En este artículo, le diré cómo configurar un entorno de aprendizaje automático en 30 minutos, crear una red neuronal para el reconocimiento de imágenes y luego ejecutar la misma red en una unidad de procesamiento de gráficos (GPU).Primero, definamos qué es una red neuronal.En nuestro caso, este es un modelo matemático, así como su implementación de software o hardware, construido sobre el principio de organización y funcionamiento de redes neuronales biológicas: redes de células nerviosas de un organismo vivo. Este concepto surgió en el estudio de los procesos que ocurren en el cerebro y en un intento de simular estos procesos.Las redes neuronales no están programadas en el sentido habitual de la palabra, están entrenadas. La capacidad de aprendizaje es una de las principales ventajas de las redes neuronales sobre los algoritmos tradicionales. Técnicamente, el entrenamiento consiste en encontrar los coeficientes de conexión entre las neuronas. En el proceso de aprendizaje, la red neuronal puede identificar relaciones complejas entre entrada y salida, así como realizar generalizaciones.Desde el punto de vista del aprendizaje automático, una red neuronal es un caso especial de métodos de reconocimiento de patrones, análisis discriminante, métodos de agrupamiento y otros métodos.Equipo
Primero, tratemos con el equipo. Necesitamos un servidor con el sistema operativo Linux instalado. El equipo para el funcionamiento de los sistemas de aprendizaje automático requiere un sistema suficientemente potente y, como consecuencia, costoso. Para aquellos que no tienen un buen automóvil a mano, les recomiendo prestar atención a la oferta de los proveedores de la nube. El servidor necesario se puede alquilar rápidamente y pagar solo por el tiempo de uso.En proyectos en los que es necesario crear redes neuronales, utilizo los servidores de uno de los proveedores de la nube rusa. La compañía ofrece servidores en la nube de alquiler específicamente para el aprendizaje automático con potentes unidades de procesamiento de gráficos (GPU) Tesla V100 de NVIDIA. En resumen: usar un servidor con una GPU puede ser docenas de veces más eficiente (rápido) en comparación con un servidor que es similar en costo y usa una CPU (un procesador central conocido) para los cálculos. Esto se logra debido a los detalles de la arquitectura GPU, que maneja los cálculos más rápido.Para realizar los ejemplos que se describen a continuación, compramos el siguiente servidor durante varios días:- SSD de 150 GB
- RAM 32 GB
- Procesador Tesla V100 de 16 Gb con 4 núcleos
Ubuntu 18.04 fue instalado en la máquina.Establecer el entorno
Ahora instale en el servidor todo lo que necesita para trabajar. Dado que nuestro artículo es principalmente para principiantes, hablaré sobre algunos puntos que les serán útiles.Mucho trabajo al configurar el entorno se realiza a través de la línea de comando. La mayoría de los usuarios usan Windows como un SO operativo. La consola estándar en este sistema operativo deja mucho que desear. Por lo tanto, utilizaremos la herramienta / Cmder conveniente . Descargue la versión mini y ejecute Cmder.exe. A continuación, debe conectarse al servidor a través de SSH:ssh root@server-ip-or-hostname
En lugar de server-ip-or-hostname, especifique la dirección IP o el nombre DNS de su servidor. Luego, ingrese la contraseña y luego de una conexión exitosa, deberíamos obtener algo como esto.Welcome to Ubuntu 18.04.3 LTS (GNU/Linux 4.15.0-74-generic x86_64)
El lenguaje principal para desarrollar modelos ML es Python. Y la plataforma más popular para usarlo en Linux es Anaconda .Instálalo en nuestro servidor.Comenzamos actualizando el administrador de paquetes local:sudo apt-get update
Instale curl (utilidad de línea de comando):sudo apt-get install curl
Descargue la última versión de Anaconda Distribution:cd /tmp
curl –O https://repo.anaconda.com/archive/Anaconda3-2019.10-Linux-x86_64.sh
Comenzamos la instalación:bash Anaconda3-2019.10-Linux-x86_64.sh
Durante el proceso de instalación, deberá confirmar el acuerdo de licencia. En una instalación exitosa, debería ver esto:Thank you for installing Anaconda3!
Para desarrollar modelos de ML, ahora se crean muchos marcos, trabajamos con los más populares: PyTorch y Tensorflow .El uso del marco le permite aumentar la velocidad de desarrollo y utilizar herramientas preparadas para tareas estándar.En este ejemplo, trabajaremos con PyTorch. Instalarlo:conda install pytorch torchvision cudatoolkit=10.1 -c pytorch
Ahora tenemos que lanzar Jupyter Notebook, una herramienta de desarrollo popular entre los especialistas de ML. Le permite escribir código e inmediatamente ver los resultados de su ejecución. Jupyter Notebook es parte de Anaconda y ya está instalado en nuestro servidor. Necesita conectarse desde nuestro sistema de escritorio.Para hacer esto, primero ejecutamos Jupyter en el servidor especificando el puerto 8080:jupyter notebook --no-browser --port=8080 --allow-root
Luego, abriendo otra pestaña en nuestra consola Cmder (el menú superior es el cuadro de diálogo Nueva consola), conéctese en el puerto 8080 al servidor a través de SSH:ssh -L 8080:localhost:8080 root@server-ip-or-hostname
Cuando ingrese el primer comando, se nos ofrecerán enlaces para abrir Jupyter en nuestro navegador:To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-18788-open.html
Or copy and paste one of these URLs:
http://localhost:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
or http://127.0.0.1:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
Use el enlace para localhost: 8080. Copie la ruta completa y péguela en la barra de direcciones del navegador local de su PC. Se abre el cuaderno Jupyter.Creemos una nueva computadora portátil: Nueva - Computadora portátil - Python 3.Verifique el funcionamiento correcto de todos los componentes que instalamos. Introducimos un ejemplo de código PyTorch en Jupyter y comenzamos la ejecución (botón Ejecutar):from __future__ import print_function
import torch
x = torch.rand(5, 3)
print(x)
El resultado debería ser algo como esto: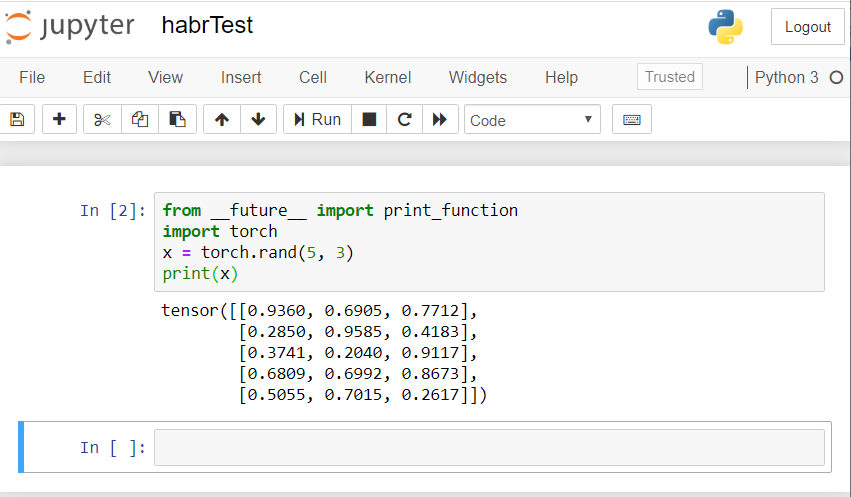 si tiene un resultado similar, ¡entonces todos estamos configurados correctamente y podemos comenzar a desarrollar una red neuronal!
si tiene un resultado similar, ¡entonces todos estamos configurados correctamente y podemos comenzar a desarrollar una red neuronal!Crea una red neuronal
Crearemos una red neuronal para el reconocimiento de imágenes. Tomamos esta guía como base .Para capacitar a la red, utilizaremos el conjunto de datos CIFAR10 disponible al público. Tiene clases: "avión", "auto", "pájaro", "gato", "venado", "perro", "rana", "caballo", "barco", "camión". Las imágenes en CIFAR10 tienen un tamaño de 3x32x32, es decir, imágenes en color de 3 canales de 32x32 píxeles.Para el trabajo, utilizaremos el paquete PyTorch creado para trabajar con imágenes: torchvision.Tomaremos los siguientes pasos en orden:- Descargue y normalice los conjuntos de datos de entrenamiento y prueba
- Definición de red neuronal
- Red de formación sobre datos de formación.
- Probar la red con datos de prueba
- Repita el entrenamiento y las pruebas de GPU
Todo el código a continuación lo ejecutaremos en el Jupyter Notebook.Descargar y normalizar CIFAR10
Copie y ejecute el siguiente código en Jupyter:
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
La respuesta debería ser así:Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verified
Derivaremos varias imágenes de entrenamiento para verificar:
import matplotlib.pyplot as plt
import numpy as np
def imshow(img):
img = img / 2 + 0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
dataiter = iter(trainloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

Definición de red neuronal
Examinemos primero cómo funciona una red neuronal para el reconocimiento de imágenes. Esta es una red de conexión directa simple. Toma entrada, la pasa a través de varias capas una por una, y finalmente da la salida.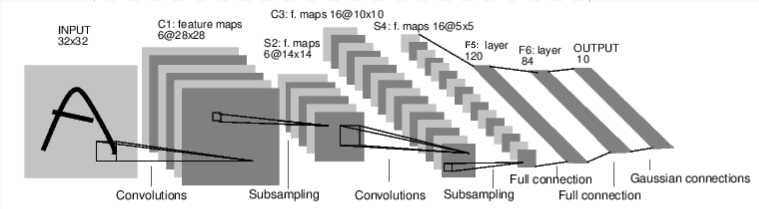 Creemos una red similar en nuestro entorno:
Creemos una red similar en nuestro entorno:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
También definimos la función de pérdida y el optimizador.
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
Red de formación sobre datos de formación.
Comenzamos a entrenar nuestra red neuronal. Le llamo la atención sobre el hecho de que después de esto, mientras ejecuta este código, tendrá que esperar un tiempo hasta que se complete el trabajo. Me llevó 5 minutos. La creación de redes lleva tiempo. for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
Obtenemos el siguiente resultado: Guardamos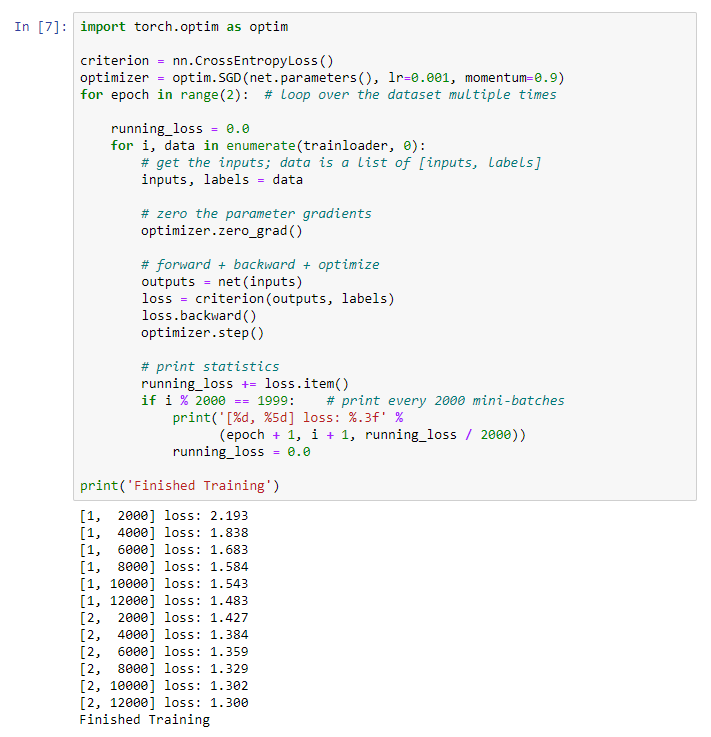 nuestro modelo entrenado:
nuestro modelo entrenado:PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
Probar la red con datos de prueba
Capacitamos a la red utilizando un conjunto de datos de capacitación. Pero debemos verificar si la red ha aprendido algo.Verificaremos esto prediciendo la etiqueta de clase que produce la red neuronal y verificando la verdad. Si el pronóstico es correcto, agregamos la muestra a la lista de pronósticos correctos.Vamos a mostrar la imagen del conjunto de pruebas:dataiter = iter(testloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
 Ahora pida a la red neuronal que nos diga qué hay en estas imágenes:
Ahora pida a la red neuronal que nos diga qué hay en estas imágenes:
net = Net()
net.load_state_dict(torch.load(PATH))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))
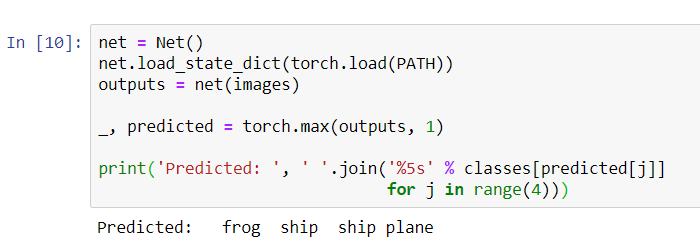 Los resultados parecen bastante buenos: la red identificó correctamente tres de las cuatro imágenes.Veamos cómo funciona la red en todo el conjunto de datos.
Los resultados parecen bastante buenos: la red identificó correctamente tres de las cuatro imágenes.Veamos cómo funciona la red en todo el conjunto de datos.
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
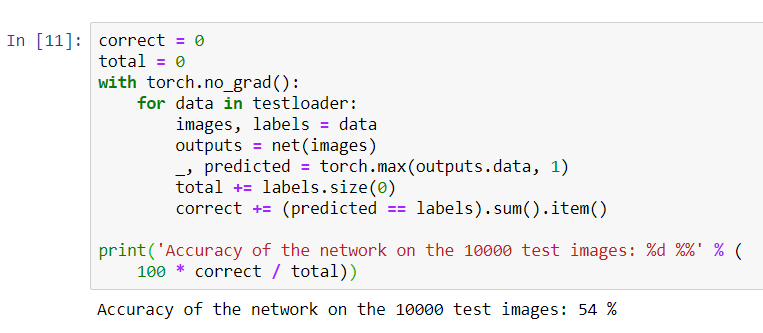 Parece que la red lo sabe y funciona. Si definió las clases al azar, la precisión sería del 10%.Ahora veamos qué clases define mejor la red:
Parece que la red lo sabe y funciona. Si definió las clases al azar, la precisión sería del 10%.Ahora veamos qué clases define mejor la red:class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
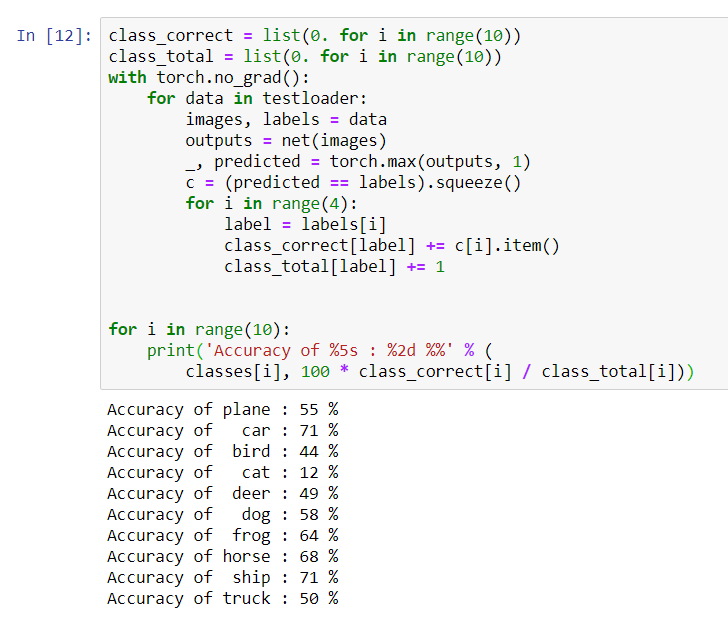 Parece que la red determina mejor los autos y las naves: 71% de precisión.Entonces la red está funcionando. Ahora intentemos transferir su trabajo al procesador gráfico (GPU) y ver qué cambios.
Parece que la red determina mejor los autos y las naves: 71% de precisión.Entonces la red está funcionando. Ahora intentemos transferir su trabajo al procesador gráfico (GPU) y ver qué cambios.Entrenamiento de red neuronal GPU
Primero, explicaré brevemente qué es CUDA. CUDA (Compute Unified Device Architecture) es una plataforma de computación paralela desarrollada por NVIDIA para computación general en GPU. Con CUDA, los desarrolladores pueden acelerar significativamente las aplicaciones informáticas utilizando las capacidades de las GPU. En nuestro servidor que compramos, esta plataforma ya está instalada.Primero definamos nuestra GPU como el primer dispositivo cuda visible.device = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" )
print ( device )
 Enviar la red a la GPU:
Enviar la red a la GPU:net.to(device)
También tendremos que enviar aportes y objetivos en cada paso y a la GPU:inputs, labels = data[0].to(device), data[1].to(device)
Ejecute el reciclaje de red que ya está en la GPU:import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
Esta vez, la capacitación en red duró aproximadamente 3 minutos. Recuerde que la misma etapa en un procesador normal duró 5 minutos. La diferencia no es significativa, esto se debe a que nuestra red no es tan grande. Cuando se utilizan matrices grandes para el entrenamiento, aumentará la diferencia entre la velocidad de la GPU y el procesador tradicional.Eso parece ser todo. Lo que logramos hacer:- Examinamos qué es la GPU y elegimos el servidor en el que está instalado;
- Configuramos un entorno de software para crear una red neuronal;
- Creamos una red neuronal para el reconocimiento de imágenes y la capacitamos;
- Repetimos el entrenamiento de la red usando la GPU y recibimos un aumento en la velocidad.
Estaré encantado de responder preguntas en los comentarios.