Investigación y conversión mediante la clasificación de secuencias pseudoaleatoriasSe han creado algoritmos en C # y qbasic y una tabla compatible con Excel, lo que demuestra la capacidad de examinar las secuencias pseudoaleatorias en busca de aleatoriedad y capaz de determinar secuencias no aleatorias o de baja potencia.Concha gráfica: tabla de Excel compatible para la investigación de más de 50 mil. elementos de 2 tipos:1. Estudio de una secuencia de números;2. El estudio de la secuencia de dígitos 0 y 1. Investigación de secuencia numérica: la tabla define características binarias, por ejemplo, menos / más e incluso / impar.La estructura gráfica de una tabla compatible con Excel utiliza las fórmulas: el
Investigación de secuencia numérica: la tabla define características binarias, por ejemplo, menos / más e incluso / impar.La estructura gráfica de una tabla compatible con Excel utiliza las fórmulas: el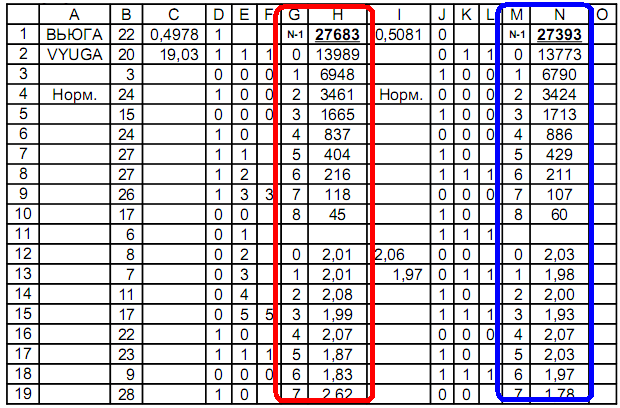 número de coincidencias en una fila se calcula mediante la fórmula N = log (1-C) / log (1-P),donde N es el paso, P es la probabilidad, C es la confiabilidad de la probabilidad.Número de paso de distribución:en C = P = 0.5; N = 1 = log0.5 / log0.5 = log (1-1 / 2) / log (1-1 / 2) = 1en C = 0.25; P = 0,5; N = 2 = log0.75 / log0.5 = log (1-1 / 4) / log (1-1 / 2) = 2, etc.La columna A es el nombre de la secuencia;Columna B - secuencia;Columna D - Primera distribución: menos / más;Columnas E, F - definición de idénticas en una fila;Columnas G, H - contando el número de signos idénticos en una fila;Columna J - 2da distribución: par / impar;Columnas K, L: definición de signos idénticos en una fila;Columnas M, N: contando el número de signos idénticos en una fila.Fórmulas utilizadas en la tabla:
número de coincidencias en una fila se calcula mediante la fórmula N = log (1-C) / log (1-P),donde N es el paso, P es la probabilidad, C es la confiabilidad de la probabilidad.Número de paso de distribución:en C = P = 0.5; N = 1 = log0.5 / log0.5 = log (1-1 / 2) / log (1-1 / 2) = 1en C = 0.25; P = 0,5; N = 2 = log0.75 / log0.5 = log (1-1 / 4) / log (1-1 / 2) = 2, etc.La columna A es el nombre de la secuencia;Columna B - secuencia;Columna D - Primera distribución: menos / más;Columnas E, F - definición de idénticas en una fila;Columnas G, H - contando el número de signos idénticos en una fila;Columna J - 2da distribución: par / impar;Columnas K, L: definición de signos idénticos en una fila;Columnas M, N: contando el número de signos idénticos en una fila.Fórmulas utilizadas en la tabla:Célula
| Fórmula
| Explicación
|
C1
| = PROMEDIO (D1: D55000)
| El valor promedio de los números de secuencia.
|
C2
| = PROMEDIO (B1: B55000)
| Distribución Promedio 1
|
D1
| = SI (B1 <C $ 2; 0; 1)
| Si el número es menor que el promedio, entonces 0, de lo contrario 1
|
D2
| = SI (B2 <C $ 2; 0; 1)
| Si el número es menor que el promedio, entonces 0, de lo contrario 1, etc.
|
E2
| = SI (D2 = D1; E1 + 1; 0)
| Si los signos de distribución son los mismos, entonces el contador de la misma en una fila es +1; de lo contrario, el contador se restablece a cero
|
F2
| = SI (E3 = 0; E2; "")
| Si se restablece el contador, se registra el contador más alto.
|
G2-g19
| 0 ... 7
| Números para comparar
|
H1
| = SUMA (H2: H10)
| Suma de comparaciones
|
H2
| =(F$1:F$55000;G2)
| 1
|
H3
| =(F$1:F$55000;G3)
| 2 ..
|
H12
| =H2/H3
|
|
I12
| =(H12:H19)
|
|
I13
| =(N12:N19)
| ..
|
I1
| =(J1:J55000)
| 2
|
J1
| =(B1/2=(B1/2);0;1)
| , 0, 1
|
J2
| =(B2/2=(B2/2);0;1)
| , 0, 1 ..
|
K2
| =(J2=J1;K1+1;0)
| , +1,
|
L2
| =(K3=0;K2;" ")
| ,
|
M2-M19
| 0…7
|
|
N1
| =(N2:N10)
|
|
N2
| =(L$1:L$55000;M2)
| 1
|
N3
| =(L$1:L$55000;M3)
| 2 ..
|
N12
| =H2/H3
|
|
Se pueden programar otras funciones de monitoreo en la tabla.En la tabla es posible crear gráficos de los valores de cualquier celda.La continuación de la tabla explora las permutaciones aleatorias de la secuencia.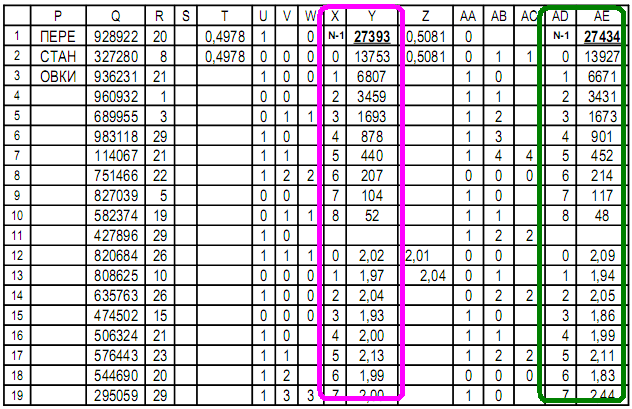 Columna Q: aleatorio para permutaciones: enteros de hasta 10 ^ 6para minimizar la repetición de las aleatorias;Columna R: inicialmente una copia de la columna B y luego modificada;Las columnas T ... AE son las mismas que las columnas C ... N.
Columna Q: aleatorio para permutaciones: enteros de hasta 10 ^ 6para minimizar la repetición de las aleatorias;Columna R: inicialmente una copia de la columna B y luego modificada;Las columnas T ... AE son las mismas que las columnas C ... N.Célula
| Fórmula
| Explicación
|
Q1
| = CASO ENTRE (0; 1,000,000)
| Aleatorio para reorganizar
|
Q2
| = CASO ENTRE (0; 1,000,000)
| Aleatorio para permutación, etc.
|
La permutación se realiza ordenando 2 columnas Q y R: lacolumna Q está al frente y la columna R es esclava.Resultado: permutación de la columna R y una nueva secuencia.Los estudios de PRNG basados en el PRNG integrado muestran la normalidad del algoritmo.Antes de la permutación de 500 celdas: Después de la permutación de 500 celdas: La
Después de la permutación de 500 celdas: La verificación muestra una buena distribución, comparando los signos: pequeño / grande y par / impar.La tabla examina el PRNG trigonométrico, usando los dígitos decimales de las funciones trigonométricas, sin usar el PRNG estándar.
verificación muestra una buena distribución, comparando los signos: pequeño / grande y par / impar.La tabla examina el PRNG trigonométrico, usando los dígitos decimales de las funciones trigonométricas, sin usar el PRNG estándar.
OPEN "rndsin.txt" FOR OUTPUT AS #1
c = 0: a = SIN(TIMER) * 100 + 200
PRINT #1, "a= ", a
FOR k = 1 TO 10 ^ 3 + a * 10 ^ 3: NEXT
FOR i = 1 TO 100
FOR j = 1 TO a
x = SIN(TIMER) * 1000 + 2000
b = COS(x): c = c + b
LOCATE 1, 1: PRINT j
NEXT
d = (ABS(c)) - INT(ABS(c))
PRINT #1, d
FOR k = 1 TO 10000 + a * b * c * 10 ^ 2: NEXT
NEXT
Antes de la permutación de 500 celdas: insatisfactorio Obviamente, la distribución es pobre, revelando la frecuencia y la dispersión de los valores, comparando los signos: pequeño / grande y par / impar.Después de la reorganización de 500 celdas: normal
Obviamente, la distribución es pobre, revelando la frecuencia y la dispersión de los valores, comparando los signos: pequeño / grande y par / impar.Después de la reorganización de 500 celdas: normal Propósito: excluir el PRNG incorporado.Método de reordenamiento: la secuencia original se ordena, la misma secuencia que se invierte o se invierte de cualquier manera se acepta como aleatoria para el reordenamiento.Por ejemplo, en Excel, se crearon 2 copias de las columnas de una secuencia a una distancia, y una fila inicial de 1 ... 55000 en una fila se construye en una columna a la izquierda y 2 columnas se ordenan de máximo a mínimo, invirtiendo los datos originales.A continuación, 2 columnas de la secuencia se asignan una al lado de la otra y se ordenan, donde la columna principal es la columna inversa y la columna esclava es la columna inicial.Antes de la permutación de 500 células: insatisfactorio
Propósito: excluir el PRNG incorporado.Método de reordenamiento: la secuencia original se ordena, la misma secuencia que se invierte o se invierte de cualquier manera se acepta como aleatoria para el reordenamiento.Por ejemplo, en Excel, se crearon 2 copias de las columnas de una secuencia a una distancia, y una fila inicial de 1 ... 55000 en una fila se construye en una columna a la izquierda y 2 columnas se ordenan de máximo a mínimo, invirtiendo los datos originales.A continuación, 2 columnas de la secuencia se asignan una al lado de la otra y se ordenan, donde la columna principal es la columna inversa y la columna esclava es la columna inicial.Antes de la permutación de 500 células: insatisfactorio Después de la permutación de 500 células: normal
Después de la permutación de 500 células: normal Resultado: la secuencia se volvió normal sin el PRNG incorporado.Conclusiones: la aleatoriedad verdadera no es natural para las personas y es posible sintetizar secuencias falsas o de baja potencia que las personas y las computadoras aceptan como secuencias aleatorias.Cualquier secuencia realmente se puede sintetizar en lenguajes de programación y en tablas compatibles con Excel.El problema de superar la aleatoriedad se resuelve reconociendo la aleatoriedad como normal o falsa en una hoja de cálculo Excel con gráficos.Q.E.D.Continúa con la aprobación:Programas de permutación en lenguajes qbasic y C #.Investigación de dígitos pi.Falsificación de aleatoriedad.2020 desarrollo de personas afines extranjeras.
Resultado: la secuencia se volvió normal sin el PRNG incorporado.Conclusiones: la aleatoriedad verdadera no es natural para las personas y es posible sintetizar secuencias falsas o de baja potencia que las personas y las computadoras aceptan como secuencias aleatorias.Cualquier secuencia realmente se puede sintetizar en lenguajes de programación y en tablas compatibles con Excel.El problema de superar la aleatoriedad se resuelve reconociendo la aleatoriedad como normal o falsa en una hoja de cálculo Excel con gráficos.Q.E.D.Continúa con la aprobación:Programas de permutación en lenguajes qbasic y C #.Investigación de dígitos pi.Falsificación de aleatoriedad.2020 desarrollo de personas afines extranjeras.