Traducción de la Guía de red neuronal recursiva de Tensorflow.org. El material analiza tanto las capacidades integradas de Keras / Tensorflow 2.0 para mallado rápido, como la posibilidad de personalizar capas y celdas. También se consideran los casos y las limitaciones del uso del núcleo CuDNN, lo que permite acelerar el proceso de aprendizaje de la red neuronal.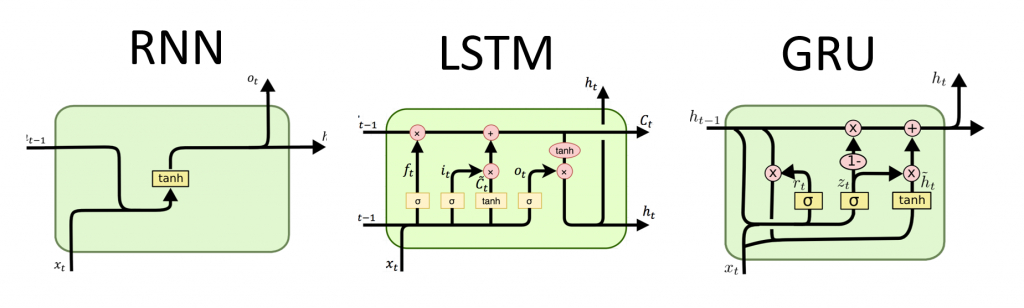 Las redes neuronales recursivas (RNN) son una clase de redes neuronales que son buenas para modelar datos en serie, como series de tiempo o lenguaje natural.Si es esquemáticamente, la capa RNN usa un bucle
Las redes neuronales recursivas (RNN) son una clase de redes neuronales que son buenas para modelar datos en serie, como series de tiempo o lenguaje natural.Si es esquemáticamente, la capa RNN usa un bucle forpara iterar sobre una secuencia ordenada en el tiempo, mientras almacena en un estado interno, información codificada sobre los pasos que ya ha visto.Keras RNN API está diseñado con un enfoque en:Facilidad de uso : una función de capas tf.keras.layers.RNN, tf.keras.layers.LSTM, tf.keras.layers.GRUle permiten construir rápidamente un modelo recursivo sin tener que realizar ajustes de configuración compleja.Fácil personalización : también puede definir su propia capa de celdas RNN (parte interna del buclefor) con un comportamiento personalizado y úselo con una capa común de `tf.keras.layers.RNN` (el bucle` for` mismo). Esto le permitirá crear rápidamente prototipos de varias ideas de investigación de manera flexible, con un mínimo de código.Instalación
from __future__ import absolute_import, division, print_function, unicode_literals
import collections
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
Construyendo un modelo simple
Keras tiene tres capas RNN incorporadas:tf.keras.layers.SimpleRNN, un RNN completamente conectado en el que la salida del paso de tiempo anterior debe pasar al siguiente paso.tf.keras.layers.GRU, propuesto por primera vez en el artículo Estudio de frases con códec RNN para traducción automática estadísticatf.keras.layers.LSTM, propuesto por primera vez en el artículo Memoria a corto plazo a largo plazo
A principios de 2015, Keras presentó las primeras implementaciones reutilizables de código abierto Python y LSTM y GRU.El siguiente es un ejemplo de un Sequentialmodelo que procesa secuencias de números enteros anidando cada número entero en un vector de 64 dimensiones, y luego procesando secuencias de vectores usando una capa LSTM.model = tf.keras.Sequential()
model.add(layers.Embedding(input_dim=1000, output_dim=64))
model.add(layers.LSTM(128))
model.add(layers.Dense(10))
model.summary()
Salidas y estados
Por defecto, la salida de la capa RNN contiene un vector por elemento. Este vector es la salida de la última celda RNN que contiene información sobre toda la secuencia de entrada. La dimensión de esta salida (batch_size, units), donde unitscorresponde al argumento unitspasado al constructor de capa.La capa RNN también puede devolver la secuencia de salida completa para cada elemento (un vector para cada paso), si así lo especifica return_sequences=True. La dimensión de esta salida es (batch_size, timesteps, units).model = tf.keras.Sequential()
model.add(layers.Embedding(input_dim=1000, output_dim=64))
model.add(layers.GRU(256, return_sequences=True))
model.add(layers.SimpleRNN(128))
model.add(layers.Dense(10))
model.summary()
Además, la capa RNN puede devolver sus estados internos finales.Los estados devueltos pueden usarse más tarde para reanudar la ejecución del RNN o para inicializar otro RNN . Esta configuración generalmente se usa en el modelo codificador-decodificador, secuencia a secuencia, donde el estado final del codificador se utiliza para el estado inicial del decodificador.Para que la capa RNN devuelva su estado interno, establezca el parámetro return_stateen valor Trueal crear la capa. Tenga en cuenta que hay LSTM2 tensores de estado, y GRUsolo uno.Para ajustar el estado inicial de una capa, simplemente llame a la capa con un argumento adicional initial_state.Tenga en cuenta que la dimensión debe coincidir con la dimensión del elemento de capa, como en el siguiente ejemplo.encoder_vocab = 1000
decoder_vocab = 2000
encoder_input = layers.Input(shape=(None, ))
encoder_embedded = layers.Embedding(input_dim=encoder_vocab, output_dim=64)(encoder_input)
output, state_h, state_c = layers.LSTM(
64, return_state=True, name='encoder')(encoder_embedded)
encoder_state = [state_h, state_c]
decoder_input = layers.Input(shape=(None, ))
decoder_embedded = layers.Embedding(input_dim=decoder_vocab, output_dim=64)(decoder_input)
decoder_output = layers.LSTM(
64, name='decoder')(decoder_embedded, initial_state=encoder_state)
output = layers.Dense(10)(decoder_output)
model = tf.keras.Model([encoder_input, decoder_input], output)
model.summary()
Capas RNN y células RNN
La API RNN, además de las capas RNN incorporadas, también proporciona API a nivel de celda. A diferencia de las capas RNN, que procesan paquetes completos de secuencias de entrada, una celda RNN procesa solo un paso de tiempo.La celda está dentro del ciclo de la forcapa RNN. Al envolver una celda con una capa, se tf.keras.layers.RNNobtiene una capa capaz de procesar paquetes de secuencia, p. RNN(LSTMCell(10)).Matemáticamente, RNN(LSTMCell(10))da el mismo resultado que LSTM(10). De hecho, la implementación de esta capa dentro de TF v1.x fue solo para crear la celda RNN correspondiente y envolverla en la capa RNN. Sin embargo, el uso de capas incrustadas GRUy LSTMpermite el uso de CuDNN que puede brindarle un mejor rendimiento.Hay tres celdas RNN incorporadas, cada una de las cuales corresponde a su propia capa RNN.tf.keras.layers.SimpleRNNCellpartidos la capa SimpleRNN.tf.keras.layers.GRUCellpartidos la capa GRU.tf.keras.layers.LSTMCellpartidos la capa LSTM.
La abstracción de una celda junto con una clase común tf.keras.layers.RNNhace que sea muy fácil implementar arquitecturas RNN personalizadas para su investigación.Estado de guardado entre lotes
Al procesar secuencias largas (posiblemente interminables), es posible que desee utilizar el patrón de estado de cross-batch .Por lo general, el estado interno de la capa RNN se restablece con cada nuevo paquete de datos (es decir, se supone que cada ejemplo que ve la capa es independiente del pasado). La capa mantendrá el estado solo mientras dure el procesamiento de este elemento.Sin embargo, si tiene secuencias muy largas, es útil dividirlas en otras más cortas y transferirlas a la capa RNN a su vez sin restablecer el estado de la capa. Por lo tanto, una capa puede almacenar información sobre la secuencia completa, aunque solo verá una subsecuencia a la vez.Puede hacer esto estableciendo `stateful = True` en el constructor.Si tiene la secuencia `s = [t0, t1, ... t1546, t1547]`, puede dividirla, por ejemplo, en:s1 = [t0, t1, ... t100]
s2 = [t101, ... t201]
...
s16 = [t1501, ... t1547]
Entonces puedes procesarlo con:lstm_layer = layers.LSTM(64, stateful=True)
for s in sub_sequences:
output = lstm_layer(s)
Cuando desee limpiar la condición, úsela layer.reset_states().Nota: En este caso, se supone que el ejemplo ien este paquete es una continuación del ejemplo del ipaquete anterior. Esto significa que todos los paquetes contienen el mismo número de elementos (tamaño del paquete). Por ejemplo, si el paquete contiene [sequence_A_from_t0_to_t100, sequence_B_from_t0_to_t100], el siguiente paquete debería contener [sequence_A_from_t101_to_t200, sequence_B_from_t101_to_t200].
Aquí hay un ejemplo completo:paragraph1 = np.random.random((20, 10, 50)).astype(np.float32)
paragraph2 = np.random.random((20, 10, 50)).astype(np.float32)
paragraph3 = np.random.random((20, 10, 50)).astype(np.float32)
lstm_layer = layers.LSTM(64, stateful=True)
output = lstm_layer(paragraph1)
output = lstm_layer(paragraph2)
output = lstm_layer(paragraph3)
lstm_layer.reset_states()
Bidireccional RNN
Para secuencias que no sean series de tiempo (p. Ej., Textos), a menudo sucede que el modelo RNN funciona mejor si procesa la secuencia no solo de principio a fin, sino también viceversa. Por ejemplo, para predecir la siguiente palabra en una oración, a menudo es útil conocer el contexto alrededor de la palabra, y no solo las palabras en frente de ella.Keras proporciona una API simple para crear tales RNN bidireccionales: un contenedor tf.keras.layers.Bidirectional.model = tf.keras.Sequential()
model.add(layers.Bidirectional(layers.LSTM(64, return_sequences=True),
input_shape=(5, 10)))
model.add(layers.Bidirectional(layers.LSTM(32)))
model.add(layers.Dense(10))
model.summary()
Debajo del capó, la Bidirectionalcapa RNN transferida go_backwardsse copiará y el campo de la capa recién copiada se volcará , y así los datos de entrada se procesarán en el orden inverso.La salida de ` BidirectionalRNN por defecto será la suma de la salida de la capa directa y la salida de la capa inversa. Si necesita otro comportamiento de fusión, p. concatenación, cambie el parámetro `merge_mode` en el constructor de contenedor` Bidirectional`.Optimización del rendimiento y núcleo CuDNN en TensorFlow 2.0
En TensorFlow 2.0, las capas LSTM y GRU incorporadas se pueden usar por defecto en los núcleos CuDNN si hay un procesador de gráficos disponible. Con este cambio, las capas anteriores keras.layers.CuDNNLSTM/CuDNNGRUestán desactualizadas y puede construir su modelo sin preocuparse por el equipo en el que funcionará.Dado que el núcleo CuDNN está construido con algunas suposiciones, esto significa que la capa no podrá usar la capa del núcleo CuDNN si cambia la configuración predeterminada de las capas LSTM o GRU incorporadas . P.ej.- Cambiar una función
activationde tanha otra. - Cambiar una función
recurrent_activationde sigmoida otra. - Uso
recurrent_dropout> 0. - Establecerlo
unrollen True, lo que hace que LSTM / GRU descomponga el interno tf.while_loopen un bucle desplegado for. - Establecer
use_biasen falso. - Usar máscaras cuando los datos de entrada no están justificados correctamente (si la máscara coincide con los datos correctos estrictamente correctos, CuDNN aún puede usarse. Este es el caso más común).
Cuando sea posible, use núcleos CuDNN
batch_size = 64
input_dim = 28
units = 64
output_size = 10
def build_model(allow_cudnn_kernel=True):
if allow_cudnn_kernel:
lstm_layer = tf.keras.layers.LSTM(units, input_shape=(None, input_dim))
else:
lstm_layer = tf.keras.layers.RNN(
tf.keras.layers.LSTMCell(units),
input_shape=(None, input_dim))
model = tf.keras.models.Sequential([
lstm_layer,
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dense(output_size)]
)
return model
Cargando el conjunto de datos MNIST
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
sample, sample_label = x_train[0], y_train[0]
Cree una instancia del modelo y compílelo
Hemos elegido sparse_categorical_crossentropyen función de las pérdidas. La salida del modelo tiene una dimensión [batch_size, 10]. La respuesta del modelo es un vector entero, cada uno de los números está en el rango de 0 a 9.model = build_model(allow_cudnn_kernel=True)
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='sgd',
metrics=['accuracy'])
model.fit(x_train, y_train,
validation_data=(x_test, y_test),
batch_size=batch_size,
epochs=5)
Construya un nuevo modelo sin núcleo CuDNN
slow_model = build_model(allow_cudnn_kernel=False)
slow_model.set_weights(model.get_weights())
slow_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='sgd',
metrics=['accuracy'])
slow_model.fit(x_train, y_train,
validation_data=(x_test, y_test),
batch_size=batch_size,
epochs=1)
Como puede ver, el modelo construido con CuDNN es mucho más rápido para el entrenamiento que el modelo que usa el núcleo TensorFlow habitual.El mismo modelo con soporte CuDNN se puede utilizar para la salida en un entorno de procesador único. La anotación tf.devicesimplemente indica el dispositivo utilizado. El modelo se ejecutará de forma predeterminada en la CPU si la GPU no está disponible.Simplemente no necesita preocuparse por el hardware en el que está trabajando. ¿No es genial?with tf.device('CPU:0'):
cpu_model = build_model(allow_cudnn_kernel=True)
cpu_model.set_weights(model.get_weights())
result = tf.argmax(cpu_model.predict_on_batch(tf.expand_dims(sample, 0)), axis=1)
print('Predicted result is: %s, target result is: %s' % (result.numpy(), sample_label))
plt.imshow(sample, cmap=plt.get_cmap('gray'))
RNN con entrada de lista / diccionario o entrada anidada
Las estructuras anidadas le permiten incluir más información en un solo paso. Por ejemplo, un cuadro de video puede contener entrada de audio y video simultáneamente. La dimensión de los datos en este caso puede ser:[batch, timestep, {\"video\": [height, width, channel], \"audio\": [frequency]}]
En otro ejemplo, los datos escritos a mano pueden tener coordenadas xey para la posición actual del lápiz, así como información de presión. Entonces los datos se pueden representar de la siguiente manera:[batch, timestep, {\"location\": [x, y], \"pressure\": [force]}]
El siguiente código crea un ejemplo de una celda RNN personalizada que funciona con dicha entrada estructurada.Definir una celda de usuario que admita entrada / salida anidada
NestedInput = collections.namedtuple('NestedInput', ['feature1', 'feature2'])
NestedState = collections.namedtuple('NestedState', ['state1', 'state2'])
class NestedCell(tf.keras.layers.Layer):
def __init__(self, unit_1, unit_2, unit_3, **kwargs):
self.unit_1 = unit_1
self.unit_2 = unit_2
self.unit_3 = unit_3
self.state_size = NestedState(state1=unit_1,
state2=tf.TensorShape([unit_2, unit_3]))
self.output_size = (unit_1, tf.TensorShape([unit_2, unit_3]))
super(NestedCell, self).__init__(**kwargs)
def build(self, input_shapes):
input_1 = input_shapes.feature1[1]
input_2, input_3 = input_shapes.feature2[1:]
self.kernel_1 = self.add_weight(
shape=(input_1, self.unit_1), initializer='uniform', name='kernel_1')
self.kernel_2_3 = self.add_weight(
shape=(input_2, input_3, self.unit_2, self.unit_3),
initializer='uniform',
name='kernel_2_3')
def call(self, inputs, states):
input_1, input_2 = tf.nest.flatten(inputs)
s1, s2 = states
output_1 = tf.matmul(input_1, self.kernel_1)
output_2_3 = tf.einsum('bij,ijkl->bkl', input_2, self.kernel_2_3)
state_1 = s1 + output_1
state_2_3 = s2 + output_2_3
output = [output_1, output_2_3]
new_states = NestedState(state1=state_1, state2=state_2_3)
return output, new_states
Construya un modelo RNN con entrada / salida anidada
Construyamos un modelo de Keras que use una capa tf.keras.layers.RNNy una celda personalizada que acabamos de definir.unit_1 = 10
unit_2 = 20
unit_3 = 30
input_1 = 32
input_2 = 64
input_3 = 32
batch_size = 64
num_batch = 100
timestep = 50
cell = NestedCell(unit_1, unit_2, unit_3)
rnn = tf.keras.layers.RNN(cell)
inp_1 = tf.keras.Input((None, input_1))
inp_2 = tf.keras.Input((None, input_2, input_3))
outputs = rnn(NestedInput(feature1=inp_1, feature2=inp_2))
model = tf.keras.models.Model([inp_1, inp_2], outputs)
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])unit_1 = 10
unit_2 = 20
unit_3 = 30
input_1 = 32
input_2 = 64
input_3 = 32
batch_size = 64
num_batch = 100
timestep = 50
cell = NestedCell(unit_1, unit_2, unit_3)
rnn = tf.keras.layers.RNN(cell)
inp_1 = tf.keras.Input((None, input_1))
inp_2 = tf.keras.Input((None, input_2, input_3))
outputs = rnn(NestedInput(feature1=inp_1, feature2=inp_2))
model = tf.keras.models.Model([inp_1, inp_2], outputs)
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])
Entrenar el modelo en datos generados aleatoriamente
Dado que no tenemos un buen conjunto de datos para este modelo, utilizamos datos aleatorios generados por la biblioteca Numpy para la demostración.input_1_data = np.random.random((batch_size * num_batch, timestep, input_1))
input_2_data = np.random.random((batch_size * num_batch, timestep, input_2, input_3))
target_1_data = np.random.random((batch_size * num_batch, unit_1))
target_2_data = np.random.random((batch_size * num_batch, unit_2, unit_3))
input_data = [input_1_data, input_2_data]
target_data = [target_1_data, target_2_data]
model.fit(input_data, target_data, batch_size=batch_size)
Con una capa, tf.keras.layers.RNNsolo necesita determinar la lógica matemática de un solo paso dentro de la secuencia, y la capa tf.keras.layers.RNNmanejará la iteración de la secuencia por usted. Esta es una forma increíblemente poderosa de crear rápidamente prototipos de nuevos tipos de RNN (por ejemplo, la variante LSTM).Después de la verificación, la traducción también aparecerá en Tensorflow.org. Si desea participar en la traducción de la documentación del sitio web de Tensorflow.org al ruso, comuníquese personalmente o envíe sus comentarios. Cualquier corrección y comentario son apreciados.