Casos para utilizar herramientas de análisis de anomalías de red: detección de fugas
En uno de los eventos, se produjo una discusión interesante sobre la utilidad de las soluciones de la clase NTA (Network Traffic Analysis), que, utilizando la infraestructura de red de telemetría de Netflow (u otros protocolos de flujo), permite detectar una amplia gama de ataques. Mis oponentes argumentaron que al analizar los encabezados y la información relacionada (y la NTA no analiza el cuerpo de los datos del paquete, a diferencia de los sistemas de detección de ataques clásicos, IDS), no se puede ver mucho. En este artículo intentaré refutar esta opinión y hacer que la conversación sea más sustantiva, daré algunos ejemplos reales cuando la NTA realmente ayude a identificar varias anomalías y amenazas que faltan en el perímetro o incluso más allá del perímetro. Y comenzaré con la amenaza que llegó primero en la clasificación de amenazas del año pasado y, creo, seguirá siéndolo este año.Se tratará de fugas de información y la capacidad de detectarlas a través de la telemetría de red.No consideraré la situación con las manos torcidas de los administradores que dejaron Internet sin protección Elastic o MongoDB. Hablemos de las acciones específicas de los atacantes, como fue el caso con la aclamada historia de las agencias de crédito Equifax. Permítame recordarle que en este caso, los atacantes penetraron primero a través de la vulnerabilidad sin parchear en el portal web público y luego en los servidores de bases de datos internos. Permaneciendo inadvertidos durante varios meses, pudieron robar datos de 146 millones de clientes de agencias de crédito. ¿Podría identificarse un incidente de este tipo utilizando soluciones DLP? Lo más probable es que no, ya que los DLP clásicos no están diseñados para la tarea de monitorear el tráfico de las bases de datos utilizando protocolos específicos, e incluso bajo la condición de que este tráfico esté encriptado.Pero la solución de la clase NTA puede detectar fácilmente tales fugas al superar un cierto valor umbral de la cantidad de información descargada de la base de datos. A continuación, mostraré cómo se configura y descubre todo esto utilizando la solución Cisco Stealthwatch Enterprise.Entonces, lo primero que debemos hacer es comprender dónde están ubicados nuestros servidores de bases de datos en la red, determinar sus direcciones y agruparlos. En Cisco Stealthwatch, la tarea de inventario se puede realizar manualmente o mediante un clasificador especial que analiza el tráfico y, de acuerdo con los protocolos utilizados y el comportamiento del nodo, le permite atribuirlo a una u otra categoría.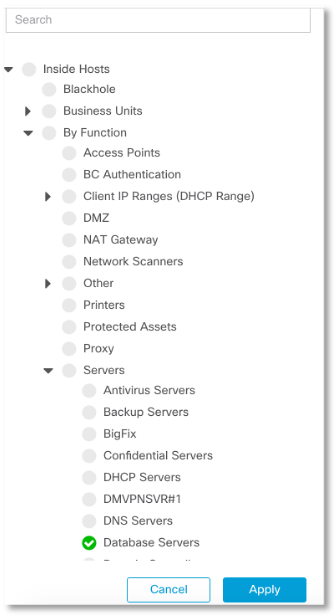 Después de tener información sobre todos los servidores de bases de datos, comenzamos una investigación para descubrir si estamos filtrando grandes cantidades de datos del grupo deseado de nodos. Vemos que en nuestro caso, las bases de datos se comunican más activamente con los servidores DHCP y los controladores de dominio.
Después de tener información sobre todos los servidores de bases de datos, comenzamos una investigación para descubrir si estamos filtrando grandes cantidades de datos del grupo deseado de nodos. Vemos que en nuestro caso, las bases de datos se comunican más activamente con los servidores DHCP y los controladores de dominio.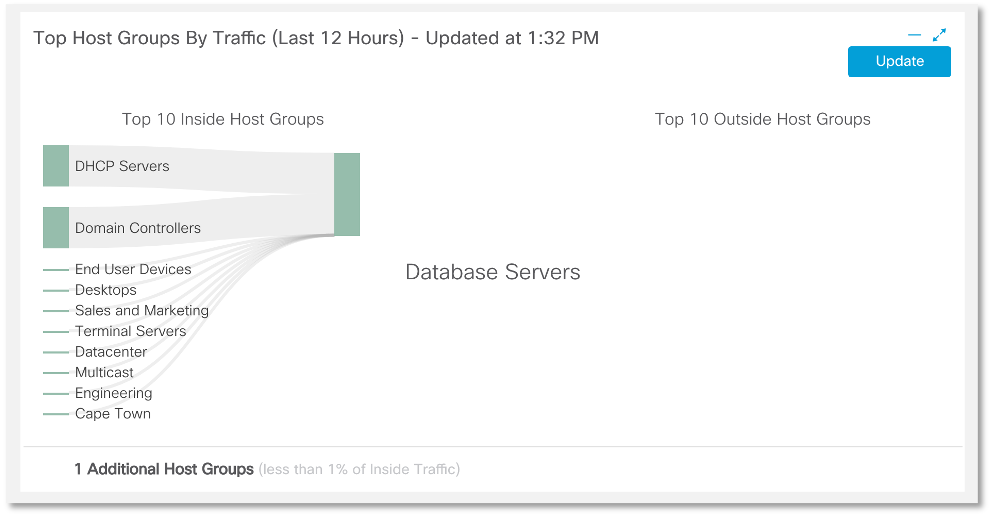 Los atacantes a menudo establecen control sobre cualquiera de los nodos de la red y lo usan como cabeza de puente para desarrollar su ataque. A nivel del tráfico de red, parece una anomalía: el escaneo de la red desde este nodo es cada vez más frecuente, se capturan datos del recurso compartido de archivos o la interacción con cualquier servidor. Por lo tanto, nuestra próxima tarea es comprender con quién se comunican exactamente nuestras bases de datos.
Los atacantes a menudo establecen control sobre cualquiera de los nodos de la red y lo usan como cabeza de puente para desarrollar su ataque. A nivel del tráfico de red, parece una anomalía: el escaneo de la red desde este nodo es cada vez más frecuente, se capturan datos del recurso compartido de archivos o la interacción con cualquier servidor. Por lo tanto, nuestra próxima tarea es comprender con quién se comunican exactamente nuestras bases de datos.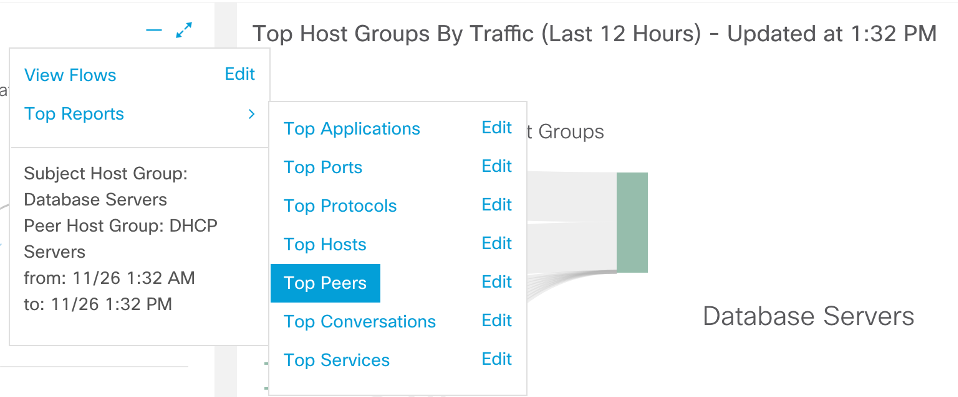 En el grupo de servidores DHCP, resulta que este es un nodo con la dirección 10.201.0.15, interacción con la que representa aproximadamente el 50% de todo el tráfico de los servidores de bases de datos.
En el grupo de servidores DHCP, resulta que este es un nodo con la dirección 10.201.0.15, interacción con la que representa aproximadamente el 50% de todo el tráfico de los servidores de bases de datos. La siguiente pregunta lógica que nos hacemos como parte de la investigación es: “¿Y cómo es este nodo 10.201.0.15? ¿Con quién está interactuando? ¿Con qué frecuencia? ¿Qué protocolos?
La siguiente pregunta lógica que nos hacemos como parte de la investigación es: “¿Y cómo es este nodo 10.201.0.15? ¿Con quién está interactuando? ¿Con qué frecuencia? ¿Qué protocolos?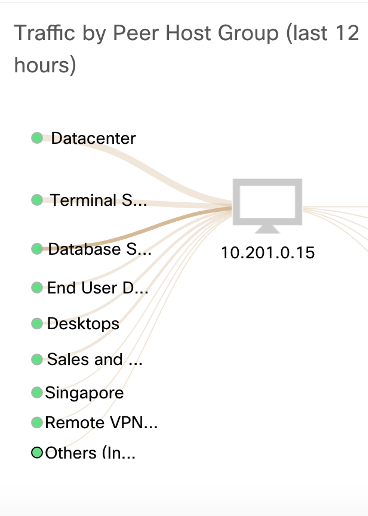 Resulta que el nodo que nos interesa se comunica con varios segmentos y nodos de nuestra red (lo cual no es sorprendente, ya que es un servidor DHCP), pero la pregunta causa demasiada interacción con el servidor terminal con la dirección 10.201.0.23. ¿Esto es normal? Claramente hay algún tipo de anomalía. Un servidor DHCP no puede comunicarse tan activamente con un servidor terminal: 5610 transmisiones y 23.5 GB de datos.
Resulta que el nodo que nos interesa se comunica con varios segmentos y nodos de nuestra red (lo cual no es sorprendente, ya que es un servidor DHCP), pero la pregunta causa demasiada interacción con el servidor terminal con la dirección 10.201.0.23. ¿Esto es normal? Claramente hay algún tipo de anomalía. Un servidor DHCP no puede comunicarse tan activamente con un servidor terminal: 5610 transmisiones y 23.5 GB de datos.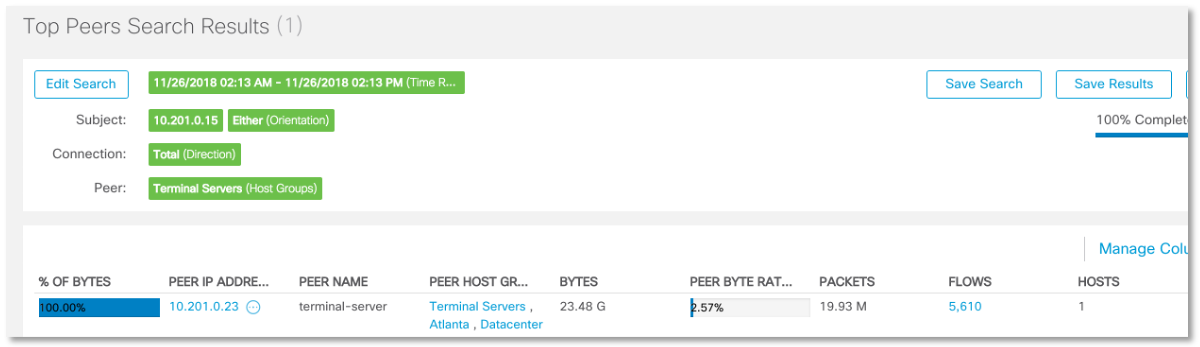 Y esta interacción se lleva a cabo a través de NFS.
Y esta interacción se lleva a cabo a través de NFS. ¿Damos el siguiente paso e intentamos entender con quién interactúa nuestro servidor terminal? Resulta que tiene una comunicación bastante activa con el mundo exterior, con nodos en los Estados Unidos, Gran Bretaña, Canadá, Dinamarca, los Emiratos Árabes Unidos, Qatar, Suiza, etc.
¿Damos el siguiente paso e intentamos entender con quién interactúa nuestro servidor terminal? Resulta que tiene una comunicación bastante activa con el mundo exterior, con nodos en los Estados Unidos, Gran Bretaña, Canadá, Dinamarca, los Emiratos Árabes Unidos, Qatar, Suiza, etc.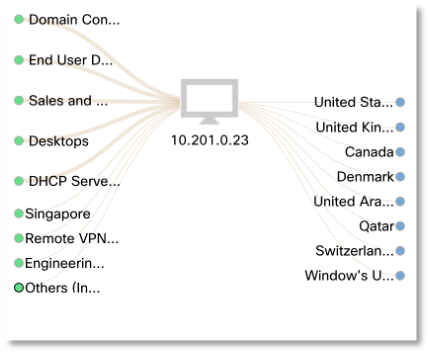 La sospecha fue causada por el hecho de la interacción P2P con Puerto Rico, que representaba el 90% de todo el tráfico. Además, nuestro servidor terminal transmitió más de 17 GB de datos a Puerto Rico a través del puerto 53, que está conectado con el protocolo DNS. ¿Te imaginas que tienes un volumen de datos transmitido a través de DNS? Y le recuerdo que, según la investigación de Cisco, el 92% del malware usa DNS para ocultar su actividad (descargar actualizaciones, recibir comandos, descargar datos).
La sospecha fue causada por el hecho de la interacción P2P con Puerto Rico, que representaba el 90% de todo el tráfico. Además, nuestro servidor terminal transmitió más de 17 GB de datos a Puerto Rico a través del puerto 53, que está conectado con el protocolo DNS. ¿Te imaginas que tienes un volumen de datos transmitido a través de DNS? Y le recuerdo que, según la investigación de Cisco, el 92% del malware usa DNS para ocultar su actividad (descargar actualizaciones, recibir comandos, descargar datos). Y si el protocolo DNS de la UIT no solo está abierto, sino que no se inspecciona, entonces tenemos un gran agujero en nuestro perímetro.
Y si el protocolo DNS de la UIT no solo está abierto, sino que no se inspecciona, entonces tenemos un gran agujero en nuestro perímetro. Tan pronto como el nodo 10.201.0.23 nos haya causado tales sospechas, ¿veremos con quién sigue hablando?
Tan pronto como el nodo 10.201.0.23 nos haya causado tales sospechas, ¿veremos con quién sigue hablando?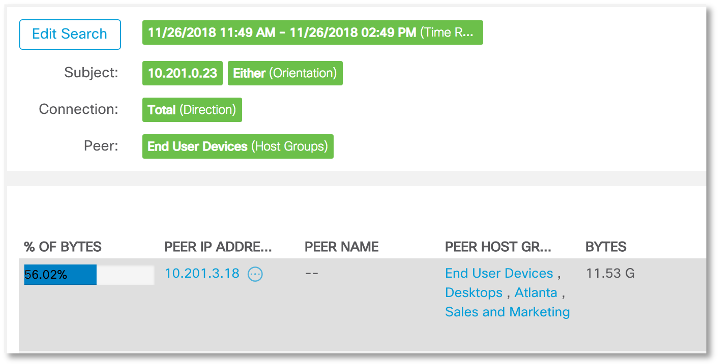 Nuestro "sospechoso" intercambia la mitad de todo el tráfico con el nodo 10.201.3.18, que se coloca en un grupo de estaciones de trabajo de empleados del departamento de ventas y marketing. ¿Qué tan típicos son estos para nuestra organización para que el servidor de terminal se "comunique" con la computadora del vendedor o comercializador?
Nuestro "sospechoso" intercambia la mitad de todo el tráfico con el nodo 10.201.3.18, que se coloca en un grupo de estaciones de trabajo de empleados del departamento de ventas y marketing. ¿Qué tan típicos son estos para nuestra organización para que el servidor de terminal se "comunique" con la computadora del vendedor o comercializador?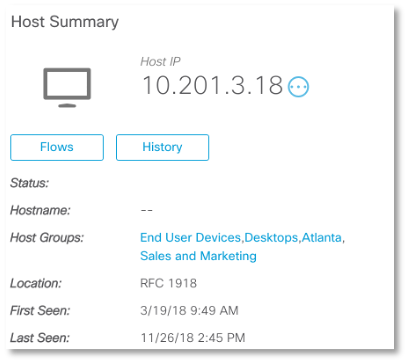 Entonces, realizamos una investigación y descubrimos la siguiente imagen. Los datos del servidor de la base de datos se "vertieron" en un servidor DHCP con su posterior transferencia a través de NFS a un servidor terminal dentro de nuestra red, y luego a direcciones externas en Puerto Rico utilizando el protocolo DNS. Esta es una clara violación de las políticas de seguridad. Al mismo tiempo, el servidor de terminal también interactuó con una de las estaciones de trabajo dentro de la red. ¿Qué causó este incidente? ¿Una cuenta robada? Dispositivo infectado? No sabemos. Esto requerirá una continuación de la investigación, que se basó en la solución de clase NTA, que permite analizar las anomalías del tráfico de la red.
Entonces, realizamos una investigación y descubrimos la siguiente imagen. Los datos del servidor de la base de datos se "vertieron" en un servidor DHCP con su posterior transferencia a través de NFS a un servidor terminal dentro de nuestra red, y luego a direcciones externas en Puerto Rico utilizando el protocolo DNS. Esta es una clara violación de las políticas de seguridad. Al mismo tiempo, el servidor de terminal también interactuó con una de las estaciones de trabajo dentro de la red. ¿Qué causó este incidente? ¿Una cuenta robada? Dispositivo infectado? No sabemos. Esto requerirá una continuación de la investigación, que se basó en la solución de clase NTA, que permite analizar las anomalías del tráfico de la red.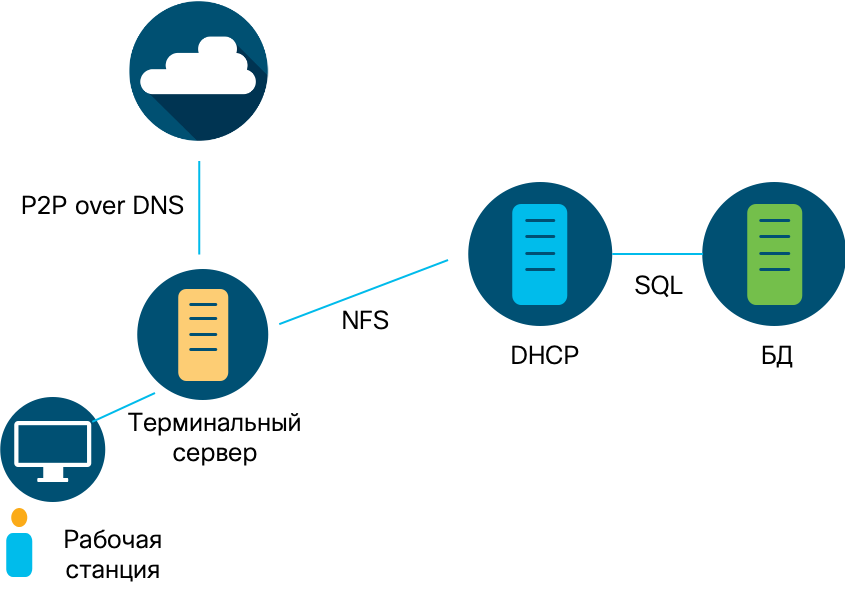 Y ahora estamos interesados en ¿qué haremos con las violaciones identificadas de la política de seguridad? Puede realizar un análisis regular de acuerdo con el esquema anterior, o puede configurar la política NTA para que señale de inmediato cuando se detectan violaciones similares. Esto se realiza a través del menú general correspondiente o para cada conexión detectada durante la investigación.
Y ahora estamos interesados en ¿qué haremos con las violaciones identificadas de la política de seguridad? Puede realizar un análisis regular de acuerdo con el esquema anterior, o puede configurar la política NTA para que señale de inmediato cuando se detectan violaciones similares. Esto se realiza a través del menú general correspondiente o para cada conexión detectada durante la investigación. Así es como se verá la regla de detección de interacción, cuyo origen es el servidor de la base de datos, y el destino es cualquier nodo externo, así como cualquier servidor web interno, excluyendo los servidores web.
Así es como se verá la regla de detección de interacción, cuyo origen es el servidor de la base de datos, y el destino es cualquier nodo externo, así como cualquier servidor web interno, excluyendo los servidores web.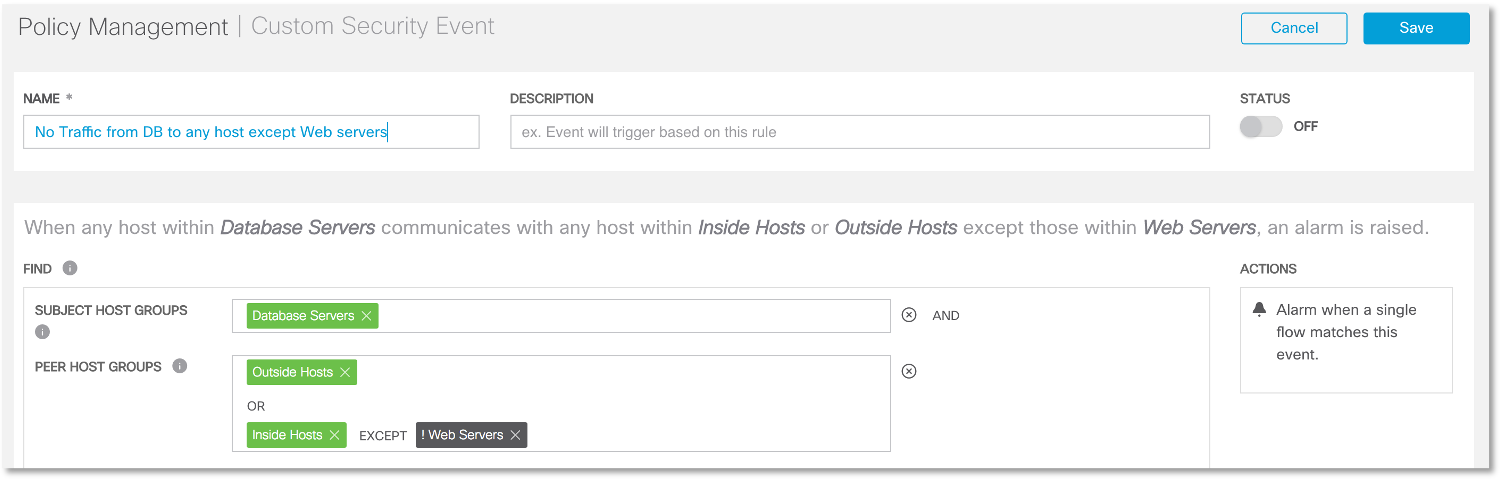 Si se detecta dicho evento, el sistema de análisis de tráfico de red genera inmediatamente una señal de alarma de correspondencia y, según la configuración, lo envía a SIEM, utilizando los medios de comunicación con el administrador, o incluso puede bloquear automáticamente la violación detectada (Cisco Stealthwatch lo hace al interactuar con Cisco ISE )
Si se detecta dicho evento, el sistema de análisis de tráfico de red genera inmediatamente una señal de alarma de correspondencia y, según la configuración, lo envía a SIEM, utilizando los medios de comunicación con el administrador, o incluso puede bloquear automáticamente la violación detectada (Cisco Stealthwatch lo hace al interactuar con Cisco ISE ) Recuerde que cuando mencioné el caso con Equifax, mencioné que los atacantes usaron un canal encriptado para volcar datos. Para DLP, este tráfico se convierte en una tarea insoluble, pero para las soluciones de clase NTA, no lo hacen: supervisan cualquier exceso de tráfico o interacción no autorizada entre nodos, independientemente del uso de cifrado.
Recuerde que cuando mencioné el caso con Equifax, mencioné que los atacantes usaron un canal encriptado para volcar datos. Para DLP, este tráfico se convierte en una tarea insoluble, pero para las soluciones de clase NTA, no lo hacen: supervisan cualquier exceso de tráfico o interacción no autorizada entre nodos, independientemente del uso de cifrado. Solo se mostró un caso arriba (en los siguientes materiales consideraremos otros ejemplos de uso de NTA para fines de seguridad de la información), pero de hecho, las soluciones modernas de la clase Network Traffic Analysis le permiten crear reglas muy flexibles y tener en cuenta no solo los parámetros básicos del encabezado del paquete IP:
Solo se mostró un caso arriba (en los siguientes materiales consideraremos otros ejemplos de uso de NTA para fines de seguridad de la información), pero de hecho, las soluciones modernas de la clase Network Traffic Analysis le permiten crear reglas muy flexibles y tener en cuenta no solo los parámetros básicos del encabezado del paquete IP: sino también realice un análisis más profundo, hasta asociar el incidente con el nombre de usuario de Active Directory, buscar archivos maliciosos por hash (por ejemplo, obtenido como un indicador de compromiso de SOSOPKA, FinCERT, Cisco Threat Grid, etc.), etc.
sino también realice un análisis más profundo, hasta asociar el incidente con el nombre de usuario de Active Directory, buscar archivos maliciosos por hash (por ejemplo, obtenido como un indicador de compromiso de SOSOPKA, FinCERT, Cisco Threat Grid, etc.), etc. Es fácil de implementar. Por ejemplo, así es como la regla habitual busca detectar todo tipo de interacción entre servidores de bases de datos y nodos externos utilizando cualquier protocolo durante los últimos 30 días. Vemos que nuestras bases de datos "se comunicaron" con nodos externos al segmento DBMS utilizando los protocolos DNS, SMB y puerto 8088.
Es fácil de implementar. Por ejemplo, así es como la regla habitual busca detectar todo tipo de interacción entre servidores de bases de datos y nodos externos utilizando cualquier protocolo durante los últimos 30 días. Vemos que nuestras bases de datos "se comunicaron" con nodos externos al segmento DBMS utilizando los protocolos DNS, SMB y puerto 8088.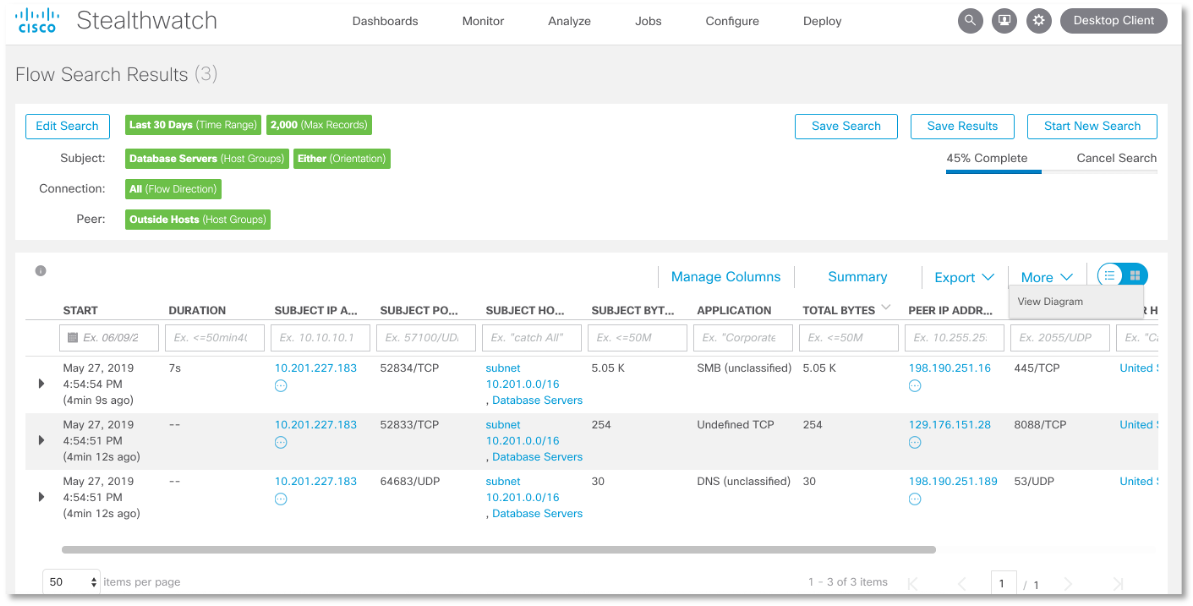 Además de la forma tabular para presentar los resultados de investigaciones o búsquedas, también podemos visualizarlos. Para nuestro escenario, un fragmento del diagrama de flujo de la red puede verse así:
Además de la forma tabular para presentar los resultados de investigaciones o búsquedas, también podemos visualizarlos. Para nuestro escenario, un fragmento del diagrama de flujo de la red puede verse así: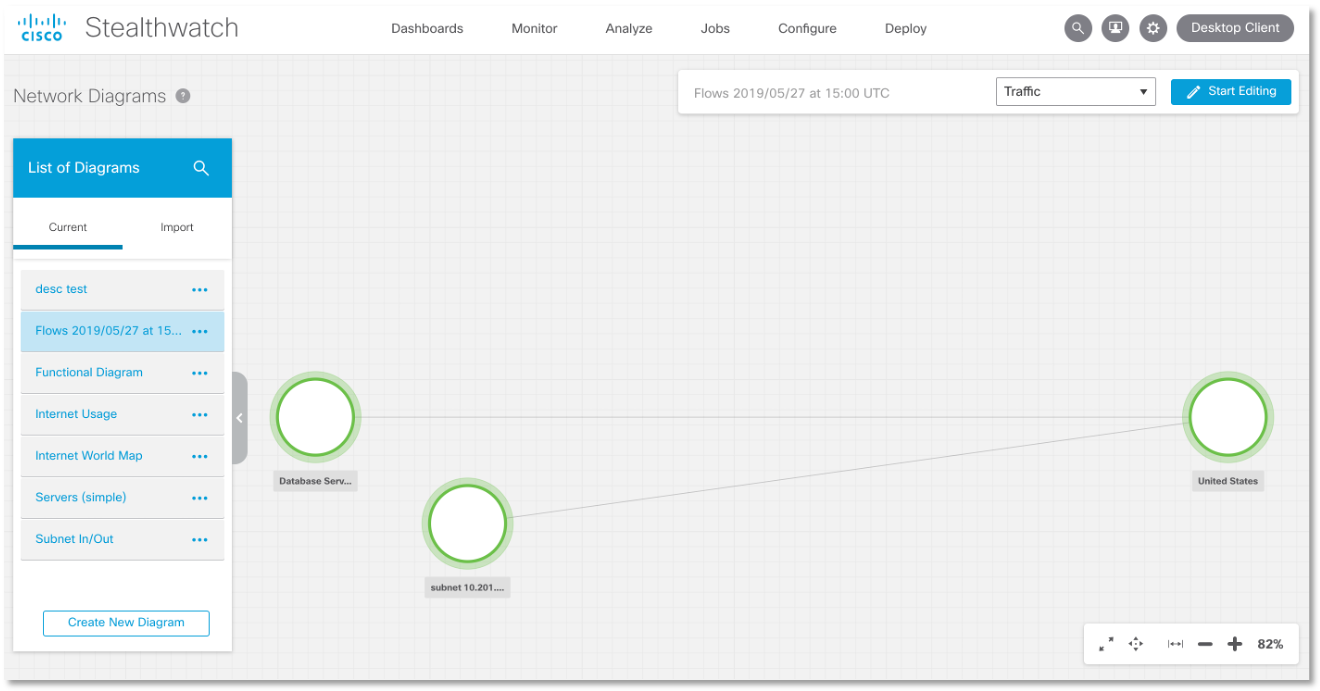 y desde el mismo mapa podemos administrar políticas: bloquear conexiones o automatizar el proceso de creación de reglas de monitoreo para los flujos de interés para nosotros.
y desde el mismo mapa podemos administrar políticas: bloquear conexiones o automatizar el proceso de creación de reglas de monitoreo para los flujos de interés para nosotros.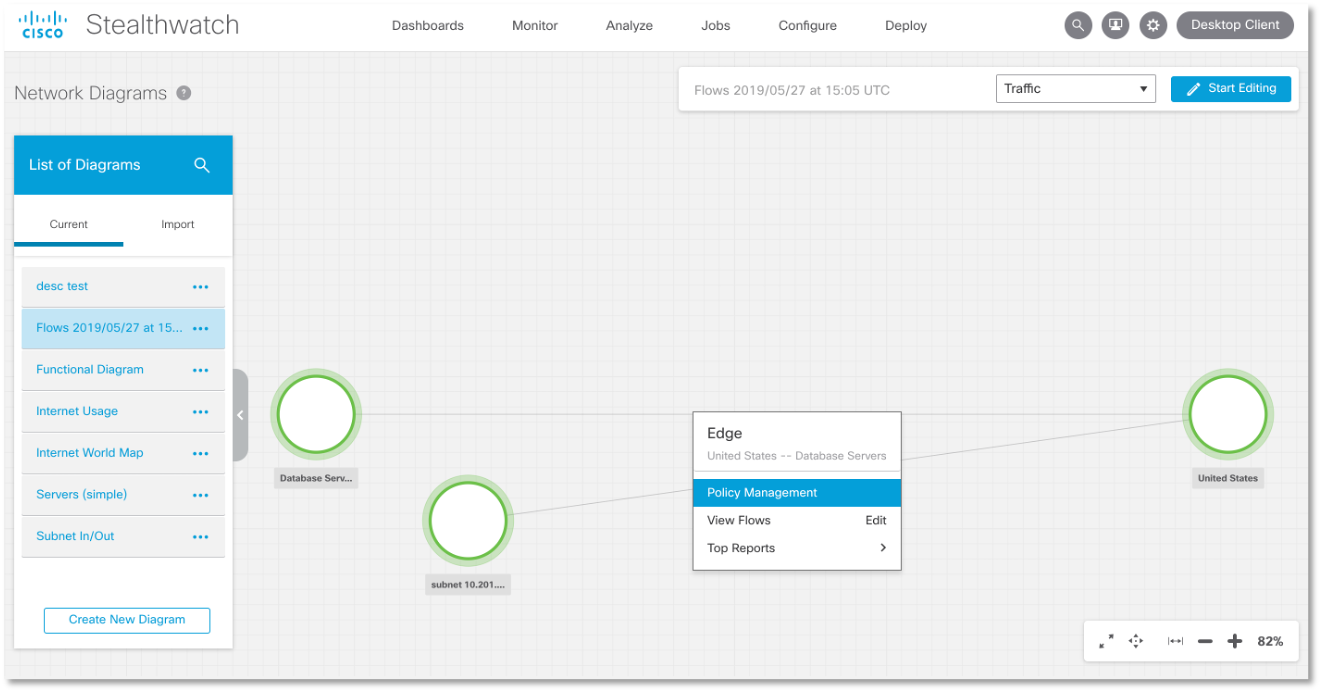 Aquí hay un ejemplo bastante interesante y animado del uso de herramientas de monitoreo de Netflow (y otros protocolos de flujo) para la ciberseguridad. En las siguientes notas, planeo mostrar cómo puede usar NTA para detectar código malicioso (por ejemplo, Shamoon), servidores maliciosos (por ejemplo, la campaña DNSpionage), programas de acceso remoto (RAT), omitir proxies corporativos, etc.
Aquí hay un ejemplo bastante interesante y animado del uso de herramientas de monitoreo de Netflow (y otros protocolos de flujo) para la ciberseguridad. En las siguientes notas, planeo mostrar cómo puede usar NTA para detectar código malicioso (por ejemplo, Shamoon), servidores maliciosos (por ejemplo, la campaña DNSpionage), programas de acceso remoto (RAT), omitir proxies corporativos, etc. Source: https://habr.com/ru/post/undefined/
All Articles