Cuando otro año fructífero llega a su fin, quiero mirar hacia atrás, hacer un balance y mostrar lo que pudimos hacer durante este tiempo. La biblioteca #DeepPavlov, por un minuto, ya tiene dos años, y estamos contentos de que nuestra comunidad esté creciendo todos los días.Durante el año de trabajo en la biblioteca, hemos logrado:- Las descargas de la biblioteca aumentaron en un tercio en comparación con el año pasado. Ahora DeepPavlov tiene más de 100 mil instalaciones y más de 10 mil instalaciones de contenedores.
- El número de soluciones comerciales ha aumentado debido a las tecnologías de vanguardia implementadas en DeepPavlov, en diversas industrias, desde el comercio minorista hasta la industria.
- Se lanzó la primera versión de DeepPavlov Agent .
- El número de miembros activos de la comunidad ha aumentado 5 veces.
- Nuestro equipo de estudiantes de pregrado y posgrado fue seleccionado para participar en el Premio Alexa Socialbot Grand Challenge 3 .
- La biblioteca se ha convertido en ganadora del concurso de la empresa Google «Powered by TensorFlow Challenge».
¿Qué ayudó a lograr tales resultados y por qué DeepPavlov es el mejor código abierto para construir IA conversacional? Lo diremos en nuestro artículo.
#DeepPavlov apunta al resultado
Recientemente, los sistemas de diálogo se han convertido en el estándar para la interacción hombre-máquina. Los chatbots se usan en casi todas las industrias, lo que simplifica la interacción entre las personas y las computadoras. Se integran perfectamente en sitios web, plataformas de mensajería y dispositivos. Muchas empresas prefieren delegar tareas rutinarias a sistemas interactivos que pueden manejar múltiples solicitudes de usuarios al mismo tiempo, ahorrando costos laborales.Sin embargo, a menudo las empresas no saben por dónde empezar cuando desarrollan un bot para satisfacer las necesidades de su negocio. Históricamente, los chatbots se pueden dividir en dos grandes grupos: según las reglas y los datos. El primer tipo se basa en comandos y plantillas predefinidos. El desarrollador del chatbot debe escribir cada uno de estos comandos utilizando expresiones regulares y análisis de datos de texto. En contraste, los bots de chat basados en datos se basan en modelos de aprendizaje automático que han sido previamente entrenados en datos de diálogo.Biblioteca de código abierto - DeepPavlovofrece una solución gratuita y fácil de usar para construir sistemas interactivos. DeepPavlov viene con varios componentes previamente entrenados para resolver problemas asociados con el procesamiento del lenguaje natural (PNL). DeepPavlov resuelve problemas tales como: clasificación de texto, corrección de errores tipográficos, reconocimiento de entidades con nombre, respuestas a preguntas sobre la base de conocimiento y muchos otros. Y puede instalar DeepPavlov en una línea ejecutando:pip install -q deeppavlov
* El marco le permite entrenar y probar modelos, así como personalizar sus hiperparámetros. La biblioteca admite plataformas Linux y Windows. Puede probar este y otros modelos en la versión demo de la biblioteca .Actualmente, se han logrado resultados modernos en muchas tareas mediante el uso de modelos basados en BERT. El equipo de DeepPavlov integró BERT en las siguientes tres tareas: clasificación de texto, reconocimiento de entidades con nombre y respuestas a preguntas. Como resultado, hemos realizado mejoras significativas en todas estas tareas.1. Modelos BERT DeepPavlov
BERT para clasificación de texto Un
modelo de clasificación de texto basado en BERT DeepPavlov sirve, por ejemplo, para resolver el problema de detección de insultos. El modelo incluye predecir si un comentario publicado en una discusión pública se considera ofensivo para uno de los participantes. Para este caso, la clasificación se lleva a cabo solo en dos clases: insultar y no insultar.Cualquier modelo previamente entrenado se puede utilizar para la salida tanto a través de la interfaz de línea de comandos (CLI) como a través de Python. Antes de usar el modelo, asegúrese de que todos los paquetes necesarios estén instalados usando el comando:python -m deeppavlov install insults_kaggle_bert
python -m deeppavlov interact insults_kaggle_bert -d
BERT para el
reconocimiento de entidades con nombre Además de los modelos de clasificación de texto, DeepPavlov incluye un modelo basado en BERT para el reconocimiento de entidades con nombre (NER). Esta es una de las tareas más comunes en PNL y el modelo más utilizado de nuestra biblioteca. Al mismo tiempo, NER tiene muchas aplicaciones comerciales. Por ejemplo, un modelo puede extraer información importante de un currículum para facilitar el trabajo de especialistas en recursos humanos. Además, NER se puede utilizar para identificar entidades relevantes en las solicitudes de los clientes, como especificaciones de productos, nombres de compañías o información de sucursales de la compañía.El equipo de DeepPavlov entrenó el modelo NER en el edificio en inglés OntoNotes, que tiene 19 tipos de marcado, incluidos PER (persona), LOC (ubicación), ORG (organización) y muchos otros. Para interactuar, debe instalarlo con el comando:python -m deeppavlov install ner_ontonotes_bert_mult
python -m deeppavlov interact ner_ontonotes_bert_mult [-d]
BERT para responder preguntas Una
respuesta contextual a una pregunta es la tarea de encontrar una respuesta a una pregunta en un contexto dado (por ejemplo, un párrafo de Wikipedia), donde la respuesta a cada pregunta es un segmento de contexto. Por ejemplo, el triple de contexto, pregunta y respuesta a continuación forma el triplete correcto para la tarea de responder la pregunta.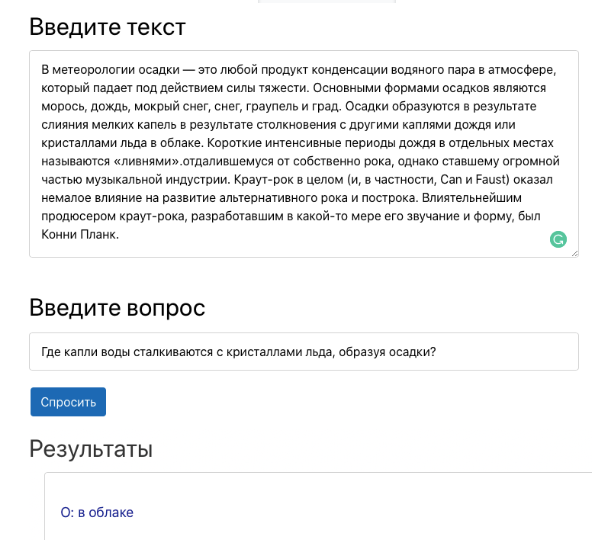 Presentación del trabajo del sistema de preguntas y respuestas en una demostración.Un sistema de respuestas a preguntas puede automatizar muchos procesos en un negocio. Por ejemplo, esto puede ayudar a los empleadores a obtener respuestas basadas en la documentación interna de la empresa. Además, el modelo ayudará a evaluar la capacidad de los estudiantes para comprender el texto en el proceso de aprendizaje. Recientemente, sin embargo, la tarea de responder preguntas basadas en el contexto ha atraído una gran atención de los científicos. Uno de los puntos de inflexión clave en esta área fue el lanzamiento del conjunto de preguntas y respuestas de Stanford (SQuAD). El conjunto de datos SQuAD ha llevado a innumerables enfoques para resolver el problema del sistema de preguntas y respuestas. Uno de los más exitosos es el modelo DeepPavlov BERT. Supera a todos los demás y actualmente está produciendo resultados que bordean las características humanas.Para usar el modelo de control de calidad basado en BERT con DeepPavlov, debe:
Presentación del trabajo del sistema de preguntas y respuestas en una demostración.Un sistema de respuestas a preguntas puede automatizar muchos procesos en un negocio. Por ejemplo, esto puede ayudar a los empleadores a obtener respuestas basadas en la documentación interna de la empresa. Además, el modelo ayudará a evaluar la capacidad de los estudiantes para comprender el texto en el proceso de aprendizaje. Recientemente, sin embargo, la tarea de responder preguntas basadas en el contexto ha atraído una gran atención de los científicos. Uno de los puntos de inflexión clave en esta área fue el lanzamiento del conjunto de preguntas y respuestas de Stanford (SQuAD). El conjunto de datos SQuAD ha llevado a innumerables enfoques para resolver el problema del sistema de preguntas y respuestas. Uno de los más exitosos es el modelo DeepPavlov BERT. Supera a todos los demás y actualmente está produciendo resultados que bordean las características humanas.Para usar el modelo de control de calidad basado en BERT con DeepPavlov, debe:python -m deeppavlov install squad_bert
python -m deeppavlov interact squad_bert -d
Se pueden encontrar más modelos en la documentación . Y si necesita tutoriales sobre el uso de componentes de la biblioteca, búsquelos en nuestro blog oficial .2. DeepPavlov Agent: una plataforma para crear bots de chat multitarea
Hoy en día, existen varios enfoques para el desarrollo de agentes interactivos. Al desarrollar agentes de conversación, la arquitectura modular se utiliza principalmente para un diálogo centrado en el que se desarrolla el guión. Sin embargo, a menudo el usuario necesita combinar un diálogo centrado, por ejemplo, con otra funcionalidad: responder preguntas o buscar información, así como mantener una conversación. Por lo tanto, el agente de diálogo ideal es un asistente personal que combina diferentes tipos de agentes, cambia entre sus funcionalidades y caracteres, dependiendo de la tarea en la que se utiliza. Al mismo tiempo, el agente debe acumular información sobre su esencia, ajustar sus algoritmos a un usuario específico. Por otro lado, debería poder integrarse con servicios externos. Por ejemplo,hacer consultas a bases de datos externas, obtener información desde allí, procesarla, resaltar lo importante y transmitirlo al usuario. Para resolver este problema, en octubre de 2019, se lanzó la primera versión de DeepPavlov Agent 1.0, una plataforma para crear bots de chat multitarea. El agente ayuda a los desarrolladores de chatbots de producción a organizar varios modelos de PNL en una sola tubería.Lea más sobre la plataforma y las características en la documentación .3. Implementación de DeepPavlov NLP SaaS
Para simplificar el trabajo con modelos NLP pre-entrenados de DeepPavlov, en septiembre de 2019, se lanzó un servicio SaaS. DeepPavlov Cloud le permite analizar texto, así como almacenar documentos en la nube. Para usar los modelos, debe registrarse en nuestro servicio y obtener un token en la sección Tokens de su cuenta personal. Por el momento, el servicio admite varios modelos de PNL previamente entrenados en ruso y está en proceso de probar el sistema.4. Participación en DSCT8 o sistema de diálogo dirigido
El uso de asistentes virtuales como Amazon Alexa y Google Assistant ha abierto oportunidades para desarrollar aplicaciones que nos permiten simplificar la implementación de muchas tareas cotidianas, como pedir un taxi, reservar una mesa en un restaurante y muchos otros. Para resolver estos problemas, se utilizan sistemas de diálogo enfocados.Dialogue State Traking (DST) es un componente clave en tales sistemas de diálogo. DST es responsable de traducir los enunciados en el lenguaje humano en una representación semántica del lenguaje, en particular, para extraer intentos y pares de valores de ranura correspondientes a la meta del usuario.Durante la participación del equipo en DSTC8Se desarrolló el modelo GOLOMB (rastreador de estado de diálogo basado en BERT multitarea orientado a GOaL), un modelo multitarea orientado a objetivos basado en BERT para rastrear el estado del diálogo. Para predecir el estado del diálogo, el modelo resuelve varios problemas de clasificación y la tarea de encontrar una subcadena. Pronto este modelo aparecerá en la biblioteca DeepPavlov. Mientras tanto, puedes leer el artículo completo aquí . Presentación del póster en la conferencia AAAI-20 en Nueva York (EE. UU.).
Presentación del póster en la conferencia AAAI-20 en Nueva York (EE. UU.).
5. Participación en el Gran Premio Socialbot de Alexa Prize
El equipo de DeepPavlov, formado por estudiantes y estudiantes de posgrado del Instituto de Física y Tecnología de Moscú, fue seleccionado para participar en el Premio Alexa Socialbot Grand Challenge 3 , una competencia internacional dedicada al desarrollo de tecnología de IA conversacional. El objetivo de la competencia es crear un bot que pueda comunicarse libremente con personas sobre temas relevantes. De las 375 solicitudes, el comité del Premio Alexa seleccionó a 10 finalistas, incluido nuestro equipo, DREAM. Por el momento, el equipo se ha movido a los cuartos de final de la competencia y está luchando por llegar a las semifinales. Puedes seguir las noticias y animar las nuestras en la página oficial , y no olvides suscribirte a Twitter . Composición del equipo Dream Team.
Composición del equipo Dream Team.
6. Participación en el desafío Powered by TF
Como se dijo anteriormente, DeepPavlov viene con varios componentes previamente entrenados que se ejecutan en TensorFlow y Keras. Y este año, el equipo de DeepPavlov ganó el concurso Google Powered by TF Challenge por el mejor proyecto de aprendizaje automático que utiliza la biblioteca TensorFlow. De los más de 600 participantes en el concurso, Google eligió los cinco mejores proyectos, uno de los cuales fue la biblioteca DeepPavlov. El proyecto fue presentado en el blog oficial de TensorFlow . Vale la pena señalar que la flexibilidad de TensorFlow nos permite crear cualquier arquitectura de red neuronal que podamos imaginar. Y en particular, utilizamos TensorFlow para una integración perfecta con modelos basados en BERT.
7. Desarrollo comunitario
El objetivo global de nuestro proyecto es permitir a los desarrolladores e investigadores en el campo de la inteligencia artificial conversacional usar las herramientas más avanzadas para crear sistemas interactivos de próxima generación, así como convertirse en una plataforma internacionalmente significativa en el campo de la IA para el intercambio de experiencias y la enseñanza de tecnologías de vanguardia.Para lograr esto, los empleados de DeepPavlovrealizar cursos de capacitación gratuitos semestrales para estudiantes y personal involucrado en Ciencias de la Computación. Uno de ellos es el curso: "Aprendizaje profundo en el procesamiento del lenguaje natural", que incluye seminarios y talleres. Las clases incluyen temas como: construcción de sistemas de diálogo, métodos para evaluar un sistema de diálogo con la capacidad de generar una respuesta, diversos marcos para sistemas de diálogo, métodos para estimar la cantidad de remuneración debido a la optimización de las políticas de diálogo, tipos de solicitudes de los usuarios, consideración de modelado de llamadas al centro de llamadas. En 2020, lanzamos un nuevo reclutamiento y ya 900 estudiantes y empleados reciben capacitación de forma gratuita. Puede seguir las noticias y el conjunto de este y otros cursos en nuestro sitio web . Y si te perdiste los cursos, pero quieres aprender más, entonces en nuestrocanal de youtube siempre puedes encontrarlos en el registro.Hoy en día, la biblioteca DeepPavlov proporciona componentes listos para AI para trabajar con texto, que se utilizan en 92 países del mundo. A partir de febrero de 2020, el número de descargas de la biblioteca alcanzó los 100,000 mil, y la dinámica de las instalaciones está ganando impulso. Además, más de 30 empresas en Rusia ya han implementado y están utilizando con éxito soluciones basadas en DeepPavlov. Esto muestra que tales soluciones son muy populares en todo el mundo.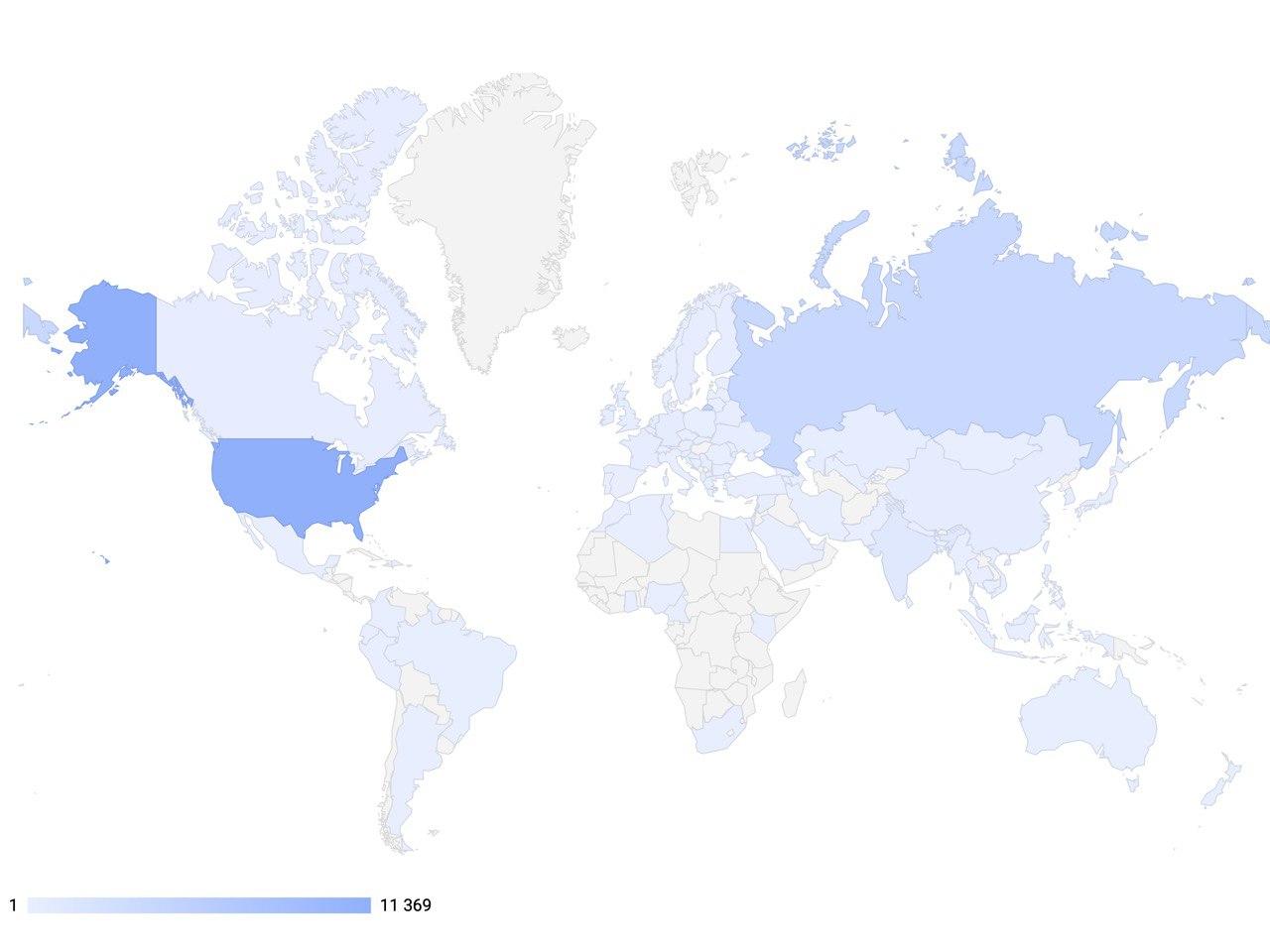
¿Que sigue?
Nos complace compartir nuestros éxitos con usted, por lo que hemos preparado un evento para nuestra comunidad. Queremos compartir experiencias y conocimientos de proyectos de producción reales sobre cómo crear los mejores asistentes de IA. Únase a la reunión de usuarios y desarrolladores de la biblioteca abierta DeepPavlov el 28 de febrero para hablar sobre inteligencia artificial y su aplicación, así como para conocer a otros miembros de la comunidad. El evento se llevará a cabo como parte de la semana de IA del 25 al 28 de febrero. Estamos esperando a todos los que usan DeepPavlov o quieren conocer nuestra tecnología.Toda la información sobre los oradores y el programa se puede encontrar en el sitio, es necesario registrarse para asistir al evento.Únete: DeepPavlov 2 años
La industria de IA continuará evolucionando, y creemos que DeepPavlov se convertirá en una tecnología avanzada que todo desarrollador utilizará para comprender el lenguaje natural. El próximo año, trabajaremos para duplicar nuestra comunidad, aumentar las herramientas de código abierto y mejorar la investigación de aprendizaje automático. Y no olvide que DeepPavlov tiene un foro : haga sus preguntas sobre la biblioteca y los modelos. ¡Gracias por la atención!