Nota perev. : En este artículo, Banzai Cloud comparte un ejemplo del uso de sus utilidades especiales para facilitar la operación de Kafka dentro de Kubernetes. Estas instrucciones ilustran cómo puede determinar el tamaño óptimo de infraestructura y configurar Kafka para lograr el rendimiento requerido. Apache Kafka es una plataforma de transmisión distribuida para crear sistemas de transmisión en tiempo real confiables, escalables y de alto rendimiento. Sus características impresionantes se pueden ampliar con Kubernetes. Para hacer esto, desarrollamos el operador Kafka Open Source y una herramienta llamada Supertubes. Le permiten ejecutar Kafka en Kubernetes y usar sus diversas funciones, como ajustar la configuración del agente, escalar en función de métricas con reequilibrio, reconocimiento de rack (conocimiento de recursos de hardware), actualizaciones "suaves" (elegantes) , etc.
Apache Kafka es una plataforma de transmisión distribuida para crear sistemas de transmisión en tiempo real confiables, escalables y de alto rendimiento. Sus características impresionantes se pueden ampliar con Kubernetes. Para hacer esto, desarrollamos el operador Kafka Open Source y una herramienta llamada Supertubes. Le permiten ejecutar Kafka en Kubernetes y usar sus diversas funciones, como ajustar la configuración del agente, escalar en función de métricas con reequilibrio, reconocimiento de rack (conocimiento de recursos de hardware), actualizaciones "suaves" (elegantes) , etc.Prueba Supertubes en tu clúster:
curl https://getsupertubes.sh | sh supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>
O consulte la documentación . También puede leer sobre algunas de las características de Kafka, que están automatizadas con la ayuda de Supertubes y el operador de Kafka. Ya escribimos sobre ellos en el blog:
Cuando decida implementar un clúster Kafka en Kubernetes, probablemente se encontrará con el problema de determinar el tamaño óptimo de la infraestructura subyacente y la necesidad de ajustar la configuración de Kafka para cumplir con los requisitos de ancho de banda. El rendimiento máximo de cada intermediario está determinado por el rendimiento de los componentes de infraestructura en su núcleo, como la memoria, el procesador, la velocidad del disco, el ancho de banda de la red, etc.Idealmente, la configuración del corredor debe ser tal que todos los elementos de la infraestructura se utilicen al máximo de sus capacidades. Sin embargo, en la vida real, esta configuración es muy complicada. Es más probable que los usuarios configuren corredores de manera que maximicen el uso de uno o dos componentes (disco, memoria o procesador). En términos generales, un corredor muestra el máximo rendimiento cuando su configuración le permite utilizar el componente más lento "en su totalidad". Entonces podemos tener una idea aproximada de la carga que puede manejar un corredor.Teóricamente, también podemos estimar el número de corredores necesarios para trabajar con una carga determinada. Sin embargo, en la práctica, hay tantas opciones de configuración en diferentes niveles que es muy difícil (si no imposible) evaluar el rendimiento potencial de una determinada configuración. En otras palabras, es muy difícil planificar la configuración, a partir de un rendimiento determinado.Para los usuarios de Supertubes, usualmente usamos el siguiente enfoque: comenzar con alguna configuración (infraestructura + configuración), luego medir su rendimiento, ajustar la configuración del agente y repetir el proceso nuevamente. Esto sucede hasta que se aprovecha al máximo el potencial del componente de infraestructura más lento.De esta manera, obtenemos una idea más clara de cuántos intermediarios necesita un clúster para hacer frente a una determinada carga (el número de intermediarios también depende de otros factores, como el número mínimo de réplicas de mensajes para garantizar la estabilidad, el número de líderes de partición, etc.). Además, tenemos una idea de qué componente de infraestructura se desea escalar verticalmente.Este artículo discutirá los pasos que tomamos para "exprimir todo" de los componentes más lentos en las configuraciones iniciales y medir el rendimiento del clúster Kafka. Una configuración altamente resistente requiere al menos tres corredores de trabajo (min.insync.replicas=3) espaciados en tres zonas de accesibilidad diferentes. Para configurar, escalar y monitorear la infraestructura de Kubernetes, utilizamos nuestra propia plataforma de administración de contenedores en la nube híbrida: Pipeline . Es compatible con las instalaciones (bare metal, VMware) y cinco tipos de nubes (Alibaba, AWS, Azure, Google, Oracle), así como cualquier combinación de las mismas.Reflexiones sobre la infraestructura y la configuración del clúster Kafka
Para los ejemplos a continuación, seleccionamos AWS como el proveedor de servicios en la nube y EKS como la distribución de Kubernetes. Se puede implementar una configuración similar utilizando PKE , una distribución de Kubernetes de Banzai Cloud, certificada por CNCF.Disco
Amazon ofrece varios tipos de volúmenes EBS . Los SSD son la base de gp2 y io1 , sin embargo, para garantizar un alto rendimiento, gp2 consume préstamos acumulados (créditos de E / S) , por lo tanto, preferimos el tipo io1 , que ofrece un alto rendimiento estable.Tipos de instancia
El rendimiento de Kafka depende en gran medida de la memoria caché de página del sistema operativo, por lo que necesitamos instancias con suficiente memoria para intermediarios (JVM) y memoria caché de página. Instance c5.2xlarge es un buen comienzo, ya que tiene 16 GB de memoria y está optimizado para trabajar con EBS . Su desventaja es que puede proporcionar el máximo rendimiento durante no más de 30 minutos cada 24 horas. Si su carga de trabajo requiere un rendimiento máximo durante un período de tiempo más largo, observe otros tipos de instancias. Hicimos exactamente eso, deteniéndonos en c5.4xlarge . Proporciona un rendimiento máximo de 593,75 Mb / s.. El rendimiento máximo del volumen EBS io1 es mayor que el de la instancia de c5.4xlarge , por lo que el elemento de infraestructura más lento es probablemente el rendimiento de E / S de este tipo de instancia (que también debe confirmarse con los resultados de nuestras pruebas de carga).Red
El ancho de banda de la red debe ser bastante grande en comparación con el rendimiento de la instancia de VM y el disco, de lo contrario, la red se convierte en un cuello de botella. En nuestro caso, la interfaz de red c5.4xlarge admite velocidades de hasta 10 Gb / s, que es significativamente mayor que el ancho de banda de la instancia de E / S de la VM.Despliegue de corredor
Los corredores deben implementarse (planeado en Kubernetes) en nodos dedicados para evitar la competencia con otros procesos por recursos de procesador, memoria, red y disco.Versión Java
La elección lógica es Java 11, porque es compatible con Docker en el sentido de que la JVM determina correctamente los procesadores y la memoria disponibles para el contenedor en el que se ejecuta el intermediario. Sabiendo que los límites del procesador son importantes, JVM establece interna y transparentemente el número de subprocesos GC y subprocesos del compilador JIT. Utilizamos una imagen de Kafka banzaicloud/kafka:2.13-2.4.0que incluye Kafka versión 2.4.0 (Scala 2.13) en Java 11.Si desea obtener más información sobre Java / JVM en Kubernetes, consulte nuestras publicaciones siguientes:
Configuración de memoria del agente
Hay dos aspectos clave para configurar la memoria del corredor: la configuración para la JVM y para el pod Kubernetes. El límite de memoria establecido para el pod debe ser mayor que el tamaño de almacenamiento dinámico máximo para que la JVM tenga suficiente espacio para el metaespacio de Java en su propia memoria y para la caché de páginas del sistema operativo que Kafka está utilizando activamente. En nuestras pruebas, ejecutamos corredores Kafka con parámetros -Xmx4G -Xms2G, y el límite de memoria para el pod era 10 Gi. Tenga en cuenta que la configuración de memoria para la JVM se puede obtener automáticamente usando -XX:MaxRAMPercentagey -X:MinRAMPercentage, según el límite de memoria para el pod.Configuración del procesador de intermediario
En términos generales, puede aumentar la productividad al aumentar la concurrencia al aumentar el número de hilos utilizados por Kafka. Cuantos más procesadores estén disponibles para Kafka, mejor. En nuestra prueba, comenzamos con un límite de 6 procesadores y gradualmente (iteramos) aumentamos su número a 15. Además, configuramos num.network.threads=12la configuración del agente para aumentar la cantidad de transmisiones que reciben datos de la red y los envían. Habiendo descubierto de inmediato que los corredores seguidores no pueden recibir réplicas lo suficientemente rápido, aumentaron num.replica.fetchersa 4 para aumentar la velocidad con la que los corredores seguidores replicaron los mensajes de los líderes.Herramienta de generación de carga
Asegúrese de que el potencial del generador de carga seleccionado no se agote antes de que el clúster Kafka (cuyo punto de referencia se está ejecutando) alcance su carga máxima. En otras palabras, es necesario realizar una evaluación preliminar de las capacidades de la herramienta de generación de carga, así como seleccionar tipos de instancias para ella con un número suficiente de procesadores y memoria. En este caso, nuestra herramienta producirá más carga de la que el clúster Kafka puede digerir. Después de muchos experimentos, nos decidimos por tres copias de c5.4xlarge , en cada una de las cuales se lanzó el generador.Benchmarking
La medición del rendimiento es un proceso iterativo que incluye los siguientes pasos:- configuración de infraestructura (clúster EKS, clúster Kafka, herramienta de generación de carga, así como Prometheus y Grafana);
- generación de carga durante un cierto período para filtrar desviaciones aleatorias en los indicadores de rendimiento recopilados;
- afinar la infraestructura y la configuración del agente en función de los indicadores de rendimiento observados;
- repitiendo el proceso hasta alcanzar el nivel requerido de ancho de banda del clúster Kafka. Al mismo tiempo, debe ser establemente reproducible y demostrar variaciones mínimas de ancho de banda.
La siguiente sección describe los pasos que se realizaron durante el clúster de prueba de referencia.Herramientas
Las siguientes herramientas se utilizaron para implementar rápidamente la configuración básica, la generación de carga y la medición del rendimiento:- Banzai Cloud Pipeline EKS Amazon c Prometheus ( Kafka ) Grafana ( ). Pipeline , , , , , .
- Sangrenel — Kafka.
- Grafana Kafka : Kubernetes Kafka, Node Exporter.
- Supertubes CLI para la forma más fácil de configurar un clúster de Kafka en Kubernetes. Zookeeper, el operador Kafka, Envoy y muchos otros componentes están instalados y configurados correctamente para iniciar el clúster Kafka listo para producción en Kubernetes.
- Para instalar supertubes CLI, use las instrucciones proporcionadas aquí .

EKS Cluster
Prepare un clúster EKS con nodos de trabajo dedicados c5.4xlarge en varias zonas de disponibilidad para pods con intermediarios Kafka, así como nodos dedicados para el generador de carga y la infraestructura de monitoreo.banzai cluster create -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/cluster_eks_202001.json
Cuando el clúster EKS esté operativo, habilite su servicio de monitoreo integrado : implementará Prometheus y Grafana en el clúster.Componentes del sistema Kafka
Instale los componentes del sistema Kafka (Zookeeper, kafka-operator) en el EKS utilizando supertubes CLI:supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>
Kafka Cluster
De manera predeterminada, EKS utiliza volúmenes gp2 EBS , por lo que debe crear una clase de almacenamiento separada basada en volúmenes io1 para el clúster Kafka:kubectl create -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-ssd
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
iopsPerGB: "50"
fsType: ext4
volumeBindingMode: WaitForFirstConsumer
EOF
Establezca un parámetro para intermediarios min.insync.replicas=3e implemente pods de intermediarios en nodos en tres zonas de disponibilidad diferentes:supertubes cluster create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/kafka_202001_3brokers.yaml --wait --timeout 600
Temas
Simultáneamente lanzamos tres instancias del generador de carga. Cada uno de ellos escribe en su propio tema, es decir, todo lo que necesitamos son tres temas:supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest1
spec:
name: perftest1
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest2
spec:
name: perftest2
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest3
spec:
name: perftest3
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
Para cada tema, el factor de replicación es 3: el valor mínimo recomendado para sistemas de producción altamente disponibles.Herramienta de generación de carga
Lanzamos tres instancias del generador de carga (cada una escrita en un tema separado). Para los pods del generador de carga, debe registrar la afinidad de nodos para que se planifiquen solo en los nodos asignados para ellos:apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: loadtest
name: perf-load1
namespace: kafka
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: loadtest
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: loadtest
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nodepool.banzaicloud.io/name
operator: In
values:
- loadgen
containers:
- args:
- -brokers=kafka-0:29092,kafka-1:29092,kafka-2:29092,kafka-3:29092
- -topic=perftest1
- -required-acks=all
- -message-size=512
- -workers=20
image: banzaicloud/perfload:0.1.0-blog
imagePullPolicy: Always
name: sangrenel
resources:
limits:
cpu: 2
memory: 1Gi
requests:
cpu: 2
memory: 1Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
Algunos puntos a tener en cuenta:- El generador de carga genera mensajes de 512 bytes y los publica en Kafka en lotes de 500 mensajes.
-required-acks=all , Kafka. , , , , . (consumers) , , , .- 20 worker' (
-workers=20). worker 5 producer', worker' Kafka. 100 producer', Kafka.
Monitoreo de clúster
Durante las pruebas de estrés del clúster Kafka, también monitoreamos su estado para asegurarnos de que no hubiera reinicios de pod, réplicas fuera de sincronización y rendimiento máximo con fluctuaciones mínimasResultados de la medición
3 corredores, tamaño de mensaje: 512 bytes
Con particiones distribuidas uniformemente en tres corredores, logramos un rendimiento de ~ 500 Mb / s (aproximadamente 990 mil mensajes por segundo) :

 el consumo de memoria de la máquina virtual JVM no superó los 2 GB:
el consumo de memoria de la máquina virtual JVM no superó los 2 GB:

 el ancho de banda del disco alcanzó el ancho de banda máximo de E / S el nodo en las tres instancias en las que trabajaron los intermediarios: a
el ancho de banda del disco alcanzó el ancho de banda máximo de E / S el nodo en las tres instancias en las que trabajaron los intermediarios: a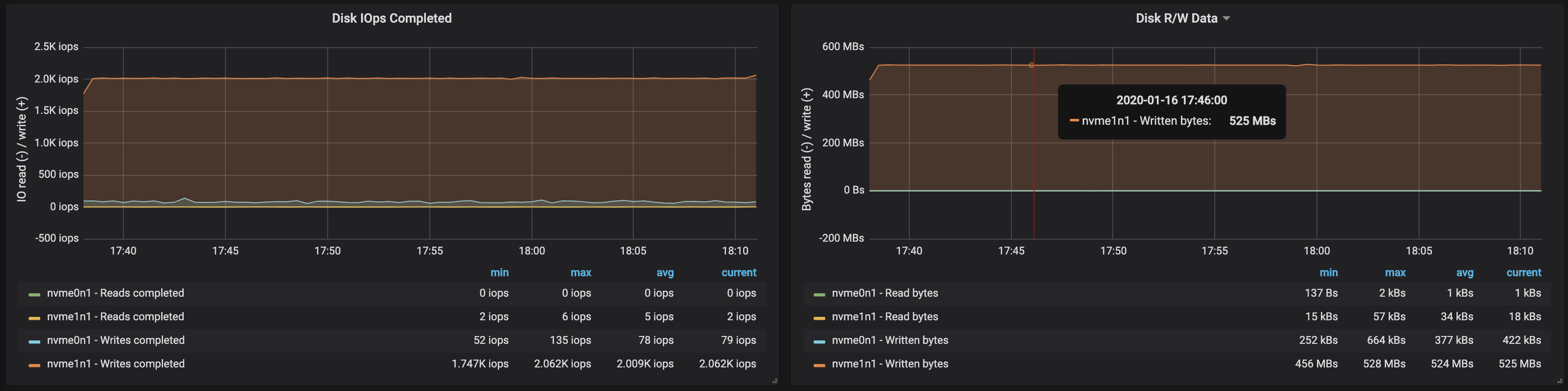

 partir de los datos sobre el uso de memoria por parte de los nodos, se deduce que el almacenamiento en caché y el almacenamiento en caché del sistema tomaron ~ 10-15 GB:
partir de los datos sobre el uso de memoria por parte de los nodos, se deduce que el almacenamiento en caché y el almacenamiento en caché del sistema tomaron ~ 10-15 GB:


3 corredores, tamaño del mensaje - 100 bytes
Con una disminución en el tamaño del mensaje, el rendimiento disminuye en aproximadamente un 15-20%: el tiempo dedicado a procesar cada mensaje se ve afectado. Además, la carga del procesador casi se duplicó.

 Dado que los nodos de intermediario todavía tienen núcleos no utilizados, puede mejorar el rendimiento cambiando la configuración de Kafka. Esta no es una tarea fácil, por lo tanto, para aumentar el rendimiento, es mejor trabajar con mensajes más grandes.
Dado que los nodos de intermediario todavía tienen núcleos no utilizados, puede mejorar el rendimiento cambiando la configuración de Kafka. Esta no es una tarea fácil, por lo tanto, para aumentar el rendimiento, es mejor trabajar con mensajes más grandes.4 corredores, tamaño de mensaje: 512 bytes
Puede aumentar fácilmente el rendimiento del clúster Kafka simplemente agregando nuevos corredores y manteniendo el equilibrio de las particiones (esto asegura una distribución uniforme de la carga entre los corredores). En nuestro caso, después de agregar un intermediario, el rendimiento del clúster aumentó a ~ 580 Mb / s (~ 1.1 millones de mensajes por segundo) . El crecimiento resultó ser menor de lo esperado: esto se debe principalmente al desequilibrio de las particiones (no todos los corredores trabajan en la cima de las oportunidades).


 El consumo de memoria de la máquina JVM permanece por debajo de 2 GB: el
El consumo de memoria de la máquina JVM permanece por debajo de 2 GB: el


 desequilibrio de la partición afectó el funcionamiento de los corredores con unidades:
desequilibrio de la partición afectó el funcionamiento de los corredores con unidades:



recomendaciones
El enfoque iterativo presentado anteriormente se puede ampliar para cubrir escenarios más complejos, incluidos cientos de consumidores, reparticionamiento, actualizaciones continuas, reinicios de pod, etc. Todo esto nos permite evaluar los límites de las capacidades del clúster de Kafka en diversas condiciones, identificar cuellos de botella en su trabajo y encontrar formas de lidiar con ellos.Desarrollamos Supertubes para implementar rápida y fácilmente un clúster, configurarlo, agregar / eliminar intermediarios y temas, responder a alertas y garantizar que Kafka funcione correctamente en Kubernetes en su conjunto. Nuestro objetivo es ayudar a concentrarse en la tarea principal ("generar" y "consumir" mensajes de Kafka) y proporcionar todo el trabajo duro a Supertubes y Kafka al operador.Si está interesado en las tecnologías Banzai Cloud y los proyectos de código abierto, suscríbase a la empresa en GitHub , LinkedIn o Twitter .PD del traductor
Lea también en nuestro blog: