Recientemente, la tarea de reconocimiento de caracteres en los programas de aplicación no es particularmente difícil: puede usar muchas bibliotecas OCR listas para usar, muchas de las cuales están casi perfeccionadas. Sin embargo, a veces puede surgir una tarea para desarrollar su propio algoritmo de reconocimiento sin utilizar bibliotecas OCR "sofisticadas" de terceros.
Esta es exactamente la tarea que surgió durante mi trabajo, y hay varias razones por las que es mejor no usar bibliotecas preparadas: el proyecto cerrado, con su certificación adicional, una cierta restricción en el número de líneas de código y el tamaño de las bibliotecas conectadas, más aún porque debe reconocer lo suficiente en el área temática conjunto de caracteres específicos
El algoritmo de reconocimiento es simple y, por supuesto, no pretende ser el más preciso, rápido y efectivo, sino que se adapta bien a su pequeña tarea.
Supongamos que tenemos entrada en forma de imágenes escaneadas de documentos en forma estructurada. Estos documentos tienen un código especial de un carácter ubicado en la esquina superior izquierda. Nuestra tarea es reconocer este símbolo y luego realizar algunas acciones, por ejemplo, clasificar el documento fuente de acuerdo con las reglas dadas.

El diagrama del algoritmo es el siguiente:
 Como sabemos de antemano dónde se encuentra nuestro símbolo, cortar un área determinada no es difícil. Para eliminar todas las "irregularidades" de los bordes del símbolo, traducimos la imagen a monocromo (blanco y negro).
Como sabemos de antemano dónde se encuentra nuestro símbolo, cortar un área determinada no es difícil. Para eliminar todas las "irregularidades" de los bordes del símbolo, traducimos la imagen a monocromo (blanco y negro).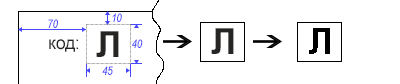
short width = 45, height = 40, offsetTop = -10, offsetLeft = -70;
BufferedImage image = ImageIO.read(file);
BufferedImage symbol = new BufferedImage(width, height, BufferedImage.TYPE_BYTE_BINARY);
Graphics2D g = symbol.createGraphics();
g.drawImage(image, offsetLeft, offsetTop, null);
A continuación, debe convertir el fragmento resultante "píxel por píxel" en una cadena binaria, es decir, una cadena donde, por ejemplo, '*' corresponde a un píxel negro y un espacio a blanco.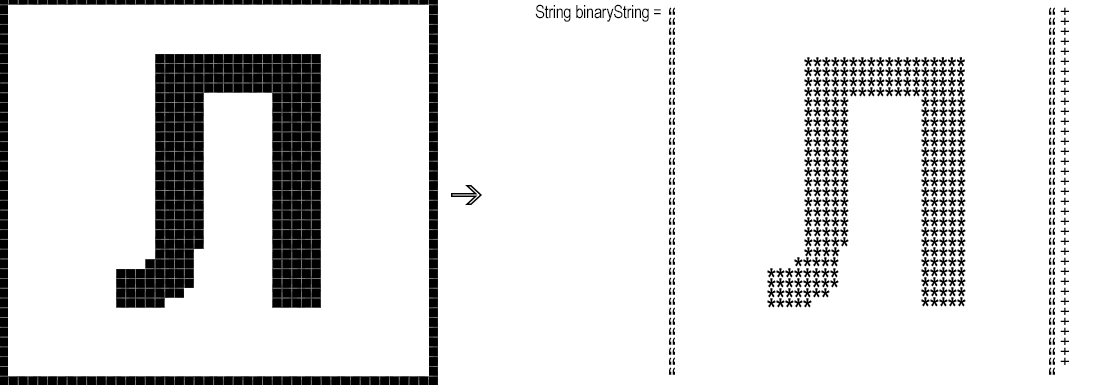
short whiteBg = -1;
StringBuilder binaryString = new StringBuilder();
for (short y = 1; y < height; y++)
for (short x = 1; x < width; x++) {
int rgb = symbol.getRGB(x, y);
binaryString.append(rgb == whiteBg ? " " : "*");
}
A continuación, debe encontrar la distancia mínima de Levenshtein entre la cadena recibida y las cadenas de referencia preparadas previamente (de hecho, puede tomar cualquier método de comparación de cadenas).int min = 1000000;
char findSymbol = "";
for (Map.Entry<Character, String> entry : originalMap.entrySet()) {
int levenshtein = levenshtein(binaryString.toString(), entry.getValue());
if (levenshtein < min) {
min = levenshtein;
findSymbol = entry.getKey();
}
}
La función de encontrar la distancia de Levenshtein se implementa como un método de acuerdo con el algoritmo estándar:public static int levenshtein(String targetStr, String sourceStr) {
int m = targetStr.length(), n = sourceStr.length();
int[][] delta = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++)
delta[i][0] = i;
for (int j = 1; j <= n; j++)
delta[0][j] = j;
for (int j = 1; j <= n; j++)
for (int i = 1; i <= m; i++) {
if (targetStr.charAt(i - 1) == sourceStr.charAt(j - 1))
delta[i][j] = delta[i - 1][j - 1];
else
delta[i][j] = Math.min(delta[i - 1][j] + 1,
Math.min(delta[i][j - 1] + 1, delta[i - 1][j - 1] + 1));
}
return delta[m][n];
}
El resultado findSymbol será nuestro reconocido personaje.Este algoritmo puede optimizarse para mejorar el rendimiento y complementarse con varias comprobaciones para mejorar la eficiencia del reconocimiento. Muchos indicadores dependen del área temática específica del problema que se está resolviendo (número de caracteres, variedad de fuentes, calidad de imagen, etc.).Se encontró de manera práctica que el método resuelve cualitativamente incluso problemas problemáticos como la "similitud" de caracteres, por ejemplo, "L" <-> "P", "5" <-> "S", "O" <-> "0". Dado que, por ejemplo, la distancia entre las cadenas binarias "L" y "P" siempre será mayor que entre la "L" reconocida y la cadena de referencia "L", incluso con algunas "irregularidades".En general, si necesita resolver un problema similar (por ejemplo, reconocimiento de naipes), con una serie de restricciones en el uso de neuronas y otras soluciones preparadas, puede tomar y modificar este método de manera segura.