Regularmente me encuentro con una situación en la que muchos desarrolladores creen sinceramente que el índice en PostgreSQL es un cuchillo suizo que ayuda universalmente con cualquier problema de rendimiento de consultas. Es suficiente agregar un nuevo índice a la tabla o incluir el campo en algún lugar del existente, y luego (¡magia-magia!) Todas las consultas usarán este índice de manera efectiva. Primero, por supuesto, o no lo harán, o no de manera eficiente, o no todos. En segundo lugar, los índices adicionales solo agregarán problemas de rendimiento al escribir.Muy a menudo, tales situaciones ocurren durante el desarrollo "de larga duración", cuando no se fabrica un producto personalizado de acuerdo con el modelo "escribió una vez, dio, olvidó", pero, como en nuestro caso, se creóservicio con un largo ciclo de vida .Las mejoras se producen de forma iterativa por las fuerzas de muchos equipos distribuidos , que se distribuyen no solo en el espacio sino también en el tiempo. Y luego, sin conocer toda la historia del desarrollo del proyecto o las características de la distribución de datos aplicada en su base de datos, puede fácilmente "meterse" con los índices. Pero las consideraciones y las solicitudes de prueba bajo el corte le permiten predecir y detectar parte de los problemas de antemano:
Primero, por supuesto, o no lo harán, o no de manera eficiente, o no todos. En segundo lugar, los índices adicionales solo agregarán problemas de rendimiento al escribir.Muy a menudo, tales situaciones ocurren durante el desarrollo "de larga duración", cuando no se fabrica un producto personalizado de acuerdo con el modelo "escribió una vez, dio, olvidó", pero, como en nuestro caso, se creóservicio con un largo ciclo de vida .Las mejoras se producen de forma iterativa por las fuerzas de muchos equipos distribuidos , que se distribuyen no solo en el espacio sino también en el tiempo. Y luego, sin conocer toda la historia del desarrollo del proyecto o las características de la distribución de datos aplicada en su base de datos, puede fácilmente "meterse" con los índices. Pero las consideraciones y las solicitudes de prueba bajo el corte le permiten predecir y detectar parte de los problemas de antemano:- índices no utilizados
- prefijo "clones"
- marca de tiempo "en el medio"
- booleano indexable
- matrices en el índice
- Basura nula
Lo más simple es encontrar índices para los que no hubo pases en absoluto . Solo necesita asegurarse de que el restablecimiento de las estadísticas ( pg_stat_reset()) se haya producido hace mucho tiempo, y no desea eliminar el usado "raramente, pero adecuadamente". Usamos la vista del sistema pg_stat_user_indexes:SELECT * FROM pg_stat_user_indexes WHERE idx_scan = 0;
Pero incluso si se utiliza el índice y no se incluyó en esta selección, esto no significa en absoluto que sea adecuado para sus consultas.¿Qué índices son [no] adecuados
Para entender por qué algunas consultas "salen mal en el índice", pensaremos en la estructura de un índice btree regular , la instancia más frecuente en la naturaleza. Los índices de un solo campo generalmente no crean ningún problema, por lo tanto, consideramos los problemas que surgen en un compuesto de un par de campos.Una forma extremadamente simplificada, como se puede imaginar, es un "pastel en capas", donde en cada capa hay árboles ordenados de acuerdo con los valores del campo correspondiente en orden.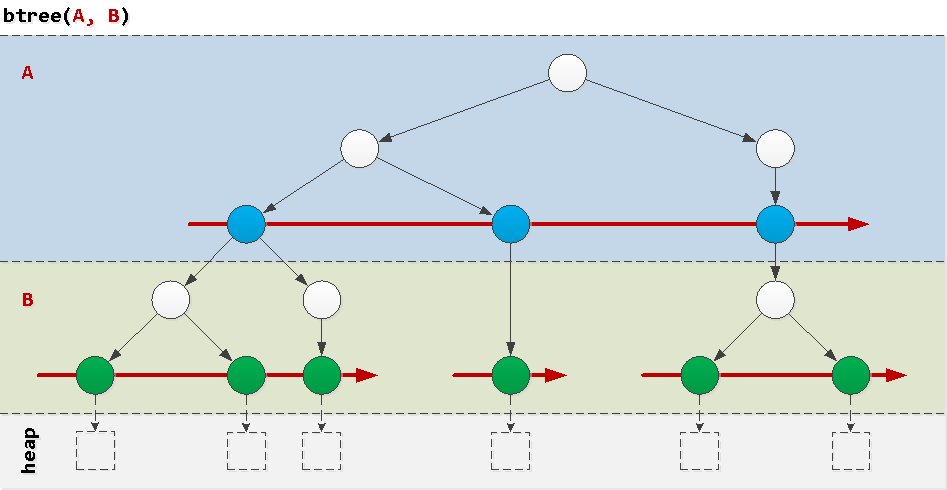 Ahora está claro que el campo A nivel mundial ordenó, y B - sólo dentro de un valor específico A . Veamos ejemplos de condiciones que ocurren en consultas reales y cómo "recorrerán" el índice.
Ahora está claro que el campo A nivel mundial ordenó, y B - sólo dentro de un valor específico A . Veamos ejemplos de condiciones que ocurren en consultas reales y cómo "recorrerán" el índice.Bueno: condición de prefijo
Tenga en cuenta que el índice btree(A, B)incluye un "subíndice" btree(A). Esto significa que todas las reglas descritas a continuación funcionarán para cualquier índice de prefijo.Es decir, si crea un índice más complejo que en nuestro ejemplo, algo del tipo btree(A, B, C): puede suponer que su base de datos "aparece" automáticamente:btree(A, B, C)btree(A, B)btree(A)
Y esto significa que la presencia "física" del índice de prefijo en la base de datos es redundante en la mayoría de los casos. Después de todo, cuantos más índices tiene que escribir una tabla, peor es para PostgreSQL, ya que llama Amplificación de escritura, Uber se quejó de ello (y aquí puede encontrar un análisis de sus afirmaciones ).Y si algo impide que la base viva bien, vale la pena encontrarla y eliminarla. Veamos un ejemplo:CREATE TABLE tbl(A integer, B integer, val integer);
CREATE INDEX ON tbl(A, B)
WHERE val IS NULL;
CREATE INDEX ON tbl(A)
WHERE val IS NULL;
CREATE INDEX ON tbl(A, B, val);
CREATE INDEX ON tbl(A);
Consulta de búsqueda de índice de prefijoWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid AND
idx.indexprs IS NULL
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, pre AS (
SELECT
nmt
, wh
, nmf$
, tpf$
, nmi
, def
FROM
fld
ORDER BY
1, 2, 3
)
SELECT DISTINCT
Y.*
FROM
pre X
JOIN
pre Y
ON Y.nmi <> X.nmi AND
(Y.nmt, Y.wh) IS NOT DISTINCT FROM (X.nmt, X.wh) AND
(
Y.nmf$[1:array_length(X.nmf$, 1)] = X.nmf$ OR
X.nmf$[1:array_length(Y.nmf$, 1)] = Y.nmf$
)
ORDER BY
1, 2, 3;
Idealmente, debería obtener una selección vacía, pero mire, estos son nuestros grupos de índices sospechosos:nmt | wh | nmf$ | tpf$ | nmi | def
---------------------------------------------------------------------------------------
tbl | (val IS NULL) | {a} | {int4} | tbl_a_idx | CREATE INDEX ...
tbl | (val IS NULL) | {a,b} | {int4,int4} | tbl_a_b_idx | CREATE INDEX ...
tbl | | {a} | {int4} | tbl_a_idx1 | CREATE INDEX ...
tbl | | {a,b,val} | {int4,int4,int4} | tbl_a_b_val_idx | CREATE INDEX ...
Luego, usted decide para cada grupo usted mismo si valió la pena eliminar el índice más corto o si el más largo no era necesario.Bien: todas las constantes excepto el último campo
Si los valores de todos los campos del índice, excepto el último, están establecidos por constantes (en nuestro ejemplo, este es el campo A), el índice se puede usar normalmente. En este caso, el valor del último campo se puede establecer de forma arbitraria: constante, desigualdad, intervalo, marcación IN (...)o = ANY(...). Y también se puede ordenar por él.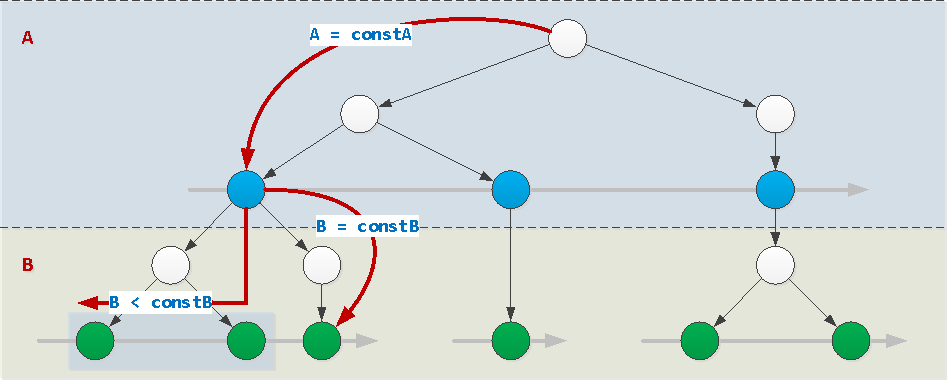
WHERE A = constA AND B [op] constB / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A = constA AND B BETWEEN constB1 AND constB2WHERE A = constA ORDER BY B
Según los índices de prefijos descritos anteriormente, esto funcionará bien:WHERE A [op] const / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A BETWEEN const1 AND const2ORDER BY AWHERE (A, B) [op] (constA, constB) / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }ORDER BY A, B
Malo: enumeración completa de la "capa"
Con parte de las consultas, la única enumeración del movimiento en el índice se convierte en una enumeración completa de todos los valores en una de las "capas". Es afortunado si hay una unidad de tales valores, y si hay miles ...Por lo general, tal problema ocurre si se utiliza la desigualdad en la consulta , la condición no determina los campos que son anteriores en el orden del índice o este orden se viola durante la ordenación.WHERE A <> constWHERE B [op] const / = ANY(...) / IN (...)ORDER BY BORDER BY B, A
Malo: el intervalo o conjunto no está en el último campo
Como consecuencia del anterior, si necesita encontrar varios valores o su rango en alguna "capa" intermedia, y luego filtrar u ordenar por los campos que se encuentran "más profundos" en el índice, habrá problemas si el número de valores únicos "en el medio" del índice es estupendo.WHERE A BETWEEN constA1 AND constA2 AND B BETWEEN constB1 AND constB2WHERE A = ANY(...) AND B = constWHERE A = ANY(...) ORDER BY BWHERE A = ANY(...) AND B = ANY(...)
Malo: expresión en lugar de campo
A veces, un desarrollador convierte inconscientemente una columna de una consulta en otra cosa, en alguna expresión para la que no hay índice. Esto se puede solucionar creando un índice a partir de la expresión deseada o realizando la transformación inversa:WHERE A - const1 [op] const2
reparar: WHERE A [op] const1 + const2WHERE A::typeOfConst = const
reparar: WHERE A = const::typeOfA
Tomamos en cuenta la cardinalidad de los campos.
Supongamos que necesita un índice (A, B), y desea elegir sólo por la igualdad : (A, B) = (constA, constB). El uso de un índice hash sería ideal , pero ... Además de no registrar (registro de wal) de dichos índices hasta la versión 10, tampoco pueden existir en varios campos:CREATE INDEX ON tbl USING hash(A, B);
En general, ha elegido btree. Entonces, ¿cuál es la mejor manera de organizar las columnas en él, (A, B)o (B, A)? Para responder a esta pregunta, es necesario tener en cuenta un parámetro como la cardinalidad de los datos en la columna correspondiente, es decir, cuántos valores únicos contiene.Imaginemos eso A = {1,2}, B = {1,2,3,4}y dibujemos un esquema del árbol de índice para ambas opciones: de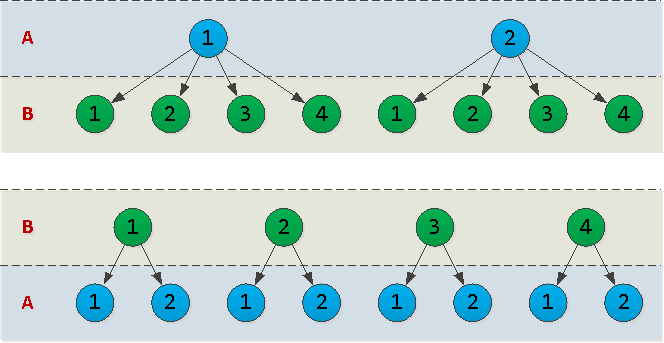 hecho, cada nodo en el árbol que dibujamos es una página en el índice. Y cuanto más haya, más espacio en disco ocupará el índice, más tiempo tomará leerlo.En nuestro ejemplo, la opción
hecho, cada nodo en el árbol que dibujamos es una página en el índice. Y cuanto más haya, más espacio en disco ocupará el índice, más tiempo tomará leerlo.En nuestro ejemplo, la opción (A, B)tiene 10 nodos y (B, A)- 12. Es decir, es más rentable poner los "campos" con el menor número de valores únicos posible "primero" .Malo: mucho y fuera de lugar (marca de tiempo "en el medio")
Exactamente por esta razón, siempre parece sospechoso si un campo con una variabilidad obviamente grande, como la marca de tiempo [tz], no es el último en su índice . Como regla general, los valores del campo de marca de tiempo aumentan monotónicamente, y los siguientes campos de índice tienen solo un valor en cada punto de tiempo.CREATE TABLE tbl(A integer, B timestamp);
CREATE INDEX ON tbl(A, B);
CREATE INDEX ON tbl(B, A);

Consulta de búsqueda para índices de marca de tiempo no final [tz]WITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
'timestamp' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamptz' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamp' = ANY(opc$[1:array_length(opc$, 1) - 1]) OR
'timestamptz' = ANY(opc$[1:array_length(opc$, 1) - 1])
ORDER BY
1, 2;
Aquí analizamos inmediatamente tanto los tipos de los campos de entrada como las clases de operadores que se les aplicaron, ya que algunas funciones de indicación de fecha y hora como date_trunc pueden resultar ser un campo de índice.nmt | nmi | def | nmf$ | tpf$ | opc$
----------------------------------------------------------------------------------
tbl | tbl_b_a_idx | CREATE INDEX ... | {b,a} | {timestamp,int4} | {timestamp,int4}
Malo: muy poco (booleano)
La otra cara de la misma moneda, se convierte en una situación en la que el índice es de campo booleano , que solo puede tomar 3 valores NULL, FALSE, TRUE. Por supuesto, su presencia tiene sentido si desea usarlo para la ordenación aplicada, por ejemplo, designándolos como el tipo de nodo en la jerarquía del árbol, ya sea una carpeta o una hoja ("carpetas primero").CREATE TABLE tbl(
id
serial
PRIMARY KEY
, leaf_pid
integer
, leaf_type
boolean
, public
boolean
);
CREATE INDEX ON tbl(leaf_pid, leaf_type);
CREATE INDEX ON tbl(public, id);
Pero, en la mayoría de los casos, este no es el caso, y las solicitudes vienen con algún valor específico del campo booleano. Y luego es posible reemplazar el índice con este campo con su versión condicional:CREATE INDEX ON tbl(id) WHERE public;
Consulta de búsqueda booleana en índicesWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
(
'bool' = ANY(tpf$) OR
'bool' = ANY(opc$)
) AND
NOT(
ARRAY(
SELECT
nmf$[i:i+1]::text
FROM
generate_series(1, array_length(nmf$, 1) - 1) i
) &&
ARRAY[
'{leaf_pid,leaf_type}'
]
)
ORDER BY
1, 2;
nmt | nmi | def | nmf$ | tpf$ | opc$
------------------------------------------------------------------------------------
tbl | tbl_public_id_idx | CREATE INDEX ... | {public,id} | {bool,int4} | {bool,int4}
Matrices en btree
Un punto separado es el intento de "indexar la matriz" utilizando el índice btree. Esto es completamente posible ya que los operadores correspondientes se aplican a ellos :(<, >, = . .) , B-, , . ( ). , , .
Pero el problema es que con el uso de algo que quiere operadores de la inclusión y la intersección : <@, @>, &&. Por supuesto, esto no funciona, porque necesitan otros tipos de índices . Cómo tal btree no funciona para la función de acceder a un elemento específico arr[i].Aprendemos a encontrar tales:CREATE TABLE tbl(
id
serial
PRIMARY KEY
, pid
integer
, list
integer[]
);
CREATE INDEX ON tbl(pid);
CREATE INDEX ON tbl(list);
Consulta de búsqueda de matriz en btreeWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid AND
cli.relam = (
SELECT
oid
FROM
pg_am
WHERE
amname = 'btree'
LIMIT 1
)
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, nmf$
, tpf$
, def
FROM
fld
WHERE
tpf$ && ARRAY(
SELECT
typname
FROM
pg_type
WHERE
typname ~ '^_'
)
ORDER BY
1, 2;
nmt | nmi | nmf$ | tpf$ | def
--------------------------------------------------------
tbl | tbl_list_idx | {list} | {_int4} | CREATE INDEX ...
Entradas de índice NULL
El último problema bastante común es "ensuciar" el índice con entradas completamente NULAS. Es decir, registros donde la expresión indexada en cada una de las columnas es NULL . Dichos registros no tienen ningún beneficio práctico, pero agregan daño con cada inserto.Por lo general, aparecen cuando crea una relación de campo o valor FK con relleno opcional en la tabla. Luego, deslice el índice para que FK funcione rápidamente ... y aquí están. Cuanto menos se llene la conexión, más "basura" caerá en el índice. Simularemos:CREATE TABLE tbl(
id
serial
PRIMARY KEY
, fk
integer
);
CREATE INDEX ON tbl(fk);
INSERT INTO tbl(fk)
SELECT
CASE WHEN i % 10 = 0 THEN i END
FROM
generate_series(1, 1000000) i;
En la mayoría de los casos, dicho índice puede convertirse en uno condicional, que también requiere menos:CREATE INDEX ON tbl(fk) WHERE (fk) IS NOT NULL;
_tmp=# \di+ tbl*
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+----------------+-------+----------+----------+---------+-------------
public | tbl_fk_idx | index | postgres | tbl | 36 MB |
public | tbl_fk_idx1 | index | postgres | tbl | 2208 kB |
public | tbl_pkey | index | postgres | tbl | 21 MB |
Para encontrar dichos índices, necesitamos conocer la distribución real de los datos, es decir, después de todo, leer todo el contenido de las tablas y superponerlo de acuerdo con las condiciones WHERE de la ocurrencia (lo haremos usando dblink ), lo que puede llevar mucho tiempo .Consulta de búsqueda para entradas NULL en índicesWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisprimary AND
idx.indisready AND
idx.indisvalid AND
NOT EXISTS(
SELECT
NULL
FROM
pg_constraint
WHERE
conindid = cli.oid
LIMIT 1
) AND
pg_relation_size(cli.oid) > 1 << 20
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, regexp_replace(
CASE
WHEN def ~ ' USING btree ' THEN
regexp_replace(def, E'.* USING btree (.*?)($| WHERE .*)', E'\\1')
END
, E' ([a-z]*_pattern_ops|(ASC|DESC)|NULLS\\s?(?:FIRST|LAST))'
, ''
, 'ig'
) fld
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, q AS (
SELECT
nmt
, $q$
SET search_path = $q$ || quote_ident((TABLE sch)) || $q$, public;
SELECT
ARRAY[
count(*)
$q$ || string_agg(
', coalesce(sum((' || coalesce(wh, 'TRUE') || ')::integer), 0)' || E'\n' ||
', coalesce(sum(((' || coalesce(wh, 'TRUE') || ') AND (' || fld || ' IS NULL))::integer), 0)' || E'\n'
, '' ORDER BY nmi) || $q$
]
FROM
$q$ || quote_ident((TABLE sch)) || $q$.$q$ || quote_ident(nmt) || $q$
$q$ q
, array_agg(clioid ORDER BY nmi) oid$
, array_agg(nmi ORDER BY nmi) idx$
, array_agg(fld ORDER BY nmi) fld$
, array_agg(wh ORDER BY nmi) wh$
FROM
fld
WHERE
fld IS NOT NULL
GROUP BY
1
ORDER BY
1
)
, res AS (
SELECT
*
, (
SELECT
qty
FROM
dblink(
'dbname=' || current_database() || ' port=' || current_setting('port')
, q
) T(qty bigint[])
) qty
FROM
q
)
, iter AS (
SELECT
*
, generate_subscripts(idx$, 1) i
FROM
res
)
, stat AS (
SELECT
nmt table_name
, idx$[i] index_name
, pg_relation_size(oid$[i]) index_size
, pg_size_pretty(pg_relation_size(oid$[i])) index_size_humanize
, regexp_replace(fld$[i], E'^\\((.*)\\)$', E'\\1') index_fields
, regexp_replace(wh$[i], E'^\\((.*)\\)$', E'\\1') index_cond
, qty[1] table_rec_count
, qty[i * 2] index_rec_count
, qty[i * 2 + 1] index_rec_count_null
FROM
iter
)
SELECT
*
, CASE
WHEN table_rec_count > 0
THEN index_rec_count::double precision / table_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_cover_prc
, CASE
WHEN index_rec_count > 0
THEN index_rec_count_null::double precision / index_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_null_prc
FROM
stat
WHERE
index_rec_count_null * 4 > index_rec_count
ORDER BY
1, 2;
-[ RECORD 1 ]--------+--------------
table_name | tbl
index_name | tbl_fk_idx
index_size | 37838848
index_size_humanize | 36 MB
index_fields | fk
index_cond |
table_rec_count | 1000000
index_rec_count | 1000000
index_rec_count_null | 900000
index_cover_prc | 100.00 -- 100%
index_null_prc | 90.00 -- 90% NULL-""
Espero que algunas de las consultas en este artículo te ayuden.