En previsión del inicio de una nueva transmisión en el curso "Developer Golang" preparó una traducción de material interesante.
Nuestro servidor DNS autorizado es utilizado por decenas de miles de sitios web. Respondemos a millones de consultas diarias. Hoy en día, los ataques de DNS se están volviendo cada vez más comunes, el DNS es una parte importante de nuestro sistema, y debemos asegurarnos de que podamos trabajar bien bajo una gran carga.dnsflood es una pequeña herramienta que puede generar una gran cantidad de solicitudes de udp.# timeout 20s ./dnsflood example.com 127.0.0.1 -p 2053
El monitoreo del sistema mostró que el uso de memoria de nuestro servicio creció tan rápido que tuvimos que detenerlo, de lo contrario nos encontraríamos con errores OOM. Fue como un problema de pérdida de memoria; Hay varias razones para la pérdida de memoria "similar" y "real":- colgando gorutinas
- mal uso del aplazamiento y finalizador
- subcadenas y subcortes
- variables globales
Esta publicación proporciona una explicación detallada de varias fugas.Antes de sacar conclusiones, primero realicemos un perfil.Godebug
Se pueden habilitar varias herramientas de depuración utilizando una variable de entorno GODEBUG, pasando una lista de pares separados por comas name=value.Planificador de seguimiento
El seguimiento del planificador puede proporcionar información sobre el comportamiento de la rutina en tiempo de ejecución. Para habilitar el seguimiento del planificador, ejecute el programa con GODEBUG=schedtrace=100, el valor determina el período de salida en ms.$ GODEBUG=schedtrace=100 ./redins -c config.json
SCHED 2952ms: ... runqueue=3 [26 11 7 18 13 30 6 3 24 25 11 0]
SCHED 3053ms: ... runqueue=3 [0 0 0 0 0 0 0 0 4 0 21 0]
SCHED 3154ms: ... runqueue=0 [0 6 2 4 0 30 0 5 0 11 2 5]
SCHED 3255ms: ... runqueue=1 [0 0 0 0 0 0 0 0 0 0 0 0]
SCHED 3355ms: ... runqueue=0 [1 0 0 0 0 0 0 0 0 0 0 0]
SCHED 3456ms: ... runqueue=0 [0 0 0 0 0 0 0 0 0 0 0 0]
SCHED 3557ms: ... runqueue=0 [13 0 3 0 3 33 2 0 10 8 10 14]
SCHED 3657ms: ...runqueue=3 [14 1 0 5 19 54 9 1 0 1 29 0]
SCHED 3758ms: ... runqueue=0 [67 1 5 0 0 1 0 0 87 4 0 0]
SCHED 3859ms: ... runqueue=6 [0 0 3 6 0 0 0 0 3 2 2 19]
SCHED 3960ms: ... runqueue=0 [0 0 1 0 1 0 0 1 0 1 0 0]
SCHED 4060ms: ... runqueue=5 [4 0 5 0 1 0 0 0 0 0 0 0]
SCHED 4161ms: ... runqueue=0 [0 0 0 0 0 0 0 1 0 0 0 0]
SCHED 4262ms: ... runqueue=4 [0 128 21 172 1 19 8 2 43 5 139 37]
SCHED 4362ms: ... runqueue=0 [0 0 0 0 0 0 0 0 0 0 0 0]
SCHED 4463ms: ... runqueue=6 [0 28 23 39 4 11 4 11 25 0 25 0]
SCHED 4564ms: ... runqueue=354 [51 45 33 32 15 20 8 7 5 42 6 0]
runqueue es la longitud de la cola global de goroutines para ejecutar. Los números entre paréntesis son la longitud de la cola del proceso.La situación ideal es cuando todos los procesos están ocupados ejecutando goroutines, y la longitud moderada de la cola de ejecución se distribuye uniformemente entre todos los procesos:SCHED 2449ms: gomaxprocs=12 idleprocs=0 threads=40 spinningthreads=1 idlethreads=1 runqueue=20 [20 20 20 20 20 20 20 20 20 20 20]
Al observar la salida de schedtrace , podemos ver períodos de tiempo en que casi todos los procesos están inactivos. Esto significa que no estamos utilizando el procesador a plena capacidad.Rastro de recolector de basura
Para habilitar el rastreo de recolección de basura (GC), ejecute el programa con una variable de entorno GODEBUG=gctrace=1:GODEBUG=gctrace=1 ./redins -c config1.json
.
.
.
gc 30 @3.727s 1%: 0.066+21+0.093 ms clock, 0.79+128/59/0+1.1 ms cpu, 67->71->45 MB, 76 MB goal, 12 P
gc 31 @3.784s 2%: 0.030+27+0.053 ms clock, 0.36+177/81/7.8+0.63 ms cpu, 79->84->55 MB, 90 MB goal, 12 P
gc 32 @3.858s 3%: 0.026+34+0.024 ms clock, 0.32+234/104/0+0.29 ms cpu, 96->100->65 MB, 110 MB goal, 12 P
gc 33 @3.954s 3%: 0.026+44+0.13 ms clock, 0.32+191/131/57+1.6 ms cpu, 117->123->79 MB, 131 MB goal, 12 P
gc 34 @4.077s 4%: 0.010+53+0.024 ms clock, 0.12+241/159/69+0.29 ms cpu, 142->147->91 MB, 158 MB goal, 12 P
gc 35 @4.228s 5%: 0.017+61+0.12 ms clock, 0.20+296/179/94+1.5 ms cpu, 166->174->105 MB, 182 MB goal, 12 P
gc 36 @4.391s 6%: 0.017+73+0.086 ms clock, 0.21+492/216/4.0+1.0 ms cpu, 191->198->122 MB, 210 MB goal, 12 P
gc 37 @4.590s 7%: 0.049+85+0.095 ms clock, 0.59+618/253/0+1.1 ms cpu, 222->230->140 MB, 244 MB goal, 12 P
.
.
.
Como vemos aquí, la cantidad de memoria utilizada aumenta, y la cantidad de tiempo que gc tarda en completar su trabajo también aumenta. Esto significa que consumimos más memoria de la que puede manejar.Puede GODEBUGobtener más información y algunas otras variables de entorno de golang aquí .Habilitar Profiler
go tool pprof- Una herramienta para analizar y perfilar datos. Hay dos formas de configurar pprof: llamar directamente a funciones runtime/pprofen su código, por ejemplo pprof.StartCPUProfile(), o instalar un net/http/pproflistado de http y obtener datos de allí, lo cual hicimos. Tiene un pprofconsumo de recursos muy pequeño, por lo que se puede usar de forma segura en el desarrollo, pero el punto final del perfil no debe estar disponible públicamente, ya que se pueden divulgar datos confidenciales.Todo lo que necesitamos hacer para la segunda opción es importar el paquete "net / http / pprof" :import (
_ "net/http/pprof"
)
luego agregue un http listner:go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
Pprof tiene varios perfiles predeterminados:- allocs : busca todas las asignaciones de memoria pasadas
- bloque : seguimiento de pila que condujo al bloqueo de primitivas de sincronización
- goroutine : seguimiento de la pila de todas las goroutines actuales
- heap : busca asignaciones de memoria de objetos vivos.
- mutex : seguimiento de pila de titulares de mutex en conflicto
- perfil : perfil del procesador.
- threadcreate : un seguimiento de pila que condujo a la creación de nuevos hilos en el sistema operativo
- trace : rastrea la ejecución del programa actual.
Nota: el punto final de seguimiento, a diferencia de todos los demás puntos finales, es un perfil de seguimiento , no pprof , en su lugar puede verlo con la herramienta go trace go tool pprof.
Ahora que todo está listo, podemos ver las herramientas disponibles.Perfilador de procesador
$ go tool pprof http:
El generador de perfiles del procesador por defecto funciona durante 30 segundos (podemos cambiar esto configurando el parámetro seconds) y recoge muestras cada 100 milisegundos, después de lo cual pasa al modo interactivo. Los comandos más comunes están disponibles top, list, web.Use top npara ver las entradas más populares en formato de texto, también hay dos opciones para ordenar la salida, -cumpor orden acumulativo y -flat.(pprof) top 10 -cum
Showing nodes accounting for 1.50s, 6.19% of 24.23s total
Dropped 347 nodes (cum <= 0.12s)
Showing top 10 nodes out of 186
flat flat% sum% cum cum%
0.03s 0.12% 0.12% 16.7s 69.13% (*Server).serveUDPPacket
0.05s 0.21% 0.33% 15.6s 64.51% (*Server).serveDNS
0 0% 0.33% 14.3s 59.10% (*ServeMux).ServeDNS
0 0% 0.33% 14.2s 58.73% HandlerFunc.ServeDNS
0.01s 0.04% 0.37% 14.2s 58.73% main.handleRequest
0.07s 0.29% 0.66% 13.5s 56.00% (*DnsRequestHandler).HandleRequest
0.99s 4.09% 4.75% 7.56s 31.20% runtime.gentraceback
0.02s 0.08% 4.83% 7.02s 28.97% runtime.systemstack
0.31s 1.28% 6.11% 6.62s 27.32% runtime.mallocgc
0.02s 0.08% 6.19% 6.35s 26.21% (*DnsRequestHandler).FindANAME
(pprof)
utilizar listpara explorar la función.(pprof) list handleRequest
Total: 24.23s
ROUTINE ======================== main.handleRequest in /home/arash/go/src/arvancloud/redins/redins.go
10ms 14.23s (flat, cum) 58.73% of Total
. . 35: l *handler.RateLimiter
. . 36: configFile string
. . 37:)
. . 38:
. . 39:func handleRequest(w dns.ResponseWriter, r *dns.Msg) {
10ms 610ms 40: context := handler.NewRequestContext(w, r)
. 50ms 41: logger.Default.Debugf("handle request: [%d] %s %s", r.Id, context.RawName(), context.Type())
. . 42:
. . 43: if l.CanHandle(context.IP()) {
. 13.57s 44: h.HandleRequest(context)
. . 45: } else {
. . 46: context.Response(dns.RcodeRefused)
. . 47: }
. . 48:}
. . 49:
(pprof)
El equipo webgenera un gráfico SVG de áreas críticas y lo abre en el navegador.(pprof)web handleReques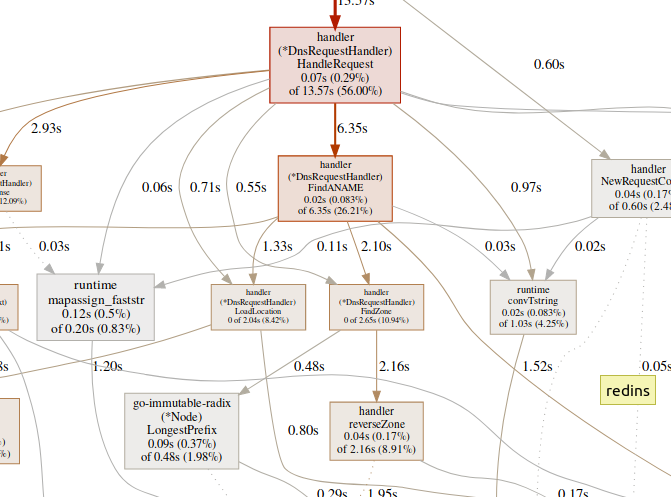 Una gran cantidad de tiempo dedicado a las funciones de GC, como
Una gran cantidad de tiempo dedicado a las funciones de GC, como runtime.mallocgc, a menudo resulta en una asignación de memoria significativa, lo que puede agregar carga al recolector de basura y aumentar la latencia.Una gran cantidad de tiempo dedicado a los mecanismos de sincronización, como runtime.chansendo runtime.lock, puede ser un signo de conflicto.Una gran cantidad de tiempo dedicado syscall.Read/Writesignifica el uso excesivo de las operaciones de E / S.Perfilador de memoria
$ go tool pprof http:
Por defecto, muestra la vida útil de la memoria asignada. Podemos ver la cantidad de objetos seleccionados usando -alloc_objectsotras opciones útiles: -iuse_objectsy -inuse_spacepara verificar la memoria en vivo .Por lo general, si desea reducir el consumo de memoria, debe tener en cuenta -inuse_space, pero si desea reducir la latencia, tenga en cuenta el -alloc_objectstiempo suficiente de ejecución / carga.Identificación de un cuello de botella.
Es importante determinar primero el tipo de cuello de botella (procesador, E / S, memoria) con el que estamos tratando. Además de los perfiladores, hay otro tipo de herramienta.go tool tracepuede mostrar lo que hacen las gorutinas en detalle. Para recopilar un ejemplo de rastreo, debemos enviar una solicitud http al punto final de rastreo:$ curl http:
El archivo generado se puede ver con la herramienta de seguimiento:$ go tool trace trace.out
2019/12/25 15:30:50 Parsing trace...
2019/12/25 15:30:59 Splitting trace...
2019/12/25 15:31:10 Opening browser. Trace viewer is listening on http:
Go tool trace es una aplicación web que utiliza el protocolo Chrome DevTools y es compatible solo con los navegadores Chrome. La página principal se ve así:Ver seguimiento (0s-409.575266ms)Ver seguimiento (411.075559ms-747.252311ms)Ver seguimiento (747.252311ms-1.234968945s)Ver seguimiento (1.234968945s-1.774245108s)Ver seguimiento (1.774245484s-2.111339514s)Ver seguimiento (2.111339514s-2.674030898s)Ver seguimiento (2.674031362s-3.044145798s)Ver seguimiento (3.044145798s-3.458795252s)Ver seguimiento (3.43953778s-4.075080634s)Ver seguimiento (4.075081098s-4.439271287s)Ver35 4.439 -4.814869651s)Ver traza (4.814869651s-5.253597835s)Análisis de GoroutinePerfil de bloqueo de red ()El bloqueo de la sincronización de perfiles ()SYSCALL perfil de bloqueo ()Programador de latencia del perfil ()las tareas definidas por el usuariolas regiones definidas por el usuario para RentAircraftal mínimo la utilización mutadortraza divide la traza de modo que su navegador puede manejarlo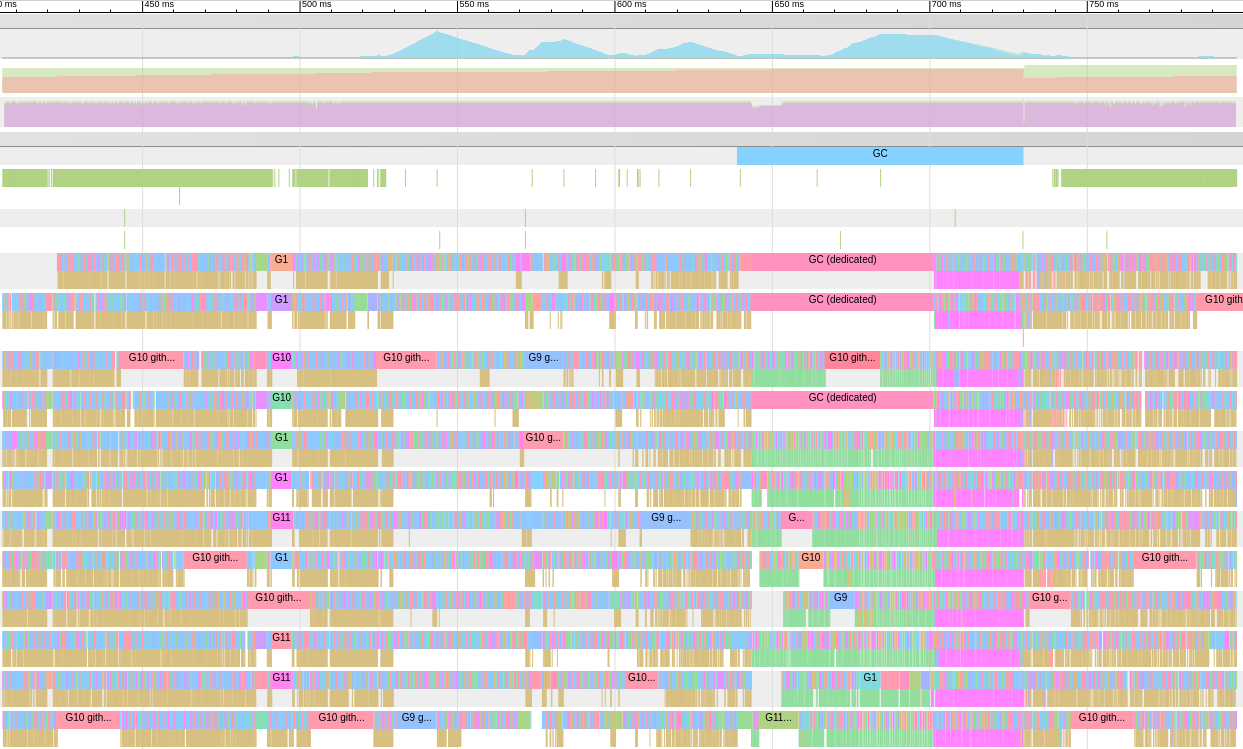 Hay una gran variedad de datos, lo que los hace casi ilegibles si No sabemos lo que estamos buscando. Dejémoslo por ahora.El siguiente enlace en la página principal es "análisis de gorutina" , que muestra los diferentes tipos de gorutinas de trabajo en el programa durante el período de rastreo:
Hay una gran variedad de datos, lo que los hace casi ilegibles si No sabemos lo que estamos buscando. Dejémoslo por ahora.El siguiente enlace en la página principal es "análisis de gorutina" , que muestra los diferentes tipos de gorutinas de trabajo en el programa durante el período de rastreo:Goroutines:
github.com/miekg/dns.(*Server).serveUDPPacket N=441703
runtime.gcBgMarkWorker N=12
github.com/karlseguin/ccache.(*Cache).worker N=2
main.Start.func1 N=1
runtime.bgsweep N=1
arvancloud/redins/handler.NewHandler.func2 N=1
runtime/trace.Start.func1 N=1
net/http.(*conn).serve N=1
runtime.timerproc N=3
net/http.(*connReader).backgroundRead N=1
N=40
Haga clic en el primer elemento con N = 441703 , esto es lo que obtenemos: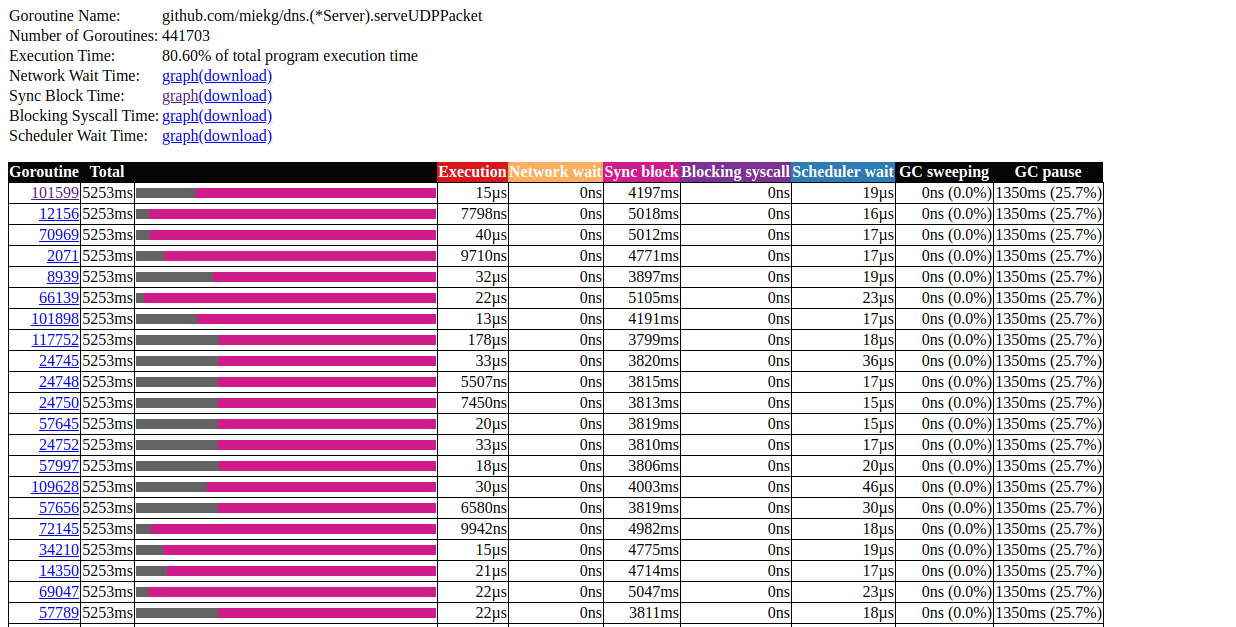 análisis de goroutinaEsto es muy interesante. La mayoría de las operaciones no tardan casi en completarse, y la mayor parte del tiempo se gasta en el bloque de sincronización. Echemos un vistazo más de cerca a uno de ellos:
análisis de goroutinaEsto es muy interesante. La mayoría de las operaciones no tardan casi en completarse, y la mayor parte del tiempo se gasta en el bloque de sincronización. Echemos un vistazo más de cerca a uno de ellos: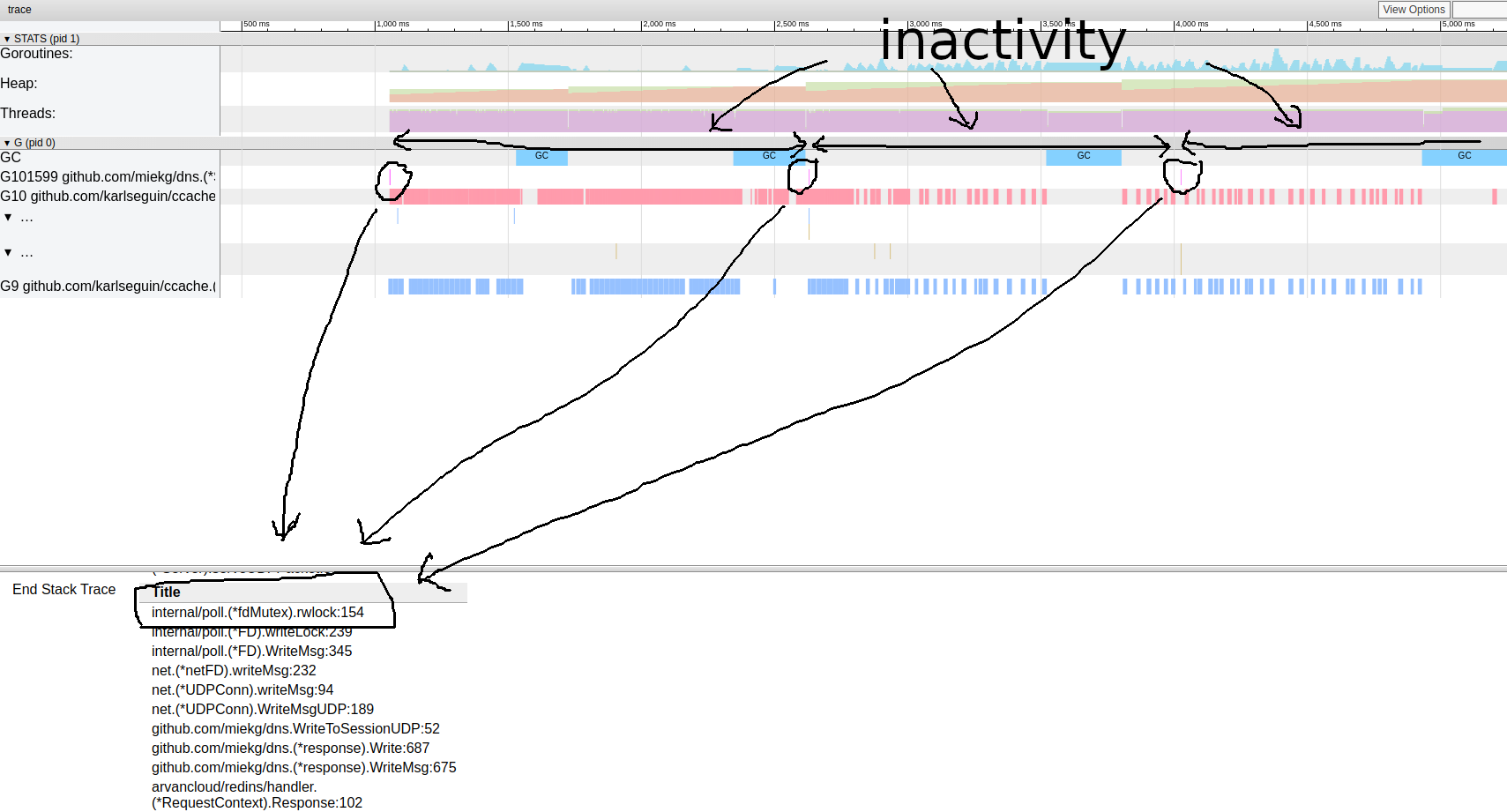 patrón de trazas de rutinaParece que nuestro programa casi siempre está inactivo. Desde aquí podemos ir directamente a la herramienta de bloqueo; el perfil de bloqueo está deshabilitado de forma predeterminada, primero debemos habilitarlo en nuestro código:
patrón de trazas de rutinaParece que nuestro programa casi siempre está inactivo. Desde aquí podemos ir directamente a la herramienta de bloqueo; el perfil de bloqueo está deshabilitado de forma predeterminada, primero debemos habilitarlo en nuestro código:runtime.SetBlockProfileRate(1)
Ahora podemos obtener una selección de cerraduras:$ go tool pprof http:
(pprof) top
Showing nodes accounting for 16.03wks, 99.75% of 16.07wks total
Dropped 87 nodes (cum <= 0.08wks)
Showing top 10 nodes out of 27
flat flat% sum% cum cum%
10.78wks 67.08% 67.08% 10.78wks 67.08% internal/poll.(*fdMutex).rwlock
5.25wks 32.67% 99.75% 5.25wks 32.67% sync.(*Mutex).Lock
0 0% 99.75% 5.25wks 32.67% arvancloud/redins/handler.(*DnsRequestHandler).Filter
0 0% 99.75% 5.25wks 32.68% arvancloud/redins/handler.(*DnsRequestHandler).FindANAME
0 0% 99.75% 16.04wks 99.81% arvancloud/redins/handler.(*DnsRequestHandler).HandleRequest
0 0% 99.75% 10.78wks 67.08% arvancloud/redins/handler.(*DnsRequestHandler).Response
0 0% 99.75% 10.78wks 67.08% arvancloud/redins/handler.(*RequestContext).Response
0 0% 99.75% 5.25wks 32.67% arvancloud/redins/handler.ChooseIp
0 0% 99.75% 16.04wks 99.81% github.com/miekg/dns.(*ServeMux).ServeDNS
0 0% 99.75% 16.04wks 99.81% github.com/miekg/dns.(*Server).serveDNS
(pprof)
Aquí tenemos dos bloqueos diferentes ( poll.fdMutex y sync.Mutex ), responsables de casi el 100% de los bloqueos. Esto confirma nuestra suposición sobre un conflicto de bloqueo, ahora solo necesitamos encontrar dónde sucede esto:(pprof) svg lock
Este comando crea un gráfico vectorial de todos los nodos que tiene en cuenta los conflictos, con énfasis en las funciones de bloqueo: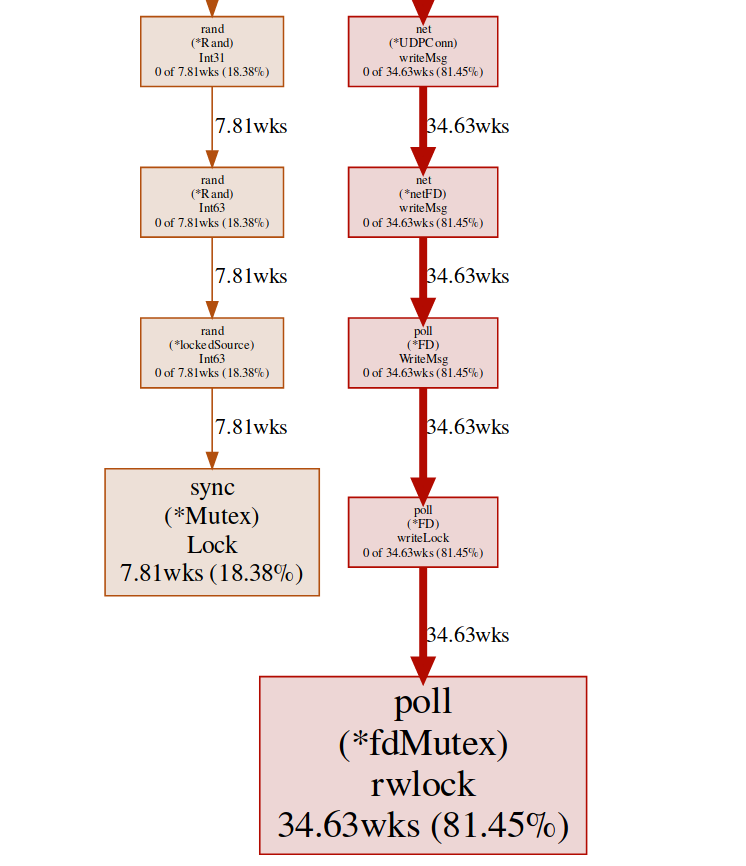 svg-graph del punto final de bloqueopodemos obtener el mismo resultado del punto final goroutine:
svg-graph del punto final de bloqueopodemos obtener el mismo resultado del punto final goroutine:$ go tool pprof http:
y entonces:(pprof) top
Showing nodes accounting for 294412, 100% of 294424 total
Dropped 84 nodes (cum <= 1472)
Showing top 10 nodes out of 32
flat flat% sum% cum cum%
294404 100% 100% 294404 100% runtime.gopark
8 0.0027% 100% 294405 100% github.com/miekg/dns.(*Server).serveUDPPacket
0 0% 100% 58257 19.79% arvancloud/redins/handler.(*DnsRequestHandler).Filter
0 0% 100% 58259 19.79% arvancloud/redins/handler.(*DnsRequestHandler).FindANAME
0 0% 100% 293852 99.81% arvancloud/redins/handler.(*DnsRequestHandler).HandleRequest
0 0% 100% 235406 79.95% arvancloud/redins/handler.(*DnsRequestHandler).Response
0 0% 100% 235406 79.95% arvancloud/redins/handler.(*RequestContext).Response
0 0% 100% 58140 19.75% arvancloud/redins/handler.ChooseIp
0 0% 100% 293852 99.81% github.com/miekg/dns.(*ServeMux).ServeDNS
0 0% 100% 293900 99.82% github.com/miekg/dns.(*Server).serveDNS
(pprof)
Casi todos nuestros programas están ubicados en runtime.gopark, es un planificador de go que tiene capacidad para goroutines; Una razón muy común para esto es un conflicto de bloqueo(pprof) svg gopark
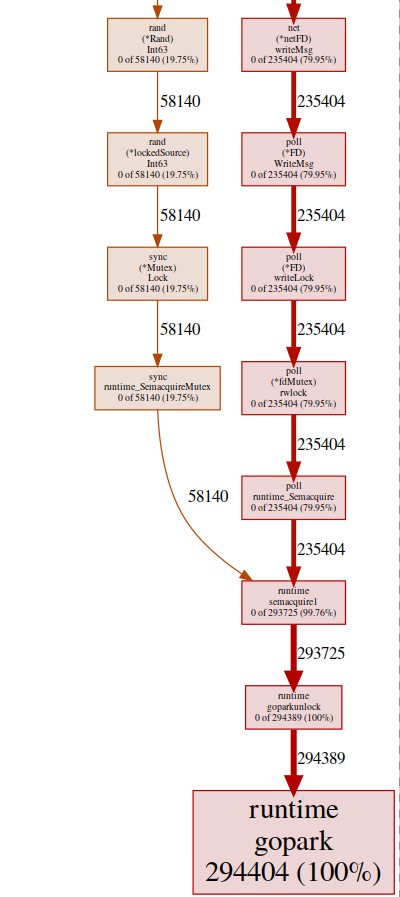 svg-graph del punto final goroutinAquí vemos dos fuentes de conflicto:
svg-graph del punto final goroutinAquí vemos dos fuentes de conflicto:UDPConn.WriteMsg ()
Parece que todas las respuestas terminan escribiendo en el mismo FD (de ahí el bloqueo), esto tiene sentido, ya que todos tienen la misma dirección de origen.Realizamos un pequeño experimento con varias soluciones, y al final decidimos usar varios oyentes para equilibrar la carga. Por lo tanto, permitimos que el sistema operativo equilibre las solicitudes entrantes entre diferentes conexiones y reduzca los conflictos.Rand ()
Parece que hay un bloqueo en las funciones regulares de matemáticas / rand (más sobre esto aquí ). Esto se puede solucionar fácilmente con la ayuda de Rand.New()un generador de números aleatorios que crea un contenedor sin bloqueo.rg := rand.New(rand.NewSource(int64(time.Now().Nanosecond())))
Es un poco mejor, pero crear una nueva fuente es caro cada vez. ¿Es posible hacerlo aún mejor? En nuestro caso, realmente no necesitamos un número aleatorio. Solo necesitamos una distribución uniforme para equilibrar la carga, y resulta que Time.Nanoseconds()puede ser adecuado para nosotros.Ahora que hemos eliminado todos los bloqueos innecesarios, echemos un vistazo a los resultados: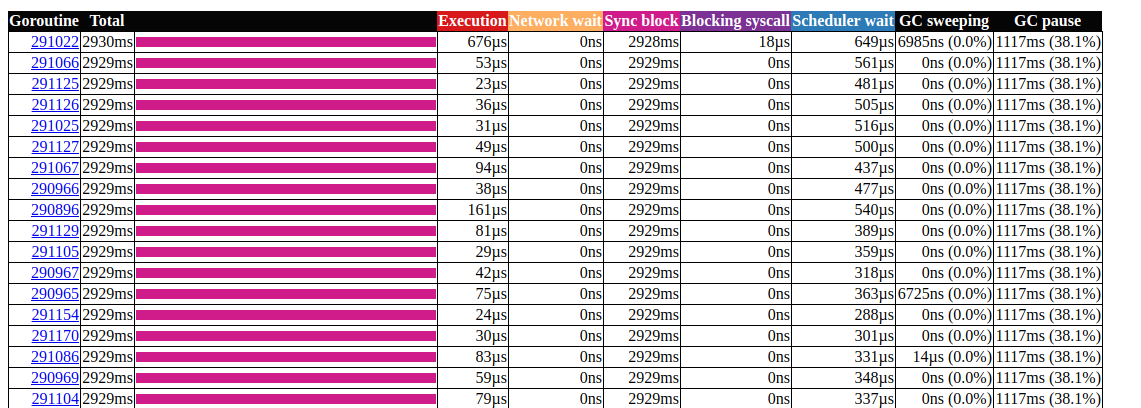 análisis de goroutin Seve mejor, pero aún así, la mayor parte del tiempo lleva bloquear la sincronización. Echemos un vistazo al perfil de bloqueo de sincronización desde la página principal de la interfaz de usuario de seguimiento:
análisis de goroutin Seve mejor, pero aún así, la mayor parte del tiempo lleva bloquear la sincronización. Echemos un vistazo al perfil de bloqueo de sincronización desde la página principal de la interfaz de usuario de seguimiento: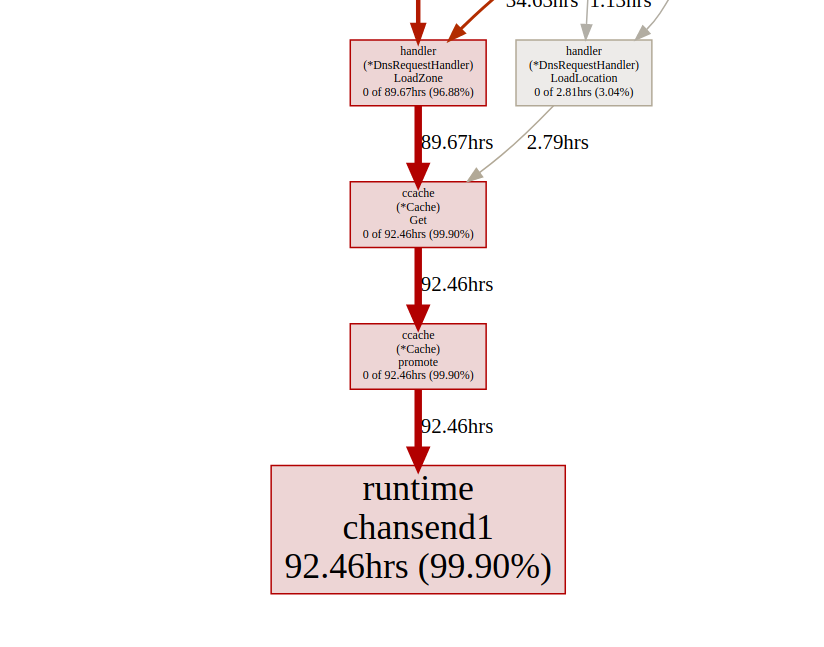 línea de tiempo de bloqueo de sincronizaciónEchemos un vistazo a la función de impulso
línea de tiempo de bloqueo de sincronizaciónEchemos un vistazo a la función de impulso ccachedesde el punto final de bloqueo pprof:(pprof) list promote
ROUTINE ======================== github.com/karlseguin/ccache.(*Cache).promote in ...
0 9.66days (flat, cum) 99.70% of Total
. . 155: h.Write([]byte(key))
. . 156: return c.buckets[h.Sum32()&c.bucketMask]
. . 157:}
. . 158:
. . 159:func (c *Cache) promote(item *Item) {
. 9.66days 160: c.promotables <- item
. . 161:}
. . 162:
. . 163:func (c *Cache) worker() {
. . 164: defer close(c.donec)
. . 165:
Todas las llamadas ccache.Get()terminan en un canal c.promotables. El almacenamiento en caché es una parte importante de nuestro servicio, debemos considerar otras opciones; En Dgraph tiene un excelente artículo sobre el estado de caché! Go , también tienen un excelente módulo de almacenamiento en caché llamado ristretto . Desafortunadamente, ristretto aún no es compatible con la versión basada en Ttl, podríamos solucionar este problema usando uno muy grande MaxCosty manteniendo el valor de tiempo de espera en nuestra estructura de caché (queremos mantener los datos obsoletos en la caché). Veamos el resultado al usar ristretto: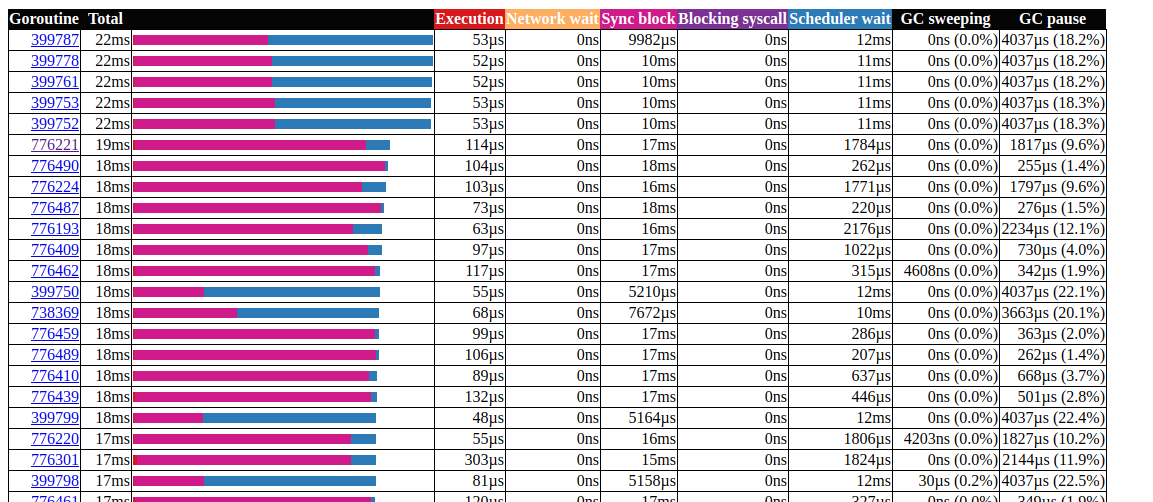 análisis de goroutin¡Genial!Pudimos reducir el tiempo de ejecución máximo de gorutina de 5000 ms a 22 ms. Sin embargo, la mayor parte del tiempo de ejecución se divide entre "bloqueo de sincronización" y "esperando el planificador". Veamos si podemos hacer algo al respecto: la
análisis de goroutin¡Genial!Pudimos reducir el tiempo de ejecución máximo de gorutina de 5000 ms a 22 ms. Sin embargo, la mayor parte del tiempo de ejecución se divide entre "bloqueo de sincronización" y "esperando el planificador". Veamos si podemos hacer algo al respecto: la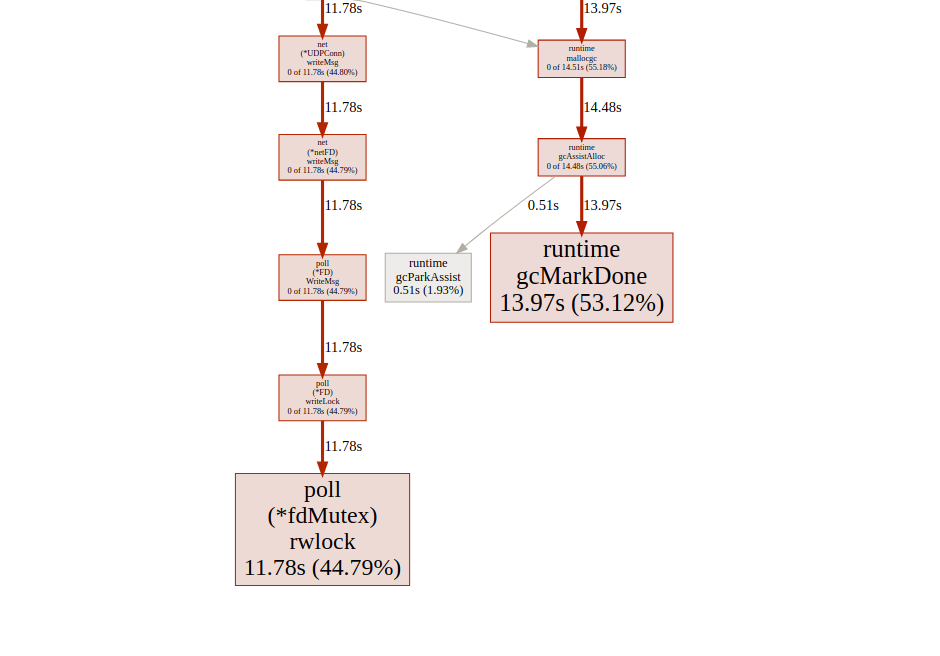 línea de tiempo del bloqueo de sincronización.Podemos hacer poco con eso
línea de tiempo del bloqueo de sincronización.Podemos hacer poco con eso fdMutex.rwlock, ahora centrémonos en otro: gcMarkDone, que es responsable del 53% del tiempo de bloqueo. Esta característica es parte del proceso de recolección de basura. Su presencia en la sección crítica es a menudo una señal de que estamos sobrecargando gc.optimización de asignación
En este punto, puede ser útil ver cómo funciona la recolección de basura; Go utiliza un selector de marca y barrido. Realiza un seguimiento de todo lo que está seleccionado, y tan pronto como alcanza el doble del tamaño (o cualquier otro valor que GOGC esté configurado) del tamaño del tamaño anterior, comienza la limpieza del GC. La evaluación se lleva a cabo en tres etapas:- Configuración de marcador (STW)
- Marcado (paralelo)
- Fin de etiquetado (STW)
Las fases Stop The World (STW) detienen todo el proceso, aunque generalmente son muy cortos, los ciclos continuos pueden aumentar la duración. Esto se debe a que en la actualidad (vaya a v1.13) las goroutinas se suplantan solo en los puntos de la llamada a la función, por lo tanto, para un ciclo continuo, es posible un tiempo de pausa arbitrariamente largo, ya que el GC espera que todas las goroutinas se detengan.Durante el marcado, gc usa alrededor del 25% GOMAXPROCS, pero se pueden agregar a la fuerza funciones auxiliares adicionales para marcar la asistencia , esto sucede cuando la gorutina de movimiento rápido supera el marcador de fondo para reducir el retraso causado por gc, debemos minimizar el uso del montón.Dos cosas a tener en cuenta:- el número de asignaciones es más importante que el tamaño (por ejemplo, 1000 asignaciones de memoria de una estructura de 20 bytes crean mucha más carga en el montón que una única asignación de 20,000 bytes);
- a diferencia de lenguajes como C / C ++, no todas las asignaciones de memoria terminan en el montón. El compilador go decide si la variable se moverá al montón o si se puede colocar dentro del marco de la pila. A diferencia de las variables asignadas en el montón, las variables asignadas en la pila no cargan gc.
Para obtener más información sobre el modelo de memoria Go y la arquitectura GC, consulte esta presentación .Para optimizar la asignación de memoria, utilizamos el kit de herramientas go:- generador de perfiles de procesador para encontrar distribuciones en caliente;
- generador de perfiles de memoria para rastrear asignaciones;
- trazador de patrones; Gc
- análisis de escape para descubrir por qué ocurre la asignación.
Comencemos con el perfilador del procesador:$ go tool pprof http:
(pprof) top 20 -cum
Showing nodes accounting for 7.27s, 29.10% of 24.98s total
Dropped 315 nodes (cum <= 0.12s)
Showing top 20 nodes out of 201
flat flat% sum% cum cum%
0 0% 0% 16.42s 65.73% github.com/miekg/dns.(*Server).serveUDPPacket
0.02s 0.08% 0.08% 16.02s 64.13% github.com/miekg/dns.(*Server).serveDNS
0.02s 0.08% 0.16% 13.69s 54.80% github.com/miekg/dns.(*ServeMux).ServeDNS
0.01s 0.04% 0.2% 13.48s 53.96% github.com/miekg/dns.HandlerFunc.ServeDNS
0.02s 0.08% 0.28% 13.47s 53.92% main.handleRequest
0.24s 0.96% 1.24% 12.50s 50.04% arvancloud/redins/handler.(*DnsRequestHandler).HandleRequest
0.81s 3.24% 4.48% 6.91s 27.66% runtime.gentraceback
3.82s 15.29% 19.78% 5.48s 21.94% syscall.Syscall
0.02s 0.08% 19.86% 5.44s 21.78% arvancloud/redins/handler.(*DnsRequestHandler).Response
0.06s 0.24% 20.10% 5.25s 21.02% arvancloud/redins/handler.(*RequestContext).Response
0.03s 0.12% 20.22% 4.97s 19.90% arvancloud/redins/handler.(*DnsRequestHandler).FindANAME
0.56s 2.24% 22.46% 4.92s 19.70% runtime.mallocgc
0.07s 0.28% 22.74% 4.90s 19.62% github.com/miekg/dns.(*response).WriteMsg
0.04s 0.16% 22.90% 4.40s 17.61% github.com/miekg/dns.(*response).Write
0.01s 0.04% 22.94% 4.36s 17.45% github.com/miekg/dns.WriteToSessionUDP
1.43s 5.72% 28.66% 4.30s 17.21% runtime.pcvalue
0.01s 0.04% 28.70% 4.15s 16.61% runtime.newstack
0.06s 0.24% 28.94% 4.09s 16.37% runtime.copystack
0.01s 0.04% 28.98% 4.05s 16.21% net.(*UDPConn).WriteMsgUDP
0.03s 0.12% 29.10% 4.04s 16.17% net.(*UDPConn).writeMsg
Estamos particularmente interesados en funciones relacionadas, mallocgcaquí es donde ayudamos con las etiquetas(pprof) svg mallocgc
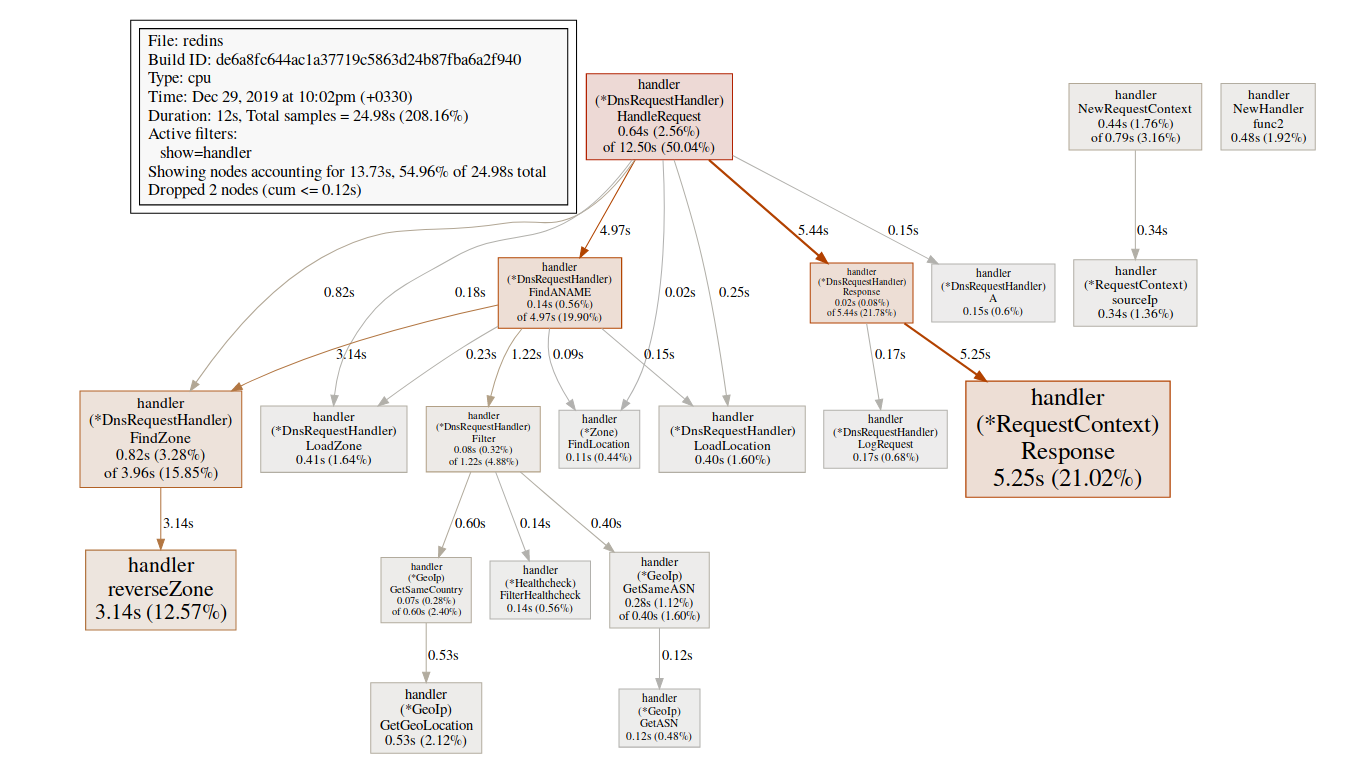 Podemos rastrear la distribución usando el punto final
Podemos rastrear la distribución usando el punto final alloc, la opción alloc_objectsignifica el número total de asignaciones, hay otras opciones para usar la memoria y el espacio de asignación.$ go tool pprof -alloc_objects http:
(pprof) top -cum
Active filters:
show=handler
Showing nodes accounting for 58464353, 59.78% of 97803168 total
Dropped 1 node (cum <= 489015)
Showing top 10 nodes out of 19
flat flat% sum% cum cum%
15401215 15.75% 15.75% 70279955 71.86% arvancloud/redins/handler.(*DnsRequestHandler).HandleRequest
2392100 2.45% 18.19% 27198697 27.81% arvancloud/redins/handler.(*DnsRequestHandler).FindANAME
711174 0.73% 18.92% 14936976 15.27% arvancloud/redins/handler.(*DnsRequestHandler).Filter
0 0% 18.92% 14161410 14.48% arvancloud/redins/handler.(*DnsRequestHandler).Response
14161410 14.48% 33.40% 14161410 14.48% arvancloud/redins/handler.(*RequestContext).Response
7284487 7.45% 40.85% 11118401 11.37% arvancloud/redins/handler.NewRequestContext
10439697 10.67% 51.52% 10439697 10.67% arvancloud/redins/handler.reverseZone
0 0% 51.52% 10371430 10.60% arvancloud/redins/handler.(*DnsRequestHandler).FindZone
2680723 2.74% 54.26% 8022046 8.20% arvancloud/redins/handler.(*GeoIp).GetSameCountry
5393547 5.51% 59.78% 5393547 5.51% arvancloud/redins/handler.(*DnsRequestHandler).LoadLocation
De ahora en adelante, podemos usar la lista para cada función y ver si podemos reducir la asignación de memoria. Vamos a ver:funciones tipo printf(pprof) list handleRequest
Total: 97803168
ROUTINE ======================== main.handleRequest in /home/arash/go/src/arvancloud/redins/redins.go
2555943 83954299 (flat, cum) 85.84% of Total
. . 35: l *handler.RateLimiter
. . 36: configFile string
. . 37:)
. . 38:
. . 39:func handleRequest(w dns.ResponseWriter, r *dns.Msg) {
. 11118401 40: context := handler.NewRequestContext(w, r)
2555943 2555943 41: logger.Default.Debugf("handle request: [%d] %s %s", r.Id, context.RawName(), context.Type())
. . 42:
. . 43: if l.CanHandle(context.IP()) {
. 70279955 44: h.HandleRequest(context)
. . 45: } else {
. . 46: context.Response(dns.RcodeRefused)
. . 47: }
. . 48:}
. . 49:
La línea 41 es especialmente interesante, incluso cuando la depuración está deshabilitada, la memoria todavía está asignada allí, podemos usar el análisis de escape para examinarlo con más detalle.Go Escape Analysis Tool es en realidad una bandera compiladora$ go build -gcflags '-m'
Puede agregar otro -m para obtener más información.$ go build -gcflags '-m '
para una interfaz más conveniente, use view-annotated-file .$ go build -gcflags '-m'
.
.
.
../redins.go:39:20: leaking param: w
./redins.go:39:42: leaking param: r
./redins.go:41:55: r.MsgHdr.Id escapes to heap
./redins.go:41:75: context.RawName() escapes to heap
./redins.go:41:91: context.Request.Type() escapes to heap
./redins.go:41:23: handleRequest []interface {} literal does not escape
./redins.go:219:17: leaking param: path
.
.
.
Aquí todos los parámetros Debugfvan al montón. Esto se debe a la forma de determinar Debugf:func (l *EventLogger) Debugf(format string, args ...interface{})
Todos los parámetros se argsconvierten a un tipo interface{}que siempre se descarga al montón. Podemos eliminar los registros de depuración o usar una biblioteca de registros con una distribución cero, por ejemplo, zerolog .Para obtener más información sobre el análisis de escape, consulte "eficiencia de asignación en golang" .Trabajar con cuerdas(pprof) list reverseZone
Total: 100817064
ROUTINE ======================== arvancloud/redins/handler.reverseZone in /home/arash/go/src/arvancloud/redins/handler/handler.go
6127746 10379086 (flat, cum) 10.29% of Total
. . 396: logger.Default.Warning("log queue is full")
. . 397: }
. . 398:}
. . 399:
. . 400:func reverseZone(zone string) string {
. 4251340 401: x := strings.Split(zone, ".")
. . 402: var y string
. . 403: for i := len(x) - 1; i >= 0; i-- {
6127746 6127746 404: y += x[i] + "."
. . 405: }
. . 406: return y
. . 407:}
. . 408:
. . 409:func (h *DnsRequestHandler) LoadZones() {
(pprof)
Como una línea en Go es inmutable, la creación de una línea temporal provoca la asignación de memoria. Comenzando con Go 1.10, puede usarlo strings.Builderpara crear una cadena.(pprof) list reverseZone
Total: 93437002
ROUTINE ======================== arvancloud/redins/handler.reverseZone in /home/arash/go/src/arvancloud/redins/handler/handler.go
0 7580611 (flat, cum) 8.11% of Total
. . 396: logger.Default.Warning("log queue is full")
. . 397: }
. . 398:}
. . 399:
. . 400:func reverseZone(zone string) string {
. 3681140 401: x := strings.Split(zone, ".")
. . 402: var sb strings.Builder
. 3899471 403: sb.Grow(len(zone)+1)
. . 404: for i := len(x) - 1; i >= 0; i-- {
. . 405: sb.WriteString(x[i])
. . 406: sb.WriteByte('.')
. . 407: }
. . 408: return sb.String()
Como no nos importa el valor de la línea invertida, podemos eliminarla Split()simplemente volteando toda la línea.(pprof) list reverseZone
Total: 89094296
ROUTINE ======================== arvancloud/redins/handler.reverseZone in /home/arash/go/src/arvancloud/redins/handler/handler.go
3801168 3801168 (flat, cum) 4.27% of Total
. . 400:func reverseZone(zone string) []byte {
. . 401: runes := []rune("." + zone)
. . 402: for i, j := 0, len(runes)-1; i < j; i, j = i+1, j-1 {
. . 403: runes[i], runes[j] = runes[j], runes[i]
. . 404: }
3801168 3801168 405: return []byte(string(runes))
. . 406:}
. . 407:
. . 408:func (h *DnsRequestHandler) LoadZones() {
. . 409: h.LastZoneUpdate = time.Now()
. . 410: zones, err := h.Redis.SMembers("redins:zones")
Lea más sobre cómo trabajar con cadenas aquí .sync.Pool
(pprof) list GetASN
Total: 69005282
ROUTINE ======================== arvancloud/redins/handler.(*GeoIp).GetASN in /home/arash/go/src/arvancloud/redins/handler/geoip.go
1146897 1146897 (flat, cum) 1.66% of Total
. . 231:func (g *GeoIp) GetASN(ip net.IP) (uint, error) {
1146897 1146897 232: var record struct {
. . 233: AutonomousSystemNumber uint `maxminddb:"autonomous_system_number"`
. . 234: }
. . 235: err := g.ASNDB.Lookup(ip, &record)
. . 236: if err != nil {
. . 237: logger.Default.Errorf("lookup failed : %s", err)
(pprof) list GetGeoLocation
Total: 69005282
ROUTINE ======================== arvancloud/redins/handler.(*GeoIp).GetGeoLocation in /home/arash/go/src/arvancloud/redins/handler/geoip.go
1376298 3604572 (flat, cum) 5.22% of Total
. . 207:
. . 208:func (g *GeoIp) GetGeoLocation(ip net.IP) (latitude float64, longitude float64, country string, err error) {
. . 209: if !g.Enable || g.CountryDB == nil {
. . 210: return
. . 211: }
1376298 1376298 212: var record struct {
. . 213: Location struct {
. . 214: Latitude float64 `maxminddb:"latitude"`
. . 215: LongitudeOffset uintptr `maxminddb:"longitude"`
. . 216: } `maxminddb:"location"`
. . 217: Country struct {
. . 218: ISOCode string `maxminddb:"iso_code"`
. . 219: } `maxminddb:"country"`
. . 220: }
. . 221:
. . 222: if err := g.CountryDB.Lookup(ip, &record); err != nil {
. . 223: logger.Default.Errorf("lookup failed : %s", err)
. . 224: return 0, 0, "", err
. . 225: }
. 2228274 226: _ = g.CountryDB.Decode(record.Location.LongitudeOffset, &longitude)
. . 227:
. . 228: return record.Location.Latitude, longitude, record.Country.ISOCode, nil
. . 229:}
. . 230:
. . 231:func (g *GeoIp) GetASN(ip net.IP) (uint, error) {
Utilizamos las funciones maxmiddb para obtener datos de geolocalización. Estas funciones se toman interface{}como parámetros que, como vimos anteriormente, pueden causar brotes de almacenamiento dinámico.podemos usar sync.Poolpara almacenar en caché elementos seleccionados pero no utilizados para su posterior reutilización.type MMDBGeoLocation struct {
Coordinations struct {
Latitude float64 `maxminddb:"latitude"`
Longitude float64
LongitudeOffset uintptr `maxminddb:"longitude"`
} `maxminddb:"location"`
Country struct {
ISOCode string `maxminddb:"iso_code"`
} `maxminddb:"country"`
}
type MMDBASN struct {
AutonomousSystemNumber uint `maxminddb:"autonomous_system_number"`
}
func (g *GeoIp) GetGeoLocation(ip net.IP) (*MMDBGeoLocation, error) {
if !g.Enable || g.CountryDB == nil {
return nil, EMMDBNotAvailable
}
var record *MMDBGeoLocation = g.LocationPool.Get().(*MMDBGeoLocation)
logger.Default.Debugf("ip : %s", ip)
if err := g.CountryDB.Lookup(ip, &record); err != nil {
logger.Default.Errorf("lookup failed : %s", err)
return nil, err
}
_ = g.CountryDB.Decode(record.Coordinations.LongitudeOffset, &record.Coordinations.Longitude)
logger.Default.Debug("lat = ", record.Coordinations.Latitude, " lang = ", record.Coordinations.Longitude, " country = ", record.Country.ISOCode)
return record, nil
}
func (g *GeoIp) GetASN(ip net.IP) (uint, error) {
var record *MMDBASN = g.AsnPool.Get().(*MMDBASN)
err := g.ASNDB.Lookup(ip, record)
if err != nil {
logger.Default.Errorf("lookup failed : %s", err)
return 0, err
}
logger.Default.Debug("asn = ", record.AutonomousSystemNumber)
return record.AutonomousSystemNumber, nil
}
Más información sobre la sincronización . Piscina aquí .Hay muchas otras optimizaciones posibles, pero por el momento, parece que ya hemos hecho lo suficiente. Para obtener más información sobre las técnicas de optimización de memoria, puede leer Eficiencia de asignación en los servicios Go de alto rendimiento .resultados
Para visualizar los resultados de la optimización de la memoria, usamos un diagrama go tool tracetitulado "Utilización mínima del mutador", aquí Mutador significa no gc.Antes de la optimización: aquí tenemos una ventana de aproximadamente 500 milisegundos sin un uso eficiente (gc consume todos los recursos), y nunca obtendremos un 80% de uso efectivo a largo plazo. Queremos que la ventana de uso efectivo cero sea lo más pequeña posible y lo más rápido posible para lograr un uso del 100%, algo así:después de la optimización:
aquí tenemos una ventana de aproximadamente 500 milisegundos sin un uso eficiente (gc consume todos los recursos), y nunca obtendremos un 80% de uso efectivo a largo plazo. Queremos que la ventana de uso efectivo cero sea lo más pequeña posible y lo más rápido posible para lograr un uso del 100%, algo así:después de la optimización: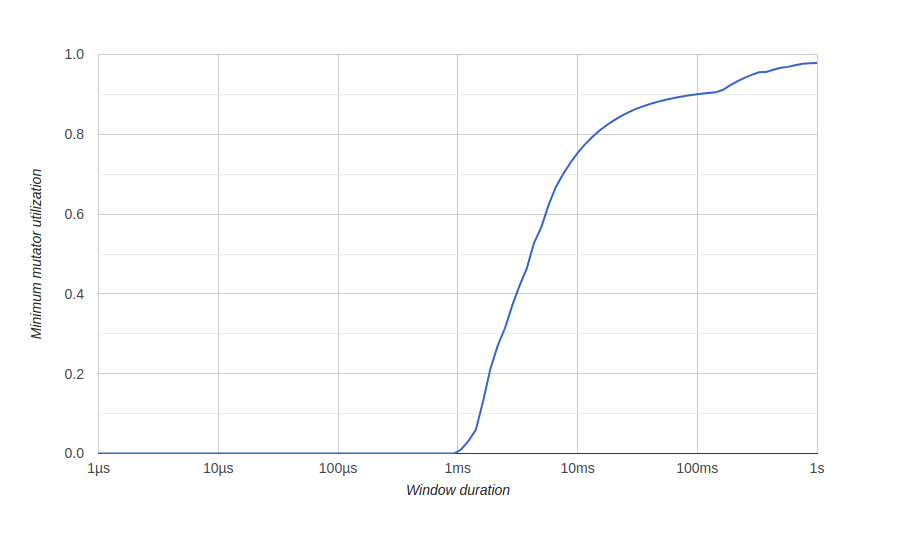
Conclusión
Mediante el uso de herramientas go, pudimos optimizar nuestro servicio para manejar una gran cantidad de solicitudes y un mejor uso de los recursos del sistema.Puedes ver nuestro código fuente en GitHub . Aquí hay una versión no optimizada y aquí hay una versión optimizada.También será útil
Eso es todo. ¡Nos vemos en el curso !