HighLoad ++, Anastasia Tsymbalyuk, Stanislav Tselovalnikov (Sberbank): cómo nos convertimos en MDA
La próxima conferencia HighLoad ++ se llevará a cabo los días 6 y 7 de abril de 2020 en San Petersburgo.Detalles y entradas aquí . HighLoad ++ Siberia 2019. Salón "Krasnoyarsk". 25 de junio, 2 p.m. Resúmenes y presentación .Desarrollar un sistema de gestión y difusión de datos industriales desde cero no es una tarea fácil. Especialmente cuando hay un retraso total, el tiempo de trabajo es una cuarta parte y los requisitos del producto son turbulencias perpetuas. Hablaremos sobre el ejemplo de la construcción de un sistema de gestión de metadatos, cómo construir un sistema escalable industrial en un corto período de tiempo, que incluye el almacenamiento y la difusión de datos.Nuestro enfoque aprovecha al máximo los metadatos, el código dinámico de SQL y la generación de código basada en codegen y manillar Swagger. Esta solución reduce el tiempo de desarrollo y reconfiguración del sistema, y agregar nuevos objetos de administración no requiere una sola línea de código nuevo.Le diremos cómo funciona en nuestro equipo: qué reglas cumplimos, qué herramientas usamos, qué dificultades encontramos y cómo las superamos heroicamente.Anastasia Tsymbalyuk (en adelante - AC): - ¡Mi nombre es Nastya, y esta es Stas!Stas Tselovalnikov (en adelante, SC): - ¡Hola a todos!AC: - Hoy le diremos sobre MDA y cómo, utilizando este enfoque, redujimos el tiempo de desarrollo y presentamos al mundo un sistema de gestión de metadatos escalable industrial. ¡Hurra!SC: - Nastya, ¿qué es la MDA?AC: - Stas, creo que ahora pasaremos a esto sin problemas. Más precisamente, hablaré sobre esto un poco al final de la presentación. Hablemos de nosotros primero:
Hablaremos sobre el ejemplo de la construcción de un sistema de gestión de metadatos, cómo construir un sistema escalable industrial en un corto período de tiempo, que incluye el almacenamiento y la difusión de datos.Nuestro enfoque aprovecha al máximo los metadatos, el código dinámico de SQL y la generación de código basada en codegen y manillar Swagger. Esta solución reduce el tiempo de desarrollo y reconfiguración del sistema, y agregar nuevos objetos de administración no requiere una sola línea de código nuevo.Le diremos cómo funciona en nuestro equipo: qué reglas cumplimos, qué herramientas usamos, qué dificultades encontramos y cómo las superamos heroicamente.Anastasia Tsymbalyuk (en adelante - AC): - ¡Mi nombre es Nastya, y esta es Stas!Stas Tselovalnikov (en adelante, SC): - ¡Hola a todos!AC: - Hoy le diremos sobre MDA y cómo, utilizando este enfoque, redujimos el tiempo de desarrollo y presentamos al mundo un sistema de gestión de metadatos escalable industrial. ¡Hurra!SC: - Nastya, ¿qué es la MDA?AC: - Stas, creo que ahora pasaremos a esto sin problemas. Más precisamente, hablaré sobre esto un poco al final de la presentación. Hablemos de nosotros primero: puedo describirme como un buscador de sinergia en soluciones industriales de TI.SC: ¿Y yo?
puedo describirme como un buscador de sinergia en soluciones industriales de TI.SC: ¿Y yo?¿Qué hace el equipo de SberData?
AC: - ¡Y usted es solo un mastodonte industrial, porque trajo más de una solución al baile de graduación!SC: - De hecho, trabajamos juntos en Sberbank en el mismo equipo y gestionamos los metadatos de SberData: AC: - SberData, si es de una manera simple: esta es una plataforma analítica donde fluyen todas las pistas digitales de cada cliente. Si usted es cliente de Sberbank, toda la información sobre usted fluye exactamente allí. Allí se almacenan muchos conjuntos de datos, pero entendemos que la cantidad de datos no significa su calidad. Y los datos sin contexto a veces son completamente inútiles, porque no podemos aplicarlos, interpretarlos, protegerlos, enriquecerlos.Solo estas tareas se resuelven mediante metadatos. Nos muestran el contexto comercial y el componente técnico de los datos, es decir, dónde aparecieron, cómo se transformaron, en qué punto la descripción mínima, el marcado es ahora. Esto ya es suficiente para comenzar a usar los datos y confiar en ellos. Esta es precisamente la tarea que resuelve los metadatos.SC: En otras palabras, la misión de nuestro equipo es aumentar la eficiencia de la plataforma analítica de información de Sberbank debido al hecho de que la información de la que acaba de hablar debe entregarse a las personas adecuadas en el momento correcto en el lugar correcto. Y recuerde, también dijo que si los datos son petróleo moderno, los metadatos son un mapa de los depósitos de este petróleo.C.A:- De hecho, esta es una de mis declaraciones brillantes, de las que estoy muy orgulloso. Técnicamente, esta tarea se redujo al hecho de que tuvimos que crear una herramienta de gestión de metadatos dentro de nuestra plataforma y garantizar su ciclo de vida completo.Pero para sumergirnos en los problemas de nuestra área temática y entender en qué punto nos encontramos, sugiero retroceder hace 9 meses.Entonces, imagine: fuera de la ventana es el mes de noviembre, todos los pájaros volaron hacia el sur, estamos tristes ... Y para ese momento teníamos un piloto exitoso con el equipo, había clientes, todos nos quedamos en la zona de confort hasta que ocurrió el punto de no retorno.
AC: - SberData, si es de una manera simple: esta es una plataforma analítica donde fluyen todas las pistas digitales de cada cliente. Si usted es cliente de Sberbank, toda la información sobre usted fluye exactamente allí. Allí se almacenan muchos conjuntos de datos, pero entendemos que la cantidad de datos no significa su calidad. Y los datos sin contexto a veces son completamente inútiles, porque no podemos aplicarlos, interpretarlos, protegerlos, enriquecerlos.Solo estas tareas se resuelven mediante metadatos. Nos muestran el contexto comercial y el componente técnico de los datos, es decir, dónde aparecieron, cómo se transformaron, en qué punto la descripción mínima, el marcado es ahora. Esto ya es suficiente para comenzar a usar los datos y confiar en ellos. Esta es precisamente la tarea que resuelve los metadatos.SC: En otras palabras, la misión de nuestro equipo es aumentar la eficiencia de la plataforma analítica de información de Sberbank debido al hecho de que la información de la que acaba de hablar debe entregarse a las personas adecuadas en el momento correcto en el lugar correcto. Y recuerde, también dijo que si los datos son petróleo moderno, los metadatos son un mapa de los depósitos de este petróleo.C.A:- De hecho, esta es una de mis declaraciones brillantes, de las que estoy muy orgulloso. Técnicamente, esta tarea se redujo al hecho de que tuvimos que crear una herramienta de gestión de metadatos dentro de nuestra plataforma y garantizar su ciclo de vida completo.Pero para sumergirnos en los problemas de nuestra área temática y entender en qué punto nos encontramos, sugiero retroceder hace 9 meses.Entonces, imagine: fuera de la ventana es el mes de noviembre, todos los pájaros volaron hacia el sur, estamos tristes ... Y para ese momento teníamos un piloto exitoso con el equipo, había clientes, todos nos quedamos en la zona de confort hasta que ocurrió el punto de no retorno.Sistema de gestión de metadatos modelo
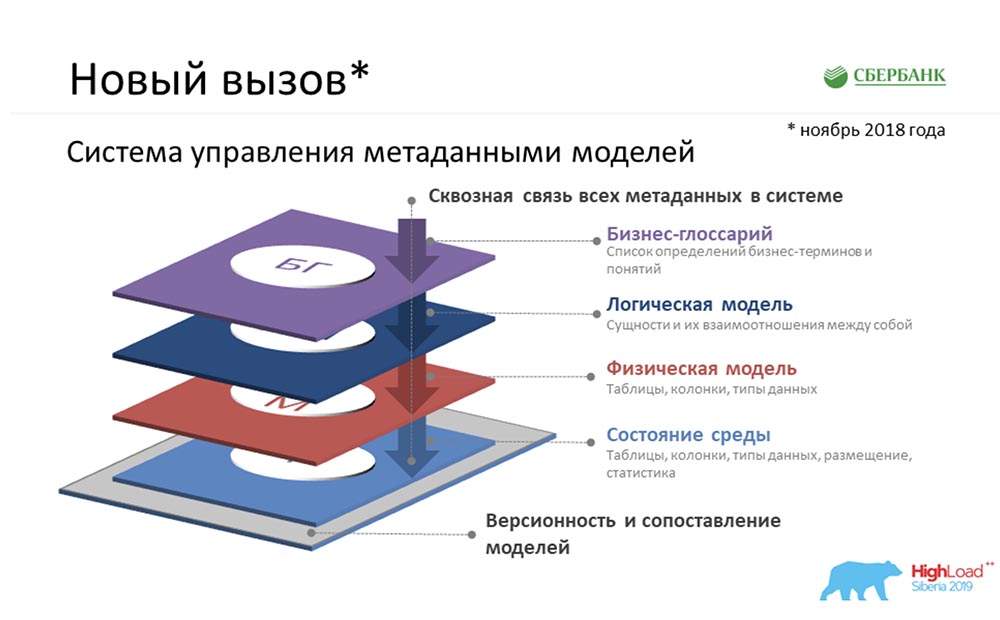 SC: - Había algo más que tenía sobre estar en una zona de confort ... De hecho, se nos asignó la tarea de crear Metadata Broker, que se suponía debía brindar la oportunidad de comunicarnos con nuestros clientes, programas y sistemas. Nuestros clientes deberían haber tenido la oportunidad en el backend de enviar algún tipo de paquete de metadatos o recibirlo. Y nosotros, al proporcionar esta función, en nuestro nivel tuvimos que acumular la información más consistente y relevante sobre metadatos en cuatro niveles lógicos:
SC: - Había algo más que tenía sobre estar en una zona de confort ... De hecho, se nos asignó la tarea de crear Metadata Broker, que se suponía debía brindar la oportunidad de comunicarnos con nuestros clientes, programas y sistemas. Nuestros clientes deberían haber tenido la oportunidad en el backend de enviar algún tipo de paquete de metadatos o recibirlo. Y nosotros, al proporcionar esta función, en nuestro nivel tuvimos que acumular la información más consistente y relevante sobre metadatos en cuatro niveles lógicos:- Nivel de glosario empresarial.
- El nivel del modelo lógico.
- El nivel del modelo físico.
- El estado del medio ambiente que recibimos debido al reverso de los entornos industriales.
Y todo esto debe ser consistente.AC: Sí, de verdad. Pero aquí también explicaría de alguna manera de manera simple, porque no excluyo que el área temática no sea clara e incomprensible ... Unglosario de negocios trata sobre lo que las personas inteligentes en trajes inventan durante horas ... cómo nombrar un término, cómo elaborar una fórmula cálculo. Piensan durante mucho tiempo, y al final solo tienen un glosario de negocios.El modelo lógico trata sobre cómo se ve el analista en el mundo, quién puede comunicarse con estas personas inteligentes con trajes y corbatas, pero al mismo tiempo comprende cómo sería posible aterrizar. Lejos de los detalles de la realización física.El modelo físico se trata cuando es el turno de programadores severos, arquitectos que realmente entienden cómo aterrizar estos objetos: en qué mesa colocar, qué campos crear, qué índices colgar ... Elestado del entorno es una especie de elenco. Esto es como un testimonio de un automóvil. Un programador a veces quiere decirle a la máquina una cosa, pero no lo entiende. Solo el estado del medio ambiente nos muestra el estado real de las cosas, y constantemente comparamos todo; y entendemos que hay una diferencia entre lo que dijo el programador y el estado real del entorno.Caso para describir metadatos
SC: - Vamos a explicarlo con un ejemplo concreto. Por ejemplo, tenemos cuatro de estos niveles designados. Supongamos que tenemos a estas personas serias vinculadas que trabajan al nivel de un glosario de negocios; no entienden en absoluto cómo y qué se organiza en su interior. Pero entienden que necesitan hacer una forma de informes obligatorios, necesitan obtener, por ejemplo, el saldo promedio de las cuentas personales: a este nivel, una persona ya debe tener su propio glosario comercial (términos de informes obligatorios) o tenerlo (saldo promedio en una cuenta personal). Luego viene el analista que lo entiende perfectamente, puede hablar el mismo idioma con él, pero también puede hablar el mismo idioma con los programadores.Él dice: "Escucha, aquí tienes toda la historia dividida en cuentas separadas como entidades, y tienen un atributo: el saldo promedio".Luego viene el arquitecto y dice: “Haremos este escaparate de préstamos a personas jurídicas. En consecuencia, haremos una tabla física de cuentas personales, haremos una tabla física de saldos diarios en cuentas personales (porque se reciben todos los días al cierre del día de negociación). Y una vez al mes en la fecha límite, calcularemos el promedio (tabla de saldos mensuales), según lo solicitado ”.Dicho y hecho. Y luego vino nuestro analizador, que fue al circuito industrial y dijo: "Sí, ya veo, hay tablas necesarias ..." ¿Qué más enriqueció esta tabla? Aquí (como ejemplo): particiones e índices, aunque, estrictamente hablando, tanto las particiones como los índices podrían estar en el nivel de diseño del modelo físico, pero podría haber algo más (por ejemplo, volumen de datos).
a este nivel, una persona ya debe tener su propio glosario comercial (términos de informes obligatorios) o tenerlo (saldo promedio en una cuenta personal). Luego viene el analista que lo entiende perfectamente, puede hablar el mismo idioma con él, pero también puede hablar el mismo idioma con los programadores.Él dice: "Escucha, aquí tienes toda la historia dividida en cuentas separadas como entidades, y tienen un atributo: el saldo promedio".Luego viene el arquitecto y dice: “Haremos este escaparate de préstamos a personas jurídicas. En consecuencia, haremos una tabla física de cuentas personales, haremos una tabla física de saldos diarios en cuentas personales (porque se reciben todos los días al cierre del día de negociación). Y una vez al mes en la fecha límite, calcularemos el promedio (tabla de saldos mensuales), según lo solicitado ”.Dicho y hecho. Y luego vino nuestro analizador, que fue al circuito industrial y dijo: "Sí, ya veo, hay tablas necesarias ..." ¿Qué más enriqueció esta tabla? Aquí (como ejemplo): particiones e índices, aunque, estrictamente hablando, tanto las particiones como los índices podrían estar en el nivel de diseño del modelo físico, pero podría haber algo más (por ejemplo, volumen de datos).Registro y almacenamiento a nivel de metadatos.
AC: - ¿Cómo se almacena todo con nosotros? ¡Esta es una forma súper simplificada del ejemplo que Stas pintó antes! ¿Cómo nos afectará todo esto?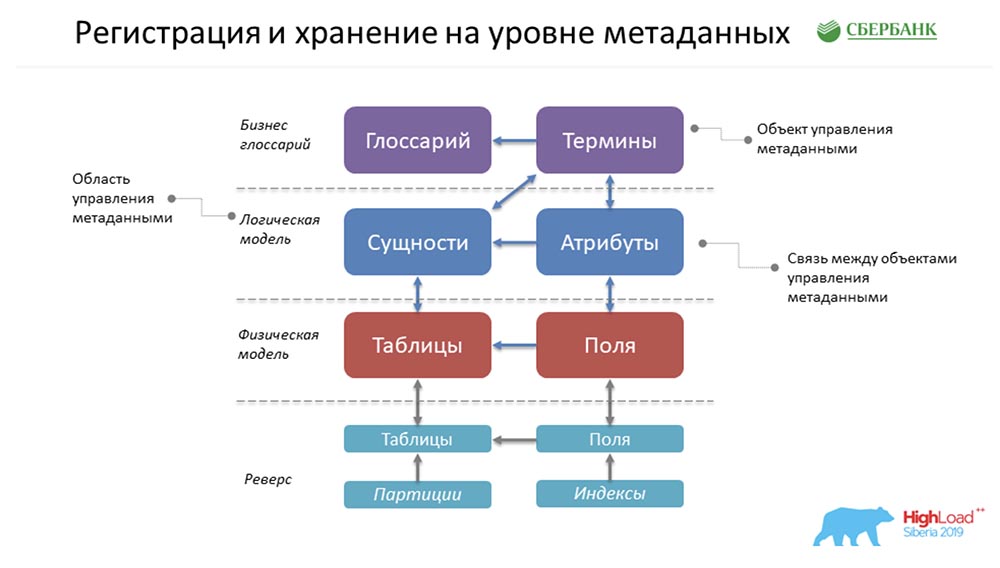 De hecho, será una línea en el objeto Glosario, una en el objeto Términos, una en las Entidades, una en los Atributos, etc. En la figura anterior, cada rectángulo es un objeto en nuestro sistema de control, que representa esta o aquella información almacenada allí.Para presentarle lentamente la terminología, le pido que tenga en cuenta lo siguiente ... ¿Qué es un objeto de gestión de metadatos? Físicamente, esto se presenta en forma de tabla, pero de hecho, cierta información se almacena allí en términos, glosarios, entidades, atributos, etc. Este término, "objeto", continuaremos utilizando en nuestra presentación.CAROLINA DEL SUR: - Aquí debe decirse que cada cubo es solo una tabla en nuestro sistema donde almacenamos metadatos, y llamamos a esto el objeto de control.
De hecho, será una línea en el objeto Glosario, una en el objeto Términos, una en las Entidades, una en los Atributos, etc. En la figura anterior, cada rectángulo es un objeto en nuestro sistema de control, que representa esta o aquella información almacenada allí.Para presentarle lentamente la terminología, le pido que tenga en cuenta lo siguiente ... ¿Qué es un objeto de gestión de metadatos? Físicamente, esto se presenta en forma de tabla, pero de hecho, cierta información se almacena allí en términos, glosarios, entidades, atributos, etc. Este término, "objeto", continuaremos utilizando en nuestra presentación.CAROLINA DEL SUR: - Aquí debe decirse que cada cubo es solo una tabla en nuestro sistema donde almacenamos metadatos, y llamamos a esto el objeto de control.Requisitos de metadatos
¿Qué teníamos en la entrada? En la entrada recibimos requisitos bastante interesantes. Había muchos de ellos, pero aquí queremos mostrar tres principales: el primer requisito es bastante clásico. Se nos dice: "Chicos, todo lo que les ha llegado una vez tiene que venir para siempre". La historización está completa y cualquier cambio en el sistema de metadatos que haya recibido (no importa si ha llegado un paquete de 100 campos (100 cambios) o si un campo ha cambiado en una tabla) requiere un nuevo registro de los metadatos. También exigen devolver la respuesta:
el primer requisito es bastante clásico. Se nos dice: "Chicos, todo lo que les ha llegado una vez tiene que venir para siempre". La historización está completa y cualquier cambio en el sistema de metadatos que haya recibido (no importa si ha llegado un paquete de 100 campos (100 cambios) o si un campo ha cambiado en una tabla) requiere un nuevo registro de los metadatos. También exigen devolver la respuesta:- por defecto - estado actual;
- por fecha;
- por número de revisión.
El segundo requisito fue más interesante: nos dijeron que pueden trabajar con nosotros en objetos, pero que tienen que programar mucho en Java, pero no quieren hacerlo. Sugirieron que mezclemos 100 objetos (o 10) a la vez, y deberíamos manejar este negocio (porque podemos). ¿Qué significa la mezcla? Por ejemplo, vinieron 10 columnas. Tienen un enlace al identificador de la tabla, pero no tenemos la tabla en sí misma: vino detrás de JSON. "Piensas y procesas, ¡es necesario que puedas"!En orden creciente de interés, el tercero: "Queremos poder usar no solo la API que nos hará, sino que queremos entendernos a nosotros mismos ..." Y en un orden arbitrario diga: "Danos la unión de este objeto a ese a través del tercer objeto. Y deje que su propio sistema comprenda cómo hacerlo todo, pregunte a la base de datos y devuelva el resultado en JSON ".Teníamos una historia así en la entrada.Estimados estimados
 AC: - Según nuestros cálculos aproximados, para implementar todo este concepto, cada objeto de control necesitaba participar en siete interfaces: simple (simple), para objeto por escritura / lectura y eliminación ...Tres más - para escritura / lectura / eliminación universal, t Es decir, que podemos tirar todo en cualquier orden y cómo transferir el conjunto de sopa al sistema, y ella descubrirá en qué orden eliminar, poner, leer.Una cosa más: construir una jerarquía para que podamos indicarle al sistema: "Regrésanos de un objeto a otro"; y devuelve un árbol de objetos anidados.
AC: - Según nuestros cálculos aproximados, para implementar todo este concepto, cada objeto de control necesitaba participar en siete interfaces: simple (simple), para objeto por escritura / lectura y eliminación ...Tres más - para escritura / lectura / eliminación universal, t Es decir, que podemos tirar todo en cualquier orden y cómo transferir el conjunto de sopa al sistema, y ella descubrirá en qué orden eliminar, poner, leer.Una cosa más: construir una jerarquía para que podamos indicarle al sistema: "Regrésanos de un objeto a otro"; y devuelve un árbol de objetos anidados.Complejidad de implementación
SC: - Además de los requisitos técnicos que nos llegaron en el momento del comienzo de esta historia, tuvimos dificultades adicionales. En primer lugar, esta es una cierta incertidumbre de los requisitos. No todos los equipos no siempre podían articular claramente lo que necesitan del servicio, y a menudo el momento de la verdad nació en el momento de la creación de prototipos de alguna historia en el circuito de def. Y si bien llegó al baile de graduación, podría haber varios ciclos.AC: - Esta es la turbulencia que se anunció al principio.SC: - Siguiente ...Había un plazo prohibitivo, porque incluso en el momento del lanzamiento más de cinco equipos dependían de nosotros. Clásicos del género: ayer se necesitaba el resultado. La opción de trabajo está en modo caballo escaldado, que es lo que hicimos.El tercero es una gran cantidad de desarrollo. Nastya en su diapositiva mostró que cuando miramos los requisitos de qué y cómo hacer, nos dimos cuenta: 1 objeto requiere siete API (ya sea para ello o para participar en siete API). Esto significa que si tenemos un parche (6 objetos, modelo, 42 API) va en una semana ...
En primer lugar, esta es una cierta incertidumbre de los requisitos. No todos los equipos no siempre podían articular claramente lo que necesitan del servicio, y a menudo el momento de la verdad nació en el momento de la creación de prototipos de alguna historia en el circuito de def. Y si bien llegó al baile de graduación, podría haber varios ciclos.AC: - Esta es la turbulencia que se anunció al principio.SC: - Siguiente ...Había un plazo prohibitivo, porque incluso en el momento del lanzamiento más de cinco equipos dependían de nosotros. Clásicos del género: ayer se necesitaba el resultado. La opción de trabajo está en modo caballo escaldado, que es lo que hicimos.El tercero es una gran cantidad de desarrollo. Nastya en su diapositiva mostró que cuando miramos los requisitos de qué y cómo hacer, nos dimos cuenta: 1 objeto requiere siete API (ya sea para ello o para participar en siete API). Esto significa que si tenemos un parche (6 objetos, modelo, 42 API) va en una semana ...Enfoque estándar
AC: Sí, en realidad 42 API por semana es solo la punta del iceberg. Somos conscientes de que para garantizar que estas 42 API funcionen, necesitamos:- en primer lugar, cree una estructura de almacenamiento para el objeto;
- en segundo lugar, para garantizar la lógica de su procesamiento;
- tercero, escriba la misma API en la que participa el objeto (o está configurado específicamente para él);
- cuarto, sería bueno cubrir idealmente todo esto con los contornos de las pruebas, probar y decir que todo está bien;
- quinto (la misma guinda del pastel), para documentar toda esta historia.
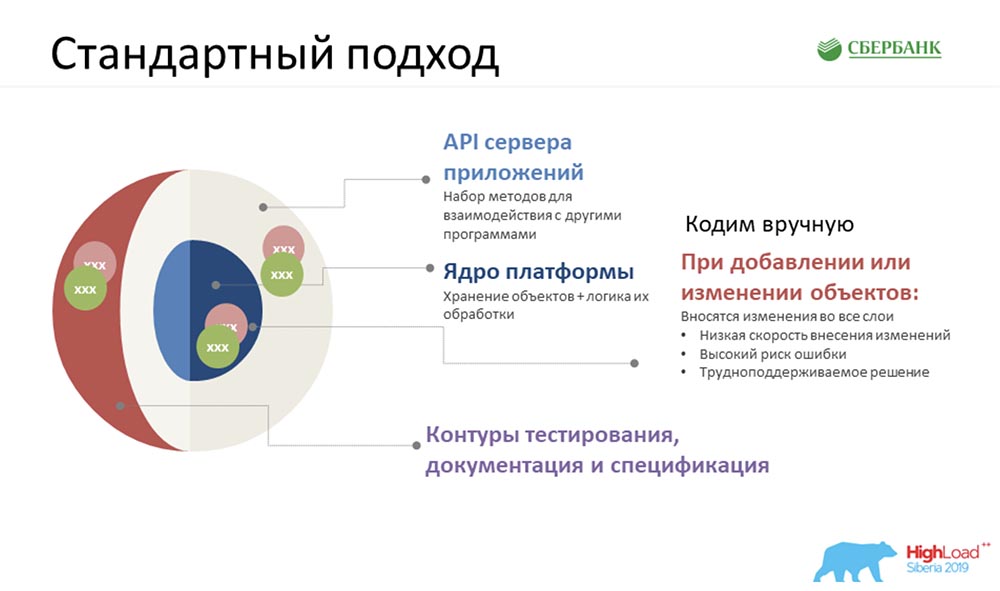 Naturalmente, lo primero que se nos ocurrió (al principio le mostramos un diagrama aproximado): teníamos unos 35 objetos. Había que hacer algo con ellos, todo esto tenía que deducirse y había muy poco tiempo. Y la primera idea que se nos ocurrió fue sentarnos, arremangarnos y comenzar a codificar.Incluso después de trabajar en este modo durante un par de días (teníamos tres equipos), alcanzamos una temperatura tan brillante ... Todos estaban nerviosos ... Y nos dimos cuenta de que necesitábamos buscar un enfoque diferente.
Naturalmente, lo primero que se nos ocurrió (al principio le mostramos un diagrama aproximado): teníamos unos 35 objetos. Había que hacer algo con ellos, todo esto tenía que deducirse y había muy poco tiempo. Y la primera idea que se nos ocurrió fue sentarnos, arremangarnos y comenzar a codificar.Incluso después de trabajar en este modo durante un par de días (teníamos tres equipos), alcanzamos una temperatura tan brillante ... Todos estaban nerviosos ... Y nos dimos cuenta de que necesitábamos buscar un enfoque diferente.Enfoque personalizado
Comenzamos a prestar atención a lo que estamos haciendo. La idea de este enfoque siempre ha estado ante nuestros ojos, porque hemos estado involucrados en metadatos durante mucho tiempo. De alguna manera, de inmediato, no se nos ocurrió ...Como puede suponer, la esencia de esta idea es utilizar metadatos. Consiste en el hecho de que recopilamos la estructura de nuestro repositorio (esto es ciertos metadatos), una vez que creamos una plantilla para algún código (por ejemplo, varias API o procedimientos para procesar lógica, scripts para crear estructuras). Una vez que creamos esta plantilla, y luego ejecutamos todos los metadatos. Por etiquetas, las propiedades se sustituyen en el código (nombres de objetos, campos, características importantes) y el código resultante está listo. Es decir, es suficiente confundirse una vez: cree una plantilla y luego use toda esta información tanto para los objetos existentes como para los nuevos. Aquí presentamos otro concepto: #META_META. Explicaré por qué, para no confundirte.Nuestro sistema se dedica a la gestión de metadatos, y el enfoque que utilizamos describe un sistema de gestión de metadatos, es decir, dos metas. "MetaMeta" - lo llamamos en casa, dentro del equipo. Para no confundir más a los demás, utilizaremos este mismo término.
Es decir, es suficiente confundirse una vez: cree una plantilla y luego use toda esta información tanto para los objetos existentes como para los nuevos. Aquí presentamos otro concepto: #META_META. Explicaré por qué, para no confundirte.Nuestro sistema se dedica a la gestión de metadatos, y el enfoque que utilizamos describe un sistema de gestión de metadatos, es decir, dos metas. "MetaMeta" - lo llamamos en casa, dentro del equipo. Para no confundir más a los demás, utilizaremos este mismo término.Mecanismo para garantizar la historización y la revisión.
SC: - Resumiste el resto de nuestro discurso. Lo contaremos con más detalle.Debo decir que cuando nos estábamos preparando para el discurso, se nos pidió que proporcionáramos información técnica que pudiera ser de interés para los colegas. Lo haremos. Además, las diapositivas serán más técnicas, tal vez alguien verá algo interesante por sí mismo.Primero, cómo resolvimos el problema de la historización y la revisión. Quizás esto es similar a cuántos lo hacen. Considere esto usando metadatos como ejemplo, que describen un solo campo en la tabla de publicación (como ejemplo):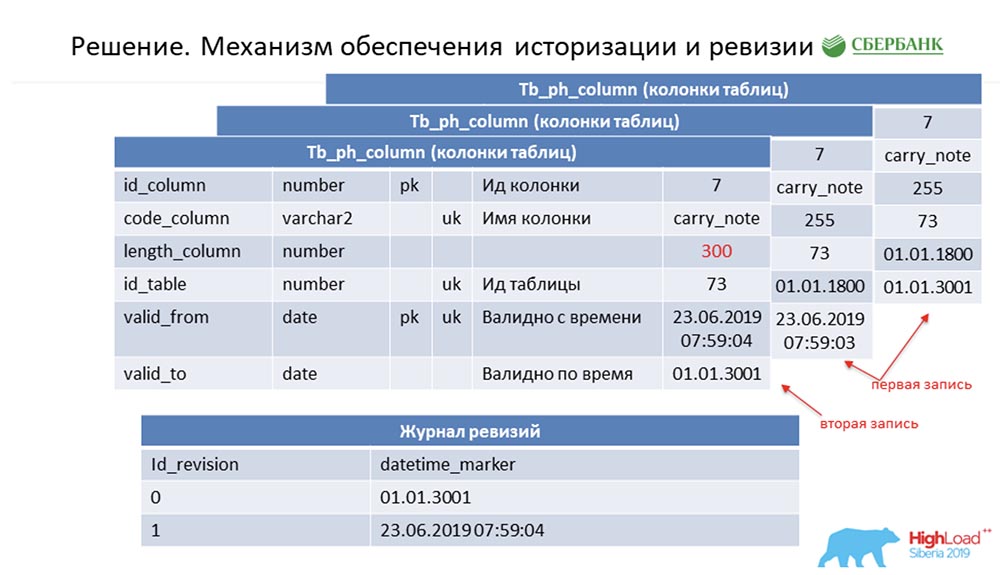 Tiene una identificación - "7", un nombre - carry_note, un enlace id_table 73 y un campo - 255. Ingresamos en la clave primaria y alternativa un campo (de tipo fecha) desde el punto de tiempo desde el cual esta entrada es válida - valid_from. Y un campo más: en qué fecha es válido este registro (valid_to). En este caso, se completan de forma predeterminada; está claro que esta entrada siempre es válida en principio. Y esto sucede hasta que queramos cambiar, digamos, la longitud del campo.Tan pronto como queramos hacer esto, cerramos el registro valid_to (arreglamos la marca de tiempo en la que ocurrió el evento). Al mismo tiempo, hacemos un nuevo registro ("300"). Es fácil notar que en esta situación, si observa la base de datos desde algún punto de tiempo por la "batalla" (entre) entre valid_from y valid_to, obtendremos un único registro, pero relevante en ese momento. Y al mismo tiempo, simultáneamente mantuvimos un registro de revisiones:
Tiene una identificación - "7", un nombre - carry_note, un enlace id_table 73 y un campo - 255. Ingresamos en la clave primaria y alternativa un campo (de tipo fecha) desde el punto de tiempo desde el cual esta entrada es válida - valid_from. Y un campo más: en qué fecha es válido este registro (valid_to). En este caso, se completan de forma predeterminada; está claro que esta entrada siempre es válida en principio. Y esto sucede hasta que queramos cambiar, digamos, la longitud del campo.Tan pronto como queramos hacer esto, cerramos el registro valid_to (arreglamos la marca de tiempo en la que ocurrió el evento). Al mismo tiempo, hacemos un nuevo registro ("300"). Es fácil notar que en esta situación, si observa la base de datos desde algún punto de tiempo por la "batalla" (entre) entre valid_from y valid_to, obtendremos un único registro, pero relevante en ese momento. Y al mismo tiempo, simultáneamente mantuvimos un registro de revisiones: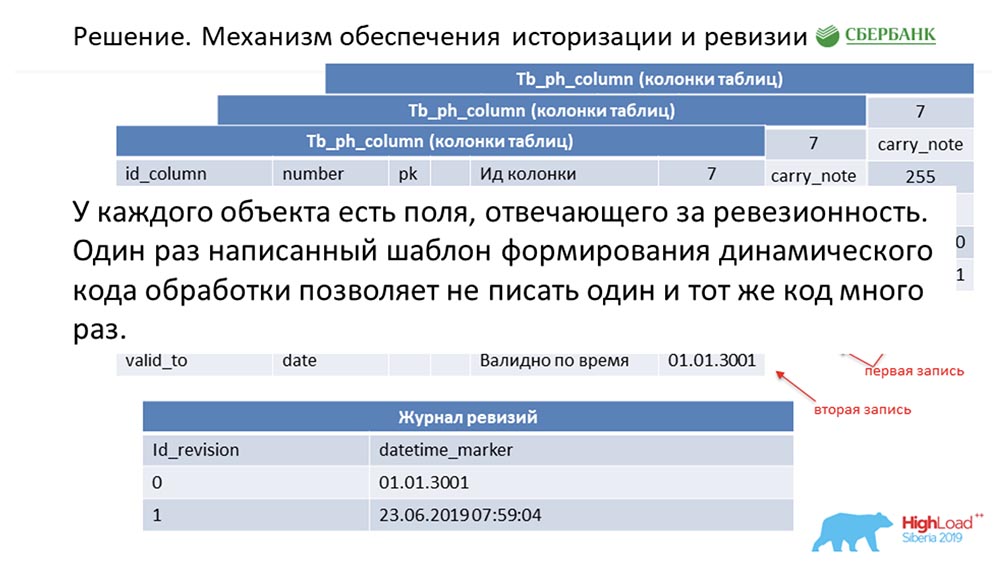 en él registramos revisiones que están aumentando en la identificación de secuencia (secuencia) y el punto de tiempo que corresponde a esta identificación de revisión. Entonces pudimos cerrar la primera demanda.C.A:- ¡Supongo que si! Aquí el enfoque es el mismo. Entendemos que cada objeto en el sistema tiene estos dos campos obligatorios, y una vez que nos confundimos, codificamos la lógica de procesamiento de esta plantilla, y luego (al generar el código dinámico) simplemente sustituimos los nombres de los objetos correspondientes. Por lo tanto, cada objeto en nuestro sistema se convierte en revisión, y todo esto puede procesarse; generalmente no escribimos una sola línea de código.
en él registramos revisiones que están aumentando en la identificación de secuencia (secuencia) y el punto de tiempo que corresponde a esta identificación de revisión. Entonces pudimos cerrar la primera demanda.C.A:- ¡Supongo que si! Aquí el enfoque es el mismo. Entendemos que cada objeto en el sistema tiene estos dos campos obligatorios, y una vez que nos confundimos, codificamos la lógica de procesamiento de esta plantilla, y luego (al generar el código dinámico) simplemente sustituimos los nombres de los objetos correspondientes. Por lo tanto, cada objeto en nuestro sistema se convierte en revisión, y todo esto puede procesarse; generalmente no escribimos una sola línea de código.Actualización por lotes
SC: - El segundo requisito para mí fue un poco más interesante. Honestamente, cuando se trataba de la entrada, al principio me entró un estupor. ¡Pero la decisión ha llegado!Les recuerdo que este es el mismo caso cuando, digamos, JSON con un paquete nos llegó por la enésima cantidad de objetos que deben insertarse en el sistema. Al mismo tiempo, al principio tenemos 10 columnas que se refieren a una tabla inexistente, y la tabla entró en la cola JSON. ¿Qué hacer? Encontramos una manera de utilizar el mecanismo de consultas jerárquicas recursivas: esta es sin duda la conexión conocida por construcción previa. Lo hicimos de la siguiente manera: aquí hay un fragmento de nuestro código de producción:
Encontramos una manera de utilizar el mecanismo de consultas jerárquicas recursivas: esta es sin duda la conexión conocida por construcción previa. Lo hicimos de la siguiente manera: aquí hay un fragmento de nuestro código de producción: En este punto (una sección de código encerrada en un óvalo rojo) es el punto principal que da una idea. Y aquí el objeto está vinculado a otro objeto vinculado por una clave externa, que está en el sistema.Para comprender: si alguien escribe código en Oracle, hay All_columns, All_all_ tables, All_constraint tables: este es el diccionario que procesan los scripts (como los que se muestran en la diapositiva anterior).En la salida, obtenemos campos que nos dan la prioridad de procesar objetos y, además, un descriptor: es esencialmente un identificador de cadena único para cualquier registro de metadatos. El código por el cual se recibe el descriptor también se indica en la diapositiva anterior.Por ejemplo, un campo: ¿cómo podría ser? Este es el código de la plataforma: oracle KP., Production. KP, my_scheme. KP, my_table. KP, etc., donde KP es el código de campo. Entonces habrá tal descriptor.AC: - ¿Cuáles son los problemas aquí? Tenemos objetos en el sistema y el orden de su inserción es muy importante para nosotros. Por ejemplo, no podemos insertar columnas delante de las tablas, porque una columna debe hacer referencia a una tabla específica. Como lo hacemos de manera estándar: primero insertamos las tablas, en respuesta obtenemos una matriz de id, por estos ID arrojamos las columnas y hacemos la segunda operación de inserción.En realidad, como mostró Stas, la longitud de esta cadena alcanza 8-9 objetos. El usuario, utilizando el enfoque estándar, necesita realizar todas estas operaciones a su vez (todas estas 9 operaciones) y comprender claramente su orden para que no ocurra ningún error.En la medida en que interprete correctamente a Stas, podemos transferir todos estos objetos al sistema en cualquier orden y no nos molestemos en cómo necesitamos hacer esta inserción: simplemente lanzamos un conjunto de sopa en el sistema, y todo determinó en qué orden insertar.Lo único que tengo es la pregunta: ¿qué pasa si insertamos el objeto por primera vez? Insertamos la tabla antes, no sabemos su id. ¿Cómo indicamos (un ejemplo puramente hipotético) que necesitamos insertar dos tablas, cada una de las cuales tiene una columna? ¿Cómo indicamos que en esta columna JSON se refiere a la tabla1, no a la tabla2?SC: - ¡Un descriptor! El identificador que indicamos en esa diapositiva (anterior).Y en esta diapositiva, se da la solución:
En este punto (una sección de código encerrada en un óvalo rojo) es el punto principal que da una idea. Y aquí el objeto está vinculado a otro objeto vinculado por una clave externa, que está en el sistema.Para comprender: si alguien escribe código en Oracle, hay All_columns, All_all_ tables, All_constraint tables: este es el diccionario que procesan los scripts (como los que se muestran en la diapositiva anterior).En la salida, obtenemos campos que nos dan la prioridad de procesar objetos y, además, un descriptor: es esencialmente un identificador de cadena único para cualquier registro de metadatos. El código por el cual se recibe el descriptor también se indica en la diapositiva anterior.Por ejemplo, un campo: ¿cómo podría ser? Este es el código de la plataforma: oracle KP., Production. KP, my_scheme. KP, my_table. KP, etc., donde KP es el código de campo. Entonces habrá tal descriptor.AC: - ¿Cuáles son los problemas aquí? Tenemos objetos en el sistema y el orden de su inserción es muy importante para nosotros. Por ejemplo, no podemos insertar columnas delante de las tablas, porque una columna debe hacer referencia a una tabla específica. Como lo hacemos de manera estándar: primero insertamos las tablas, en respuesta obtenemos una matriz de id, por estos ID arrojamos las columnas y hacemos la segunda operación de inserción.En realidad, como mostró Stas, la longitud de esta cadena alcanza 8-9 objetos. El usuario, utilizando el enfoque estándar, necesita realizar todas estas operaciones a su vez (todas estas 9 operaciones) y comprender claramente su orden para que no ocurra ningún error.En la medida en que interprete correctamente a Stas, podemos transferir todos estos objetos al sistema en cualquier orden y no nos molestemos en cómo necesitamos hacer esta inserción: simplemente lanzamos un conjunto de sopa en el sistema, y todo determinó en qué orden insertar.Lo único que tengo es la pregunta: ¿qué pasa si insertamos el objeto por primera vez? Insertamos la tabla antes, no sabemos su id. ¿Cómo indicamos (un ejemplo puramente hipotético) que necesitamos insertar dos tablas, cada una de las cuales tiene una columna? ¿Cómo indicamos que en esta columna JSON se refiere a la tabla1, no a la tabla2?SC: - ¡Un descriptor! El identificador que indicamos en esa diapositiva (anterior).Y en esta diapositiva, se da la solución: Los descriptores se usan en el sistema como una especie de campo mnemónico que no existe, pero que reemplaza a id. En ese momento, cuando al principio el sistema comprende que es necesario insertar la tabla - insert, recibirá id; y ya en la etapa de generar la consulta SQL para la inserción y la columna, operará en id. El usuario no puede tomar un baño de vapor: "¡Dale el mango y ejecuta!". El sistema lo hará.
Los descriptores se usan en el sistema como una especie de campo mnemónico que no existe, pero que reemplaza a id. En ese momento, cuando al principio el sistema comprende que es necesario insertar la tabla - insert, recibirá id; y ya en la etapa de generar la consulta SQL para la inserción y la columna, operará en id. El usuario no puede tomar un baño de vapor: "¡Dale el mango y ejecuta!". El sistema lo hará.Consulta universal sobre un grupo de objetos relacionados
Quizás mi caso favorito. Este es el requisito técnico favorito que teníamos. Vinieron a nosotros y dijeron: “¡Chicos, háganlo para que el sistema pueda hacer todo! De un objeto a otro, por favor. Adivina cómo todo se une entre ellos. Devuélvenos, JSON, por favor. No queremos programar mucho usando su servicio "...Pregunta:" ¿Cómo? "En realidad fuimos por el mismo camino. Exactamente la misma construcción: se utilizó para resolver este problema. La única diferencia es que había un filtro válido, que desenrollaba este árbol jerárquico solo para aquellas historias donde se requería un descriptor. Relativamente hablando, era único para cada objeto. Aquí, todas las conexiones posibles en el sistema no están retorcidas (tenemos unos 50 objetos).Todas las posibles conexiones entre objetos se preparan de antemano. Si tenemos un objeto involucrado en tres relaciones, respectivamente, se prepararán tres líneas para que el algoritmo pueda entender. Y tan pronto como nos llega la solicitud de JSON, vamos al lugar donde se preparó esta historia por adelantado en MeteMet, estamos buscando la forma en que la necesitamos. Si no encontramos, esta es una historia, si la encontramos, formamos una consulta en la base de datos. Ejecutando: devolviendo JSON (según lo solicitado).AC: - Como resultado, podemos transferir al sistema de qué objeto queremos recibir. Y si puede delinear una conexión clara entre dos objetos, entonces el sistema mismo determinará qué nivel de anidamiento le devolverá el objeto en el árbol:¡Es muy flexible! Una vez más, nuestros usuarios se encuentran en un estado de "turbulencia": hoy necesitan una cosa, mañana necesitan otra. Y esta solución nos permite adaptar la estructura de manera muy flexible. Estos fueron tres casos clave que se utilizaron en nuestro lado central.SC: - Resumamos algunos. Está claro que ahora no contaremos todas las fichas debido al tiempo limitado. Tres casos, en nuestra opinión, llevamos a cabo y contamos. Tuvimos éxito, pudimos poner toda la lógica más compleja, y la que debería funcionar de manera uniforme para cada objeto de gestión de metadatos, en el código del núcleo.No podríamos hacer que este código sea 100% dinámico, lo que significa que con cualquier objeto creado (no importa si ya se creó o se creará más tarde; lo principal es crearlo de acuerdo con las reglas), el sistema puede funcionar: no es necesario agregar nada, volver a escribirlo. Solo probar es suficiente. Aparcamos toda esta historia en tres métodos universales. En mi opinión, hay suficientes para resolver casi cualquier problema comercial:
se utilizó para resolver este problema. La única diferencia es que había un filtro válido, que desenrollaba este árbol jerárquico solo para aquellas historias donde se requería un descriptor. Relativamente hablando, era único para cada objeto. Aquí, todas las conexiones posibles en el sistema no están retorcidas (tenemos unos 50 objetos).Todas las posibles conexiones entre objetos se preparan de antemano. Si tenemos un objeto involucrado en tres relaciones, respectivamente, se prepararán tres líneas para que el algoritmo pueda entender. Y tan pronto como nos llega la solicitud de JSON, vamos al lugar donde se preparó esta historia por adelantado en MeteMet, estamos buscando la forma en que la necesitamos. Si no encontramos, esta es una historia, si la encontramos, formamos una consulta en la base de datos. Ejecutando: devolviendo JSON (según lo solicitado).AC: - Como resultado, podemos transferir al sistema de qué objeto queremos recibir. Y si puede delinear una conexión clara entre dos objetos, entonces el sistema mismo determinará qué nivel de anidamiento le devolverá el objeto en el árbol:¡Es muy flexible! Una vez más, nuestros usuarios se encuentran en un estado de "turbulencia": hoy necesitan una cosa, mañana necesitan otra. Y esta solución nos permite adaptar la estructura de manera muy flexible. Estos fueron tres casos clave que se utilizaron en nuestro lado central.SC: - Resumamos algunos. Está claro que ahora no contaremos todas las fichas debido al tiempo limitado. Tres casos, en nuestra opinión, llevamos a cabo y contamos. Tuvimos éxito, pudimos poner toda la lógica más compleja, y la que debería funcionar de manera uniforme para cada objeto de gestión de metadatos, en el código del núcleo.No podríamos hacer que este código sea 100% dinámico, lo que significa que con cualquier objeto creado (no importa si ya se creó o se creará más tarde; lo principal es crearlo de acuerdo con las reglas), el sistema puede funcionar: no es necesario agregar nada, volver a escribirlo. Solo probar es suficiente. Aparcamos toda esta historia en tres métodos universales. En mi opinión, hay suficientes para resolver casi cualquier problema comercial:- en primer lugar, este mismo "actualizador" universal es un método que puede actualizar / insertar / eliminar (eliminar es cerrar un registro) en uno o un grupo de objetos transferidos en orden aleatorio.
- el segundo es un método que puede devolver información universal sobre un solo objeto;
- el tercero es el mismo método que puede devolver Información de unión conectada por grupos de objetos.
Así resultó, e hicimos el núcleo. Y luego pasaremos a tu parte favorita.Punto de entrada de la aplicación
AC: Sí, esta es mi parte favorita, porque esta es mi área de responsabilidad: Servidor de aplicaciones. Para comprender en qué situación me encontraba, intentaré meterte nuevamente en un problema.Stas hizo un buen trabajo y me pasó estos tres métodos estándar que manipulaban estos objetos. Esta es una descripción puramente esquemática: en realidad, hay muchas más: volvamos al principio para sumergirlo ... ¿Cómo se presentarán aquí los metadatos en el sistema?
volvamos al principio para sumergirlo ... ¿Cómo se presentarán aquí los metadatos en el sistema?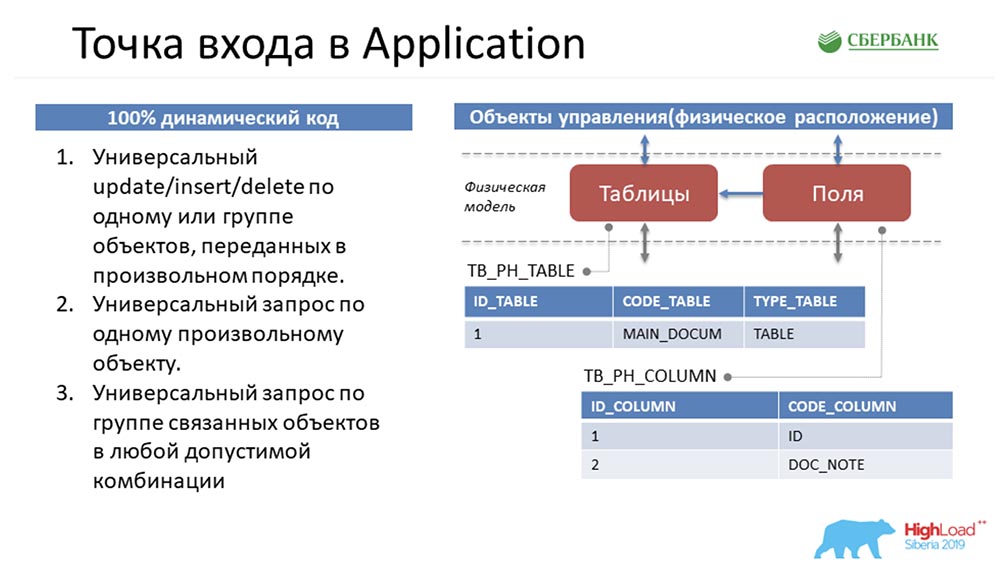 Si vemos que hay una tabla en el entorno, caerá en nuestro sistema como un registro en el objeto de tabla y un par de registros en el objeto de campo. Esencialmente, hemos creado una estructura.Podemos notar que la cantidad de estos objetos es diferente. Luego, para manipular estos objetos, para llevar todo a una estructura universal, de modo que los tres métodos entiendan lo que se está discutiendo, Stas hace un movimiento con el caballo. Toma y voltea todos los objetos, es decir, representa cualquier objeto en nuestro sistema de gestión de metadatos como cuatro líneas:
Si vemos que hay una tabla en el entorno, caerá en nuestro sistema como un registro en el objeto de tabla y un par de registros en el objeto de campo. Esencialmente, hemos creado una estructura.Podemos notar que la cantidad de estos objetos es diferente. Luego, para manipular estos objetos, para llevar todo a una estructura universal, de modo que los tres métodos entiendan lo que se está discutiendo, Stas hace un movimiento con el caballo. Toma y voltea todos los objetos, es decir, representa cualquier objeto en nuestro sistema de gestión de metadatos como cuatro líneas: dado que cualquier objeto en nuestro sistema de gestión de metadatos es físicamente una tabla, cualquier objeto puede descomponerse de acuerdo con estos cuatro signos: número de línea , tabla, campo y valor de campo. Fue Stas quien se le ocurrió todo esto, y necesitaba implementarlo de alguna manera y dárselo a los usuarios.CAROLINA DEL SUR:- Lo siento, pero ¿cómo puedo transmitirle en una columna de respuesta plana, por ejemplo, que aún no se ha creado, se creará alguna vez, y Dios sabe lo que puede ser? Por lo tanto, la única opción en las condiciones del código dinámico es configurar la interacción entre núcleo y aplicación, para transmitirle esta información, solo como la vemos. Creo que, desde mi punto de vista, esta decisión fue ingeniosa, porque vino solo de ti.AC: - Ahora no discutiremos sobre esto. Dos semanas antes del final de la fecha límite, me quedé con el hecho de que tenía estos tres métodos en mis manos (a la izquierda en la diapositiva anterior) que manipulaban la estructura universal (a la derecha en la misma diapositiva).Mi primer pensamiento fue simplemente envolver todo a nivel API e ir al usuario con esto, diciendo: “¡Mira, qué cosa más brillante! ¡Tu puedes hacer cualquier cosa! Transfiera cualquier objeto, o incluso los inexistentes. Genial, sí "?!
dado que cualquier objeto en nuestro sistema de gestión de metadatos es físicamente una tabla, cualquier objeto puede descomponerse de acuerdo con estos cuatro signos: número de línea , tabla, campo y valor de campo. Fue Stas quien se le ocurrió todo esto, y necesitaba implementarlo de alguna manera y dárselo a los usuarios.CAROLINA DEL SUR:- Lo siento, pero ¿cómo puedo transmitirle en una columna de respuesta plana, por ejemplo, que aún no se ha creado, se creará alguna vez, y Dios sabe lo que puede ser? Por lo tanto, la única opción en las condiciones del código dinámico es configurar la interacción entre núcleo y aplicación, para transmitirle esta información, solo como la vemos. Creo que, desde mi punto de vista, esta decisión fue ingeniosa, porque vino solo de ti.AC: - Ahora no discutiremos sobre esto. Dos semanas antes del final de la fecha límite, me quedé con el hecho de que tenía estos tres métodos en mis manos (a la izquierda en la diapositiva anterior) que manipulaban la estructura universal (a la derecha en la misma diapositiva).Mi primer pensamiento fue simplemente envolver todo a nivel API e ir al usuario con esto, diciendo: “¡Mira, qué cosa más brillante! ¡Tu puedes hacer cualquier cosa! Transfiera cualquier objeto, o incluso los inexistentes. Genial, sí "?! Y dicen: “¿Pero entiendes que tu servicio no está especializado en absoluto? Como usuario, no entiendo qué objetos puedo transferir al sistema, cómo puedo manipularlos ... Para mí es un recuadro negro, generalmente tengo miedo de enviar datos; Puedo estar equivocado, tengo miedo. Haz que pueda seguir claramente las instrucciones y ver qué objetos hay en el sistema y qué métodos de manipulación puedo usar ".
Y dicen: “¿Pero entiendes que tu servicio no está especializado en absoluto? Como usuario, no entiendo qué objetos puedo transferir al sistema, cómo puedo manipularlos ... Para mí es un recuadro negro, generalmente tengo miedo de enviar datos; Puedo estar equivocado, tengo miedo. Haz que pueda seguir claramente las instrucciones y ver qué objetos hay en el sistema y qué métodos de manipulación puedo usar ".Partícula. Un acercamiento
Luego nos quedó claro que era genial hacer una especificación para nuestro servicio. En resumen, para hacer una lista de objetos de nuestro sistema, una lista de puntos, manipulaciones y qué objetos hacen malabares entre sí. Dio la casualidad de que en nuestra empresa utilizamos Swagger para estos fines como algún tipo de solución arquitectónica. Después de mirar la estructura Swagger, me di cuenta de que necesitaba llevar a algún lado la estructura de los objetos que están en el sistema. Del núcleo, recibí solo tres métodos estándar y un cambiador de tabla. Nada más. Para mí, me pareció una tarea imposible obtener toda la estructura que está en el repositorio de estos cuatro campos estándar. Sinceramente, no entendí dónde conseguirme todas las descripciones de los objetos, todos los valores permitidos, toda la lógica ...SC:- ¿Qué significa dónde? Usted y yo tenemos MetaMeta, que proporciona el núcleo en modo de tiempo real. El núcleo en ejecución en tiempo real genera una consulta SQL que se comunica con la base de datos. Todo está ahí, no solo lo que necesitas. También hay enlaces entre objetos.AC: - Siguiendo el consejo de Stas, fui a MetaMetu y me sorprendió, porque todo el kit de caballeros necesario para generar especificaciones estándar estaba presente allí. Luego surgió la idea de que necesita crear una plantilla y pintar todo de acuerdo con siete escenarios posibles: 7 API estándar para cada objeto.
Después de mirar la estructura Swagger, me di cuenta de que necesitaba llevar a algún lado la estructura de los objetos que están en el sistema. Del núcleo, recibí solo tres métodos estándar y un cambiador de tabla. Nada más. Para mí, me pareció una tarea imposible obtener toda la estructura que está en el repositorio de estos cuatro campos estándar. Sinceramente, no entendí dónde conseguirme todas las descripciones de los objetos, todos los valores permitidos, toda la lógica ...SC:- ¿Qué significa dónde? Usted y yo tenemos MetaMeta, que proporciona el núcleo en modo de tiempo real. El núcleo en ejecución en tiempo real genera una consulta SQL que se comunica con la base de datos. Todo está ahí, no solo lo que necesitas. También hay enlaces entre objetos.AC: - Siguiendo el consejo de Stas, fui a MetaMetu y me sorprendió, porque todo el kit de caballeros necesario para generar especificaciones estándar estaba presente allí. Luego surgió la idea de que necesita crear una plantilla y pintar todo de acuerdo con siete escenarios posibles: 7 API estándar para cada objeto.Partícula. OEA + Manillares
Por lo tanto, es fácil notar en qué consiste la especificación: puede ir al sitio web de la OEA y a los Manillares (en la parte inferior de la diapositiva) y ver en qué debe consistir: hay un conjunto de puntos finales, un conjunto de métodos y al final hay modelos. El código se repite de vez en cuando. Para cada objeto, debemos escribir get, put. Eliminar; para un grupo de objetos, debemos escribir esto y así sucesivamente.El truco consistía en escribir toda la historia una vez y ya no bañarse. La diapositiva muestra un ejemplo de código real. Los objetos azules son etiquetas en los manillares, este es un motor de plantillas; bastante flexible, aconsejo a todos: puede personalizarlo usted mismo, escribir manejadores de etiquetas personalizadas ...En lugar de estas etiquetas azules, cuando esta plantilla se ejecuta sobre todos los metadatos, se sustituyen todas las propiedades significativas: el nombre del objeto, su descripción, algún tipo de lógica (por ejemplo, que necesitamos agregar un parámetro adicional, dependiendo de la propiedad), etc. Al final hay un enlace al modelo que está interpretando.
puede ir al sitio web de la OEA y a los Manillares (en la parte inferior de la diapositiva) y ver en qué debe consistir: hay un conjunto de puntos finales, un conjunto de métodos y al final hay modelos. El código se repite de vez en cuando. Para cada objeto, debemos escribir get, put. Eliminar; para un grupo de objetos, debemos escribir esto y así sucesivamente.El truco consistía en escribir toda la historia una vez y ya no bañarse. La diapositiva muestra un ejemplo de código real. Los objetos azules son etiquetas en los manillares, este es un motor de plantillas; bastante flexible, aconsejo a todos: puede personalizarlo usted mismo, escribir manejadores de etiquetas personalizadas ...En lugar de estas etiquetas azules, cuando esta plantilla se ejecuta sobre todos los metadatos, se sustituyen todas las propiedades significativas: el nombre del objeto, su descripción, algún tipo de lógica (por ejemplo, que necesitamos agregar un parámetro adicional, dependiendo de la propiedad), etc. Al final hay un enlace al modelo que está interpretando.Código de solicitud Swagger Codegen + Manillar
Todo esto lo codificamos, grabamos, inventamos una especificación. Todo fue muy bueno y genial. Tenemos los 7 escenarios posibles para cada objeto.Se lo dio al usuario. Él dijo: "¡Guau! ¡Frio! ¡Ahora queremos usarlo! ” ¿Cuál es el problema, de nuevo?Tenemos una especificación que describe cada método en detalle, qué hacer con él, qué objetos manipular. Y hay tres métodos de kernel estándar que toman la tabla invertida descrita anteriormente como entrada.Entonces solo tenía que cruzar uno con el otro (ahora me parece fácil). Es decir, cuando un usuario llama a un método en la interfaz, teníamos que reenviarlo correctamente al núcleo, convirtiendo el modelo (donde tenemos especificaciones hermosas) en estos cuatro campos estándar. Eso fue todo lo que había que hacer. Para poner todo esto en práctica, necesitábamos transformaciones "nominativas" ...
Para poner todo esto en práctica, necesitábamos transformaciones "nominativas" ...Conversiones
Swagger inicialmente tiene una herramienta de este tipo: Swagger Codegen. Si alguna vez entró en las especificaciones, inventado, entonces hay un botón "Generar parte del servidor". Haga clic, elija un idioma: se generará un proyecto terminado para usted.Se genera notablemente: hay todas las descripciones de clase, todas las descripciones de punto final ... funciona. Puede ejecutarlo localmente, funcionará. El problema es uno: devuelve apéndices; cada método no se incrementa.La idea era agregar lógica basada en estos siete escenarios en el generador de código: "estropear" una de las plantillas estándar, configurarla usted mismo. Aquí hay un ejemplo de código real que usamos en el motor de plantillas y una lista de las acciones que necesitábamos realizar para configurar este generador de código para nosotros mismos: Lo más importante que hicieron fue conectar las bibliotecas necesarias, escribir clases para comunicarse con el núcleo e interpretar (según el escenario) la llamada de uno o más métodos en el lado del núcleo. El modelo también se entregó: del hermoso indicado en la especificación a cuatro campos, y luego se transformó nuevamente.Probablemente el caso más difícil aquí fue darle al usuario un árbol, porque el núcleo también nos devuelve cuatro líneas: ve y mira en qué nivel se encuentra la jerarquía. Utilizamos el mecanismo de relaciones externas, que está en el IDE, es decir, fuimos a MetaMetu, observamos todos los caminos de uno a otro y generamos dinámicamente un árbol a través de ellos. El usuario puede pedirnos desde cualquier objeto lo que quiera: se le devolverá un hermoso árbol a la salida, en el que todo ya está estructurado.SC: - Te detendré por un segundo, porque ya estoy empezando a perderme. Te preguntaré al estilo de "¿Entiendo eso correctamente? ...Quiere decir que hemos calculado todos los códigos más complejos y complejos que tendrían que escribirse para algún objeto nuevo. Y para ahorrar tiempo, no para hacerlo, logramos meter todo en el núcleo y hacer que esta historia sea dinámica ... Pero esta API (como bromearon, "obstinada") es tan "cualquier cosa" que da miedo darla a conocer: abordar de manera ineficiente con él, puedes corromper los metadatos. Esto es por un lado.Por otro lado, nos dimos cuenta de que no podemos comunicarnos con nuestros clientes clientes a menos que les demos una API, que será una proyección única de los objetos de gestión de metadatos que están incrustados en el sistema (de hecho, ejecutamos un cierto contrato para nuestro servicio). Parece que todo, golpeamos: si el objeto no está allí, todavía no está allí, y cuando aparece, aparece la extensión del contrato, ya un nuevo código.Parece que nos hemos metido en la codificación manual evitable, pero aquí propone hacer este código por botón. Nuevamente, logramos escapar de la historia cuando necesitamos escribir algo con nuestras manos. ¿Esto es verdad?AC: Sí, realmente lo es. En general, mi idea era comenzar a programar de una vez por todas, al menos con la ayuda de motores de plantillas. Escriba el código una vez y luego relájese. E incluso si aparece un nuevo objeto en el sistema: con el botón que iniciamos la actualización, todo está ajustado, tenemos una nueva estructura, se generan nuevos métodos, todo está bien y bien.
Lo más importante que hicieron fue conectar las bibliotecas necesarias, escribir clases para comunicarse con el núcleo e interpretar (según el escenario) la llamada de uno o más métodos en el lado del núcleo. El modelo también se entregó: del hermoso indicado en la especificación a cuatro campos, y luego se transformó nuevamente.Probablemente el caso más difícil aquí fue darle al usuario un árbol, porque el núcleo también nos devuelve cuatro líneas: ve y mira en qué nivel se encuentra la jerarquía. Utilizamos el mecanismo de relaciones externas, que está en el IDE, es decir, fuimos a MetaMetu, observamos todos los caminos de uno a otro y generamos dinámicamente un árbol a través de ellos. El usuario puede pedirnos desde cualquier objeto lo que quiera: se le devolverá un hermoso árbol a la salida, en el que todo ya está estructurado.SC: - Te detendré por un segundo, porque ya estoy empezando a perderme. Te preguntaré al estilo de "¿Entiendo eso correctamente? ...Quiere decir que hemos calculado todos los códigos más complejos y complejos que tendrían que escribirse para algún objeto nuevo. Y para ahorrar tiempo, no para hacerlo, logramos meter todo en el núcleo y hacer que esta historia sea dinámica ... Pero esta API (como bromearon, "obstinada") es tan "cualquier cosa" que da miedo darla a conocer: abordar de manera ineficiente con él, puedes corromper los metadatos. Esto es por un lado.Por otro lado, nos dimos cuenta de que no podemos comunicarnos con nuestros clientes clientes a menos que les demos una API, que será una proyección única de los objetos de gestión de metadatos que están incrustados en el sistema (de hecho, ejecutamos un cierto contrato para nuestro servicio). Parece que todo, golpeamos: si el objeto no está allí, todavía no está allí, y cuando aparece, aparece la extensión del contrato, ya un nuevo código.Parece que nos hemos metido en la codificación manual evitable, pero aquí propone hacer este código por botón. Nuevamente, logramos escapar de la historia cuando necesitamos escribir algo con nuestras manos. ¿Esto es verdad?AC: Sí, realmente lo es. En general, mi idea era comenzar a programar de una vez por todas, al menos con la ayuda de motores de plantillas. Escriba el código una vez y luego relájese. E incluso si aparece un nuevo objeto en el sistema: con el botón que iniciamos la actualización, todo está ajustado, tenemos una nueva estructura, se generan nuevos métodos, todo está bien y bien.Tuning MetaMeta
Para mejorar aún más nuestro servicio, enriquecimos el MetaMeta estándar. En la entrada, teníamos lo que quedaba del núcleo. También agregamos una descripción adicional a los objetos, los objetos se agrupan en áreas. Mostramos todo esto en la especificación para que el usuario entienda lo que está manipulando y con qué objeto se está comunicando actualmente.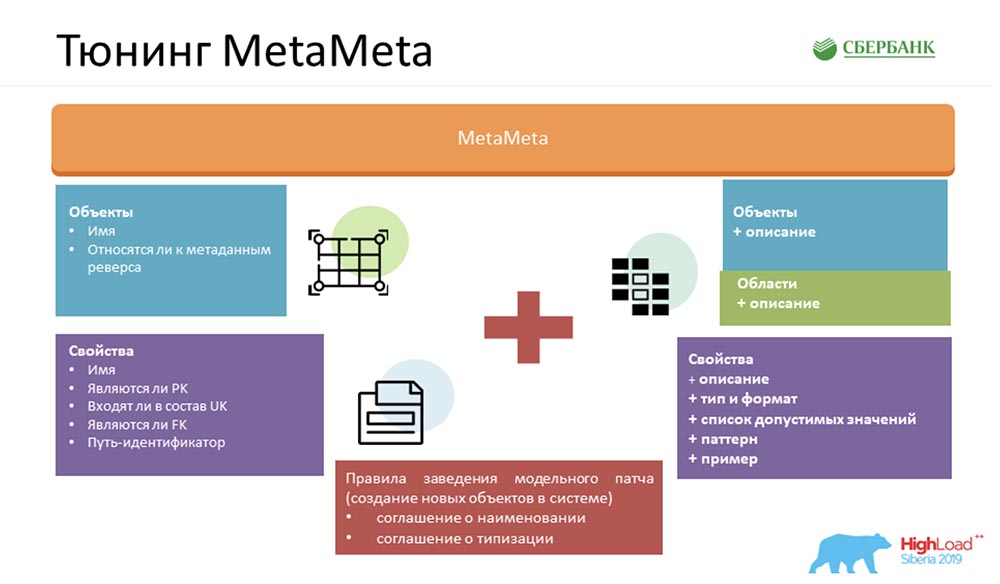 Solo agregamos algunas pequeñas cosas allí: tipos, formatos, listas de valores aceptables, patrones, ejemplos. Esto también agrada a los usuarios: ya entienden claramente qué se puede insertar, qué no. También proporcionamos un artefacto de cliente al usuario, que nos permite detectar errores al comunicarnos con nuestro servicio (precisamente por formato, ya en la etapa de compilación).Pero lo más importante, para que toda esta magia funcione, teníamos que estar de acuerdo en el interior: crear un conjunto de ciertas reglas. No hay muchos, conté tres (hay dos en la diapositiva, por lo que habrá que recordar uno):
Solo agregamos algunas pequeñas cosas allí: tipos, formatos, listas de valores aceptables, patrones, ejemplos. Esto también agrada a los usuarios: ya entienden claramente qué se puede insertar, qué no. También proporcionamos un artefacto de cliente al usuario, que nos permite detectar errores al comunicarnos con nuestro servicio (precisamente por formato, ya en la etapa de compilación).Pero lo más importante, para que toda esta magia funcione, teníamos que estar de acuerdo en el interior: crear un conjunto de ciertas reglas. No hay muchos, conté tres (hay dos en la diapositiva, por lo que habrá que recordar uno):- Convenio de denominación. Específicamente nombramos objetos en el sistema para facilitar el reconocimiento de escenarios para su uso posterior.
- Acuerdo de mecanografía. Esto es para determinar correctamente los tipos, formatos y que pelearon entre el kernel y el servidor de aplicaciones, utilizamos el sistema de verificación, por el cual entendemos a qué formato pertenece una propiedad en particular.
- Claves foráneas válidas. Si el objeto recibe un enlace no válido a otro objeto, toda esta magia funcionará incorrectamente.
Resultado
SC: - Es genial, pero mucha teoría. ¿Puedes dar algún ejemplo práctico?AC: - Sí, lo preparé especialmente. Antes de partir para la conferencia, el viernes por la noche, literalmente 5 minutos antes del final de la jornada laboral, Stas me dijo: “¡Oh, mira! Lancé un parche modelo, ¡qué genial! Sería bueno actualizar nuestro servicio ". El parche contenía solo dos objetos, pero entiendo que con el enfoque anterior tendría que confundirme y escribir o agregar 7 API.Inmediatamente solo tuve que hacer clic en un botón para hacer que toda esta magia funcionara. Especialmente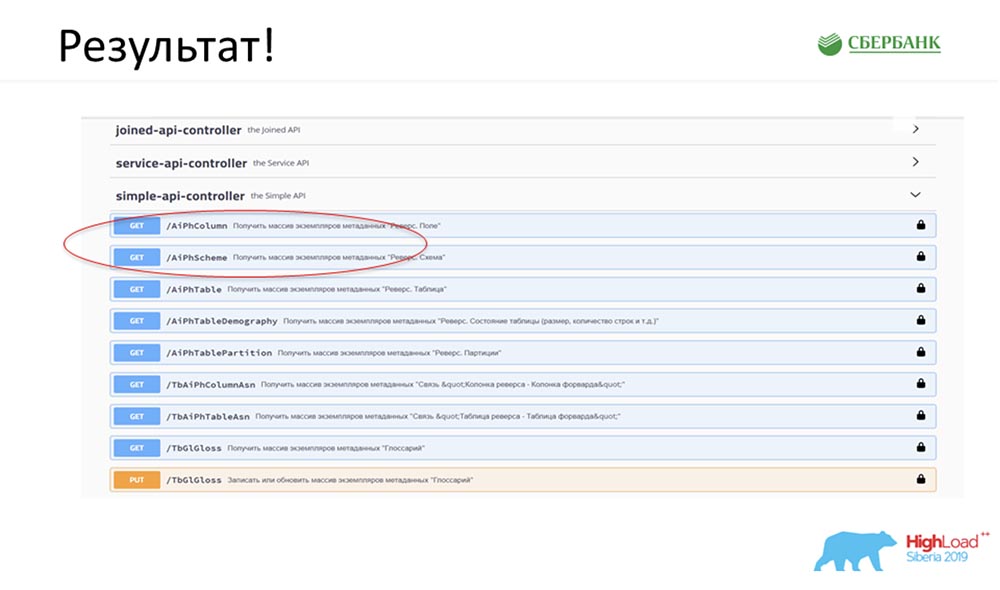 encerré en un círculo rojo el lugar donde está a punto de ocurrir la magia: hago clic en el botón ... Estas son, por supuesto, capturas de pantalla, pero en realidad todo funciona así:
encerré en un círculo rojo el lugar donde está a punto de ocurrir la magia: hago clic en el botón ... Estas son, por supuesto, capturas de pantalla, pero en realidad todo funciona así: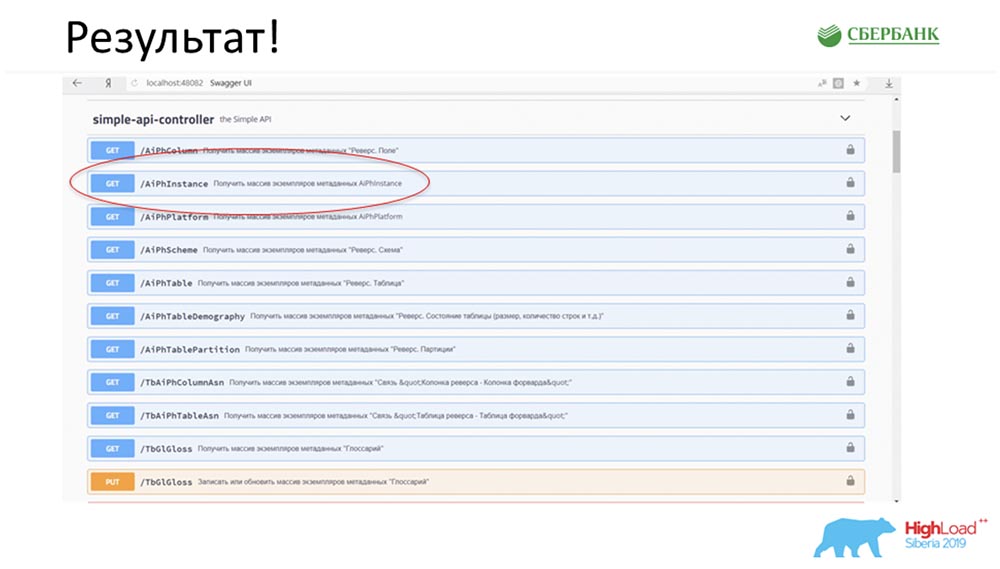 Tenemos un nuevo método (entre los dos) que ya proporciona datos, mediante el cual en la jerarquía podemos consultar toda la estructura, todos los objetos anidados: ¡
Tenemos un nuevo método (entre los dos) que ya proporciona datos, mediante el cual en la jerarquía podemos consultar toda la estructura, todos los objetos anidados: ¡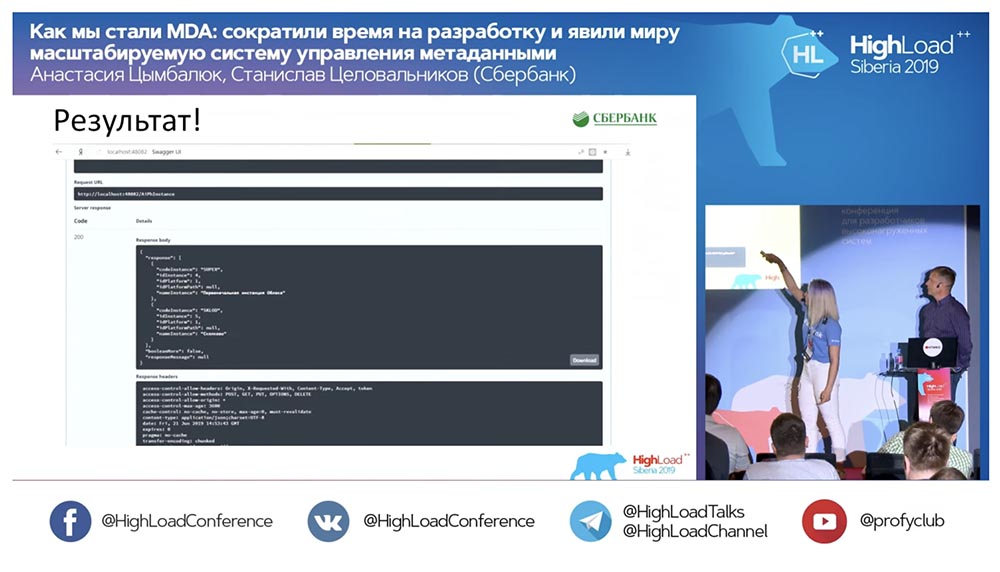
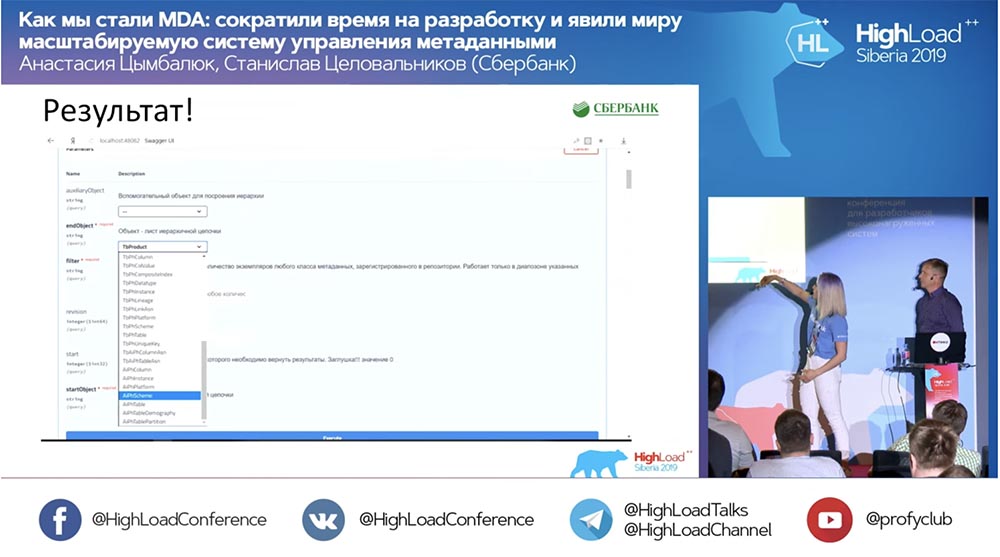
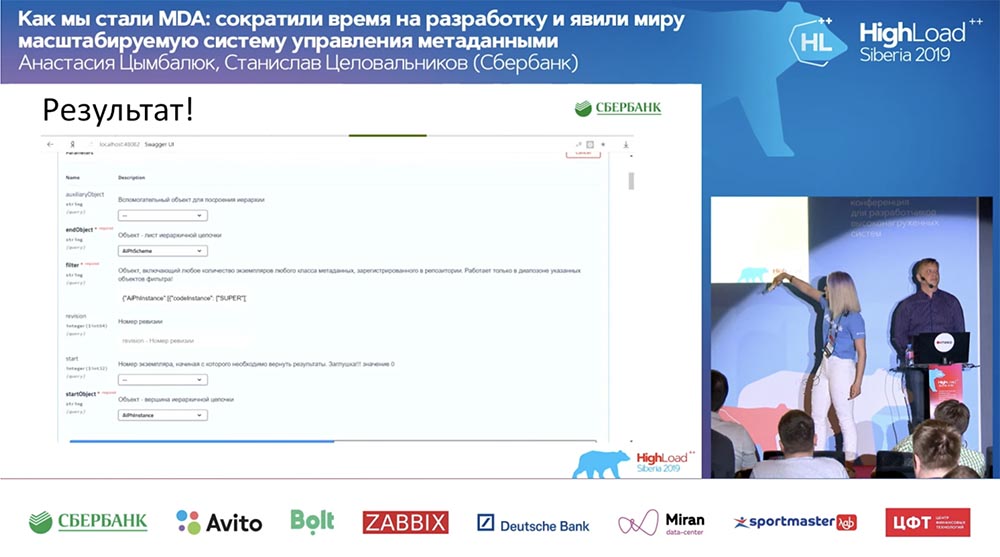 y todo funciona! No he escrito una sola línea de código en absoluto.
y todo funciona! No he escrito una sola línea de código en absoluto.Resumen
SC: - En primer lugar, ¿cuál es el hecho? Gestionamos la lógica más compleja, que llevaría a nuestros programadores la mayor parte del tiempo, empacar en un código de kernel 100% dinámico que pueda funcionar con objetos, los que son y los que serán: en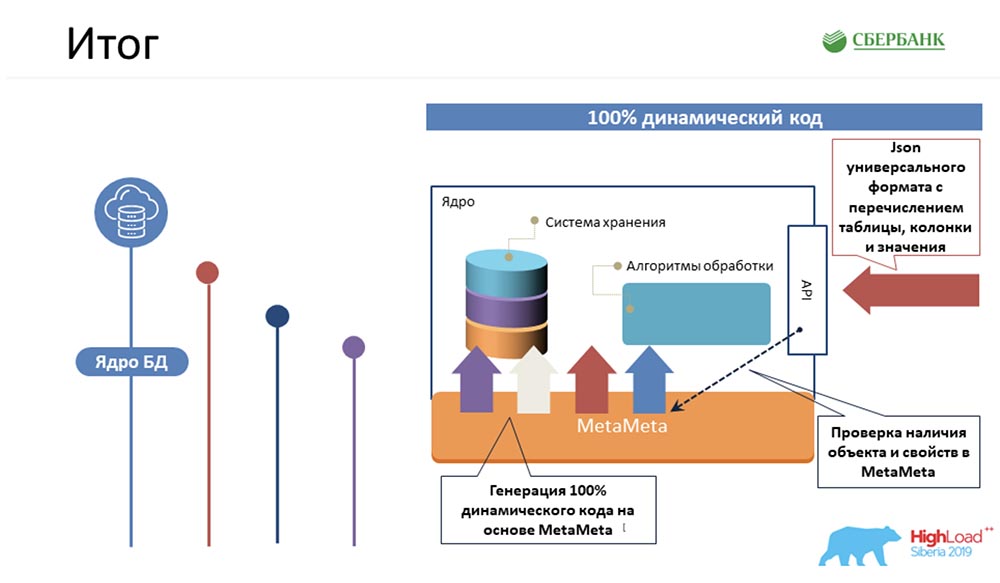 segundo lugar, logramos el nivel del servidor de aplicaciones (donde no es posible) para evitar también la programación debido a la generación de código: el mismo botón que demostró:
segundo lugar, logramos el nivel del servidor de aplicaciones (donde no es posible) para evitar también la programación debido a la generación de código: el mismo botón que demostró: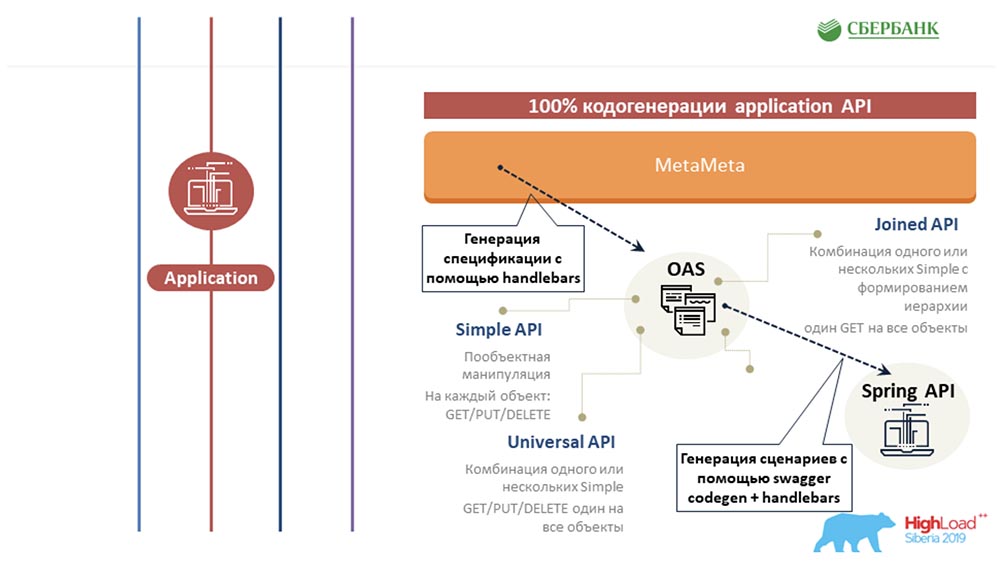 AC: - Intentamos extender el mismo enfoque basado en metadatos a otras áreas, al área de prueba. También escribimos una plantilla una vez para algún objeto, inserte etiquetas allí. Y cuando esta plantilla se ejecuta a lo largo de los metadatos, genera una hoja terminada con todos los escenarios de prueba, es decir, cubrimos todos los objetos con pruebas.
AC: - Intentamos extender el mismo enfoque basado en metadatos a otras áreas, al área de prueba. También escribimos una plantilla una vez para algún objeto, inserte etiquetas allí. Y cuando esta plantilla se ejecuta a lo largo de los metadatos, genera una hoja terminada con todos los escenarios de prueba, es decir, cubrimos todos los objetos con pruebas.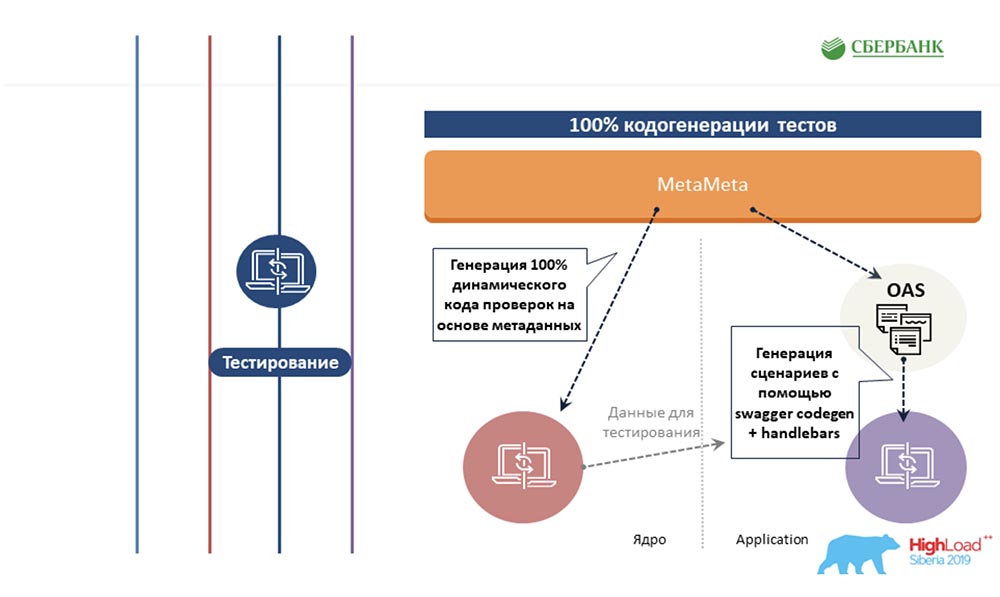 El siguiente es la cereza en el pastel. Sé que a pocas personas les gusta documentar lo que hacen. También resolvimos este dolor basado en metadatos. Una vez que preparamos una plantilla con marcado html, la etiquetamos. Y cuando revisamos los metadatos, todas estas etiquetas se sustituyen con sus propiedades correspondientes a los objetos.
El siguiente es la cereza en el pastel. Sé que a pocas personas les gusta documentar lo que hacen. También resolvimos este dolor basado en metadatos. Una vez que preparamos una plantilla con marcado html, la etiquetamos. Y cuando revisamos los metadatos, todas estas etiquetas se sustituyen con sus propiedades correspondientes a los objetos. El resultado es una hermosa página html terminada. Luego publicamos en Confluence, y podemos ofrecer a nuestros usuarios un formato legible para que puedan ver lo que tenemos en el sistema, cómo trabajar con él, una descripción mínima, valores aceptables, propiedades requeridas, claves ... Todos pueden hacer esto ver y puede resolverlo con bastante facilidad.Como resultado, tenemos cuatro puntos principales, y este enfoque se llama MDA (Model Driven Architecture). Por alguna razón, esto se traduce como "arquitectura basada en modelos", aunque yo lo llamaría un "método de desarrollo de software".
El resultado es una hermosa página html terminada. Luego publicamos en Confluence, y podemos ofrecer a nuestros usuarios un formato legible para que puedan ver lo que tenemos en el sistema, cómo trabajar con él, una descripción mínima, valores aceptables, propiedades requeridas, claves ... Todos pueden hacer esto ver y puede resolverlo con bastante facilidad.Como resultado, tenemos cuatro puntos principales, y este enfoque se llama MDA (Model Driven Architecture). Por alguna razón, esto se traduce como "arquitectura basada en modelos", aunque yo lo llamaría un "método de desarrollo de software". ¿Cual es el punto? Creas un modelo, acuerdas ciertas reglas. Luego crea patrones de transformación una vez de este modelo en algún lenguaje de programación disponible para usted. Todo esto funciona para cambiar objetos viejos, para agregar nuevos. Escribes el código una vez y ya no te molestas.SC: - Honestamente esperé todo el informe cuando respondiste esta pregunta. Pasemos a mis diapositivas favoritas.
¿Cual es el punto? Creas un modelo, acuerdas ciertas reglas. Luego crea patrones de transformación una vez de este modelo en algún lenguaje de programación disponible para usted. Todo esto funciona para cambiar objetos viejos, para agregar nuevos. Escribes el código una vez y ya no te molestas.SC: - Honestamente esperé todo el informe cuando respondiste esta pregunta. Pasemos a mis diapositivas favoritas.Decisión. Proceso. antes de
AC: - “El proceso. Antes ", este es nuestro orgullo, porque solíamos programar mucho, no comíamos casi nada, éramos muy malvados. Tuve que realizar todos estos 5 pasos para cada objeto: fue muy triste y nos llevó mucho tiempo. Ahora hemos reducido esta cadena alimentaria a tres enlaces, el más importante de los cuales es simplemente crear correctamente el objeto, y nada más:
fue muy triste y nos llevó mucho tiempo. Ahora hemos reducido esta cadena alimentaria a tres enlaces, el más importante de los cuales es simplemente crear correctamente el objeto, y nada más: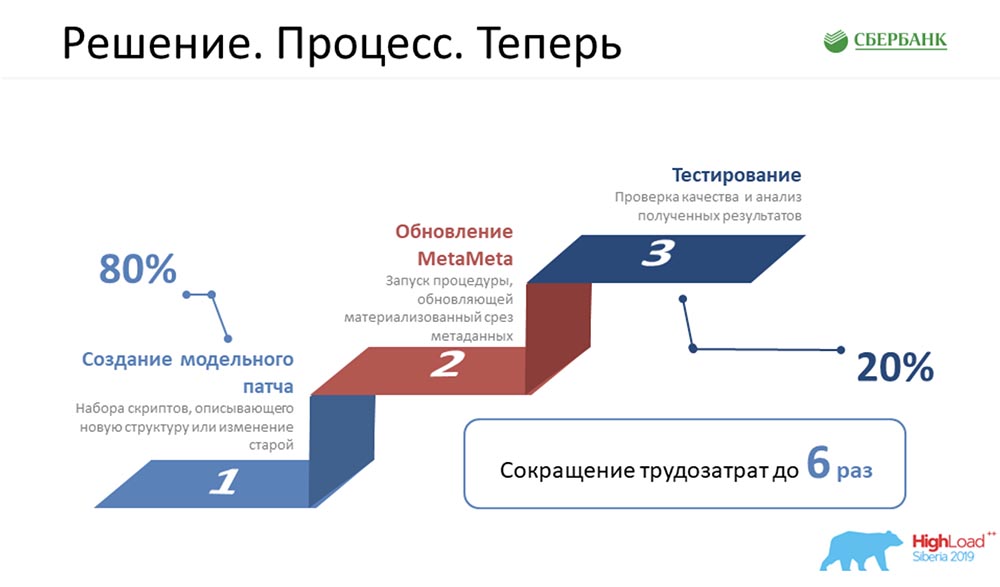 MetaMeta se inicia mediante un botón (actualización), luego prueba. Actualmente estamos buscando asegurarnos de que nada se nos caiga, ya que recientemente comenzamos a aplicar este enfoque. Estamos tratando de controlar todo este proceso.Según las estimaciones, todos nuestros costos laborales para el desarrollo de todo nuestro software se han reducido en 6 veces.CAROLINA DEL SUR:- Por mi parte, quiero decir sinceramente que el número 6 no está volado, incluso es conservador. De hecho, la eficiencia es aún mayor.
MetaMeta se inicia mediante un botón (actualización), luego prueba. Actualmente estamos buscando asegurarnos de que nada se nos caiga, ya que recientemente comenzamos a aplicar este enfoque. Estamos tratando de controlar todo este proceso.Según las estimaciones, todos nuestros costos laborales para el desarrollo de todo nuestro software se han reducido en 6 veces.CAROLINA DEL SUR:- Por mi parte, quiero decir sinceramente que el número 6 no está volado, incluso es conservador. De hecho, la eficiencia es aún mayor.Planes futuros
Usted solicitó al final del informe que reflexione sobre nuestros planes. En primer lugar, parece que debemos lograr no solo una solución completa, sino alienada y en caja. Estas tecnologías se pueden aplicar en algún lugar cercano, donde sea apropiado. Me gustaría lograr un producto terminado que se desarrolle y que podamos ofrecer en nombre de Sberbank.Por supuesto, si hablamos de tareas inmediatas, todas se muestran en las diapositivas con viñetas. A pesar de la optimización que recibimos, la carga en el equipo sigue siendo bastante grave. No puedo decir con certeza desde qué trimestre podemos pasar a la implementación de estos pasos.Número 6 y el caso que trajo Nastya, son honestos. Realmente fue el viernes, cuando necesitábamos obtener documentos (avión, viaje, etc.). El equipo adyacente estaba programado para las pruebas el lunes, y necesitábamos lanzar este parche, no configurar a los chicos. ¡Funcionó! Este es un caso real.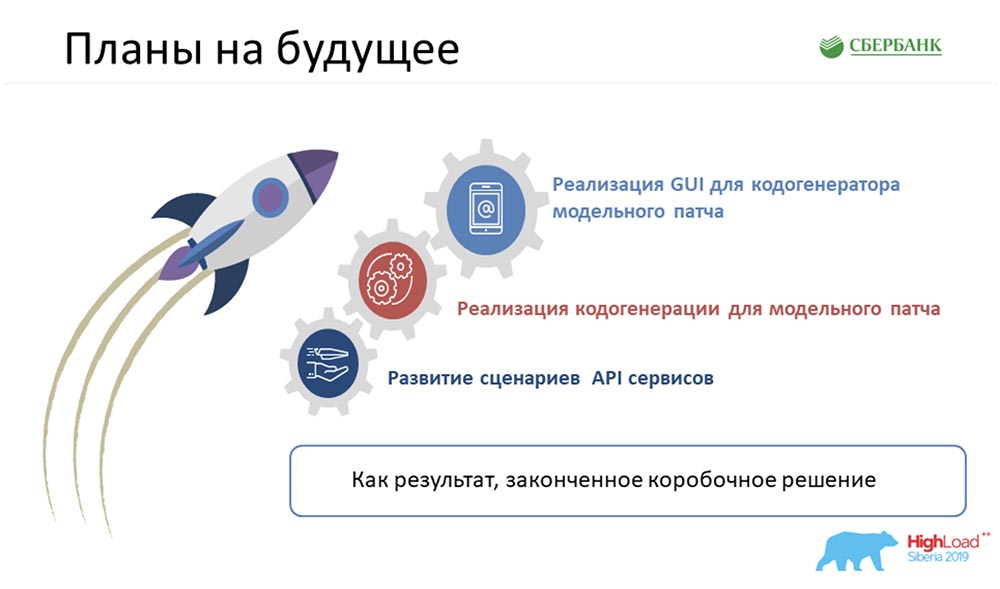 Sería feliz si esto pudiera ser útil para cualquiera de ustedes. Si tiene alguna pregunta, estamos a su disposición. Y después del informe, también hay algo de tiempo aquí. Pedir. ¡Estaremos encantados de ayudarte!C.A:- De hecho, este enfoque, creo, puede comenzar a ser utilizado por todos. No necesariamente en nuestra forma (estamos comprometidos con la gestión de metadatos). Puede ser un sistema de control de cualquier cosa. Todo lo que necesita tener a mano es una vista relacional de las cosas, tomar metadatos a partir de ahí, comprender algunos motores de plantillas y comprender un lenguaje de programación (cómo funciona).Todas estas herramientas son de dominio público: ya puede comenzar a buscar en Google y comprender cómo usarlas. Estoy seguro de que usarlos hará que su vida sea más fácil, mejor y, en general, liberará tiempo para tareas nuevas, ambiciosas y geniales. ¡Gracias!
Sería feliz si esto pudiera ser útil para cualquiera de ustedes. Si tiene alguna pregunta, estamos a su disposición. Y después del informe, también hay algo de tiempo aquí. Pedir. ¡Estaremos encantados de ayudarte!C.A:- De hecho, este enfoque, creo, puede comenzar a ser utilizado por todos. No necesariamente en nuestra forma (estamos comprometidos con la gestión de metadatos). Puede ser un sistema de control de cualquier cosa. Todo lo que necesita tener a mano es una vista relacional de las cosas, tomar metadatos a partir de ahí, comprender algunos motores de plantillas y comprender un lenguaje de programación (cómo funciona).Todas estas herramientas son de dominio público: ya puede comenzar a buscar en Google y comprender cómo usarlas. Estoy seguro de que usarlos hará que su vida sea más fácil, mejor y, en general, liberará tiempo para tareas nuevas, ambiciosas y geniales. ¡Gracias!Preguntas
Pregunta de la audiencia (en adelante - A): - ¿Entiendo correctamente que todo está acumulado porque usa una base de datos relacional? Me parece que si mirara hacia la base de datos orientada a documentos, toda esta solución sería mucho más fácil de lo que veo ahora.SC: - En realidad no. Con lo que comenzamos cuando hablamos de las personas que trabajan en el nivel del glosario y la araña que va al baile de graduación, lee estas historias y comprueba; de hecho, la tabla con el campo que es responsable de este término del glosario tiene lugar en el baile de graduación. . Dijeron desde nuestro servicio: “Chicos, deberían tener una API REST. Cómo lo haces es tu problema. Aquí hay una lista de tecnologías permitidas: use algo de esta lista (esto es lo que podemos usar en Sberbank) ”.Este es el nivel de nuestra solución, arquitectura aplicada. Para nosotros, por el contrario, fue más fácil hacer esto no relacional. ¿Por qué? Daré un ejemplo, uno de muchos ... Por ejemplo, necesito asegurarme, cuando escribo un campo, que no se refiere a una tabla que no existe. Acabo de hacer una clave externa en la base de datos y no estoy preocupado. No estoy escribiendo una línea, no me dejará hacer este disco. ¡Y hay muchos ejemplos de este tipo!Aquí deberíamos hablar de otra cosa. Una historia más complicada: lanzaremos un parche modelo con un conjunto de datos de ajuste / certificación, y hay 6 objetos allí. E inevitablemente, para que pueda proporcionar este conjunto caballeroso de API, necesita tres meses para trabajar (de improviso). Nos llevará una semana y media. Sin aplicar estas tecnologías, era simplemente imposible sobrevivir en estas condiciones. ¡Simplemente no daríamos ese nivel de servicio!Esto es posible si construyó la producción de tal manera que tenga un parche modelo (nuevo objeto), un botón "Hacer todo bien" y algún software que probará en modo de emulación del cliente. Ganó uno nuevo, el anterior no se cayó, esto tenía que lograrse, pero cómo, fue la elección del equipo. A: Tengo una segunda pregunta. ¿Y cuál es un ejemplo de uso de la vida? Entiendo que teóricamente parece que al menos puedes describir el mundo entero con tu objeto META_META ... Pero en la vida, ¿cómo lo usas? A juzgar por cómo se implementa (todo se debe poner entre sí), ¡debería reducir la velocidad!CAROLINA DEL SUR:- Por cierto, no (sorprendentemente)! Otra aplicación de esta historia son los generadores de código. Aquí es donde se construyen algunos escaparates, almacenes, y usted es ETL, está tratando de estacionar todas las opciones posibles en nueve plantillas, nueve motores de plantillas que se describen de antemano. Usando metadatos, usted describe esta transformación, usando estas plantillas como apéndices. Además, esta máquina sin programación proporciona un código ETL, genera código basado en metadatos. Creo que también existen tales tecnologías, los enfoques serán apropiados y correctos.R: Estaba contando con un ejemplo más específico.R: Dime, por favor, estaba escrito en tus requisitos que necesitas hacer consultas estructurales complejas (Unirse y similares). ¿En qué idioma se implementa o lo describe de alguna manera lógicamente?CAROLINA DEL SUR:- Acceso a través de la API REST, la mayoría de las veces es Java, aunque puede ser cualquier idioma. Nuestro servicio ha sido publicado (dhttps, pregunte https, obtendrá JSON de vuelta). Esas piezas de código que mostramos son SQL. Para entender en qué orden debe procesarse, realizamos algunos ajustes de SQL en los diccionarios DBMS y lo estacionamos en un esquema separado en forma de representaciones materializadas. En consecuencia, cuando se lanza un parche modelo, se hace clic en el botón "Actualizar vista materializada" (aparecen los campos +). Pero realmente nuestro código es Java y Oracle.C.A:- Vale la pena señalar aquí que decidimos dividir las áreas de responsabilidad. Deliberadamente transferimos toda la magia al núcleo, y la aplicación simplemente interpreta correctamente estas respuestas. Es decir, el mecanismo de unión en sí ocurre en el núcleo, y Java simplemente lo dispersa de manera competente en el árbol y le da al usuario el resultado final.R: ¿Y qué hace Code Gens? ¿Ya escribe la lógica de las consultas complejas allí? ¿O se hace del lado del cliente? Necesitamos entender de qué lado se está describiendo ... Presentaron, resulta, Code Gen, en el que es necesario describir con precisión en alguna estructura: por ejemplo, quiero que mi API aprenda tal y tal Join, revise la lista; luego diga si hay adentro o no ... - las consultas complejas son suficientes. ¿En qué etapa se escribe esto?CAROLINA DEL SUR:- Si entiendo su pregunta correctamente, esta es exactamente la historia cuando nuestros clientes, nuestros clientes (este es un equipo dentro del núcleo, la plataforma) dicen: "Escucha, no queremos programar, danos esto". "Esto es todo" todo se hizo en el núcleo. El núcleo: ¿esencialmente qué? 80 por ciento, tal vez 90: esta es la generación de código dinámico, el texto que se llamará desde PL / SQL, pero se dirigirá a la base de datos. Allí, incluso a tiempo, esta línea se genera durante más tiempo, luego se accede a la base de datos (por ejemplo, la solicitud de unión), se devuelve, se envuelve en JSON y se muestra al revés. Además, Java transforma todo esto en un contrato, que depende de la estructura.Y:- Revelado una solución de actualización por lotes. ¿Y cómo se realiza la garantía de entrega? ¿Ha llegado el paquete completo o parte del paquete? ¿Tienen un cierto cachend? ¿Y cómo asegurarse de que ni el servicio caiga, ni las estructuras de datos tengan algún tipo de coherencia, para que no haya errores?SC: - Tenemos un protocolo, hay dos modos de actualización. En uno de ellos puede establecer la bandera "Aplicar todo lo que pueda". Hay algún software que Excel convierte a JSON; puede haber 10 mil líneas. Y usted, estrictamente hablando, dos líneas pueden ser inválidas (error). Y usted dice: "Aplique todo lo que pueda"; o "Solo aplique si la historia completa no tendrá un solo error". Allí, el estado integral será la reversión, por ejemplo. De hecho, se realiza una inserción en la base de datos, pero no se llama a commit.En caso de error, se llama reversión, está en el protocolo; obtienes el protocolo de todos modos. Obtiene un estado en cada línea y tiene un identificador en un campo separado, ya sea un número (ID de objeto) o alguna clave alternativa, o ambas. El protocolo permite comprender lo que sucedió con mi solicitud.AC: - El propio usuario indica en cuál de las opciones debe moverse. Pasamos este parámetro al lado del núcleo, y el núcleo ya produce toda la magia, nos da la respuesta y la interpretamos.Y:"¿Por qué no usaste ningún compilador de expresiones incorporado que ayudaría a definir la regla?" Supongamos que tenemos una plantilla, estoy blogueando en algún idioma (lenguaje de script escrito / no escrito); escribió: "Quiero una lista". Pasó este fragmento para que algún procesador de código lo masticara todo, lo pusiera en una base de datos NoSQL, como se sugiere en la primera pregunta ... Aún así, ¿no está claro por qué una base de datos relacional y por qué y cómo lidiar con la redundancia de datos? Un hombre te envía una plantilla con mil millones de basura ... ¿Cómo se alcanzan estos acuerdos cuando una persona lo necesita?
A: Tengo una segunda pregunta. ¿Y cuál es un ejemplo de uso de la vida? Entiendo que teóricamente parece que al menos puedes describir el mundo entero con tu objeto META_META ... Pero en la vida, ¿cómo lo usas? A juzgar por cómo se implementa (todo se debe poner entre sí), ¡debería reducir la velocidad!CAROLINA DEL SUR:- Por cierto, no (sorprendentemente)! Otra aplicación de esta historia son los generadores de código. Aquí es donde se construyen algunos escaparates, almacenes, y usted es ETL, está tratando de estacionar todas las opciones posibles en nueve plantillas, nueve motores de plantillas que se describen de antemano. Usando metadatos, usted describe esta transformación, usando estas plantillas como apéndices. Además, esta máquina sin programación proporciona un código ETL, genera código basado en metadatos. Creo que también existen tales tecnologías, los enfoques serán apropiados y correctos.R: Estaba contando con un ejemplo más específico.R: Dime, por favor, estaba escrito en tus requisitos que necesitas hacer consultas estructurales complejas (Unirse y similares). ¿En qué idioma se implementa o lo describe de alguna manera lógicamente?CAROLINA DEL SUR:- Acceso a través de la API REST, la mayoría de las veces es Java, aunque puede ser cualquier idioma. Nuestro servicio ha sido publicado (dhttps, pregunte https, obtendrá JSON de vuelta). Esas piezas de código que mostramos son SQL. Para entender en qué orden debe procesarse, realizamos algunos ajustes de SQL en los diccionarios DBMS y lo estacionamos en un esquema separado en forma de representaciones materializadas. En consecuencia, cuando se lanza un parche modelo, se hace clic en el botón "Actualizar vista materializada" (aparecen los campos +). Pero realmente nuestro código es Java y Oracle.C.A:- Vale la pena señalar aquí que decidimos dividir las áreas de responsabilidad. Deliberadamente transferimos toda la magia al núcleo, y la aplicación simplemente interpreta correctamente estas respuestas. Es decir, el mecanismo de unión en sí ocurre en el núcleo, y Java simplemente lo dispersa de manera competente en el árbol y le da al usuario el resultado final.R: ¿Y qué hace Code Gens? ¿Ya escribe la lógica de las consultas complejas allí? ¿O se hace del lado del cliente? Necesitamos entender de qué lado se está describiendo ... Presentaron, resulta, Code Gen, en el que es necesario describir con precisión en alguna estructura: por ejemplo, quiero que mi API aprenda tal y tal Join, revise la lista; luego diga si hay adentro o no ... - las consultas complejas son suficientes. ¿En qué etapa se escribe esto?CAROLINA DEL SUR:- Si entiendo su pregunta correctamente, esta es exactamente la historia cuando nuestros clientes, nuestros clientes (este es un equipo dentro del núcleo, la plataforma) dicen: "Escucha, no queremos programar, danos esto". "Esto es todo" todo se hizo en el núcleo. El núcleo: ¿esencialmente qué? 80 por ciento, tal vez 90: esta es la generación de código dinámico, el texto que se llamará desde PL / SQL, pero se dirigirá a la base de datos. Allí, incluso a tiempo, esta línea se genera durante más tiempo, luego se accede a la base de datos (por ejemplo, la solicitud de unión), se devuelve, se envuelve en JSON y se muestra al revés. Además, Java transforma todo esto en un contrato, que depende de la estructura.Y:- Revelado una solución de actualización por lotes. ¿Y cómo se realiza la garantía de entrega? ¿Ha llegado el paquete completo o parte del paquete? ¿Tienen un cierto cachend? ¿Y cómo asegurarse de que ni el servicio caiga, ni las estructuras de datos tengan algún tipo de coherencia, para que no haya errores?SC: - Tenemos un protocolo, hay dos modos de actualización. En uno de ellos puede establecer la bandera "Aplicar todo lo que pueda". Hay algún software que Excel convierte a JSON; puede haber 10 mil líneas. Y usted, estrictamente hablando, dos líneas pueden ser inválidas (error). Y usted dice: "Aplique todo lo que pueda"; o "Solo aplique si la historia completa no tendrá un solo error". Allí, el estado integral será la reversión, por ejemplo. De hecho, se realiza una inserción en la base de datos, pero no se llama a commit.En caso de error, se llama reversión, está en el protocolo; obtienes el protocolo de todos modos. Obtiene un estado en cada línea y tiene un identificador en un campo separado, ya sea un número (ID de objeto) o alguna clave alternativa, o ambas. El protocolo permite comprender lo que sucedió con mi solicitud.AC: - El propio usuario indica en cuál de las opciones debe moverse. Pasamos este parámetro al lado del núcleo, y el núcleo ya produce toda la magia, nos da la respuesta y la interpretamos.Y:"¿Por qué no usaste ningún compilador de expresiones incorporado que ayudaría a definir la regla?" Supongamos que tenemos una plantilla, estoy blogueando en algún idioma (lenguaje de script escrito / no escrito); escribió: "Quiero una lista". Pasó este fragmento para que algún procesador de código lo masticara todo, lo pusiera en una base de datos NoSQL, como se sugiere en la primera pregunta ... Aún así, ¿no está claro por qué una base de datos relacional y por qué y cómo lidiar con la redundancia de datos? Un hombre te envía una plantilla con mil millones de basura ... ¿Cómo se alcanzan estos acuerdos cuando una persona lo necesita? CAROLINA DEL SUR:"Trataré de responder cuando entendí la pregunta". La mayor parte del programa se comunica con nosotros ahora. Cuando se establece el mecanismo de interacción de integración, no tanta gente se comunica con nosotros como los programas. Hay, por supuesto, casos en que las personas envían a la exelniks para el derrame primario: hacemos JSON de ellos, cargamos, pero esta es más una configuración primaria.Y tenemos un modo cuando envió 5.000 líneas, de las cuales 4.900 regresaron con el estado "Procesé, no encontré ningún cambio, no hice nada". Pero esto se refleja en el protocolo y no hay error. Esto es, por un lado, redundancia.Tenemos toda esta historia almacenada en una forma aproximada a la tercera, normal, que simplemente no implica redundancia, en contraste con algunas estructuras desnormalizadas que se utilizan, por ejemplo, para escaparates.¿Por qué relacional? Los generadores de código funcionan para nosotros, y la sensibilidad a la calidad de los metadatos en el sistema es muy alta. Y cuando tengamos la oportunidad de configurar una clave externa usando relacional y asegurarnos ... El registro simplemente no se acuesta: habrá un error si algo está mal en el sistema, si ocurre una falla. Y queremos, pero no estamos buscando trabajo adicional ...No somos medidos debido a la cantidad de líneas de código que escribimos: "¿Has resuelto la cuestión del servicio y su estabilidad o no?" Es posible que no escriba nada, lo principal es que funciona. En este sentido, fue simplemente más rápido y más conveniente para nosotros hacerlo.No tomo un proveedor específico, ¡pero las bases de datos relacionales se han desarrollado durante 20 años! No es solo así. Tomemos, por ejemplo, Word o Excel en Windows: no programa el código allí, que con la ayuda de "Ensamblador" accede y mueve las cabezas del disco duro para escribir un archivo ... ¡Lo mismo está aquí! Acabamos de utilizar esos desarrollos que estaban en RDBMS, y fue conveniente.C.A:- Para garantizar todos nuestros requisitos, la integridad de los metadatos era importante para nosotros. Y aquí probablemente también quisimos transmitir que no tenemos que aferrarnos en absoluto: usamos relacional, no relacional ... La esencia del informe es que también puede comenzar a usarlo. No necesariamente en una base relacional, porque seguramente otros también tienen algún tipo de metadatos que se pueden recopilar: al menos, qué tablas, campos y todo esto está programado.A: - El sistema implica algún uso. ¿Cómo planifica (o ya lo hizo) la entrega de datos a su sistema? Está claro que algún tipo de actualización de la estructura de datos va al supermercado. ¿Cómo te llega todo esto? Automáticamente, o su agente está de pie, ¿o está cediendo a todos los equipos de desarrollo para que reciba actualizaciones?C.A:- Tenemos dos modos de operación. Una es cuando los propios desarrolladores o los propios equipos se ven obligados a insertar metadatos en el sistema a través de los servicios REST. El segundo modo de operación es ese mismo "aspirador": nosotros mismos vamos al medio ambiente y tomamos todos los metadatos posibles a partir de ahí. Hacemos esto una vez al día y simplemente verificamos lo que nos enviaron los desarrolladores.
CAROLINA DEL SUR:"Trataré de responder cuando entendí la pregunta". La mayor parte del programa se comunica con nosotros ahora. Cuando se establece el mecanismo de interacción de integración, no tanta gente se comunica con nosotros como los programas. Hay, por supuesto, casos en que las personas envían a la exelniks para el derrame primario: hacemos JSON de ellos, cargamos, pero esta es más una configuración primaria.Y tenemos un modo cuando envió 5.000 líneas, de las cuales 4.900 regresaron con el estado "Procesé, no encontré ningún cambio, no hice nada". Pero esto se refleja en el protocolo y no hay error. Esto es, por un lado, redundancia.Tenemos toda esta historia almacenada en una forma aproximada a la tercera, normal, que simplemente no implica redundancia, en contraste con algunas estructuras desnormalizadas que se utilizan, por ejemplo, para escaparates.¿Por qué relacional? Los generadores de código funcionan para nosotros, y la sensibilidad a la calidad de los metadatos en el sistema es muy alta. Y cuando tengamos la oportunidad de configurar una clave externa usando relacional y asegurarnos ... El registro simplemente no se acuesta: habrá un error si algo está mal en el sistema, si ocurre una falla. Y queremos, pero no estamos buscando trabajo adicional ...No somos medidos debido a la cantidad de líneas de código que escribimos: "¿Has resuelto la cuestión del servicio y su estabilidad o no?" Es posible que no escriba nada, lo principal es que funciona. En este sentido, fue simplemente más rápido y más conveniente para nosotros hacerlo.No tomo un proveedor específico, ¡pero las bases de datos relacionales se han desarrollado durante 20 años! No es solo así. Tomemos, por ejemplo, Word o Excel en Windows: no programa el código allí, que con la ayuda de "Ensamblador" accede y mueve las cabezas del disco duro para escribir un archivo ... ¡Lo mismo está aquí! Acabamos de utilizar esos desarrollos que estaban en RDBMS, y fue conveniente.C.A:- Para garantizar todos nuestros requisitos, la integridad de los metadatos era importante para nosotros. Y aquí probablemente también quisimos transmitir que no tenemos que aferrarnos en absoluto: usamos relacional, no relacional ... La esencia del informe es que también puede comenzar a usarlo. No necesariamente en una base relacional, porque seguramente otros también tienen algún tipo de metadatos que se pueden recopilar: al menos, qué tablas, campos y todo esto está programado.A: - El sistema implica algún uso. ¿Cómo planifica (o ya lo hizo) la entrega de datos a su sistema? Está claro que algún tipo de actualización de la estructura de datos va al supermercado. ¿Cómo te llega todo esto? Automáticamente, o su agente está de pie, ¿o está cediendo a todos los equipos de desarrollo para que reciba actualizaciones?C.A:- Tenemos dos modos de operación. Una es cuando los propios desarrolladores o los propios equipos se ven obligados a insertar metadatos en el sistema a través de los servicios REST. El segundo modo de operación es ese mismo "aspirador": nosotros mismos vamos al medio ambiente y tomamos todos los metadatos posibles a partir de ahí. Hacemos esto una vez al día y simplemente verificamos lo que nos enviaron los desarrolladores. SC: - De los cuatro niveles que examinamos, los tres niveles principales (glosario, modelos lógicos, modelos físicos) son la historia que nos llega por defecto en el modo Metadata Broker, y somos un participante pasivo. Nos llaman, nos pasan algo, preguntan; nuestra tarea es estacionar de manera consistente. Aunque hay casos en los que configuramos algunas historias con los recursos del equipo, si estamos muy interesados en tener estos metadatos.Como dijo Nastya, con respecto a la historia al revés (en la jerga técnica que lo llamamos "aspiradora"), vamos al entorno industrial y leemos algunos datos. Hay diferentes casos: estamos listos para discutir más tarde, estamos listos para contar muchas historias interesantes.A: - Soy del centro de tecnología financiera. Vi una palabra familiar allí: DACUM principal. Nuestra plataforma tiene sus propios metadatos. ¿Cómo están amigos, directamente con las tablas de Oracle o con nuestros metadatos en este caso? Porque en nuestro caso, ser amigo de las tablas de Oracle no es del todo indicativo.CAROLINA DEL SUR:- Existe una tabla DACUM principal, que contiene el cableado. Esto no es un secreto: hubo y hay productos que funcionan en esta historia. Estas son una de las fuentes de información en el repositorio. Hay algún tipo de sistema que es un proveedor de datos. Naturalmente, está en el centro de nuestra atención desde el punto de vista de los metadatos, porque una de las historias que deberíamos mostrar y que no hemos tocado aquí (debido al tema del informe) es el linaje de datos. Debe mostrar de dónde proviene el historial de datos de este campo. En este sentido, si hay una tabla DACUM principal, lo sabemos.
SC: - De los cuatro niveles que examinamos, los tres niveles principales (glosario, modelos lógicos, modelos físicos) son la historia que nos llega por defecto en el modo Metadata Broker, y somos un participante pasivo. Nos llaman, nos pasan algo, preguntan; nuestra tarea es estacionar de manera consistente. Aunque hay casos en los que configuramos algunas historias con los recursos del equipo, si estamos muy interesados en tener estos metadatos.Como dijo Nastya, con respecto a la historia al revés (en la jerga técnica que lo llamamos "aspiradora"), vamos al entorno industrial y leemos algunos datos. Hay diferentes casos: estamos listos para discutir más tarde, estamos listos para contar muchas historias interesantes.A: - Soy del centro de tecnología financiera. Vi una palabra familiar allí: DACUM principal. Nuestra plataforma tiene sus propios metadatos. ¿Cómo están amigos, directamente con las tablas de Oracle o con nuestros metadatos en este caso? Porque en nuestro caso, ser amigo de las tablas de Oracle no es del todo indicativo.CAROLINA DEL SUR:- Existe una tabla DACUM principal, que contiene el cableado. Esto no es un secreto: hubo y hay productos que funcionan en esta historia. Estas son una de las fuentes de información en el repositorio. Hay algún tipo de sistema que es un proveedor de datos. Naturalmente, está en el centro de nuestra atención desde el punto de vista de los metadatos, porque una de las historias que deberíamos mostrar y que no hemos tocado aquí (debido al tema del informe) es el linaje de datos. Debe mostrar de dónde proviene el historial de datos de este campo. En este sentido, si hay una tabla DACUM principal, lo sabemos.Un poco de publicidad :)
Gracias por estar con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes? Apóyenos haciendo un pedido o recomendando a sus amigos VPS basado en la nube para desarrolladores desde $ 4.99 , un análogo único de servidores de nivel básico que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2697 v3 (6 núcleos) 10GB DDR4 480GB SSD 1Gbps desde $ 19 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).Dell R730xd 2 veces más barato en el centro de datos Equinix Tier IV en Amsterdam? ¡Solo tenemos 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV desde $ 199 en los Países Bajos!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - ¡desde $ 99! Lea sobre Cómo construir un edificio de infraestructura. clase c con servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo? Source: https://habr.com/ru/post/undefined/
All Articles