HighLoad ++, Mikhail Tyulenev (MongoDB): Consistencia causal: de la teoría a la práctica
La próxima conferencia HighLoad ++ se llevará a cabo los días 6 y 7 de abril de 2020 en San Petersburgo.Detalles y entradas aquí . HighLoad ++ Siberia 2019. Salón "Krasnoyarsk". 25 de junio, 12:00. Resúmenes y presentación . Sucede que los requisitos prácticos entran en conflicto con una teoría en la que no se tienen en cuenta aspectos importantes para un producto comercial. Este informe presenta el proceso de selección y combinación de varios enfoques para crear componentes de consistencia causal basados en investigaciones académicas basadas en los requisitos de un producto comercial. Los estudiantes aprenderán sobre los enfoques teóricos existentes para los relojes lógicos, el seguimiento de dependencias, la seguridad del sistema, la sincronización del reloj y por qué MongoDB se detuvo en estas o esas soluciones.Mikhail Tyulenev (en adelante, MT): - Hablaré sobre la coherencia causal: esta es una característica en la que trabajamos en MongoDB. Trabajo en un grupo de sistemas distribuidos, lo hicimos hace unos dos años.
Sucede que los requisitos prácticos entran en conflicto con una teoría en la que no se tienen en cuenta aspectos importantes para un producto comercial. Este informe presenta el proceso de selección y combinación de varios enfoques para crear componentes de consistencia causal basados en investigaciones académicas basadas en los requisitos de un producto comercial. Los estudiantes aprenderán sobre los enfoques teóricos existentes para los relojes lógicos, el seguimiento de dependencias, la seguridad del sistema, la sincronización del reloj y por qué MongoDB se detuvo en estas o esas soluciones.Mikhail Tyulenev (en adelante, MT): - Hablaré sobre la coherencia causal: esta es una característica en la que trabajamos en MongoDB. Trabajo en un grupo de sistemas distribuidos, lo hicimos hace unos dos años. En el proceso, tuve que familiarizarme con mucha investigación académica, porque esta característica está bien estudiada. Resultó que ni un solo artículo se ajusta a lo que se requiere en producción, la base de datos en vista de requisitos muy específicos, que probablemente se encuentran en cualquier aplicación de producción.Hablaré sobre cómo nosotros, como consumidores de Investigación académica, preparamos algo que luego podemos presentar a nuestros usuarios como un plato listo para usar, conveniente y seguro.
En el proceso, tuve que familiarizarme con mucha investigación académica, porque esta característica está bien estudiada. Resultó que ni un solo artículo se ajusta a lo que se requiere en producción, la base de datos en vista de requisitos muy específicos, que probablemente se encuentran en cualquier aplicación de producción.Hablaré sobre cómo nosotros, como consumidores de Investigación académica, preparamos algo que luego podemos presentar a nuestros usuarios como un plato listo para usar, conveniente y seguro.Consistencia causal. Definamos conceptos
Para empezar, quiero describir en términos generales qué es la coherencia causal. Hay dos personajes: Leonard y Penny (la serie "The Big Bang Theory"):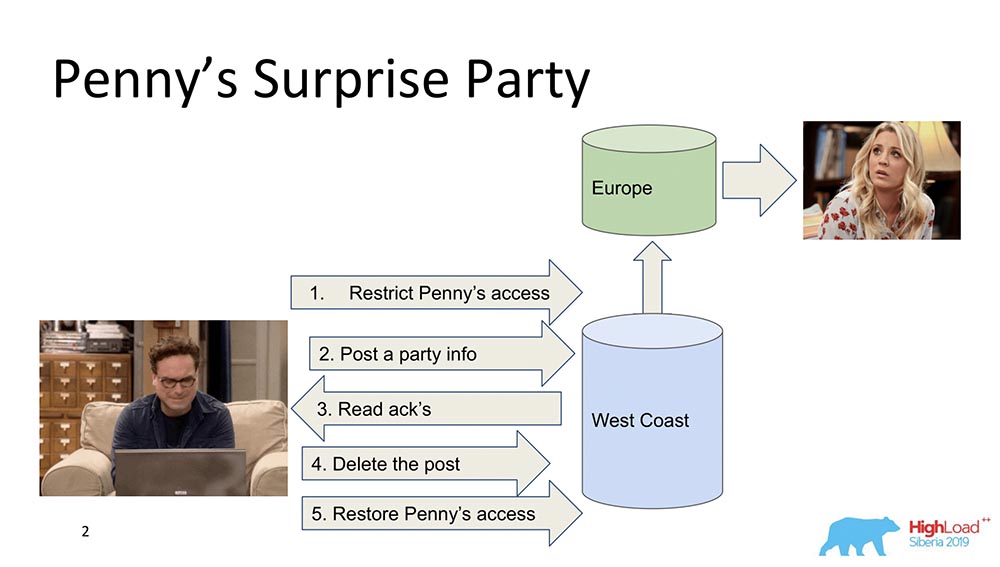 supongamos que Penny está en Europa, y Leonard quiere hacerle algún tipo de sorpresa, una fiesta. Y no se le ocurre nada mejor que echarla de la lista de amigos, enviando actualizaciones para alimentar a todos los amigos: "¡Hagamos feliz a Penny!" (ella en Europa, mientras duerme, no ve todo esto y no puede ver, porque no está allí). Al final, elimina esta publicación, la borra del "Feed" y restaura el acceso para que no note nada y no haya escándalo.Todo está bien, pero supongamos que el sistema está distribuido y que los eventos salieron un poco mal. Tal vez, por ejemplo, sucede que la restricción de acceso de Penny ocurrió después de que apareció esta publicación, si los eventos no están conectados por una relación causal. En realidad, este es un ejemplo de cuándo se requiere coherencia causal para cumplir una función comercial (en este caso).De hecho, estas son propiedades bastante triviales de la base de datos: muy pocas personas las admiten. Pasemos a las modelos.
supongamos que Penny está en Europa, y Leonard quiere hacerle algún tipo de sorpresa, una fiesta. Y no se le ocurre nada mejor que echarla de la lista de amigos, enviando actualizaciones para alimentar a todos los amigos: "¡Hagamos feliz a Penny!" (ella en Europa, mientras duerme, no ve todo esto y no puede ver, porque no está allí). Al final, elimina esta publicación, la borra del "Feed" y restaura el acceso para que no note nada y no haya escándalo.Todo está bien, pero supongamos que el sistema está distribuido y que los eventos salieron un poco mal. Tal vez, por ejemplo, sucede que la restricción de acceso de Penny ocurrió después de que apareció esta publicación, si los eventos no están conectados por una relación causal. En realidad, este es un ejemplo de cuándo se requiere coherencia causal para cumplir una función comercial (en este caso).De hecho, estas son propiedades bastante triviales de la base de datos: muy pocas personas las admiten. Pasemos a las modelos.Modelos de consistencia
¿Qué es un modelo de coherencia en las bases de datos en general? Estas son algunas de las garantías que ofrece un sistema distribuido con respecto a qué datos y en qué secuencia puede recibir el cliente.En principio, todos los modelos de consistencia se reducen a qué tan distribuido es el sistema como un sistema que funciona, por ejemplo, con el mismo gesto en una computadora portátil. Y así es como el sistema, que funciona en miles de "Nodos" geo-distribuidos, es similar a una computadora portátil, en la que todas estas propiedades se ejecutan automáticamente en principio.Por lo tanto, los modelos de coherencia solo se aplican a los sistemas distribuidos. Todos los sistemas que existían anteriormente y funcionaban en la misma escala vertical no experimentaron tales problemas. Había una caché de búfer, y siempre se leía todo.Modelo fuerte
En realidad, el primer modelo es Fuerte (o la línea de capacidad de subida, como se le llama a menudo). Este es un modelo de coherencia que garantiza que cada cambio, tan pronto como se reciba la confirmación de que ha ocurrido, sea visible para todos los usuarios del sistema.Esto crea un orden global de todos los eventos en la base de datos. Esta es una propiedad de consistencia muy fuerte, y generalmente es muy costosa. Sin embargo, está muy bien mantenido. Simplemente es muy costoso y lento, simplemente rara vez se usan. Esto se llama capacidad de subida.Hay otra propiedad más poderosa que se admite en la "Llave", llamada Consistencia Externa. Hablaremos de él un poco más tarde.Causal
Lo siguiente es Causal, justo de lo que estaba hablando. Hay varios subniveles entre Strong y Causal de los que no hablaré, pero todos se reducen a Causal. Este es un modelo importante porque es el más fuerte de todos los modelos, la consistencia más fuerte en presencia de una red o particiones.Causales es en realidad una situación en la que los eventos están conectados por una relación causal. Muy a menudo se perciben como Lea sus derechos desde el punto de vista del cliente. Si el cliente observó algunos valores, no puede ver los valores que estaban en el pasado. Ya está comenzando a ver lecturas de prefijos. Todo se reduce a lo mismo.Causales como modelo de coherencia es un ordenamiento parcial de eventos en el servidor, en el que los eventos de todos los clientes se observan en la misma secuencia. En este caso, Leonard y Penny.Eventual
El tercer modelo es la consistencia eventual. Esto es lo que admite absolutamente todos los sistemas distribuidos, un modelo mínimo que generalmente tiene sentido. Significa lo siguiente: cuando tenemos algunos cambios en los datos, se vuelven consistentes en algún momento.En ese momento, ella no dice nada, de lo contrario se convertiría en Consistencia Externa: habría una historia completamente diferente. Sin embargo, este es un modelo muy popular, el más común. Por defecto, todos los usuarios de sistemas distribuidos usan Consistencia Eventual.Quiero dar algunos ejemplos comparativos: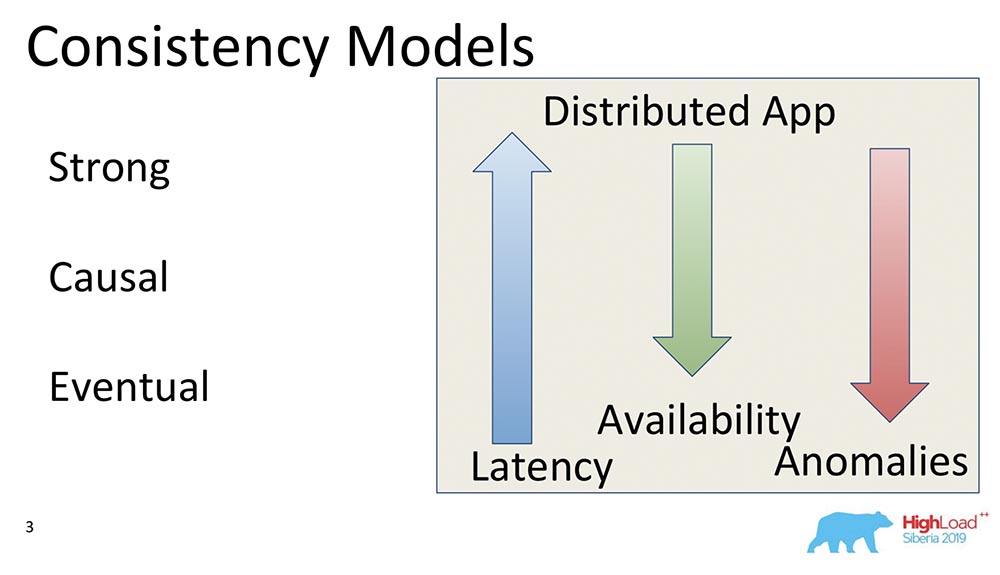 ¿Qué significan estas flechas?
¿Qué significan estas flechas?- Latency. : , , , . Eventual Consistency , , , memory .
- Availability. , partitions, - – , , - . Eventual Consistency – , .
- Anomalies. , , . Strong Consistency , Eventual Consistency . : Eventual Consistency, ? , Eventual Consistency- , , , ; - ; . , .
CAP
Cuando vea las palabras consistencia, disponibilidad, ¿qué le viene a la mente? Derecha - teorema de CAP! Ahora quiero disipar el mito ... No soy yo, está Martin Kleppman, quien escribió un artículo maravilloso, un libro maravilloso. El teorema de CAP es un principio formulado en la década de 2000 que consiste en Consistencia, Disponibilidad, Particiones: tome dos, y no puede elegir tres. Era un cierto principio. Gilbert y Lynch probaron como teorema unos años más tarde. Luego se utilizó como mantra: los sistemas comenzaron a dividirse en CA, CP, AP, etc.Este teorema se probó en realidad por las siguientes razones ... Primero, la disponibilidad se consideró no como un valor continuo de cero a cientos (0 - el sistema está "muerto", 100 - responde rápidamente; estamos acostumbrados a considerarlo), sino como una propiedad del algoritmo , lo que garantiza que con todas sus ejecuciones devuelva datos.¡No hay una palabra sobre el tiempo de respuesta! Hay un algoritmo que devuelve datos después de 100 años, un algoritmo perfectamente disponible, que forma parte del teorema CAP.Segundo: se probó un teorema para los cambios en los valores de la misma clave, a pesar de que estos cambios son una línea redimensionable. Esto significa que, de hecho, prácticamente no se usan, porque los modelos son diferentes Consistencia eventual, Consistencia fuerte (tal vez).¿Por qué es todo esto? Además, el teorema de CAP en la forma en que se demuestra que prácticamente no es aplicable rara vez se usa. En una forma teórica, de alguna manera limita todo. Resulta un cierto principio que es intuitivamente cierto, pero de ninguna manera, en general, está probado.
El teorema de CAP es un principio formulado en la década de 2000 que consiste en Consistencia, Disponibilidad, Particiones: tome dos, y no puede elegir tres. Era un cierto principio. Gilbert y Lynch probaron como teorema unos años más tarde. Luego se utilizó como mantra: los sistemas comenzaron a dividirse en CA, CP, AP, etc.Este teorema se probó en realidad por las siguientes razones ... Primero, la disponibilidad se consideró no como un valor continuo de cero a cientos (0 - el sistema está "muerto", 100 - responde rápidamente; estamos acostumbrados a considerarlo), sino como una propiedad del algoritmo , lo que garantiza que con todas sus ejecuciones devuelva datos.¡No hay una palabra sobre el tiempo de respuesta! Hay un algoritmo que devuelve datos después de 100 años, un algoritmo perfectamente disponible, que forma parte del teorema CAP.Segundo: se probó un teorema para los cambios en los valores de la misma clave, a pesar de que estos cambios son una línea redimensionable. Esto significa que, de hecho, prácticamente no se usan, porque los modelos son diferentes Consistencia eventual, Consistencia fuerte (tal vez).¿Por qué es todo esto? Además, el teorema de CAP en la forma en que se demuestra que prácticamente no es aplicable rara vez se usa. En una forma teórica, de alguna manera limita todo. Resulta un cierto principio que es intuitivamente cierto, pero de ninguna manera, en general, está probado.Consistencia causal: el modelo más fuerte
Lo que está sucediendo ahora: puede obtener las tres cosas: Consistencia, Disponibilidad se puede obtener usando Particiones. En particular, la consistencia causal es el modelo de consistencia más fuerte, que, en presencia de particiones (interrupciones de red), todavía funciona. Por lo tanto, es de gran interés y, por lo tanto, estamos comprometidos en ello. Primero, simplifica el trabajo de los desarrolladores de aplicaciones. En particular, existe una gran cantidad de soporte del servidor: cuando se garantiza que todos los registros que se producen dentro de un cliente llegarán en este orden al otro cliente. En segundo lugar, soporta particiones.
Primero, simplifica el trabajo de los desarrolladores de aplicaciones. En particular, existe una gran cantidad de soporte del servidor: cuando se garantiza que todos los registros que se producen dentro de un cliente llegarán en este orden al otro cliente. En segundo lugar, soporta particiones.Cocina interior MongoDB
Recordando ese almuerzo, nos trasladamos a la cocina. Hablaré sobre el modelo del sistema, es decir, qué es MongoDB para aquellos que escuchan por primera vez sobre dicha base de datos.
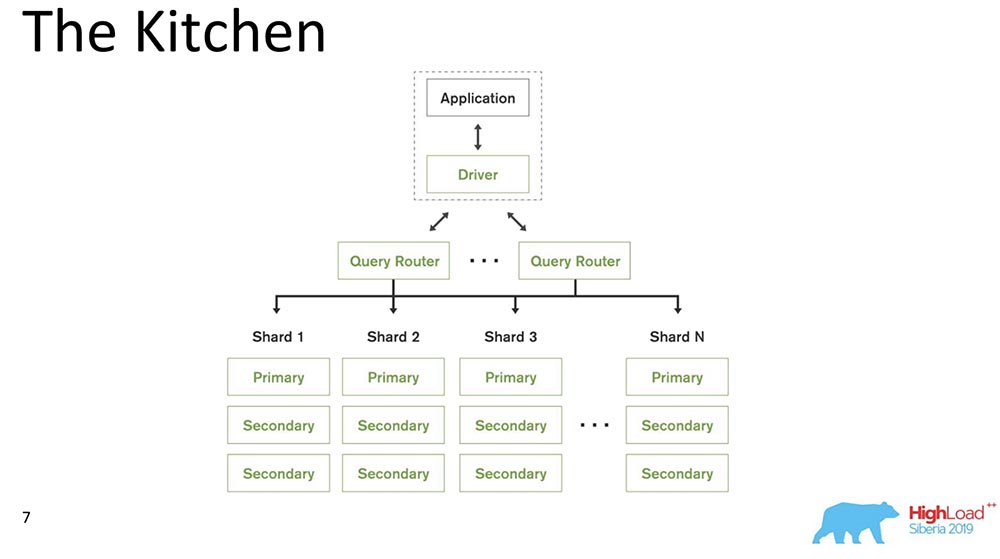 MongoDB (en lo sucesivo, "MongoBD") es un sistema distribuido que admite escala horizontal, es decir, fragmentación; y dentro de cada fragmento, también admite redundancia de datos, es decir, replicación.El fragmentación en "MongoBD" (base de datos no relacional) realiza un equilibrio automático, es decir, cada colección de documentos (o "tabla" en términos de datos relacionales) en pedazos, y el servidor ya los mueve automáticamente entre fragmentos.El Enrutador de consultas que distribuye consultas para el cliente es un cliente a través del cual funciona. Él ya sabe dónde y qué datos se encuentran, envía todas las solicitudes al fragmento correcto.Otro punto importante: MongoDB es un maestro único. Hay un primario: puede tomar registros que admitan las claves que contiene. No puede hacer escritura multimaestro.Hicimos la versión 4.2: allí aparecieron nuevas cosas interesantes. En particular, insertaron Lucene, la búsqueda, era ejecutable java directamente en "Mongo", y allí fue posible buscar a través de Lucene, lo mismo que en "Elastic".E hicieron un nuevo producto: Gráficos, también está disponible en Atlas (la propia nube de Mongo). Tienen nivel gratuito, puedes jugar con esto. Realmente me gustaron los gráficos: la visualización de datos es muy intuitiva.
MongoDB (en lo sucesivo, "MongoBD") es un sistema distribuido que admite escala horizontal, es decir, fragmentación; y dentro de cada fragmento, también admite redundancia de datos, es decir, replicación.El fragmentación en "MongoBD" (base de datos no relacional) realiza un equilibrio automático, es decir, cada colección de documentos (o "tabla" en términos de datos relacionales) en pedazos, y el servidor ya los mueve automáticamente entre fragmentos.El Enrutador de consultas que distribuye consultas para el cliente es un cliente a través del cual funciona. Él ya sabe dónde y qué datos se encuentran, envía todas las solicitudes al fragmento correcto.Otro punto importante: MongoDB es un maestro único. Hay un primario: puede tomar registros que admitan las claves que contiene. No puede hacer escritura multimaestro.Hicimos la versión 4.2: allí aparecieron nuevas cosas interesantes. En particular, insertaron Lucene, la búsqueda, era ejecutable java directamente en "Mongo", y allí fue posible buscar a través de Lucene, lo mismo que en "Elastic".E hicieron un nuevo producto: Gráficos, también está disponible en Atlas (la propia nube de Mongo). Tienen nivel gratuito, puedes jugar con esto. Realmente me gustaron los gráficos: la visualización de datos es muy intuitiva.Ingredientes de consistencia causal
Conté unos 230 artículos publicados sobre este tema, de Leslie Lampert. Ahora de mi memoria les traeré algunas partes de estos materiales. Todo comenzó con un artículo de Leslie Lampert, que fue escrito en la década de 1970. Como puede ver, algunas investigaciones sobre este tema aún están en curso. Ahora la coherencia causal está experimentando interés en relación con el desarrollo de sistemas distribuidos.
Todo comenzó con un artículo de Leslie Lampert, que fue escrito en la década de 1970. Como puede ver, algunas investigaciones sobre este tema aún están en curso. Ahora la coherencia causal está experimentando interés en relación con el desarrollo de sistemas distribuidos.Limitaciones
¿Cuáles son las limitaciones? Este es en realidad uno de los puntos principales, porque las restricciones que imponen los sistemas de producción son muy diferentes de las restricciones que existen en los artículos académicos. A menudo son bastante artificiales.
- En primer lugar, "MongoDB" es un maestro único, como ya he dicho (esto se simplifica enormemente).
- , 10 . - , .
- , , , binary, , .
- , Research : . «» – . , , – . , .
- , – : , performance degradation .
- Otro punto es generalmente anti-académico: compatibilidad de versiones anteriores y futuras. Los controladores antiguos deben admitir nuevas actualizaciones y la base de datos debe admitir controladores antiguos.
En general, todo esto impone limitaciones.Componentes de consistencia causal
Ahora hablaré sobre algunos de los componentes. Si consideramos la consistencia causal general, podemos distinguir los bloques. Elegimos entre los trabajos que pertenecen a un determinado bloque: seguimiento de dependencias, la elección de las horas, cómo se pueden sincronizar estos relojes entre sí y cómo garantizamos la seguridad: este es un plan aproximado de lo que hablaré:
Seguimiento de dependencia completa
¿Por qué es necesario? Para que cuando los datos se repliquen, cada registro, cada cambio de datos contiene información sobre los cambios de los que depende. El primer cambio ingenuo es cuando cada mensaje que contiene un registro contiene información sobre mensajes anteriores: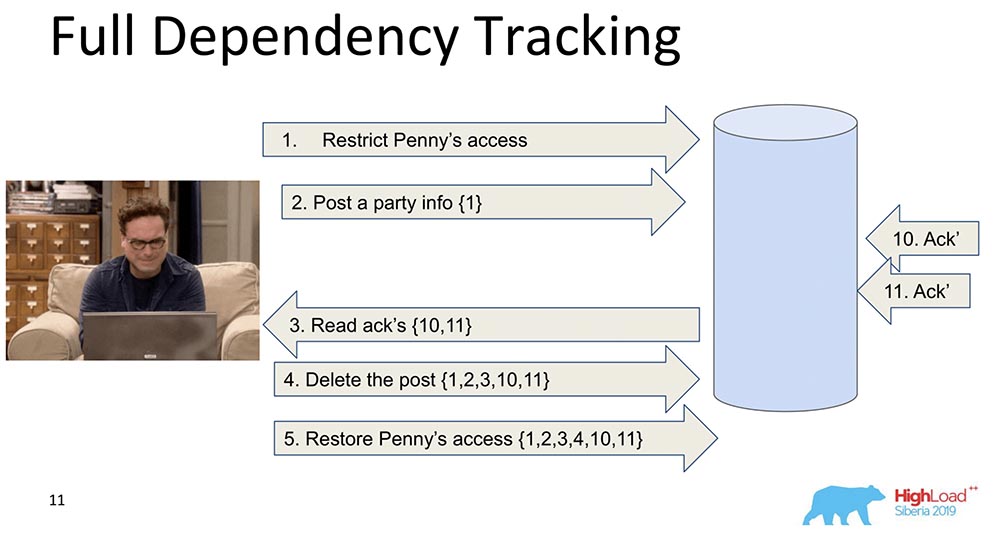 en este ejemplo, el número entre llaves es el número de registros. A veces, estos registros con valores incluso se transfieren en su totalidad, a veces se transfieren algunas versiones. La conclusión es que cada cambio contiene información sobre el anterior (obviamente lleva todo en sí mismo).¿Por qué decidimos no utilizar este enfoque (seguimiento completo)? Obviamente, porque este enfoque no es práctico: cualquier cambio en la red social depende de todos los cambios anteriores en esta red social, transmitiendo, por ejemplo, Facebook o Vkontakte en cada actualización. Sin embargo, hay mucha investigación, a saber, el seguimiento de la dependencia completa: se trata de redes sociales, para algunas situaciones realmente funciona.
en este ejemplo, el número entre llaves es el número de registros. A veces, estos registros con valores incluso se transfieren en su totalidad, a veces se transfieren algunas versiones. La conclusión es que cada cambio contiene información sobre el anterior (obviamente lleva todo en sí mismo).¿Por qué decidimos no utilizar este enfoque (seguimiento completo)? Obviamente, porque este enfoque no es práctico: cualquier cambio en la red social depende de todos los cambios anteriores en esta red social, transmitiendo, por ejemplo, Facebook o Vkontakte en cada actualización. Sin embargo, hay mucha investigación, a saber, el seguimiento de la dependencia completa: se trata de redes sociales, para algunas situaciones realmente funciona.Seguimiento explícito de dependencias
El siguiente es más limitado. Aquí también se considera la transmisión de información, pero solo la que claramente depende. Lo que depende de lo que, como regla, ya está determinado por la aplicación. Cuando los datos se replican, solo se devuelven las respuestas cuando se realiza una solicitud, cuando se satisfacen las dependencias anteriores, es decir, se muestran. Esta es la esencia de cómo funciona la consistencia causal.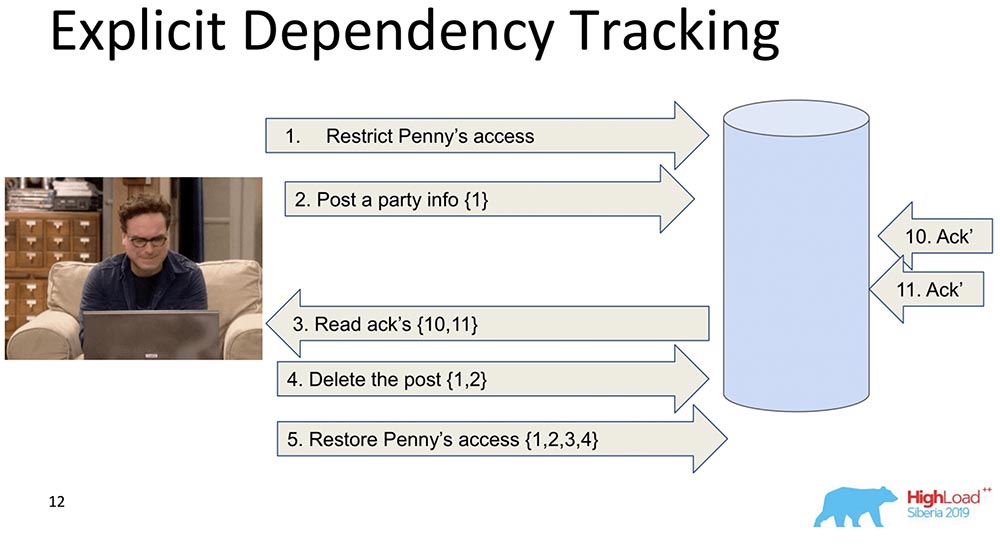 Ella ve que el registro 5 depende de los registros 1, 2, 3, 4, respectivamente, espera antes de que el cliente tenga acceso a los cambios realizados por el decreto de acceso de Penny cuando todos los cambios anteriores ya han pasado a la base de datos.Esto tampoco nos conviene, porque de todos modos hay demasiada información, y esto se ralentizará. Hay un enfoque diferente ...
Ella ve que el registro 5 depende de los registros 1, 2, 3, 4, respectivamente, espera antes de que el cliente tenga acceso a los cambios realizados por el decreto de acceso de Penny cuando todos los cambios anteriores ya han pasado a la base de datos.Esto tampoco nos conviene, porque de todos modos hay demasiada información, y esto se ralentizará. Hay un enfoque diferente ...Reloj Lamport
Son muy viejos. Lamport Clock implica que estas dependencias se colapsan en una función escalar llamada Lamport Clock.Una función escalar es un número abstracto. A menudo llamado tiempo lógico. En cada evento, este contador aumenta. El contador, que el proceso conoce actualmente, envía cada mensaje. Está claro que los procesos pueden estar fuera de sincronización, pueden tener tiempos completamente diferentes. Sin embargo, el sistema de alguna manera equilibra el reloj con tales mensajes. ¿Qué pasa en este caso?Rompí ese gran fragmento en dos, para que quede claro: los amigos pueden vivir en un nodo que contiene una pieza de la colección, y Feed puede vivir en otro nodo que contiene una pieza de esta colección. ¿Está claro cómo pueden salir de turno? Primero, Feed dice: "Replicado", y luego Friends. Si el sistema no proporciona ninguna garantía de que Feed no se mostrará hasta que también se entreguen las dependencias de Friends en la colección Friends, entonces tendremos una situación que mencioné.Usted ve cómo el tiempo de contador lógico aumenta en Feed: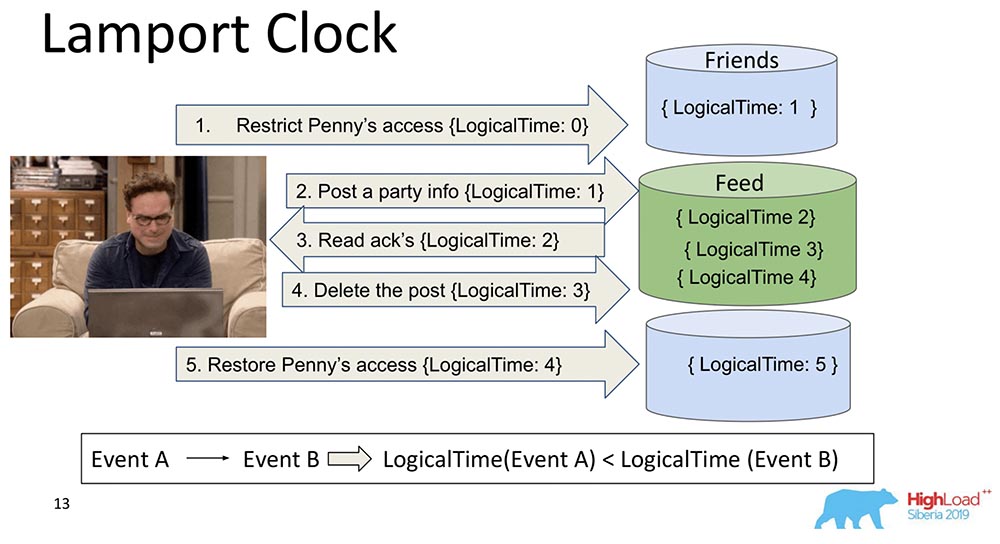 Por lo tanto, la propiedad principal de este Reloj Lamport y la coherencia causal (explicada a través del Reloj Lamport) es la siguiente: si tenemos eventos A y B, y el evento B depende del evento A *, entonces se deduce que el LogicalTime del Evento A es menor que el LogicalTime del Evento B.* A veces incluso dicen que A sucedió antes que B, es decir, A sucedió antes que B: este es un tipo de relación que ordena parcialmente todo el conjunto de eventos que generalmente ocurrieron.Lo contrario está mal. Esta es en realidad una de las principales desventajas de Lamport Clock: el pedido parcial. Existe un concepto de eventos simultáneos, es decir, eventos en los que ni (A sucedió antes que B) ni (A sucedió antes que B). Un ejemplo es la adición paralela de Leonard a amigos de otra persona (ni siquiera Leonard, sino Sheldon, por ejemplo).Esta es la propiedad que a menudo se usa cuando se trabaja con relojes Lamport: miran la función exactamente y sacan una conclusión de esto, tal vez estos eventos son dependientes. Porque en una dirección esto es cierto: si LogicalTime A es menor que LogicalTime B, entonces B no puede suceder antes que A; y si más, entonces tal vez.
Por lo tanto, la propiedad principal de este Reloj Lamport y la coherencia causal (explicada a través del Reloj Lamport) es la siguiente: si tenemos eventos A y B, y el evento B depende del evento A *, entonces se deduce que el LogicalTime del Evento A es menor que el LogicalTime del Evento B.* A veces incluso dicen que A sucedió antes que B, es decir, A sucedió antes que B: este es un tipo de relación que ordena parcialmente todo el conjunto de eventos que generalmente ocurrieron.Lo contrario está mal. Esta es en realidad una de las principales desventajas de Lamport Clock: el pedido parcial. Existe un concepto de eventos simultáneos, es decir, eventos en los que ni (A sucedió antes que B) ni (A sucedió antes que B). Un ejemplo es la adición paralela de Leonard a amigos de otra persona (ni siquiera Leonard, sino Sheldon, por ejemplo).Esta es la propiedad que a menudo se usa cuando se trabaja con relojes Lamport: miran la función exactamente y sacan una conclusión de esto, tal vez estos eventos son dependientes. Porque en una dirección esto es cierto: si LogicalTime A es menor que LogicalTime B, entonces B no puede suceder antes que A; y si más, entonces tal vez.Reloj del vector
El desarrollo lógico de los relojes Lamport es el Vector Clock. Se diferencian en que cada nodo que está aquí contiene su propio reloj separado, y se transmiten como un vector.En este caso, verá que el índice cero del vector es responsable de Feed, y el primer índice del vector es para Friends (cada uno de estos nodos). Y ahora aumentarán: el índice cero del "Feed" aumenta al grabar - 1, 2, 3: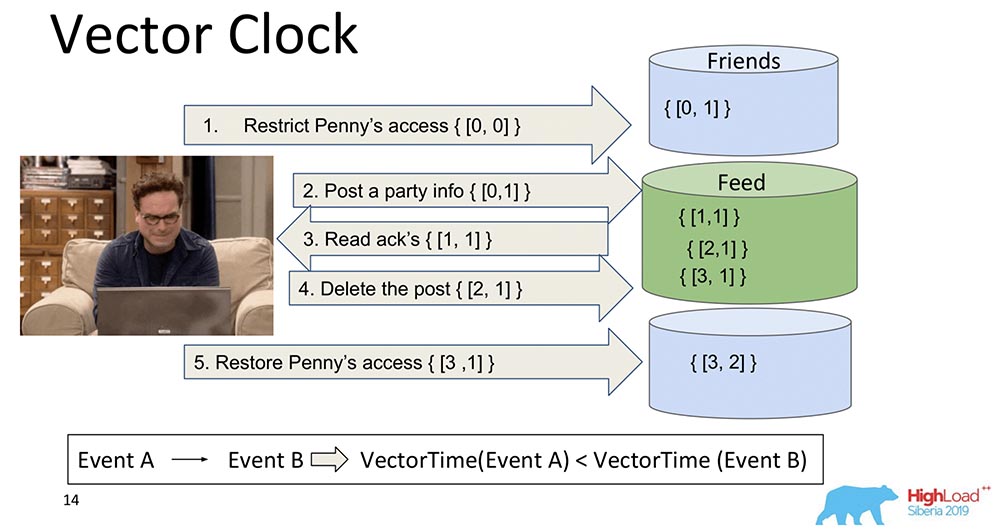 ¿Cómo es mejor el Vector Clock? El hecho de que pueden descubrir qué eventos son simultáneos y cuándo ocurren en diferentes nodos. Esto es muy importante para un sistema de fragmentación como MongoBD. Sin embargo, no elegimos esto, aunque es algo maravilloso, funciona muy bien y probablemente nos convenga ...Si tenemos 10 mil fragmentos, no podemos transferir 10 mil componentes, incluso si comprimimos, pensamos algo más: de todos modos, la carga útil será varias veces menor que el volumen de todo este vector. Por lo tanto, rechinando nuestros corazones y dientes, abandonamos este enfoque y pasamos a otro.
¿Cómo es mejor el Vector Clock? El hecho de que pueden descubrir qué eventos son simultáneos y cuándo ocurren en diferentes nodos. Esto es muy importante para un sistema de fragmentación como MongoBD. Sin embargo, no elegimos esto, aunque es algo maravilloso, funciona muy bien y probablemente nos convenga ...Si tenemos 10 mil fragmentos, no podemos transferir 10 mil componentes, incluso si comprimimos, pensamos algo más: de todos modos, la carga útil será varias veces menor que el volumen de todo este vector. Por lo tanto, rechinando nuestros corazones y dientes, abandonamos este enfoque y pasamos a otro.Llave TrueTime. Reloj atómico
Dije que habrá una historia sobre Spanner. Esto es algo genial, justo en el siglo XXI: relojes atómicos, sincronización GPS.¿Que idea? Spanner es un sistema de Google que recientemente incluso ha estado disponible para las personas (le han adjuntado SQL). Cada transacción tiene una marca de tiempo. Como la hora está sincronizada *, a cada evento se le puede asignar una hora específica: el reloj atómico tiene un tiempo de espera, después del cual se garantiza que ocurrirá otra hora. Por lo tanto, solo escribiendo en la base de datos y esperando un cierto período de tiempo, se garantiza automáticamente la serialización del evento. Tienen el modelo de consistencia más fuerte, que en principio se puede imaginar: es la consistencia externa.* Este es el principal problema de los relojes Lampart: nunca son sincrónicos en los sistemas distribuidos. Pueden divergir, incluso con NTP, todavía no funcionan muy bien. "Spanner" tiene un reloj atómico y la sincronización parece ser de microsegundos.¿Por qué no elegimos? No suponemos que nuestros usuarios tengan un reloj atómico incorporado. Cuando aparezcan, al estar integrados en cada computadora portátil, habrá algún tipo de sincronización GPS súper genial, entonces sí ... Mientras tanto, lo mejor que es posible es Amazon, estaciones base para fanáticos ... Por lo tanto, utilizamos otros relojes.
Por lo tanto, solo escribiendo en la base de datos y esperando un cierto período de tiempo, se garantiza automáticamente la serialización del evento. Tienen el modelo de consistencia más fuerte, que en principio se puede imaginar: es la consistencia externa.* Este es el principal problema de los relojes Lampart: nunca son sincrónicos en los sistemas distribuidos. Pueden divergir, incluso con NTP, todavía no funcionan muy bien. "Spanner" tiene un reloj atómico y la sincronización parece ser de microsegundos.¿Por qué no elegimos? No suponemos que nuestros usuarios tengan un reloj atómico incorporado. Cuando aparezcan, al estar integrados en cada computadora portátil, habrá algún tipo de sincronización GPS súper genial, entonces sí ... Mientras tanto, lo mejor que es posible es Amazon, estaciones base para fanáticos ... Por lo tanto, utilizamos otros relojes.Reloj híbrido
Esto es en realidad lo que marca el "MongoBD" mientras se garantiza la coherencia causal. ¿Qué son híbridos? Un híbrido es un valor escalar, pero consta de dos componentes:
- La primera es la era de Unix (cuántos segundos han pasado desde el "comienzo del mundo de la informática").
- El segundo es un incremento, también un int sin signo de 32 bits.
Eso es todo, en realidad. Existe este enfoque: la parte responsable de la hora está sincronizada con el reloj todo el tiempo; Cada vez que se produce una actualización, esta parte se sincroniza con el reloj y resulta que la hora siempre es más o menos correcta, y el incremento le permite distinguir entre eventos que ocurrieron al mismo tiempo.¿Por qué es esto importante para MongoBD? Debido a que le permite hacer algún tipo de restauradores de respaldo en un momento determinado, es decir, el evento se indexa por tiempo. Esto es importante cuando se necesitan algunos eventos; Para una base de datos, los eventos son cambios en la base de datos que se producen en determinados momentos.¡Solo te diré la razón más importante (por favor, no se lo digas a nadie)! Hicimos esto porque los datos ordenados e indexados en MongoDB OpLog se ven así. OpLog es una estructura de datos que contiene absolutamente todos los cambios en la base de datos: primero van a OpLog, y luego ya se aplican al almacenamiento en el caso de que sea una fecha o fragmento replicado.Esa fue la razón principal. Aún así, también hay requisitos prácticos para desarrollar la base de datos, lo que significa que debe ser simple: hay poco código, la menor cantidad posible de elementos rotos que deben reescribirse y probarse. El hecho de que nuestros registros de operación fueran indexados por un reloj híbrido fue de gran ayuda y nos permitió tomar la decisión correcta. Realmente valió la pena y de alguna manera funcionó mágicamente, en el primer prototipo. ¡Era muy intersante!Sincronización de reloj
Existen varios métodos de sincronización descritos en la literatura científica. Estoy hablando de sincronización cuando tenemos dos fragmentos diferentes. Si hay un conjunto de réplicas, no hay necesidad de sincronización allí: es un "maestro único"; tenemos un OpLog en el que entran todos los cambios; en este caso, todo ya está ordenado secuencialmente en el "Oplog" mismo. Pero si tenemos dos fragmentos diferentes, la sincronización de tiempo es importante aquí. ¡Aquí los relojes vectoriales ayudaron más! Pero no los tenemos. El segundo es Heartbeats. Puede intercambiar algunas señales que ocurren cada unidad de tiempo. Pero los Hartbits son demasiado lentos, no podemos proporcionar latencia a nuestro cliente.El tiempo verdadero es, por supuesto, algo maravilloso. Pero, nuevamente, este es probablemente el futuro ... Aunque el Atlas ya se puede hacer, ya hay sincronizadores de tiempo "amazónicos" rápidos. Pero no estará disponible para todos.Cotillear es cuando todos los mensajes incluyen tiempo. Esto es más o menos lo que usamos. Cada mensaje entre nodos, un controlador, un enrutador de nodos de datos, absolutamente todo para "MongoDB": estos son algunos elementos, componentes de la base de datos que contienen un reloj que fluye. En todas partes tienen el significado del tiempo híbrido, se transmite. 64 bits? Permite, es posible.
El segundo es Heartbeats. Puede intercambiar algunas señales que ocurren cada unidad de tiempo. Pero los Hartbits son demasiado lentos, no podemos proporcionar latencia a nuestro cliente.El tiempo verdadero es, por supuesto, algo maravilloso. Pero, nuevamente, este es probablemente el futuro ... Aunque el Atlas ya se puede hacer, ya hay sincronizadores de tiempo "amazónicos" rápidos. Pero no estará disponible para todos.Cotillear es cuando todos los mensajes incluyen tiempo. Esto es más o menos lo que usamos. Cada mensaje entre nodos, un controlador, un enrutador de nodos de datos, absolutamente todo para "MongoDB": estos son algunos elementos, componentes de la base de datos que contienen un reloj que fluye. En todas partes tienen el significado del tiempo híbrido, se transmite. 64 bits? Permite, es posible.¿Cómo funciona todo junto?
Aquí miro un conjunto de réplicas para hacerlo un poco más fácil. Hay primaria y secundaria. Secundario realiza la replicación y no siempre está completamente sincronizado con Primario.Hay una inserción (inserción) en las "Primarias" con un cierto valor de tiempo. Este inserto aumenta el contador interno en 11, si es máximo. O verificará los valores del reloj y se sincronizará por el reloj si el reloj es más grande. Esto le permite ordenar por tiempo.Después de que él hace un registro, ocurre un momento importante. Las horas están en "MongoDB" y se incrementan solo si se registran en el "Oplog". Este es un evento que cambia el estado del sistema. Absolutamente en todos los artículos clásicos, un evento se considera un mensaje que ingresa a un nodo: ha llegado un mensaje, lo que significa que el sistema ha cambiado su estado.Esto se debe al hecho de que durante el estudio no es del todo posible entender cómo se interpretará este mensaje. Sabemos con certeza que si no se refleja en el "Oplog", no se interpretará de ninguna manera, y solo la entrada en el "Oplog" es un cambio en el estado del sistema. Esto nos simplifica todo: el modelo simplifica y nos permite organizarnos en el marco de un conjunto de réplicas y muchas otras cosas útiles.Devuelve el valor que ya se ha registrado en el "Oplog". Sabemos que en el "Oplog" este valor yace, y su tiempo es 12. Ahora, digamos, la lectura comienza desde otro nodo (Secundario), y se transfiere ya después de ClusterTime. mensaje. Él dice: "Necesito todo lo que sucedió después de al menos 12 o durante doce" (ver fig. Arriba).Esto es lo que se llama Causal a consistente (CAT). Existe un concepto tal en teoría que es una porción de tiempo, que es consistente en sí mismo. En este caso, podemos decir que este es el estado del sistema que se observó en el momento 12.Ahora no hay nada aquí, porque parece simular una situación en la que Secundario necesita replicar datos de Primario. Está esperando ... Y ahora han llegado los datos, devuelve estos valores.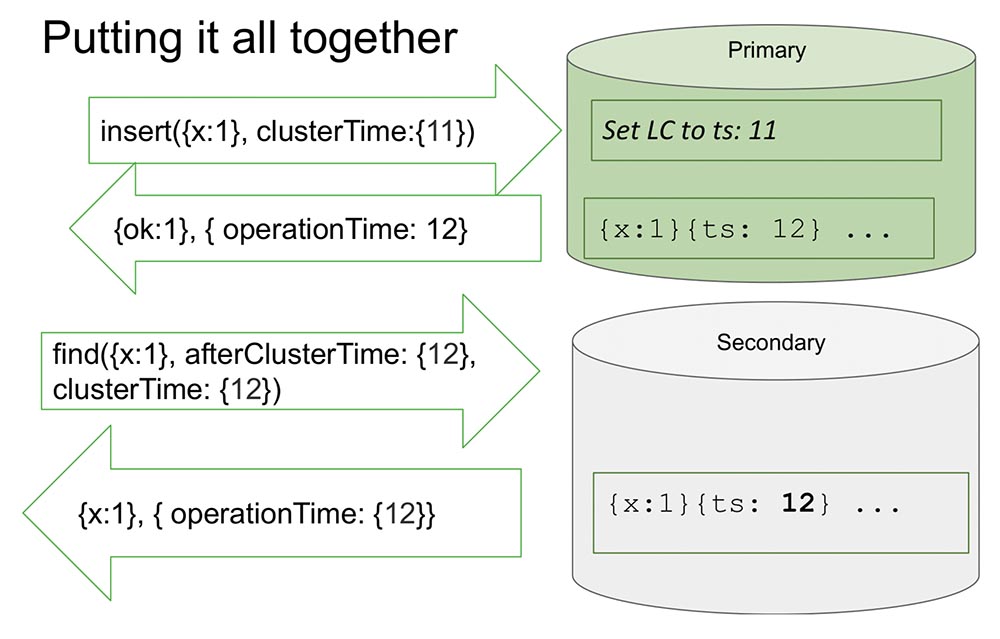 Así es como funciona todo. Casi.¿Qué significa "casi"? Supongamos que hay alguna persona que ha leído y entendido cómo funciona todo esto. Me di cuenta de que cada vez que se produce ClusterTime, actualiza el reloj lógico interno, y luego el siguiente registro aumenta en uno. Esta función ocupa 20 líneas. Supongamos que esta persona transmite el mayor número posible de 64 bits, menos uno.¿Por qué es menos uno? Debido a que el reloj interno se sustituye en este valor (obviamente, este es el más grande posible y más que la hora actual), entonces habrá una entrada en el "Olog", y el reloj se incrementará en uno más, y ya habrá un valor máximo (simplemente hay todas las unidades, no hay a dónde ir , ints sin signo).Está claro que después de esto, el sistema se vuelve completamente inaccesible por nada. Solo se puede descargar, limpiar, mucho trabajo manual. Disponibilidad total:
Así es como funciona todo. Casi.¿Qué significa "casi"? Supongamos que hay alguna persona que ha leído y entendido cómo funciona todo esto. Me di cuenta de que cada vez que se produce ClusterTime, actualiza el reloj lógico interno, y luego el siguiente registro aumenta en uno. Esta función ocupa 20 líneas. Supongamos que esta persona transmite el mayor número posible de 64 bits, menos uno.¿Por qué es menos uno? Debido a que el reloj interno se sustituye en este valor (obviamente, este es el más grande posible y más que la hora actual), entonces habrá una entrada en el "Olog", y el reloj se incrementará en uno más, y ya habrá un valor máximo (simplemente hay todas las unidades, no hay a dónde ir , ints sin signo).Está claro que después de esto, el sistema se vuelve completamente inaccesible por nada. Solo se puede descargar, limpiar, mucho trabajo manual. Disponibilidad total: Además, si esto se replica en otro lugar, entonces todo el clúster simplemente se acuesta. ¡Una situación absolutamente inaceptable que cualquiera puede organizar de forma rápida y sencilla! Por lo tanto, consideramos este momento como uno de los más importantes. ¿Cómo prevenirlo?
Además, si esto se replica en otro lugar, entonces todo el clúster simplemente se acuesta. ¡Una situación absolutamente inaceptable que cualquiera puede organizar de forma rápida y sencilla! Por lo tanto, consideramos este momento como uno de los más importantes. ¿Cómo prevenirlo?Nuestra forma es firmar clusterTime
Por lo tanto, se transmite en el mensaje (antes del texto azul). Pero también comenzamos a generar una firma (texto azul): la firma se genera mediante una clave que se almacena dentro de la base de datos, dentro del perímetro protegido; se genera, actualiza (los usuarios no ven nada). Se genera hash y cada mensaje se firma durante la creación y se valida al recibirlo.Probablemente, la pregunta surge en las personas: "¿Cuánto se ralentiza?" Dije que debería funcionar rápidamente, especialmente en ausencia de esta función.¿Qué significa usar consistencia causal en este caso? Esto mostrará el parámetro afterClusterTime. Y sin él, simplemente pasará valores de todos modos. Los chismes, desde la versión 3.6, siempre funcionan.Si dejamos la generación constante de firmas, esto ralentizará el sistema incluso en ausencia de características, lo que no cumple con nuestros enfoques y requisitos. ¿Y que hemos hecho?
firma se genera mediante una clave que se almacena dentro de la base de datos, dentro del perímetro protegido; se genera, actualiza (los usuarios no ven nada). Se genera hash y cada mensaje se firma durante la creación y se valida al recibirlo.Probablemente, la pregunta surge en las personas: "¿Cuánto se ralentiza?" Dije que debería funcionar rápidamente, especialmente en ausencia de esta función.¿Qué significa usar consistencia causal en este caso? Esto mostrará el parámetro afterClusterTime. Y sin él, simplemente pasará valores de todos modos. Los chismes, desde la versión 3.6, siempre funcionan.Si dejamos la generación constante de firmas, esto ralentizará el sistema incluso en ausencia de características, lo que no cumple con nuestros enfoques y requisitos. ¿Y que hemos hecho?¡Hazlo rápido!
Una cosa bastante simple, pero el truco es interesante: lo compartiré, tal vez alguien esté interesado.Tenemos un hash que almacena datos firmados. Todos los datos pasan por el caché. El caché no firma específicamente la hora, sino el Rango. Cuando llega un cierto valor, generamos un Rango, enmascaramos los últimos 16 bits y firmamos este valor: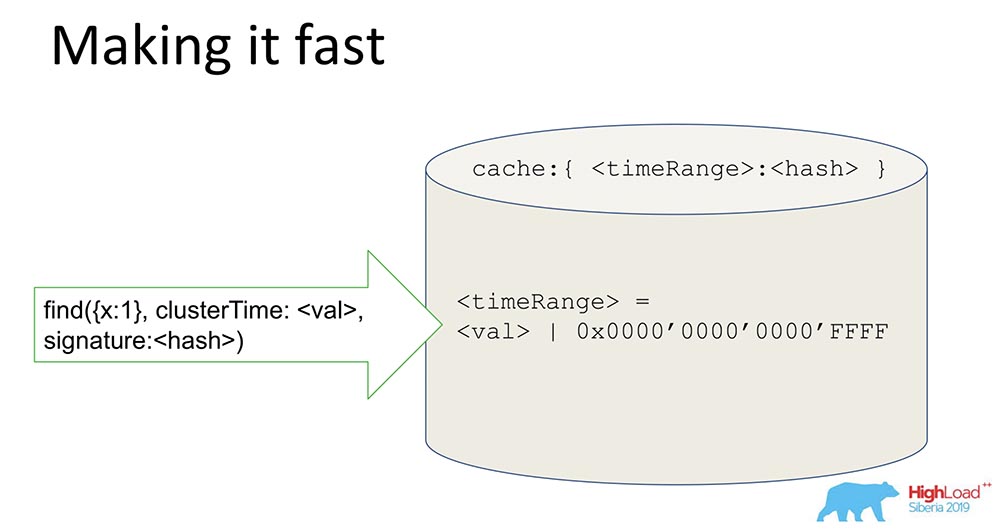 Al recibir dicha firma, aceleramos el sistema (condicionalmente) 65 mil veces. Funciona muy bien: cuando hicieron los experimentos, el tiempo en que tuvimos una actualización constante se redujo realmente en 10 mil veces. Está claro que cuando están en desacuerdo, esto no funciona. Pero en la mayoría de los casos prácticos esto funciona. La combinación de la firma Range con la firma resolvió el problema de seguridad.
Al recibir dicha firma, aceleramos el sistema (condicionalmente) 65 mil veces. Funciona muy bien: cuando hicieron los experimentos, el tiempo en que tuvimos una actualización constante se redujo realmente en 10 mil veces. Está claro que cuando están en desacuerdo, esto no funciona. Pero en la mayoría de los casos prácticos esto funciona. La combinación de la firma Range con la firma resolvió el problema de seguridad.Que hemos aprendido
Lecciones que aprendimos de esto:- , , , . - ( , . .), , . , , , . – .
, , («», ) – . ? . , . – , . - . , «» , , , availability, latency .
- La última es que tuvimos que considerar diferentes ideas y combinar varios artículos generalmente diferentes en un solo enfoque, juntos. La idea de firmar, por ejemplo, surgió de un artículo que examinó el protocolo de Paxos, que para los no bizantinos Faylor dentro del protocolo de autorización, para los bizantinos fuera del protocolo de autorización ... En general, esto es exactamente lo que hicimos al final.
¡No hay absolutamente nada nuevo aquí! Pero tan pronto como lo mezclamos todo ... Es como decir que la receta de la ensalada Olivier no tiene sentido, porque los huevos, la mayonesa y los pepinos ya han surgido ... Es casi la misma historia.
 En esto terminaré. ¡Gracias!
En esto terminaré. ¡Gracias!Preguntas
Pregunta de la audiencia (en adelante - B): - ¡Gracias, Michael, por el informe! El tema del tiempo es interesante. Estás usando chismes. Dijeron que todos tienen su propio tiempo, todos conocen su hora local. Según tengo entendido, tenemos un controlador: puede haber muchos clientes con controladores, planificadores de consultas también, muchos fragmentos ... Pero, ¿qué hará el sistema si de repente tenemos una discrepancia? Alguien decide que es así por un minuto. adelante, alguien, ¿un minuto atrás? ¿Dónde nos encontraremos?MT: - ¡Gran pregunta realmente! Solo quería decir sobre fragmentos. Si entiendo la pregunta correctamente, tenemos esta situación: hay un fragmento 1 y un fragmento 2, la lectura se produce a partir de estos dos fragmentos: tienen una discrepancia, no interactúan entre sí, porque el tiempo que conocen es diferente, especialmente el tiempo que Existen en oplogs.Supongamos que el fragmento 1 hizo un millón de registros, el fragmento 2 no hizo nada y la solicitud llegó en dos fragmentos. Y el primero tiene AfterClusterTime más de un millón. En tal situación, como expliqué, el fragmento 2 nunca responderá en absoluto.P: - ¿Quería saber cómo se sincronizan y elegir una hora lógica?MT: - Muy fácil de sincronizar. Fragmento, cuando afterClusterTime viene a él, y no encuentra el tiempo en el "Catch", no inicia ninguna aprobación. Es decir, él levanta sus manos a este valor con sus manos. Esto significa que no tiene eventos que coincidan con esta consulta. Él crea este evento artificialmente y, por lo tanto, se convierte en el Causal consistente.P: - ¿Y si después de eso, otros eventos que se perdieron en algún lugar de la red aún le llegan?MONTE:- El fragmento está tan arreglado que ya no vendrán, ya que es un solo maestro. Si él ya ha grabado, entonces no vendrán, sino que vendrán después. No puede suceder que en algún lugar algo esté atascado, entonces él no escribirá, y luego llegaron estos eventos, y se violó la coherencia causal. Cuando no escribe, todos tienen que venir después (los esperará). A:- Tengo algunas preguntas sobre las líneas. La coherencia causal supone que hay una determinada cola de acciones que deben realizarse. ¿Qué pasa si perdemos un paquete? Así que el 10 fue, el 11 ... el 12 desapareció, y todos los demás esperan que se cumpla. Y de repente nuestro auto murió, no podemos hacer nada. ¿Hay una longitud máxima de cola que se acumula antes de ejecutarse? ¿Qué falla fatal ocurre cuando se pierde cualquier estado? Además, si escribimos que hay algún tipo de estado anterior, ¿deberíamos comenzar de alguna manera? ¡Y no se apartaron de él!MONTE:- ¡También una pregunta maravillosa! ¿Que estamos haciendo? MongoDB tiene el concepto de registros de quórum, lecturas de quórum. ¿Cuándo puede desaparecer un mensaje? Cuando el registro no es quórum o cuando la lectura no es quórum (también se puede pegar algo de basura).Con respecto a la consistencia causal, realizamos una gran prueba experimental, que resultó en el hecho de que cuando la grabación y la lectura no son quórum, ocurren violaciones de consistencia causal. ¡Exactamente lo que dices!Nuestro consejo: use al menos la lectura de quórum cuando use la consistencia causal. En este caso, no se perderá nada, incluso si se pierde el registro de quórum ... Esta es una situación ortogonal: si el usuario no desea que se pierdan los datos, debe usar el registro de quórum. La consistencia causal no garantiza la durabilidad. La garantía de durabilidad es proporcionada por la replicación y la maquinaria asociada con la replicación.P: - Cuando creamos una instancia que el fragmentación hace por nosotros (no maestro, sino esclavo, respectivamente), se basa en el tiempo de Unix de su propia máquina o en el tiempo del "maestro"; sincronizado por primera vez o periódicamente?MONTE:- Ahora lo dejaré claro. Fragmento (es decir, partición horizontal): siempre hay Primario. Y en un fragmento puede haber un "maestro" y puede haber réplicas. Pero el fragmento siempre admite la escritura, ya que debe admitir un determinado dominio (Primario está en el fragmento).P: - Es decir, ¿todo depende únicamente del "maestro"? Utilice siempre el tiempo "maestro"?MT: Sí. Se puede decir en sentido figurado: el reloj está marcando cuando hay una grabación en el "maestro", en el "Oplog".P: ¿Tenemos un cliente que se conecta y no necesita saber nada sobre el tiempo?MONTE:- En general, ¡no necesitas saber nada! Si hablamos sobre cómo funciona en el cliente: en el cliente, cuando quiere usar la coherencia causal, necesita abrir una sesión. Ahora todo está ahí: tanto las transacciones en la sesión como la recuperación de derechos ... Una sesión es un orden de eventos lógicos que ocurren con un cliente.Si abre esta sesión y dice que quiere coherencia causal (si por defecto la sesión admite coherencia causal), todo funciona automáticamente. El conductor recuerda este momento y lo aumenta cuando recibe un nuevo mensaje. Recuerda qué respuesta devolvió la anterior del servidor que devolvió los datos. La siguiente solicitud contendrá afterCluster ("el tiempo es mayor que esto").¡El cliente no necesita saber absolutamente nada! Esto es absolutamente opaco para él. Si las personas usan estas funciones, ¿qué puedo hacer? Primero, puede leer de forma segura las secundarias: puede escribir en Primaria y leer desde secundarias replicadas geográficamente y asegurarse de que funciona. Al mismo tiempo, las sesiones que se grabaron en Primaria se pueden transferir incluso a Secundaria, es decir, puede usar no una sesión, sino varias.P: - El tema de la coherencia eventual está fuertemente relacionado con la nueva capa de informática Compute: tipos de datos CRDT (tipos de datos replicados sin conflictos). ¿Ha considerado la integración de este tipo de datos en la base de datos y qué puede decir al respecto?MT: - Buena pregunta! CRDT tiene sentido para conflictos de escritura: en MongoDB - maestro único.A:- Tengo una pregunta de los devops. En el mundo real, hay situaciones jesuitas en las que ocurre la falla bizantina, y las personas malvadas dentro del perímetro protegido comienzan a adherirse al protocolo y envían paquetes de manualidades de una manera especial.
A:- Tengo algunas preguntas sobre las líneas. La coherencia causal supone que hay una determinada cola de acciones que deben realizarse. ¿Qué pasa si perdemos un paquete? Así que el 10 fue, el 11 ... el 12 desapareció, y todos los demás esperan que se cumpla. Y de repente nuestro auto murió, no podemos hacer nada. ¿Hay una longitud máxima de cola que se acumula antes de ejecutarse? ¿Qué falla fatal ocurre cuando se pierde cualquier estado? Además, si escribimos que hay algún tipo de estado anterior, ¿deberíamos comenzar de alguna manera? ¡Y no se apartaron de él!MONTE:- ¡También una pregunta maravillosa! ¿Que estamos haciendo? MongoDB tiene el concepto de registros de quórum, lecturas de quórum. ¿Cuándo puede desaparecer un mensaje? Cuando el registro no es quórum o cuando la lectura no es quórum (también se puede pegar algo de basura).Con respecto a la consistencia causal, realizamos una gran prueba experimental, que resultó en el hecho de que cuando la grabación y la lectura no son quórum, ocurren violaciones de consistencia causal. ¡Exactamente lo que dices!Nuestro consejo: use al menos la lectura de quórum cuando use la consistencia causal. En este caso, no se perderá nada, incluso si se pierde el registro de quórum ... Esta es una situación ortogonal: si el usuario no desea que se pierdan los datos, debe usar el registro de quórum. La consistencia causal no garantiza la durabilidad. La garantía de durabilidad es proporcionada por la replicación y la maquinaria asociada con la replicación.P: - Cuando creamos una instancia que el fragmentación hace por nosotros (no maestro, sino esclavo, respectivamente), se basa en el tiempo de Unix de su propia máquina o en el tiempo del "maestro"; sincronizado por primera vez o periódicamente?MONTE:- Ahora lo dejaré claro. Fragmento (es decir, partición horizontal): siempre hay Primario. Y en un fragmento puede haber un "maestro" y puede haber réplicas. Pero el fragmento siempre admite la escritura, ya que debe admitir un determinado dominio (Primario está en el fragmento).P: - Es decir, ¿todo depende únicamente del "maestro"? Utilice siempre el tiempo "maestro"?MT: Sí. Se puede decir en sentido figurado: el reloj está marcando cuando hay una grabación en el "maestro", en el "Oplog".P: ¿Tenemos un cliente que se conecta y no necesita saber nada sobre el tiempo?MONTE:- En general, ¡no necesitas saber nada! Si hablamos sobre cómo funciona en el cliente: en el cliente, cuando quiere usar la coherencia causal, necesita abrir una sesión. Ahora todo está ahí: tanto las transacciones en la sesión como la recuperación de derechos ... Una sesión es un orden de eventos lógicos que ocurren con un cliente.Si abre esta sesión y dice que quiere coherencia causal (si por defecto la sesión admite coherencia causal), todo funciona automáticamente. El conductor recuerda este momento y lo aumenta cuando recibe un nuevo mensaje. Recuerda qué respuesta devolvió la anterior del servidor que devolvió los datos. La siguiente solicitud contendrá afterCluster ("el tiempo es mayor que esto").¡El cliente no necesita saber absolutamente nada! Esto es absolutamente opaco para él. Si las personas usan estas funciones, ¿qué puedo hacer? Primero, puede leer de forma segura las secundarias: puede escribir en Primaria y leer desde secundarias replicadas geográficamente y asegurarse de que funciona. Al mismo tiempo, las sesiones que se grabaron en Primaria se pueden transferir incluso a Secundaria, es decir, puede usar no una sesión, sino varias.P: - El tema de la coherencia eventual está fuertemente relacionado con la nueva capa de informática Compute: tipos de datos CRDT (tipos de datos replicados sin conflictos). ¿Ha considerado la integración de este tipo de datos en la base de datos y qué puede decir al respecto?MT: - Buena pregunta! CRDT tiene sentido para conflictos de escritura: en MongoDB - maestro único.A:- Tengo una pregunta de los devops. En el mundo real, hay situaciones jesuitas en las que ocurre la falla bizantina, y las personas malvadas dentro del perímetro protegido comienzan a adherirse al protocolo y envían paquetes de manualidades de una manera especial. MT: - ¡Las personas malvadas dentro del perímetro son como un caballo de Troya! Las personas malvadas dentro del perímetro pueden hacer muchas cosas malas.P: - Está claro que dejar un agujero en el servidor, en términos generales, a través del cual puede pegar el zoológico de elefantes y colapsar todo el grupo para siempre ... Tomará tiempo para la recuperación manual ... Esto es, por decirlo suavemente, mal. Por otro lado, esto es curioso: en la vida real, en la práctica, ¿hay situaciones en las que ocurren ataques internos naturalmente similares?MONTE:- Dado que rara vez encuentro brechas de seguridad en la vida real, no puedo decir, tal vez sucedan. Pero si hablamos de filosofía de desarrollo, entonces creemos que sí: tenemos un perímetro que proporciona a los muchachos que hacen seguridad: es un castillo, un muro; y dentro del perímetro puedes hacer lo que quieras. Está claro que hay usuarios con la capacidad de mirar solo, y hay usuarios con la capacidad de borrar el directorio.Dependiendo de los derechos, el daño que los usuarios pueden hacer puede ser un mouse o un elefante. Está claro que un usuario con todos los derechos puede hacer cualquier cosa. Un usuario con derechos de daño no amplios puede causar significativamente menos. En particular, no puede romper el sistema.A:- En el perímetro seguro, alguien subió para formar protocolos inesperados para el servidor con el fin de configurar el servidor con cáncer, y si tiene suerte, entonces todo el clúster ... ¿Es tan "bueno"?MT: - Nunca he oído hablar de esas cosas. El hecho de que de esta manera pueda llenar el servidor no es un secreto. Para llenar el interior, ser del protocolo, ser un usuario autorizado que puede escribir algo así en un mensaje ... En realidad, es imposible, porque de todos modos se verificará. Es posible deshabilitar esta autenticación para los usuarios que no lo deseen; este es su problema; en términos generales, ellos mismos destruyeron las paredes y puedes meter un elefante allí, lo que pisoteará ... En general, puedes vestirte como un reparador, ¡ven a buscarlo!A:Gracias por el informe. Sergey (Yandex). En "Mong" hay una constante que limita el número de miembros con derecho a voto en el conjunto de réplica, y esta constante es 7 (siete). ¿Por qué es esto una constante? ¿Por qué este no es algún tipo de parámetro?MT: - Conjunto de réplicas también tenemos 40 nodos. Siempre hay una mayoría. No sé qué versión ...P: - En el conjunto de réplicas, puede ejecutar miembros sin derecho a voto, pero votando: un máximo de 7. ¿Cómo, en este caso, experimentar el cierre si tenemos el conjunto de réplica retirado a 3 centros de datos? Un centro de datos puede apagarse fácilmente y otra máquina se cae.MT: - Esto ya está un poco fuera del alcance del informe. Esta es una pregunta común. Quizás entonces pueda decírselo.
MT: - ¡Las personas malvadas dentro del perímetro son como un caballo de Troya! Las personas malvadas dentro del perímetro pueden hacer muchas cosas malas.P: - Está claro que dejar un agujero en el servidor, en términos generales, a través del cual puede pegar el zoológico de elefantes y colapsar todo el grupo para siempre ... Tomará tiempo para la recuperación manual ... Esto es, por decirlo suavemente, mal. Por otro lado, esto es curioso: en la vida real, en la práctica, ¿hay situaciones en las que ocurren ataques internos naturalmente similares?MONTE:- Dado que rara vez encuentro brechas de seguridad en la vida real, no puedo decir, tal vez sucedan. Pero si hablamos de filosofía de desarrollo, entonces creemos que sí: tenemos un perímetro que proporciona a los muchachos que hacen seguridad: es un castillo, un muro; y dentro del perímetro puedes hacer lo que quieras. Está claro que hay usuarios con la capacidad de mirar solo, y hay usuarios con la capacidad de borrar el directorio.Dependiendo de los derechos, el daño que los usuarios pueden hacer puede ser un mouse o un elefante. Está claro que un usuario con todos los derechos puede hacer cualquier cosa. Un usuario con derechos de daño no amplios puede causar significativamente menos. En particular, no puede romper el sistema.A:- En el perímetro seguro, alguien subió para formar protocolos inesperados para el servidor con el fin de configurar el servidor con cáncer, y si tiene suerte, entonces todo el clúster ... ¿Es tan "bueno"?MT: - Nunca he oído hablar de esas cosas. El hecho de que de esta manera pueda llenar el servidor no es un secreto. Para llenar el interior, ser del protocolo, ser un usuario autorizado que puede escribir algo así en un mensaje ... En realidad, es imposible, porque de todos modos se verificará. Es posible deshabilitar esta autenticación para los usuarios que no lo deseen; este es su problema; en términos generales, ellos mismos destruyeron las paredes y puedes meter un elefante allí, lo que pisoteará ... En general, puedes vestirte como un reparador, ¡ven a buscarlo!A:Gracias por el informe. Sergey (Yandex). En "Mong" hay una constante que limita el número de miembros con derecho a voto en el conjunto de réplica, y esta constante es 7 (siete). ¿Por qué es esto una constante? ¿Por qué este no es algún tipo de parámetro?MT: - Conjunto de réplicas también tenemos 40 nodos. Siempre hay una mayoría. No sé qué versión ...P: - En el conjunto de réplicas, puede ejecutar miembros sin derecho a voto, pero votando: un máximo de 7. ¿Cómo, en este caso, experimentar el cierre si tenemos el conjunto de réplica retirado a 3 centros de datos? Un centro de datos puede apagarse fácilmente y otra máquina se cae.MT: - Esto ya está un poco fuera del alcance del informe. Esta es una pregunta común. Quizás entonces pueda decírselo.
Un poco de publicidad :)
Gracias por estar con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes? Apóyenos haciendo un pedido o recomendando a sus amigos VPS basado en la nube para desarrolladores desde $ 4.99 , un análogo único de servidores de nivel básico que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2697 v3 (6 núcleos) 10GB DDR4 480GB SSD 1Gbps desde $ 19 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).Dell R730xd 2 veces más barato en el centro de datos Equinix Tier IV en Amsterdam? ¡Solo tenemos 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV desde $ 199 en los Países Bajos!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - ¡desde $ 99! Lea sobre Cómo construir un edificio de infraestructura. clase c con servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo? Source: https://habr.com/ru/post/undefined/
All Articles