¡Hola a todos!Quiero hablar sobre un proyecto muy aburrido en el que la robótica, el aprendizaje automático (y juntos, esto es el aprendizaje robótico), la realidad virtual y un poco de tecnología en la nube se entrecruzaron. Y todo esto tiene sentido. Después de todo, es realmente conveniente pasar a un robot, mostrar qué hacer y luego entrenar pesos en el servidor ML utilizando los datos almacenados.Debajo del corte, diremos cómo funciona ahora, y algunos detalles sobre cada uno de los aspectos que tuvieron que desarrollarse.
Para qué
Para empezar, vale la pena revelar un poco.Parece que los robots armados con Deep Learning están a punto de expulsar a las personas de sus trabajos en todas partes. De hecho, no todo es tan sencillo. Cuando las acciones se repiten estrictamente, los procesos ya están realmente bien automatizados. Si hablamos de "robots inteligentes", es decir, aplicaciones donde la visión por computadora y los algoritmos ya son suficientes. Pero también hay muchas historias extremadamente complicadas. Los robots apenas pueden hacer frente a la variedad de objetos con los que tienen que lidiar y a la diversidad del entorno.Puntos clave
Hay 3 cosas clave en términos de implementación que aún no se encuentran en todas partes:- (data-driven learning). .. , , , . , .
- ()
- - (Human-machine collaboration)
El segundo también es importante porque en este momento observaremos un cambio en los enfoques de aprendizaje, algoritmos, detrás de ellos y herramientas informáticas. Los algoritmos de percepción y control serán más flexibles. Una actualización de robot cuesta dinero. Y la calculadora se puede usar de manera más eficiente si servirá a varios robots a la vez. Este concepto se llama "robótica en la nube".Con este último, todo es simple: la inteligencia artificial no está lo suficientemente desarrollada en este momento para proporcionar el 100% de confiabilidad y precisión en todas las situaciones requeridas por las empresas. Por lo tanto, el operador supervisor, que a veces puede ayudar a los robots de las salas, no le hará daño.Esquema
Para empezar, sobre una plataforma de software / red que proporciona todas las funciones descritas: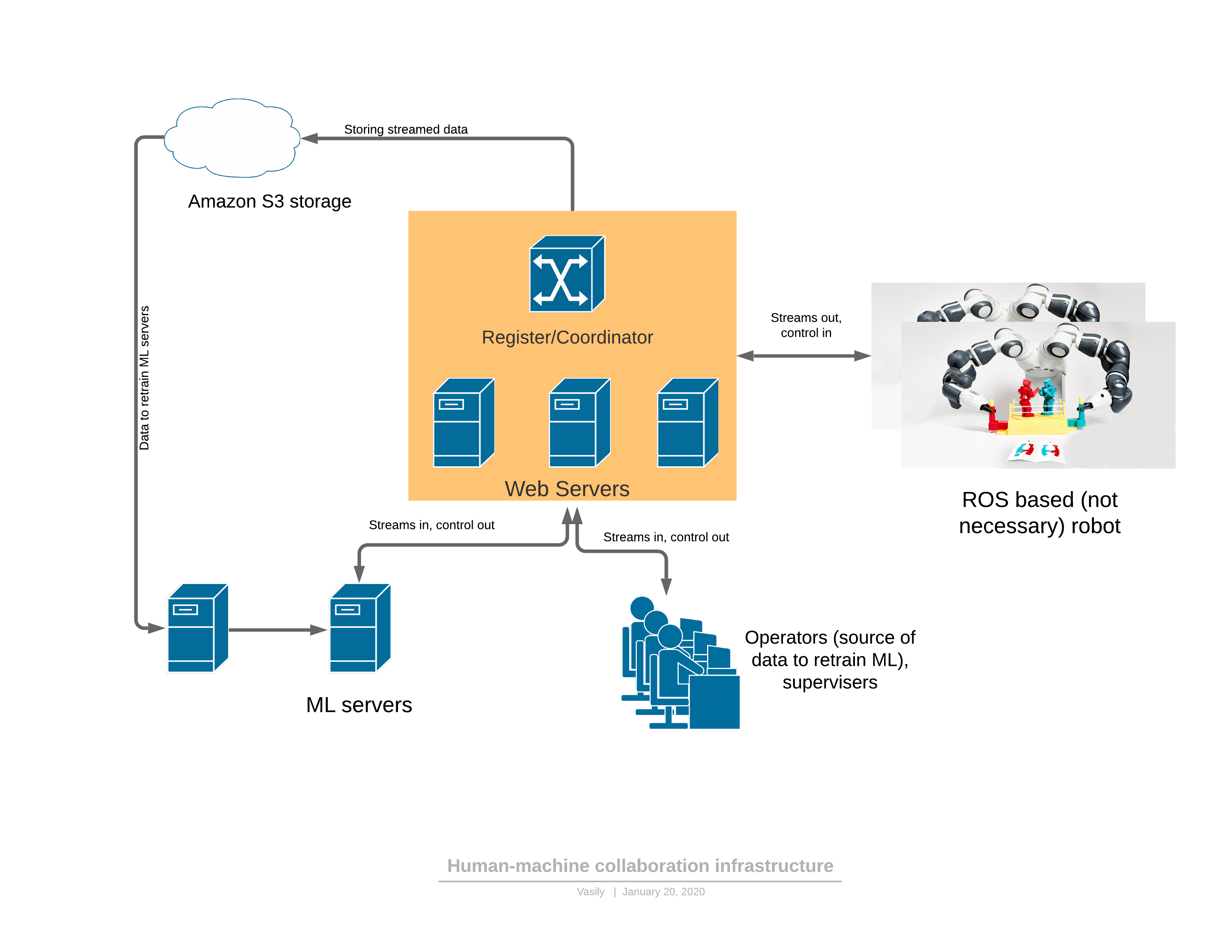 Componentes:
Componentes:- El robot envía una transmisión de video 3D al servidor y recibe el control en respuesta.
- : - , (, , , )
- ML ( ), , , . — 3D , .
- - , 3D , UI . — .
Hay 2 modos de funcionamiento del robot: automático y manual.En modo manual, el robot funciona si el servicio ML aún no está entrenado. Luego, el robot pasa de automático a manual, a pedido del operador (vi comportamientos extraños mientras observaba el robot) o cuando los servicios de ML detectan una anomalía. Acerca de la detección de anomalías será más tarde, esta es una parte muy importante, sin la cual es imposible aplicar el enfoque propuesto.La evolución del control es la siguiente:- La tarea para el robot se forma en términos legibles por humanos y se describen indicadores de rendimiento.
- El operador se conecta al robot en VR y realiza la tarea dentro del flujo de trabajo existente durante algún tiempo
- La parte de ML se entrena sobre los datos recibidos
- , ML
3D
Muy a menudo, los robots utilizan el entorno ROS (sistema operativo del robot), que de hecho es un marco para administrar "nodos" (nodos), cada uno de los cuales proporciona parte de la funcionalidad del robot. En general, esta es una forma relativamente conveniente de programar robots, que de alguna manera se asemeja a la arquitectura de microservicio de las aplicaciones web en su esencia. La principal ventaja de ROS es el estándar de la industria y ya hay una gran cantidad de módulos necesarios para crear un robot. Incluso los brazos robóticos industriales pueden tener un módulo de interfaz ROS.Lo más simple es crear un modelo de puente entre nuestra parte del servidor y ROS. Por ejemplo, tal. Ahora nuestro proyecto utiliza una versión más desarrollada del "nodo" ROS, que inicia sesión y sondea el microservicio del registro al que el servidor de retransmisión puede conectarse un robot en particular. El código fuente se proporciona solo como un ejemplo de instrucciones para instalar el módulo ROS. Al principio, cuando dominas este marco (ROS), todo parece bastante hostil, pero la documentación es bastante buena, y después de un par de semanas, los desarrolladores comienzan a usar su funcionalidad con bastante confianza.Interesante: el problema de la compresión del flujo de datos 3D, que debe producirse directamente en el robot.No es tan fácil comprimir el mapa de profundidad. Incluso con un pequeño grado de compresión del flujo RGB, se permite una distorsión local muy grave del brillo de los píxeles reales en los bordes o cuando se permiten objetos en movimiento. El ojo casi no se da cuenta de esto, pero tan pronto como se permiten las mismas distorsiones en el mapa de profundidad, al renderizar en 3D todo se vuelve muy malo: (del artículo )Estos defectos en los bordes estropean en gran medida la escena 3D, porque solo hay mucha basura en el aire.Comenzamos a utilizar la compresión cuadro por cuadro: JPEG para RGB y PNG para un mapa de profundidad con pequeños hacks. Este método comprime la transmisión de 30FPS para una resolución de escáner 3D de 640x480 a 25 Mbps. También se puede proporcionar una mejor compresión si el tráfico es crítico para la aplicación. Hay códecs de flujo 3D comerciales que también se pueden usar para comprimir este flujo.
(del artículo )Estos defectos en los bordes estropean en gran medida la escena 3D, porque solo hay mucha basura en el aire.Comenzamos a utilizar la compresión cuadro por cuadro: JPEG para RGB y PNG para un mapa de profundidad con pequeños hacks. Este método comprime la transmisión de 30FPS para una resolución de escáner 3D de 640x480 a 25 Mbps. También se puede proporcionar una mejor compresión si el tráfico es crítico para la aplicación. Hay códecs de flujo 3D comerciales que también se pueden usar para comprimir este flujo.Control de realidad virtual.
Después de calibrar el marco de referencia de la cámara y el robot (y ya escribimos un artículo sobre calibración ), el brazo del robot se puede controlar en realidad virtual. El controlador establece tanto la posición en 3D XYZ como la orientación. Para algunos roboruk, solo 3 coordenadas serán suficientes, pero con un gran número de grados de libertad, la orientación de la herramienta especificada por el controlador también debe transmitirse. Además, hay suficientes controles en los controladores para ejecutar comandos del robot, como encender / apagar la bomba, controlar la pinza y otros.Inicialmente, se decidió utilizar el marco de JavaScript para el marco A de realidad virtual, basado en el motor WebVR. Y los primeros resultados (demostración en video al final del artículo para el brazo de 4 coordenadas) se obtuvieron en el marco A.De hecho, resultó que WebVR (o A-frame) era una solución fallida por varias razones:- compatibilidad principalmente con FireFox , y fue en FireFox que el marco de marco A no liberó recursos de textura (el resto de los navegadores hicieron frente) hasta que el consumo de memoria alcanzó 16 GB
- interacción limitada con controladores de realidad virtual y casco. Entonces, por ejemplo, no fue posible agregar marcas adicionales con las que puede establecer la posición, por ejemplo, de los codos del operador.
- La aplicación requería múltiples subprocesos o varios procesos. En un hilo / proceso, fue necesario descomprimir los cuadros de video, en otro - dibujar. Como resultado, todo se organizó a través de los trabajadores, pero el tiempo de desempaque llegó a 30 ms, y la renderización en realidad virtual se debe hacer a una frecuencia de 90FPS.
Todas estas deficiencias resultaron en el hecho de que la representación del marco no tuvo tiempo en los 10 ms asignados y hubo contracciones muy desagradables en la realidad virtual. Probablemente, todo podría superarse, pero la identidad de cada navegador era un poco molesta.Ahora decidimos partir hacia el puerto C #, OpenTK y C # de la biblioteca OpenVR. Todavía hay una alternativa: la unidad. Escriben que Unity es para principiantes ... pero difícil.Lo más importante que necesitaba ser encontrado y conocido para ganar libertad:VRTextureBounds_t bounds = new VRTextureBounds_t() { uMin = 0, vMin = 0, uMax = 1f, vMax = 1f };
OpenVR.Compositor.Submit(EVREye.Eye_Left, ref leftTexture, ref bounds, EVRSubmitFlags.Submit_Default);
OpenVR.Compositor.Submit(EVREye.Eye_Right, ref rightTexture, ref bounds, EVRSubmitFlags.Submit_Default);
(este es el código para enviar dos texturas a los ojos izquierdo y derecho del casco),es decir dibuje en OpenGL en la textura que ven los diferentes ojos y envíelo a las gafas. Joy no conocía límites cuando resultó que llenaba el ojo izquierdo de rojo y el derecho de azul. Solo un par de días y ahora el mapa de profundidad y RGB que viene a través de webSocket se transfirió al modelo poligonal en 10 ms en lugar de 30 en JS. Y luego simplemente interrogue las coordenadas y los botones de los controladores, ingrese el sistema de eventos para los botones, procese los clics del usuario, ingrese la máquina de estado para la interfaz de usuario y ahora puede tomar un vaso del espresso:Ahora la calidad del Realsense D435 es algo deprimente, pero pasará tan pronto como instalemos al menos un escáner 3D tan interesante de Microsoft , cuya nube de puntos es mucho más precisa.Lado del servidor
Servidor de retransmisiónEl elemento funcional principal es el retransmisor del servidor (servidor en el medio), que recibe una transmisión de video del robot con imágenes en 3D y lecturas del sensor y el estado del robot y lo distribuye entre los consumidores. Datos de entrada: cuadros empaquetados y lecturas de sensores que provienen de TCP / IP. La distribución a los consumidores se realiza mediante sockets web (un mecanismo muy conveniente para transmitir a varios consumidores, incluido un navegador).Además, el servidor de almacenamiento provisional almacena el flujo de datos en el almacenamiento en la nube S3 para que luego pueda usarse para la capacitación.Cada servidor de retransmisión admite la API http, que le permite conocer su estado actual, lo cual es conveniente para monitorear las conexiones actuales.La tarea de retransmisión es bastante difícil, tanto desde el punto de vista de la informática como desde el punto de vista del tráfico. Por lo tanto, aquí seguimos la lógica de que los servidores de retransmisión se implementan en una variedad de servidores en la nube. Y eso significa que debe realizar un seguimiento de quién se está conectando a dónde (especialmente si los robots y los operadores están en diferentes regiones).RegistrarseEl más confiable ahora será difícil de configurar para cada robot a qué servidores se puede conectar (la redundancia no afectará). El servicio de gestión de ML está asociado con el robot, sondea el servidor de retransmisión para determinar a cuál está conectado el robot y se conecta al correspondiente, si, por supuesto, tiene suficientes derechos para esto. La aplicación del operador funciona de manera similar.Lo mas agradable! Debido a que el entrenamiento de robots es un servicio, el servicio solo es visible para nosotros en el interior. Por lo tanto, su interfaz puede ser lo más conveniente posible para nosotros. Aquellos. es una consola en el navegador (hay una biblioteca terminalJS que es hermosa en su simplicidad , que es muy fácil de modificar si desea funciones adicionales, como la finalización automática de TAB o la reproducción del historial de llamadas) y se ve así: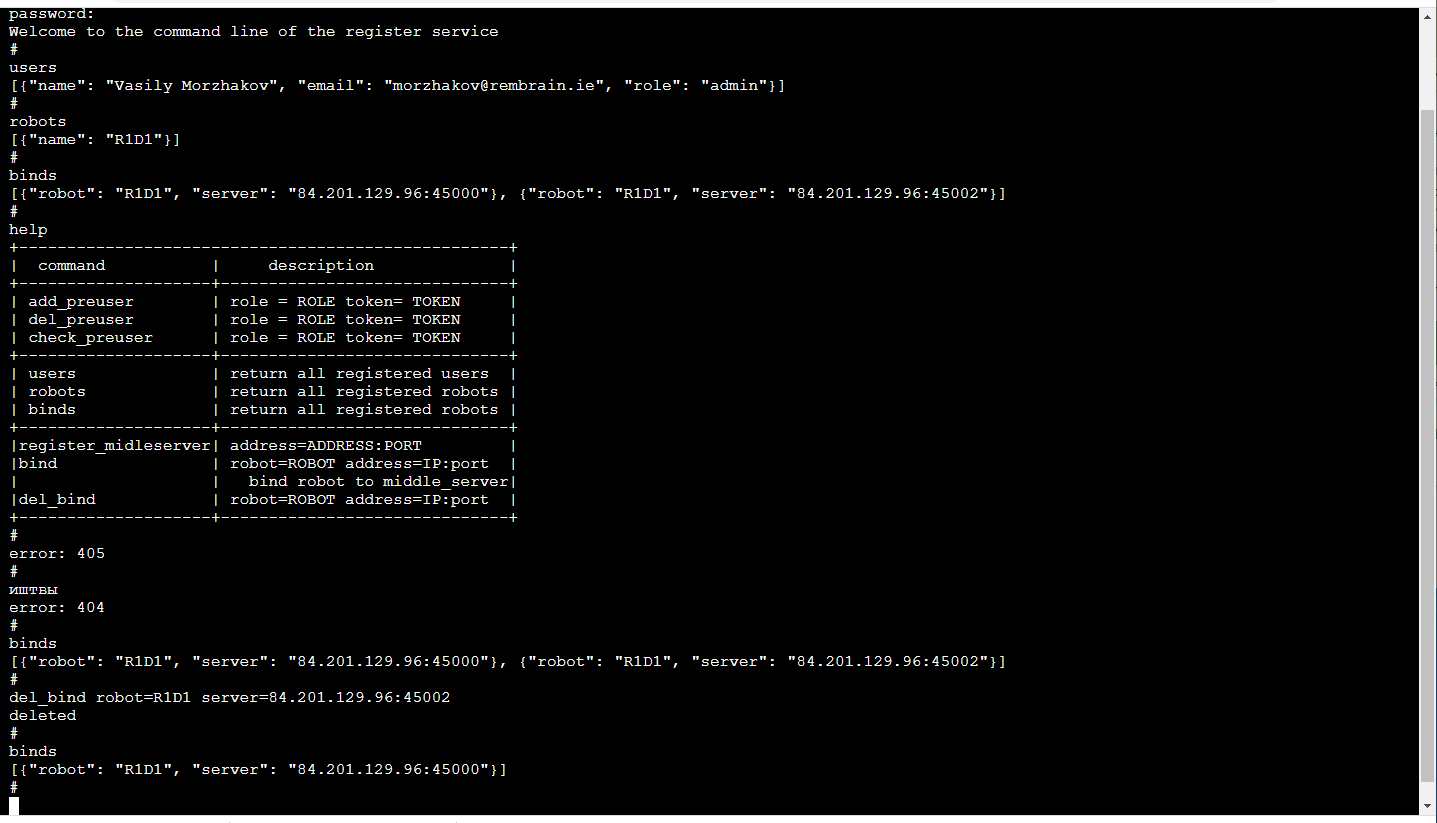 Esto, por supuesto, es un tema separado para el debate, por qué la línea de comandos muy cómodo. Por cierto, es especialmente conveniente hacer pruebas unitarias de dicha interfaz.Además de la API http, este servicio implementa un mecanismo para registrar usuarios con tokens temporales, operadores de inicio / cierre de sesión, administradores y robots, soporte de sesión, claves de cifrado de sesión para el cifrado de tráfico entre el servidor de retransmisión y el robot.Todo esto se hace en Python con Flask, una pila muy cercana para los desarrolladores de ML (es decir, nosotros). Sí, además, la infraestructura existente de CI / CD para microservicios está en términos amigables con Flask.
Esto, por supuesto, es un tema separado para el debate, por qué la línea de comandos muy cómodo. Por cierto, es especialmente conveniente hacer pruebas unitarias de dicha interfaz.Además de la API http, este servicio implementa un mecanismo para registrar usuarios con tokens temporales, operadores de inicio / cierre de sesión, administradores y robots, soporte de sesión, claves de cifrado de sesión para el cifrado de tráfico entre el servidor de retransmisión y el robot.Todo esto se hace en Python con Flask, una pila muy cercana para los desarrolladores de ML (es decir, nosotros). Sí, además, la infraestructura existente de CI / CD para microservicios está en términos amigables con Flask.Problema de retraso
Si queremos controlar los manipuladores en tiempo real, entonces el retraso mínimo es extremadamente útil. Si el retraso es demasiado grande (más de 300 ms), entonces es muy difícil controlar los manipuladores en función de la imagen en el casco virtual. En nuestra solución, debido a la compresión cuadro por cuadro (es decir, no hay almacenamiento en búfer) y al no usar herramientas estándar como GStreamer, el retraso incluso teniendo en cuenta el servidor intermedio es de aproximadamente 150-200 ms. El tiempo de transmisión a través de la red es de unos 80 ms. El resto del retraso es causado por la cámara Realsense D435 y la frecuencia de captura limitada.Por supuesto, este es un problema de altura completa que surge en el modo de "seguimiento", cuando el manipulador en su realidad sigue constantemente al controlador del operador en la realidad virtual. En el modo de moverse a un punto dado XYZ, el retraso no causa ningún problema al operador.Parte ML
Hay 2 tipos de servicios: gestión y formación.El servicio de capacitación recopila los datos almacenados en el almacenamiento S3 e inicia el reentrenamiento de los pesos del modelo. Al final de la capacitación, los pesos se envían al servicio de gestión.El servicio de gestión no es diferente en términos de datos de entrada y salida de la aplicación del operador. Del mismo modo, el flujo de entrada RGBD (RGB + Profundidad), las lecturas del sensor y el estado del robot, los comandos de control de salida. Debido a esta identidad, parece posible capacitarse en el marco del concepto de “capacitación basada en datos”.El estado del robot (y las lecturas del sensor) es una historia clave para ML. Define el contexto. Por ejemplo, un robot tendrá una máquina de estados que es característica de su funcionamiento, que determina en gran medida qué tipo de control es necesario. Estos 2 valores se transmiten junto con cada trama: el modo operativo y el vector de estado del robot.Y un poco sobre el entrenamiento:en la demostración al final del artículo fue la tarea de encontrar un objeto (un cubo para niños) en una escena 3D. Esta es una tarea básica para las aplicaciones de pick & place.El entrenamiento se basó en un par de marcos "antes y después" y designación de objetivos obtenidos con control manual: Debido a la presencia de dos mapas de profundidad, fue fácil calcular la máscara del objeto movido en el marco:
Debido a la presencia de dos mapas de profundidad, fue fácil calcular la máscara del objeto movido en el marco: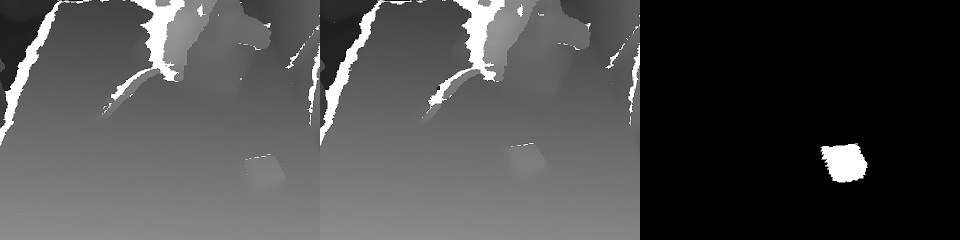 además, se proyectan xyz en el plano de la cámara y puede seleccionar la vecindad del objeto capturado:
además, se proyectan xyz en el plano de la cámara y puede seleccionar la vecindad del objeto capturado: En realidad con este barrio y funcionará.Primero obtenemos XY entrenando a Unet una red convolucional para la segmentación de cubos.Luego, necesitamos determinar la profundidad y comprender si la imagen es anormal frente a nosotros. Esto se hace usando un codificador automático en RGB y un codificador automático condicional en profundidad.Arquitectura del modelo para el codificador automático de entrenamiento:
En realidad con este barrio y funcionará.Primero obtenemos XY entrenando a Unet una red convolucional para la segmentación de cubos.Luego, necesitamos determinar la profundidad y comprender si la imagen es anormal frente a nosotros. Esto se hace usando un codificador automático en RGB y un codificador automático condicional en profundidad.Arquitectura del modelo para el codificador automático de entrenamiento: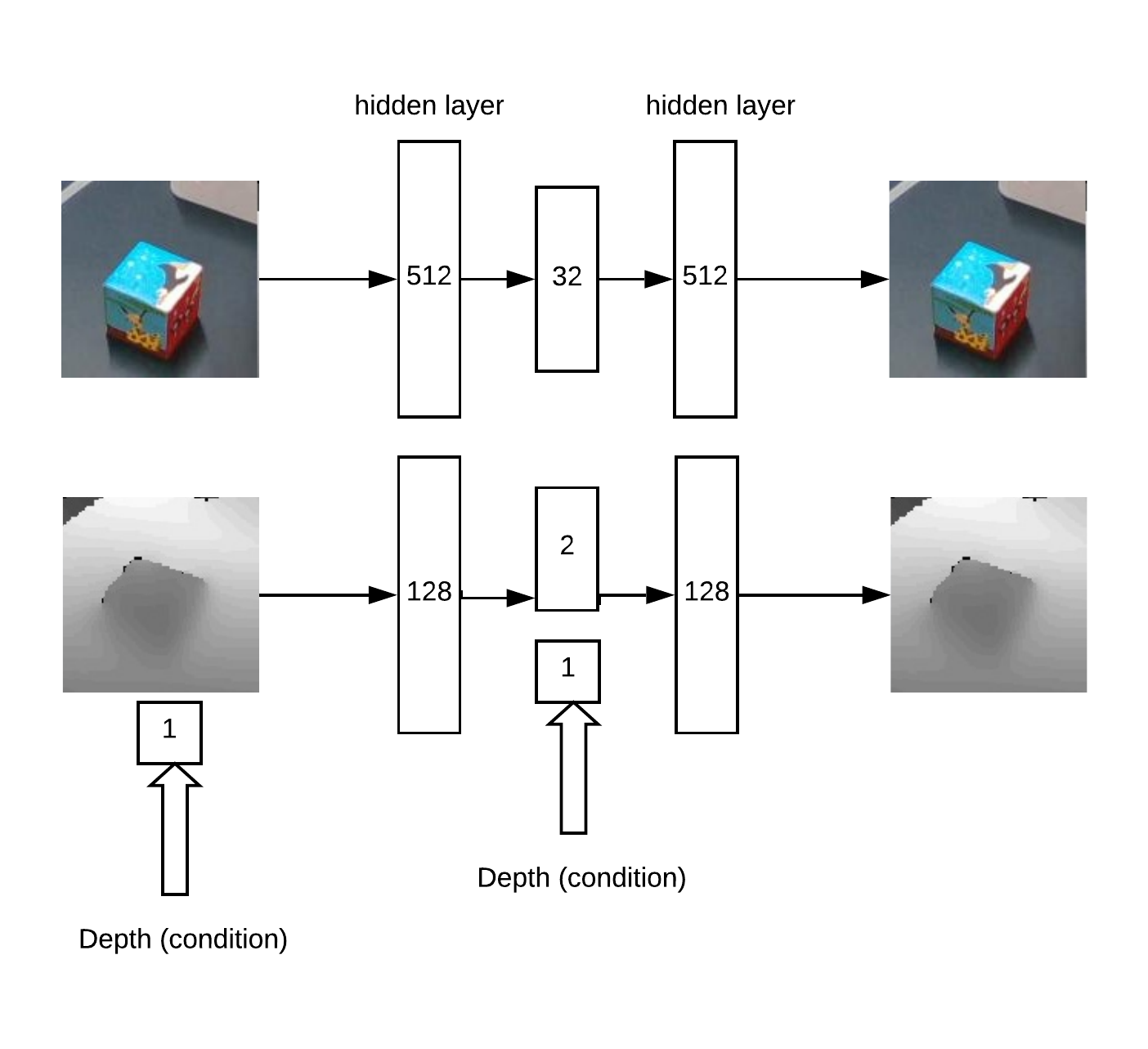 Como resultado, la lógica del trabajo:
Como resultado, la lógica del trabajo:- buscar un máximo en el "mapa de calor" (determinar las coordenadas angulares u = x / zv = y / z del objeto) que excede el umbral
- luego el codificador automático reconstruye la vecindad del punto encontrado para todas las hipótesis en profundidad (con un paso dado de min_depth a max_depth) y selecciona la profundidad a la cual la discrepancia entre la reconstrucción y la entrada es mínima
- Teniendo las coordenadas angulares u, v y profundidad, puede obtener las coordenadas x, y, z
Un ejemplo de reconstrucción de codificador automático de un mapa de profundidades de cubo con una profundidad correctamente definida: en parte, la idea de un método de búsqueda de profundidad se basa en un artículo sobre conjuntos de codificadores automáticos .Este enfoque funciona bien para objetos de varias formas.Pero, en general, hay muchos enfoques diferentes para encontrar un objeto XYZ a partir de una imagen RGBD. Por supuesto, es necesario en la práctica y en una gran cantidad de datos elegir el método más preciso.También estaba la tarea de detectar anomalías, para esto necesitamos una red convolucional de segmentación para aprender de las máscaras disponibles. Luego, de acuerdo con esta máscara, puede evaluar la precisión de la reconstrucción del codificador automático en el mapa de profundidad y RGB. Debido a esta discrepancia, uno puede decidir sobre la presencia de una anomalía.Debido a este método, es posible detectar la aparición de objetos no vistos previamente en el marco, que sin embargo son detectados por el algoritmo de búsqueda primario.
en parte, la idea de un método de búsqueda de profundidad se basa en un artículo sobre conjuntos de codificadores automáticos .Este enfoque funciona bien para objetos de varias formas.Pero, en general, hay muchos enfoques diferentes para encontrar un objeto XYZ a partir de una imagen RGBD. Por supuesto, es necesario en la práctica y en una gran cantidad de datos elegir el método más preciso.También estaba la tarea de detectar anomalías, para esto necesitamos una red convolucional de segmentación para aprender de las máscaras disponibles. Luego, de acuerdo con esta máscara, puede evaluar la precisión de la reconstrucción del codificador automático en el mapa de profundidad y RGB. Debido a esta discrepancia, uno puede decidir sobre la presencia de una anomalía.Debido a este método, es posible detectar la aparición de objetos no vistos previamente en el marco, que sin embargo son detectados por el algoritmo de búsqueda primario.Demostración
La comprobación y depuración de toda la plataforma de software creada se realizó en el stand:- Cámara 3D Realsense D435
- 4 coordenadas Dobot Magician
- Casco VR HTC Vive
- Servidores en Yandex Cloud (reduce la latencia en comparación con la nube de AWS)
En el video, enseñamos cómo encontrar un cubo en una escena 3D realizando una tarea en VR pick & place. Alrededor de 50 ejemplos fueron suficientes para entrenar en un cubo. Luego el objeto cambia y se muestran unos 30 ejemplos más. Después de volver a entrenar, el robot puede encontrar un nuevo objeto.El proceso completo duró aproximadamente 15 minutos, de los cuales aproximadamente la mitad del modelo de entrenamiento pesó.Y en este video, YuMi controla en realidad virtual. Para aprender a manipular objetos, debe evaluar la orientación y ubicación de la herramienta. La matemática se basa en un principio similar, pero ahora se encuentra en la etapa de prueba y desarrollo.Conclusión
Big data y Deep learning no es todo.Estamos cambiando el enfoque del aprendizaje, avanzando hacia la forma en que las personas aprenden cosas nuevas, repitiendo lo que ven.El aparato matemático "bajo el capó", que desarrollaremos en aplicaciones reales, está dirigido al problema de la interpretación y el control sensibles al contexto. El contexto aquí es información natural disponible de sensores de robot o información externa sobre el proceso actual.Y, cuanto más procesos tecnológicos dominemos, más se desarrollará la estructura del "cerebro en las nubes", y se entrenarán sus partes individuales.Fortalezas de este enfoque:- la posibilidad de aprender a manipular objetos variables
- Aprender en un entorno cambiante (por ejemplo, robots móviles)
- tareas mal estructuradas
- poco tiempo de comercialización; Puede realizar el objetivo incluso en modo manual utilizando los operadores
Limitación:- necesidad de internet confiable y bueno
- Se necesitan métodos adicionales para lograr una alta precisión, por ejemplo, cámaras en el manipulador mismo
Actualmente estamos trabajando en aplicar nuestro enfoque a la tarea estándar de selección y colocación de varios objetos. Pero nos parece (¡naturalmente!) Que él es capaz de más. ¿Alguna idea de dónde más probar tu mano?¡Gracias por su atención!