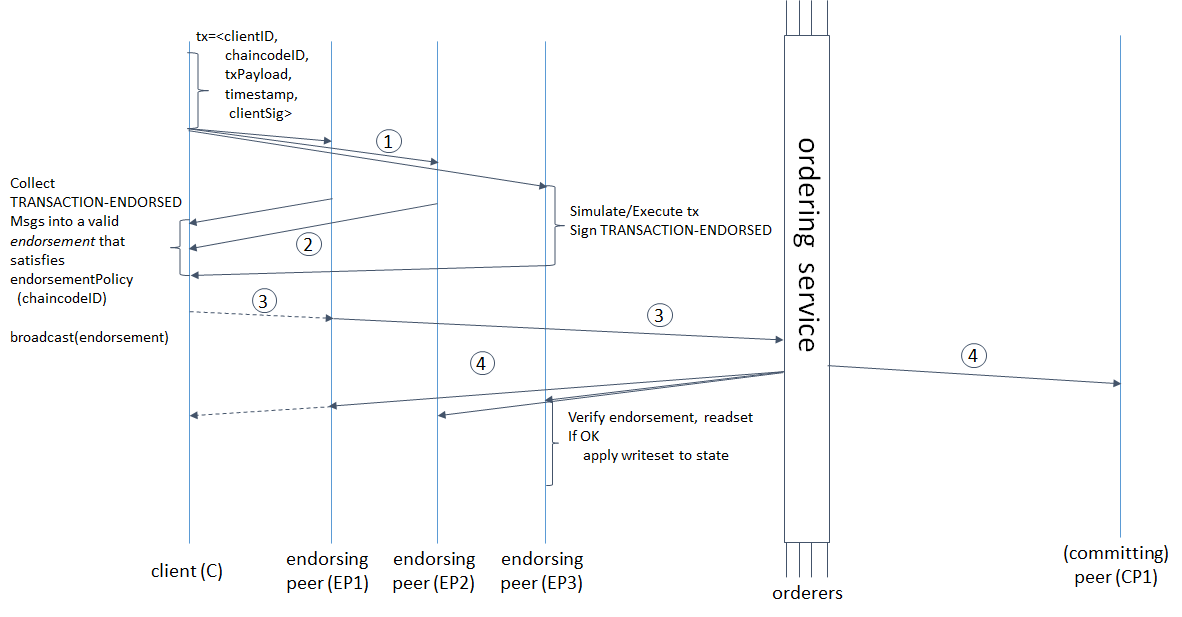 tomado de aquí : hyperledger-fabric.readthedocs.io/en/release-1.4/arch-deep-dive.html#swimlane(1) El cliente genera una transacción, la envía a sus pares de respaldo, este último simula la transacción (aplica los cambios realizados por el chaincode al estado actual, pero no se compromete con el libro mayor) y obtiene RWSet: nombres, versiones y valores clave tomados de la colección en CouchDB, ( 2) los endosantes envían el RWSet firmado al cliente, (3) el cliente verifica las firmas de todos los pares necesarios (endosantes), y luego envía la transacción al servicio de pedidos, o la envía sin verificación (la verificación seguirá teniendo lugar más tarde), el servicio de pedidos formará un bloque y ( 4) envía de vuelta a todos los pares, no solo a los endosantes; los pares comprueban que las versiones clave en el conjunto de lectura coinciden con las versiones en la base de datos, las firmas de todos los endosantes, y finalmente confirman el bloqueo.Pero eso no es todo. Las palabras "la orden forma un bloque" oculta no solo el orden de las transacciones, sino también 3 solicitudes de red consecutivas del líder a los seguidores y viceversa: el líder agrega un mensaje al registro, envía a los seguidores, este último agrega a su registro, envía la confirmación de una replicación exitosa al líder, el líder envía un mensaje , envía una confirmación de confirmación a los seguidores, los seguidores se comprometen. Cuanto menor sea el tamaño y el tiempo de formación del bloque, más a menudo será necesario que el servicio de pedidos establezca un consenso. Hyperledger Fabric tiene dos parámetros de formación de bloque: BatchTimeout - tiempo de formación de bloque y BatchSize - tamaño de bloque (número de transacciones y el tamaño del bloque en bytes). Tan pronto como uno de los parámetros alcanza el límite, se libera un nuevo bloque. Cuantos más nodos de warrant, más tardará. Por lo tanto, debe aumentar BatchTimeout y BatchSize. Pero dado que los RWSets están versionados, cuanto más bloqueamos, mayor es la probabilidad de conflictos MVCC. Además, con un aumento en BatchTimeout, UX es catastróficamente degradante. Me parece razonable y obvio el siguiente esquema para resolver estos problemas.
tomado de aquí : hyperledger-fabric.readthedocs.io/en/release-1.4/arch-deep-dive.html#swimlane(1) El cliente genera una transacción, la envía a sus pares de respaldo, este último simula la transacción (aplica los cambios realizados por el chaincode al estado actual, pero no se compromete con el libro mayor) y obtiene RWSet: nombres, versiones y valores clave tomados de la colección en CouchDB, ( 2) los endosantes envían el RWSet firmado al cliente, (3) el cliente verifica las firmas de todos los pares necesarios (endosantes), y luego envía la transacción al servicio de pedidos, o la envía sin verificación (la verificación seguirá teniendo lugar más tarde), el servicio de pedidos formará un bloque y ( 4) envía de vuelta a todos los pares, no solo a los endosantes; los pares comprueban que las versiones clave en el conjunto de lectura coinciden con las versiones en la base de datos, las firmas de todos los endosantes, y finalmente confirman el bloqueo.Pero eso no es todo. Las palabras "la orden forma un bloque" oculta no solo el orden de las transacciones, sino también 3 solicitudes de red consecutivas del líder a los seguidores y viceversa: el líder agrega un mensaje al registro, envía a los seguidores, este último agrega a su registro, envía la confirmación de una replicación exitosa al líder, el líder envía un mensaje , envía una confirmación de confirmación a los seguidores, los seguidores se comprometen. Cuanto menor sea el tamaño y el tiempo de formación del bloque, más a menudo será necesario que el servicio de pedidos establezca un consenso. Hyperledger Fabric tiene dos parámetros de formación de bloque: BatchTimeout - tiempo de formación de bloque y BatchSize - tamaño de bloque (número de transacciones y el tamaño del bloque en bytes). Tan pronto como uno de los parámetros alcanza el límite, se libera un nuevo bloque. Cuantos más nodos de warrant, más tardará. Por lo tanto, debe aumentar BatchTimeout y BatchSize. Pero dado que los RWSets están versionados, cuanto más bloqueamos, mayor es la probabilidad de conflictos MVCC. Además, con un aumento en BatchTimeout, UX es catastróficamente degradante. Me parece razonable y obvio el siguiente esquema para resolver estos problemas.Evite esperar la finalización del bloque y no pierda la capacidad de rastrear el estado de la transacción
Cuanto mayor sea el tiempo de formación y el tamaño del bloque, mayor será el rendimiento de la cadena de bloques. Uno de los otros no sigue directamente, pero debe recordarse que la creación de consenso en RAFT requiere tres solicitudes de red del líder a los seguidores y viceversa. Cuantos más nodos de orden, más tiempo llevará. Cuanto menor es el tamaño y el tiempo de formación del bloque, más interacciones tienen. ¿Cómo aumentar el tiempo de formación y el tamaño del bloque sin aumentar el tiempo de espera para una respuesta del sistema para el usuario final?En primer lugar, debe resolver de alguna manera los conflictos MVCC causados por un gran tamaño de bloque, que puede incluir diferentes RWSets con la misma versión. Obviamente, en el lado del cliente (en relación con la red blockchain, este puede ser el backend, y lo digo en serio), necesita un controlador de conflictos MVCC, que puede ser un servicio separado o un decorador regular a través de una llamada de activación de transacción con lógica de reintento.El reintento se puede implementar con una estrategia exponencial, pero luego la latencia se degradará de la misma manera. Por lo tanto, debe utilizar un reintento aleatorio dentro de ciertos límites pequeños o uno permanente. Con un ojo en posibles conflictos en la primera realización.El siguiente paso es hacer que la interacción del cliente con el sistema sea asíncrona para que no espere 15, 30 o 10,000,000 segundos, lo que configuraremos como BatchTimeout. Pero al mismo tiempo, debe guardar la oportunidad para asegurarse de que los cambios iniciados por la transacción estén escritos / no escritos en la cadena de bloques.Puede usar una base de datos para almacenar el estado de la transacción. La opción más fácil es CouchDB debido a su facilidad de uso: la base de datos tiene una interfaz de usuario lista para usar, una API REST, y puede configurar fácilmente la replicación y el fragmentación para ella. Puede crear solo una colección separada en la misma instancia de CouchDB que Fabric usa para almacenar su estado mundial. Necesitamos almacenar documentos de este tipo.{
Status string
TxID: string
Error: string
}
Este documento se escribe en la base de datos antes de que la transacción se transfiera a sus pares, se devuelve una identificación de entidad al usuario (se usa la misma ID como clave) si se trata de una operación para crear algo, y luego los campos Estado, TxID y Error se actualizan a medida que se recibe información relevante de los pares. En este esquema, el usuario no espera a que finalmente se forme el bloque, observa la rueda giratoria en la pantalla durante 10 segundos, recibe una respuesta instantánea del sistema y continúa trabajando.Elegimos BoltDB para almacenar estados de transacciones, porque necesitamos ahorrar memoria y no queremos perder tiempo en la interacción de la red con un servidor de base de datos independiente, especialmente cuando esta interacción se lleva a cabo utilizando el protocolo de texto sin formato. Por cierto, utiliza CouchDB para implementar el esquema descrito anteriormente o simplemente para almacenar el estado mundial, en cualquier caso, tiene sentido optimizar la forma en que se almacenan los datos en CouchDB. De forma predeterminada, en CouchDB, el tamaño de los nodos del árbol b es de 1279 bytes, que es mucho más pequeño que el tamaño del sector en el disco, lo que significa que tanto la lectura como el reequilibrio del árbol requerirán más acceso físico al disco. El tamaño óptimo cumple con el estándar de formato avanzado y es de 4 kilobytes. Para la optimización, necesitamos establecer el parámetro btree_chunk_size en 4096en el archivo de configuración CouchDB. Para BoltDB, dicha intervención manual no es necesaria .
En este esquema, el usuario no espera a que finalmente se forme el bloque, observa la rueda giratoria en la pantalla durante 10 segundos, recibe una respuesta instantánea del sistema y continúa trabajando.Elegimos BoltDB para almacenar estados de transacciones, porque necesitamos ahorrar memoria y no queremos perder tiempo en la interacción de la red con un servidor de base de datos independiente, especialmente cuando esta interacción se lleva a cabo utilizando el protocolo de texto sin formato. Por cierto, utiliza CouchDB para implementar el esquema descrito anteriormente o simplemente para almacenar el estado mundial, en cualquier caso, tiene sentido optimizar la forma en que se almacenan los datos en CouchDB. De forma predeterminada, en CouchDB, el tamaño de los nodos del árbol b es de 1279 bytes, que es mucho más pequeño que el tamaño del sector en el disco, lo que significa que tanto la lectura como el reequilibrio del árbol requerirán más acceso físico al disco. El tamaño óptimo cumple con el estándar de formato avanzado y es de 4 kilobytes. Para la optimización, necesitamos establecer el parámetro btree_chunk_size en 4096en el archivo de configuración CouchDB. Para BoltDB, dicha intervención manual no es necesaria .Contrapresión: estrategia de amortiguación
Pero puede haber muchos mensajes. Más de lo que el sistema es capaz de procesar, compartir recursos con una docena de otros servicios además de los que se muestran en el diagrama, y todo esto debería funcionar sin fallas, incluso en máquinas en las que el lanzamiento de Intellij Idea será extremadamente tedioso.El problema de los diferentes rendimientos de los sistemas de comunicación, productor y consumidor, se resuelve de diferentes maneras. Veamos que podemos hacer.Descarte : podemos afirmar que no podemos procesar más de X transacciones en T segundos. Todas las solicitudes que exceden este límite se restablecen. Es bastante simple, pero luego puedes olvidarte de UX.Controlador: el consumidor debe tener alguna interfaz a través de la cual, dependiendo de la carga, podrá controlar los tps del productor. No está mal, pero impone obligaciones a los desarrolladores del cliente que crean la carga para implementar esta interfaz. Para nosotros, esto es inaceptable, ya que la cadena de bloques en el futuro se integrará en una gran cantidad de sistemas existentes.Almacenamiento en búfer: en lugar de idear resistir el flujo de datos de entrada, podemos almacenar en búfer este flujo y procesarlo a la velocidad requerida. Obviamente, esta es la mejor solución si queremos proporcionar una buena experiencia de usuario. Implementamos el buffer usando la cola en RabbitMQ. Se agregaron dos nuevas acciones al esquema: (1) después de recibir la solicitud de la API, se pone en cola un mensaje con los parámetros necesarios para llamar a la transacción, y el cliente recibe un mensaje de que la transacción fue aceptada por el sistema, (2) el backend lee los datos con la velocidad especificada en la configuración de la cola inicia una transacción y actualiza los datos en el almacén de estado.Ahora puede aumentar el tiempo de formación y la capacidad de bloqueo tanto como desee, ocultando retrasos al usuario.
Se agregaron dos nuevas acciones al esquema: (1) después de recibir la solicitud de la API, se pone en cola un mensaje con los parámetros necesarios para llamar a la transacción, y el cliente recibe un mensaje de que la transacción fue aceptada por el sistema, (2) el backend lee los datos con la velocidad especificada en la configuración de la cola inicia una transacción y actualiza los datos en el almacén de estado.Ahora puede aumentar el tiempo de formación y la capacidad de bloqueo tanto como desee, ocultando retrasos al usuario.Otras herramientas
Aquí no se dijo nada sobre el chaincode, porque, como regla, no hay nada que optimizar en él. Chaincode debe ser lo más simple y seguro posible, eso es todo lo que se requiere de él. Cheynkod escribir de forma simple y segura nos ayuda a crear un gran marco SSKit de S7 Techlab y un analizador estático Revive ^ CC .Además, nuestro equipo está desarrollando un conjunto de utilidades para hacer que trabajar con Fabric sea simple y agradable: un explorador de blockchain , una utilidad para cambiar automáticamente la configuración de red (agregar / eliminar organizaciones, nodos RAFT), una utilidad para revocar certificados y eliminar identidad . Si quieres contribuir, bienvenido.Conclusión
Este enfoque facilita la sustitución de Hyperledger Fabric con Quorum, otras redes privadas de Ethereum (PoA o incluso PoW), reducen significativamente el ancho de banda real, pero al mismo tiempo mantienen una UX normal (tanto para los usuarios en el navegador como para los sistemas integrados). Al reemplazar Fabric con Ethereum en el esquema, solo necesitará cambiar la lógica del servicio / decorador de reintento para procesar conflictos MVCC al nonce de incremento atómico y reenvío. El almacenamiento en búfer y el estado permitió desacoplar el tiempo de respuesta del tiempo de formación del bloque. Ahora puede agregar miles de nodos de pedido y no tener miedo de que los bloques se formen con demasiada frecuencia y cargar el servicio de pedidos.En general, eso es todo lo que quería compartir. Me alegraría si esto ayuda a alguien en su trabajo.