Kafka Streams es una biblioteca de Java para analizar y procesar datos almacenados en Apache Kafka. Al igual que con cualquier otra plataforma de procesamiento de transmisión, es capaz de realizar el procesamiento de datos con y / o sin preservación del estado en tiempo real. En esta publicación intentaré describir por qué lograr una alta disponibilidad (99.99%) es problemático en Kafka Streams y qué podemos hacer para lograrlo.Que necesitamos saber
Antes de describir el problema y las posibles soluciones, veamos los conceptos básicos de Kafka Streams. Si ha trabajado con las API de Kafka para consumidores / productores, entonces la mayoría de estos paradigmas le son familiares. En las siguientes secciones, intentaré describir en pocas palabras el almacenamiento de datos en particiones, el reequilibrio de los grupos de consumidores y cómo los conceptos básicos de los clientes de Kafka se ajustan a la biblioteca de Kafka Streams.Kafka: Particionando datos
En el mundo de Kafka, las aplicaciones de productores envían datos como pares clave-valor a un tema específico. El tema en sí está dividido en una o más particiones en los corredores de Kafka. Kafka utiliza una clave de mensaje para indicar en qué partición se deben escribir los datos. En consecuencia, los mensajes con la misma clave siempre terminan en la misma partición.Las aplicaciones de consumo se organizan en grupos de consumidores, y cada grupo puede tener una o más instancias de consumidores.Cada instancia de un consumidor en el grupo de consumidores es responsable de procesar los datos de un conjunto único de particiones del tema de entrada.
Las instancias del consumidor son esencialmente un medio para ampliar el procesamiento en su grupo de consumidores.Kafka: reequilibrio del grupo de consumidores
Como dijimos anteriormente, cada instancia del grupo de consumidores recibe un conjunto de particiones únicas de las que consume datos. Cada vez que un nuevo consumidor se une a un grupo, debe realizarse un reequilibrio para obtener una partición. Lo mismo sucede cuando el consumidor muere, el resto del consumidor debe tomar sus particiones para asegurarse de que se procesen todas las particiones.Kafka Streams: corrientes
Al comienzo de esta publicación, nos familiarizamos con el hecho de que la biblioteca Kafka Streams está construida sobre la base de API de productores y consumidores y el procesamiento de datos está organizado de la misma manera que la solución estándar en Kafka. En la configuración de Kafka Streams, el campo application.id es equivalente a group.iden la API del consumidor. Kafka Streams crea previamente un cierto número de subprocesos y cada uno de ellos realiza el procesamiento de datos de una o más particiones de temas de entrada. Hablando en la terminología de la API del consumidor, las transmisiones coinciden esencialmente con instancias del consumidor del mismo grupo. Los subprocesos son la forma principal de escalar el procesamiento de datos en Kafka Streams, esto se puede hacer verticalmente aumentando el número de subprocesos para cada aplicación de Kafka Streams en una máquina, u horizontalmente agregando una máquina adicional con el mismo application.id.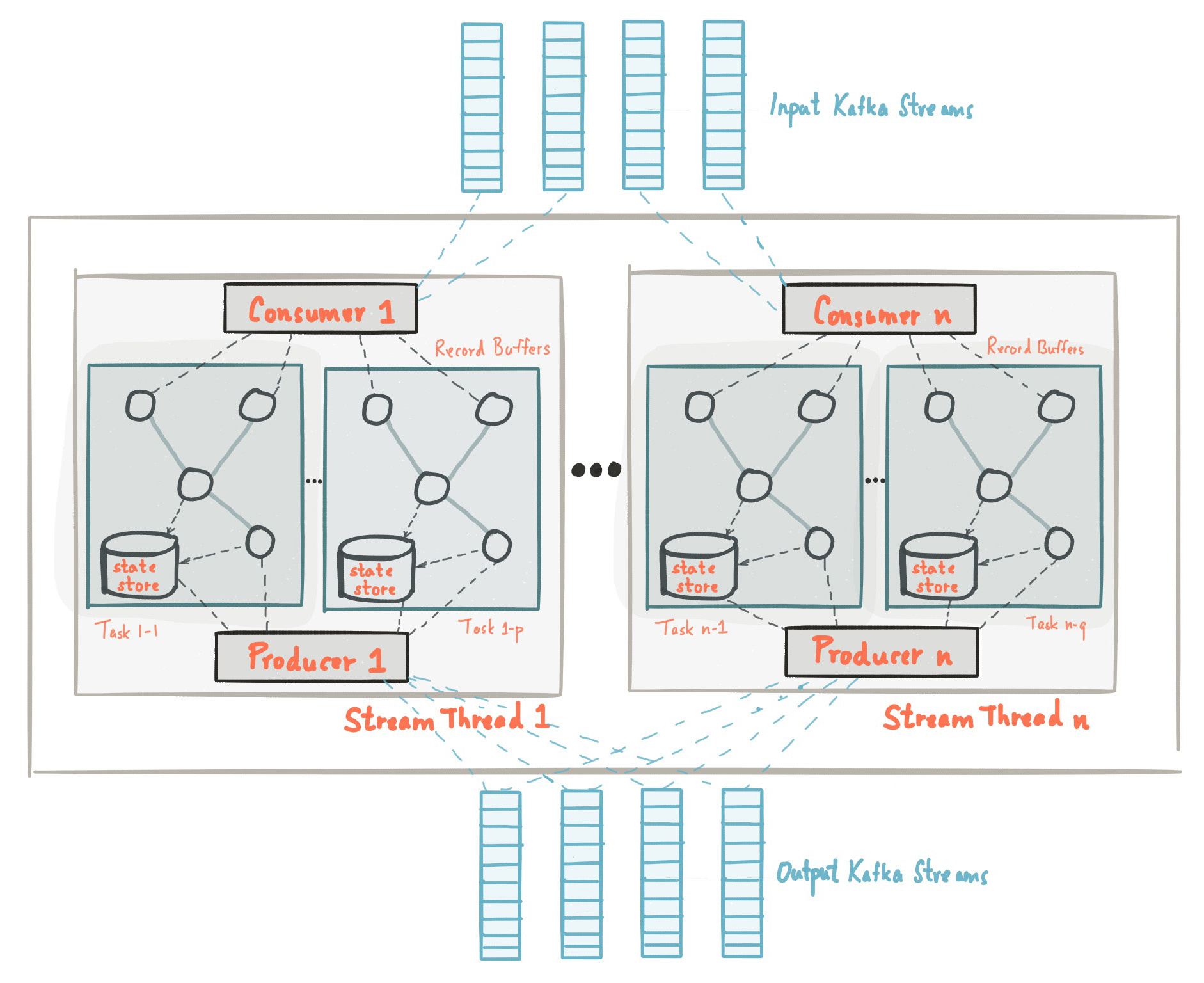 Fuente: kafka.apache.org/21/documentation/streams/architectureHay muchos más elementos en Kafka Streams, como tareas, topología de procesamiento, modelo de subprocesos, etc., que no discutiremos en esta publicación. Más información se puede encontrar aquí.
Fuente: kafka.apache.org/21/documentation/streams/architectureHay muchos más elementos en Kafka Streams, como tareas, topología de procesamiento, modelo de subprocesos, etc., que no discutiremos en esta publicación. Más información se puede encontrar aquí.Kafka Streams: almacenamiento estatal
En el procesamiento continuo, hay operaciones con y sin preservación del estado. El estado es lo que permite que la aplicación recuerde la información necesaria que va más allá del alcance del registro que se está procesando actualmente.Las operaciones estatales, como conteo, cualquier tipo de agregación, uniones, etc., son mucho más complicadas. Esto se debe al hecho de que al tener solo un registro, no puede determinar el último estado (por ejemplo, contar) para una clave determinada, por lo que debe almacenar el estado de su transmisión en su aplicación. Como discutimos anteriormente, cada subproceso procesa un conjunto de particiones únicas; por lo tanto, un subproceso procesa solo un subconjunto del conjunto de datos completo. Esto significa que cada subproceso de aplicación de Kafka Streams con el mismo application.id mantiene su propio estado aislado. No entraremos en detalles sobre cómo se forma el estado en Kafka Streams, pero es importante comprender que los estados se restauran utilizando el tema de registro de cambios (tema de registro de cambios) y se guardan no solo en el disco local, sino también en Kafka Broker.Guardar el registro de cambios de estado en Kafka Broker como un tema separado está hecho no solo para la tolerancia a fallas, sino también para que pueda implementar fácilmente nuevas instancias de Kafka Streams con el mismo application.id. Dado que el estado se almacena como un tema de registro de cambios en el lado del intermediario, una nueva instancia puede cargar su propio estado desde este tema.Puede encontrar más información sobre el almacenamiento estatal aquí .¿Por qué la alta disponibilidad es problemática con Kafka Streams?
Revisamos los conceptos y principios básicos del procesamiento de datos con Kafka Streams. Ahora intentemos combinar todas las partes y analizar por qué lograr una alta disponibilidad puede ser problemático. De las secciones anteriores, debemos recordar:- Los datos en el tema de Kafka se dividen en particiones, que se distribuyen entre las secuencias de Kafka Streams.
- Las aplicaciones de Kafka Streams con el mismo application.id son, de hecho, un grupo de consumidores, y cada uno de sus hilos es una instancia aislada separada del consumidor.
- Para las operaciones de estado, el hilo mantiene su propio estado, que está "reservado" por el tema de Kafka en forma de un registro de cambios.
- , Kafka , .
TransferWise SPaaS (Stream Processing as a Service)
Antes de resaltar la esencia de esta publicación, déjenme decirles primero lo que creamos en TransferWise y por qué la alta disponibilidad es muy importante para nosotros.En TransferWise, tenemos varios nodos para el procesamiento de transmisión, y cada nodo contiene varias instancias de Kafka Streams para cada equipo de producto. Las instancias de Kafka Streams que están diseñadas para un equipo de desarrollo específico tienen un application.id especial y generalmente tienen más de 5 subprocesos. En general, los equipos suelen tener 10-20 hilos (equivalentes al número de instancias de consumidores) en todo el clúster. Las aplicaciones que se implementan en los nodos escuchan temas de entrada y realizan varios tipos de operaciones con y sin estado en los datos de entrada y proporcionan actualizaciones de datos en tiempo real para los microservicios posteriores posteriores.Los equipos de productos necesitan actualizar los datos agregados en tiempo real. Esto es necesario para proporcionar a nuestros clientes la capacidad de transferir dinero instantáneamente. Nuestro SLA habitual:En cualquier día, el 99,99% de los datos agregados deberían estar disponibles en menos de 10 segundos.
Para darle una idea, durante las pruebas de estrés, Kafka Streams pudo procesar y agregar 20.085 mensajes de entrada por segundo. Por lo tanto, 10 segundos de SLA bajo carga normal sonaban bastante alcanzables. Desafortunadamente, nuestro SLA no se alcanzó durante la actualización continua de los nodos en los que se implementan las aplicaciones, y a continuación describiré por qué sucedió esto.Actualización de nodo deslizante
En TransferWise, creemos firmemente en la entrega continua de nuestro software y generalmente lanzamos nuevas versiones de nuestros servicios un par de veces al día. Veamos un ejemplo de una simple actualización continua del servicio y veamos qué sucede durante el proceso de lanzamiento. Nuevamente, debemos recordar que:- Los datos en el tema de Kafka se dividen en particiones, que se distribuyen entre las secuencias de Kafka Streams.
- Las aplicaciones de Kafka Streams con el mismo application.id son, de hecho, un grupo de consumidores, y cada uno de sus hilos es una instancia aislada separada del consumidor.
- Para las operaciones de estado, el hilo mantiene su propio estado, que está "reservado" por el tema de Kafka en forma de un registro de cambios.
- , Kafka , .
Un proceso de liberación en un solo nodo generalmente toma de ocho a nueve segundos. Durante el lanzamiento, las instancias de Kafka Streams en el nodo "se reinician suavemente". Por lo tanto, para un solo nodo, el tiempo requerido para reiniciar correctamente el servicio es de aproximadamente ocho a nueve segundos. Obviamente, cerrar una instancia de Kafka Streams en un nodo provoca un reequilibrio del grupo de consumidores. Dado que los datos están particionados, todas las particiones que pertenecían a la instancia de arranque deben distribuirse entre las aplicaciones activas de Kafka Streams con el mismo application.id. Esto también se aplica a los datos agregados que se han guardado en el disco. Hasta que este proceso se complete, los datos no serán procesados.Réplicas en espera
Para reducir el tiempo de reequilibrio para las aplicaciones de Kafka Streams, existe un concepto de réplicas de respaldo, que se definen en la configuración como num.standby.replicas. Las réplicas de respaldo son copias del almacén estatal local. Este mecanismo permite replicar la tienda de estado de una instancia de Kafka Streams a otra. Cuando el hilo de Kafka Streams muere por cualquier motivo, la duración del proceso de recuperación de estado se puede minimizar. Desafortunadamente, por las razones que explicaré a continuación, incluso las réplicas de respaldo no ayudarán con una actualización continua del servicio.Supongamos que tenemos dos instancias de Kafka Streams en dos máquinas diferentes: nodo-a y nodo-b. Para cada una de las instancias de Kafka Streams, num.standby.replicas = 1 se indica en estos 2 nodos. Con esta configuración, cada instancia de Kafka Streams mantiene su copia del almacenamiento en otro nodo. Durante una actualización continua, tenemos la siguiente situación:- La nueva versión del servicio se ha implementado en el nodo-a.
- La instancia de Kafka Streams en el nodo-a está deshabilitada.
- El reequilibrio ha comenzado.
- El repositorio del nodo-a ya se ha replicado en el nodo-b, ya que especificamos la configuración num.standby.replicas = 1.
- El nodo-b ya tiene una copia oculta del nodo-a, por lo que el proceso de reequilibrio ocurre casi al instante.
- El nodo-a se inicia de nuevo.
- node-a se une a un grupo de consumidores.
- El corredor de Kafka ve una nueva instancia de Kafka Streams y comienza a reequilibrar.
Como podemos ver, num.standby.replicas solo ayuda en escenarios de un apagado completo de un nodo. Esto significa que si el nodo-a se bloquea, entonces el nodo-b podría continuar funcionando correctamente casi instantáneamente. Pero en una situación de actualización continua, después de desconectarse, el nodo-a se unirá nuevamente al grupo, y este último paso provocará un reequilibrio. Cuando el nodo-a se une al grupo de consumidores después de un reinicio, se considerará como una nueva instancia del consumidor. Nuevamente, debemos recordar que el procesamiento de datos en tiempo real se detiene hasta que una nueva instancia restaura su estado del tema del registro de cambios.Tenga en cuenta que el reequilibrio de particiones cuando una nueva instancia se une a un grupo no se aplica a la API de Kafka Streams, ya que así es exactamente como funciona el protocolo del grupo de consumidores Apache Kafka.Logro: Alta disponibilidad con Kafka Streams
A pesar del hecho de que las bibliotecas de cliente de Kafka no proporcionan una funcionalidad integrada para el problema mencionado anteriormente, existen algunos trucos que se pueden usar para lograr una alta disponibilidad de clúster durante una actualización continua. La idea detrás de las réplicas de respaldo sigue siendo válida, y tener máquinas de respaldo cuando sea el momento adecuado es una buena solución que utilizamos para garantizar una alta disponibilidad en caso de falla de la instancia.El problema con nuestra configuración inicial fue que teníamos un grupo de consumidores para todos los equipos en todos los nodos. Ahora, en lugar de un grupo de consumidores, tenemos dos, y el segundo actúa como un clúster "activo". En prod, los nodos tienen una variable especial CLUSTER_ID, que se agrega al application.id de las instancias de Kafka Streams. Aquí hay una muestra de la configuración Spring boot application.yml:application.ymlspring.profiles: production
streaming-pipelines:
team-a-stream-app-id: "${CLUSTER_ID}-team-a-stream-app"
team-b-stream-app-id: "${CLUSTER_ID}-team-b-stream-app"
En un momento dado, solo uno de los clústeres está en modo activo, respectivamente, el clúster de respaldo no envía mensajes en tiempo real a microservicios posteriores. Durante el lanzamiento del lanzamiento, el clúster de respaldo se activa, lo que permite una actualización continua en el primer clúster. Dado que este es un grupo de consumidores completamente diferente, nuestros clientes ni siquiera notan ninguna violación en el procesamiento, y los servicios posteriores continúan recibiendo mensajes del grupo recientemente activo. Una de las desventajas obvias de usar un grupo de consumidores de respaldo es la sobrecarga adicional y el consumo de recursos, pero, sin embargo, esta arquitectura proporciona garantías adicionales, control y tolerancia a fallas de nuestro sistema de procesamiento de transmisión.Además de agregar un clúster adicional, también hay trucos que pueden mitigar el problema con reequilibrios frecuentes.Aumentar group.initial.rebalance.delay.ms
A partir de Kafka 0.11.0.0, se ha agregado la configuración group.initial.rebalance.delay.ms. Según la documentación, esta configuración es responsable de:La cantidad de tiempo en milisegundos que GroupCoordinator retrasará el reequilibrio inicial del consumidor del grupo.
Por ejemplo, si establecemos 60,000 milisegundos en esta configuración, entonces con una actualización continua podemos tener una ventana de minutos para el lanzamiento de la versión. Si la instancia de Kafka Streams se reinicia correctamente en esta ventana de tiempo, no se llamará a reequilibrar. Tenga en cuenta que los datos de los que fue responsable la instancia reiniciada de Kafka Streams no estarán disponibles hasta que el nodo vuelva al modo en línea. Por ejemplo, si el reinicio de una instancia demora aproximadamente ocho segundos, tendrá ocho segundos de tiempo de inactividad para los datos de los que es responsable esta instancia.Cabe señalar que la principal desventaja de este concepto es que, en caso de falla de un nodo, recibirá un retraso adicional de un minuto durante la restauración, teniendo en cuenta la configuración actual.Reducción del tamaño del segmento en temas de registro de cambios
La gran demora en reequilibrar Kafka Stream se debe a la restauración de las tiendas estatales a partir de temas de registro de cambios. Los temas de registro de cambios son temas comprimidos, lo que le permite almacenar el último registro para una clave particular en el tema. Describiré brevemente este concepto a continuación.Los temas en Kafka Broker están organizados en segmentos. Cuando un segmento alcanza el tamaño de umbral configurado, se crea un nuevo segmento y el anterior se comprime. De manera predeterminada, este umbral se establece en 1 GB. Como sabrán, la estructura de datos principal que subyace a los temas de Kafka y sus particiones es la estructura de registro con una escritura directa, es decir, cuando se envían mensajes al tema, siempre se agregan al último segmento "activo", y la compresión no es pasandoPor lo tanto, la mayoría de los estados de almacenamiento almacenados en el registro de cambios siempre están en el archivo de "segmento activo" y nunca se comprimen, lo que genera millones de mensajes de registro de cambios sin comprimir. Para Kafka Streams, esto significa que durante el reequilibrio, cuando la instancia de Kafka Streams restaura su estado del tema del registro de cambios, necesita leer muchas entradas redundantes del tema del registro de cambios. Dado que las tiendas estatales solo se preocupan por el último estado y no por el historial, este tiempo de procesamiento se desperdicia. La reducción del tamaño del segmento causará una compresión de datos más agresiva, por lo que las nuevas instancias de aplicaciones Kafka Streams pueden recuperarse mucho más rápido.Conclusión
Aunque Kafka Streams no proporciona una capacidad incorporada para proporcionar alta disponibilidad durante una actualización continua del servicio, esto aún se puede hacer a nivel de infraestructura. Debemos recordar que Kafka Streams no es un "marco de clúster" a diferencia de Apache Flink o Apache Spark. Es una biblioteca ligera de Java que permite a los desarrolladores crear aplicaciones escalables para la transmisión de datos. A pesar de esto, proporciona los bloques de construcción necesarios para lograr objetivos de transmisión tan ambiciosos como la disponibilidad de "99.99%".