El año 2018 estaba terminando ...Una vez, en un claro día de diciembre, nuestra Compañía decidió comprar un nuevo hardware. No, por supuesto, esto no sucedió de la noche a la mañana. La decisión fue tomada antes. Mucho más temprano. Pero, como siempre, no siempre nuestros deseos coinciden con las capacidades de los accionistas. Y no había dinero, y aguantamos. Pero finalmente, ese momento alegre llegó cuando la adquisición fue aprobada en todos los niveles. Todo estuvo bien, los trabajadores de cuello blanco aplaudieron alegremente, estaban cansados de procesar documentos durante 25 horas mensuales en servidores de 7 años, y pidieron al Departamento de TI con mucha persistencia algo para darles más tiempo para otras cosas igualmente importantes. .Prometimos reducir el tiempo de procesamiento de documentos en 3 veces, hasta 8 horas. Para esto, se disparó un gorrión desde un cañón. Esta opción parecía la única, ya que nuestro equipo no tenía, y nunca tuvo, un administrador de base de datos para aplicar todo tipo de optimización de consultas (DBA).La configuración del equipo seleccionado fue, por supuesto, altísima. Estos fueron tres servidores de la compañía HPE : DL560 Gen10. Cada uno de ellos contaba con 4 procesadores Intel Xeon Platinum 8164 2.0Ghz con 26 núcleos, 256 DDR4 RAM, así como 8 SSD 800Gb SAS (SSD 800Gb WD Ultrastar DC SS530 WUSTR6480ASS204) + 8 SSD 1.92Tb (Western Digital Ultrastar DC SS530 )Estas "piezas de hierro" estaban destinadas al clúster VMware (HA + DRS + vSAN). Que ha estado trabajando con nosotros durante casi 3 años en servidores similares de las generaciones 7 y 8, también de HPE. Por cierto, no hubo problemas hasta que HPE se negó a admitirlos y actualizar ESXi desde la versión 6.0, incluso a la 6.5, sin una pandereta. Bueno, bueno, como resultado, fue posible actualizar. Al cambiar la imagen de instalación, eliminar módulos de problemas incompatibles de la imagen de instalación, etc. Esto también agregó combustible al fuego de nuestro deseo de combinar todo lo nuevo. Por supuesto, si no fuera por los nuevos "trucos" de vSAN, en el ataúd vimos una actualización de todo el sistema desde la versión 6.0 a una más nueva, y no habría necesidad de escribir un artículo, pero no estamos buscando formas fáciles ...Entonces, compramos este equipo y decidimos reemplazar el obsoleto. Aplicamos el último SPP a cada nuevo servidor, instalamos en cada uno de ellos dos tarjetas de red Ethernet 10G (una para redes de usuarios y la segunda para SAN, 656596-B21 HP Ethernet 10Gb 2-port 530T). Sí, cada nuevo servidor venía con una tarjeta de red SFP + sin módulos, pero nuestra infraestructura de red implicaba Ethernet (dos pilas de conmutadores DELL 4032N para redes LAN y SAN), y el distribuidor de HP en Moscú no tenía módulos HPE 813874-B21 y nosotros No esperaron.Cuando llegó el momento de instalar ESXi e incorporar nuevos nodos en un centro de datos VMware común, ocurrió un "milagro". Al final resultó que, HPE ESXi Custom ISO versión 6.5 y posteriores no está diseñado para instalarse en nuevos servidores Gen10. Solo hardcore, solo 6.7. Y tuvimos que seguir inconscientemente los preceptos de la "empresa virtual".Se creó un nuevo clúster HA + DRS, se creó un clúster vSAN, todo cumpliendo estrictamente con VMware HCL y este documento . Todo se configuró de acuerdo con el Feng Shui y solo las "alarmas" periódicas eran sospechosas al monitorear vSAN sobre los valores de los parámetros distintos de cero en esta sección: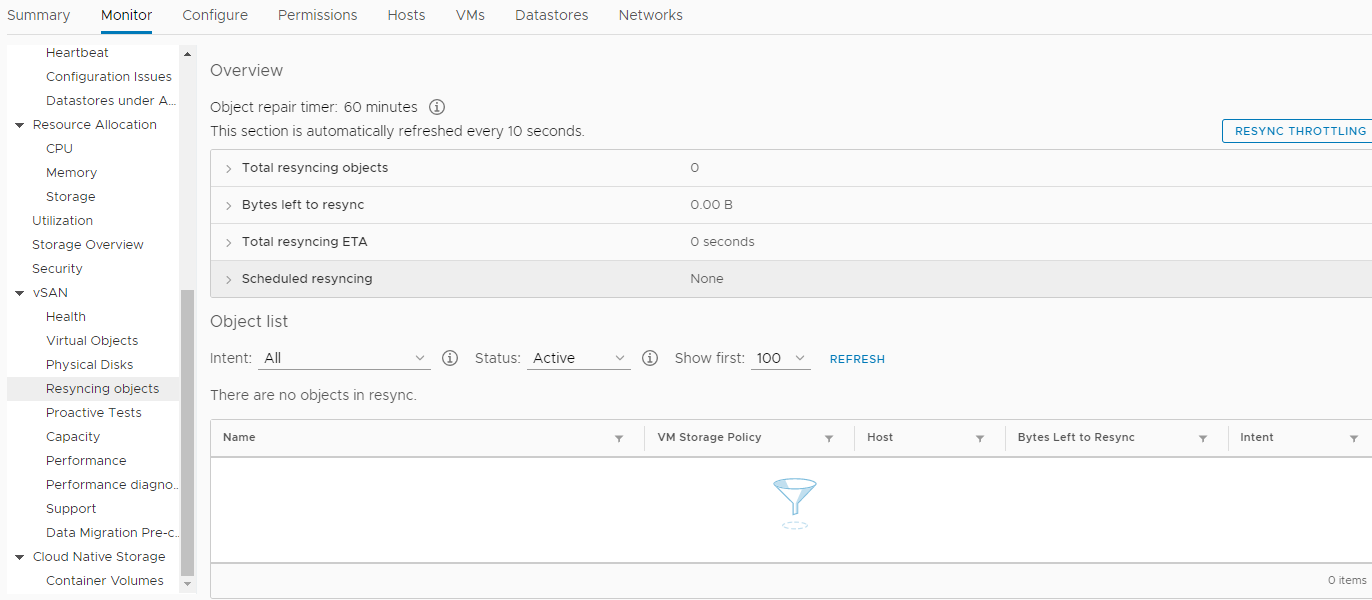 Con tranquilidad, trasladamos todas las máquinas virtuales (aproximadamente 50 unidades) a nuevos servidores y a un nuevo almacenamiento vSAN integrado en discos SSD, verificamos el rendimiento del procesamiento de documentos en el nuevo entorno (por cierto, resultó ahorrar mucho más tiempo del que planeamos) . Hasta que la base más pesada se transfirió al nuevo clúster, la operación, que se mencionó al principio del artículo, ¡tomó alrededor de 4 horas en lugar de 25! Esta fue una contribución significativa al estado de ánimo de Año Nuevo de todos los participantes en el proceso. Algunos probablemente comenzaron a soñar con un premio. Luego, todos se fueron felices para las vacaciones de Año Nuevo.Cuando comenzaron los días laborables del nuevo año 2019, nada auguraba una catástrofe. ¡Todos los servicios, transferidos a nuevas capacidades, sin exagerar, despegaron! Solo los eventos en la sección de resincronización de objetos se volvieron mucho más. Y después de un par de semanas ocurrieron problemas. Temprano en la mañana, casi todos los servicios clave de la Compañía (1s, MSSQL, SMB, Exchange, etc.) dejaron de responder o comenzaron a responder con un largo retraso. Toda la infraestructura se sumió en un completo caos, y nadie sabía qué sucedía y qué hacer. Todas las máquinas virtuales en vCenter se veían "verdes", no hubo errores en su monitoreo. Reiniciar no ayudó. Además, después de un reinicio, algunas máquinas ni siquiera pudieron arrancar, mostrando varios errores de proceso en la consola. El infierno parecía venir a nosotros y el diablo se frotaba las manos con anticipación.Bajo la presión de un estrés grave, fue posible determinar la fuente del desastre. Este problema resultó ser el almacenamiento distribuido vSAN. La corrupción no controlada de datos en discos de máquinas virtuales ocurrió, a primera vista, sin ninguna razón. En ese momento, la única solución que parecía racional era ponerse en contacto con el soporte técnico de VMware con gritos: SOS, guardar-ayuda!Y esta decisión, posteriormente, salvó a la Compañía de la pérdida de datos relevantes, incluidos los buzones de los empleados, las bases de datos y los archivos compartidos. Juntos, estamos hablando de más de 30 terabytes de información.Está obligado a rendir homenaje al personal de soporte de VMware que no "jugó al fútbol" con el titular de la suscripción de soporte técnico básico, pero incluyó este caso en el segmento Enterpise, y el proceso giró las 24 horas.Lo que pasó después:
Con tranquilidad, trasladamos todas las máquinas virtuales (aproximadamente 50 unidades) a nuevos servidores y a un nuevo almacenamiento vSAN integrado en discos SSD, verificamos el rendimiento del procesamiento de documentos en el nuevo entorno (por cierto, resultó ahorrar mucho más tiempo del que planeamos) . Hasta que la base más pesada se transfirió al nuevo clúster, la operación, que se mencionó al principio del artículo, ¡tomó alrededor de 4 horas en lugar de 25! Esta fue una contribución significativa al estado de ánimo de Año Nuevo de todos los participantes en el proceso. Algunos probablemente comenzaron a soñar con un premio. Luego, todos se fueron felices para las vacaciones de Año Nuevo.Cuando comenzaron los días laborables del nuevo año 2019, nada auguraba una catástrofe. ¡Todos los servicios, transferidos a nuevas capacidades, sin exagerar, despegaron! Solo los eventos en la sección de resincronización de objetos se volvieron mucho más. Y después de un par de semanas ocurrieron problemas. Temprano en la mañana, casi todos los servicios clave de la Compañía (1s, MSSQL, SMB, Exchange, etc.) dejaron de responder o comenzaron a responder con un largo retraso. Toda la infraestructura se sumió en un completo caos, y nadie sabía qué sucedía y qué hacer. Todas las máquinas virtuales en vCenter se veían "verdes", no hubo errores en su monitoreo. Reiniciar no ayudó. Además, después de un reinicio, algunas máquinas ni siquiera pudieron arrancar, mostrando varios errores de proceso en la consola. El infierno parecía venir a nosotros y el diablo se frotaba las manos con anticipación.Bajo la presión de un estrés grave, fue posible determinar la fuente del desastre. Este problema resultó ser el almacenamiento distribuido vSAN. La corrupción no controlada de datos en discos de máquinas virtuales ocurrió, a primera vista, sin ninguna razón. En ese momento, la única solución que parecía racional era ponerse en contacto con el soporte técnico de VMware con gritos: SOS, guardar-ayuda!Y esta decisión, posteriormente, salvó a la Compañía de la pérdida de datos relevantes, incluidos los buzones de los empleados, las bases de datos y los archivos compartidos. Juntos, estamos hablando de más de 30 terabytes de información.Está obligado a rendir homenaje al personal de soporte de VMware que no "jugó al fútbol" con el titular de la suscripción de soporte técnico básico, pero incluyó este caso en el segmento Enterpise, y el proceso giró las 24 horas.Lo que pasó después:- El soporte técnico de VMware planteó dos preguntas principales: cómo recuperar datos y cómo resolver el problema de la corrupción de datos "fantasma" en discos de máquinas virtuales en el clúster de combate "vSAN". Por cierto, los datos no estaban en ninguna parte para recuperarse, ya que el almacenamiento adicional estaba ocupado por copias de seguridad y simplemente no había ningún lugar para desplegar servicios de "combate".
- Mientras que, junto con VMware, intenté juntar los objetos "dañados" en el clúster de vSAN, mis colegas extrajeron con urgencia un nuevo almacenamiento que pudiera acomodar los más de 30 terabytes de datos de la Compañía.
- , , VMware , , «» - - . , ?
- .
- , « » .
- , , «» .
- Tuve que sacrificar temporalmente (durante un par de días) la eficiencia del correo, en aras de 6 terabytes adicionales de espacio libre en el almacenamiento, para lanzar los servicios clave de los que dependían los ingresos de la Compañía.
- Miles de líneas de chat con colegas de VMware de habla inglesa se guardaron "para la memoria", aquí hay un breve extracto de nuestras conversaciones:
I understood that you are now migrating all the VMs out of vSAN datastore.
May I know, how the migration task is going on.? How many VMs left and how much time is expected to migrate the remaining VMs. ?
There are 6 vms still need to be migrated. 1 of them is fail so far.
How much time is expected to complete the migration for the working VMs..?
I think atleast 2-3 hours
ok
Can you please SSH to vCenter server ?
you on it
/localhost/Datacenter ###CLUB/computers/###Cluster> vsan.check_state .
2019-02-02 05:22:34 +0300: Step 1: Check for inaccessible vSAN objects
Detected 3 objects to be inaccessible
Detected 7aa2265c-6e46-2f49-df40-20677c0084e0 on esxi-dl560-gen10-2.####.lan to be inaccessible
Detected 99c3515c-bee0-9faa-1f13-20677c038dd8 on esxi-dl560-gen10-3.####.lan to be inaccessible
Detected f1ca455c-d47e-11f7-7e90-20677c038de0 on esxi-dl560-gen10-1.####.lan to be inaccessible
2019-02-02 05:22:34 +0300: Step 2: Check for invalid/inaccessible VMs
Detected VM 'i.#####.ru' as being 'inaccessible'
2019-02-02 05:22:34 +0300: Step 3: Check for VMs for which VC/hostd/vmx are out of sync
Did not find VMs for which VC/hostd/vmx are out of sync
/localhost/Datacenter ###CLUB/computers/###Cluster>
Thank you
second vm with issues: sd.####.ru
Cómo se manifestó este problema (además de los servicios de organización firmemente caídos).Crecimiento exponencial de errores de suma de comprobación (CRC) "de la nada" durante el intercambio de datos con discos en modo HBA. Cómo verificar esto: ingrese el siguiente comando en la consola de cada nodo ESXi:while true; do clear; for disk in $(localcli vsan storage list | grep -B10 'ity Tier: tr' |grep "VSAN UUID"|awk '{print $3}'|sort -u);do echo ==DISK==$disk====;vsish -e get /vmkModules/lsom/disks/$disk/checksumErrors | grep -v ':0';done; sleep 3; done
Como resultado de la ejecución, puede ver errores de CRC para cada disco en el clúster de vSAN de este nodo (no se mostrarán valores cero). Si tiene valores positivos y, además, están en constante crecimiento, entonces hay una razón para que surjan tareas constantemente en la sección Monitor -> vSAN -> Resincing de objetos del clúster.¿Cómo recuperar discos de máquinas virtuales que no se clonan ni migran por medios estándar?¿Quién hubiera pensado usar el poderoso comando cat:1. cd vSAN
[root@esxi-dl560-gen10-1:~] cd /vmfs/volumes/vsanDatastore/estaff
2. grep vmdk uuid
[root@esxi-dl560-gen10-1:/vmfs/volumes/vsan:52f53dfd12dddc84-f712dbefac32cd1a/2636a75c-e8f1-d9ca-9a00-20677c0084e0] grep vsan *vmdk
estaff.vmdk:RW 10485760 VMFS "vsan://3836a75c-d2dc-5f5d-879c-20677c0084e0"
estaff_1.vmdk:RW 41943040 VMFS "vsan://3736a75c-e412-a6c8-6ce4-20677c0084e0"
[root@esxi-dl560-gen10-1:/vmfs/volumes/vsan:52f53dfd12dddc84-f712dbefac32cd1a/2636a75c-e8f1-d9ca-9a00-20677c0084e0]
3. VM , :
mkdir /vmfs/volumes/POWERVAULT/estaff
4. vmx
cp *vmx *vmdk /vmfs/volumes/POWERVAULT/estaff
5. , ^_^
/usr/lib/vmware/osfs/bin/objtool open -u 3836a75c-d2dc-5f5d-879c-20677c0084e0; sleep 1; cat /vmfs/devices/vsan/3836a75c-d2dc-5f5d-879c-20677c0084e0 >> /vmfs/volumes/POWERVAULT/estaff/estaff-flat.vmdk
6. cd :
cd /vmfs/volumes/POWERVAULT/estaff
7. - estaff.vmdk
[root@esxi-dl560-gen10-1:/tmp] cat estaff.vmdk
# Disk DescriptorFile
version=4
encoding="UTF-8"
CID=a7bb7cdc
parentCID=ffffffff
createType="vmfs"
# Extent description
RW 10485760 VMFS "vsan://3836a75c-d2dc-5f5d-879c-20677c0084e0" <<<<< "estaff-flat.vmdk"
# The Disk Data Base
#DDB
ddb.adapterType = "ide"
ddb.deletable = "true"
ddb.geometry.cylinders = "10402"
ddb.geometry.heads = "16"
ddb.geometry.sectors = "63"
ddb.longContentID = "6379fa7fdf6009c344bd9a64a7bb7cdc"
ddb.thinProvisioned = "1"
ddb.toolsInstallType = "1"
ddb.toolsVersion = "10252"
ddb.uuid = "60 00 C2 92 c7 97 ca ae-8d da 1c e2 3c df cf a5"
ddb.virtualHWVersion = "8"
[root@esxi-dl560-gen10-1:/tmp]
Cómo reconocer discos naa.xxxx ... en grupos de discos:[root@esxi-dl560-gen10-1:/vmfs/volumes] vdq -Hi
Mappings:
DiskMapping[0]:
SSD: naa.5000c5003024eb43
MD: naa.5000cca0aa0025f4
MD: naa.5000cca0aa00253c
MD: naa.5000cca0aa0022a8
MD: naa.5000cca0aa002500
DiskMapping[2]:
SSD: naa.5000c5003024eb47
MD: naa.5000cca0aa002698
MD: naa.5000cca0aa0029c4
MD: naa.5000cca0aa002950
MD: naa.5000cca0aa0028cc
DiskMapping[4]:
SSD: naa.5000c5003024eb4f
MD: naa.5000c50030287137
MD: naa.5000c50030287093
MD: naa.5000c50030287027
MD: naa.5000c5003024eb5b
MD: naa.5000c50030287187
Cómo averiguar los UUID de vUAN para cada naa ...:[root@esxi-dl560-gen10-1:/vmfs/volumes] localcli vsan storage list | grep -B15 'ity Tier: tr' | grep -E '^naa|VSAN UUID'
naa.5000cca0aa002698:
VSAN UUID: 52247b7d-fed5-a2f2-a2e8-5371fa7ef8ed
naa.5000cca0aa0029c4:
VSAN UUID: 52309c55-3ecc-3fe8-f6ec-208701d83813
naa.5000c50030287027:
VSAN UUID: 523d7ea5-a926-3acd-2d58-0c1d5889a401
naa.5000cca0aa0022a8:
VSAN UUID: 524431a2-4291-cb49-7070-8fa1d5fe608d
naa.5000c50030287187:
VSAN UUID: 5255739f-286c-8808-1ab9-812454968734
naa.5000cca0aa0025f4: <<<<<<<
VSAN UUID: 52b1d17e-02cc-164b-17fa-9892df0c1726
naa.5000cca0aa00253c:
VSAN UUID: 52bd28f3-d84e-e1d5-b4dc-54b75456b53f
naa.5000cca0aa002950:
VSAN UUID: 52d6e04f-e1af-cfb2-3230-dd941fd8a032
naa.5000c50030287137:
VSAN UUID: 52df506a-36ea-f113-137d-41866c923901
naa.5000cca0aa002500:
VSAN UUID: 52e2ce99-1836-c825-6600-653e8142e10f
naa.5000cca0aa0028cc:
VSAN UUID: 52e89346-fd30-e96f-3bd6-8dbc9e9b4436
naa.5000c50030287093:
VSAN UUID: 52ecacbe-ef3b-aa6e-eba3-6e713a0eb3b2
naa.5000c5003024eb5b:
VSAN UUID: 52f1eecb-befa-12d6-8457-a031eacc1cab
Y lo más importante.El problema resultó ser la operación incorrecta del firmware del controlador RAID y el controlador HPE con vSAN.Anteriormente, en VMware 6.7 U1, el firmware compatible para el controlador HPE Smart Array P816i-a SR Gen10 en vSAN HCL era la versión 1.98 (que resultó ser fatal para nuestra organización), y ahora dice 1.65 .Además, la versión 1.99, que resolvió el problema en ese momento (31 de enero de 2019), ya estaba en los contenedores de HPE, pero no la pasaron ni a VMware ni a nosotros, citando la falta de certificación, a pesar de nuestras renuncias y todo eso. , dicen, lo principal para nosotros es resolver el problema con el almacenamiento y eso es todo.Como resultado, el problema finalmente se resolvió solo después de tres meses, cuando se lanzó la versión de firmware 1.99 para el controlador de disco.¿Qué conclusiones he sacado?- ( ), .
- ! .
- «» , «» «» , 30% «».
- HPE, , .
- , :
- HPE - . , Enterprise . , , ).
- No preveía una situación en la que se pudiera necesitar espacio en disco adicional para colocar copias de todos los servidores de la Compañía en caso de emergencia.
- Además, a la luz de lo que sucedió, para VMware ya no compraré hardware para grandes empresas, ningún proveedor que no sea DELL. Por qué, porque DELL, hasta donde yo sé, adquirió VMware, y ahora se espera que la integración de hardware y software en esta dirección sea lo más cercana posible.
Como dicen, quemados en leche, soplar en el agua.Eso es todo chicos. Deseo que nunca te metas en situaciones tan terribles.Según recuerdo, ¡ya me sorprenderé!