Optimización masiva de consultas PostgreSQL. Kirill Borovikov (Tensor)
El informe presenta algunos enfoques que le permiten monitorear el rendimiento de las consultas SQL cuando hay millones de ellas por día y cientos de servidores PostgreSQL controlados.Qué soluciones técnicas nos permiten procesar eficientemente tal volumen de información y cómo facilita la vida de un desarrollador ordinario.¿Quién está interesado en analizar problemas específicos y diversas técnicas para optimizar consultas SQL y resolver problemas típicos de DBA en PostgreSQL ? También puede leer una serie de artículos sobre este tema. Mi nombre es Kirill Borovikov, represento a la empresa "Tensor" . Específicamente, me especializo en trabajar con bases de datos en nuestra empresa.Hoy les diré cómo estamos haciendo la optimización de consultas, cuando no necesiten "recoger" el rendimiento de una sola solicitud, sino resolver el problema en masa. Cuando hay millones de solicitudes y necesita encontrar algunos enfoques para resolver este gran problema.En general, "Tensor" para nuestros millones de clientes es VLSI: nuestra aplicación : una red social corporativa, soluciones de comunicación por video, para la gestión de documentos internos y externos, sistemas de contabilidad para la contabilidad y el almacenamiento ... Es decir, una "mega-combinación" para la gestión empresarial integrada, que es más de 100 proyectos internos diferentes.Para garantizar que todos trabajen y se desarrollen normalmente, tenemos 10 centros de desarrollo en todo el país, tienen más de 1000 desarrolladores .Hemos estado trabajando con PostgreSQL desde 2008 y hemos acumulado una gran cantidad de lo que procesamos, es decir, datos de clientes, estadísticas, análisis, datos de sistemas de información externos, más de 400 TB . Solo "en producción" hay alrededor de 250 servidores, y en total los servidores de bases de datos que monitoreamos son alrededor de 1000.
Mi nombre es Kirill Borovikov, represento a la empresa "Tensor" . Específicamente, me especializo en trabajar con bases de datos en nuestra empresa.Hoy les diré cómo estamos haciendo la optimización de consultas, cuando no necesiten "recoger" el rendimiento de una sola solicitud, sino resolver el problema en masa. Cuando hay millones de solicitudes y necesita encontrar algunos enfoques para resolver este gran problema.En general, "Tensor" para nuestros millones de clientes es VLSI: nuestra aplicación : una red social corporativa, soluciones de comunicación por video, para la gestión de documentos internos y externos, sistemas de contabilidad para la contabilidad y el almacenamiento ... Es decir, una "mega-combinación" para la gestión empresarial integrada, que es más de 100 proyectos internos diferentes.Para garantizar que todos trabajen y se desarrollen normalmente, tenemos 10 centros de desarrollo en todo el país, tienen más de 1000 desarrolladores .Hemos estado trabajando con PostgreSQL desde 2008 y hemos acumulado una gran cantidad de lo que procesamos, es decir, datos de clientes, estadísticas, análisis, datos de sistemas de información externos, más de 400 TB . Solo "en producción" hay alrededor de 250 servidores, y en total los servidores de bases de datos que monitoreamos son alrededor de 1000. SQL es un lenguaje declarativo. Usted describe no "cómo" algo debería funcionar, sino "qué" desea recibir. DBMS sabe mejor cómo hacer JOIN: cómo conectar sus tabletas, qué condiciones imponer, qué irá por índice, qué no ...Algunos DBMS aceptan sugerencias: "No, conecte estas dos tabletas en tal o cual cola", pero PostgreSQL no. Esta es la posición consciente de los desarrolladores líderes: "Mejor terminaremos el optimizador de consultas que dejar que los desarrolladores usen algún tipo de sugerencia".Pero, a pesar de que PostgreSQL no permite que el "exterior" se controle a sí mismo, le permite ver perfectamente qué sucede "dentro" cuando ejecuta su consulta y dónde tiene problemas.
SQL es un lenguaje declarativo. Usted describe no "cómo" algo debería funcionar, sino "qué" desea recibir. DBMS sabe mejor cómo hacer JOIN: cómo conectar sus tabletas, qué condiciones imponer, qué irá por índice, qué no ...Algunos DBMS aceptan sugerencias: "No, conecte estas dos tabletas en tal o cual cola", pero PostgreSQL no. Esta es la posición consciente de los desarrolladores líderes: "Mejor terminaremos el optimizador de consultas que dejar que los desarrolladores usen algún tipo de sugerencia".Pero, a pesar de que PostgreSQL no permite que el "exterior" se controle a sí mismo, le permite ver perfectamente qué sucede "dentro" cuando ejecuta su consulta y dónde tiene problemas. En general, ¿con qué problemas clásicos suele aparecer el desarrollador [viene a DBA]? "Aquí hemos cumplido la solicitud, y todo es lento , todo se cuelga, algo sucede ... ¡Algún tipo de problema!"Las razones son casi siempre las mismas:
En general, ¿con qué problemas clásicos suele aparecer el desarrollador [viene a DBA]? "Aquí hemos cumplido la solicitud, y todo es lento , todo se cuelga, algo sucede ... ¡Algún tipo de problema!"Las razones son casi siempre las mismas:
: « SQL 10 JOIN...» — , «», . , (10 FROM) - . []
PostgreSQL, «» , — «» . 10 , 10 , PostgreSQL , . []- «»
, , , . … - , .
, (INSERT, UPDATE, DELETE) — .
... Y para todo lo demás, ¡ necesitamos un plan ! Necesitamos ver qué está sucediendo dentro del servidor. El plan de ejecución de consultas para PostgreSQL es un árbol del algoritmo de ejecución de consultas en una representación textual. Es el algoritmo que, como resultado del análisis realizado por el planificador, fue reconocido como el más efectivo.Cada nodo de árbol es una operación: extraer datos de una tabla o índice, construir un mapa de bits, unir dos tablas, unir, intersectar o eliminar muestras. El cumplimiento de la solicitud es un paso a través de los nodos de este árbol.Para obtener un plan de consulta, la forma más fácil es ejecutar la declaración
El plan de ejecución de consultas para PostgreSQL es un árbol del algoritmo de ejecución de consultas en una representación textual. Es el algoritmo que, como resultado del análisis realizado por el planificador, fue reconocido como el más efectivo.Cada nodo de árbol es una operación: extraer datos de una tabla o índice, construir un mapa de bits, unir dos tablas, unir, intersectar o eliminar muestras. El cumplimiento de la solicitud es un paso a través de los nodos de este árbol.Para obtener un plan de consulta, la forma más fácil es ejecutar la declaración EXPLAIN. Para obtener todos los atributos reales, es decir, ejecutar una consulta basada en - EXPLAIN (ANALYZE, BUFFERS) SELECT ....El punto negativo: cuando lo ejecutas, sucede "aquí y ahora", por lo tanto, solo es adecuado para la depuración local. Si toma un servidor de alta carga, que está bajo una fuerte corriente de cambios de datos, y ve: “¡Ay! Aquí somos más lentos a Xia una solicitud ". Hace media hora, hace una hora, mientras estaba ejecutando y obteniendo esta solicitud de los registros, llevándola nuevamente al servidor, todo su conjunto de datos y estadísticas han cambiado. Lo ejecutas para depurar, ¡y funciona rápido! Y no puedes entender por qué, por qué fue lento. Para comprender qué era exactamente en el momento en que la solicitud se ejecuta en el servidor, las personas inteligentes escribieron el módulo auto_explain. Está presente en casi todas las distribuciones PostgreSQL más comunes, y simplemente puede activarlo en el archivo de configuración.Si entiende que una solicitud se está ejecutando por más tiempo que el límite que usted le dijo, toma una "instantánea" del plan para esta solicitud y las escribe juntas en un registro .
Para comprender qué era exactamente en el momento en que la solicitud se ejecuta en el servidor, las personas inteligentes escribieron el módulo auto_explain. Está presente en casi todas las distribuciones PostgreSQL más comunes, y simplemente puede activarlo en el archivo de configuración.Si entiende que una solicitud se está ejecutando por más tiempo que el límite que usted le dijo, toma una "instantánea" del plan para esta solicitud y las escribe juntas en un registro . Todo parece estar bien ahora, vamos al registro y vemos allí ... [paso de texto]. Pero no podemos decir nada sobre él, excepto por el hecho de que este es un plan excelente, porque tardó 11 ms en completarse.Todo parece estar bien, pero nada está claro sobre lo que realmente sucedió. Además del tiempo total, no vemos mucho. Porque mirar tal texto plano "latuha" es generalmente querido.Pero incluso si es amado, aunque incómodo, pero hay problemas más importantes:
Todo parece estar bien ahora, vamos al registro y vemos allí ... [paso de texto]. Pero no podemos decir nada sobre él, excepto por el hecho de que este es un plan excelente, porque tardó 11 ms en completarse.Todo parece estar bien, pero nada está claro sobre lo que realmente sucedió. Además del tiempo total, no vemos mucho. Porque mirar tal texto plano "latuha" es generalmente querido.Pero incluso si es amado, aunque incómodo, pero hay problemas más importantes:- . , Index Scan — , - . , «» , CTE — « ».
- : , , — . , , , , loops — . . , , , — - « ».
En estas circunstancias, comprenda "¿Quién es el eslabón más débil?" Casi irrealista. Por lo tanto, incluso los propios desarrolladores en el "manual" escriben que "Comprender el plan es un arte que necesita ser aprendido, experiencia ..." .Pero tenemos 1000 desarrolladores, y cada uno de ellos no pasará esta experiencia a sus cabezas. Yo, tú, él, ellos lo saben, y alguien de allá, ya no está allí. Tal vez aprenderá, o tal vez no, pero necesita trabajar ahora, y de dónde obtendría esta experiencia.Visualización del plan
Por lo tanto, nos dimos cuenta de que para hacer frente a estos problemas, necesitamos una buena visualización del plan . [artículo]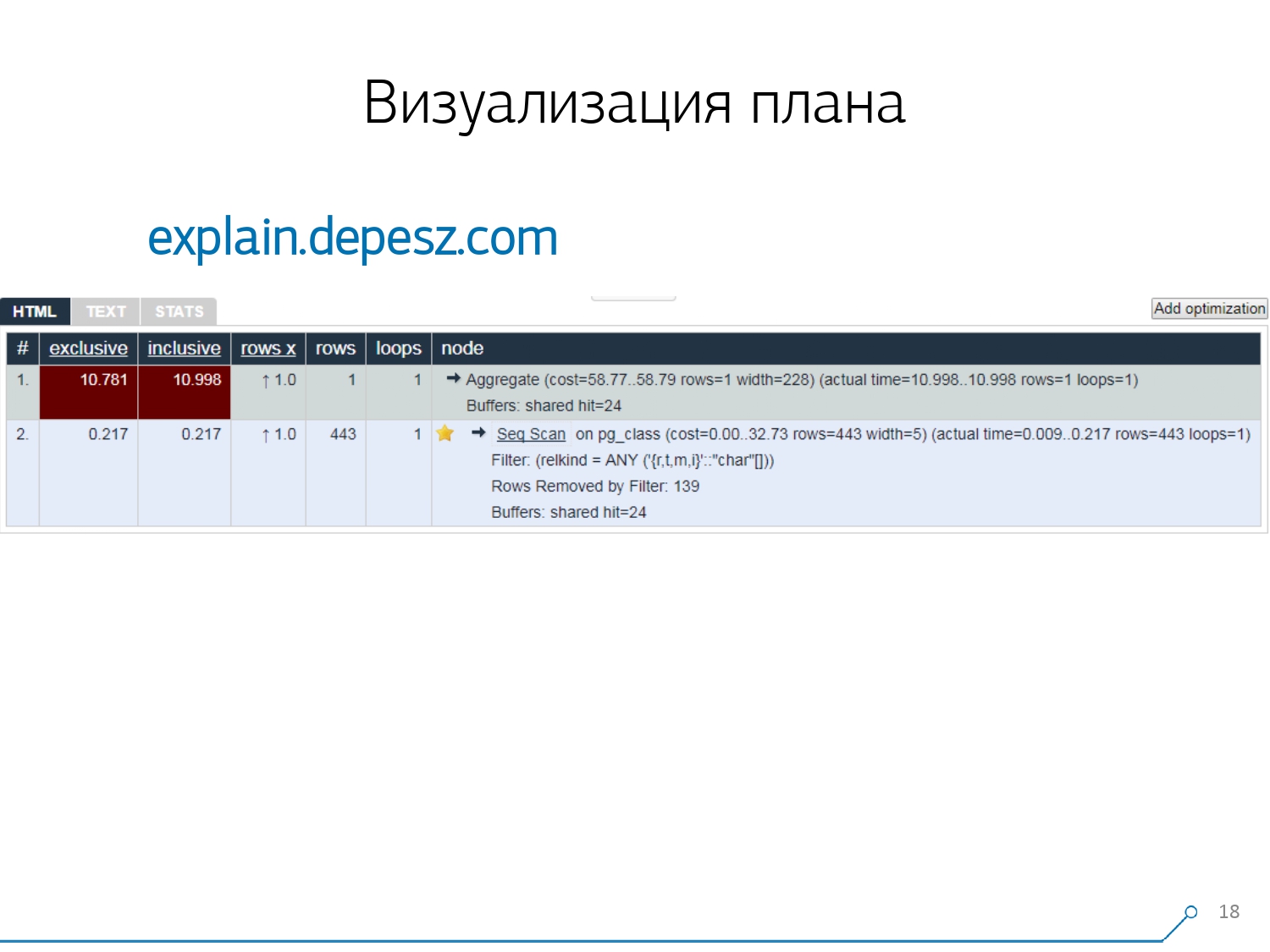 Primero fuimos "alrededor del mercado" - veamos en Internet lo que existe en general.Pero resultó que las soluciones relativamente "en vivo" que están más o menos desarrolladas, son muy pocas, literalmente, una cosa: explicar.depesz.com de Hubert Lubaczewski. En la entrada al campo "alimente" una representación textual del plan, le muestra una placa con los datos analizados:
Primero fuimos "alrededor del mercado" - veamos en Internet lo que existe en general.Pero resultó que las soluciones relativamente "en vivo" que están más o menos desarrolladas, son muy pocas, literalmente, una cosa: explicar.depesz.com de Hubert Lubaczewski. En la entrada al campo "alimente" una representación textual del plan, le muestra una placa con los datos analizados:- tiempo de trabajo del nodo adecuado
- tiempo total en todo el subárbol
- la cantidad de registros que se recuperaron y que se esperaba estadísticamente
- el propio cuerpo del nodo
Este servicio también tiene la capacidad de compartir el archivo de enlaces. Lanzaste tu plan allí y dijiste: "Oye, Vasya, aquí hay un enlace para ti, algo está mal allí". Pero hay algunos problemas menores.En primer lugar, una gran cantidad de copiar y pegar. Coges un trozo del tronco, lo pones allí, y una y otra vez.En segundo lugar, no hay un análisis de la cantidad de datos leídos , los mismos buffers que muestra
Pero hay algunos problemas menores.En primer lugar, una gran cantidad de copiar y pegar. Coges un trozo del tronco, lo pones allí, y una y otra vez.En segundo lugar, no hay un análisis de la cantidad de datos leídos , los mismos buffers que muestra EXPLAIN (ANALYZE, BUFFERS), aquí no vemos. Simplemente no sabe cómo desmontarlos, comprenderlos y trabajar con ellos. Cuando lee muchos datos y comprende que puede "descomponerse" incorrectamente en un disco y caché en la memoria, esta información es muy importante.El tercer punto negativo es el desarrollo muy débil de este proyecto. Los commits son muy pequeños, es bueno si cada seis meses, y el código en Perl.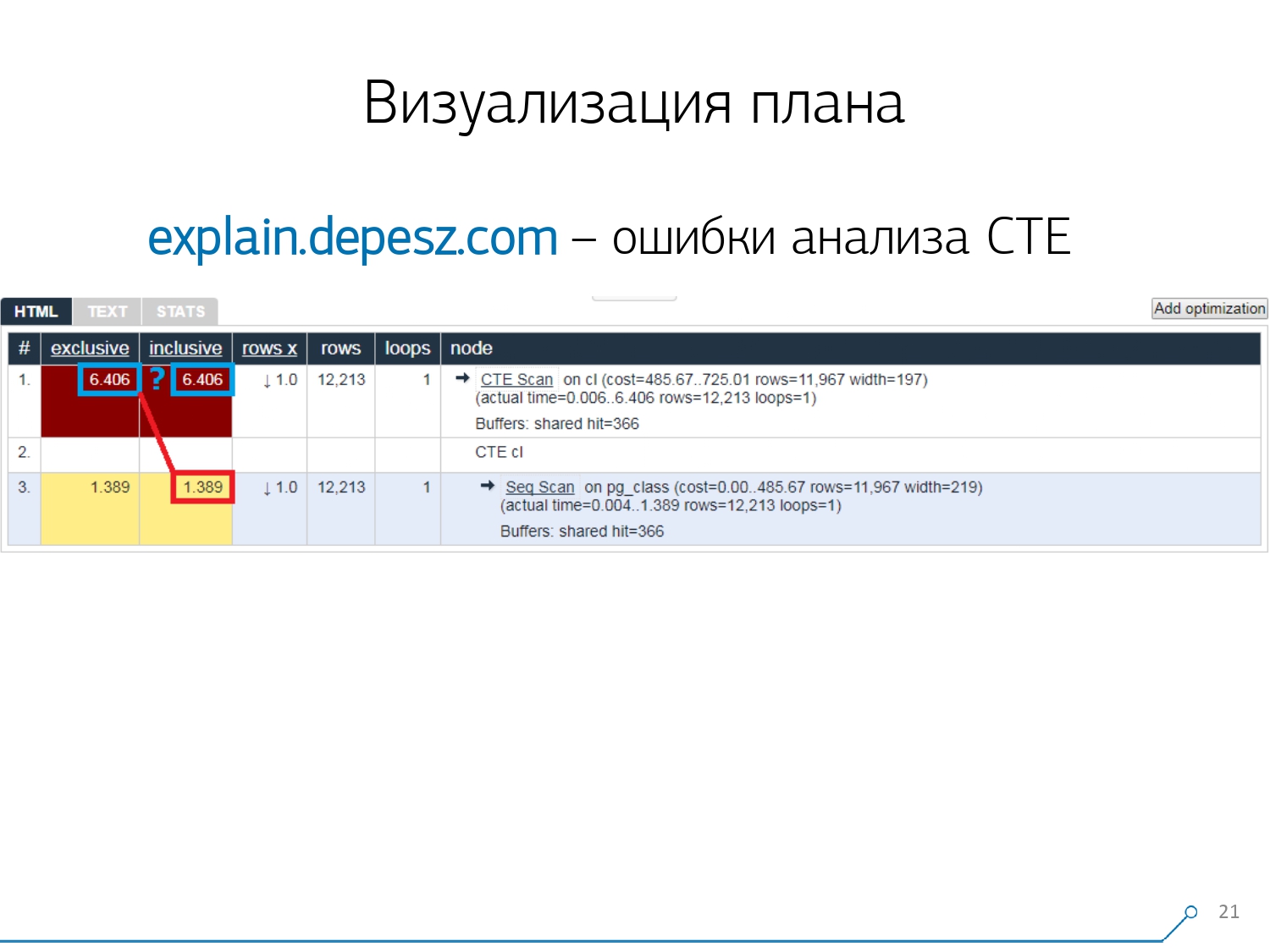 Pero todo esto es "letra", de alguna manera se podría vivir con ella, pero hay una cosa que nos ha alejado de este servicio. Estos son errores de análisis de Expresión de tabla común (CTE) y varios nodos dinámicos como InitPlan / SubPlan.Si cree en esta imagen, entonces tenemos que el tiempo de ejecución total de cada nodo individual es mayor que el tiempo de ejecución total de toda la solicitud. Es simple: el tiempo de generación de este CTE no se resta del nodo de escaneo CTE . Por lo tanto, ya no sabemos la respuesta correcta, cuánto tomó el escaneo CTE en sí.
Pero todo esto es "letra", de alguna manera se podría vivir con ella, pero hay una cosa que nos ha alejado de este servicio. Estos son errores de análisis de Expresión de tabla común (CTE) y varios nodos dinámicos como InitPlan / SubPlan.Si cree en esta imagen, entonces tenemos que el tiempo de ejecución total de cada nodo individual es mayor que el tiempo de ejecución total de toda la solicitud. Es simple: el tiempo de generación de este CTE no se resta del nodo de escaneo CTE . Por lo tanto, ya no sabemos la respuesta correcta, cuánto tomó el escaneo CTE en sí. Luego nos dimos cuenta de que era hora de escribir el nuestro: ¡hurra! Cada desarrollador dice: "Ahora escribiremos el nuestro, ¡será súper!"Tomaron una pila típica de servicios web: el núcleo en Node.js + Express, extrajeron Bootstrap y para hermosos diagramas - D3.js. Y nuestras expectativas estaban justificadas: recibimos el primer prototipo en 2 semanas:
Luego nos dimos cuenta de que era hora de escribir el nuestro: ¡hurra! Cada desarrollador dice: "Ahora escribiremos el nuestro, ¡será súper!"Tomaron una pila típica de servicios web: el núcleo en Node.js + Express, extrajeron Bootstrap y para hermosos diagramas - D3.js. Y nuestras expectativas estaban justificadas: recibimos el primer prototipo en 2 semanas:- propio analizador de planes
Es decir, ahora generalmente podemos analizar cualquier plan de los generados por PostgreSQL. - Análisis correcto de nodos dinámicos : CTE Scan, InitPlan, SubPlan
- Análisis de la distribución de los búferes : dónde se leen las páginas de datos de la memoria, de la caché local, de dónde proviene el disco
- visibilidad recibida
Para que no esté "en el registro" que esté "cavando", sino que vea el "enlace más débil" inmediatamente en la imagen.
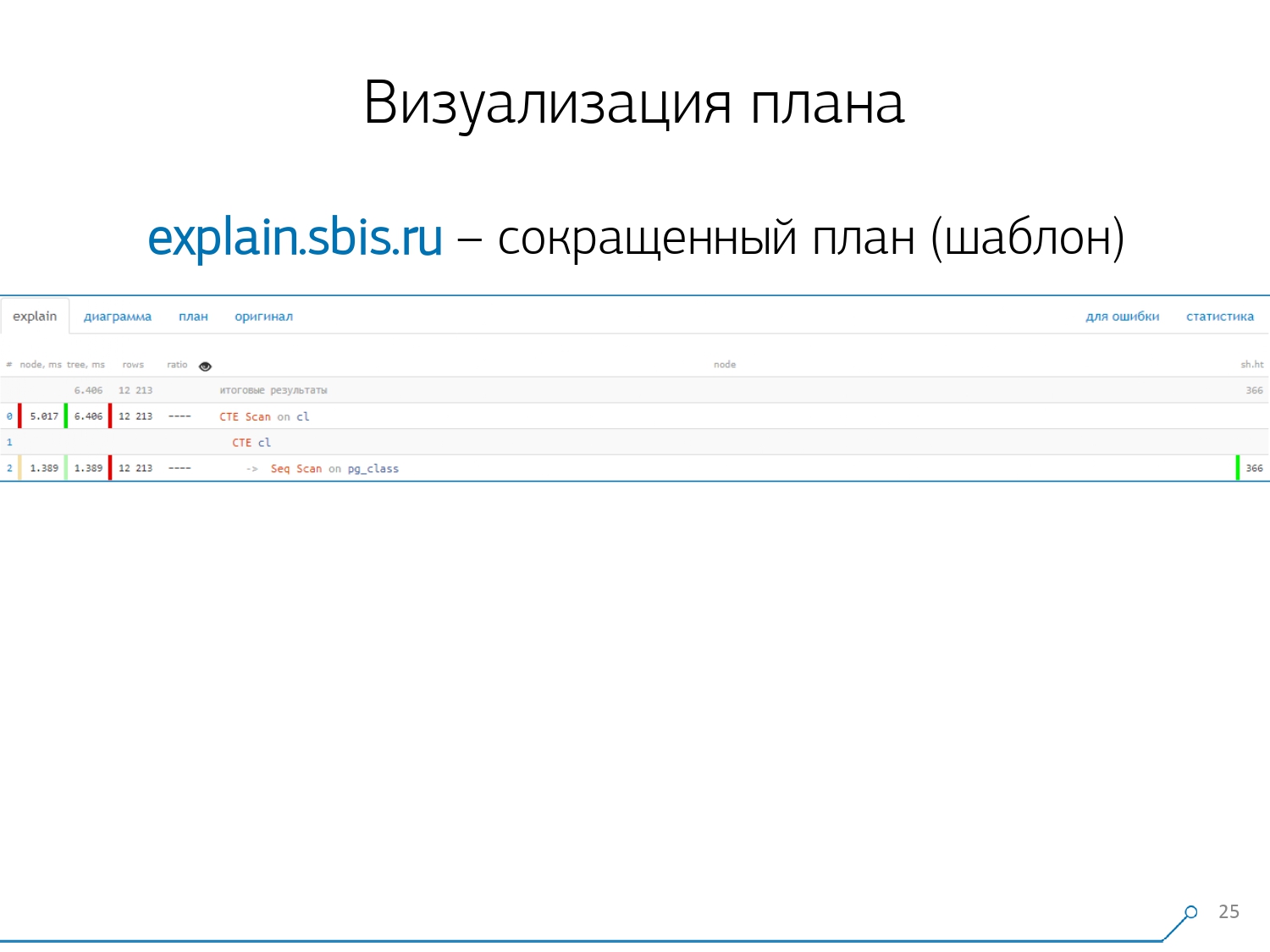 Obtuvimos algo como esto, inmediatamente con resaltado de sintaxis. Pero generalmente nuestros desarrolladores ya no están trabajando con una presentación completa del plan, sino con una presentación más corta. Después de todo, ya analizamos todos los dígitos y los lanzamos de izquierda a derecha, y dejamos solo la primera línea en el medio, qué tipo de nodo es: CTE Scan, CTE o Seq Scan generación por algún tipo de etiqueta.Esta vista abreviada es lo que llamamos la plantilla del plan .
Obtuvimos algo como esto, inmediatamente con resaltado de sintaxis. Pero generalmente nuestros desarrolladores ya no están trabajando con una presentación completa del plan, sino con una presentación más corta. Después de todo, ya analizamos todos los dígitos y los lanzamos de izquierda a derecha, y dejamos solo la primera línea en el medio, qué tipo de nodo es: CTE Scan, CTE o Seq Scan generación por algún tipo de etiqueta.Esta vista abreviada es lo que llamamos la plantilla del plan .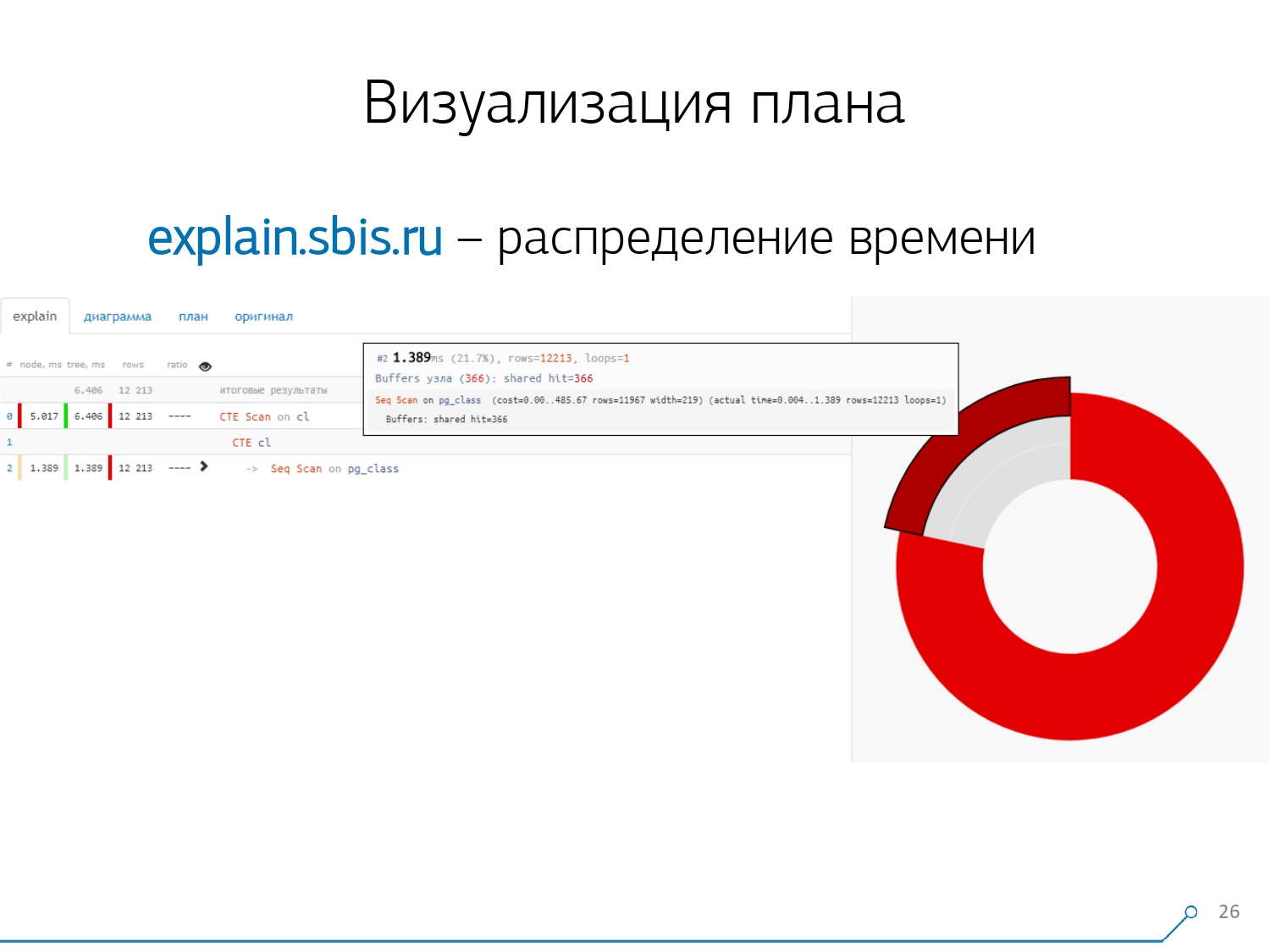 ¿Qué más sería conveniente? Sería conveniente ver qué proporción de qué nodo del tiempo total se nos asigna, y simplemente "pegó" el gráfico circular en el lateral .Señalamos el nodo y vemos: con nosotros, resulta que Seq Scan tomó menos de un cuarto de todo el tiempo, y los 3/4 restantes tomaron CTE Scan. ¡Horror! Este es un pequeño comentario sobre la "velocidad de disparo" de CTE Scan, si los usa activamente en sus consultas. No son muy rápidos: pierden incluso con el escaneo de tabla habitual. [artículo] [artículo]Pero, por lo general, estos diagramas son más interesantes, más complicados cuando señalamos inmediatamente un segmento y vemos, por ejemplo, que más de la mitad de las veces, algunos Seq Scan “comieron”. Además, había algún tipo de filtro en el interior, se arrojaron un montón de registros ... Puede lanzar esta imagen directamente al desarrollador y decir: "Vasya, ¡todo está mal contigo aquí! ¡Comprende, mira, algo anda mal!
¿Qué más sería conveniente? Sería conveniente ver qué proporción de qué nodo del tiempo total se nos asigna, y simplemente "pegó" el gráfico circular en el lateral .Señalamos el nodo y vemos: con nosotros, resulta que Seq Scan tomó menos de un cuarto de todo el tiempo, y los 3/4 restantes tomaron CTE Scan. ¡Horror! Este es un pequeño comentario sobre la "velocidad de disparo" de CTE Scan, si los usa activamente en sus consultas. No son muy rápidos: pierden incluso con el escaneo de tabla habitual. [artículo] [artículo]Pero, por lo general, estos diagramas son más interesantes, más complicados cuando señalamos inmediatamente un segmento y vemos, por ejemplo, que más de la mitad de las veces, algunos Seq Scan “comieron”. Además, había algún tipo de filtro en el interior, se arrojaron un montón de registros ... Puede lanzar esta imagen directamente al desarrollador y decir: "Vasya, ¡todo está mal contigo aquí! ¡Comprende, mira, algo anda mal! Naturalmente, hubo un "rastrillo".Lo primero que "pisaron" es el problema del redondeo. El tiempo de nodo de cada individuo en el plan se indica con una precisión de 1 μs. Y cuando el número de ciclos de nodos excede, por ejemplo, 1000, después de la ejecución PostgreSQL lo dividió "hasta", luego, en el cálculo inverso, obtenemos el tiempo total "en algún lugar entre 0,95 ms y 1,05 ms". Cuando la cuenta se gasta en microsegundos, nada todavía, pero cuando ya está en [mili] segundos, es necesario tener en cuenta esta información al "desvincular" recursos en los nodos del "quién tiene cuánto consumió a quién".
Naturalmente, hubo un "rastrillo".Lo primero que "pisaron" es el problema del redondeo. El tiempo de nodo de cada individuo en el plan se indica con una precisión de 1 μs. Y cuando el número de ciclos de nodos excede, por ejemplo, 1000, después de la ejecución PostgreSQL lo dividió "hasta", luego, en el cálculo inverso, obtenemos el tiempo total "en algún lugar entre 0,95 ms y 1,05 ms". Cuando la cuenta se gasta en microsegundos, nada todavía, pero cuando ya está en [mili] segundos, es necesario tener en cuenta esta información al "desvincular" recursos en los nodos del "quién tiene cuánto consumió a quién". El segundo punto, más complejo, es la distribución de recursos (esos mismos buffers) entre nodos dinámicos. Esto nos costó las primeras 2 semanas en el prototipo más el plus de la semana 4.Obtener este problema es bastante simple: creamos un CTE y supuestamente estamos leyendo algo en él. De hecho, PostgreSQL es inteligente y no leerá nada allí. Luego tomamos el primer registro y los primeros cien del mismo CTE.
El segundo punto, más complejo, es la distribución de recursos (esos mismos buffers) entre nodos dinámicos. Esto nos costó las primeras 2 semanas en el prototipo más el plus de la semana 4.Obtener este problema es bastante simple: creamos un CTE y supuestamente estamos leyendo algo en él. De hecho, PostgreSQL es inteligente y no leerá nada allí. Luego tomamos el primer registro y los primeros cien del mismo CTE.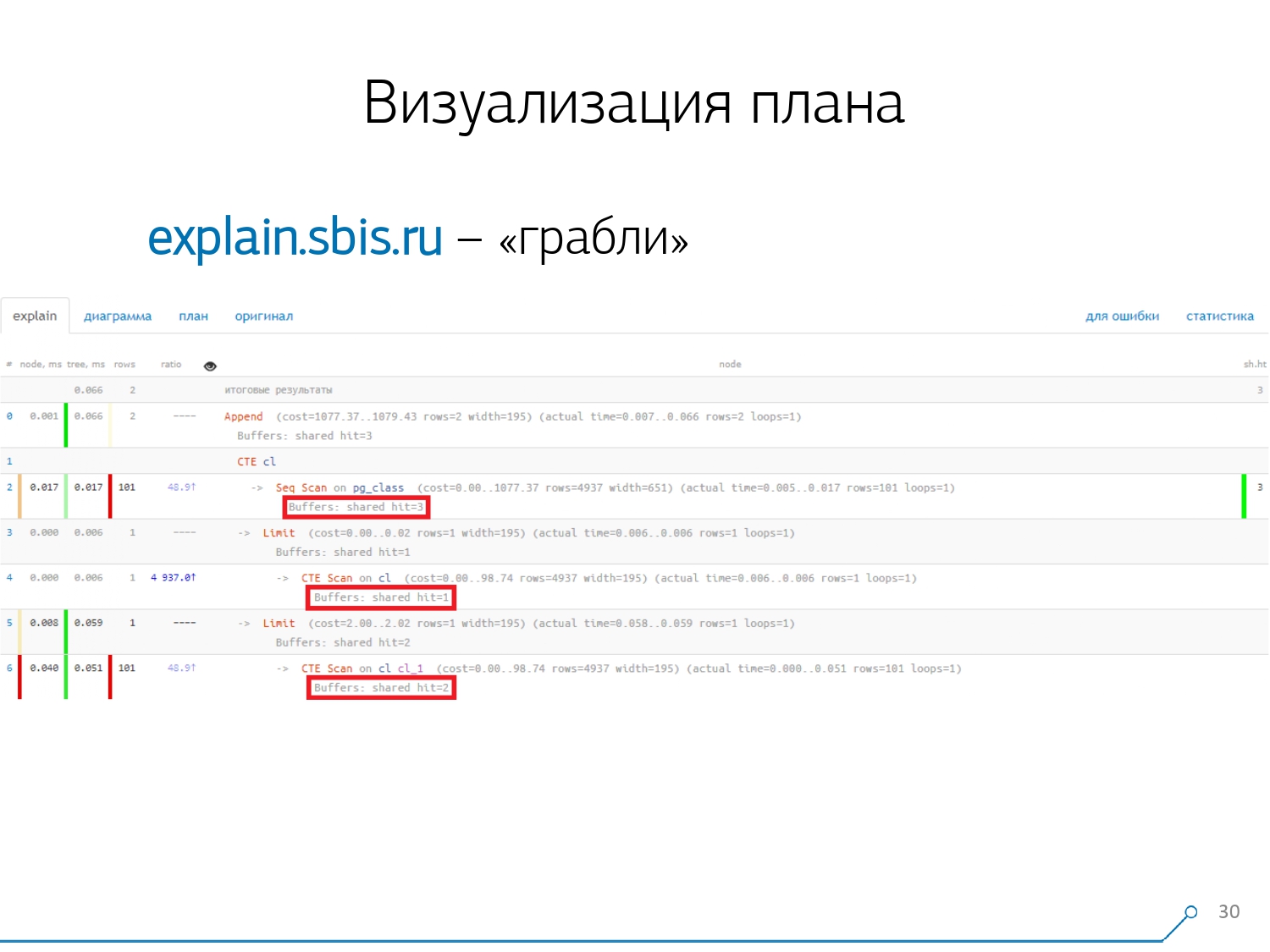 Observamos el plan y entendemos: extraño, tenemos 3 buffers (páginas de datos) que se "consumieron" en Seq Scan, otro 1 en CTE Scan y 2 más en el segundo CTE Scan. Es decir, si todo se resume simplemente, obtenemos 6, ¡pero de la placa solo leemos 3! CTE Scan no lee nada de ninguna parte, pero funciona directamente con la memoria de proceso. Es decir, ¡claramente hay algo mal aquí!De hecho, resulta que aquí todas esas 3 páginas de datos que se solicitaron a Seq Scan, primero 1 pidieron el primer CTE Scan, y luego el segundo, y leyeron otras 2. Es decir, se leyeron 3 páginas en total datos, no 6.
Observamos el plan y entendemos: extraño, tenemos 3 buffers (páginas de datos) que se "consumieron" en Seq Scan, otro 1 en CTE Scan y 2 más en el segundo CTE Scan. Es decir, si todo se resume simplemente, obtenemos 6, ¡pero de la placa solo leemos 3! CTE Scan no lee nada de ninguna parte, pero funciona directamente con la memoria de proceso. Es decir, ¡claramente hay algo mal aquí!De hecho, resulta que aquí todas esas 3 páginas de datos que se solicitaron a Seq Scan, primero 1 pidieron el primer CTE Scan, y luego el segundo, y leyeron otras 2. Es decir, se leyeron 3 páginas en total datos, no 6.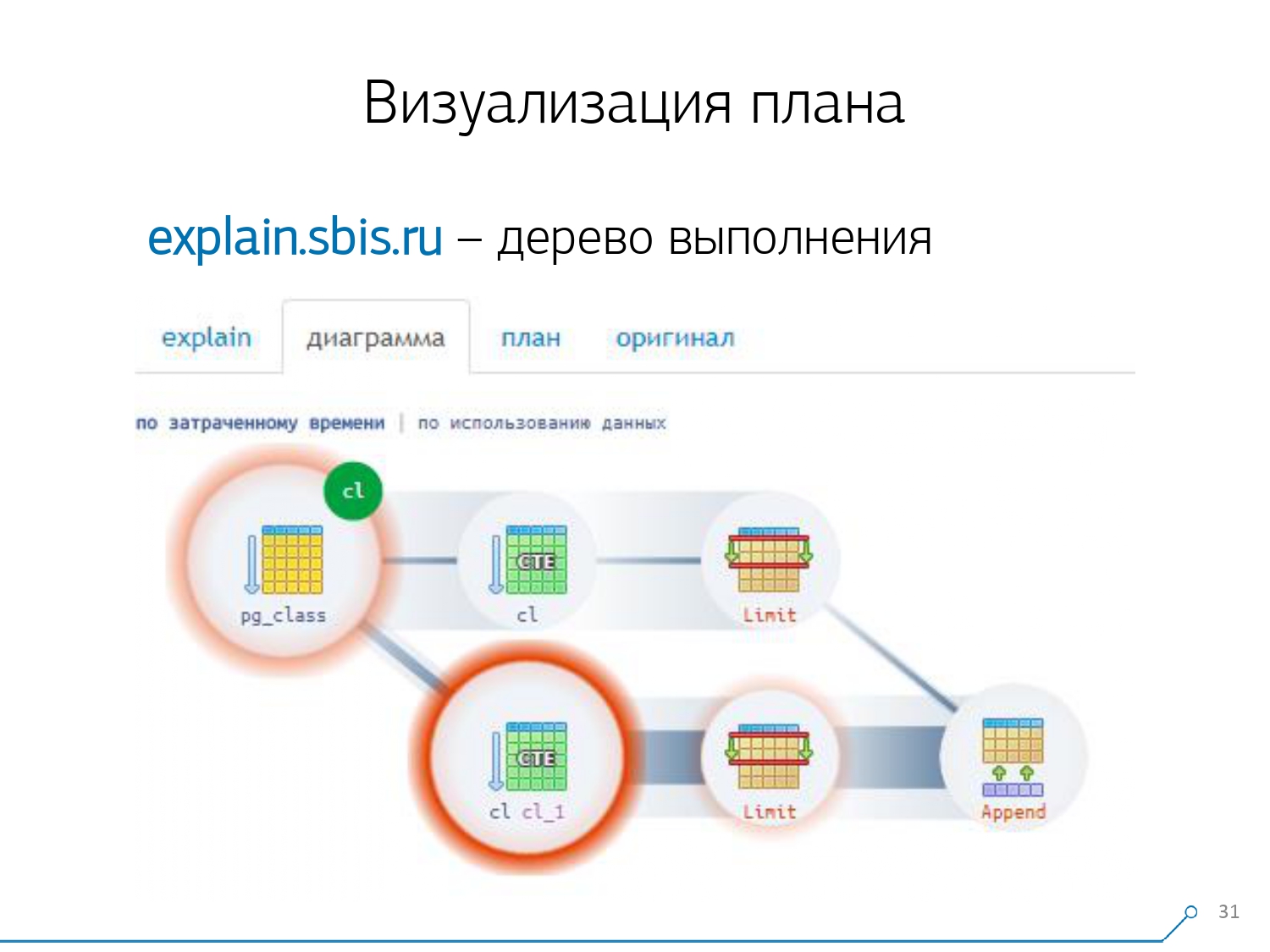 Y esta imagen nos llevó a comprender que la implementación del plan ya no es un árbol, sino solo una especie de gráfico acíclico. Y obtuvimos un cuadro como este para que entendamos "de dónde vino en absoluto". Es decir, aquí creamos un CTE de pg_class, y lo solicitamos dos veces, y casi todo el tiempo nos llevó a la sucursal cuando lo solicitamos por segunda vez. Está claro que leer el registro 101 es mucho más costoso que solo el primero de la tableta.
Y esta imagen nos llevó a comprender que la implementación del plan ya no es un árbol, sino solo una especie de gráfico acíclico. Y obtuvimos un cuadro como este para que entendamos "de dónde vino en absoluto". Es decir, aquí creamos un CTE de pg_class, y lo solicitamos dos veces, y casi todo el tiempo nos llevó a la sucursal cuando lo solicitamos por segunda vez. Está claro que leer el registro 101 es mucho más costoso que solo el primero de la tableta. Exhalamos por un rato. Ellos dijeron: “Ahora, Neo, ¡sabes kung fu! Ahora nuestra experiencia está en tu pantalla. Ahora puedes usarlo. [artículo]
Exhalamos por un rato. Ellos dijeron: “Ahora, Neo, ¡sabes kung fu! Ahora nuestra experiencia está en tu pantalla. Ahora puedes usarlo. [artículo]Consolidación de registro
Nuestros 1000 desarrolladores dieron un suspiro de alivio. Pero entendimos que solo tenemos cientos de servidores de "batalla", y todo este "copiar y pegar" por parte de los desarrolladores no es del todo conveniente. Nos dimos cuenta de que necesitábamos recogerlo nosotros mismos. En general, hay un módulo regular que puede recopilar estadísticas, sin embargo, también debe activarse en la configuración; este es el módulo pg_stat_statements . Pero no nos convenía.En primer lugar, asigna diferentes QueryId a las mismas consultas en diferentes esquemas dentro de la misma base de datos . Es decir, si primero realiza
En general, hay un módulo regular que puede recopilar estadísticas, sin embargo, también debe activarse en la configuración; este es el módulo pg_stat_statements . Pero no nos convenía.En primer lugar, asigna diferentes QueryId a las mismas consultas en diferentes esquemas dentro de la misma base de datos . Es decir, si primero realiza SET search_path = '01'; SELECT * FROM user LIMIT 1;, y luego SET search_path = '02';la misma solicitud, las estadísticas de este módulo tendrán entradas diferentes, y no podré recopilar estadísticas generales precisamente en el contexto de este perfil de solicitud, sin tener en cuenta los esquemas.El segundo punto que nos impidió usarlo es la falta de planes . Es decir, no hay un plan, solo existe la solicitud en sí. Vemos lo que se desaceleró, pero no entendemos por qué. Y aquí volvemos al problema de un conjunto de datos que cambia rápidamente.Y el último punto es la falta de "hechos" . Es decir, es imposible abordar una instancia específica de ejecución de consulta: no está allí, solo hay estadísticas agregadas. Aunque es posible trabajar con él, es muy difícil.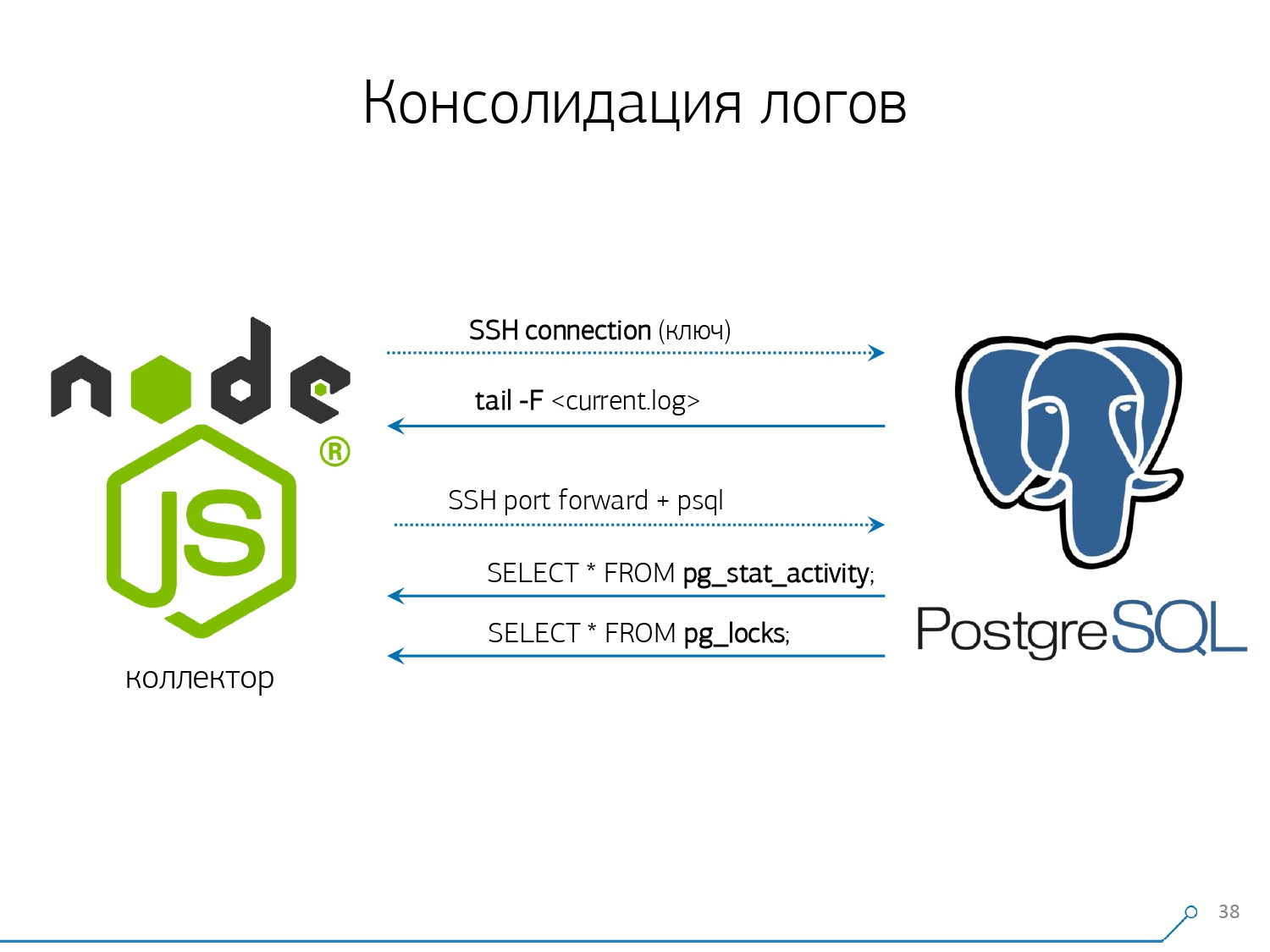 Por lo tanto, decidimos luchar contra "copiar y pegar" y comenzamos a escribir un coleccionista .El recopilador está conectado a través de SSH, "extrae" una conexión segura al servidor con la base de datos utilizando el certificado y se
Por lo tanto, decidimos luchar contra "copiar y pegar" y comenzamos a escribir un coleccionista .El recopilador está conectado a través de SSH, "extrae" una conexión segura al servidor con la base de datos utilizando el certificado y se tail -F"aferra" al archivo de registro. Entonces en esta sesiónobtenemos un "espejo" completo del archivo de registro completo que genera el servidor. La carga en el servidor en sí es mínima, porque no analizamos nada allí, simplemente reflejamos el tráfico.Como ya comenzamos a escribir la interfaz en Node.js, continuamos escribiendo el recopilador en ella. Y esta tecnología valió la pena, porque es muy conveniente usar JavaScript para trabajar con datos de texto mal formateados, que es el registro. Y la propia infraestructura de Node.js como plataforma de back-end le permite trabajar de manera fácil y conveniente con conexiones de red y, de hecho, con algún tipo de flujo de datos.En consecuencia, "extraemos" dos conexiones: la primera es "escuchar" el registro en sí y llevarlo a nosotros mismos, y la segunda es pedir periódicamente la base de datos. "Pero en el registro llegó que la placa con el oid 123 estaba bloqueada", pero no le dice nada al desarrollador, y sería bueno preguntarle a la base de datos "¿Qué es OID = 123 después de todo?" Entonces, periódicamente le pedimos a la base algo que aún no sabemos en casa. "¡Simplemente no se tenía en cuenta, hay una especie de abejas parecidas a elefantes! ..." Comenzamos a desarrollar este sistema cuando queríamos monitorear 10 servidores. El más crítico en nuestro entendimiento, en el que hubo algunos problemas que fueron difíciles de tratar. Pero durante el primer trimestre obtuvimos cien para el monitoreo, porque el sistema "entró", todos lo querían, todos estaban cómodos.Todo esto debe agregarse, el flujo de datos es grande, activo. En realidad, controlamos lo que podemos manejar y luego lo usamos. También usamos PostgreSQL como un almacén de datos. Pero nada es más rápido para "verter" datos en él que
"¡Simplemente no se tenía en cuenta, hay una especie de abejas parecidas a elefantes! ..." Comenzamos a desarrollar este sistema cuando queríamos monitorear 10 servidores. El más crítico en nuestro entendimiento, en el que hubo algunos problemas que fueron difíciles de tratar. Pero durante el primer trimestre obtuvimos cien para el monitoreo, porque el sistema "entró", todos lo querían, todos estaban cómodos.Todo esto debe agregarse, el flujo de datos es grande, activo. En realidad, controlamos lo que podemos manejar y luego lo usamos. También usamos PostgreSQL como un almacén de datos. Pero nada es más rápido para "verter" datos en él que COPYtodavía no hay un operador .Pero simplemente "verter" los datos no es realmente nuestra tecnología. Porque si tiene alrededor de 50 mil solicitudes por segundo en un centenar de servidores, esto generará entre 100 y 150 GB de registros por día. Por lo tanto, tuvimos que cuidadosamente "ver" la base.En primer lugar, hicimos la partición todos los días , porque, en general, a nadie le interesa la correlación entre los días. ¿Cuál es la diferencia que tuvo ayer, si esta noche lanzó una nueva versión de la aplicación y algunas estadísticas nuevas?En segundo lugar, aprendimos (nos vimos obligados) a escribir muy, muy rápidamente usandoCOPY . Es decir, no solo COPYporque es más rápido INSERT, sino aún más rápido. El tercer punto: tuve que abandonar los disparadores, respectivamente, y de Foreign Keys . Es decir, no tenemos integridad absolutamente referencial. Porque si tiene una tabla en la que hay un par de FK, y dice en la estructura de la base de datos que "aquí hay una entrada de registro se refiere a FK, por ejemplo, un grupo de registros", entonces cuando lo inserta, PostgreSQL no tiene nada más cómo tomar y ejecutar honestamente
El tercer punto: tuve que abandonar los disparadores, respectivamente, y de Foreign Keys . Es decir, no tenemos integridad absolutamente referencial. Porque si tiene una tabla en la que hay un par de FK, y dice en la estructura de la base de datos que "aquí hay una entrada de registro se refiere a FK, por ejemplo, un grupo de registros", entonces cuando lo inserta, PostgreSQL no tiene nada más cómo tomar y ejecutar honestamente SELECT 1 FROM master_fk1_table WHERE ...con el identificador que está intentando insertar, solo para verificar que esta entrada está allí, que no está "rompiendo" esta clave externa con su inserción.Obtenemos en lugar de un registro en la tabla de destino y sus índices, otro plus de lectura de todas las tablas a las que se refiere. Y no lo necesitamos en absoluto: nuestra tarea es anotar tanto como sea posible y lo más rápido posible con la menor carga. Así que FK - ¡abajo!El siguiente punto es la agregación y el hash. Inicialmente, se implementaron en nuestra base de datos; después de todo, es conveniente inmediatamente, cuando llega una grabación, hacer "más uno" en algún tipo de placa justo en el gatillo . Es bueno, conveniente, pero lo mismo es malo: inserte un registro, pero se ve obligado a leer y escribir otra cosa desde otra tabla. Además, no solo eso, leer y escribir, sino también hacerlo siempre.Ahora imagine que tiene una placa en la que simplemente cuenta el número de solicitudes que pasaron en un host en particular:+1, +1, +1, ..., +1. Y usted, en principio, no lo necesita: todo esto puede resumirse en la memoria del recopilador y enviarse a la base de datos a la vez +10.Sí, en caso de algunos fallos de funcionamiento, su integridad lógica puede "desmoronarse", pero este es un caso casi irreal: porque tiene un servidor normal, tiene una batería en el controlador, tiene un registro de transacciones, un registro en el sistema de archivos ... En general, no vale la pena. No vale la pena la pérdida de productividad que obtiene debido al trabajo de los disparadores / FK, los costos en los que incurre al mismo tiempo.Lo mismo con el hash. Una determinada solicitud vuela hacia usted, usted calcula un determinado identificador de la base de datos a partir de ella, escribe en la base de datos y luego se la cuenta a todos. Todo está bien, hasta que en el momento de la grabación, una segunda persona se acerca a ti y quiere grabarlo, y tienes un bloqueo, y esto ya es malo. Por lo tanto, si puede eliminar la generación de algunos ID en el cliente (en relación con la base de datos), es mejor hacerlo.Estábamos perfectamente preparados para usar MD5 a partir del texto: una solicitud, un plan, una plantilla, ... Lo calculamos en el lado del recopilador y "vertimos" la ID ya hecha en la base de datos. La longitud de MD5 y la partición diaria nos permiten no preocuparnos por posibles colisiones.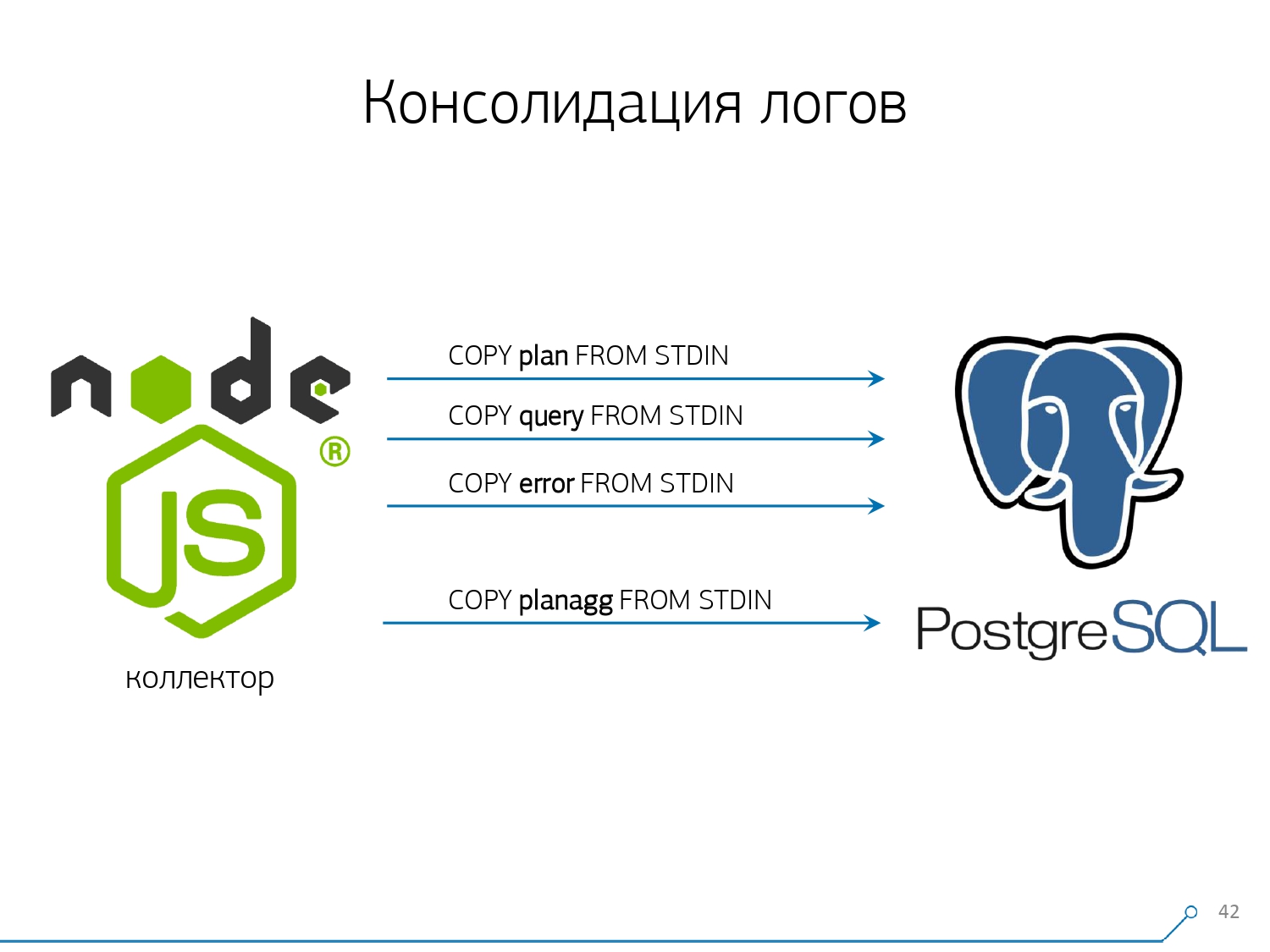 Pero para grabar todo esto rápidamente, necesitábamos modificar el procedimiento de grabación en sí.¿Cómo sueles escribir datos? Tenemos algún tipo de conjunto de datos, lo descomponemos en varias tablas y luego COPIAMOS - primero en el primero, luego en el segundo, en el tercero ... Es inconveniente, porque escribimos un flujo de datos en tres pasos secuencialmente. Desagradable. ¿Es posible hacerlo más rápido? ¡Lata!Para hacer esto, es suficiente descomponer estos flujos en paralelo entre sí. Resulta que tenemos errores, solicitudes, plantillas, bloqueos, volando en flujos separados ... - y lo escribimos todo en paralelo. Para hacer esto, simplemente mantenga el canal COPY permanentemente abierto en cada tabla de destino individual .
Pero para grabar todo esto rápidamente, necesitábamos modificar el procedimiento de grabación en sí.¿Cómo sueles escribir datos? Tenemos algún tipo de conjunto de datos, lo descomponemos en varias tablas y luego COPIAMOS - primero en el primero, luego en el segundo, en el tercero ... Es inconveniente, porque escribimos un flujo de datos en tres pasos secuencialmente. Desagradable. ¿Es posible hacerlo más rápido? ¡Lata!Para hacer esto, es suficiente descomponer estos flujos en paralelo entre sí. Resulta que tenemos errores, solicitudes, plantillas, bloqueos, volando en flujos separados ... - y lo escribimos todo en paralelo. Para hacer esto, simplemente mantenga el canal COPY permanentemente abierto en cada tabla de destino individual . Es decir, el colector siempre tiene una secuenciaen el que puedo escribir los datos que necesito. Pero para que la base de datos vea estos datos y alguien no se quede bloqueado, esperando que se escriban estos datos, COPY debe interrumpirse con cierta periodicidad . Para nosotros, un período del orden de 100 ms resultó ser el más efectivo: cierre e inmediatamente vuelva a abrirlo en la misma mesa. Y si no tenemos una transmisión en algunos picos, entonces agrupamos a un cierto límite.Además, descubrimos que para dicho perfil de carga, cualquier agregación cuando se recopilan registros en paquetes es mala. El mal clásico está
Es decir, el colector siempre tiene una secuenciaen el que puedo escribir los datos que necesito. Pero para que la base de datos vea estos datos y alguien no se quede bloqueado, esperando que se escriban estos datos, COPY debe interrumpirse con cierta periodicidad . Para nosotros, un período del orden de 100 ms resultó ser el más efectivo: cierre e inmediatamente vuelva a abrirlo en la misma mesa. Y si no tenemos una transmisión en algunos picos, entonces agrupamos a un cierto límite.Además, descubrimos que para dicho perfil de carga, cualquier agregación cuando se recopilan registros en paquetes es mala. El mal clásico está INSERT ... VALUESmás allá de 1000 registros. Porque en este momento tiene un pico de grabación en los medios, y todos los que intenten escribir algo en el disco esperarán.Para deshacerse de tales anomalías, simplemente no agregue nada, no proteja en absoluto . Y si se produce el almacenamiento en búfer en el disco (afortunadamente, la API Stream en Node.js le permite averiguarlo): posponga esta conexión. Ahí es cuando llega el evento de que es gratis nuevamente: escríbalo desde la cola acumulada. Mientras tanto, está ocupado: tome el próximo libre del grupo y escríbalo.Antes de implementar este enfoque para la grabación de datos, teníamos aproximadamente operaciones de escritura 4K, y de esta manera redujimos la carga en 4 veces. Ahora han crecido otras 6 veces debido a las nuevas bases observables, hasta 100 MB / s. Y ahora almacenamos registros durante los últimos 3 meses en una cantidad de aproximadamente 10-15 TB, con la esperanza de que en solo tres meses cualquier desarrollador pueda resolver cualquier problema.Entendemos los problemas
Pero solo recopilar todos estos datos es bueno, útil, apropiado, pero no suficiente: debe comprenderlo. Porque son millones de planes diferentes por día. Pero millones son incontrolables, primero debe hacer "menos". Y, antes que nada, es necesario decidir cómo organizará este "más pequeño".Hemos identificado por nosotros mismos tres puntos clave:
Pero millones son incontrolables, primero debe hacer "menos". Y, antes que nada, es necesario decidir cómo organizará este "más pequeño".Hemos identificado por nosotros mismos tres puntos clave:- quién envió esta solicitud
, es decir, desde qué aplicación "voló": interfaz web, back-end, sistema de pago u otra cosa. - ¿Dónde sucedió esto?
En qué servidor en particular. Porque si tiene varios servidores en una aplicación, y de repente uno "embotado" (porque el "disco se ha podrido", "pérdida de memoria", algún otro problema), entonces necesita abordar específicamente el servidor. - cómo se manifestó el problema de una forma u otra
Para comprender “quién” nos envió la solicitud, utilizamos una herramienta regular: establecer una variable de sesión: SET application_name = '{bl-host}:{bl-method}';enviar el nombre de host de la lógica de negocios desde la cual se realiza la solicitud y el nombre del método o aplicación que la inició.Después de pasar al "propietario" de la solicitud, debe mostrarse en el registro, para esto configuramos la variable log_line_prefix = ' %m [%p:%v] [%d] %r %a'. Cualquier persona interesada puede ver en el manual lo que todo esto significa. Resulta que vemos en el registro:- hora
- identificadores de procesos y transacciones
- nombre base
- IP de la persona que envió esta solicitud
- y nombre del método
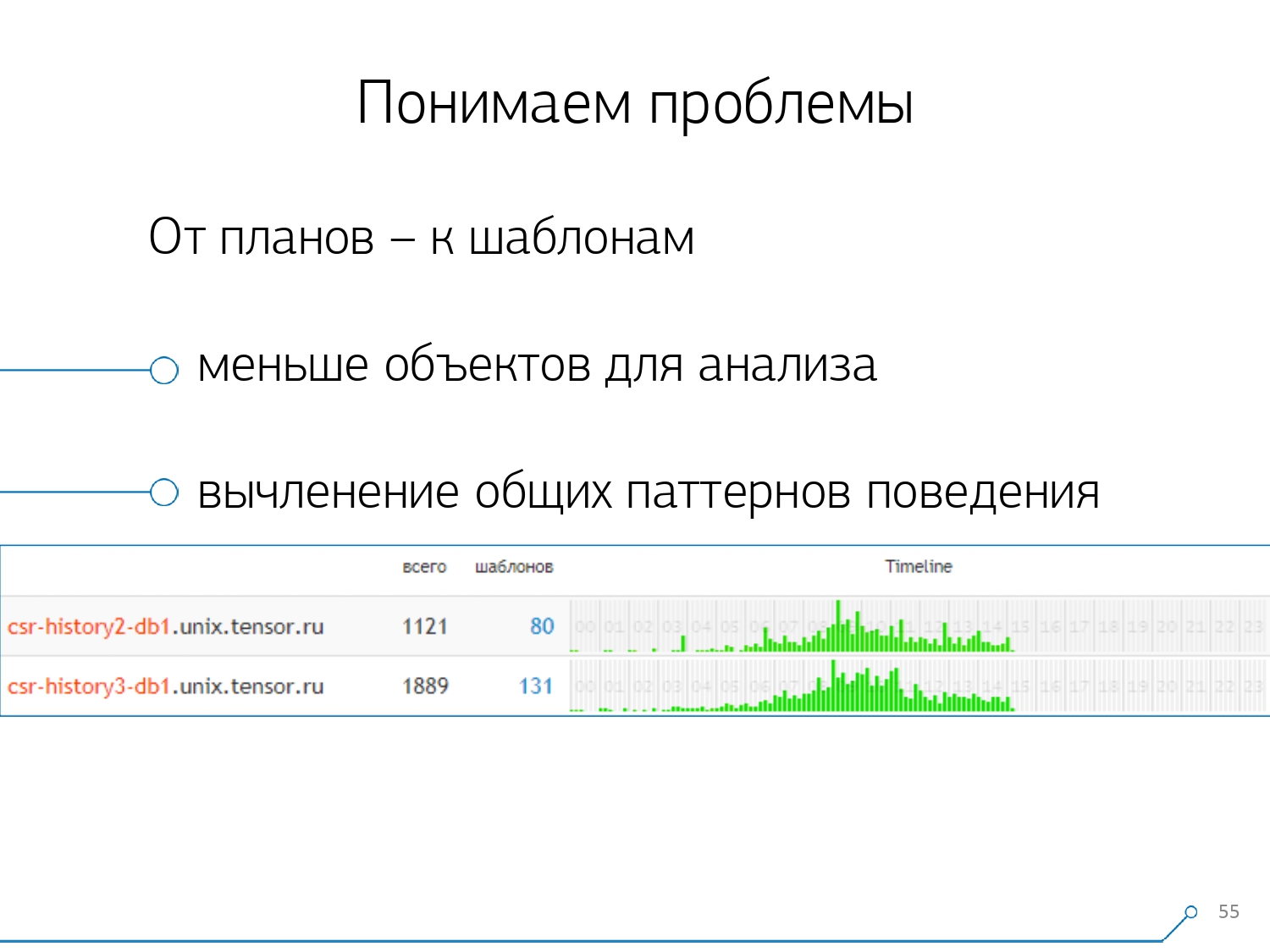 Luego nos dimos cuenta de que no es muy interesante observar la correlación de una solicitud entre diferentes servidores. Ocurre con poca frecuencia cuando tiene una aplicación que igualmente daña aquí y allá. Pero incluso si es lo mismo, mire cualquiera de estos servidores.Entonces, la sección “un servidor - un día” resultó ser suficiente para cualquier análisis.La primera sección analítica es la "plantilla" , una forma abreviada de presentación del plan, libre de todos los indicadores numéricos. La segunda sección es la aplicación o método, y la tercera es el nodo específico del plan que nos causó problemas.Cuando pasamos de instancias específicas a plantillas, inmediatamente recibimos dos ventajas:
Luego nos dimos cuenta de que no es muy interesante observar la correlación de una solicitud entre diferentes servidores. Ocurre con poca frecuencia cuando tiene una aplicación que igualmente daña aquí y allá. Pero incluso si es lo mismo, mire cualquiera de estos servidores.Entonces, la sección “un servidor - un día” resultó ser suficiente para cualquier análisis.La primera sección analítica es la "plantilla" , una forma abreviada de presentación del plan, libre de todos los indicadores numéricos. La segunda sección es la aplicación o método, y la tercera es el nodo específico del plan que nos causó problemas.Cuando pasamos de instancias específicas a plantillas, inmediatamente recibimos dos ventajas:
, .
, «» - , . , - , , , — , , — , , . , , .
 El resto de los métodos se basan en los indicadores que extraemos del plan: cuántas veces se produjo dicho patrón, el tiempo total y promedio, la cantidad de datos leídos del disco y la cantidad de la memoria ...Porque, por ejemplo, usted llega a la página de análisis por host, vea: algo demasiado en el disco para leer el comienzo. El disco del servidor no funciona, ¿y quién lee de él?Y puede ordenar por cualquier columna y decidir con qué se enfrentará en este momento: con la carga en el procesador o el disco, o con el número total de solicitudes ... Ordenado, se veía "superior", reparado, lanzó una nueva versión de la aplicación.[video conferencia]Y de inmediato puede ver diferentes aplicaciones que vienen con la misma plantilla de una solicitud como
El resto de los métodos se basan en los indicadores que extraemos del plan: cuántas veces se produjo dicho patrón, el tiempo total y promedio, la cantidad de datos leídos del disco y la cantidad de la memoria ...Porque, por ejemplo, usted llega a la página de análisis por host, vea: algo demasiado en el disco para leer el comienzo. El disco del servidor no funciona, ¿y quién lee de él?Y puede ordenar por cualquier columna y decidir con qué se enfrentará en este momento: con la carga en el procesador o el disco, o con el número total de solicitudes ... Ordenado, se veía "superior", reparado, lanzó una nueva versión de la aplicación.[video conferencia]Y de inmediato puede ver diferentes aplicaciones que vienen con la misma plantilla de una solicitud comoSELECT * FROM users WHERE login = 'Vasya'. Frontend, backend, procesamiento ... Y te preguntas por qué el usuario debería leer el procesamiento si no interactúa con él.La forma opuesta es ver inmediatamente desde la aplicación lo que está haciendo. Por ejemplo, una interfaz es esto, esto, esto y esto una vez por hora (solo ayuda la línea de tiempo). Y de inmediato surge la pregunta: parece que no es asunto del front-end hacer algo una vez por hora ... Después de un tiempo, nos dimos cuenta de que carecíamos de estadísticas agregadas en términos de nodos del plan . Aislamos de los planes solo aquellos nodos que hacen algo con los datos de las propias tablas (leerlos / escribirlos por índice o no). De hecho, en relación con la imagen anterior, solo se agrega un aspecto: cuántos registros nos trajo este nodo y cuántos cayó (Filas eliminadas por filtro).No tiene un índice adecuado en la placa, lo solicita, vuela más allá del índice, cae en Seq Scan ... ha filtrado todos los registros excepto uno. ¿Y por qué necesita 100 millones de registros filtrados por día, es mejor rodar el índice?
Después de un tiempo, nos dimos cuenta de que carecíamos de estadísticas agregadas en términos de nodos del plan . Aislamos de los planes solo aquellos nodos que hacen algo con los datos de las propias tablas (leerlos / escribirlos por índice o no). De hecho, en relación con la imagen anterior, solo se agrega un aspecto: cuántos registros nos trajo este nodo y cuántos cayó (Filas eliminadas por filtro).No tiene un índice adecuado en la placa, lo solicita, vuela más allá del índice, cae en Seq Scan ... ha filtrado todos los registros excepto uno. ¿Y por qué necesita 100 millones de registros filtrados por día, es mejor rodar el índice? Después de examinar todos los planes por nodos, nos dimos cuenta de que hay algunas estructuras típicas en los planes que probablemente parezcan sospechosas. Y sería bueno decirle al desarrollador: "Amigo, aquí primero lees por índice, luego ordenas y luego cortas", como regla, hay un registro.Todos los que escribieron consultas con este patrón probablemente se encontraron con: "Dame el último pedido para Vasya, su fecha" Y si no tienes un índice por fecha, o el índice utilizado no tiene una fecha, entonces sigue exactamente ese "rastrillo" y pisa .Pero sabemos que esto es un "rastrillo", entonces, ¿por qué no decirle inmediatamente al desarrollador qué debe hacer? En consecuencia, al abrir el plan ahora, nuestro desarrollador ve de inmediato una hermosa imagen con indicaciones, donde se le dice de inmediato: "Tienes problemas aquí y aquí, pero se resuelven de un modo a otro".Como resultado, la cantidad de experiencia que se necesitaba para resolver problemas al principio y ahora ha disminuido significativamente. Aquí tenemos esa herramienta.
Después de examinar todos los planes por nodos, nos dimos cuenta de que hay algunas estructuras típicas en los planes que probablemente parezcan sospechosas. Y sería bueno decirle al desarrollador: "Amigo, aquí primero lees por índice, luego ordenas y luego cortas", como regla, hay un registro.Todos los que escribieron consultas con este patrón probablemente se encontraron con: "Dame el último pedido para Vasya, su fecha" Y si no tienes un índice por fecha, o el índice utilizado no tiene una fecha, entonces sigue exactamente ese "rastrillo" y pisa .Pero sabemos que esto es un "rastrillo", entonces, ¿por qué no decirle inmediatamente al desarrollador qué debe hacer? En consecuencia, al abrir el plan ahora, nuestro desarrollador ve de inmediato una hermosa imagen con indicaciones, donde se le dice de inmediato: "Tienes problemas aquí y aquí, pero se resuelven de un modo a otro".Como resultado, la cantidad de experiencia que se necesitaba para resolver problemas al principio y ahora ha disminuido significativamente. Aquí tenemos esa herramienta.
Source: https://habr.com/ru/post/undefined/
All Articles