 Cuando los problemas de análisis van más allá de las herramientas preconstruidas, probablemente sea hora de que elija una base de datos para análisis. No debe escribir scripts de consultas en la base de datos de trabajo, porque puede cambiar el orden de los datos y, muy probablemente, ralentizar la aplicación.También puede eliminar accidentalmente información importante si analistas o ingenieros trabajan allí.Para el análisis, necesita un tipo separado de base de datos. ¿Pero cuál es la verdad?En esta publicación consideraremos ofertas y mejores prácticas para una empresa promedio que recién comienza a funcionar. Cualquiera sea la configuración que elija, puede encontrar un compromiso en el futuro para mejorar el rendimiento sobre lo que estamos discutiendo aquí.Trabajando con un gran número de clientes, encontramos que los criterios más importantes que deben considerarse son:
Cuando los problemas de análisis van más allá de las herramientas preconstruidas, probablemente sea hora de que elija una base de datos para análisis. No debe escribir scripts de consultas en la base de datos de trabajo, porque puede cambiar el orden de los datos y, muy probablemente, ralentizar la aplicación.También puede eliminar accidentalmente información importante si analistas o ingenieros trabajan allí.Para el análisis, necesita un tipo separado de base de datos. ¿Pero cuál es la verdad?En esta publicación consideraremos ofertas y mejores prácticas para una empresa promedio que recién comienza a funcionar. Cualquiera sea la configuración que elija, puede encontrar un compromiso en el futuro para mejorar el rendimiento sobre lo que estamos discutiendo aquí.Trabajando con un gran número de clientes, encontramos que los criterios más importantes que deben considerarse son:- Tipo de datos analizados
- ¿Cuántos datos tienes?
- El enfoque de su equipo de ingeniería.
- ¿Qué tan rápido necesita información?
¿Qué tipos de datos analizas?
Piensa en los datos que quieres analizar. ¿Encajan bien en filas y columnas como una gran hoja de cálculo de Excel? ¿O tendría más sentido si los pones en un documento de Word?Si respondió Excel, una base de datos relacional como Postgres, MySQL, Amazon Redshift o BigQuery satisfará sus necesidades. Estas bases de datos relacionales estructuradas son excelentes cuando sabes exactamente qué datos vas a recibir y cómo se relacionan entre sí, básicamente, cómo se relacionan las filas y las columnas. Para la mayoría de los tipos de análisis de usuarios, las bases de datos relacionales funcionan bien. Los atributos del usuario como nombres, correos electrónicos y planes de facturación se ajustan perfectamente a la tabla, como los eventos del usuario y sus propiedades .Por otro lado, si sus datos se ajustan mejor en una hoja de papel, debe consultar una base de datos no relacional (NoSQL) como Hadoop o Mongo.Las bases de datos no relacionales se caracterizan por una gran cantidad de valores privados (millones) de datos semiestructurados. Ejemplos clásicos de datos semiestructurados son textos como correo electrónico, libros y redes sociales, datos audiovisuales y datos geográficos. Si realiza una gran cantidad de minería de texto, procesamiento de lenguaje o procesamiento de imágenes, lo más probable es que necesite usar almacenes de datos no relacionales.
¿Con cuántos datos está tratando?
La siguiente pregunta que debe hacerse es cuántos datos está tratando. Cuantos más datos tenga, más útil será la base de datos no relacional, ya que no impondrá restricciones a los datos entrantes, lo que le permitirá escribir en la base de datos más rápido. Estas no son restricciones estrictas, y cada una puede procesar más o menos datos dependiendo de varios factores, pero descubrimos que cada una de las bases de datos funciona perfectamente dentro de estos límites.Si tiene menos de 1 TB de datos, con Postgres obtendrá un buen rendimiento. Pero se ralentiza a aproximadamente 6 TB. Si le gusta MySQL pero necesita una escala ligeramente mayor, Aurora (la propia versión de Amazon) puede alcanzar los 64 TB. Para un tamaño de petabyte, Amazon Redshift suele ser una buena opción, ya que está optimizado para análisis de hasta 2 PB. Para el procesamiento paralelo o incluso los datos MOAR, probablemente sea hora de echar un vistazo a Hadoop.Sin embargo, AWS nos dijo que están ejecutando Amazon.com en Redshift, por lo que si tiene un equipo de DBA de primera clase, puede escalar más allá del "límite" de 2 PB.
Estas no son restricciones estrictas, y cada una puede procesar más o menos datos dependiendo de varios factores, pero descubrimos que cada una de las bases de datos funciona perfectamente dentro de estos límites.Si tiene menos de 1 TB de datos, con Postgres obtendrá un buen rendimiento. Pero se ralentiza a aproximadamente 6 TB. Si le gusta MySQL pero necesita una escala ligeramente mayor, Aurora (la propia versión de Amazon) puede alcanzar los 64 TB. Para un tamaño de petabyte, Amazon Redshift suele ser una buena opción, ya que está optimizado para análisis de hasta 2 PB. Para el procesamiento paralelo o incluso los datos MOAR, probablemente sea hora de echar un vistazo a Hadoop.Sin embargo, AWS nos dijo que están ejecutando Amazon.com en Redshift, por lo que si tiene un equipo de DBA de primera clase, puede escalar más allá del "límite" de 2 PB.¿En qué se centra su equipo de ingeniería?
Esta es otra pregunta importante que debe hacerse al discutir la base de datos. Cuanto más pequeño sea su equipo en general, mayor será la probabilidad de que sus ingenieros se centren principalmente en la creación de productos, en lugar del procesamiento y la gestión de datos. El número de personas que puede dedicar a estos proyectos afectará en gran medida sus opciones.Con algunos recursos de ingeniería, tiene más opciones: puede ir a una base de datos relacional o no relacional. Las bases de datos relacionales toman menos tiempo que NoSQL.Si tiene varios ingenieros que están trabajando en la instalación, pero no puede traer a nadie al servicio, elija algo como Postgres , Google SQL (alojamiento opcional de MySQL) o Almacenes de segmentos(Redshift hosting) es probablemente una mejor opción que Redshift, Aurora o BigQuery, ya que requieren una corrección periódica del procesamiento de datos. Si tiene más tiempo para el servicio, elegir Redshift o BigQuery proporcionará consultas más rápidas y a mayor escala.Las bases de datos relacionales tienen otra ventaja: puede usar SQL para consultarlas. SQL es bien conocido tanto por los analistas como por los ingenieros, y es más fácil de aprender que la mayoría de los lenguajes de programación.Por otro lado, el análisis de datos semiestructurados generalmente requiere, como mínimo, experiencia en programación orientada a objetos o, mejor, experiencia en escribir código para trabajar con grandes datos. Incluso con la llegada de herramientas analíticas como Hunkpara Hadoop o Slamdata para MongoDB, necesitará un analista experimentado o especialista en datos para analizar este tipo de bases de datos.¿Qué tan rápido necesita estos datos?
Si bien el "análisis en tiempo real" es muy popular para casos como la detección de fraudes y el monitoreo del sistema, la mayoría de los análisis no requieren datos en tiempo real o análisis inmediato.Cuando responde preguntas, por ejemplo, qué causa la salida de usuarios o cómo las personas cambian de su aplicación a su sitio web, el acceso a sus datos con un ligero retraso (intervalos por hora o por día) es bastante aceptable. Sus datos no cambian minuto a minuto.Por lo tanto, si está trabajando principalmente en el análisis real, debe consultar una base de datos optimizada para análisis, como Redshift o BigQuery. Dichas bases de datos están diseñadas para acomodar una gran cantidad de datos y leer y combinar datos rápidamente, lo que agiliza las consultas. También pueden descargar datos lo suficientemente rápido (cada hora) mientras alguien realiza el proceso de limpieza, redimensionando y monitoreando el clúster.Si necesita absolutamente datos en tiempo real, debe recurrir a una base de datos no estructurada como Hadoop. Puede diseñar su base de datos Hadoop para que los datos se carguen muy rápidamente, aunque consultarla puede llevar más tiempo dependiendo del uso de RAM, el espacio disponible en el disco y la estructura de datos.Postgres vs. Amazon Redshift vs. Google bigquery
Probablemente ya se haya dado cuenta de que una base de datos relacional sería la mejor opción para analizar la mayoría de los tipos de comportamiento del usuario. La información sobre cómo sus usuarios interactúan con su sitio y aplicaciones puede caber fácilmente en un formato estructurado.analytics.track('Completed Order') — select * from ios.completed_order
 Entonces, la pregunta es qué base de datos SQL usar. Se deben considerar cuatro criterios.
Entonces, la pregunta es qué base de datos SQL usar. Se deben considerar cuatro criterios.Tamaño vs. velocidad
Cuando necesita velocidad, vale la pena considerar Postgres: para una base de datos de menos de 1TB, Postgres es bastante rápido para cargar datos y consultas. Además, está disponible. A medida que se acerque a 6 TB (heredado de Amazon RDS), sus consultas se ejecutarán más lentamente.Por lo tanto, cuando necesita un tamaño más grande, generalmente recomendamos Redshift. Nuestra experiencia muestra que Redshift tiene la mejor relación calidad-precio.SQL resaltado
Redshift se basa en una variación de Postgres, y ambos admiten el buen SQL antiguo. Redshift no admite todos los tipos de datos y funciones que admite Postgres, pero está mucho más cerca del estándar de la industria que BigQuery, que tiene su propio SQL.A diferencia de muchos otros sistemas basados en SQL, BigQuery usa una sintaxis separada por comas para indicar uniones de tabla, y no de acuerdo con la documentación de SQL . Esto significa que, sin precaución, las consultas SQL pueden provocar errores o resultados inesperados. Por lo tanto, muchos de los equipos que conocimos no pueden convencer a sus analistas para que aprendan BigQuery SQL.Ecosistema de terceros
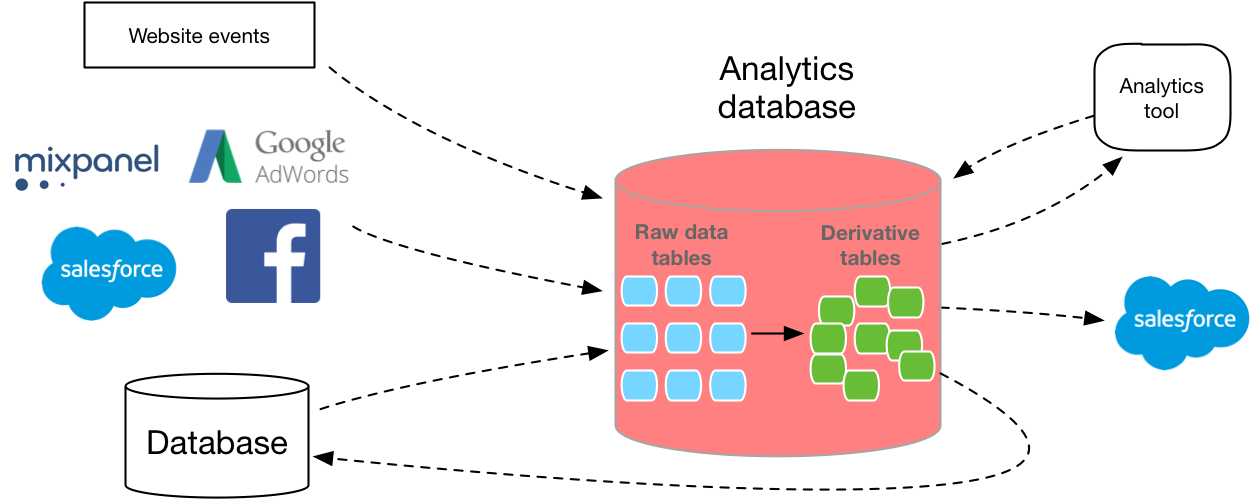
Rara vez su almacén de datos vive solo. Debe colocar los datos en una base de datos y, además, debe usar algún tipo de software para analizarlos. (A menos que ejecute la consulta SQL desde la línea de comandos).Por lo tanto, a la gente a menudo le gusta que Redshift tenga un ecosistema muy grande de herramientas de terceros. AWS tiene capacidades como el Segment Data Warehouse para cargar datos en Redshift desde la API de análisis, y también funcionan con casi todas las herramientas de visualización de datos en el mercado. Menos servicios de terceros se conectan a Google, por lo que mover los mismos datos a BigQuery puede llevar más tiempo desarrollarlo, y no tendrá tantas opciones para el software de BI.Puedes ver socios de Amazonaquí y google aquí .Sin embargo, si ya usa Google Cloud Storage en lugar de Amazon S3, puede ser beneficioso para usted permanecer en el ecosistema de Google. Ambos servicios facilitan la descarga de datos si ya existe en el repositorio de almacenamiento en la nube correspondiente, de modo que aunque no viole los términos de uso, será mucho más fácil si deja de usar uno de estos proveedores.Formación
Ahora que tiene una idea más clara de qué base de datos usar, el siguiente paso es descubrir cómo recopilará los datos en la base de datos.Muchos desarrolladores de bases de datos nuevos subestiman lo difícil que es construir una tubería de datos escalable. Debe escribir su propia capa de extracción, API de recopilación de datos, consulta y capa de conversión. Y todos tienen que escalar. Además, debe determinar el diseño correcto según el tamaño y el tipo de cada columna. MVP replica su base de datos de producción en una nueva instancia, pero esto generalmente significa usar una base de datos que no está optimizada para análisis.Afortunadamente, hay varias opciones en el mercado que pueden ayudarlo a sortear algunos de estos obstáculos y hacer automáticamente un ETL por usted.Pero ya sea su propio desarrollo o compra, vale la pena obtener datos en SQL.Con base en los datos iniciales del usuario, solo con la ayuda de un formato SQL flexible podrá responder en detalle preguntas sobre lo que están haciendo sus clientes, evaluar con precisión la distribución, comprender el comportamiento multiplataforma, crear paneles para una empresa en particular y mucho más.