Hola HabrMi nombre es Misha Butrimov, me gustaría hablar un poco sobre Cassandra. Mi historia será útil para aquellos que nunca se han encontrado con las bases de datos NoSQL: tiene muchas características de implementación y dificultades que debes conocer. Y si, aparte de Oracle o cualquier otra base relacional, no has visto nada, estas cosas te salvarán la vida.¿Qué tiene de bueno Cassandra? Esta es una base de datos NoSQL diseñada sin un solo punto de falla, que se adapta bien. Si necesita agregar un par de terabytes para cualquier base, simplemente agregue nodos al anillo. ¿Extenderlo a otro centro de datos? Agregar nodos al clúster. Aumentar RPS procesados? Agregar nodos al clúster. La otra forma también funciona. ¿En qué más es buena? Es para manejar muchas solicitudes. ¿Pero cuánto es cuánto? 10, 20, 30, 40 mil solicitudes por segundo: esto no es mucho. 100 mil solicitudes por segundo para grabación, también. Hay compañías que dijeron que tienen 2 millones de solicitudes por segundo. Aquí probablemente tengan que creer.Y, en principio, Cassandra tiene una gran diferencia con los datos relacionales: no se parece en absoluto a ellos. Y esto es muy importante para recordar.
¿En qué más es buena? Es para manejar muchas solicitudes. ¿Pero cuánto es cuánto? 10, 20, 30, 40 mil solicitudes por segundo: esto no es mucho. 100 mil solicitudes por segundo para grabación, también. Hay compañías que dijeron que tienen 2 millones de solicitudes por segundo. Aquí probablemente tengan que creer.Y, en principio, Cassandra tiene una gran diferencia con los datos relacionales: no se parece en absoluto a ellos. Y esto es muy importante para recordar.No todo lo que se ve igual funciona igual
Una vez que un colega vino a mí y me preguntó: “Aquí está el lenguaje de consulta CQL Cassandra, y tiene una declaración select, tiene dónde, tiene y. Escribo cartas y no funciona. ¿Por qué?". Si tratas a Cassandra como una base de datos relacional, entonces esta es una manera ideal de terminar tu vida con un brutal suicidio. Y no defiendo, está prohibido en Rusia. Solo estás diseñando algo mal.Por ejemplo, un cliente se acerca a nosotros y nos dice: “Construyamos una base de datos para programas de televisión o una base de datos para un directorio de recetas. Tendremos platos de comida allí o una lista de series y actores ”. Decimos con alegría: "¡Vamos!". Son dos bytes para enviar, un par de placas y todo está listo, todo funcionará de manera muy rápida y confiable. Y todo está bien hasta que los clientes vengan y digan que las amas de casa también están resolviendo el problema inverso: tienen una lista de productos y quieren saber qué plato quieren cocinar. Estás muerto.Esto se debe a que Cassandra es una base de datos híbrida: es un valor clave y almacena datos en columnas anchas. Hablando en Java o Kotlin, podría describirse así:Map<RowKey, SortedMap<ColumnKey, ColumnValue>>Es decir, un mapa, dentro del cual también hay un mapa ordenado. La primera clave de este mapa es la clave de fila o la clave de partición: la clave de partición. La segunda clave, que es la clave del mapa ya ordenado, es la clave de agrupación.Para ilustrar la distribución de la base de datos, dibujamos tres nodos. Ahora necesita comprender cómo descomponer los datos en nodos. Porque si ponemos todo en uno (por cierto, puede haber mil, dos mil, cinco, tantos como desee), esto no se trata realmente de distribución. Por lo tanto, necesitamos una función matemática que devuelva un número. Solo un número, un int largo que caerá en algún rango. Y tenemos un nodo que será responsable de un rango, el segundo - para el segundo, n-ésimo - para el n-ésimo. Este número se toma utilizando una función hash que se aplica solo a lo que llamamos la tecla Partición. Esta es la columna que se especifica en la directiva Clave primaria, y esta es la columna que será la primera y más básica clave de mapa. Determina qué nodo obtiene qué datos. Se crea una tabla en Cassandra con casi la misma sintaxis que en SQL:
Este número se toma utilizando una función hash que se aplica solo a lo que llamamos la tecla Partición. Esta es la columna que se especifica en la directiva Clave primaria, y esta es la columna que será la primera y más básica clave de mapa. Determina qué nodo obtiene qué datos. Se crea una tabla en Cassandra con casi la misma sintaxis que en SQL:CREATE TABLE users (
user_id uu id,
name text,
year int,
salary float,
PRIMARY KEY(user_id)
)
La clave primaria en este caso consiste en una columna, y también es una clave de partición.¿Cómo caerán los usuarios con nosotros? Parte recaerá en una nota, parte en otra y parte en una tercera. Resulta una tabla hash ordinaria, también es un mapa, también es un diccionario en Python, también es una estructura de valores clave simple desde la cual podemos leer todos los valores, leer y escribir por clave.
Seleccione: cuando permitir el filtrado se convierte en escaneo completo, o cómo no hacerlo
Vamos a escribir alguna declaración al selecto El: select * from users where, userid = . Resulta, al parecer, como en Oracle: escribimos select, especificamos condiciones y todo funciona, los usuarios lo entienden. Pero si selecciona, por ejemplo, un usuario con un determinado año de nacimiento, Cassandra jura que no puede cumplir con la solicitud. Debido a que no sabe nada acerca de cómo distribuimos los datos sobre el año de nacimiento, solo tiene una columna especificada como clave. Entonces ella dice: "Está bien, todavía puedo cumplir con esta solicitud. Agregar permitir filtrado ". Agregamos una directiva, todo funciona. Y en ese momento sucede algo terrible.Cuando manejamos datos de prueba, todo está bien. Y cuando cumple con la solicitud en producción, donde, por ejemplo, tenemos 4 millones de registros, entonces no todo es muy bueno para nosotros. Debido a que permitir el filtrado es una directiva que permite a Cassandra recopilar todos los datos de esta tabla de todos los nodos, todos los centros de datos (si hay muchos de ellos en este clúster), y solo luego filtrarlos. Este es un análogo de Full Scan, y casi nadie está encantado con él.Si solo necesitáramos usuarios por identificadores, esto nos convendría. Pero a veces necesitamos escribir otras consultas e imponer otras restricciones a la selección. Por lo tanto, recordamos: todos tenemos un mapa, que tiene una clave de partición, pero dentro de él hay un mapa ordenado.Y ella también tiene una clave, que llamamos Clustering Key. Esta clave, que, a su vez, consiste en las columnas que seleccionamos, con las que Cassandra comprende cómo se ordenan físicamente sus datos y se ubicarán en cada nodo. Es decir, para alguna clave de partición, la clave de agrupación le dirá exactamente cómo insertar los datos en este árbol, qué lugar ocuparán allí.Esto es realmente un árbol, simplemente se llama un comparador allí, en el que pasamos un cierto conjunto de columnas en forma de un objeto, y también se configura en forma de una enumeración de columnas.CREATE TABLE users_by_year_salary_id (
user_id uuid,
name text,
year int,
salary float,
PRIMARY KEY((year), salary, user_id)
Preste atención a la directiva de la clave primaria, tiene el primer argumento (en nuestro caso el año) es siempre la clave de partición. Puede constar de una o varias columnas, no importa. Si hay varias columnas, debe eliminarlo nuevamente entre paréntesis para que el preprocesador del idioma comprenda que esta es la clave Primaria, y detrás de ella todas las demás columnas: la clave de Agrupación. En este caso, se transmitirán en el comparador en el orden en que van. Es decir, la primera columna es más significativa, la segunda es menos significativa y así sucesivamente. A medida que escribimos para clases de datos, por ejemplo, campos iguales: enumeramos campos, y para ellos escribimos cuáles son más grandes y cuáles son más pequeños. En Cassandra, este es, relativamente hablando, el campo de clase de datos al que se aplicarán los iguales escritos para él.Establecemos el tipo, imponemos restricciones
Debe recordarse que el orden de clasificación (decreciente, creciente, no importa) se establece al mismo tiempo que se crea la clave, y luego no puede cambiarla más tarde. Determina físicamente cómo se ordenarán los datos y cómo se encontrarán. Si necesita cambiar la clave de agrupación o el orden de clasificación, deberá crear una nueva tabla y verter datos en ella. Con el existente esto no funcionará.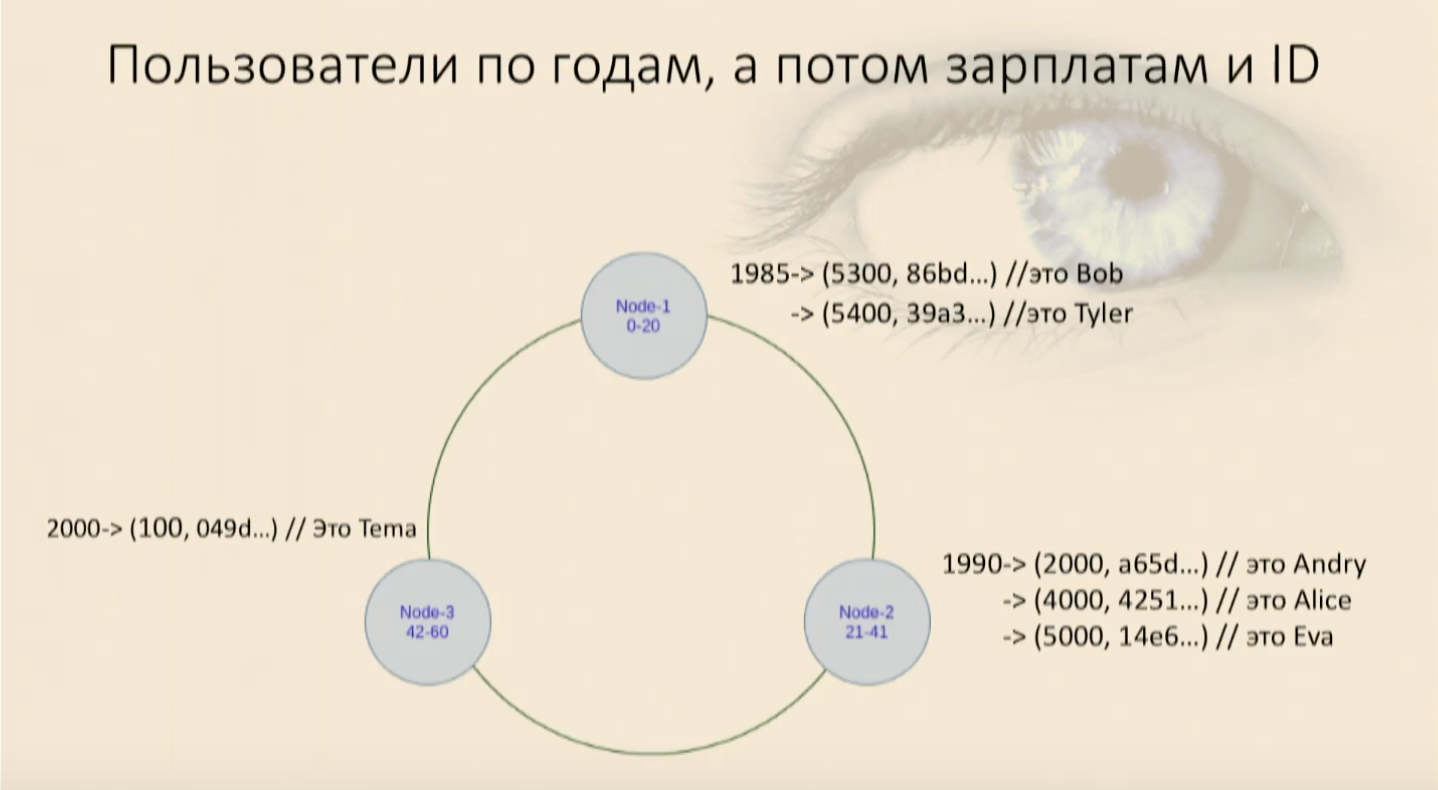 Llenamos nuestra mesa con usuarios y vimos que entraron en un anillo, primero por año de nacimiento, y luego dentro de cada nodo por salario y por identificación de usuario. Ahora podemos seleccionar, imponiendo restricciones.Nuestro trabajo aparece de nuevo
Llenamos nuestra mesa con usuarios y vimos que entraron en un anillo, primero por año de nacimiento, y luego dentro de cada nodo por salario y por identificación de usuario. Ahora podemos seleccionar, imponiendo restricciones.Nuestro trabajo aparece de nuevowhere, and, y los usuarios llegan a nosotros, y todo vuelve a estar bien. Pero si tratamos de usar solo la parte clave de Clustering, la menos significativa, Cassandra jurará de inmediato que no podemos encontrar en nuestro mapa dónde este objeto tiene estos campos para el comparador nulo, pero este se acaba de configurar - Donde yace. Tendré que recoger todos los datos de este nodo nuevamente y filtrarlos. Y esto es un análogo de Full Scan dentro del nodo, esto es malo.En cualquier situación incomprensible, cree una nueva tabla
Si queremos poder obtener usuarios por ID o por edad o por salario, ¿qué debemos hacer? Nada. Solo usa dos tablas. Si necesita obtener usuarios de tres maneras diferentes, habrá tres tablas. Atrás quedaron los días en que ahorramos espacio en el tornillo. Este es el recurso más barato. Cuesta mucho menos que el tiempo de respuesta, que puede ser fatal para el usuario. El usuario es mucho más amable de obtener algo en un segundo que en 10 minutos.Intercambiamos espacio excesivo, datos desnormalizados para la capacidad de escalar bien, trabajar de manera confiable. De hecho, en realidad, un clúster que consta de tres centros de datos, cada uno de los cuales tiene cinco nodos, con un nivel aceptable de almacenamiento de datos (cuando no se pierde nada con seguridad), puede sobrevivir completamente a la muerte de un centro de datos. Y dos nodos más en cada uno de los dos restantes. Y solo después de eso comienzan los problemas. Esta es una redundancia bastante buena, cuesta un par de unidades y procesadores ssd innecesarios. Por lo tanto, para usar Cassandra, que nunca es SQL, en el que no hay relaciones ni claves foráneas, debe conocer reglas simples.Diseñamos todo desde una solicitud. Lo principal no son los datos, sino cómo va a funcionar la aplicación con ellos. Si necesita recibir diferentes datos de diferentes maneras o los mismos datos de diferentes maneras, debemos ponerlos de la manera que sea conveniente para la aplicación. De lo contrario, fallaremos en Full Scan y Cassandra no nos dará ninguna ventaja.La desnormalización de datos es la norma. Olvídate de las formas normales, ya no tenemos bases de datos relacionales. Ponemos algo 100 veces, mentirá 100 veces. Es más barato que detenerlo de todos modos.Seleccionamos las claves para particionar para que se distribuyan normalmente. No necesitamos que el hash de nuestras teclas caiga en un rango estrecho. Es decir, el año de nacimiento en el ejemplo anterior es un mal ejemplo. Más bien, es bueno si nuestros usuarios se distribuyen normalmente por año de nacimiento, y malo si hablamos de estudiantes de 5to grado; no será muy bueno dividir allí.La ordenación se selecciona una vez durante la creación de la clave de agrupación. Si necesita cambiarlo, tendrá que llenar en exceso nuestra tabla con una clave diferente.Y lo más importante: si necesitamos recopilar los mismos datos de 100 formas diferentes, tendremos 100 tablas diferentes.