Hace unas semanas, en una conversación durante la cena, un colega se quejó de algún tipo de proceso lento. Calculó la cantidad de bytes generados, la cantidad de ciclos de procesamiento y, en última instancia, la cantidad de RAM. Un colega dijo que una GPU moderna con un ancho de banda de memoria de más de 500 GB / s consumiría su tarea y no se ahogaría.Me pareció que este es un enfoque interesante. Personalmente, no he evaluado previamente los objetivos de rendimiento desde esta perspectiva. Sí, sé sobre la diferencia en el rendimiento del procesador y la memoria. Sé cómo escribir código que hace un uso intensivo del caché. Sé las cifras aproximadas de retraso. Pero esto no es suficiente para evaluar de inmediato el ancho de banda de la memoria.Aquí hay un experimento mental. Imagine en la memoria una matriz continua de mil millones de enteros de 32 bits. Esto es de 4 gigabytes. ¿Cuánto tiempo llevará iterar sobre esta matriz y sumar los valores? ¿Cuántos bytes por segundo puede leer la CPU de la RAM? ¿Datos continuos? ¿Acceso aleatorio? ¿Qué tan bien se puede paralelizar este proceso?Dirás que estas son preguntas inútiles. Los programas reales son demasiado complejos para hacer un hito tan ingenuo. ¡Y ahí está! La verdadera respuesta es "dependiendo de la situación".Sin embargo, creo que vale la pena explorar este tema. No estoy tratando de encontrar la respuesta . Pero creo que podemos definir algunos límites superiores e inferiores, algunos puntos interesantes en el medio y aprender algo en el proceso.
Sé cómo escribir código que hace un uso intensivo del caché. Sé las cifras aproximadas de retraso. Pero esto no es suficiente para evaluar de inmediato el ancho de banda de la memoria.Aquí hay un experimento mental. Imagine en la memoria una matriz continua de mil millones de enteros de 32 bits. Esto es de 4 gigabytes. ¿Cuánto tiempo llevará iterar sobre esta matriz y sumar los valores? ¿Cuántos bytes por segundo puede leer la CPU de la RAM? ¿Datos continuos? ¿Acceso aleatorio? ¿Qué tan bien se puede paralelizar este proceso?Dirás que estas son preguntas inútiles. Los programas reales son demasiado complejos para hacer un hito tan ingenuo. ¡Y ahí está! La verdadera respuesta es "dependiendo de la situación".Sin embargo, creo que vale la pena explorar este tema. No estoy tratando de encontrar la respuesta . Pero creo que podemos definir algunos límites superiores e inferiores, algunos puntos interesantes en el medio y aprender algo en el proceso.Los números que todo programador debe saber
Si lees blogs de programación, probablemente encuentres "números que todo programador debería saber". Se ven algo así:Enlace a caché L1 0.5 ns
Predicción incorrecta de 5 ns
Enlace a caché L2 7 ns 14x a caché L1
Mutex Capture / Release 25 ns
Enlace a memoria principal 100 ns 20x a caché L2, 200x a caché L1
Comprima 1000 bytes con Zippy 3000 ns 3 μs
Envío de 1000 bytes a través de una red de 1 Gbps 10,000 ns 10 μs
Lectura aleatoria 4000 con SSD 150,000 ns 150 μs ~ 1GB / s SSD
Lea 1 MB secuencialmente de 250,000 ns 250 μs
Paquete de ida y vuelta dentro del centro de datos 500,000 ns 500 μs
1 MB de lectura secuencial en SSD 1,000,000 ns 1,000 μs 1 ms ~ 1 GB / s SSD, 4x memoria
Búsqueda de disco 10,000,000 ns 10,000 μs 10 ms 20x al centro de datos
Lea 1 MB secuencialmente desde el disco 20,000,000 ns 20,000 μs 20 ms 80x en memoria, 20x en SSD
Envío de paquetes CA-> Países Bajos-> CA 150,000,000 ns 150,000 μs 150 ms
Fuente: Jonas BonerGran lista. Aparece en HackerNews al menos una vez al año. Todo programador debe saber estos números.Pero estos números son sobre otra cosa. La latencia y el ancho de banda no son lo mismo.Retraso en 2020
Esa lista fue compilada en 2012, y este artículo de 2020, los tiempos han cambiado. Estos son los números de Intel i7 con StackOverflow .Hit en caché L1, ~ 4 ciclos (2.1 - 1.2 ns)
Hit en el caché L2, ~ 10 ciclos (5.3 - 3.0 ns)
Hit en el caché L3, para un solo núcleo ~ 40 ciclos (21.4 - 12.0 ns)
Hit en caché L3, juntos por otro kernel ~ 65 ciclos (34.8 - 19.5 ns)
Golpee el caché L3, con un cambio para otro kernel ~ 75 ciclos (40.2 - 22.5 ns)
RAM local ~ 60 ns
¡Interesante! ¿Qué cambió?- L1 se ha vuelto más lento;
0,5 → 1,5
- L2 más rápido;
7 → 4,2
- La relación de L1 y L2 se reduce mucho;
2,5x 14(¡Guau!)
- El caché L3 ahora se ha convertido en el estándar;
12 40
- RAM se ha vuelto más rápido;
100 → 60
No sacaremos conclusiones de largo alcance. No está claro cómo se calcularon los números originales. No compararemos manzanas con naranjas.Aquí hay algunas cifras de wikichip sobre el ancho de banda y el tamaño de caché de mi procesador.Ancho de banda de memoria: 39,74 gigabytes por segundo
Caché L1: 192 kilobytes (32 KB por núcleo)
Caché L2: 1.5 megabytes (256 KB por núcleo)
Caché L3: 12 megabytes (compartido; 2 MB por núcleo)
Qué quiero saber:- Límite superior de rendimiento de RAM
- límite inferior
- Límites de caché L1 / L2 / L3
Benchmarking ingenuo
Hagamos algunas pruebas. Para medir el ancho de banda, escribí un programa simple de C ++. Muy aproximadamente ella se ve así.
std::vector<int> nums;
for (size_t i = 0; i < 1024*1024*1024; ++i)
nums.push_back(rng() % 1024);
for (int thread_count = 1; thread_count <= MAX_THREADS; ++thread_count) {
auto slice_len = nums.size() / thread_count;
for (size_t thread = 0; thread < thread_count; ++thread) {
auto begin = nums.begin() + thread * slice_len;
auto end = (thread == thread_count - 1)
? nums.end() : begin + slice_len;
futures.push_back(std::async([begin, end] {
int64_t sum = 0;
for (auto ptr = begin; ptr < end; ++ptr)
sum += *ptr;
return sum;
}));
}
int64_t sum = 0;
for (auto& future : futures)
sum += future.get();
}
Se omiten algunos detalles. Pero entendiste la idea. Crea una gran variedad continua de elementos. Divida la matriz en fragmentos separados. Procese cada fragmento en un hilo separado. Acumular resultados.También necesita medir el acceso aleatorio. Es muy difícil. Lo intenté de varias maneras, finalmente decidí mezclar índices precalculados. Cada índice existe exactamente una vez. Luego, el bucle interno itera sobre los índices y los cálculos sum += nums[index].std::vector<int> nums = ;
std::vector<uint32_t> indices = ;
int64_t sum = 0;
for (auto ptr = indices.begin(); ptr < indices.end(); ++ptr) {
auto idx = *ptr;
sum += nums[idx];
}
return sum;
Al calcular el rendimiento, no considero la memoria de la matriz de índice. Solo se cuentan los bytes que contribuyen al total sum. No comparo mi hardware, pero evalúo la capacidad de trabajar con conjuntos de datos de diferentes tamaños y con diferentes esquemas de acceso.Realizaremos pruebas con tres tipos de datos:int- el entero principal de 32 bitsmatri4x4- contiene int[16]; cabe en una línea de caché de 64 bytesmatrix4x4_simd: utiliza herramientas integradas__m256iGran cuadra
Mi primera prueba funciona con un gran bloque de memoria. Un bloque de Nelementos de 1 GB se resalta y se llena con pequeños valores aleatorios. Un bucle simple itera sobre una matriz N veces, por lo que accede a la memoria con un volumen N para calcular la suma int64_t. Varios subprocesos dividen la matriz, y cada uno tiene acceso al mismo número de elementos.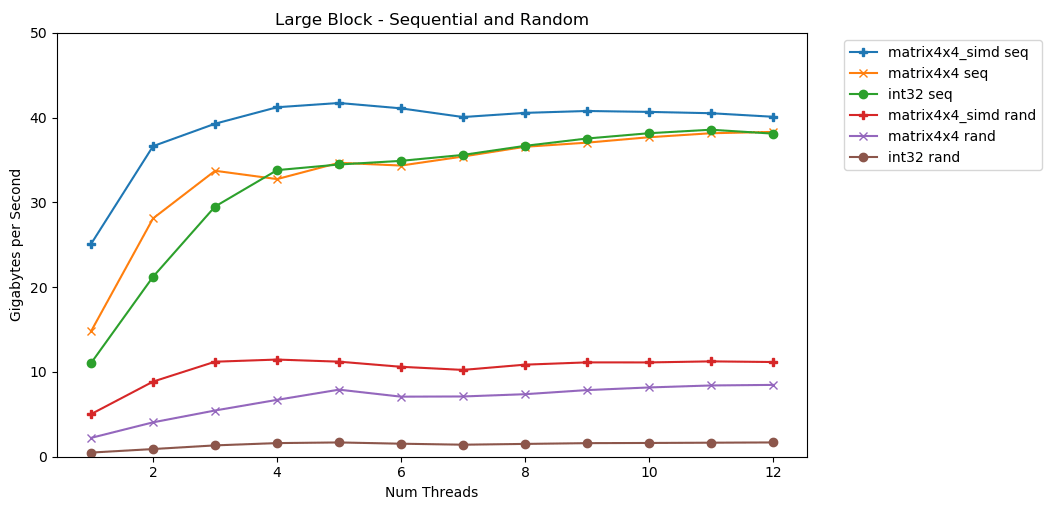 TA-dah! En este gráfico, tomamos el tiempo de ejecución promedio de la operación de suma y lo convertimos de
TA-dah! En este gráfico, tomamos el tiempo de ejecución promedio de la operación de suma y lo convertimos de runtime_in_nanosecondsa gigabytes_per_second.Muy buen resultado. int32puede leer secuencialmente 11 GB / s en una sola secuencia. Se escala linealmente hasta que alcanza 38 GB / s. Pruebas matrix4x4y matrix4x4_simdmás rápido, pero descansa contra el mismo techo.Existe un límite claro y obvio sobre la cantidad de datos que podemos leer de la RAM por segundo. En mi sistema, esto es aproximadamente 40 GB / s. Esto cumple con las especificaciones actuales enumeradas anteriormente.A juzgar por los tres gráficos inferiores, el acceso aleatorio es lento. Muy, muy lento. El rendimiento de int32un solo subproceso es insignificante 0.46 GB / s. ¡Esto es 24 veces más lento que el apilamiento secuencial a 11.03 GB / s! La prueba matrix4x4muestra el mejor resultado, porque se ejecuta en líneas de caché completas. Pero sigue siendo de cuatro a siete veces más lento que el acceso secuencial y alcanza un máximo de solo 8 GB / s.Bloque pequeño: lectura secuencial
En mi sistema, el tamaño de caché L1 / L2 / L3 para cada transmisión es de 32 KB, 256 KB y 2 MB. ¿Qué sucede si tomas un bloque de elementos de 32 kilobytes y lo repites 125,000 veces? Esto es 4 GB de memoria, pero siempre iremos al caché.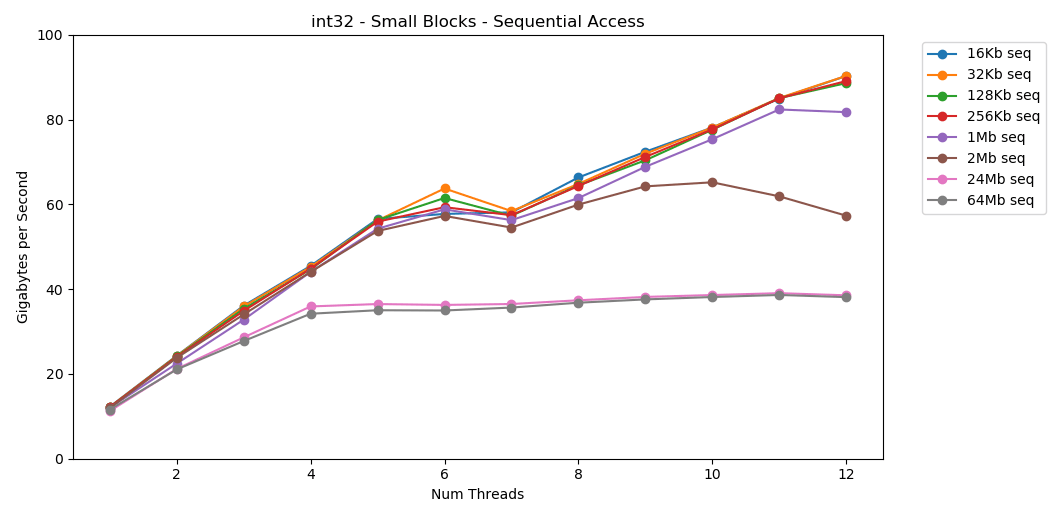 ¡Increíble! El rendimiento de subproceso único es similar a la lectura de un bloque grande, aproximadamente 12 GB / s. Excepto que esta vez, el multihilo rompe el techo de 40 GB / s. Que tiene sentido. Los datos permanecen en la memoria caché, por lo que el cuello de botella de RAM no aparece. Para los datos que no cabían en el caché L3, se aplica el mismo límite máximo de aproximadamente 38 GB / s.La prueba
¡Increíble! El rendimiento de subproceso único es similar a la lectura de un bloque grande, aproximadamente 12 GB / s. Excepto que esta vez, el multihilo rompe el techo de 40 GB / s. Que tiene sentido. Los datos permanecen en la memoria caché, por lo que el cuello de botella de RAM no aparece. Para los datos que no cabían en el caché L3, se aplica el mismo límite máximo de aproximadamente 38 GB / s.La prueba matrix4x4muestra resultados similares al circuito, pero aún más rápido; 31 GB / s en modo de subproceso único, 171 GB / s en modo de subproceso múltiple.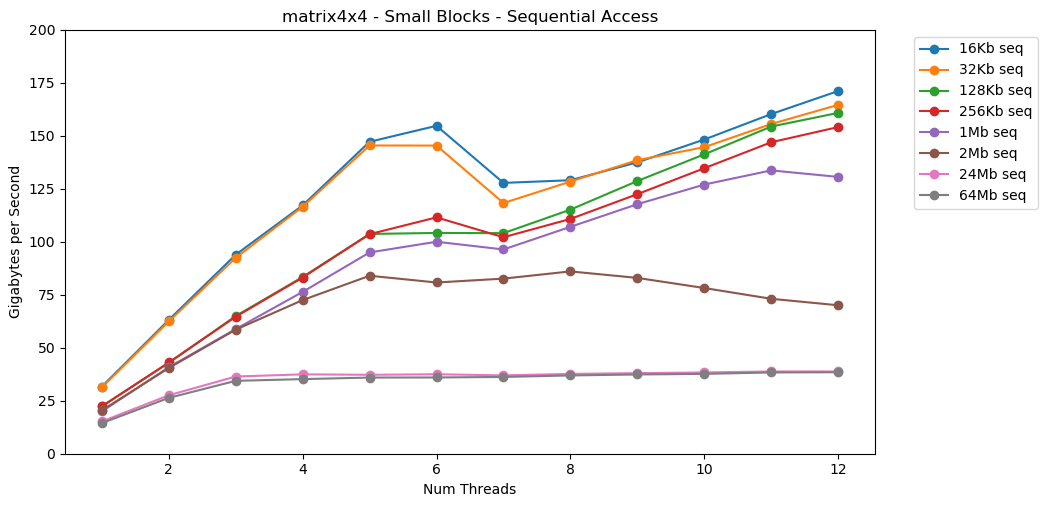 Ahora echemos un vistazo
Ahora echemos un vistazo matrix4x4_simd. Presta atención al eje y.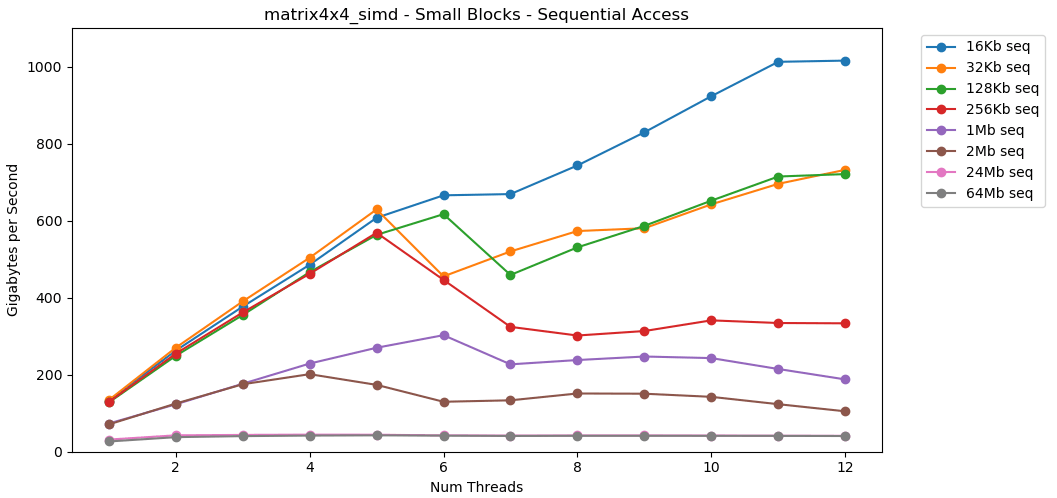
matrix4x4_simdrealizado excepcionalmente rápido. Es 10 veces más rápido que int32. ¡En un bloque de 16 KB, incluso rompe 1000 GB / s!Obviamente, esta es una prueba de superficie sintética. La mayoría de las aplicaciones no realizan la misma operación con los mismos datos un millón de veces seguidas. La prueba no muestra el rendimiento en el mundo real.Pero la lección es clara. Dentro del caché, los datos se procesan rápidamente . Con un techo muy alto cuando se usa SIMD: más de 100 GB / s en modo de subproceso único, más de 1000 GB / s en subproceso múltiple. Escribir datos en el caché es lento y tiene un límite estricto de aproximadamente 40 GB / s.Bloque pequeño: lectura aleatoria
Hagamos lo mismo, pero ahora con acceso aleatorio. Esta es mi parte favorita del artículo.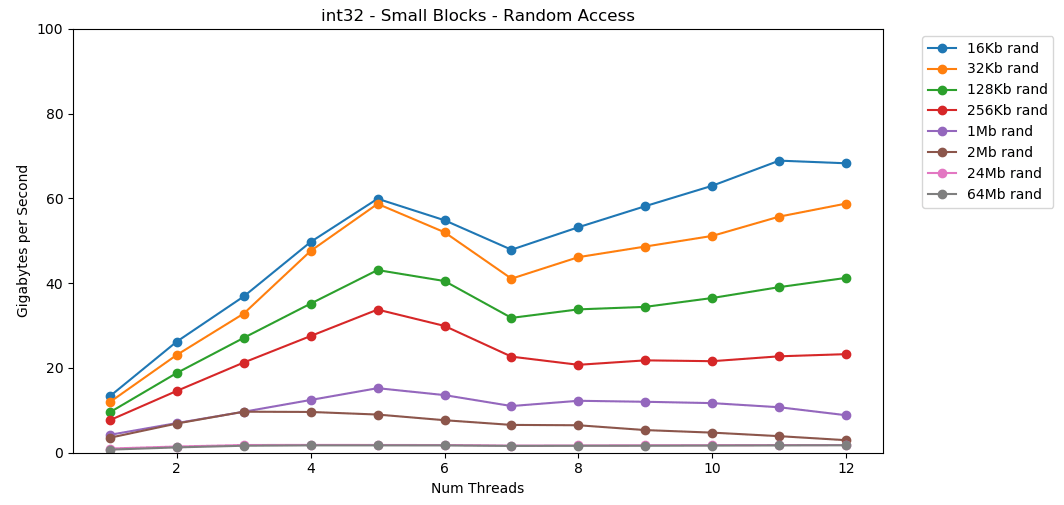 La lectura de valores aleatorios de la RAM es lenta, solo 0.46 GB / s. Leer valores aleatorios del caché L1 es muy rápido: 13 GB / s. Esto es más rápido que leer datos en serie
La lectura de valores aleatorios de la RAM es lenta, solo 0.46 GB / s. Leer valores aleatorios del caché L1 es muy rápido: 13 GB / s. Esto es más rápido que leer datos en serie int32de la RAM (11 GB / s).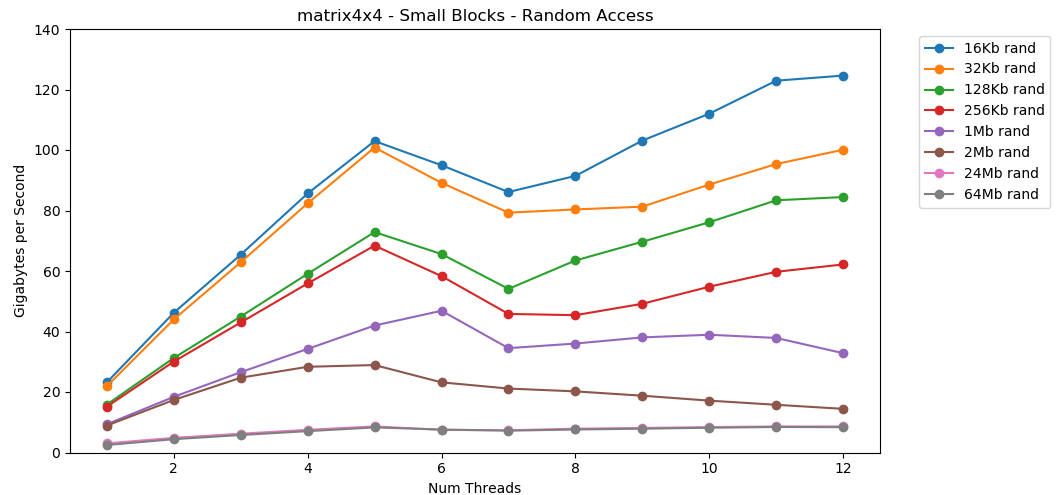 La prueba
La prueba matrix4x4muestra un resultado similar para la misma plantilla, pero aproximadamente el doble de rápido que int.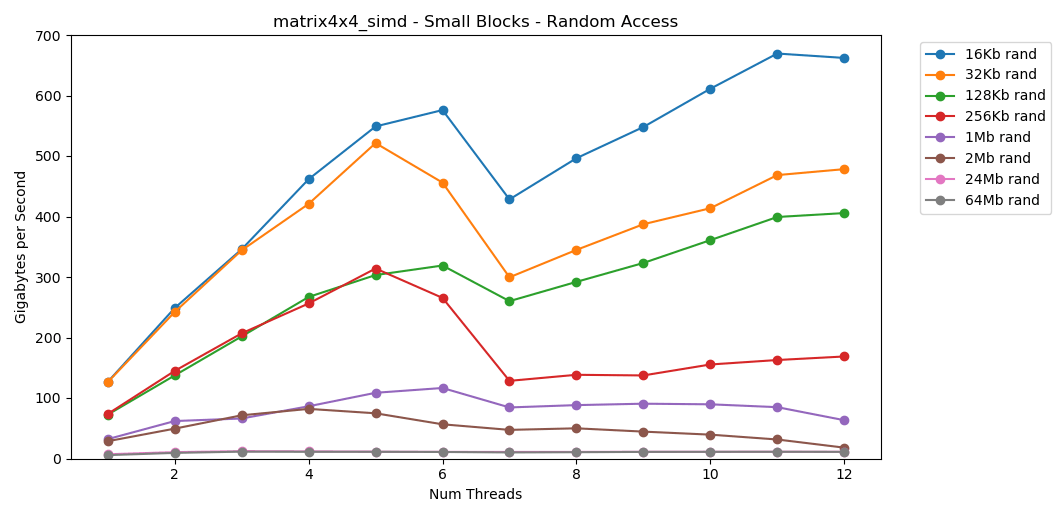 El acceso aleatorio es
El acceso aleatorio es matrix4x4_simdincreíblemente rápido.Resultados de acceso aleatorio
La lectura libre de la memoria es lenta. Catastróficamente lento. Menos de 1 GB / s para ambos casos de prueba int32. Al mismo tiempo, las lecturas aleatorias del caché son sorprendentemente rápidas. Es comparable a la lectura secuencial de RAM.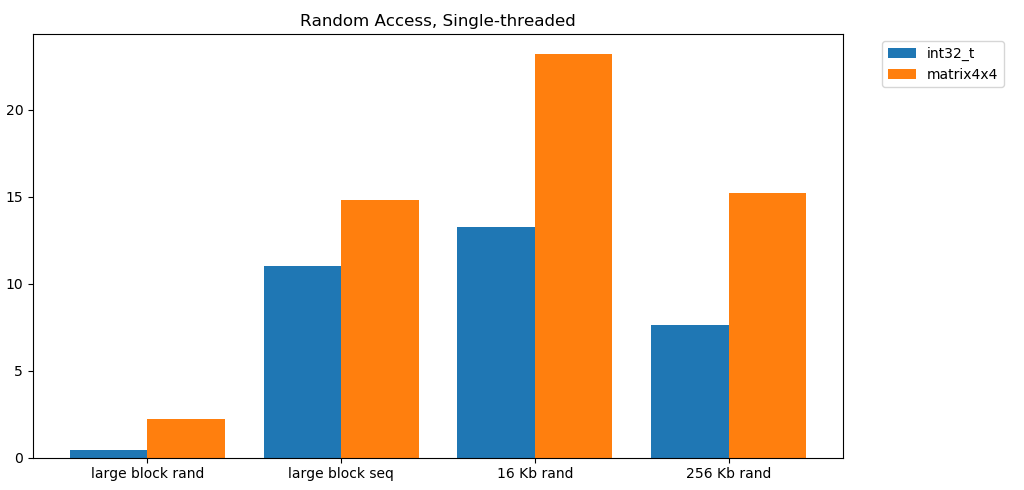 Necesita ser digerido. El acceso aleatorio al caché es comparable en velocidad al acceso secuencial a la RAM. La caída de L1 16 KB a L2 256 KB es solo la mitad o menos.Creo que esto tendrá profundas consecuencias.
Necesita ser digerido. El acceso aleatorio al caché es comparable en velocidad al acceso secuencial a la RAM. La caída de L1 16 KB a L2 256 KB es solo la mitad o menos.Creo que esto tendrá profundas consecuencias.Las listas enlazadas se consideran dañinas.
Perseguir un puntero (saltar sobre punteros) es malo. Muy muy mal. ¿Cuánto está disminuyendo el rendimiento? Ver por ti mismo. Hice una prueba adicional que se envuelve matrix4x4en std::unique_ptr. Cada acceso pasa por un puntero. Aquí hay un resultado terrible, simplemente catastrófico. 1 hilo | matriz4x4 | unique_ptr | diff |
-------------------- | --------------- | ------------ | -------- |
Bloque grande - Seq | 14,8 GB / s | 0.8 GB / s | 19x |
16 KB - Seq | 31,6 GB / s | 2,2 GB / s | 14x |
256 KB - Seq | 22,2 GB / s | 1,9 GB / s | 12x |
Bloque grande - Rand | 2,2 GB / s | 0.1 GB / s | 22x |
16 KB - Rand | 23,2 GB / s | 1,7 GB / s | 14x |
256 KB - Rand | 15,2 GB / s | 0.8 GB / s | 19x |
6 hilos | matriz4x4 | unique_ptr | diff |
-------------------- | --------------- | ------------ | -------- |
Bloque grande - Seq | 34,4 GB / s | 2.5 GB / s | 14x |
16 KB - Seq | 154,8 GB / s | 8.0 GB / s | 19x |
256 KB - Seq | 111,6 GB / s | 5,7 GB / s | 20x |
Bloque grande - Rand | 7,1 GB / s | 0.4 GB / s | 18x |
16 KB - Rand | 95.0 GB / s | 7.8 GB / s | 12x |
256 KB - Rand | 58,3 GB / s | 1,6 GB / s | 36x |La suma secuencial de los valores detrás del puntero se realiza a una velocidad de menos de 1 GB / s. La velocidad de acceso aleatorio de doble salto del caché es de solo 0.1 GB / s.Persiguiendo un puntero ralentiza la ejecución del código 10-20 veces. No dejes que tus amigos usen listas vinculadas. Por favor, piense en el caché.Estimación de presupuesto para marcos
Es común que los desarrolladores de juegos establezcan un límite (presupuesto) para la carga en la CPU y la cantidad de memoria. Pero nunca he visto un presupuesto de ancho de banda.En los juegos modernos, FPS continúa creciendo. Ahora está a 60 FPS. VR opera a una frecuencia de 90 Hz. Tengo un monitor de juego de 144 Hz. Es increíble, por lo que el 60 FPS parece una mierda. Nunca volveré al viejo monitor. Esports y streamers Twitch monitorea 240 Hz. Este año, Asus presentó un monstruo de 360 Hz en el CES.Mi procesador tiene un límite superior de aproximadamente 40 GB / s. ¡Eso parece un gran número! Sin embargo, a una frecuencia de 240 Hz, solo se obtienen 167 MB por cuadro. Una aplicación realista puede generar 5 GB / s de tráfico a 144 Hz, que es solo 69 MB por cuadro.Aquí hay una tabla con algunos números. El | 1 | 10 | 30 60 90 144 240 360 |
-------- | ------- | -------- | -------- | -------- | ------ - | -------- | -------- | -------- |
40 GB / s | 40 GB | 4 GB | 1.3 GB | 667 MB | 444 MB | 278 MB | 167 MB | 111 MB |
10 GB / s | 10 GB | 1 GB | 333 MB | 166 MB | 111 MB | 69 MB | 42 MB | 28 MB |
1 GB / s | 1 GB | 100 MB | 33 MB | 17 MB | 11 MB | 7 MB | 4 MB | 3 MB |
Me parece que es útil evaluar los problemas desde esta perspectiva. Esto deja en claro que algunas ideas no son factibles. Alcanzar 240 Hz no es fácil. Esto no sucederá por sí solo.Los números que todo programador debe saber (2020)
La lista anterior está desactualizada. Ahora debe actualizarse y ponerse en conformidad para 2020.Aquí hay algunos números para la computadora de mi casa. Esta es una mezcla de AIDA64, Sandra y mis puntos de referencia. Las figuras no dan una imagen completa y son solo un punto de partida.Latencia L1: 1 ns
Retardo L2: 2.5 ns
Retardo L3: 10 ns
Latencia RAM: 50 ns
(por hilo)
Banda L1: 210 GB / s
Banda L2: 80 GB / s
Banda L3: 60 GB / s
(sistema completo)
Banda RAM: 45 GB / s
Sería bueno crear un punto de referencia de código abierto pequeño y simple. Algunos archivos C que se pueden ejecutar en computadoras de escritorio, servidores, dispositivos móviles, consolas, etc. Pero no soy el tipo de persona que escribe dicha herramienta.Denegación de responsabilidad
Medir el ancho de banda de la memoria es difícil. Muy dificil. Probablemente hay errores en mi código. Muchos factores no contabilizados. Si tiene alguna crítica a mi técnica, probablemente tenga razón.En definitiva, creo que esto es normal. Este artículo no trata sobre el rendimiento exacto de mi escritorio. Esta es una declaración del problema desde cierto punto de vista. Y sobre cómo aprender a hacer algunos cálculos matemáticos aproximados.Conclusión
Un colega compartió conmigo una opinión interesante sobre el ancho de banda de la memoria de la GPU y el rendimiento de la aplicación. Esto me llevó a estudiar el rendimiento de la memoria en las computadoras modernas.Para cálculos aproximados, aquí hay algunos números para un escritorio moderno:- Rendimiento RAM
- Máximo:
45 / - En promedio, aproximadamente:
5 / - Mínimo:
1 /
- Rendimiento de caché L1 / L2 / L3 (por núcleo)
- Máximo (c simd):
210 // 80 //60 / - En promedio, aproximadamente:
25 // 15 //9 / - Mínimo:
13 // 8 //3,5 /
Las clasificaciones de muestra están relacionadas con el rendimiento matrix4x4. El código real nunca será tan simple. Pero para los cálculos en una servilleta, este es un punto de partida razonable. Debe ajustar esta cifra en función de los patrones de acceso a la memoria en su programa, las características de su equipo y el código.Sin embargo, lo más importante es una nueva forma de pensar sobre los problemas. Presentar el problema en bytes por segundo o bytes por cuadro es otra lente para mirar. Esta es una herramienta útil por si acaso.Gracias por leer.Fuente
Benchmark C ++Python Graphdata.jsonMás investigación
Este artículo solo tocó ligeramente el tema. Probablemente no voy a entrar en eso. Pero si lo hiciera, entonces podría cubrir algunos de los siguientes aspectos:Especificaciones del Sistema
Las pruebas se realizaron en la PC de mi casa. Solo configuraciones de stock, sin overclocking.- SO: Windows 10 v1903 compilación 18362
- CPU: Intel i7-8700k @ 3.70 GHz
- RAM: 2x16 GSkill Ripjaw DDR4-3200 (16-18-18-38 @ 1600 MHz)
- Placa base: Asus TUF Z370-Plus Gaming