En este artículo, hablaré sobre un par de trucos simples que son útiles cuando se trabaja con datos que no caben en la máquina local, pero que aún son demasiado pequeños para ser llamados Grandes. Siguiendo la analogía del idioma inglés (grande pero no grande), llamaremos a este dato grueso. Estamos hablando de tamaños de unidades y decenas de gigabytes.[Descargo de responsabilidad] Si te encanta el SQL, todo lo que está escrito a continuación puede provocar emociones negativas brillantes, muy probablemente, en los Países Bajos hay 49262 Tesla, 427 de ellos son taxis, mejor no seguir leyendo [/ Descargo de responsabilidad]. El punto de partida fue un artículo sobre el centro con una descripción de un conjunto de datos interesante: una lista completa de vehículos registrados en los Países Bajos, 14 millones de líneas, desde tractores de camiones hasta bicicletas eléctricas a velocidades superiores a 25 km / h.El conjunto es interesante, toma 7 GB, puede descargarlo en el sitio web de la organización responsable.El intento de manejar los datos tal como están en los pandas para filtrarlos y limpiarlos terminó en un fiasco (¡señores de los húsares SQL, advertí!). Los pandas cayeron por falta de memoria en el escritorio con 8 GB. Con un poco de derramamiento de sangre, la pregunta puede resolverse si recuerda que los pandas pueden leer archivos csv en piezas de tamaño moderado. El tamaño del fragmento en filas está determinado por el parámetro chunksize.Para ilustrar el trabajo, escribiremos una función simple que haga una solicitud y determine cuántos automóviles Tesla hay en total y qué proporción de ellos trabajan en taxis. Sin trucos con lectura de fragmentos, una solicitud de este tipo primero consume toda la memoria, luego sufre durante mucho tiempo y, al final, la rampa se cae.Con la lectura de fragmentos, nuestra función se verá así:
El punto de partida fue un artículo sobre el centro con una descripción de un conjunto de datos interesante: una lista completa de vehículos registrados en los Países Bajos, 14 millones de líneas, desde tractores de camiones hasta bicicletas eléctricas a velocidades superiores a 25 km / h.El conjunto es interesante, toma 7 GB, puede descargarlo en el sitio web de la organización responsable.El intento de manejar los datos tal como están en los pandas para filtrarlos y limpiarlos terminó en un fiasco (¡señores de los húsares SQL, advertí!). Los pandas cayeron por falta de memoria en el escritorio con 8 GB. Con un poco de derramamiento de sangre, la pregunta puede resolverse si recuerda que los pandas pueden leer archivos csv en piezas de tamaño moderado. El tamaño del fragmento en filas está determinado por el parámetro chunksize.Para ilustrar el trabajo, escribiremos una función simple que haga una solicitud y determine cuántos automóviles Tesla hay en total y qué proporción de ellos trabajan en taxis. Sin trucos con lectura de fragmentos, una solicitud de este tipo primero consume toda la memoria, luego sufre durante mucho tiempo y, al final, la rampa se cae.Con la lectura de fragmentos, nuestra función se verá así:def pandas_chunky_query():
print('reading csv file with pandas in chunks')
filtered_chunk_list=[]
for chunk in pd.read_csv('C:\Open_data\RDW_full.CSV', chunksize=1E+6):
filtered_chunk=chunk[chunk['Merk'].isin(['TESLA MOTORS','TESLA'])]
filtered_chunk_list.append(filtered_chunk)
model_df = pd.concat(filtered_chunk_list)
print(model_df['Taxi indicator'].value_counts())
Al especificar un millón de líneas perfectamente razonables, puede ejecutar la consulta en 1:46 y usar 1965 M de memoria en su punto máximo. Todos los números para un escritorio tonto con algo antiguo, de ocho núcleos, aproximadamente 8 GB de memoria y bajo el séptimo Windows.
 Si cambia chunksize, el consumo máximo de memoria lo sigue literalmente, el tiempo de ejecución no cambia mucho. Para líneas de 0.5 M, la solicitud toma 1:44 y 1063 MB, para 2M 1:53 y 3762 MB.La velocidad no es particularmente agradable, y menos aún es que leer el archivo en fragmentos hace que sea necesario escribir funciones adaptadas para esto, trabajando con listas de fragmentos que luego deben ensamblarse en un marco de datos. Además, el formato csv en sí no es muy feliz, lo que ocupa mucho espacio y se lee lentamente.Como podemos conducir datos a una rampa, se puede usar un formato Apachev mucho más compacto para el almacenamientoparquet donde hay compresión y, gracias al esquema de datos, es mucho más rápido de leer cuando se lee. Y la rampa es bastante capaz de trabajar con él. Solo que ahora no puede leerlos en fragmentos. ¿Qué hacer?- ¡ Divirtámonos , toma el
Si cambia chunksize, el consumo máximo de memoria lo sigue literalmente, el tiempo de ejecución no cambia mucho. Para líneas de 0.5 M, la solicitud toma 1:44 y 1063 MB, para 2M 1:53 y 3762 MB.La velocidad no es particularmente agradable, y menos aún es que leer el archivo en fragmentos hace que sea necesario escribir funciones adaptadas para esto, trabajando con listas de fragmentos que luego deben ensamblarse en un marco de datos. Además, el formato csv en sí no es muy feliz, lo que ocupa mucho espacio y se lee lentamente.Como podemos conducir datos a una rampa, se puede usar un formato Apachev mucho más compacto para el almacenamientoparquet donde hay compresión y, gracias al esquema de datos, es mucho más rápido de leer cuando se lee. Y la rampa es bastante capaz de trabajar con él. Solo que ahora no puede leerlos en fragmentos. ¿Qué hacer?- ¡ Divirtámonos , toma el acordeón del botón Dask y acelera!Dask! Un sustituto de la rampa fuera de la caja, capaz de leer archivos de gran tamaño, capaz de trabajar en paralelo en varios núcleos y utilizando cálculos perezosos. Para mi sorpresa sobre Dask en Habré, solo hay 4 publicaciones .Entonces, tomamos el dask, introducimos el csv original en él y con una conversión mínima, lo llevamos al piso. Al leer, dask jura por la ambigüedad de los tipos de datos en algunas columnas, por lo que los configuramos explícitamente (en aras de la claridad, lo mismo se hizo para la rampa, el tiempo de funcionamiento es mayor teniendo en cuenta este factor, el diccionario con dtypes se corta para mayor claridad en todas las consultas), el resto es para él . Además, para la verificación, realizamos pequeñas mejoras en el piso, es decir, tratamos de reducir los tipos de datos a los más compactos, reemplazar un par de columnas con texto sí / no con booleanos y convertir otros datos a los tipos más económicos (para el número de cilindros del motor, uint8 es definitivamente suficiente). Guardamos el piso optimizado por separado y vemos lo que obtenemos.Lo primero que agrada cuando trabajamos con Dask es que no necesitamos escribir nada superfluo simplemente porque tenemos datos densos. Si no presta atención al hecho de que se importa el dask, y no la rampa, todo se ve igual que procesar un archivo con cien líneas en la rampa (más un par de silbatos decorativos para perfilar).def dask_query():
print('reading CSV file with dask')
with ProgressBar(), ResourceProfiler(dt=0.25) as rprof:
raw_data=dd.read_csv('C:\Open_data\RDW_full.CSV')
model_df=raw_data[raw_data['Merk'].isin(['TESLA MOTORS','TESLA'])]
print(model_df['Taxi indicator'].value_counts().compute())
rprof.visualize()
Ahora compare el impacto del archivo fuente en el rendimiento cuando trabaje con dasko. Primero leemos el mismo archivo csv que cuando trabajamos con la rampa. Lo mismo sobre dos minutos y dos gigabytes de memoria (1:38 2096 Mb). Parecería, ¿valió la pena besarse en los arbustos?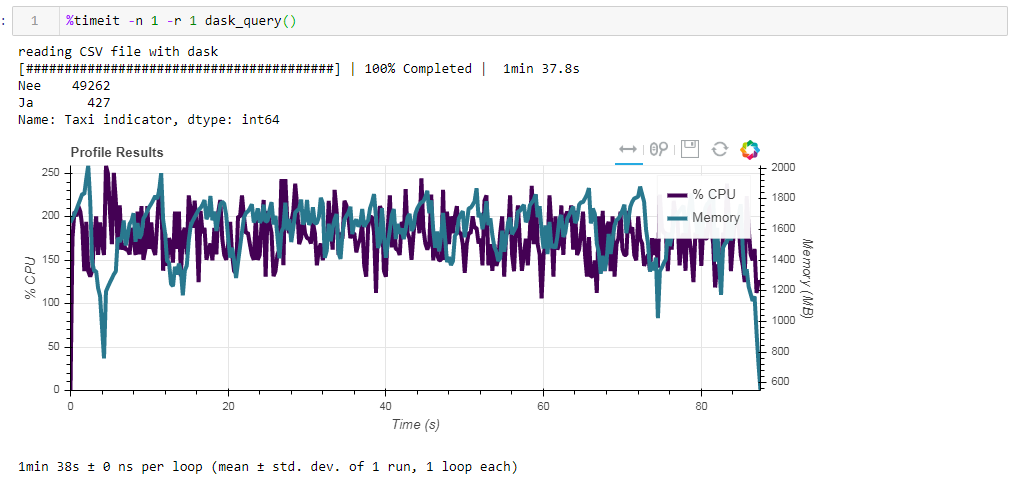 Ahora alimente el tablero con un archivo de parquet no optimizado. La solicitud se procesó en aproximadamente 54 segundos, consumiendo 1388 MB de memoria, y el archivo en sí para la solicitud ahora es 10 veces más pequeño (aproximadamente 700 MB). Aquí los bonos ya son visibles de forma convexa. La utilización de la CPU de cientos de por ciento es la paralelización en varios núcleos.
Ahora alimente el tablero con un archivo de parquet no optimizado. La solicitud se procesó en aproximadamente 54 segundos, consumiendo 1388 MB de memoria, y el archivo en sí para la solicitud ahora es 10 veces más pequeño (aproximadamente 700 MB). Aquí los bonos ya son visibles de forma convexa. La utilización de la CPU de cientos de por ciento es la paralelización en varios núcleos.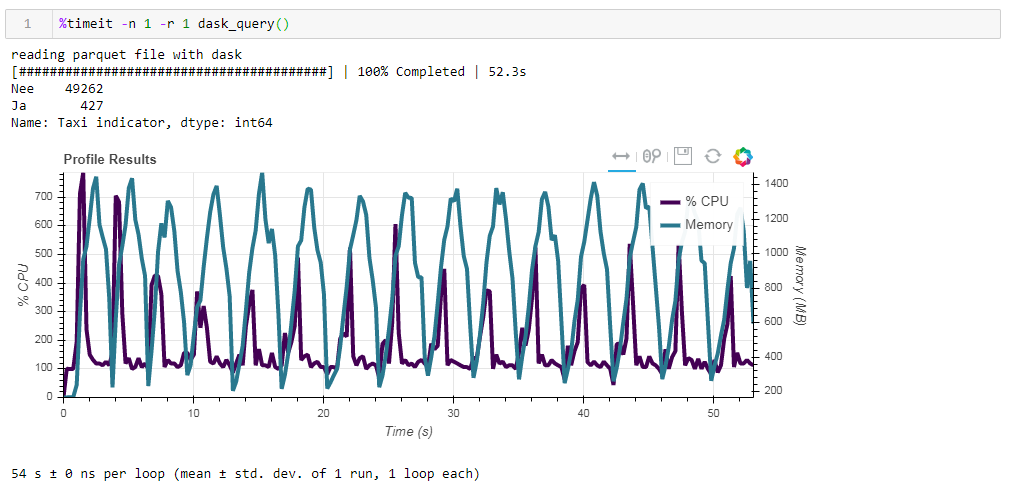 El parquet previamente optimizado con tipos de datos ligeramente modificados en forma comprimida es solo 1 MB menos, lo que significa que sin pistas todo se comprime de manera bastante eficiente. El aumento de la productividad tampoco es particularmente significativo. La solicitud tarda los mismos 53 segundos y consume un poco menos de memoria: 1332 MB.Según los resultados de nuestros ejercicios, podemos decir lo siguiente:
El parquet previamente optimizado con tipos de datos ligeramente modificados en forma comprimida es solo 1 MB menos, lo que significa que sin pistas todo se comprime de manera bastante eficiente. El aumento de la productividad tampoco es particularmente significativo. La solicitud tarda los mismos 53 segundos y consume un poco menos de memoria: 1332 MB.Según los resultados de nuestros ejercicios, podemos decir lo siguiente:- Si sus datos son "gordos" y está acostumbrado a una rampa, el tamaño de trozo ayudará a la rampa a digerir este volumen, la velocidad será soportable.
- Si desea obtener más velocidad, ahorre espacio durante el almacenamiento y no se está reteniendo con solo una rampa, entonces el anochecer con parquet es una buena combinación.
Finalmente, sobre computación perezosa. Una de las características del dask es que utiliza cálculos perezosos, es decir, los cálculos no se realizan inmediatamente como se encuentran en el código, sino cuando realmente son necesarios o cuando lo solicitó explícitamente utilizando el método de cálculo. Por ejemplo, en nuestra función, dask no lee todos los datos en la memoria cuando le indicamos que lea el archivo. Los lee más tarde, y solo las columnas que se relacionan con la solicitud.Esto se ve fácilmente en el siguiente ejemplo. Tomamos un archivo prefiltrado en el que dejamos solo 12 columnas de las 64 iniciales, el parquet comprimido ocupa 203 MB. Si ejecuta nuestra solicitud habitual, se ejecutará en 8.8 segundos, y el uso máximo de memoria será de aproximadamente 300 MB, lo que corresponde a una décima parte del archivo comprimido si lo supera en un csv simple.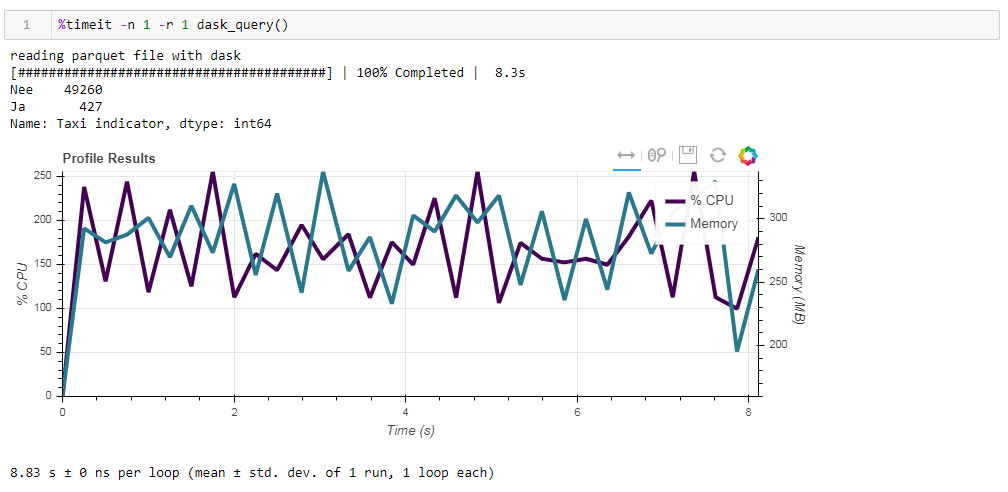 Si le solicitamos explícitamente que lea el archivo y luego ejecute la solicitud, el consumo de memoria será casi 10 veces mayor. Modificamos ligeramente nuestra función al leer explícitamente el archivo:
Si le solicitamos explícitamente que lea el archivo y luego ejecute la solicitud, el consumo de memoria será casi 10 veces mayor. Modificamos ligeramente nuestra función al leer explícitamente el archivo:def dask_query():
print('reading parquet file with dask')
with ProgressBar(), ResourceProfiler(dt=0.25) as rprof:
raw_data=dd.read_parquet('C:\Open_data\RDW_filtered.parquet' ).compute()
model_df=raw_data[raw_data['Merk'].isin(['TESLA MOTORS','TESLA'])]
print(model_df['Taxi indicator'].value_counts())
rprof.visualize()
Y esto es lo que obtenemos, 10.5 segundos y 3568 MB de memoria (!)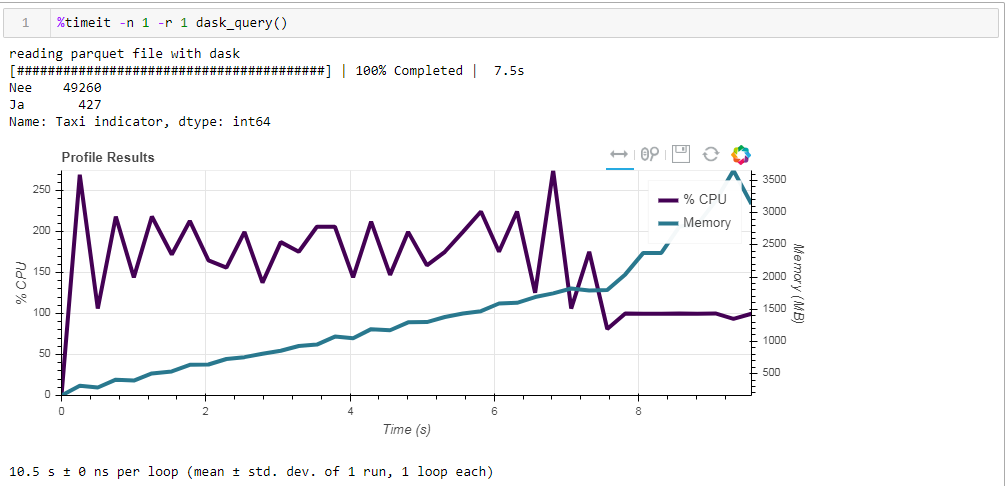 Una vez más, estamos convencidos de que el desperdicio es competente en sus tareas, y no vale la pena volver a meterse en él con la microgestión una vez más.
Una vez más, estamos convencidos de que el desperdicio es competente en sus tareas, y no vale la pena volver a meterse en él con la microgestión una vez más.