Se preparó una traducción del artículo antes del inicio del curso de Machine Learning de OTUS.
Tarea
En esta guía, utilizamos el conjunto de datos Bitcoin vs USD .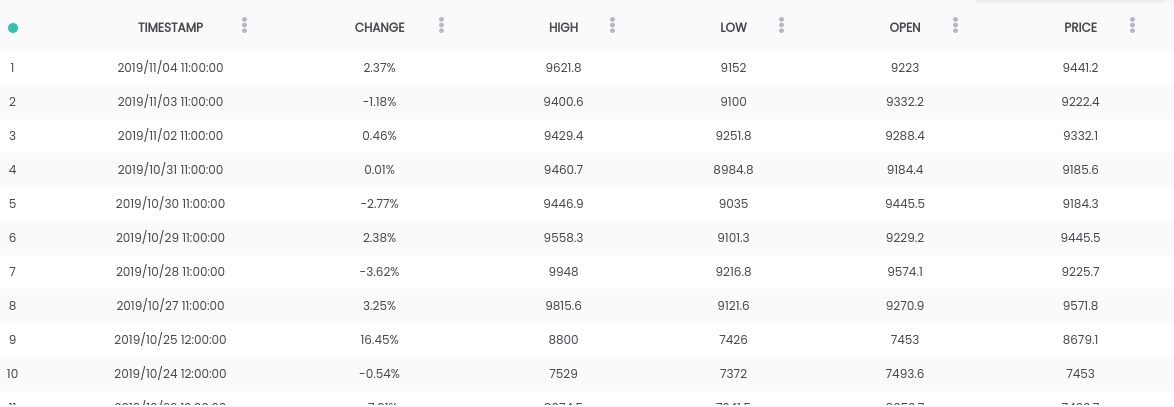 El conjunto de datos anterior contiene un resumen diario de precios, donde la columna CAMBIO es el cambio en el precio como un porcentaje del precio del día anterior ( PRECIO ) versus el nuevo ( ABIERTO ).Objetivo: para simplificar la tarea, nos centraremos en predecir si el precio aumentará ( CAMBIO> 0 ) o caerá ( CAMBIO <0 ) al día siguiente. (Por lo tanto, podemos usar predicciones "en la vida real").Requisitos
El conjunto de datos anterior contiene un resumen diario de precios, donde la columna CAMBIO es el cambio en el precio como un porcentaje del precio del día anterior ( PRECIO ) versus el nuevo ( ABIERTO ).Objetivo: para simplificar la tarea, nos centraremos en predecir si el precio aumentará ( CAMBIO> 0 ) o caerá ( CAMBIO <0 ) al día siguiente. (Por lo tanto, podemos usar predicciones "en la vida real").Requisitos- Python 2.6+ o 3.1+ deben estar instalados en el sistema
- Instalar pandas , sklearn y openblender (usando pip)
$ pip install pandas OpenBlender scikit-learn
Paso 1. Obtenga datos de Bitcoin
Para comenzar, importemos las bibliotecas necesarias:import OpenBlender
import pandas as pd
import json
Ahora extraiga los datos a través de la API de OpenBlender .Primero, definamos los parámetros (en nuestro caso, esto es solo la identificación del conjunto de datos de bitcoin ):
parameters = {
'id_dataset':'5d4c3af79516290b01c83f51'
}
Nota: deberá crear una cuenta en openblender.io (es gratis) y agregar un token (lo encontrará en la pestaña "Cuenta"):parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51'
}
Ahora pongamos los datos en el Dataframe 'df' :
def pullObservationsToDF(parameters):
action = 'API_getObservationsFromDataset'
df = pd.read_json(json.dumps(OpenBlender.call(action,parameters)['sample']), convert_dates=False,convert_axes=False) .sort_values('timestamp', ascending=False)
df.reset_index(drop=True, inplace=True)
return df
df = pullObservationsToDF(parameters)
Y mírelos: Nota: ¡los valores pueden variar, ya que el conjunto de datos se actualiza diariamente !
Nota: ¡los valores pueden variar, ya que el conjunto de datos se actualiza diariamente !Paso 2. Preparación de datos
Para empezar, necesitamos crear un objetivo de pronóstico, que será si " CAMBIAR " aumentará o disminuirá. Para hacer esto, agregue 'success_thr_over': 0 a los parámetros del umbral de destino:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold':{'feature':'change', 'success_thr_over': 0}
}
Si extraemos los datos de la API nuevamente:df = pullObservationsToDF(parameters)
df.head()
 El atributo "CHANGE" ha sido reemplazado por un nuevo atributo 'change_over_0', que se convierte en 1 si "CHANGE" es positivo y 0 si no. Este será un objetivo de aprendizaje automático.Si queremos predecir la observación de "mañana", no podremos usar la información de mañana, así que agreguemos un retraso de un período.
El atributo "CHANGE" ha sido reemplazado por un nuevo atributo 'change_over_0', que se convierte en 1 si "CHANGE" es positivo y 0 si no. Este será un objetivo de aprendizaje automático.Si queremos predecir la observación de "mañana", no podremos usar la información de mañana, así que agreguemos un retraso de un período.parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold':{'feature':'change','success_thr_over' : 0},
'lag_target_feature':{'feature':'change_over_0', 'periods' : 1}
}
df = pullObservationsToDF(parameters)
df.head()
 Esto simplemente alinea 'change_over_0' con los datos del día anterior (período) y cambia su nombre a 'TARGET_change_over_0' .Veamos la dependencia:
Esto simplemente alinea 'change_over_0' con los datos del día anterior (período) y cambia su nombre a 'TARGET_change_over_0' .Veamos la dependencia:target_variable = 'TARGET_change_over_0'
df = df.dropna()
df.corr()[target_variable].sort_values()
 Son linealmente independientes y es poco probable que sean útiles.
Son linealmente independientes y es poco probable que sean útiles.Paso 3. Obtenga datos de noticias comerciales
Después de buscar dependencias en OpenBlender , encontré el conjunto de datos de Fox Business News que ayudará a generar buenos pronósticos para nuestro objetivo. Necesitamos encontrar una manera de convertir los valores de la columna 'título' en características numéricas contando las repeticiones de palabras y grupos de palabras en el resumen de noticias, y compararlas a tiempo con nuestro conjunto de datos de bitcoin. Es más fácil de lo que parece.Primero debe crear un TextVectorizer para el atributo 'título' de la noticia:
Necesitamos encontrar una manera de convertir los valores de la columna 'título' en características numéricas contando las repeticiones de palabras y grupos de palabras en el resumen de noticias, y compararlas a tiempo con nuestro conjunto de datos de bitcoin. Es más fácil de lo que parece.Primero debe crear un TextVectorizer para el atributo 'título' de la noticia:action = 'API_createTextVectorizer'
vectorizer_parameters = {
'token' : 'your_token',
'name' : 'Fox Business TextVectorizer',
'sources':[{'id_dataset' : '5d571f9e9516293a12ad4f6d',
'features' : ['title']}],
'ngram_range' : {'min' : 1, 'max' : 2},
'language' : 'en',
'remove_stop_words' : 'on',
'min_count_limit' : 2
}
Crearemos un vectorizador para obtener todos los signos como palabras simbólicas en forma de números. Arriba, indicamos lo siguiente:- nombre : llamémoslo 'Fox Business TextVectorizer' ;
- ancla : id del conjunto de datos y el nombre de las características que necesitaremos usar como fuente (en nuestro caso, solo la columna 'título' );
- ngram_range : longitud mínima y máxima de un conjunto de palabras para la tokenización;
- idioma : inglés
- remove_stop_words : para eliminar palabras de detención de la fuente;
- min_count_limit : el número mínimo de repeticiones que deben considerarse como un token (las ocurrencias únicas rara vez son útiles).
Ahora ejecuta esto:res = OpenBlender.call(action, vectorizer_parameters)
res
Responder:{
'message' : 'TextVectorizer created successfully.'
'id_textVectorizer' : '5dc1a404951629331f6359dd',
'num_ngrams': 4270
}
Se creó TextVectorizer , que generó 4270 n-gramos de acuerdo con nuestra configuración. Un poco más tarde necesitaremos la identificación generada:5dc1a404951629331f6359ddPaso 4. Resumen de noticias compatible con el conjunto de datos bitcoin
Ahora tenemos que comparar el resumen de noticias y los datos del tipo de cambio de bitcoin a tiempo. En general, esto significa que necesita combinar dos conjuntos de datos utilizando una marca de tiempo como clave. Agreguemos los datos combinados a nuestras opciones de extracción de datos originales:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold' : {'feature':'change','success_thr_over':0},
'lag_target_feature' : {'feature':'change_over_0', 'periods':1},
'blends':[{'id_blend':'5dc1a404951629331f6359dd',
'blend_type' : 'text_ts',
'restriction' : 'predictive',
'specifications':{'time_interval_size' : 3600*12 }}]
}
Arriba, indicamos lo siguiente:- id_blend : id de nuestro textVectorizer;
- blend_type : 'text_ts' para que Python comprenda que es una mezcla de texto y marca de tiempo;
- restricción : 'predictiva' , de modo que no haya una "mezcla" de noticias del futuro con todas las observaciones, sino solo con las que se publicaron antes del tiempo especificado.
- blend_class : ' la observación más cercana ' , de modo que solo las observaciones más cercanas se "mezclan";
- especificaciones : la cantidad máxima posible de tiempo transcurrido para la transferencia de observación, en este caso 12 horas (3600 * 12). Esto significa que cada observación del precio de bitcoin se pronosticará en función de las noticias de las últimas 12 horas.
Finalmente, simplemente agregamos un filtro por la fecha 'date_filter' , que comienza el 20 de agosto, porque ahí fue cuando Fox News comenzó a recopilar datos y 'drop_non_numeric' para que solo obtengamos números:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold' : {'feature':'change','success_thr_over':0},
'lag_target_feature' : {'feature':'change_over_0', 'periods':1},
'blends':[{'id_blend':'5dc1a404951629331f6359dd',
'blend_type' : 'text_ts',
'restriction' : 'predictive',
'blend_class' : 'closest_observation',
'specifications':{'time_interval_size' : 3600*12 }}],
'date_filter':{'start_date':'2019-08-20T16:59:35.825Z',
'end_date':'2019-11-04T17:59:35.825Z'},
'drop_non_numeric' : 1
}
Nota : Indiqué el 4 de noviembre como 'end_date' , ya que fue el día en que escribí este código, puede cambiar la fecha.Volvamos a obtener los datos:df = pullObservationsToDF(parameters)
print(df.shape)
df.head()
(57, 2115) Ahora tenemos más de 2000 signos con tokens y 57 observaciones.
Ahora tenemos más de 2000 signos con tokens y 57 observaciones.Paso 5. Aplicar ML al objetivo de predicción
Ahora finalmente tenemos un conjunto de datos limpio, y se ve exactamente como lo necesitamos, con un desplazamiento de tiempo del objetivo y los datos numéricos asociados.Veamos las correlaciones más altas con 'Target_change_over_0' : ahora tenemos algunos atributos de correlación. Dividamos el conjunto de datos en entrenamiento y prueba en orden cronológico para que podamos entrenar el modelo en las primeras observaciones y probarlo en las posteriores.
ahora tenemos algunos atributos de correlación. Dividamos el conjunto de datos en entrenamiento y prueba en orden cronológico para que podamos entrenar el modelo en las primeras observaciones y probarlo en las posteriores.X = df.loc[:, df.columns != target_variable].values
y = df.loc[:,[target_variable]].values
div = int(round(len(X) * 0.29))
X_test = X[:div]
y_test = y[:div]
print(X_test.shape)
print(y_test.shape)
X_train = X[div:]
y_train = y[div:]
print(X_train.shape)
print(y_train.shape)
 Tenemos 40 observaciones para entrenamiento y 17 para pruebas.Ahora importamos las bibliotecas necesarias:
Tenemos 40 observaciones para entrenamiento y 17 para pruebas.Ahora importamos las bibliotecas necesarias:from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_auc_score
from sklearn import metrics
Ahora, usemos un bosque aleatorio (RandomForest) y hagamos una predicción:rf = RandomForestRegressor(n_estimators = 1000)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
Para facilitar las cosas, pongamos las predicciones y y_test en el Marco de datos:df_res = pd.DataFrame({'y_test':y_test[:,0], 'y_pred':y_pred})
df_res.head()
Nuestro verdadero 'y_test' es binario, pero nuestros pronósticos son de tipo flotante , así que redondeémoslos , suponiendo que si son mayores que 0.5, esto significa un aumento en el precio, y si es menor que 0.5, una disminución.threshold = 0.5
preds = [1 if val > threshold else 0 for val in df_res['y_pred']]
Ahora, para comprender mejor los resultados, obtenemos el AUC, la matriz de errores y el indicador de precisión:print(roc_auc_score(preds, df_res['y_test']))
print(metrics.confusion_matrix(preds, df_res['y_test']))
print(accuracy_score(preds, df_res['y_test']))
 Obtuvimos el 64.7% de las predicciones correctas con 0.65 AUC.
Obtuvimos el 64.7% de las predicciones correctas con 0.65 AUC.- 9 veces predijimos una disminución, y el precio disminuyó (derecha);
- 5 veces predijimos una disminución, y el precio aumentó (incorrectamente);
- 1 vez predijimos un aumento, pero el precio disminuyó incorrectamente);
- 2 veces predijimos un aumento, y el precio aumentó (verdadero).
Aprende más sobre el curso .