Comprender el modelo de aprendizaje automático que rompe CAPTCHA
¡Hola a todos! Este mes, OTUS está reclutando un nuevo grupo en el curso de Machine Learning . Según la tradición establecida, en la víspera del inicio del curso, compartimos con ustedes la traducción de material interesante sobre el tema. La visión por computadora es uno de los temas más relevantes e investigados de la IA [1], sin embargo, los métodos actuales para resolver problemas utilizando redes neuronales convolucionales son muy criticados porque estas redes son fáciles de engañar. Para no ser infundado, le contaré varias razones: las redes de este tipo dan un resultado incorrecto con alta confianza para las imágenes naturales que no contienen señales estadísticas [2], de las que dependen las redes neuronales convolucionales, para las imágenes que previamente se clasificaron correctamente, pero en el que un píxel [3] o imágenes con objetos físicos que se agregaron a la escena pero no tuvieron que cambiar el resultado de clasificación [4] cambió. El hecho es que, si queremos crear máquinas verdaderamente inteligentes,Nos parece razonable invertir en el estudio de nuevas ideas.Una de estas nuevas ideas es la aplicación de Vicarious de la Red Cortical Recursiva (RCN), que se inspira en la neurociencia. Este modelo afirmaba ser extremadamente efectivo para romper el captcha de texto, lo que provocaba muchas conversaciones sobre sí mismo . Por lo tanto, decidí escribir varios artículos, cada uno de los cuales explica un cierto aspecto de este modelo. En este artículo, hablaremos sobre su estructura y cómo se genera la generación de imágenes presentadas en los materiales del artículo principal sobre RCN [5].Este artículo asume que ya está familiarizado con las redes neuronales convolucionales, por lo que trazaré muchas analogías con ellas.Para prepararse para la conciencia de RCN, debe comprender que los RCN se basan en la idea de separar la forma (boceto del objeto) de la apariencia (su textura) y que es un modelo generativo, no discriminante, por lo que podemos generar imágenes al usarlo, como en un generativo redes de confrontación. Además, se utiliza una estructura jerárquica paralela, similar a la arquitectura de redes neuronales convolucionales, que comienza con la etapa de determinar la forma del objeto objetivo en las capas inferiores, y luego se agrega su apariencia en la capa superior. A diferencia de las redes neuronales convolucionales, el modelo que estamos considerando se basa en una rica base teórica de modelos gráficos, en lugar de sumas ponderadas y descenso de gradiente. Ahora profundicemos en las características de la estructura RCN.
La visión por computadora es uno de los temas más relevantes e investigados de la IA [1], sin embargo, los métodos actuales para resolver problemas utilizando redes neuronales convolucionales son muy criticados porque estas redes son fáciles de engañar. Para no ser infundado, le contaré varias razones: las redes de este tipo dan un resultado incorrecto con alta confianza para las imágenes naturales que no contienen señales estadísticas [2], de las que dependen las redes neuronales convolucionales, para las imágenes que previamente se clasificaron correctamente, pero en el que un píxel [3] o imágenes con objetos físicos que se agregaron a la escena pero no tuvieron que cambiar el resultado de clasificación [4] cambió. El hecho es que, si queremos crear máquinas verdaderamente inteligentes,Nos parece razonable invertir en el estudio de nuevas ideas.Una de estas nuevas ideas es la aplicación de Vicarious de la Red Cortical Recursiva (RCN), que se inspira en la neurociencia. Este modelo afirmaba ser extremadamente efectivo para romper el captcha de texto, lo que provocaba muchas conversaciones sobre sí mismo . Por lo tanto, decidí escribir varios artículos, cada uno de los cuales explica un cierto aspecto de este modelo. En este artículo, hablaremos sobre su estructura y cómo se genera la generación de imágenes presentadas en los materiales del artículo principal sobre RCN [5].Este artículo asume que ya está familiarizado con las redes neuronales convolucionales, por lo que trazaré muchas analogías con ellas.Para prepararse para la conciencia de RCN, debe comprender que los RCN se basan en la idea de separar la forma (boceto del objeto) de la apariencia (su textura) y que es un modelo generativo, no discriminante, por lo que podemos generar imágenes al usarlo, como en un generativo redes de confrontación. Además, se utiliza una estructura jerárquica paralela, similar a la arquitectura de redes neuronales convolucionales, que comienza con la etapa de determinar la forma del objeto objetivo en las capas inferiores, y luego se agrega su apariencia en la capa superior. A diferencia de las redes neuronales convolucionales, el modelo que estamos considerando se basa en una rica base teórica de modelos gráficos, en lugar de sumas ponderadas y descenso de gradiente. Ahora profundicemos en las características de la estructura RCN.Capas de características
El primer tipo de capa en RCN se llama capa de entidades. Consideraremos el modelo gradualmente, así que supongamos por ahora que toda la jerarquía del modelo consta solo de capas de este tipo apiladas una encima de la otra. Pasaremos de conceptos abstractos de alto nivel a características más específicas de las capas inferiores, como se muestra en la Figura 1 . Una capa de este tipo consta de varios nodos ubicados en un espacio bidimensional, de manera similar a los mapas de características en redes neuronales convolucionales. Figura 1 : Varias capas de entidades ubicadas una encima de la otra con nodos en un espacio bidimensional. La transición de la cuarta a la primera capa significa la transición de lo general a lo particular.Cada nodo consta de varios canales, cada uno de los cuales representa una característica separada. Los canales son variables binarias que toman el valor Verdadero o Falso, lo que indica si existe un objeto correspondiente a este canal en la imagen final generada en la coordenada (x, y) del nodo. En cualquier nivel, los nodos tienen el mismo tipo de canales.Como ejemplo, tomemos una capa intermedia y hablemos sobre sus canales y las capas anteriores para simplificar la explicación. La lista de canales en esta capa será una hipérbola, un círculo y una parábola. En cierta ejecución al generar la imagen, los cálculos de las capas superpuestas requerían un círculo en la coordenada (1,1). Por lo tanto, el nodo (1, 1) tendrá un canal correspondiente al objeto "círculo" en el valor Verdadero. Esto afectará directamente a algunos nodos en la capa a continuación, es decir, las entidades de nivel inferior que están asociadas con el círculo en el vecindario (1,1) se establecerán en Verdadero. Estos objetos de nivel inferior pueden ser, por ejemplo, cuatro arcos con diferentes orientaciones. Cuando se activan las características de la capa inferior, activan los canales en las capas aún más bajas hasta que se alcanza la última capa,Generador de imágenes. La visualización de activación se muestra enLa Figura 2 .Puedes preguntar, ¿cómo quedará claro que la representación de un círculo es de 4 arcos? ¿Y cómo sabe RCN que necesita un canal para representar el círculo? Los canales y sus enlaces a otras capas se formarán en la etapa de entrenamiento RCN.
Figura 1 : Varias capas de entidades ubicadas una encima de la otra con nodos en un espacio bidimensional. La transición de la cuarta a la primera capa significa la transición de lo general a lo particular.Cada nodo consta de varios canales, cada uno de los cuales representa una característica separada. Los canales son variables binarias que toman el valor Verdadero o Falso, lo que indica si existe un objeto correspondiente a este canal en la imagen final generada en la coordenada (x, y) del nodo. En cualquier nivel, los nodos tienen el mismo tipo de canales.Como ejemplo, tomemos una capa intermedia y hablemos sobre sus canales y las capas anteriores para simplificar la explicación. La lista de canales en esta capa será una hipérbola, un círculo y una parábola. En cierta ejecución al generar la imagen, los cálculos de las capas superpuestas requerían un círculo en la coordenada (1,1). Por lo tanto, el nodo (1, 1) tendrá un canal correspondiente al objeto "círculo" en el valor Verdadero. Esto afectará directamente a algunos nodos en la capa a continuación, es decir, las entidades de nivel inferior que están asociadas con el círculo en el vecindario (1,1) se establecerán en Verdadero. Estos objetos de nivel inferior pueden ser, por ejemplo, cuatro arcos con diferentes orientaciones. Cuando se activan las características de la capa inferior, activan los canales en las capas aún más bajas hasta que se alcanza la última capa,Generador de imágenes. La visualización de activación se muestra enLa Figura 2 .Puedes preguntar, ¿cómo quedará claro que la representación de un círculo es de 4 arcos? ¿Y cómo sabe RCN que necesita un canal para representar el círculo? Los canales y sus enlaces a otras capas se formarán en la etapa de entrenamiento RCN.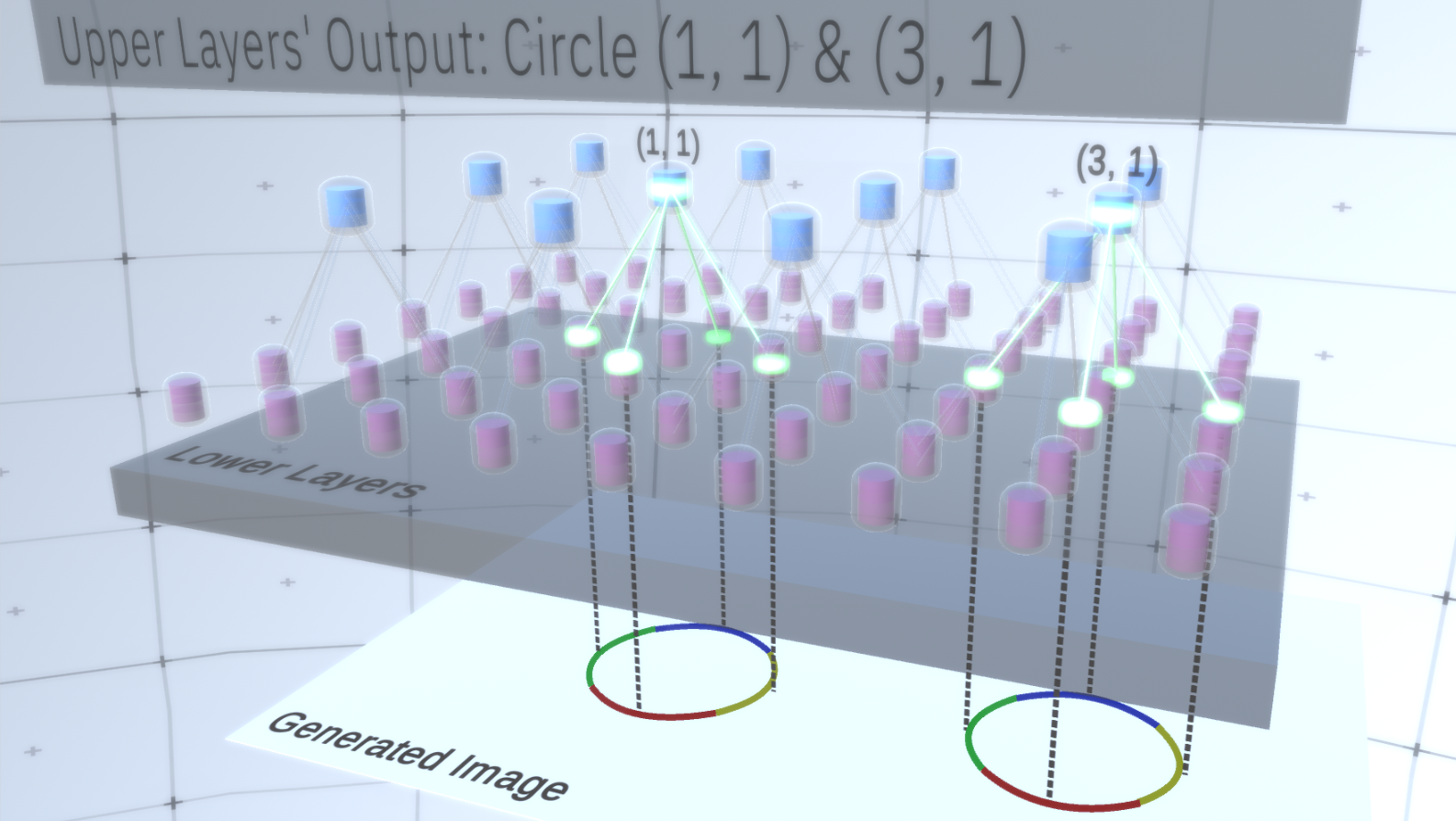 Figura 2: Flujo de información en capas de entidades. Los nodos de signos son cápsulas que contienen discos que representan canales. Algunas de las capas superior e inferior se presentaron en forma de paralelepípedo por simplicidad, sin embargo, en realidad también consisten en nodos de características como capas intermedias. Tenga en cuenta que la capa intermedia superior consta de 3 canales, y la segunda capa consta de 4 canales.Puede indicar un método muy rígido y determinista para generar el modelo adoptado, pero para las personas, las pequeñas perturbaciones de la curvatura del círculo todavía se consideran un círculo, como puede ver en la Figura 3 .
Figura 2: Flujo de información en capas de entidades. Los nodos de signos son cápsulas que contienen discos que representan canales. Algunas de las capas superior e inferior se presentaron en forma de paralelepípedo por simplicidad, sin embargo, en realidad también consisten en nodos de características como capas intermedias. Tenga en cuenta que la capa intermedia superior consta de 3 canales, y la segunda capa consta de 4 canales.Puede indicar un método muy rígido y determinista para generar el modelo adoptado, pero para las personas, las pequeñas perturbaciones de la curvatura del círculo todavía se consideran un círculo, como puede ver en la Figura 3 .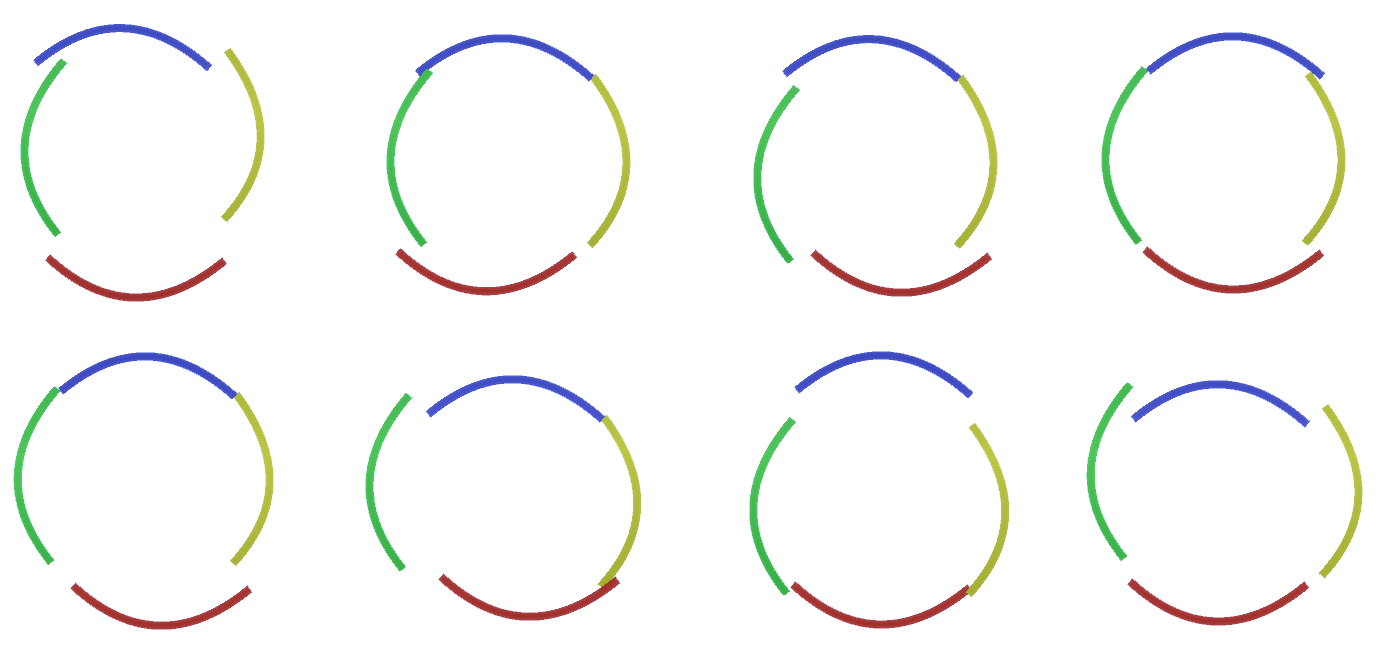 Figura 3: Muchas variaciones de la construcción de un círculo de cuatro arcos curvos de la Figura 2.Sería difícil considerar cada una de estas variaciones como un nuevo canal separado en la capa. Del mismo modo, agrupar variaciones en la misma entidad facilitará en gran medida la generalización en nuevas variaciones cuando adaptemos RCN a la clasificación en lugar de generar un poco más tarde. Pero, ¿cómo cambiamos RCN para tener esta oportunidad?
Figura 3: Muchas variaciones de la construcción de un círculo de cuatro arcos curvos de la Figura 2.Sería difícil considerar cada una de estas variaciones como un nuevo canal separado en la capa. Del mismo modo, agrupar variaciones en la misma entidad facilitará en gran medida la generalización en nuevas variaciones cuando adaptemos RCN a la clasificación en lugar de generar un poco más tarde. Pero, ¿cómo cambiamos RCN para tener esta oportunidad?Capas de submuestreo
Para hacer esto, necesita un nuevo tipo de capa: la capa de agrupación. Se encuentra entre dos capas de signos y actúa como intermediario entre ellas. También consta de canales, sin embargo, tienen valores enteros, no binarios.Para ilustrar cómo funcionan estas capas, volvamos al ejemplo del círculo. En lugar de requerir 4 arcos con coordenadas fijas desde la capa de entidades que se encuentra arriba como una característica de un círculo, la búsqueda se realizará en la capa de submuestra. Luego, cada canal activado en la capa de submuestra seleccionará un nodo en la capa subyacente en su vecindad para permitir una ligera distorsión de la característica. Por lo tanto, si establecemos comunicación con 9 nodos directamente debajo del nodo de submuestra, el canal de submuestra, cuando esté activado, seleccionará de manera uniforme uno de estos 9 nodos y lo activará, y el índice del nodo seleccionado será el estado del canal de submuestra - un número entero. En la figura 4puede ver varias ejecuciones, donde cada ejecución usa un conjunto diferente de nodos de nivel inferior, respectivamente, lo que le permite crear un círculo de varias maneras. Figura 4: Operación de capas de submuestreo. Cada cuadro en esta imagen GIF es un lanzamiento por separado. Los nodos de submuestreo están en cubos. En esta imagen, los nodos de la submuestra tienen 4 canales equivalentes a 4 canales de la capa de entidades debajo de ella. Las capas superior e inferior se eliminaron por completo de la imagen.A pesar de que necesitábamos la variabilidad de nuestro modelo, sería mejor si se mantuviera más restringido y centrado. En las dos figuras anteriores, algunos círculos parecen demasiado extraños para interpretarlos realmente como círculos debido al hecho de que los arcos no están interconectados, como se puede ver en la Figura 5. Nos gustaría evitar generarlos. Por lo tanto, si pudiéramos agregar un mecanismo para submuestreo de canales para coordinar la selección de nodos de entidades y enfocarnos en formas continuas, nuestro modelo sería más preciso.
Figura 4: Operación de capas de submuestreo. Cada cuadro en esta imagen GIF es un lanzamiento por separado. Los nodos de submuestreo están en cubos. En esta imagen, los nodos de la submuestra tienen 4 canales equivalentes a 4 canales de la capa de entidades debajo de ella. Las capas superior e inferior se eliminaron por completo de la imagen.A pesar de que necesitábamos la variabilidad de nuestro modelo, sería mejor si se mantuviera más restringido y centrado. En las dos figuras anteriores, algunos círculos parecen demasiado extraños para interpretarlos realmente como círculos debido al hecho de que los arcos no están interconectados, como se puede ver en la Figura 5. Nos gustaría evitar generarlos. Por lo tanto, si pudiéramos agregar un mecanismo para submuestreo de canales para coordinar la selección de nodos de entidades y enfocarnos en formas continuas, nuestro modelo sería más preciso. Figura 5: Muchas opciones para construir un círculo. Esas opciones que queremos soltar están marcadas con cruces rojas.Los autores de RCN utilizaron conexión lateral en capas de submuestreo para este propósito. Esencialmente, los canales de submuestreo tendrán enlaces con otros canales de submuestreo del entorno inmediato, y estos enlaces no permitirán que algunos pares de estados coexistan en dos canales simultáneamente. De hecho, el área de muestra de estos dos canales será simplemente limitada. En varias versiones del círculo, estas conexiones, por ejemplo, no permitirán que dos arcos adyacentes se alejen uno del otro. Este mecanismo se muestra en la Figura 6.. Una vez más, estas relaciones se establecen en la etapa de capacitación. Cabe señalar que las redes neuronales artificiales modernas de vainilla no tienen conexiones laterales en sus capas, aunque sí existen en redes neuronales biológicas y se supone que juegan un papel en la integración del contorno en la corteza visual (pero, francamente, la corteza visual tiene donde dispositivo más complejo de lo que parece en la declaración anterior).
Figura 5: Muchas opciones para construir un círculo. Esas opciones que queremos soltar están marcadas con cruces rojas.Los autores de RCN utilizaron conexión lateral en capas de submuestreo para este propósito. Esencialmente, los canales de submuestreo tendrán enlaces con otros canales de submuestreo del entorno inmediato, y estos enlaces no permitirán que algunos pares de estados coexistan en dos canales simultáneamente. De hecho, el área de muestra de estos dos canales será simplemente limitada. En varias versiones del círculo, estas conexiones, por ejemplo, no permitirán que dos arcos adyacentes se alejen uno del otro. Este mecanismo se muestra en la Figura 6.. Una vez más, estas relaciones se establecen en la etapa de capacitación. Cabe señalar que las redes neuronales artificiales modernas de vainilla no tienen conexiones laterales en sus capas, aunque sí existen en redes neuronales biológicas y se supone que juegan un papel en la integración del contorno en la corteza visual (pero, francamente, la corteza visual tiene donde dispositivo más complejo de lo que parece en la declaración anterior).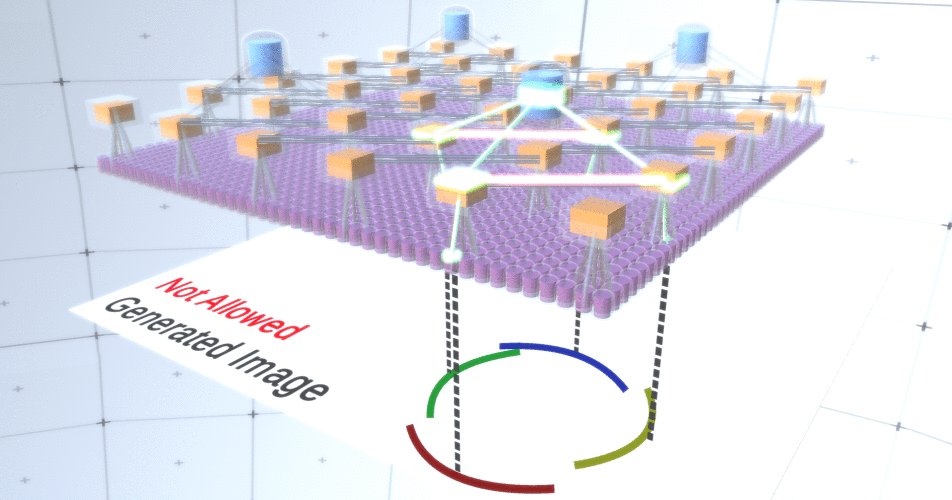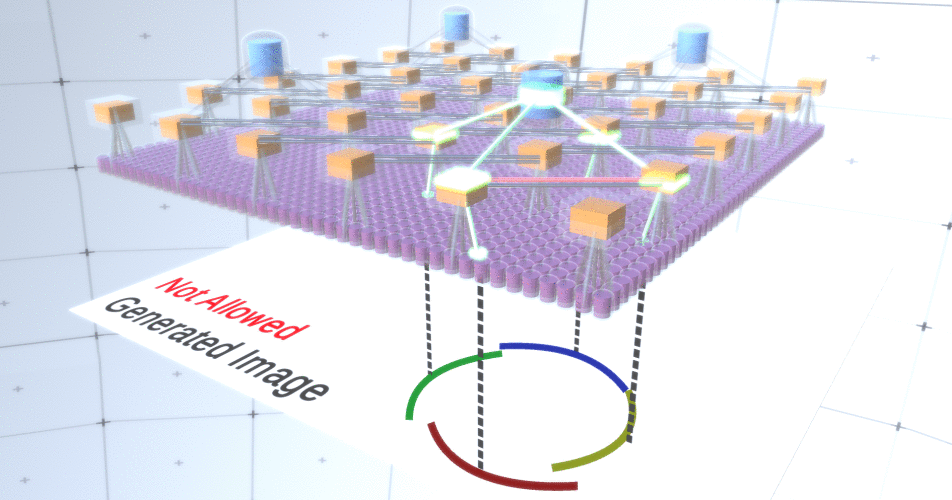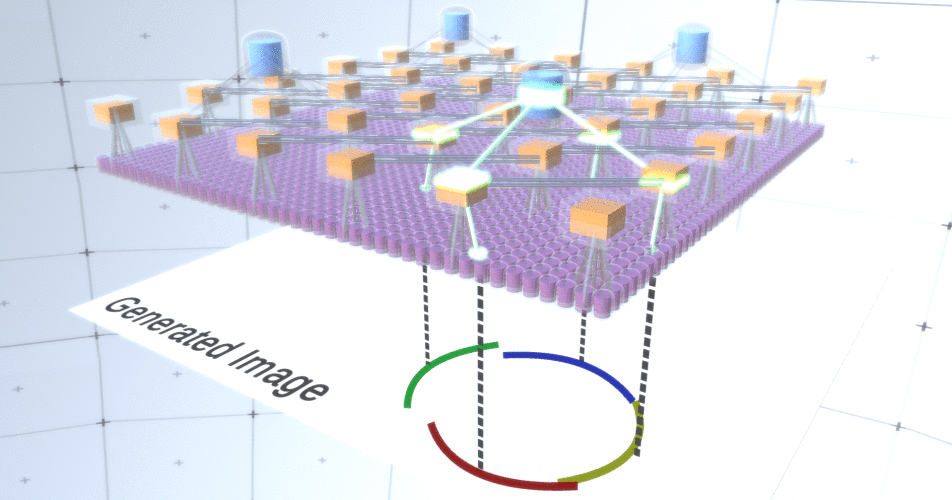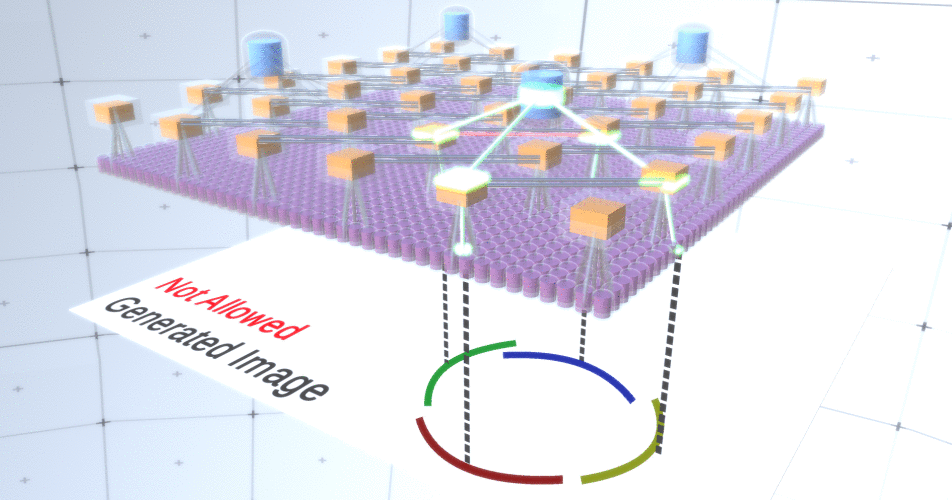 Figura 6: GIF- RCN . , . , RCN , , . .Hasta ahora, hablamos de las capas intermedias de RCN, solo tenemos la capa superior y la capa inferior que interactúa con los píxeles de la imagen generada. La capa superior es una capa de entidad regular, donde los canales de cada nodo serán clases de nuestro conjunto de datos etiquetado. Al generar, simplemente seleccionamos la ubicación y la clase que queremos crear, vamos al nodo con la ubicación especificada y decimos que activa el canal de la clase que seleccionamos. Esto activa algunos de los canales en la capa de submuestra debajo de ella, luego la capa de características debajo, y así sucesivamente, hasta llegar a la última capa de características. Según su conocimiento de las redes neuronales convolucionales, debe pensar que la capa superior tendrá un solo nodo, pero esto no es así, y esta es una de las ventajas de RCN,pero una discusión sobre este tema está más allá del alcance de este artículo.La última capa de entidades será única. ¿Recuerdas que hablé sobre cómo los RCN separan la forma de la apariencia? Es esta capa la responsable de obtener la forma del objeto generado. Por lo tanto, esta capa debería funcionar con características de muy bajo nivel, los bloques de construcción más básicos de cualquier forma, lo que nos ayudará a generar cualquier forma deseada. Los bordes pequeños que giran en diferentes ángulos son bastante adecuados, y son precisamente ellos los que usan los autores de la tecnología.Los autores seleccionaron los atributos del último nivel para representar una ventana de 3x3 que tiene un borde con un cierto ángulo de rotación, que llaman descriptor de parche. El número de ángulos de rotación que eligieron es 16. Además, para poder agregar una apariencia más adelante, necesita dos orientaciones para cada rotación para poder determinar si el fondo está en el borde izquierdo o derecho, si estos son bordes externos. y orientación adicional en el caso de límites internos (es decir, dentro del objeto). En la Figura 7 se muestran las características del último ensamblaje de capas, y la Figura 8 muestra cómo los descriptores de parches pueden generar cierta forma.
Figura 6: GIF- RCN . , . , RCN , , . .Hasta ahora, hablamos de las capas intermedias de RCN, solo tenemos la capa superior y la capa inferior que interactúa con los píxeles de la imagen generada. La capa superior es una capa de entidad regular, donde los canales de cada nodo serán clases de nuestro conjunto de datos etiquetado. Al generar, simplemente seleccionamos la ubicación y la clase que queremos crear, vamos al nodo con la ubicación especificada y decimos que activa el canal de la clase que seleccionamos. Esto activa algunos de los canales en la capa de submuestra debajo de ella, luego la capa de características debajo, y así sucesivamente, hasta llegar a la última capa de características. Según su conocimiento de las redes neuronales convolucionales, debe pensar que la capa superior tendrá un solo nodo, pero esto no es así, y esta es una de las ventajas de RCN,pero una discusión sobre este tema está más allá del alcance de este artículo.La última capa de entidades será única. ¿Recuerdas que hablé sobre cómo los RCN separan la forma de la apariencia? Es esta capa la responsable de obtener la forma del objeto generado. Por lo tanto, esta capa debería funcionar con características de muy bajo nivel, los bloques de construcción más básicos de cualquier forma, lo que nos ayudará a generar cualquier forma deseada. Los bordes pequeños que giran en diferentes ángulos son bastante adecuados, y son precisamente ellos los que usan los autores de la tecnología.Los autores seleccionaron los atributos del último nivel para representar una ventana de 3x3 que tiene un borde con un cierto ángulo de rotación, que llaman descriptor de parche. El número de ángulos de rotación que eligieron es 16. Además, para poder agregar una apariencia más adelante, necesita dos orientaciones para cada rotación para poder determinar si el fondo está en el borde izquierdo o derecho, si estos son bordes externos. y orientación adicional en el caso de límites internos (es decir, dentro del objeto). En la Figura 7 se muestran las características del último ensamblaje de capas, y la Figura 8 muestra cómo los descriptores de parches pueden generar cierta forma.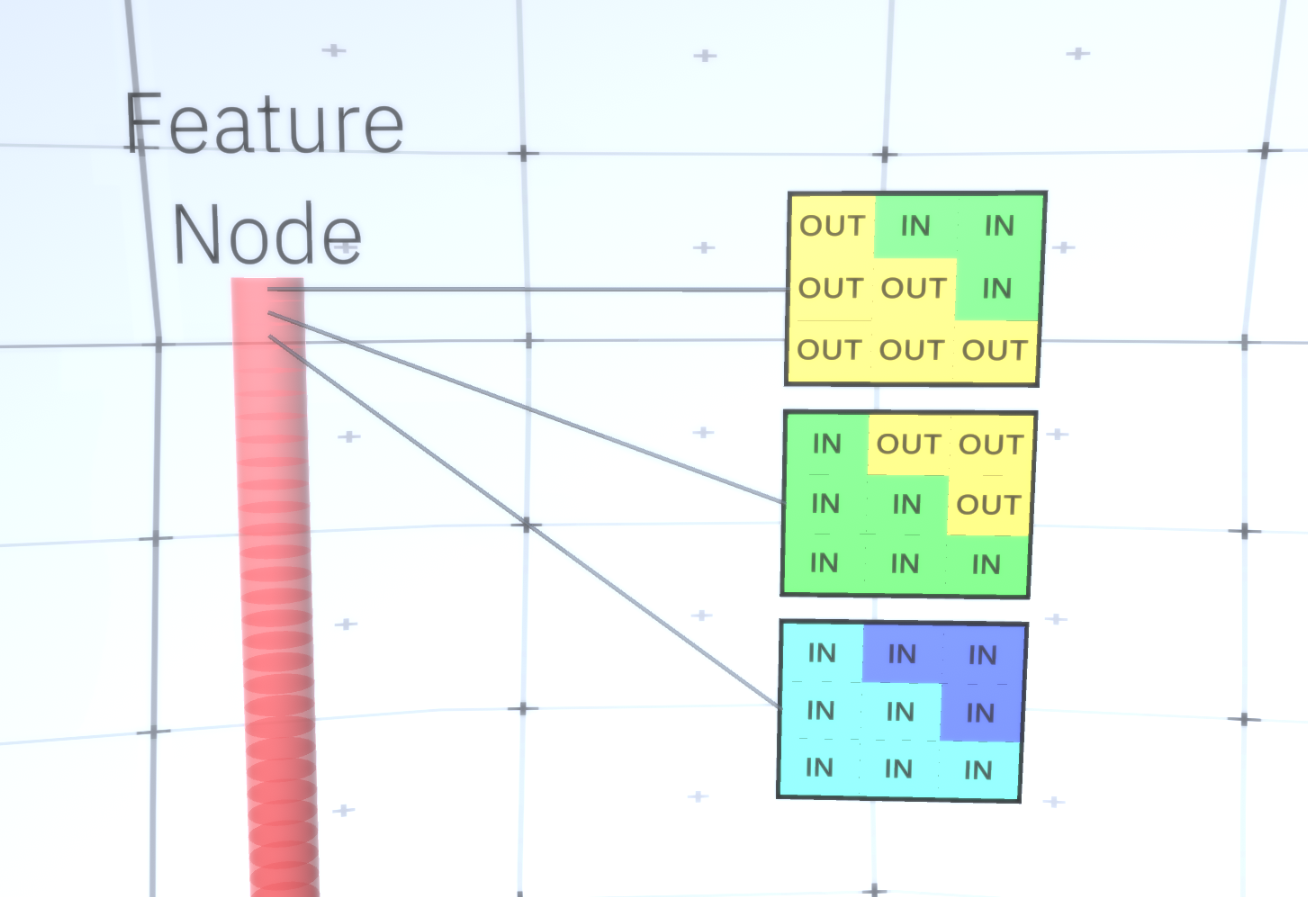 Figura 7: . 48 ( ) , 16 3 . – 45 . “IN " , “OUT” — .
Figura 7: . 48 ( ) , 16 3 . – 45 . “IN " , “OUT” — . 8: «i» .Ahora que hemos alcanzado la última capa de signos, tenemos un diagrama en el que se determinan los límites del objeto y la comprensión de si el área está fuera del borde es interna o externa. Queda por agregar una apariencia, designando cada área restante de la imagen como IN o OUT y pintar sobre el área. Un campo aleatorio condicional puede ayudar aquí. Sin entrar en detalles matemáticos, simplemente asignamos a cada píxel en la imagen final una distribución de probabilidad por color y estado (IN o OUT). Esta distribución reflejará la información obtenida desde el borde del mapa. Por ejemplo, si hay dos píxeles adyacentes, uno de los cuales está IN y el otro está OUT, la probabilidad de que tengan un color diferente aumenta considerablemente. Si dos píxeles adyacentes están en lados opuestos del borde interno, la probabilidadque tendrá un color diferente también aumentará. Si los píxeles se encuentran dentro del borde y no están separados por nada, entonces aumenta la probabilidad de que tengan el mismo color, pero los píxeles externos pueden tener una ligera desviación entre sí y así sucesivamente. Para obtener la imagen final, simplemente haga una selección de la distribución de probabilidad conjunta que acabamos de instalar. Para hacer que la imagen generada sea más interesante, podemos reemplazar los colores con la textura. No discutiremos esta capa porque RCN puede realizar la clasificación sin basarse en la apariencia.Para obtener la imagen final, simplemente haga una selección de la distribución de probabilidad conjunta que acabamos de instalar. Para hacer que la imagen generada sea más interesante, podemos reemplazar los colores con la textura. No discutiremos esta capa porque RCN puede realizar la clasificación sin basarse en la apariencia.Para obtener la imagen final, simplemente haga una selección de la distribución de probabilidad conjunta que acabamos de instalar. Para hacer que la imagen generada sea más interesante, podemos reemplazar los colores con la textura. No discutiremos esta capa porque RCN puede realizar la clasificación sin basarse en la apariencia.Bueno, terminaremos aquí por hoy. Si desea saber más sobre RCN, lea este artículo [5] y el apéndice con materiales adicionales, o puede leer mis otros artículos sobre las conclusiones lógicas , la capacitación y los resultados del uso de RCN en varios conjuntos de datos .
8: «i» .Ahora que hemos alcanzado la última capa de signos, tenemos un diagrama en el que se determinan los límites del objeto y la comprensión de si el área está fuera del borde es interna o externa. Queda por agregar una apariencia, designando cada área restante de la imagen como IN o OUT y pintar sobre el área. Un campo aleatorio condicional puede ayudar aquí. Sin entrar en detalles matemáticos, simplemente asignamos a cada píxel en la imagen final una distribución de probabilidad por color y estado (IN o OUT). Esta distribución reflejará la información obtenida desde el borde del mapa. Por ejemplo, si hay dos píxeles adyacentes, uno de los cuales está IN y el otro está OUT, la probabilidad de que tengan un color diferente aumenta considerablemente. Si dos píxeles adyacentes están en lados opuestos del borde interno, la probabilidadque tendrá un color diferente también aumentará. Si los píxeles se encuentran dentro del borde y no están separados por nada, entonces aumenta la probabilidad de que tengan el mismo color, pero los píxeles externos pueden tener una ligera desviación entre sí y así sucesivamente. Para obtener la imagen final, simplemente haga una selección de la distribución de probabilidad conjunta que acabamos de instalar. Para hacer que la imagen generada sea más interesante, podemos reemplazar los colores con la textura. No discutiremos esta capa porque RCN puede realizar la clasificación sin basarse en la apariencia.Para obtener la imagen final, simplemente haga una selección de la distribución de probabilidad conjunta que acabamos de instalar. Para hacer que la imagen generada sea más interesante, podemos reemplazar los colores con la textura. No discutiremos esta capa porque RCN puede realizar la clasificación sin basarse en la apariencia.Para obtener la imagen final, simplemente haga una selección de la distribución de probabilidad conjunta que acabamos de instalar. Para hacer que la imagen generada sea más interesante, podemos reemplazar los colores con la textura. No discutiremos esta capa porque RCN puede realizar la clasificación sin basarse en la apariencia.Bueno, terminaremos aquí por hoy. Si desea saber más sobre RCN, lea este artículo [5] y el apéndice con materiales adicionales, o puede leer mis otros artículos sobre las conclusiones lógicas , la capacitación y los resultados del uso de RCN en varios conjuntos de datos .Fuentes:
- [1] R. Perrault, Y. Shoham, E. Brynjolfsson, et al., The AI Index 2019 Annual Report (2019), Instituto de IA centrado en el ser humano - Universidad de Stanford.
- [2] D. Hendrycks, K. Zhao, S. Basart, et al., Natural Adversarial Ejemplos (2019), arXiv: 1907.07174.
- [3] J. Su, D. Vasconcellos Vargas y S. Kouichi, One Pixel Attack for Fooling Deep Neural Networks (2017), arXiv: 1710.08864.
- [4] M. Sharif, S. Bhagavatula, L. Bauer, Un marco general para ejemplos adversarios con objetivos (2017), arXiv: 1801.00349.
- [5] D. George, W. Lehrach, K. Kansky, et al., A Generative Vision Model that Trains with High Data Efficiency and Break Text-based CAPTCHAs (2017), Science Mag (Vol 358 — Issue 6368).
- [6] H. Liang, X. Gong, M. Chen, et al., Interactions Between Feedback and Lateral Connections in the Primary Visual Cortex (2017), Proceedings of the National Academy of Sciences of the United States of America.
: « : ». Source: https://habr.com/ru/post/undefined/
All Articles