Durante años, los expertos en C ++ han estado discutiendo la semántica de los valores, la inmutabilidad y el intercambio de recursos a través de la comunicación. Sobre un mundo nuevo sin mutexes y razas, sin patrones de Command y Observer. De hecho, no todo es tan simple. El principal problema aún está en nuestras estructuras de datos. Las estructuras de datos inmutables no cambian sus valores. Para hacer algo con ellos, necesita crear nuevos valores. Los valores antiguos permanecen en el mismo lugar, por lo que pueden leerse desde diferentes flujos sin problemas y bloqueos. Como resultado, los recursos se pueden compartir de manera más racional y ordenada, porque los valores antiguos y nuevos pueden usar datos comunes. Gracias a esto, son mucho más rápidos de comparar entre sí y almacenan de forma compacta el historial de operaciones con la posibilidad de cancelación. Todo esto encaja perfectamente en sistemas multihilo e interactivos: tales estructuras de datos simplifican la arquitectura de las aplicaciones de escritorio y permiten que los servicios se escalen mejor. Las estructuras inmutables son el secreto del éxito de Clojure y Scala, e incluso la comunidad JavaScript ahora las aprovecha, porque tienen la biblioteca Immutable.js,escrito en las entrañas de la empresa Facebook.Bajo el corte: video y traducción del informe de Juan Puente de la conferencia C ++ Rusia 2019 Moscú. Juan habla de Immer , una biblioteca de estructuras inmutables para C ++. En el post:
Las estructuras de datos inmutables no cambian sus valores. Para hacer algo con ellos, necesita crear nuevos valores. Los valores antiguos permanecen en el mismo lugar, por lo que pueden leerse desde diferentes flujos sin problemas y bloqueos. Como resultado, los recursos se pueden compartir de manera más racional y ordenada, porque los valores antiguos y nuevos pueden usar datos comunes. Gracias a esto, son mucho más rápidos de comparar entre sí y almacenan de forma compacta el historial de operaciones con la posibilidad de cancelación. Todo esto encaja perfectamente en sistemas multihilo e interactivos: tales estructuras de datos simplifican la arquitectura de las aplicaciones de escritorio y permiten que los servicios se escalen mejor. Las estructuras inmutables son el secreto del éxito de Clojure y Scala, e incluso la comunidad JavaScript ahora las aprovecha, porque tienen la biblioteca Immutable.js,escrito en las entrañas de la empresa Facebook.Bajo el corte: video y traducción del informe de Juan Puente de la conferencia C ++ Rusia 2019 Moscú. Juan habla de Immer , una biblioteca de estructuras inmutables para C ++. En el post:- ventajas arquitectónicas de la inmunidad;
- creación de un tipo de vector persistente efectivo basado en árboles RRB;
- Análisis de la arquitectura en el ejemplo de un editor de texto simple.
La tragedia de la arquitectura basada en valores.
Para comprender la importancia de las estructuras de datos inmutables, discutimos la semántica de los valores. Esta es una característica muy importante de C ++, considero que es una de las principales ventajas de este lenguaje. Por todo esto, es muy difícil usar la semántica de valores como nos gustaría. Creo que esta es la tragedia de la arquitectura basada en valores, y el camino a esta tragedia está pavimentado con buenas intenciones. Supongamos que necesitamos escribir software interactivo basado en un modelo de datos con una representación de un documento editable por el usuario. Cuando la arquitectura basada en los valores en el seno de este modelo utiliza los tipos simples y convenientes de valores que ya existe en el lenguaje: vector, map, tuple,struct. La lógica de aplicación se crea a partir de funciones que toman documentos por valor y devuelven una nueva versión de un documento por valor. Este documento puede cambiar dentro de la función (como sucede a continuación), pero la semántica de los valores en C ++, aplicada al argumento por valor y al tipo de retorno por valor, asegura que no haya efectos secundarios.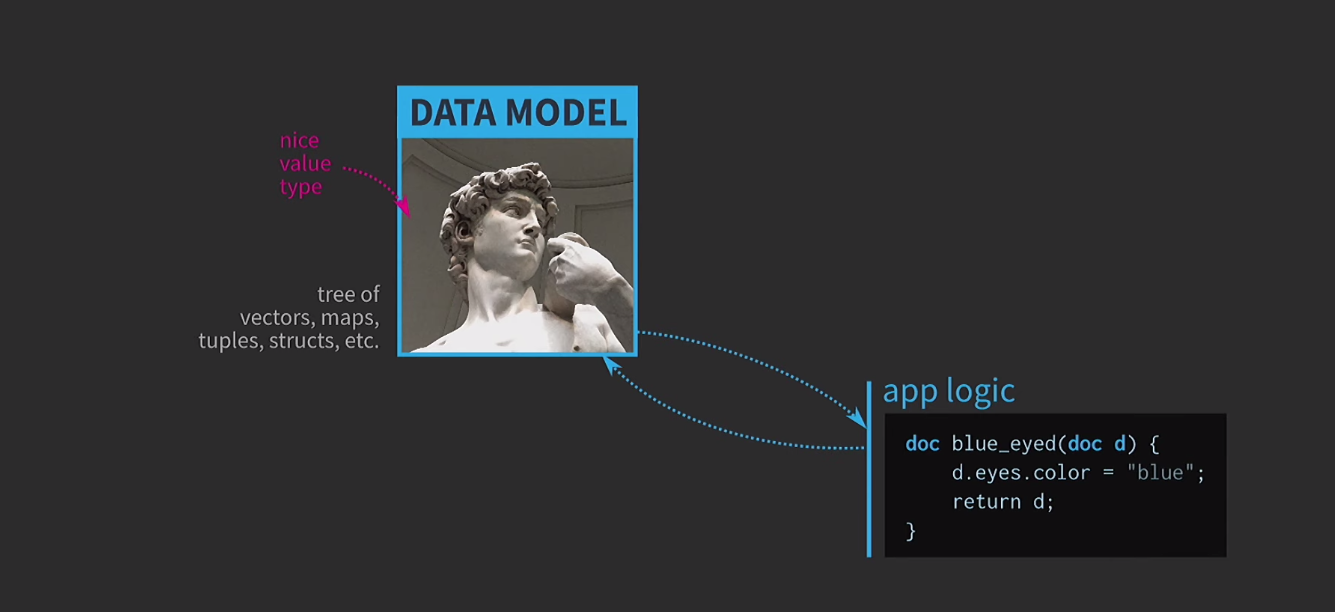 Esta característica es muy fácil de analizar y probar.
Esta característica es muy fácil de analizar y probar. Como estamos trabajando con valores, intentaremos implementar la acción de deshacer. Esto puede ser difícil, pero con nuestro enfoque es una tarea trivial: tenemos
Como estamos trabajando con valores, intentaremos implementar la acción de deshacer. Esto puede ser difícil, pero con nuestro enfoque es una tarea trivial: tenemos std::vectorcon diferentes estados varias copias del documento.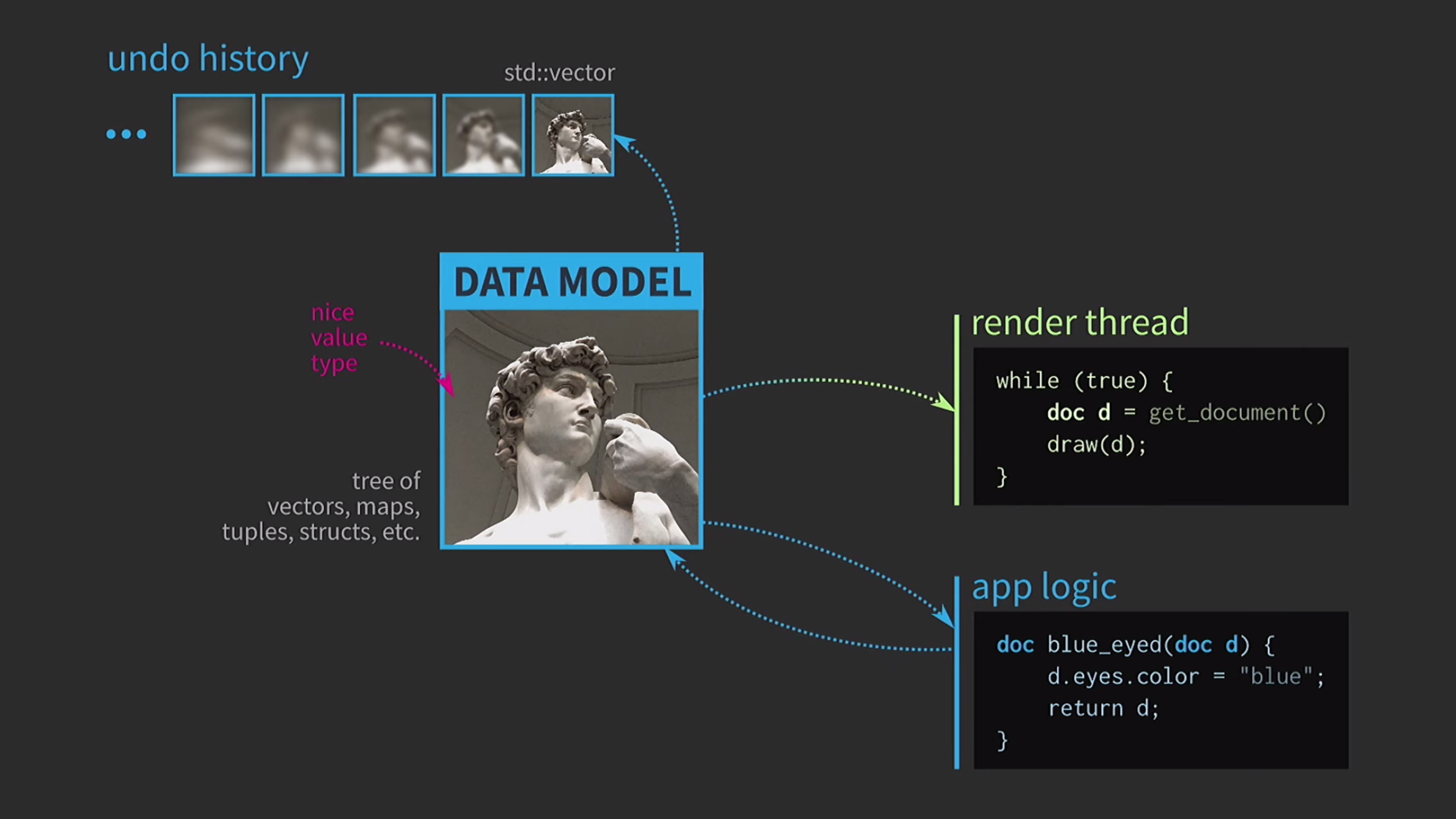 Supongamos que también tenemos una interfaz de usuario, y para garantizar su capacidad de respuesta, la asignación de la interfaz de usuario debe realizarse en un hilo separado. El documento se envía a otra secuencia por mensaje, y la interacción también se realiza en función de los mensajes, y no a través del uso compartido del estado
Supongamos que también tenemos una interfaz de usuario, y para garantizar su capacidad de respuesta, la asignación de la interfaz de usuario debe realizarse en un hilo separado. El documento se envía a otra secuencia por mensaje, y la interacción también se realiza en función de los mensajes, y no a través del uso compartido del estado mutexes. Cuando la segunda transmisión recibe la copia, allí puede realizar todas las operaciones necesarias. Guardar un documento en el disco suele ser muy lento, especialmente si el documento es grande. Por lo tanto, el uso de
Guardar un documento en el disco suele ser muy lento, especialmente si el documento es grande. Por lo tanto, el uso de std::asyncesta operación se realiza de forma asincrónica. Usamos una lambda, ponemos un signo igual dentro para tener una copia, y ahora puede guardar sin otros tipos primitivos de sincronización.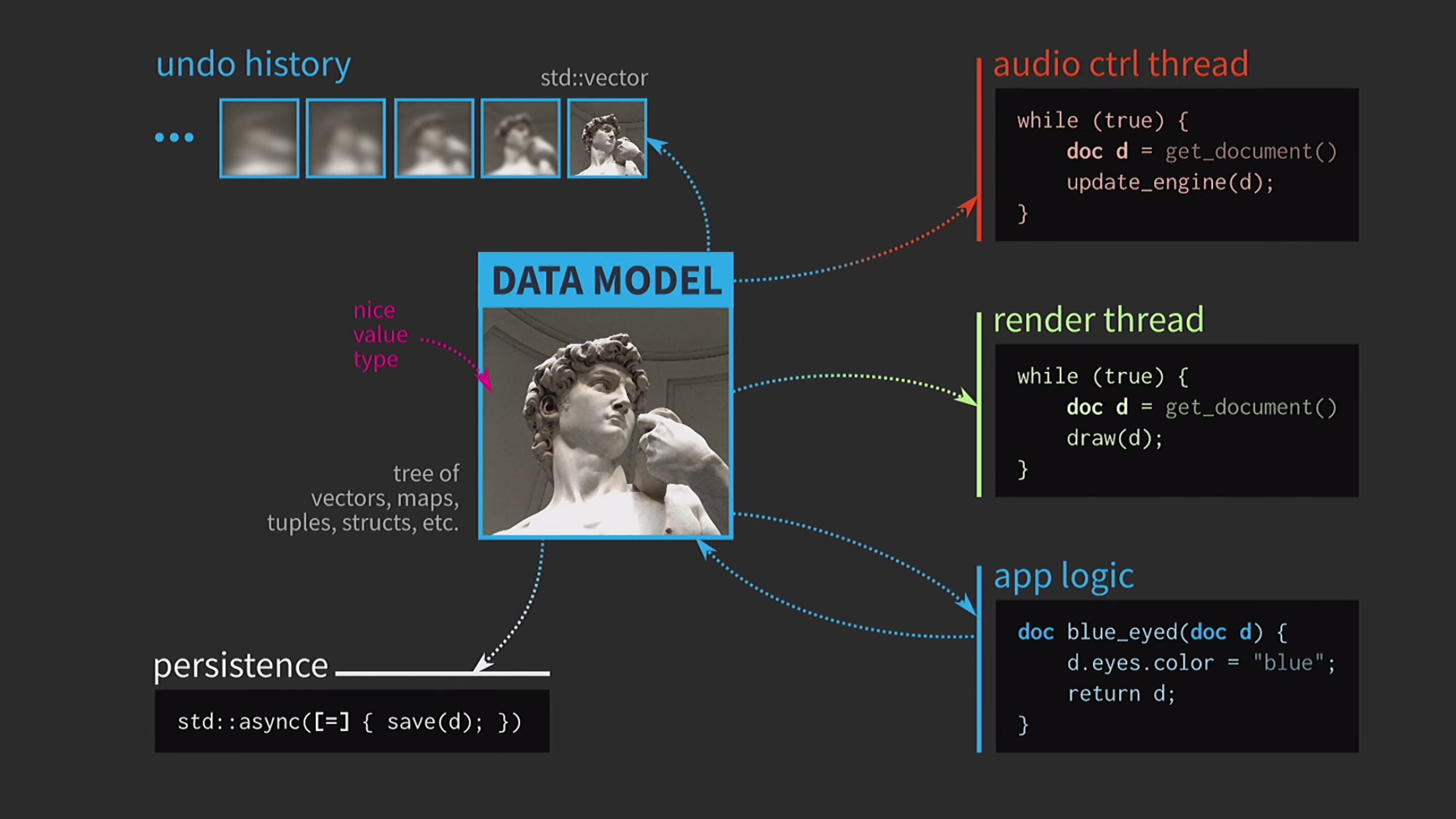 Además, supongamos que también tenemos un flujo de control de sonido. Como dije, trabajé mucho con el software de música, y el sonido es otra representación de nuestro documento, debe estar en una secuencia separada. Por lo tanto, también se requiere una copia del documento para esta secuencia.Como resultado, obtuvimos un esquema muy hermoso, pero no demasiado realista.
Además, supongamos que también tenemos un flujo de control de sonido. Como dije, trabajé mucho con el software de música, y el sonido es otra representación de nuestro documento, debe estar en una secuencia separada. Por lo tanto, también se requiere una copia del documento para esta secuencia.Como resultado, obtuvimos un esquema muy hermoso, pero no demasiado realista.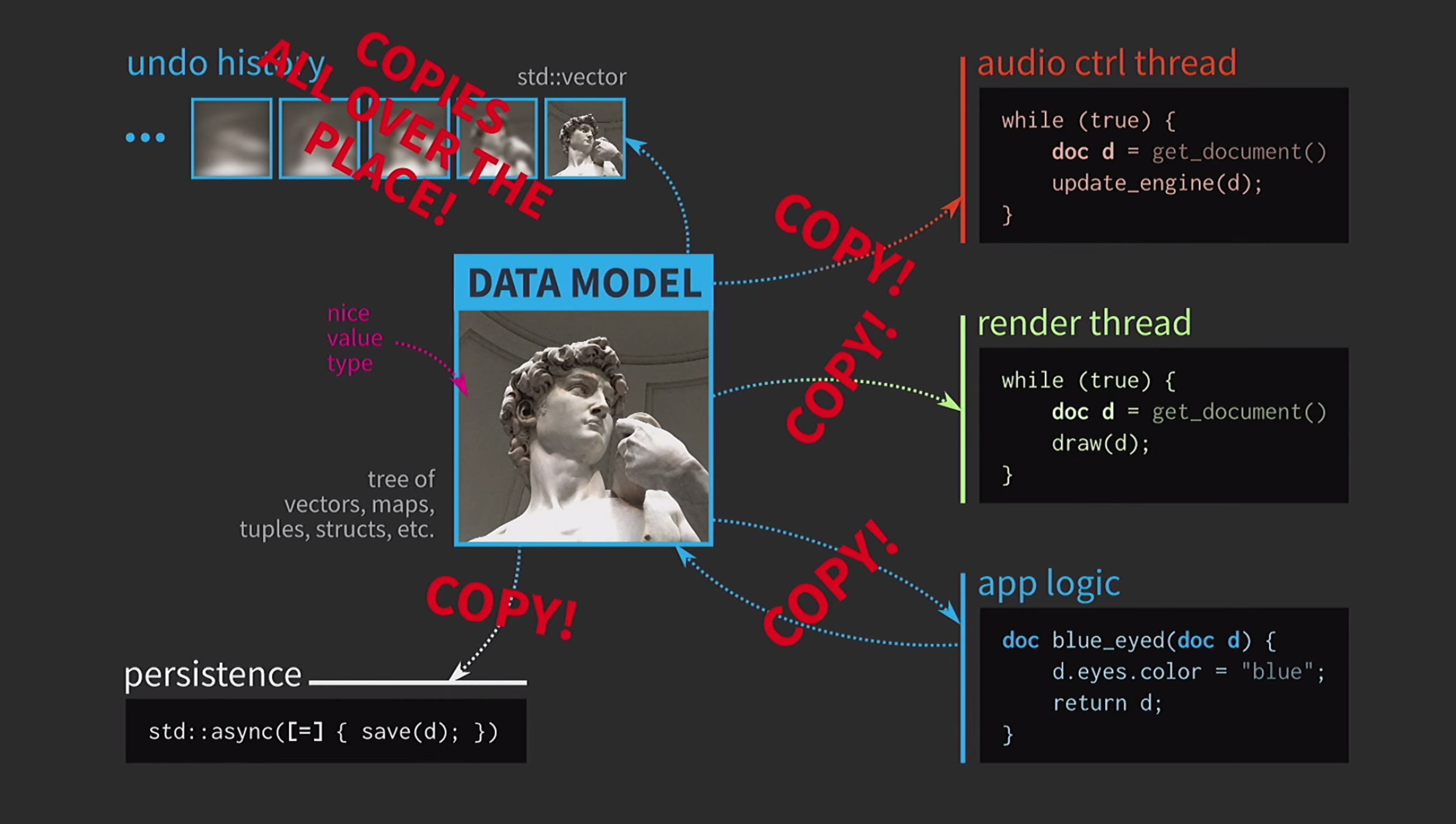 Constantemente tiene que copiar documentos, el historial de acciones para la cancelación toma gigabytes, y para cada representación de la interfaz de usuario debe hacer una copia profunda del documento. En general, todas las interacciones son demasiado costosas.
Constantemente tiene que copiar documentos, el historial de acciones para la cancelación toma gigabytes, y para cada representación de la interfaz de usuario debe hacer una copia profunda del documento. En general, todas las interacciones son demasiado costosas.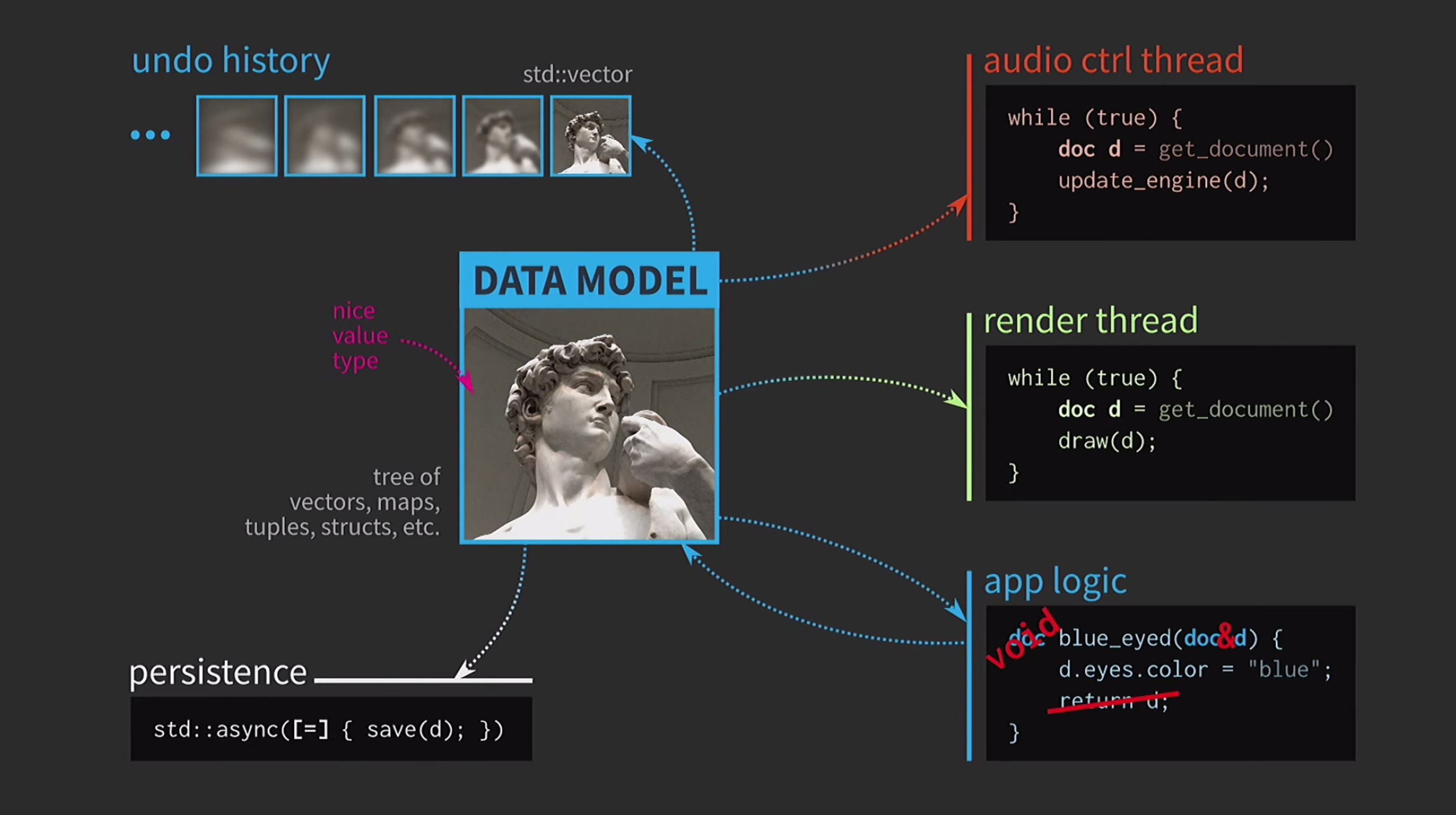 ¿Qué está haciendo el desarrollador de C ++ en esta situación? En lugar de aceptar un documento por valor, la lógica de la aplicación ahora acepta un enlace al documento y lo actualiza si es necesario. En este caso, no necesita devolver nada. Pero ahora no estamos tratando con valores, sino con objetos y ubicaciones. Esto crea nuevos problemas: si hay un enlace al estado con acceso compartido, lo necesita
¿Qué está haciendo el desarrollador de C ++ en esta situación? En lugar de aceptar un documento por valor, la lógica de la aplicación ahora acepta un enlace al documento y lo actualiza si es necesario. En este caso, no necesita devolver nada. Pero ahora no estamos tratando con valores, sino con objetos y ubicaciones. Esto crea nuevos problemas: si hay un enlace al estado con acceso compartido, lo necesita mutex. Esto es extremadamente costoso, por lo que habrá alguna representación de nuestra interfaz de usuario en forma de un árbol extremadamente complejo de varios Widgets.Todos estos elementos deben recibir actualizaciones cuando cambia un documento, por lo que se necesita algún mecanismo de cola para las señales de cambio. Además, la historia del documento ya no es un conjunto de estados; será una implementación del patrón de Equipo. La operación debe implementarse dos veces, en una dirección y en la otra, y asegurarse de que todo sea simétrico. Guardar en un hilo separado ya es demasiado difícil, por lo que habrá que abandonarlo.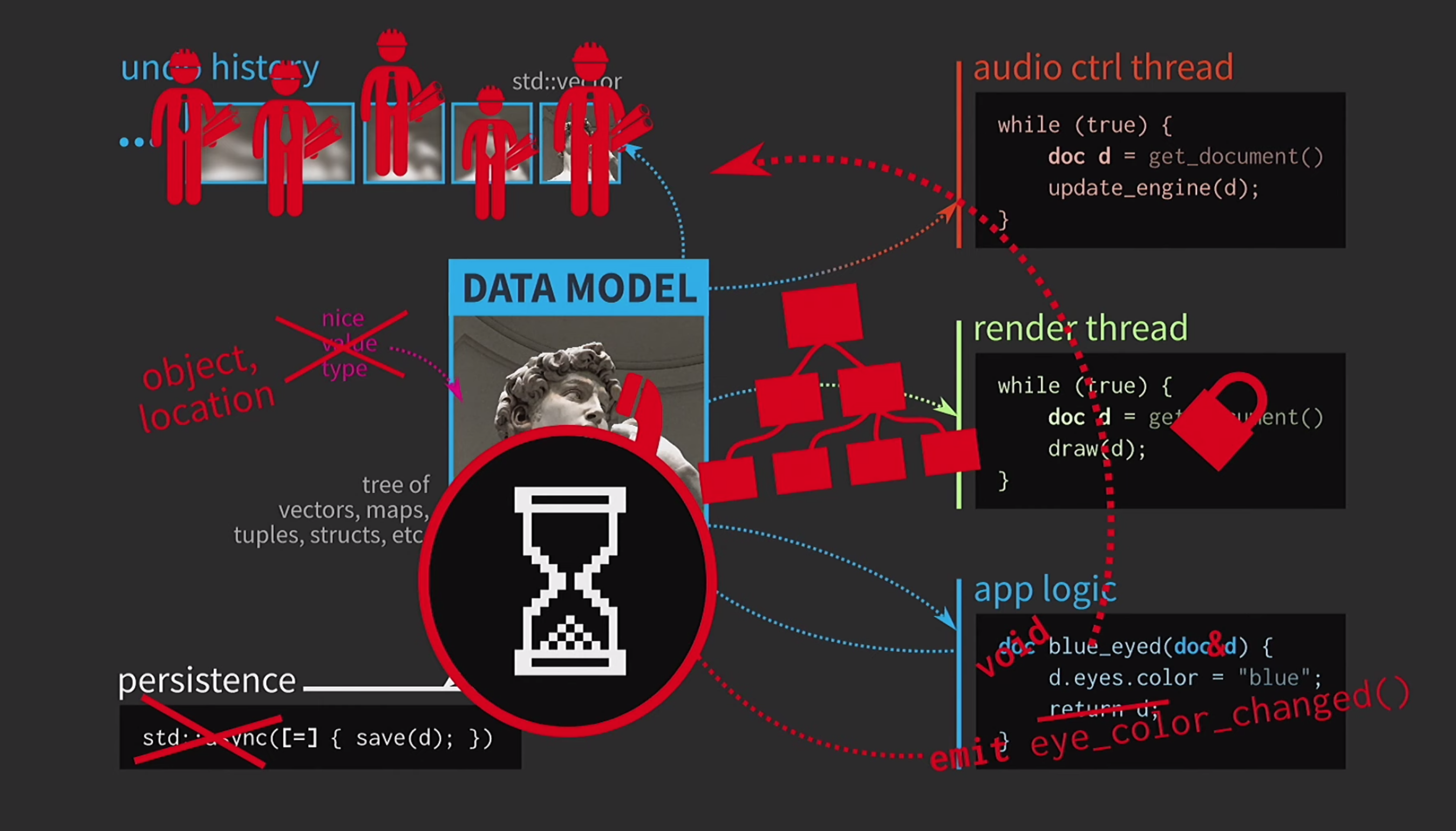 Los usuarios ya están acostumbrados a la imagen del reloj de arena, por lo que está bien si esperan un poco. Otra cosa es aterradora: el monstruo de la pasta ahora rige nuestro código.¿En qué punto todo fue cuesta abajo? Diseñamos nuestro código muy bien, y luego tuvimos que comprometernos debido a la copia. Pero en C ++, se requiere copiar para pasar por valor solo para datos mutables. Si el objeto es inmutable, entonces el operador de asignación puede implementarse para que solo copie el puntero a la representación interna y nada más.
Los usuarios ya están acostumbrados a la imagen del reloj de arena, por lo que está bien si esperan un poco. Otra cosa es aterradora: el monstruo de la pasta ahora rige nuestro código.¿En qué punto todo fue cuesta abajo? Diseñamos nuestro código muy bien, y luego tuvimos que comprometernos debido a la copia. Pero en C ++, se requiere copiar para pasar por valor solo para datos mutables. Si el objeto es inmutable, entonces el operador de asignación puede implementarse para que solo copie el puntero a la representación interna y nada más.const auto v0 = vector<int>{};
Considere una estructura de datos que podría ayudarnos. En el siguiente vector, todos los métodos están marcados como const, por lo que es inmutable. En la ejecución .push_back, el vector no se actualiza; en cambio, se devuelve un nuevo vector al que se agregan los datos transferidos. Desafortunadamente, no podemos usar corchetes con este enfoque debido a cómo se definen. En cambio, puedes usar la función.setque devuelve una nueva versión con un elemento actualizado. Nuestra estructura de datos ahora tiene una propiedad que se llama persistencia en la programación funcional. No significa que guardemos esta estructura de datos en el disco duro, sino el hecho de que cuando se actualiza, el contenido anterior no se elimina; en cambio, se crea una nueva bifurcación de nuestro mundo, es decir, la estructura. Gracias a esto, podemos comparar los valores pasados con el presente; esto se hace con la ayuda de dos assert.const auto v0 = vector<int>{};
const auto v1 = v0.push_back(15);
const auto v2 = v1.push_back(16);
const auto v3 = v2.set(0, 42);
assert(v2.size() == v0.size() + 2);
assert(v3[0] - v1[0] == 27);
Los cambios ahora se pueden verificar directamente, ya no son propiedades ocultas de la estructura de datos. Esta característica es especialmente valiosa en sistemas interactivos donde constantemente tenemos que cambiar los datos.Otra propiedad importante es el intercambio estructural. Ahora no estamos copiando todos los datos para cada nueva versión de la estructura de datos. Incluso con .push_backy.setNo todos los datos se copian, pero solo una pequeña parte de ellos. Todos nuestros tenedores tienen acceso común a una vista compacta, que es proporcional al número de cambios, no al número de copias. También se deduce que la comparación es muy rápida: si todo se almacena en un bloque de memoria, en un puntero, simplemente puede comparar los punteros y no examinar los elementos que están dentro de ellos, si son iguales.Dado que este vector, me parece, es extremadamente útil, lo implementé en una biblioteca separada: esto es immer , una biblioteca de estructuras inmutables, un proyecto de código abierto.Al escribirlo, quería que su uso fuera familiar para los desarrolladores de C ++. Hay muchas bibliotecas que implementan los conceptos de programación funcional en C ++, pero da la impresión de que los desarrolladores escriben para Haskell y no para C ++. Esto crea inconvenientes. Además, logré un buen rendimiento. Las personas usan C ++ cuando los recursos disponibles son limitados. Finalmente, quería que la biblioteca fuera personalizable. Este requisito está relacionado con el requisito de rendimiento.En busca de un vector mágico
En la segunda parte del informe, consideraremos cómo se estructura este vector inmutable. La forma más fácil de comprender los principios de dicha estructura de datos es comenzando con una lista regular. Si está un poco familiarizado con la programación funcional (usando Lisp o Haskell como ejemplo), sabe que las listas son las estructuras de datos inmutables más comunes.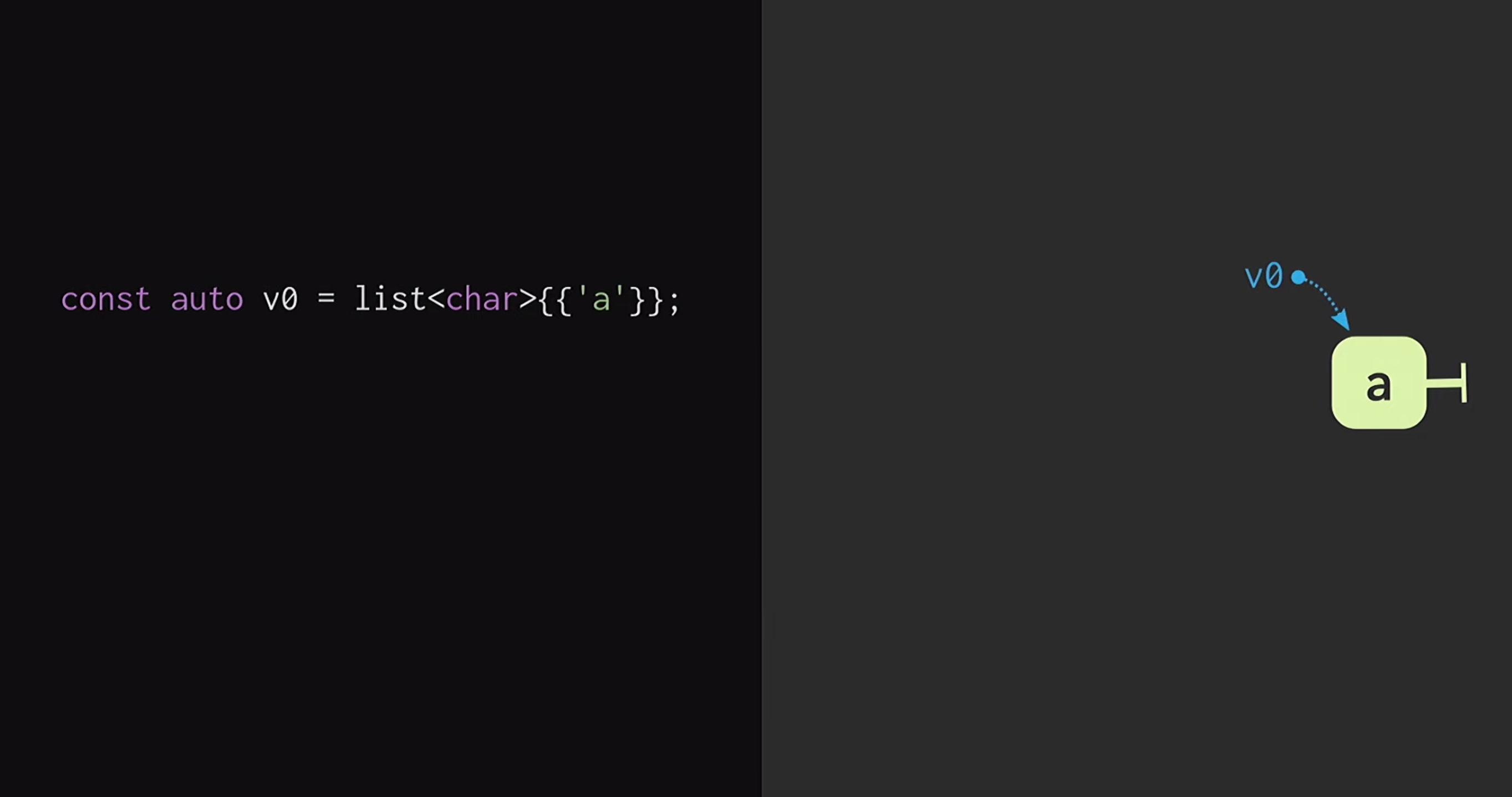 Para comenzar, supongamos que tenemos una lista con un solo nodo
Para comenzar, supongamos que tenemos una lista con un solo nodo v1que v0indican diferentes elementos.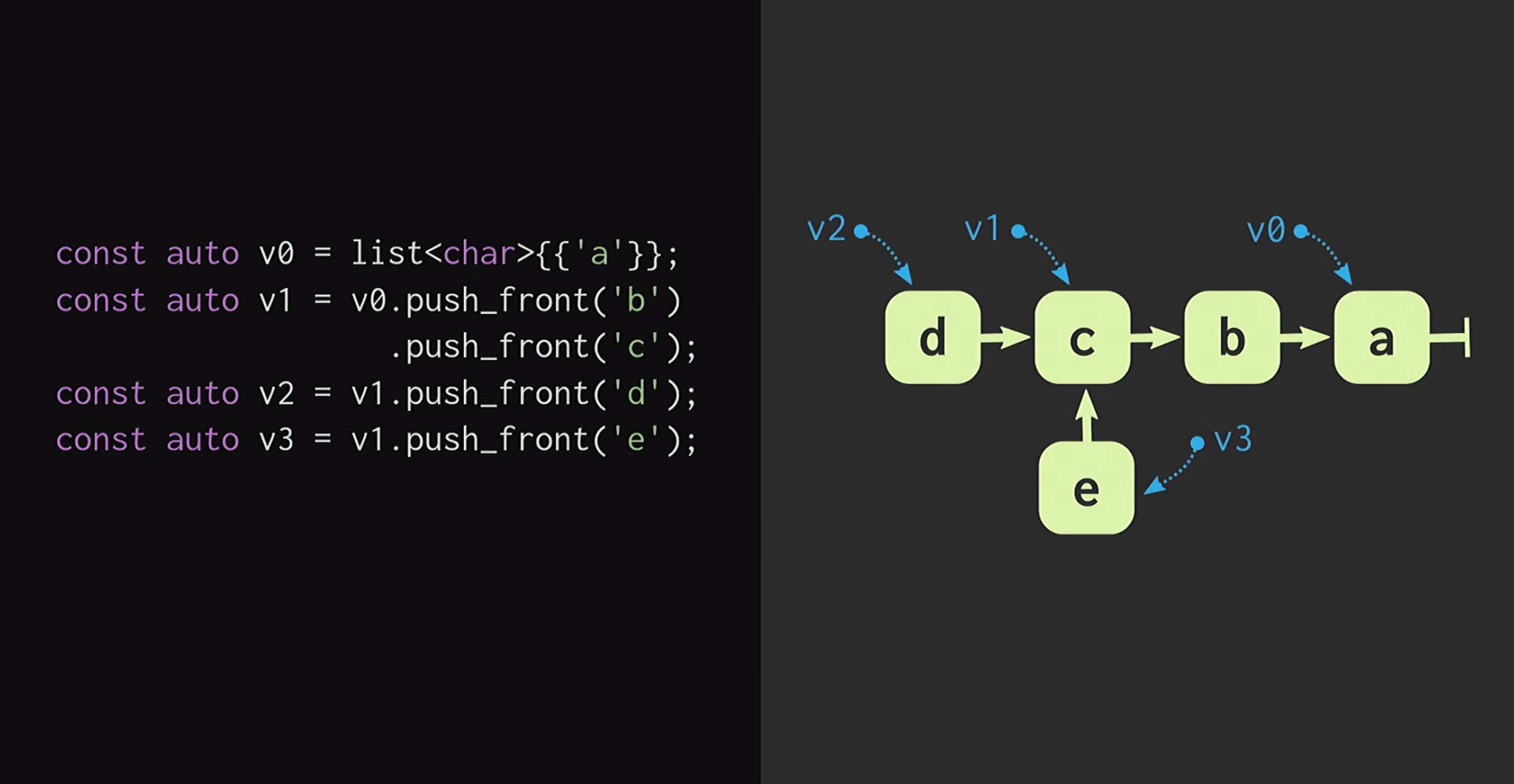 También podemos crear una bifurcación de la realidad, es decir, crear una nueva lista que tenga el mismo final, pero un comienzo diferente.Dichas estructuras de datos se han estudiado durante mucho tiempo: Chris Okasaki escribió el trabajo fundamental de Estructuras de datos puramente funcionales . Además, la estructura de datos de Finger Tree propuesta por Ralf Hinze y Ross Paterson es muy interesante . Pero para C ++, tales estructuras de datos no funcionan bien. Usan nodos pequeños, y sabemos que en C ++ los nodos pequeños significan una falta de eficiencia de almacenamiento en caché.Además, a menudo se basan en propiedades que C ++ no tiene, como la pereza. Por lo tanto, el trabajo de Phil Bagwell sobre estructuras de datos inmutables es mucho más útil para nosotros: un enlace escrito a principios de la década de 2000, así como el trabajo de Rich Hickey: enlace, autor de Clojure. Rich Hickey creó una lista, que en realidad no es una lista, sino que se basa en estructuras de datos modernas: vectores y mapas hash. Estas estructuras de datos tienen eficiencia de almacenamiento en caché e interactúan bien con los procesadores modernos, por lo que no es deseable trabajar con nodos pequeños. Dichas estructuras se pueden usar en C ++.¿Cómo construir un vector inmune? En el corazón de cualquier estructura, incluso remotamente parecida a un vector, debe haber una matriz. Pero la matriz no tiene intercambio estructural. Para cambiar cualquier elemento de la matriz, sin perder la propiedad de persistencia, debe copiar la matriz completa. Para no hacer esto, la matriz se puede dividir en partes separadas.Ahora, al actualizar un elemento vectorial, necesitamos copiar solo una pieza, y no todo el vector. Pero esas piezas en sí mismas no son una estructura de datos; deben combinarse de una forma u otra. Póngalos en otra matriz. Una vez más, surge el problema de que la matriz puede ser muy grande, y luego copiarla nuevamente tomará demasiado tiempo.Dividimos esta matriz en partes, las colocamos nuevamente en una matriz separada y repetimos este procedimiento hasta que solo haya una matriz raíz. La estructura resultante se llama árbol residual. Este árbol se describe por la constante M = 2B, es decir, el factor de ramificación. Este indicador de rama debe ser una potencia de dos, y muy pronto descubriremos por qué. En el ejemplo de la diapositiva, se usan bloques de cuatro caracteres, pero en la práctica, se usan bloques de 32 caracteres. Hay experimentos con los que puede encontrar el tamaño de bloque óptimo para una arquitectura en particular. Esto le permite lograr la mejor proporción de acceso estructural compartido al tiempo de acceso: cuanto más bajo sea el árbol, menor será el tiempo de acceso.Al leer esto, los desarrolladores que escriben en C ++ probablemente piensen: ¡pero las estructuras basadas en árboles son muy lentas! Los árboles crecen con un aumento en el número de elementos en ellos, y debido a esto, los tiempos de acceso se degradan. Es por eso que los programadores prefieren
También podemos crear una bifurcación de la realidad, es decir, crear una nueva lista que tenga el mismo final, pero un comienzo diferente.Dichas estructuras de datos se han estudiado durante mucho tiempo: Chris Okasaki escribió el trabajo fundamental de Estructuras de datos puramente funcionales . Además, la estructura de datos de Finger Tree propuesta por Ralf Hinze y Ross Paterson es muy interesante . Pero para C ++, tales estructuras de datos no funcionan bien. Usan nodos pequeños, y sabemos que en C ++ los nodos pequeños significan una falta de eficiencia de almacenamiento en caché.Además, a menudo se basan en propiedades que C ++ no tiene, como la pereza. Por lo tanto, el trabajo de Phil Bagwell sobre estructuras de datos inmutables es mucho más útil para nosotros: un enlace escrito a principios de la década de 2000, así como el trabajo de Rich Hickey: enlace, autor de Clojure. Rich Hickey creó una lista, que en realidad no es una lista, sino que se basa en estructuras de datos modernas: vectores y mapas hash. Estas estructuras de datos tienen eficiencia de almacenamiento en caché e interactúan bien con los procesadores modernos, por lo que no es deseable trabajar con nodos pequeños. Dichas estructuras se pueden usar en C ++.¿Cómo construir un vector inmune? En el corazón de cualquier estructura, incluso remotamente parecida a un vector, debe haber una matriz. Pero la matriz no tiene intercambio estructural. Para cambiar cualquier elemento de la matriz, sin perder la propiedad de persistencia, debe copiar la matriz completa. Para no hacer esto, la matriz se puede dividir en partes separadas.Ahora, al actualizar un elemento vectorial, necesitamos copiar solo una pieza, y no todo el vector. Pero esas piezas en sí mismas no son una estructura de datos; deben combinarse de una forma u otra. Póngalos en otra matriz. Una vez más, surge el problema de que la matriz puede ser muy grande, y luego copiarla nuevamente tomará demasiado tiempo.Dividimos esta matriz en partes, las colocamos nuevamente en una matriz separada y repetimos este procedimiento hasta que solo haya una matriz raíz. La estructura resultante se llama árbol residual. Este árbol se describe por la constante M = 2B, es decir, el factor de ramificación. Este indicador de rama debe ser una potencia de dos, y muy pronto descubriremos por qué. En el ejemplo de la diapositiva, se usan bloques de cuatro caracteres, pero en la práctica, se usan bloques de 32 caracteres. Hay experimentos con los que puede encontrar el tamaño de bloque óptimo para una arquitectura en particular. Esto le permite lograr la mejor proporción de acceso estructural compartido al tiempo de acceso: cuanto más bajo sea el árbol, menor será el tiempo de acceso.Al leer esto, los desarrolladores que escriben en C ++ probablemente piensen: ¡pero las estructuras basadas en árboles son muy lentas! Los árboles crecen con un aumento en el número de elementos en ellos, y debido a esto, los tiempos de acceso se degradan. Es por eso que los programadores prefieren std::unordered_map, en lugar de std::map. Me apresuro a tranquilizarte: nuestro árbol crece muy lentamente. Un vector que contiene todos los valores posibles de un int de 32 bits tiene solo 7 niveles de altura. Se puede demostrar experimentalmente que con este tamaño de datos, la relación de la memoria caché al volumen de carga afecta significativamente el rendimiento que la profundidad del árbol.Veamos cómo se realiza el acceso a un elemento de un árbol. Suponga que necesita pasar al elemento 17. Tomamos una representación binaria del índice y la dividimos en grupos del tamaño de un factor de ramificación. En cada grupo, usamos el valor binario correspondiente y, por lo tanto, bajamos del árbol.Luego, supongamos que necesitamos hacer un cambio en esta estructura de datos, es decir, ejecutar el método
En cada grupo, usamos el valor binario correspondiente y, por lo tanto, bajamos del árbol.Luego, supongamos que necesitamos hacer un cambio en esta estructura de datos, es decir, ejecutar el método .set.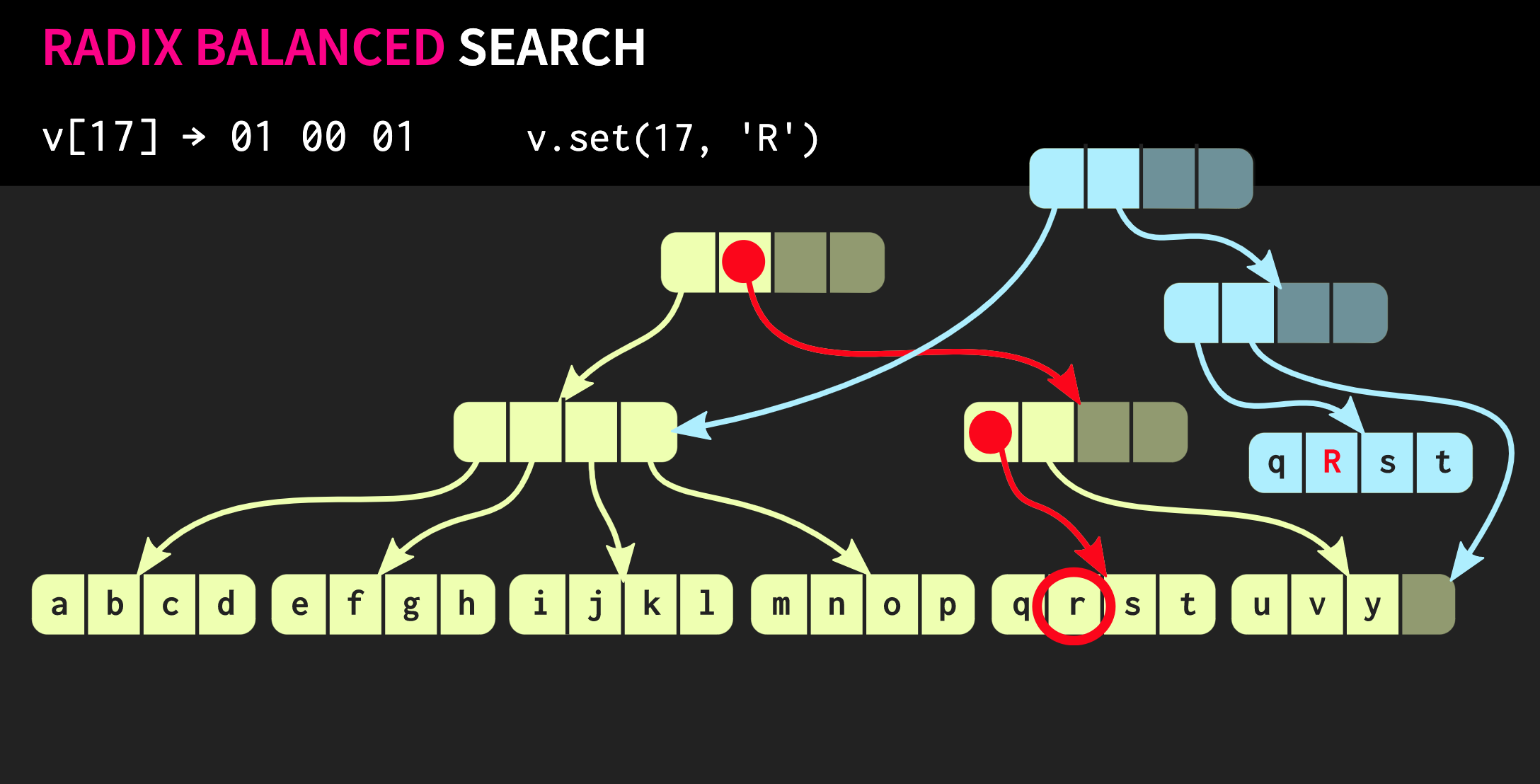 Para hacer esto, primero debe copiar el bloque en el que se encuentra el elemento y luego copiar cada nodo interno en el camino hacia el elemento. Por un lado, se debe copiar una gran cantidad de datos, pero al mismo tiempo una parte importante de estos datos es común, lo que compensa su volumen.Por cierto, hay una estructura de datos mucho más antigua que es muy similar a la que describí. Estas son páginas de memoria con un árbol de tabla de páginas. Su gestión también se lleva a cabo mediante una llamada
Para hacer esto, primero debe copiar el bloque en el que se encuentra el elemento y luego copiar cada nodo interno en el camino hacia el elemento. Por un lado, se debe copiar una gran cantidad de datos, pero al mismo tiempo una parte importante de estos datos es común, lo que compensa su volumen.Por cierto, hay una estructura de datos mucho más antigua que es muy similar a la que describí. Estas son páginas de memoria con un árbol de tabla de páginas. Su gestión también se lleva a cabo mediante una llamada fork.Intentemos mejorar nuestra estructura de datos. Supongamos que necesitamos conectar dos vectores. La estructura de datos descrita hasta ahora tiene las mismas limitaciones std::vector:que tiene celdas vacías en su parte más a la derecha. Dado que la estructura está perfectamente equilibrada, estas celdas vacías no pueden estar en el medio del árbol. Por lo tanto, si hay un segundo vector que queremos combinar con el primero, necesitaremos copiar los elementos en celdas vacías, lo que creará celdas vacías en el segundo vector, y al final tendremos que copiar todo el segundo vector. Tal operación tiene una complejidad computacional O (n), donde n es el tamaño del segundo vector.Intentaremos lograr un mejor resultado. Hay una versión modificada de nuestra estructura de datos llamada árbol equilibrado de radix relajado. En esta estructura, los nodos que no están en el camino de la izquierda pueden tener celdas vacías. Por lo tanto, en tales nodos incompletos (o relajados), es necesario calcular el tamaño del subárbol. Ahora puede realizar una operación de unión compleja pero logarítmica. Esta operación de complejidad de tiempo constante es O (log (32)). Como los árboles son poco profundos, el tiempo de acceso es constante, aunque relativamente largo. Debido al hecho de que tenemos una operación de unión de este tipo, una versión relajada de esta estructura de datos se denomina confluente: además de ser persistente, y se puede bifurcar, dos de estas estructuras se pueden combinar en una.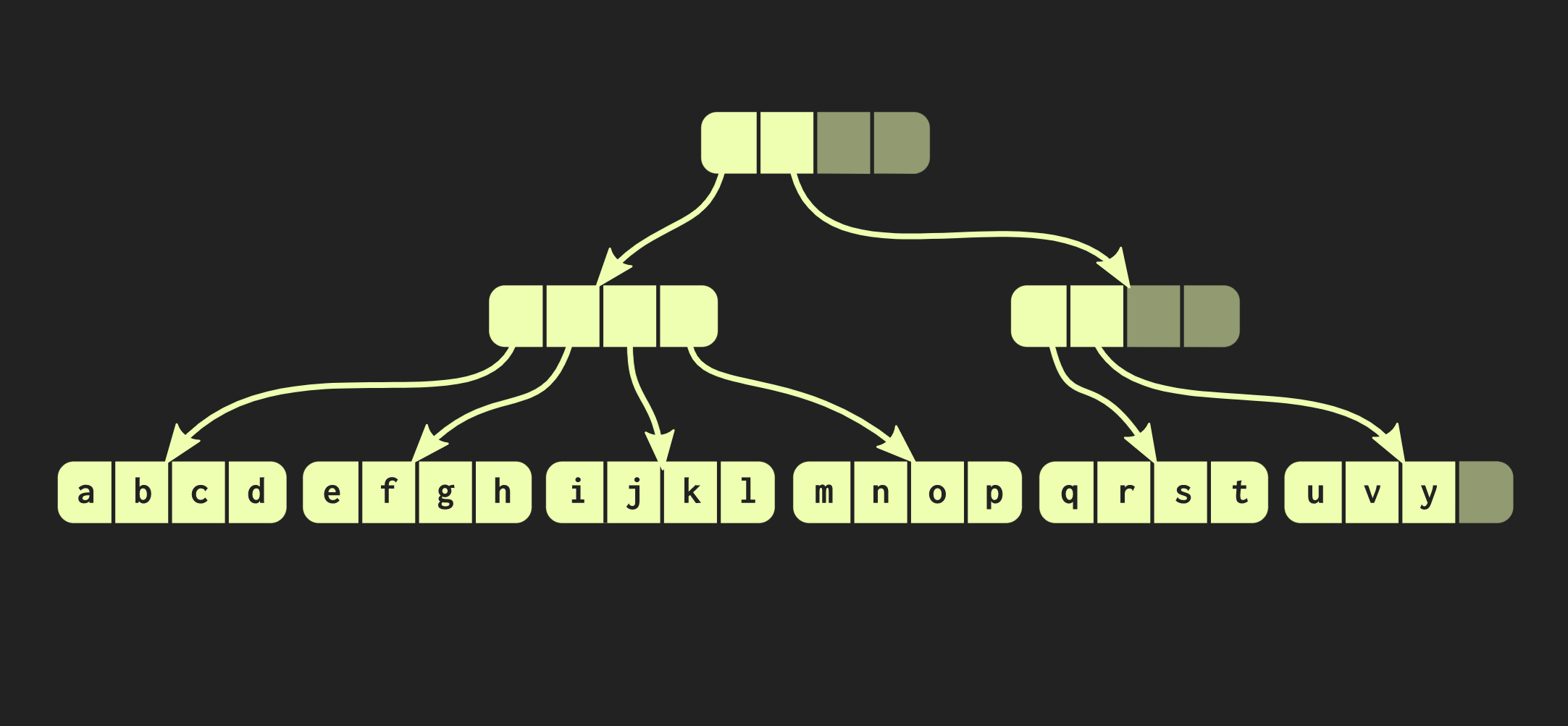 En el ejemplo con el que hemos trabajado hasta ahora, la estructura de datos es muy clara, pero en la práctica, las implementaciones en Clojure y otros lenguajes funcionales se ven diferentes. Crean contenedores para cada valor, es decir, cada elemento en el vector está en una celda separada, y los nodos de hoja contienen punteros a estos elementos. Pero este enfoque es extremadamente ineficiente, en C ++ generalmente no pone todos los valores en un contenedor. Por lo tanto, sería mejor si estos elementos se ubican en nodos directamente. Entonces surge otro problema: diferentes elementos tienen diferentes tamaños. Si el elemento tiene el mismo tamaño que el puntero, nuestra estructura se verá como la que se muestra a continuación:
En el ejemplo con el que hemos trabajado hasta ahora, la estructura de datos es muy clara, pero en la práctica, las implementaciones en Clojure y otros lenguajes funcionales se ven diferentes. Crean contenedores para cada valor, es decir, cada elemento en el vector está en una celda separada, y los nodos de hoja contienen punteros a estos elementos. Pero este enfoque es extremadamente ineficiente, en C ++ generalmente no pone todos los valores en un contenedor. Por lo tanto, sería mejor si estos elementos se ubican en nodos directamente. Entonces surge otro problema: diferentes elementos tienen diferentes tamaños. Si el elemento tiene el mismo tamaño que el puntero, nuestra estructura se verá como la que se muestra a continuación: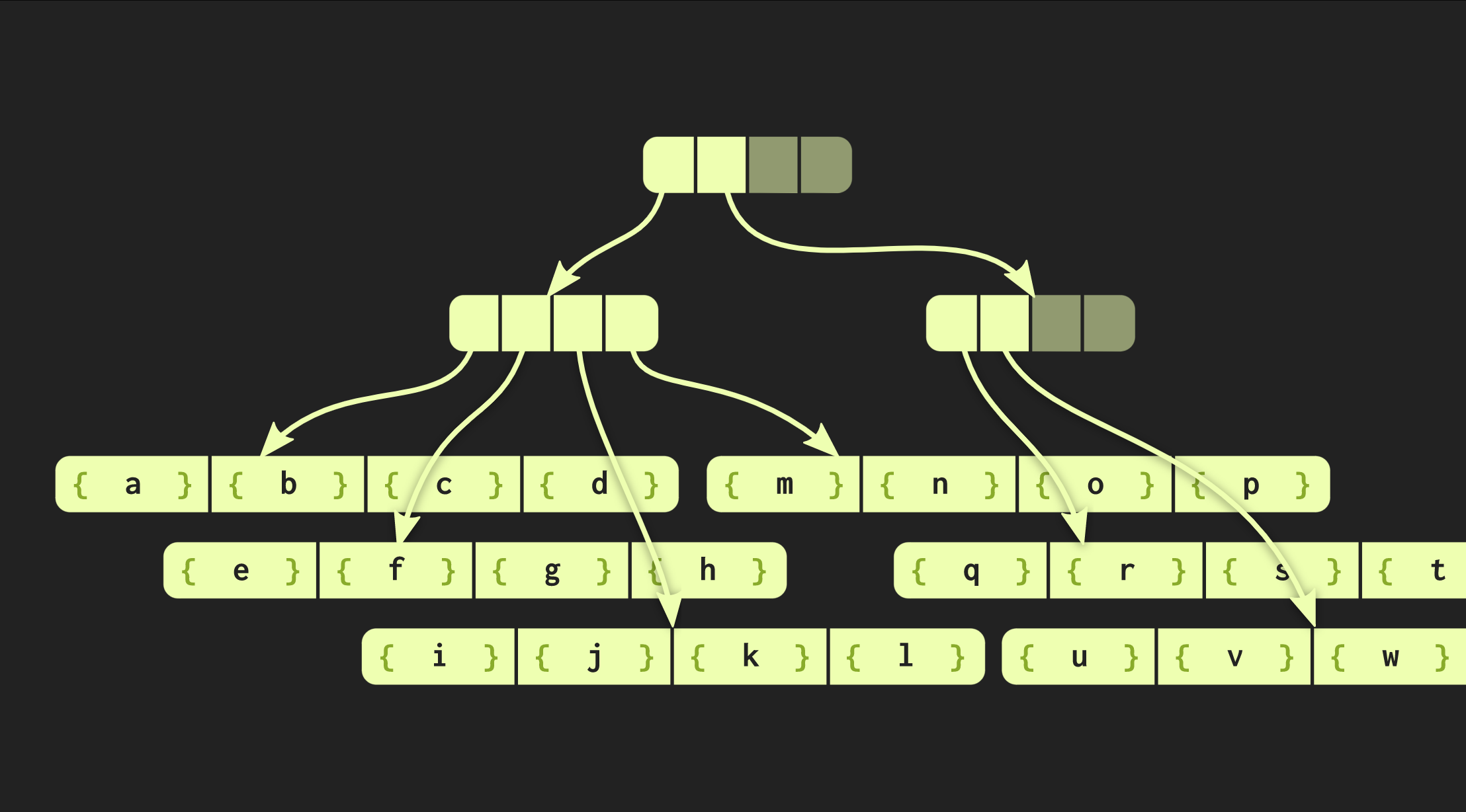 Pero si los elementos son grandes, entonces la estructura de datos pierde las propiedades que medimos (tiempo de acceso O (log (32) ()), porque copiar una de las hojas ahora lleva más tiempo. Por lo tanto, cambié esta estructura de datos para que a medida que aumenta el tamaño el número de elementos contenidos en él disminuyó el número de estos elementos en los nodos de la hoja. Por el contrario, si los elementos son pequeños, ahora pueden caber más. La nueva versión del árbol se llama árbol de incrustación radix balanceado. No se describe por una constante, sino por dos: uno de ellos describe nodos internos y el segundo - frondoso. La implementación del árbol en C ++ puede calcular el tamaño óptimo del elemento de la hoja dependiendo del tamaño de los punteros y de los elementos mismos.Nuestro árbol ya está funcionando bastante bien, pero aún se puede mejorar. Eche un vistazo a una función similar a una función
Pero si los elementos son grandes, entonces la estructura de datos pierde las propiedades que medimos (tiempo de acceso O (log (32) ()), porque copiar una de las hojas ahora lleva más tiempo. Por lo tanto, cambié esta estructura de datos para que a medida que aumenta el tamaño el número de elementos contenidos en él disminuyó el número de estos elementos en los nodos de la hoja. Por el contrario, si los elementos son pequeños, ahora pueden caber más. La nueva versión del árbol se llama árbol de incrustación radix balanceado. No se describe por una constante, sino por dos: uno de ellos describe nodos internos y el segundo - frondoso. La implementación del árbol en C ++ puede calcular el tamaño óptimo del elemento de la hoja dependiendo del tamaño de los punteros y de los elementos mismos.Nuestro árbol ya está funcionando bastante bien, pero aún se puede mejorar. Eche un vistazo a una función similar a una función iota:vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = v.push_back(i);
return v;
}
Toma una entrada vector, se ejecuta push_backal final del vector para cada número entero entre firsty last, y devuelve lo que sucedió. Todo está en orden con la corrección de esta función, pero funciona de manera ineficiente. Cada llamada push_backcopia el bloque más a la izquierda innecesariamente: la siguiente llamada empuja otro elemento y la copia se repite nuevamente, y los datos copiados por el método anterior se eliminan.Puede probar otra implementación de esta función, en la que abandonamos la persistencia dentro de la función. Se puede usar transient vectorcon una API mutable que sea compatible con la API normal vector. Dentro de dicha función, cada llamada push_backcambia la estructura de datos.vector<int> myiota(vector<int> v, int first, int last)
{
auto t = v.transient();
for (auto i = first; i < last; ++i)
t.push_back(i);
return t.persistent();
}
Esta implementación es más eficiente y le permite reutilizar nuevos elementos en el camino correcto. Al final de la función, se realiza una llamada .persistent()que devuelve inmutable vector. Los posibles efectos secundarios permanecen invisibles desde fuera de la función. El original vectorera y sigue siendo inmutable, solo se cambian los datos creados dentro de la función. Como dije, una ventaja importante de este enfoque es que puede usar std::back_inserteralgoritmos estándar que requieren API mutables.Considere otro ejemplo.vector<char> say_hi(vector<char> v)
{
return v.push_back('h')
.push_back('i')
.push_back('!');
}
La función no acepta y regresa vector, pero dentro se ejecuta una cadena de llamadas push_back. Aquí, como en el ejemplo anterior, puede ocurrir una copia innecesaria dentro de la llamada push_back. Tenga en cuenta que el primer valor que se ejecuta push_backes el valor con nombre, y el resto es el valor r, es decir, enlaces anónimos. Si utiliza el recuento de referencias, el método push_backpuede referirse a los contadores de referencia para los nodos para los que se asigna memoria en el árbol. Y en el caso del valor r, si el número de enlaces es uno, queda claro que ninguna otra parte del programa accede a estos nodos. Aquí el rendimiento es exactamente el mismo que en el caso con transient.vector<char> say_hi(vector<char> v)
{
return v.push_back('h') ⟵ named value: v
.push_back('i') ⟵ r-value value
.push_back('!'); ⟵ r-value value
}
Además, para ayudar al compilador, podemos ejecutarlo move(v), ya que vno se usa en ningún otro lugar de la función. Teníamos una ventaja importante, que no estaba en la transientvariante: si pasamos el valor devuelto de otro say_hi a la función say_hi, entonces no habrá copias adicionales. En el caso de c, transientexisten límites en los que puede producirse un exceso de copia. En otras palabras, tenemos una estructura de datos persistente e inmutable, cuyo rendimiento depende de la cantidad real de acceso compartido en tiempo de ejecución. Si no se comparte, el rendimiento será el mismo que el de una estructura de datos mutable. Esta es una propiedad extremadamente importante. El ejemplo que ya te mostré arriba puede reescribirse con un método move(v).vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = std::move(v).push_back(i);
return v;
}
Hasta ahora hemos hablado de vectores, y además de ellos también hay mapas hash. Están dedicados a un informe muy útil de Phil Nash: El Santo Grial. Una matriz hash mapeada trie para C ++ . Describe tablas hash implementadas en base a los mismos principios de los que acabo de hablar.Estoy seguro de que muchos de ustedes tienen dudas sobre el desempeño de tales estructuras. ¿Trabajan rápidamente en la práctica? He hecho muchas pruebas y, en resumen, mi respuesta es sí. Si desea obtener más información sobre los resultados de las pruebas, se publican en mi artículo para la Conferencia Internacional de Programación Funcional 2017. Ahora, creo, es mejor discutir no los valores absolutos, sino el efecto que esta estructura de datos tiene en el sistema en su conjunto. Por supuesto, la actualización de nuestro vector es más lenta porque necesita copiar varios bloques de datos y asignar memoria para otros datos. Pero eludir nuestro vector se realiza casi a la misma velocidad que uno normal. Fue muy importante para mí lograr esto, ya que la lectura de datos se realiza con mucha más frecuencia que el cambio.Además, debido a la actualización más lenta, no es necesario copiar nada, solo se copia la estructura de datos. Por lo tanto, el tiempo dedicado a actualizar el vector se amortiza, por así decirlo, para todas las copias realizadas en el sistema. Por lo tanto, si aplica esta estructura de datos en una arquitectura similar a la que describí al comienzo del informe, el rendimiento aumentará significativamente.Ewig
No seré infundado y demostraré mi estructura de datos usando un ejemplo. Escribí un pequeño editor de texto. Esta es una herramienta interactiva llamada ewig , en la que los documentos están representados por vectores inmutables. Tengo una copia de toda la Wikipedia en esperanto guardada en mi disco, pesa 1 gigabyte (al principio quería descargar la versión en inglés, pero es demasiado grande). Independientemente del editor de texto que utilice, estoy seguro de que no le gustará este archivo. Y cuando descargue este archivo en ewig , puede editarlo de inmediato, porque la descarga es asíncrona. La navegación de archivos funciona, nada se cuelga, no mutex, no hay sincronización. Como puede ver, el archivo descargado toma 20 millones de líneas de código.Antes de considerar las propiedades más importantes de esta herramienta, prestemos atención a un detalle divertido. Al comienzo de la línea, resaltada en blanco en la parte inferior de la imagen, verá dos guiones. Es muy probable que esta IU sea familiar para los usuarios de emacs; los guiones allí significan que el documento no se ha modificado de ninguna manera. Si realiza algún cambio, se muestran asteriscos en lugar de guiones. Pero, a diferencia de otros editores, si elimina estos cambios en ewig (no lo deshaga, simplemente elimínelo), aparecerán nuevamente guiones en lugar de asteriscos, ya que todas las versiones anteriores del texto se guardan en ewig . Gracias a esto, no se necesita un indicador especial para mostrar si el documento ha sido modificado: la presencia de cambios se determina en comparación con el documento original.Considere otra propiedad interesante de la herramienta: copie todo el texto y péguelo un par de veces en el medio del texto existente. Como puede ver, esto sucede al instante. Unir vectores aquí es una operación logarítmica, y el logaritmo de varios millones no es una operación tan larga. Si intenta guardar este documento enorme en su disco duro, tomará mucho más tiempo, ya que el texto ya no se presenta como un vector obtenido de la versión anterior de este vector. Al guardar en el disco, se produce la serialización, por lo que se pierde la persistencia.
Al comienzo de la línea, resaltada en blanco en la parte inferior de la imagen, verá dos guiones. Es muy probable que esta IU sea familiar para los usuarios de emacs; los guiones allí significan que el documento no se ha modificado de ninguna manera. Si realiza algún cambio, se muestran asteriscos en lugar de guiones. Pero, a diferencia de otros editores, si elimina estos cambios en ewig (no lo deshaga, simplemente elimínelo), aparecerán nuevamente guiones en lugar de asteriscos, ya que todas las versiones anteriores del texto se guardan en ewig . Gracias a esto, no se necesita un indicador especial para mostrar si el documento ha sido modificado: la presencia de cambios se determina en comparación con el documento original.Considere otra propiedad interesante de la herramienta: copie todo el texto y péguelo un par de veces en el medio del texto existente. Como puede ver, esto sucede al instante. Unir vectores aquí es una operación logarítmica, y el logaritmo de varios millones no es una operación tan larga. Si intenta guardar este documento enorme en su disco duro, tomará mucho más tiempo, ya que el texto ya no se presenta como un vector obtenido de la versión anterior de este vector. Al guardar en el disco, se produce la serialización, por lo que se pierde la persistencia.Regresar a la arquitectura basada en valores
 Comencemos por cómo no puede volver a esta arquitectura: usando el controlador, el modelo y la vista habituales de estilo Java, que se usan con mayor frecuencia para aplicaciones interactivas en C ++. No hay nada malo con ellos, pero no son adecuados para nuestro problema. Por un lado, el patrón Modelo-Vista-Controlador permite la separación de tareas, pero por otro lado, cada uno de estos elementos es un objeto, tanto desde un punto de vista orientado a objetos como desde el punto de vista de C ++, es decir, estas son áreas de memoria con mutable condición. Ver sabe sobre Modelo; lo que es mucho peor: el Modelo sabe indirectamente acerca de la Vista, porque es casi seguro que hay una devolución de llamada a través de la cual se le notifica a la Vista cuando cambia el Modelo. Incluso con la mejor implementación de principios orientados a objetos, tenemos muchas dependencias mutuas.
Comencemos por cómo no puede volver a esta arquitectura: usando el controlador, el modelo y la vista habituales de estilo Java, que se usan con mayor frecuencia para aplicaciones interactivas en C ++. No hay nada malo con ellos, pero no son adecuados para nuestro problema. Por un lado, el patrón Modelo-Vista-Controlador permite la separación de tareas, pero por otro lado, cada uno de estos elementos es un objeto, tanto desde un punto de vista orientado a objetos como desde el punto de vista de C ++, es decir, estas son áreas de memoria con mutable condición. Ver sabe sobre Modelo; lo que es mucho peor: el Modelo sabe indirectamente acerca de la Vista, porque es casi seguro que hay una devolución de llamada a través de la cual se le notifica a la Vista cuando cambia el Modelo. Incluso con la mejor implementación de principios orientados a objetos, tenemos muchas dependencias mutuas.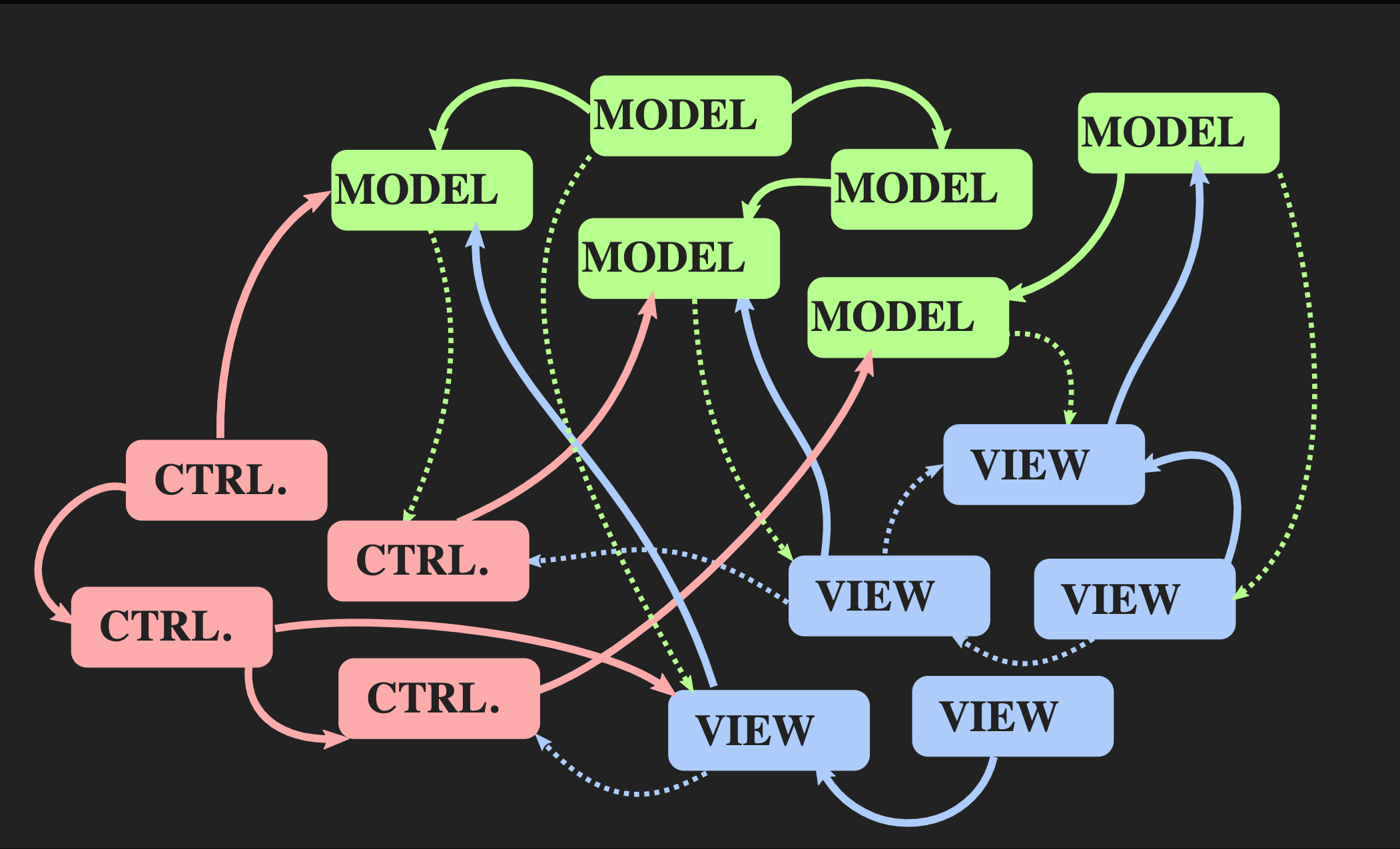 A medida que la aplicación crece y se agregan nuevos modelos, controladores y vistas, surge una situación en la que, para cambiar un segmento del programa, debe conocer todas las partes asociadas, todas las vistas que reciben alertas
A medida que la aplicación crece y se agregan nuevos modelos, controladores y vistas, surge una situación en la que, para cambiar un segmento del programa, debe conocer todas las partes asociadas, todas las vistas que reciben alertas callback, etc. Como resultado, todos el familiar monstruo de la pasta comienza a mirar a través de estas dependencias.¿Es posible otra arquitectura? Existe un enfoque alternativo para el patrón Modelo-Vista-Controlador denominado "Arquitectura de flujo de datos unidireccional". Este concepto no fue inventado por mí, se usa con bastante frecuencia en el desarrollo web. En Facebook, esto se llama la arquitectura Flux, pero en C ++, aún no se aplica.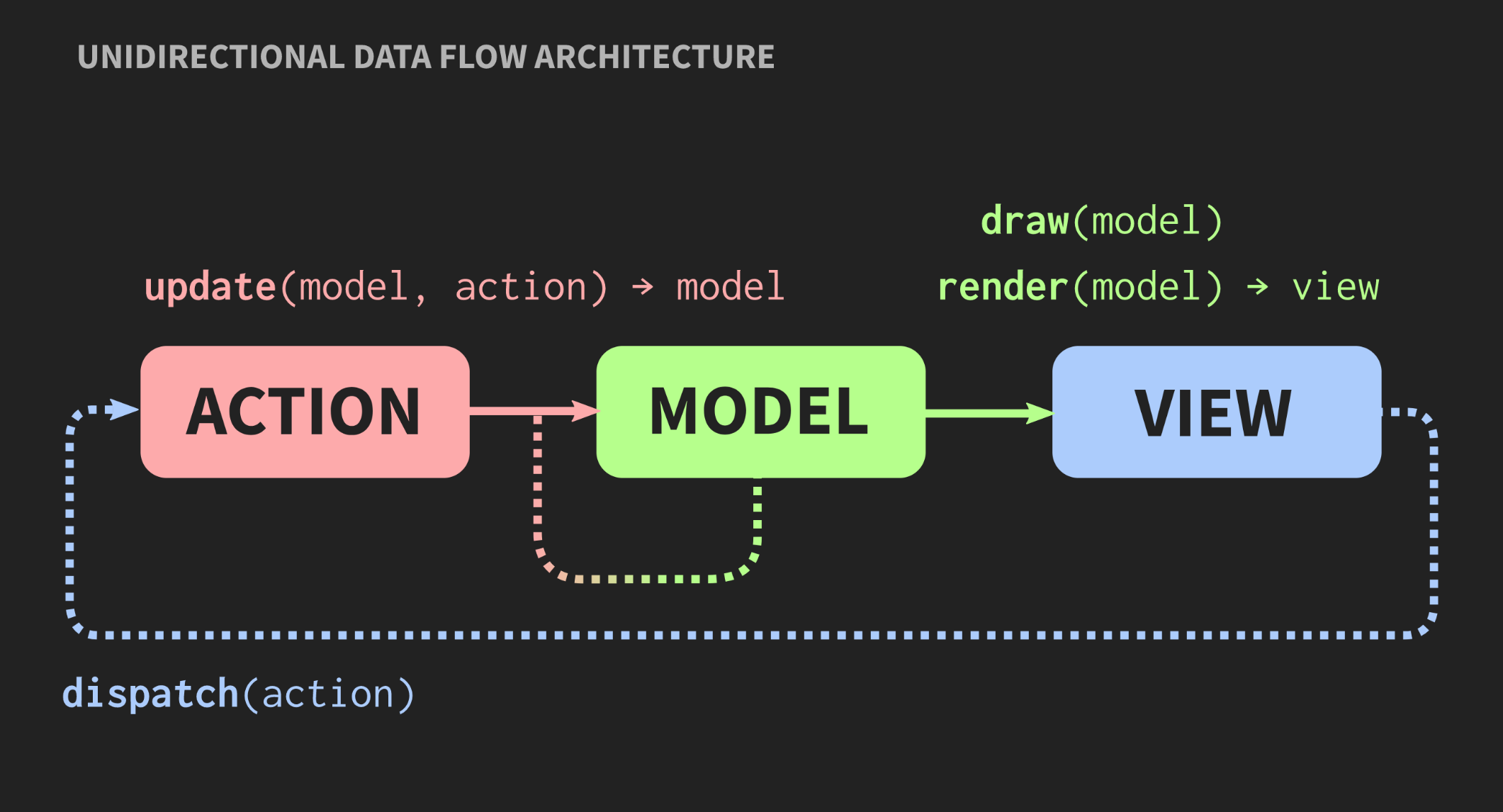 Los elementos de dicha arquitectura ya nos son familiares: Acción, Modelo y Vista, pero el significado de bloques y flechas es diferente. Los bloques son valores, no objetos y no regiones con estados mutables. Esto se aplica incluso a Ver. Además, las flechas no son enlaces, porque sin objetos no puede haber enlaces. Aquí las flechas son funciones. Entre Acción y Modelo, hay una función de actualización que acepta el Modelo actual, es decir, el estado actual del mundo, y Acción, que es una representación de un evento, por ejemplo, un clic del mouse o un evento de otro nivel de abstracción, por ejemplo, la inserción de un elemento o símbolo en un documento. La función de actualización actualiza el documento y devuelve el nuevo estado del mundo. El modelo se conecta al renderizado de la función Ver, que toma el Modelo y devuelve la vista. Esto requiere un marco en el que la vista se pueda representar como valores.En el desarrollo web, React hace esto, pero en C ++ todavía no hay nada igual, aunque quién sabe, si hay personas que quieren pagarme para escribir algo como esto, puede aparecer pronto. Mientras tanto, puede usar la API del modo Inmediato, en la que la función de dibujo le permite crear un valor como efecto secundario.Finalmente, la Vista debe tener un mecanismo que permita al usuario u otras fuentes de eventos enviar Acción. Hay una manera fácil de implementar esto, se presenta a continuación:
Los elementos de dicha arquitectura ya nos son familiares: Acción, Modelo y Vista, pero el significado de bloques y flechas es diferente. Los bloques son valores, no objetos y no regiones con estados mutables. Esto se aplica incluso a Ver. Además, las flechas no son enlaces, porque sin objetos no puede haber enlaces. Aquí las flechas son funciones. Entre Acción y Modelo, hay una función de actualización que acepta el Modelo actual, es decir, el estado actual del mundo, y Acción, que es una representación de un evento, por ejemplo, un clic del mouse o un evento de otro nivel de abstracción, por ejemplo, la inserción de un elemento o símbolo en un documento. La función de actualización actualiza el documento y devuelve el nuevo estado del mundo. El modelo se conecta al renderizado de la función Ver, que toma el Modelo y devuelve la vista. Esto requiere un marco en el que la vista se pueda representar como valores.En el desarrollo web, React hace esto, pero en C ++ todavía no hay nada igual, aunque quién sabe, si hay personas que quieren pagarme para escribir algo como esto, puede aparecer pronto. Mientras tanto, puede usar la API del modo Inmediato, en la que la función de dibujo le permite crear un valor como efecto secundario.Finalmente, la Vista debe tener un mecanismo que permita al usuario u otras fuentes de eventos enviar Acción. Hay una manera fácil de implementar esto, se presenta a continuación:application update(application state, action ev);
void run(const char* fname)
{
auto term = terminal{};
auto state = application{load_buffer(fname), key_map_emacs};
while (!state.done) {
draw(state);
auto act = term.next();
state = update(state, act);
}
}
Con la excepción de guardar y cargar de forma asincrónica, este es el código que se utiliza en el editor que se acaba de presentar. Aquí hay un objeto terminalque le permite leer y escribir desde la línea de comandos. Además, applicationeste es el valor de Model, almacena todo el estado de la aplicación. Como puede ver en la parte superior de la pantalla, hay una función que devuelve una nueva versión application. El ciclo dentro de la función se ejecuta hasta que la aplicación necesita cerrarse, es decir, hasta !state.done. En el bucle, se dibuja un nuevo estado, luego se solicita el siguiente evento. Finalmente, el estado se almacena en una variable local statey el ciclo comienza nuevamente. Este código tiene una ventaja muy importante: solo existe una variable mutable durante la ejecución del programa, es un objeto state.Los desarrolladores de Clojure llaman a esta arquitectura de un solo átomo: hay un solo punto en toda la aplicación a través del cual se realizan todos los cambios. La lógica de la aplicación no participa en la actualización de este punto de ninguna manera; esto hace un ciclo especialmente diseñado para esto. Gracias a esto, la lógica de la aplicación consiste completamente en funciones puras, como funciones update.Con este enfoque para escribir aplicaciones, la forma de pensar sobre el software está cambiando. El trabajo ahora comienza no con el diagrama UML de interfaces y operaciones, sino con los datos en sí. Hay algunas similitudes con el diseño orientado a datos. Es cierto que el diseño orientado a datos generalmente se usa para obtener el máximo rendimiento, aquí, además de la velocidad, nos esforzamos por la simplicidad y la corrección. El énfasis es ligeramente diferente, pero existen importantes similitudes en la metodología.using index = int;
struct coord
{
index row = {};
index col = {};
};
using line = immer::flex_vector<char>;
using text = immer::flex_vector<line>;
struct file
{
immer::box<std::string> name;
text content;
};
struct snapshot
{
text content;
coord cursor;
};
struct buffer
{
file from;
text content;
coord cursor;
coord scroll;
std::optional<coord> selection_start;
immer::vector<snapshot> history;
std::optional<std::size_t> history_pos;
};
struct application
{
buffer current;
key_map keys;
key_seq input;
immer::vector<text> clipboard;
immer::vector<message> messages;
};
struct action { key_code key; coord size; };
Arriba están los principales tipos de datos de nuestra aplicación. El cuerpo principal de la aplicación consta line, que es flex_vector, y flex_vector es vectoruno para el que puede realizar una operación de unión. El siguiente textes el vector en el que se almacena line. Como puede ver, esta es una representación muy simple del texto. Textalmacenado con la ayuda filede los cuales tiene un nombre, es decir, una dirección en el sistema de archivos, y en realidad text. Como se fileusa otro tipo, un simple pero muy útil: box. Este es un contenedor de un solo elemento. Le permite poner en un montón y mover un objeto, copiando que puede ser demasiado intensivo en recursos.Otro tipo importante: snapshot. Según este tipo, una función de cancelación está activa. Contiene un documento (en el formulariotext) y posición del cursor (coord). Esto le permite devolver el cursor a la posición en la que estaba durante la edición.El siguiente tipo es buffer. Este es un término de vim y emacs, ya que los documentos abiertos se llaman allí. En bufferhay un archivo del que se descargó el texto, así como el contenido del texto - esto le permite comprobar los cambios en el documento. Para resaltar parte del texto, hay una variable opcional que selection_startindica el comienzo de la selección. El vector de snapshotes la historia del texto. Tenga en cuenta que no utilizamos el patrón Equipo; el historial consta solo de estados. Finalmente, si la cancelación se acaba de completar, necesitamos un índice de posición en el historial del estado history_pos.El siguiente tipo: application. Contiene un documento abierto (búfer) key_mapykey_seqpara atajos de teclado, así como un vector textpara el portapapeles y otro vector para mensajes que se muestran en la parte inferior de la pantalla. Hasta ahora, en la versión debut de la aplicación, solo habrá un hilo y un tipo de acción que tome entrada key_codey coord.Lo más probable es que muchos de ustedes ya estén pensando en cómo implementar estas operaciones. Si se toma por valor y se devuelve por valor, en la mayoría de los casos las operaciones son bastante simples. El código de mi editor de texto está publicado en github , para que pueda ver cómo se ve realmente. Ahora me detendré en detalles solo en el código que implementa la función de cancelación.Cancelar
Escribir correctamente una cancelación sin la infraestructura adecuada no es tan simple. En mi editor, lo implementé siguiendo las líneas de emacs, así que primero un par de palabras sobre sus principios básicos. Aquí falta el comando de retorno y, gracias a esto, no puede perder el trabajo. Si es necesaria una devolución, se realiza cualquier cambio en el texto, y luego todas las acciones de cancelación vuelven a formar parte del historial de cancelación. Este principio se muestra arriba. El rombo rojo aquí muestra una posición en la historia: si una cancelación no se ha completado, el rombo rojo siempre está al final. Si cancela, el diamante retrocederá un estado, pero al mismo tiempo, se agregará otro estado al final de la cola, lo mismo que el usuario ve actualmente (S3). Si cancela nuevamente y regresa al estado S2, el estado S2 se agrega al final de la cola. Si ahora el usuario realiza algún tipo de cambio, se agregará al final de la cola como un nuevo estado de S5 y se moverá un rombo a él. Ahora, al deshacer acciones pasadas, las acciones de deshacer anteriores se desplazarán primero. Para implementar dicho sistema de cancelación, el siguiente código es suficiente:
Este principio se muestra arriba. El rombo rojo aquí muestra una posición en la historia: si una cancelación no se ha completado, el rombo rojo siempre está al final. Si cancela, el diamante retrocederá un estado, pero al mismo tiempo, se agregará otro estado al final de la cola, lo mismo que el usuario ve actualmente (S3). Si cancela nuevamente y regresa al estado S2, el estado S2 se agrega al final de la cola. Si ahora el usuario realiza algún tipo de cambio, se agregará al final de la cola como un nuevo estado de S5 y se moverá un rombo a él. Ahora, al deshacer acciones pasadas, las acciones de deshacer anteriores se desplazarán primero. Para implementar dicho sistema de cancelación, el siguiente código es suficiente:buffer record(buffer before, buffer after)
{
if (before.content != after.content) {
after.history = after.history.push_back({before.content, before.cursor});
if (before.history_pos == after.history_pos)
after.history_pos = std::nullopt;
}
return after;
}
buffer undo(buffer buf)
{
auto idx = buf.history_pos.value_or(buf.history.size());
if (idx > 0) {
auto restore = buf.history[--idx];
buf.content = restore.content;
buf.cursor = restore.cursor;
buf.history_pos = idx;
}
return buf;
}
Hay dos acciones, recordy undo. Recordrealizado durante cualquier operación. Esto es muy conveniente ya que no necesitamos saber si se produjo alguna edición del documento. La función es transparente a la lógica de la aplicación. Después de cualquier acción, la función verifica si el documento ha cambiado. Si se ha producido un cambio, push_backse ejecutan los contenidos y la posición del cursor history. Si la acción no condujo a un cambio history_pos(es decir, la entrada recibida bufferno es causada por la acción cancelar), entonces history_posse asigna un valor null. Si es necesario undo, lo comprobamos history_pos. Si no tiene sentido, consideramos que history_posestá al final de la historia. Si el historial de cancelación no está vacío (es decir,history_posno al comienzo de la historia), se realiza la cancelación. El contenido actual y el cursor se reemplazan y cambian history_pos. La irrevocabilidad de la operación de deshacer se logra mediante la función record, que también se llama durante la operación de deshacer.Entonces, tenemos una operación undoque ocupa 10 líneas de código, y que sin cambios (o con cambios mínimos) se puede usar en casi cualquier otra aplicación.Viaje en el tiempo
Sobre el viaje en el tiempo. Como veremos ahora, este es un tema relacionado con la cancelación. Demostraré el trabajo de un marco que agregará funcionalidades útiles a cualquier aplicación con una arquitectura similar. El marco aquí se llama ewig-debug . Esta versión de ewig incluye algunas características de depuración. Ahora desde el navegador puede abrir el depurador, en el que puede examinar el estado de la aplicación. Vemos que la última acción fue cambiar el tamaño, porque abrí una nueva ventana, y mi administrador de ventanas redimensionó automáticamente la ventana ya abierta. Por supuesto, para la serialización automática en JSON, tuve que agregar anotaciones para la estructura de la biblioteca especial de reflexión. Pero el resto del sistema es bastante universal, se puede conectar a cualquier aplicación similar. Ahora en el navegador puede ver todas las acciones completadas. Por supuesto, hay un estado inicial que no tiene acción. Este es el estado anterior a la descarga. Además, al hacer doble clic puedo devolver la aplicación a su estado anterior. Esta es una herramienta de depuración muy útil que le permite rastrear la ocurrencia de un mal funcionamiento en la aplicación.Si está interesado, puede escuchar mi informe sobre CPPCON 19, Los valores más valiosos, allí examinaré este depurador en detalle.Además, la arquitectura basada en el valor se discute con más detalle allí. En él, también te digo cómo implementar acciones y organizarlas jerárquicamente. Esto asegura la modularidad del sistema y elimina la necesidad de mantener todo en una gran función de actualización. Además, ese informe habla sobre asincronía y descargas de archivos multiproceso. Existe otra versión de este informe en la que media hora de material adicional son estructuras de datos inmutables posmodernas.
Vemos que la última acción fue cambiar el tamaño, porque abrí una nueva ventana, y mi administrador de ventanas redimensionó automáticamente la ventana ya abierta. Por supuesto, para la serialización automática en JSON, tuve que agregar anotaciones para la estructura de la biblioteca especial de reflexión. Pero el resto del sistema es bastante universal, se puede conectar a cualquier aplicación similar. Ahora en el navegador puede ver todas las acciones completadas. Por supuesto, hay un estado inicial que no tiene acción. Este es el estado anterior a la descarga. Además, al hacer doble clic puedo devolver la aplicación a su estado anterior. Esta es una herramienta de depuración muy útil que le permite rastrear la ocurrencia de un mal funcionamiento en la aplicación.Si está interesado, puede escuchar mi informe sobre CPPCON 19, Los valores más valiosos, allí examinaré este depurador en detalle.Además, la arquitectura basada en el valor se discute con más detalle allí. En él, también te digo cómo implementar acciones y organizarlas jerárquicamente. Esto asegura la modularidad del sistema y elimina la necesidad de mantener todo en una gran función de actualización. Además, ese informe habla sobre asincronía y descargas de archivos multiproceso. Existe otra versión de este informe en la que media hora de material adicional son estructuras de datos inmutables posmodernas.Para resumir
Creo que es hora de hacer un balance. Citaré a Andy Wingo: es un excelente desarrollador, dedicó mucho tiempo a V8 y a los compiladores en general, finalmente se dedica a apoyar a Guile, implementando Scheme for GNU. Recientemente, escribió en su Twitter: “Para lograr una ligera aceleración del programa, medimos cada pequeño cambio y dejamos solo aquellos que dan un resultado positivo. Y realmente logramos una aceleración significativa, ciegamente, invirtiendo mucho esfuerzo, sin tener 100% de confianza y guiados solo por la intuición. Qué dicotomía más extraña.Me parece que los desarrolladores de C ++ están teniendo éxito en el primer género. Danos un sistema cerrado y nosotros, armados con nuestras herramientas, exprimiremos todo lo que sea posible. Pero en el segundo género no estamos acostumbrados a trabajar. Por supuesto, el segundo enfoque es más arriesgado y, a menudo, conduce a una pérdida de gran esfuerzo. Por otro lado, al reescribir completamente un programa, a menudo se puede hacer más fácil y más rápido. Espero haber logrado convencerte de que al menos intentes este segundo enfoque.Juan Puente habló en la conferencia C ++ Rusia 2019 Moscú y habló sobre las estructuras de datos que le permiten hacer cosas interesantes. Parte de la magia de estas estructuras radica en la elisión de copia: esto es de lo que Anton Polukhin y Roman Rusyaev hablarán en la próxima conferencia . Siga las actualizaciones del programa en el sitio.