HighLoad ++, Mikhail Makurov, Maxim Chernetsov (Intersvyaz): Zabbix, 100kNVPS en un servidor
La próxima conferencia HighLoad ++ se llevará a cabo los días 6 y 7 de abril de 2020 en San Petersburgo. Detalles y entradas aquí . HighLoad ++ Moscú 2018. Salón de Moscú. 9 de noviembre, 3 p.m. Resúmenes y presentación . * Monitoreo - en línea y análisis.* Las principales limitaciones de la plataforma ZABBIX.* Solución para escalar el almacenamiento de análisis.* Optimización del servidor ZABBIX.* Optimización de la interfaz de usuario.* Experiencia en la operación del sistema con cargas de más de 40k NVPS.* Brevemente conclusiones.Mikhail Makurov (en adelante - MM): - ¡Hola a todos!Maxim Chernetsov (en adelante - MCH): - ¡Buenas tardes!MM: - Permítanme presentarles a Maxim. Max es un ingeniero talentoso, el mejor networker que conozco. Maxim trata con redes y servicios, su desarrollo y operación.
* Monitoreo - en línea y análisis.* Las principales limitaciones de la plataforma ZABBIX.* Solución para escalar el almacenamiento de análisis.* Optimización del servidor ZABBIX.* Optimización de la interfaz de usuario.* Experiencia en la operación del sistema con cargas de más de 40k NVPS.* Brevemente conclusiones.Mikhail Makurov (en adelante - MM): - ¡Hola a todos!Maxim Chernetsov (en adelante - MCH): - ¡Buenas tardes!MM: - Permítanme presentarles a Maxim. Max es un ingeniero talentoso, el mejor networker que conozco. Maxim trata con redes y servicios, su desarrollo y operación. MCH: - Y me gustaría hablar sobre Michael. Michael es un desarrollador C. Escribió algunas soluciones de procesamiento de tráfico altamente cargadas para nuestra empresa. Vivimos y trabajamos en los Urales, en la ciudad de campesinos severos de Chelyabinsk, en la compañía Intersvyaz. Nuestra empresa es proveedora de servicios de Internet y televisión por cable para un millón de personas en 16 ciudades.MM:- Y vale la pena decir que Intersvyaz es mucho más que un simple proveedor, es una empresa de TI. La mayoría de nuestras decisiones las toma nuestro departamento de TI.R: desde servidores que procesan tráfico, hasta el centro de llamadas y la aplicación móvil. Hay alrededor de 80 personas en el departamento de TI con competencias muy, muy diversas.
MCH: - Y me gustaría hablar sobre Michael. Michael es un desarrollador C. Escribió algunas soluciones de procesamiento de tráfico altamente cargadas para nuestra empresa. Vivimos y trabajamos en los Urales, en la ciudad de campesinos severos de Chelyabinsk, en la compañía Intersvyaz. Nuestra empresa es proveedora de servicios de Internet y televisión por cable para un millón de personas en 16 ciudades.MM:- Y vale la pena decir que Intersvyaz es mucho más que un simple proveedor, es una empresa de TI. La mayoría de nuestras decisiones las toma nuestro departamento de TI.R: desde servidores que procesan tráfico, hasta el centro de llamadas y la aplicación móvil. Hay alrededor de 80 personas en el departamento de TI con competencias muy, muy diversas.Sobre Zabbix y su arquitectura
MCH: - Y ahora intentaré establecer un récord personal y decir en un minuto qué es Zabbix (en adelante - "Zabbiks").Zabbix se posiciona como un sistema de monitoreo "listo para usar" a nivel empresarial. Tiene muchas características que simplifican la vida: reglas avanzadas de escalación, API para integración, agrupación y detección automática de hosts y métricas. En Zabbix hay las llamadas herramientas de escalado: proxies. Zabbix es un sistema de código abierto.Brevemente sobre arquitectura. Podemos decir que consta de tres componentes: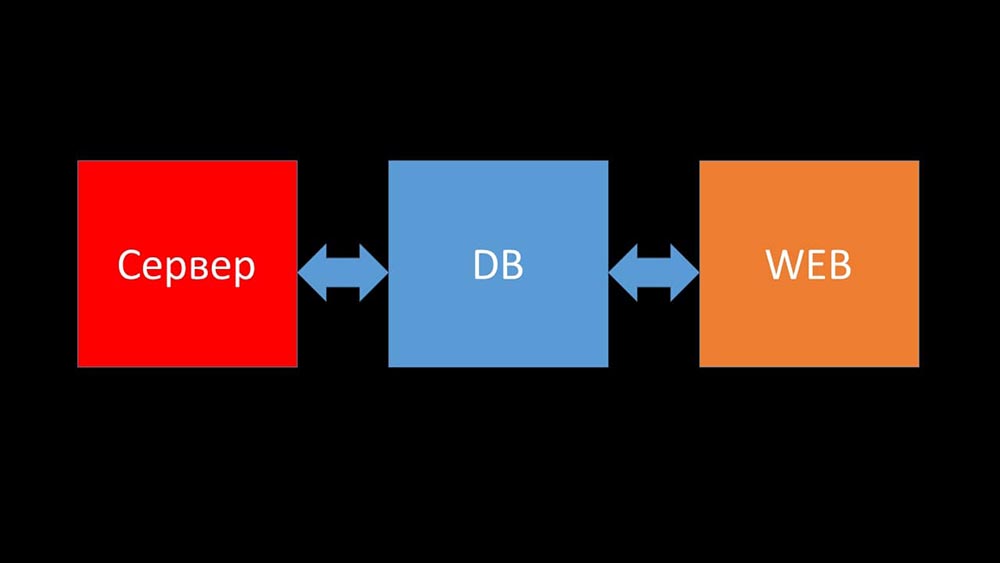
- Servidor. Está escrito en C. Con un procesamiento bastante complicado y la transmisión de información entre flujos. Todo el procesamiento tiene lugar en él: desde recibir hasta guardar en la base de datos.
- Todos los datos se almacenan en la base de datos. Zabbix es compatible con MySQL, PostreSQL y Oracle.
- La interfaz web está escrita en PHP. En la mayoría de los sistemas, viene con un servidor Apache, pero funciona de manera más eficiente en el paquete nginx + php.
Hoy nos gustaría contar de la vida de nuestra empresa una historia relacionada con Zabbix ...Historia de vida de la empresa Intersvyaz. ¿Qué tenemos y qué se necesita?
 Hace 5 o 6 meses. Una vez después del trabajo ...MCH: - ¡Misha, hola! Me alegro de que pude atraparte, hay una conversación. Nuevamente tuvimos problemas con el monitoreo. Durante un accidente grave, todo se ralentizó y no hubo información sobre el estado de la red. Lamentablemente, esta no es la primera vez que se repite. Necesito tu ayuda. ¡Hagamos que nuestro monitoreo funcione bajo cualquier circunstancia!MM: - Pero sincronicemos primero. No he buscado allí por un par de años. Hasta donde recuerdo, rechazamos a Nagios y nos cambiamos a Zabbix hace 8 años. Y ahora parece que tenemos 6 servidores potentes y alrededor de una docena de servidores proxy. ¿Estoy confundiendo algo?MCH:- Casi. 15 servidores, algunos de los cuales son máquinas virtuales. Lo más importante, esto no nos salva en el momento en que más lo necesitamos. Como un accidente: los servidores se están ralentizando y no se ve nada. Intentamos optimizar la configuración, pero esto no proporciona la ganancia de rendimiento óptima.MM: - Ya veo. ¿Buscaste algo, cavaste algo del diagnóstico?MCH:- Lo primero con lo que tiene que lidiar es solo la base de datos. MySQL se carga constantemente, preservando nuevas métricas, y cuando Zabbix comienza a generar un montón de eventos, la base de datos entra literalmente en sí misma durante varias horas. Ya le conté sobre la optimización de la configuración, pero literalmente este año actualizamos el hardware: hay más de cien gigabytes de memoria en los servidores y las matrices de discos en SSD RAID-ahs; no tiene sentido crecer linealmente. qué hacemos?MM: - Ya veo. En general, MySQL es una base de datos LTP. Aparentemente, ya no es adecuado para almacenar un archivo de métricas de nuestro tamaño. Vamos a resolverlo.MCH: ¡ Vamos!
Hace 5 o 6 meses. Una vez después del trabajo ...MCH: - ¡Misha, hola! Me alegro de que pude atraparte, hay una conversación. Nuevamente tuvimos problemas con el monitoreo. Durante un accidente grave, todo se ralentizó y no hubo información sobre el estado de la red. Lamentablemente, esta no es la primera vez que se repite. Necesito tu ayuda. ¡Hagamos que nuestro monitoreo funcione bajo cualquier circunstancia!MM: - Pero sincronicemos primero. No he buscado allí por un par de años. Hasta donde recuerdo, rechazamos a Nagios y nos cambiamos a Zabbix hace 8 años. Y ahora parece que tenemos 6 servidores potentes y alrededor de una docena de servidores proxy. ¿Estoy confundiendo algo?MCH:- Casi. 15 servidores, algunos de los cuales son máquinas virtuales. Lo más importante, esto no nos salva en el momento en que más lo necesitamos. Como un accidente: los servidores se están ralentizando y no se ve nada. Intentamos optimizar la configuración, pero esto no proporciona la ganancia de rendimiento óptima.MM: - Ya veo. ¿Buscaste algo, cavaste algo del diagnóstico?MCH:- Lo primero con lo que tiene que lidiar es solo la base de datos. MySQL se carga constantemente, preservando nuevas métricas, y cuando Zabbix comienza a generar un montón de eventos, la base de datos entra literalmente en sí misma durante varias horas. Ya le conté sobre la optimización de la configuración, pero literalmente este año actualizamos el hardware: hay más de cien gigabytes de memoria en los servidores y las matrices de discos en SSD RAID-ahs; no tiene sentido crecer linealmente. qué hacemos?MM: - Ya veo. En general, MySQL es una base de datos LTP. Aparentemente, ya no es adecuado para almacenar un archivo de métricas de nuestro tamaño. Vamos a resolverlo.MCH: ¡ Vamos!La integración de Zabbix y Clickhouse como resultado del hackathon
Después de un tiempo, recibimos datos interesantes: la mayor parte del espacio en nuestra base de datos estaba ocupada por el archivo de métricas y menos del 1% se usaba para la configuración, las plantillas y la configuración. En ese momento, durante más de un año ya habíamos estado operando la solución Big Data basada en Clickhouse. La dirección del movimiento era obvia para nosotros. En nuestro Hackathon de primavera, escribió la integración de Zabbix con Clickhouse para el servidor y la interfaz. En ese momento, Zabbix ya tenía soporte para ElasticSearch, y decidimos compararlos.
mayor parte del espacio en nuestra base de datos estaba ocupada por el archivo de métricas y menos del 1% se usaba para la configuración, las plantillas y la configuración. En ese momento, durante más de un año ya habíamos estado operando la solución Big Data basada en Clickhouse. La dirección del movimiento era obvia para nosotros. En nuestro Hackathon de primavera, escribió la integración de Zabbix con Clickhouse para el servidor y la interfaz. En ese momento, Zabbix ya tenía soporte para ElasticSearch, y decidimos compararlos.
Compare Clickhouse y Elasticsearch
MM: - En comparación, generamos la misma carga que proporciona el servidor Zabbix y analizamos cómo se comportarían los sistemas. Escribimos datos en lotes de 1000 líneas, usamos CURL. Anteriormente sugerimos que Clickhouse sería más efectivo para el perfil de carga que hace Zabbix. Los resultados incluso excedieron nuestras expectativas: bajo las mismas condiciones de prueba, Clickhouse escribió tres veces más datos. Al mismo tiempo, ambos sistemas consumieron de manera muy eficiente (una pequeña cantidad de recursos) mientras leían datos. Pero "Elastix" requería una gran cantidad de procesador al grabar:En total, Clickhouse superó significativamente a Elastix en el consumo y la velocidad del procesador. Al mismo tiempo, debido a la compresión de datos, "Clickhouse" usa 11 veces menos en el disco duro y realiza aproximadamente 30 veces menos operaciones de disco:
bajo las mismas condiciones de prueba, Clickhouse escribió tres veces más datos. Al mismo tiempo, ambos sistemas consumieron de manera muy eficiente (una pequeña cantidad de recursos) mientras leían datos. Pero "Elastix" requería una gran cantidad de procesador al grabar:En total, Clickhouse superó significativamente a Elastix en el consumo y la velocidad del procesador. Al mismo tiempo, debido a la compresión de datos, "Clickhouse" usa 11 veces menos en el disco duro y realiza aproximadamente 30 veces menos operaciones de disco: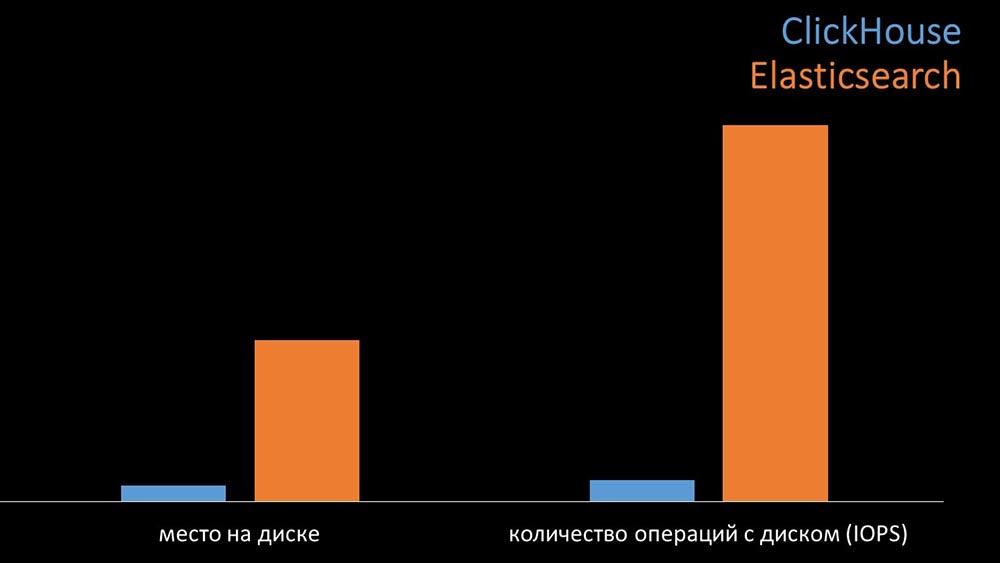 MCH: - Sí, trabajar con el subsistema de disco en "Clickhouse" es muy efectivo. Debajo de las bases, puede usar enormes discos SATA y obtener una velocidad de escritura de cientos de miles de líneas por segundo. El sistema "listo para usar" admite fragmentación, replicación, es muy fácil de configurar. Estamos más que contentos con su funcionamiento durante un año.Para optimizar los recursos, puede instalar "Clickhouse" junto a la base principal existente y así ahorrar mucho tiempo de procesador y operaciones de disco. Sacamos el archivo de métricas a los clústeres existentes de "Clickhouse":
MCH: - Sí, trabajar con el subsistema de disco en "Clickhouse" es muy efectivo. Debajo de las bases, puede usar enormes discos SATA y obtener una velocidad de escritura de cientos de miles de líneas por segundo. El sistema "listo para usar" admite fragmentación, replicación, es muy fácil de configurar. Estamos más que contentos con su funcionamiento durante un año.Para optimizar los recursos, puede instalar "Clickhouse" junto a la base principal existente y así ahorrar mucho tiempo de procesador y operaciones de disco. Sacamos el archivo de métricas a los clústeres existentes de "Clickhouse":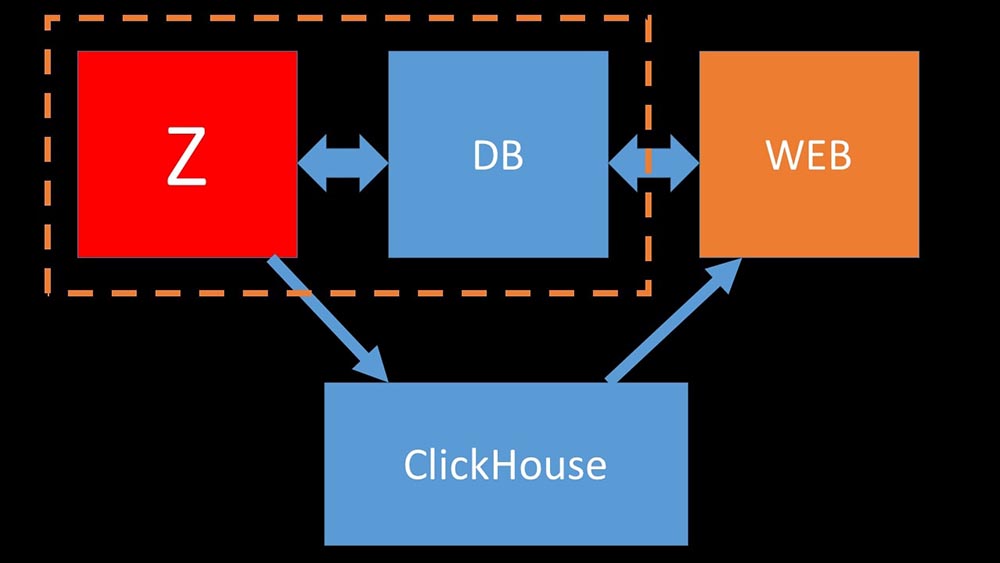 Descargamos la base de datos MySQL principal tanto que pudimos combinarla en la misma máquina con el servidor Zabbix y abandonar el servidor dedicado para MySQL.
Descargamos la base de datos MySQL principal tanto que pudimos combinarla en la misma máquina con el servidor Zabbix y abandonar el servidor dedicado para MySQL.¿Cómo funciona el sondeo en Zabbix?
Hace 4 mesesMM: - Bueno, ¿puedes olvidarte de los problemas con la base?MCH: - ¡Eso es seguro! Otro problema que debemos resolver es la recolección lenta de datos. Ahora todos nuestros 15 servidores proxy están sobrecargados con SNMP y procesos de votación. Y no hay otro que configurar servidores nuevos y nuevos.MM: - Genial. Pero primero dime cómo funciona el sondeo en Zabbix.MCH: - En resumen, hay 20 tipos de métricas y una docena de formas de obtenerlas. Zabbix puede recopilar datos ya sea en el modo "solicitud-respuesta", o esperar nuevos datos a través de la "Interfaz Trapper". Vale la pena señalar que en el Zabbix original, este método (Trapper) es el más rápido.Hay proxies para el equilibrio de carga:
Vale la pena señalar que en el Zabbix original, este método (Trapper) es el más rápido.Hay proxies para el equilibrio de carga: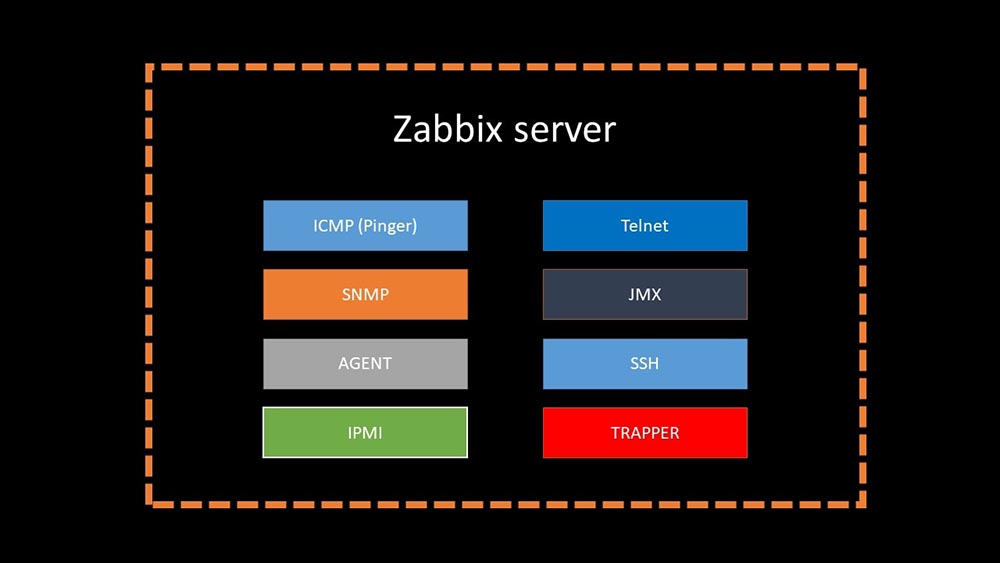 Los proxies pueden realizar las mismas funciones de recopilación que el servidor Zabbix, recibir tareas de él y enviar métricas recopiladas a través de la interfaz Trapper. Este es el método de equilibrio de carga recomendado oficialmente. Además, los proxies son útiles para monitorear una infraestructura remota que funciona a través de NAT o un canal lento:
Los proxies pueden realizar las mismas funciones de recopilación que el servidor Zabbix, recibir tareas de él y enviar métricas recopiladas a través de la interfaz Trapper. Este es el método de equilibrio de carga recomendado oficialmente. Además, los proxies son útiles para monitorear una infraestructura remota que funciona a través de NAT o un canal lento: MM: - Todo está claro con la arquitectura. Debemos mirar la fuente ...Un par de días después
MM: - Todo está claro con la arquitectura. Debemos mirar la fuente ...Un par de días despuésCuento de cómo ganó nmap fping
MM: - Parece que desenterré algo.MCH: - ¡Dime!MM: - Encontré que durante las verificaciones de disponibilidad, Zabbix realiza una verificación de hasta 128 hosts a la vez. Traté de aumentar esta cifra a 500 y eliminé el intervalo entre paquetes en su ping (ping); esto aumentó el rendimiento en un factor de dos. Pero me gustaría grandes números.MCH: - En mi práctica, a veces tengo que verificar la disponibilidad de miles de hosts, y no he visto nada más rápido que nmap. Estoy seguro de que esta es la forma más rápida. ¡Vamos a intentarlo! Necesita aumentar significativamente el número de hosts en una iteración.MM: - ¿Verifica más de quinientos? 600?MCH: - Al menos un par de miles.MM:- Bueno. Lo más importante que quería decir: descubrí que la mayoría de las encuestas en Zabbix se realizaban sincrónicamente. Debemos rehacerlo asincrónicamente. Entonces podemos aumentar drásticamente el número de métricas recopiladas por los encuestadores, especialmente si aumentamos el número de métricas en una iteración.MCH: ¡Genial! ¿Y cuando?MM: - Como siempre, ayer.MCH: - Comparamos ambas versiones de fping y nmap: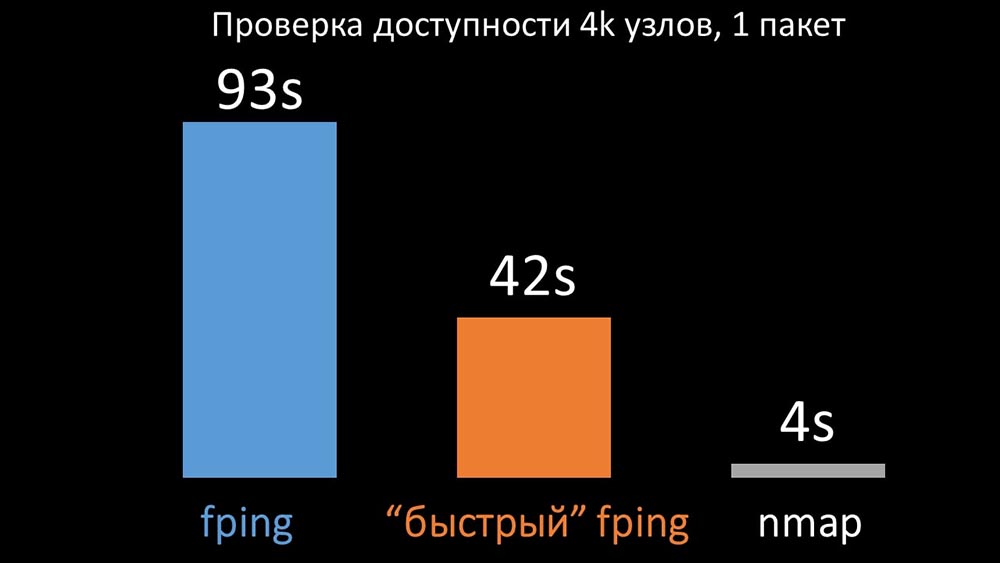 En una gran cantidad de hosts, se esperaba que nmap fuera hasta cinco veces más eficiente. Dado que nmap solo verifica el hecho de la disponibilidad y el tiempo de respuesta, transferimos el cálculo de pérdida a los desencadenantes y redujimos significativamente los intervalos de verificación de disponibilidad. Encontramos el número óptimo de hosts para nmap en la región de 4 mil por iteración. Nmap nos permitió reducir los costos de CPU para verificaciones de disponibilidad en tres veces y reducir el intervalo de 120 segundos a 10.
En una gran cantidad de hosts, se esperaba que nmap fuera hasta cinco veces más eficiente. Dado que nmap solo verifica el hecho de la disponibilidad y el tiempo de respuesta, transferimos el cálculo de pérdida a los desencadenantes y redujimos significativamente los intervalos de verificación de disponibilidad. Encontramos el número óptimo de hosts para nmap en la región de 4 mil por iteración. Nmap nos permitió reducir los costos de CPU para verificaciones de disponibilidad en tres veces y reducir el intervalo de 120 segundos a 10.Optimización de sondeo
MM: - Luego fuimos por los encuestadores. Estábamos principalmente interesados en la eliminación de SNMP y agentes. En Zabbix, las encuestas se realizaron sincrónicamente y se tomaron medidas especiales para aumentar la eficiencia del sistema. En modo síncrono, la indisponibilidad del host provoca una degradación significativa de los sondeos. Hay un sistema completo de estados, hay procesos especiales: los llamados sondeos inalcanzables que funcionan solo con hosts inaccesibles: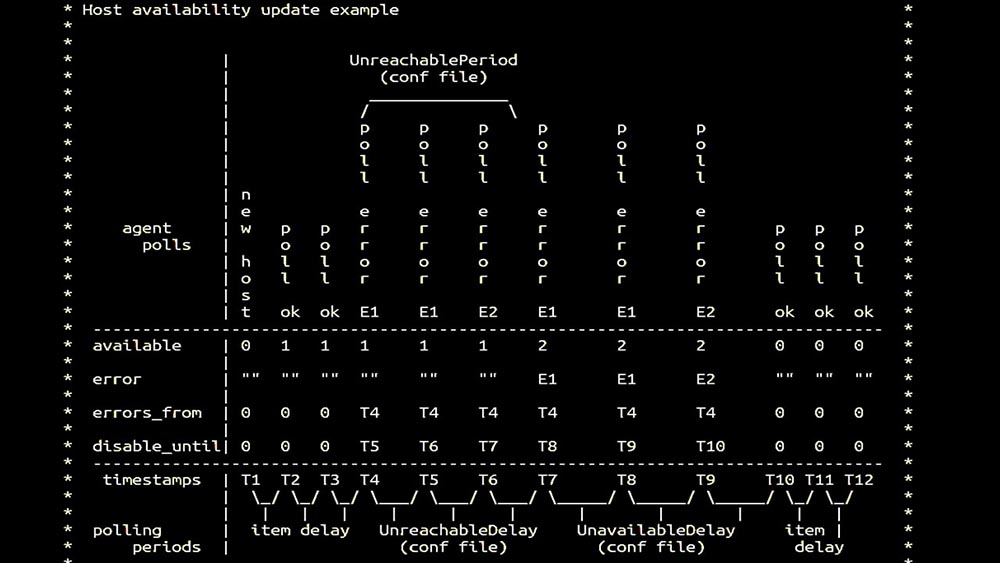 este es un comentario que demuestra la matriz de estados, toda la complejidad del sistema de transición que se requiere para que el sistema siga siendo efectivo. Además, el sondeo sincrónico en sí mismo es bastante lento:
este es un comentario que demuestra la matriz de estados, toda la complejidad del sistema de transición que se requiere para que el sistema siga siendo efectivo. Además, el sondeo sincrónico en sí mismo es bastante lento: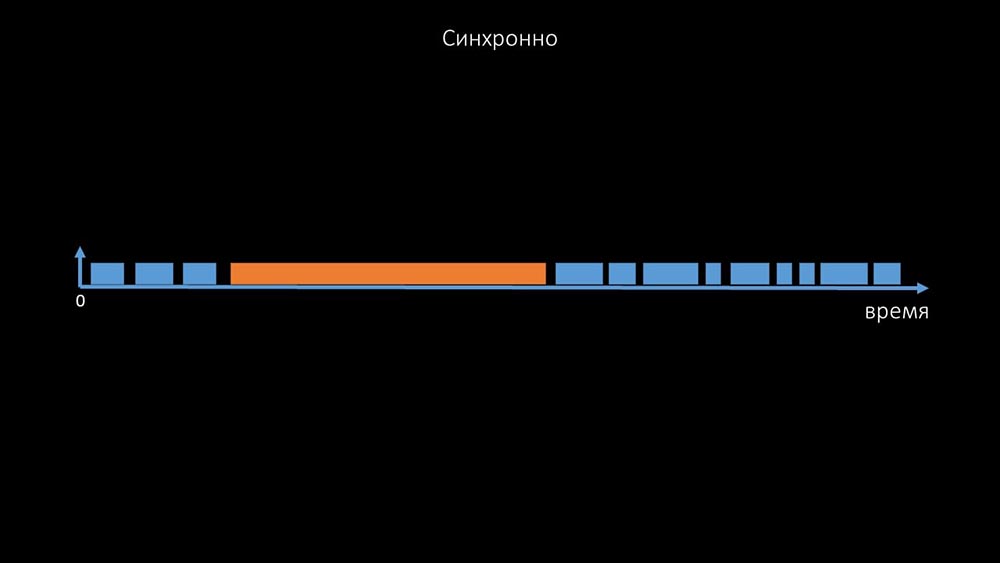 Es por eso que miles de hilos de votación en una docena de servidores proxy no pudieron recopilar la cantidad de datos necesaria para nosotros. La implementación asincrónica resolvió no solo los problemas con el número de subprocesos, sino que también simplificó significativamente el sistema de estado de los hosts inaccesibles, porque para cualquier número verificado en una iteración de sondeo, el tiempo máximo de espera fue 1 tiempo de espera:
Es por eso que miles de hilos de votación en una docena de servidores proxy no pudieron recopilar la cantidad de datos necesaria para nosotros. La implementación asincrónica resolvió no solo los problemas con el número de subprocesos, sino que también simplificó significativamente el sistema de estado de los hosts inaccesibles, porque para cualquier número verificado en una iteración de sondeo, el tiempo máximo de espera fue 1 tiempo de espera: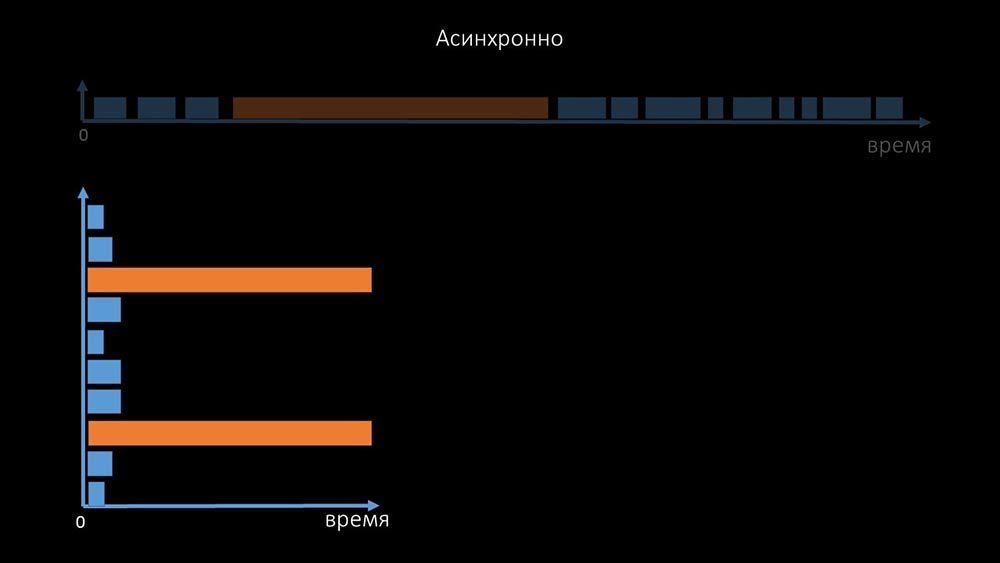 además, modificamos y mejoramos el sistema de sondeo para SNMP- consultas El hecho es que la mayoría no puede responder a múltiples solicitudes SNMP al mismo tiempo. Por lo tanto, creamos un modo híbrido cuando el sondeo SNMP del mismo host se realiza de forma asíncrona:
además, modificamos y mejoramos el sistema de sondeo para SNMP- consultas El hecho es que la mayoría no puede responder a múltiples solicitudes SNMP al mismo tiempo. Por lo tanto, creamos un modo híbrido cuando el sondeo SNMP del mismo host se realiza de forma asíncrona: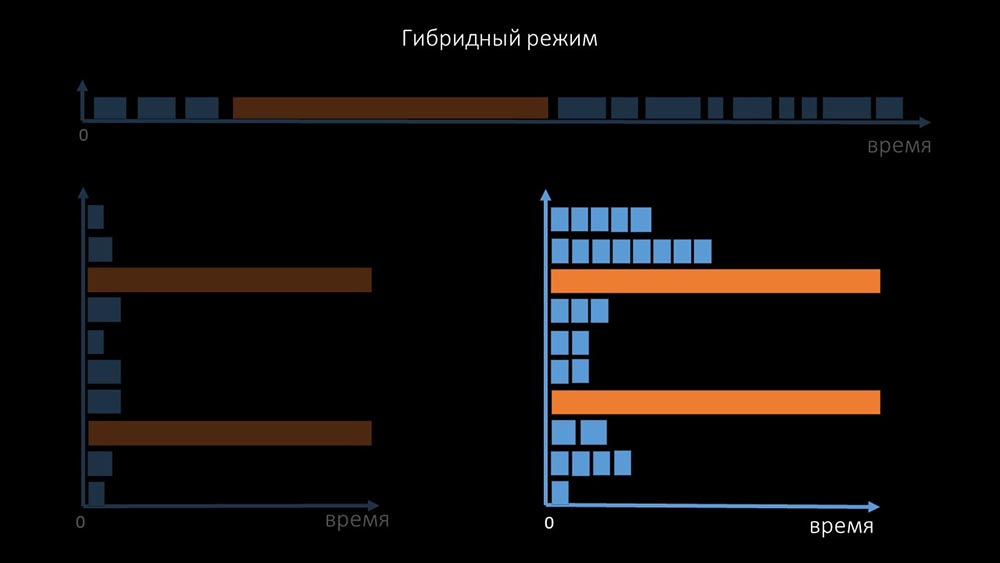 esto se hace para todo el paquete de hosts. Al final, este modo no es más lento que completamente asíncrono, ya que sondear un centenar y medio de valores SNMP es mucho más rápido que 1 tiempo de espera.Nuestros experimentos mostraron que el número óptimo de solicitudes en una iteración es de aproximadamente 8 mil con sondeo SNMP. En total, la transición al modo asincrónico permitió acelerar el rendimiento del sondeo 200 veces, varios cientos de veces.MCH: - Las optimizaciones de sondeo obtenidas mostraron que no solo podemos deshacernos de todos los proxies, sino también reducir los intervalos para muchas comprobaciones, y los proxies no serán necesarios como una forma de compartir la carga.Hace unos tres meses
esto se hace para todo el paquete de hosts. Al final, este modo no es más lento que completamente asíncrono, ya que sondear un centenar y medio de valores SNMP es mucho más rápido que 1 tiempo de espera.Nuestros experimentos mostraron que el número óptimo de solicitudes en una iteración es de aproximadamente 8 mil con sondeo SNMP. En total, la transición al modo asincrónico permitió acelerar el rendimiento del sondeo 200 veces, varios cientos de veces.MCH: - Las optimizaciones de sondeo obtenidas mostraron que no solo podemos deshacernos de todos los proxies, sino también reducir los intervalos para muchas comprobaciones, y los proxies no serán necesarios como una forma de compartir la carga.Hace unos tres mesesCambie la arquitectura, ¡aumente la carga!
MM: - Bueno, Max, ¿es hora de ser productivo? Necesito un servidor potente y un buen ingeniero.MCH: - Bueno, lo planeamos. Es hora de despegar a 5.000 métricas por segundo.Mañana después de la actualización deMCH: - Misha, actualizamos, pero retrocedimos por la mañana ... ¿Adivina qué velocidad alcanzaste?MM: - Mil 20 como máximo.MCH: - ¡Sí, 25! Desafortunadamente, estamos donde comenzamos.MM: - ¿Y entonces? ¿Recibió algún diagnóstico?MCH: - Sí, por supuesto! Aquí, por ejemplo, un top interesante: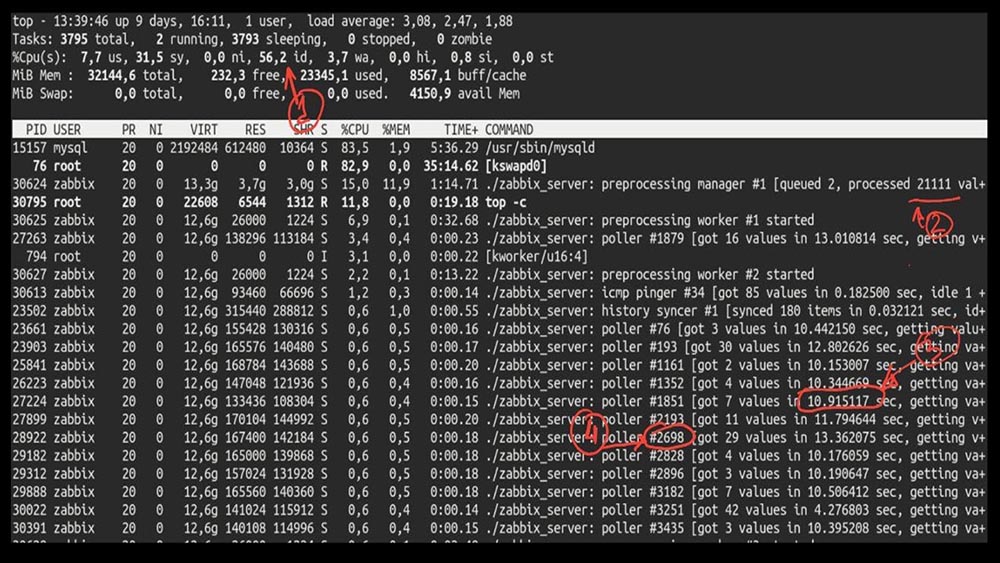 MM: - Veamos. Veo que probamos una gran cantidad de hilos de votación:
MM: - Veamos. Veo que probamos una gran cantidad de hilos de votación: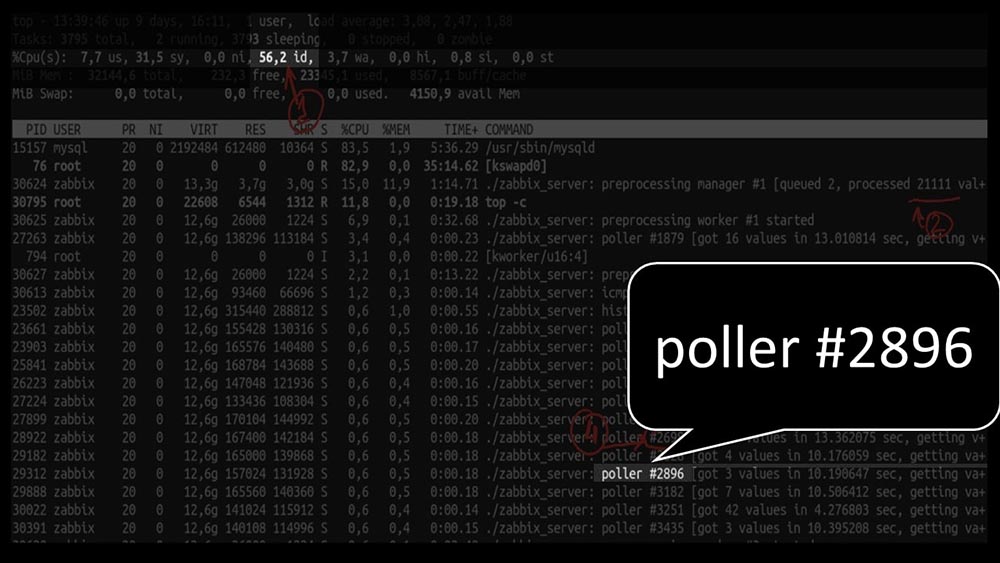 pero al mismo tiempo no pudimos utilizar el sistema ni siquiera a la mitad:
pero al mismo tiempo no pudimos utilizar el sistema ni siquiera a la mitad: Y el rendimiento general es bastante pequeño, alrededor de 4 mil métricas por segundo:
Y el rendimiento general es bastante pequeño, alrededor de 4 mil métricas por segundo: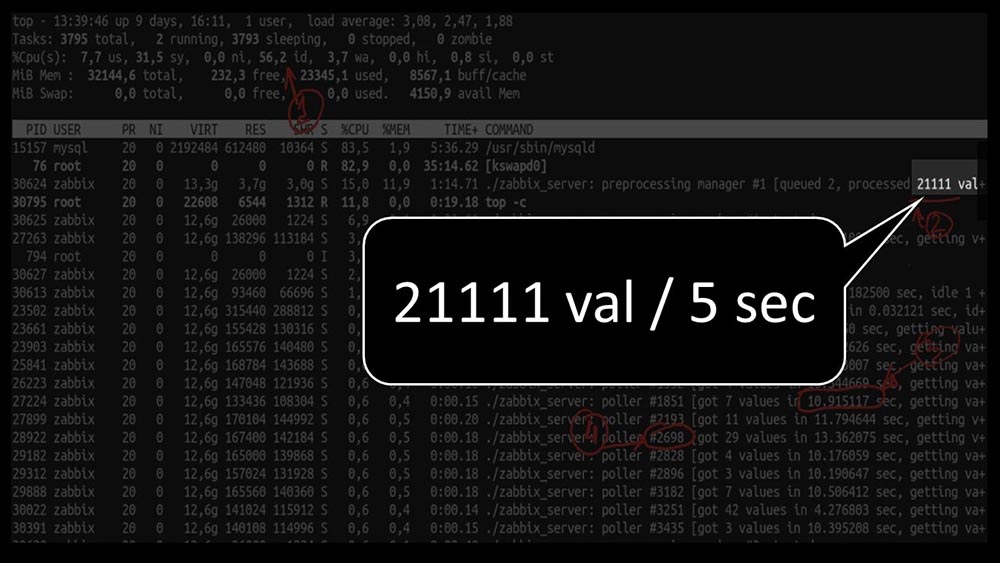 ¿hay algo más?MCH: - Sí, parte de uno de los encuestadores:
¿hay algo más?MCH: - Sí, parte de uno de los encuestadores: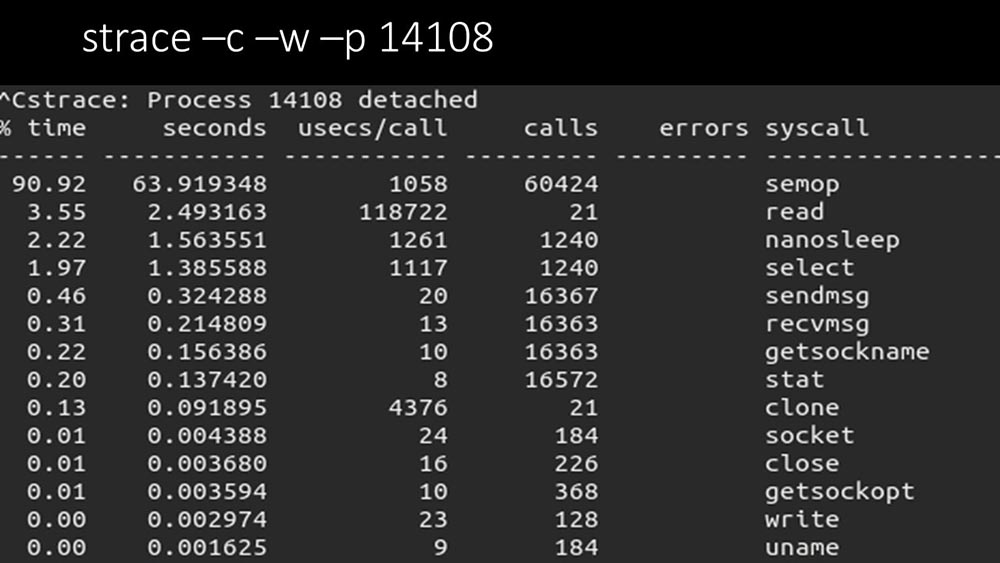 MM: - Aquí se ve claramente que el proceso de votación está esperando "semáforos". Estos son bloqueos:
MM: - Aquí se ve claramente que el proceso de votación está esperando "semáforos". Estos son bloqueos: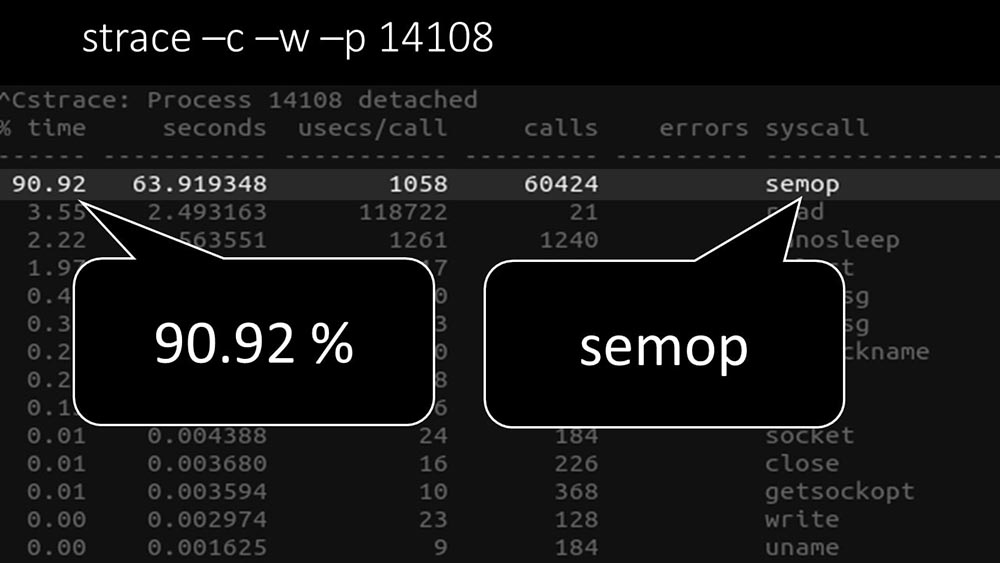 MCH: - No está claro.MM: - Mira, esto es como una situación en la que un montón de hilos intentan trabajar con recursos con los que solo uno puede trabajar a la vez. Entonces, todo lo que pueden hacer es compartir este recurso por tiempo:
MCH: - No está claro.MM: - Mira, esto es como una situación en la que un montón de hilos intentan trabajar con recursos con los que solo uno puede trabajar a la vez. Entonces, todo lo que pueden hacer es compartir este recurso por tiempo: y la productividad total de trabajar con dicho recurso está limitada por la velocidad de un núcleo:
y la productividad total de trabajar con dicho recurso está limitada por la velocidad de un núcleo: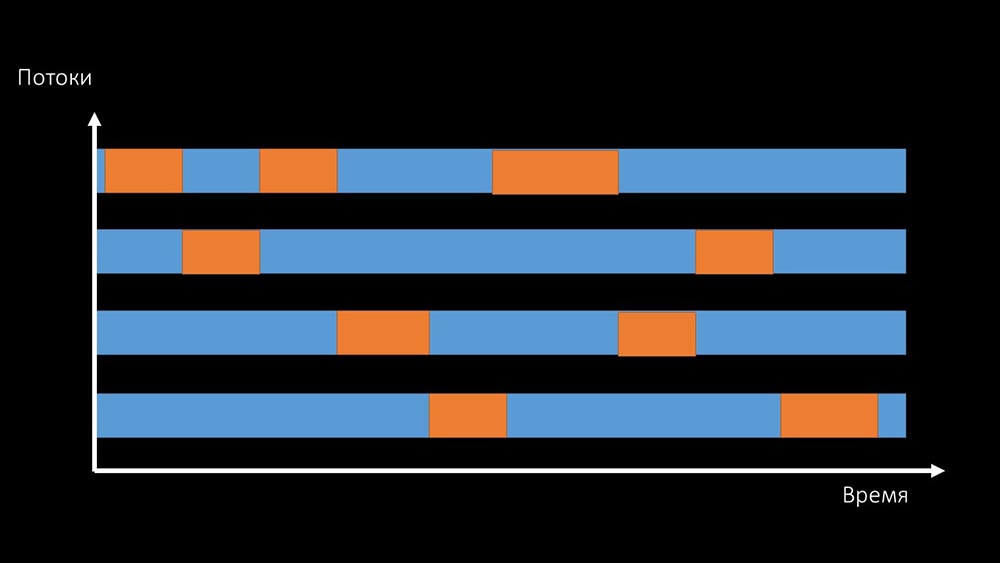 hay dos formas de resolver este problema.Actualice la máquina de planchar, cambie a núcleos más rápidos:
hay dos formas de resolver este problema.Actualice la máquina de planchar, cambie a núcleos más rápidos: O cambie la arquitectura y , al mismo tiempo , la carga:
O cambie la arquitectura y , al mismo tiempo , la carga: MCH: - Por cierto, usaremos menos núcleos en una máquina de prueba que en una de combate, ¡pero serán 1.5 veces más rápidas en frecuencia por núcleo!MM: - ¿ Eso está claro? Es necesario mirar el código del servidor.
MCH: - Por cierto, usaremos menos núcleos en una máquina de prueba que en una de combate, ¡pero serán 1.5 veces más rápidas en frecuencia por núcleo!MM: - ¿ Eso está claro? Es necesario mirar el código del servidor.Ruta de datos en el servidor Zabbix
MCH: - Para entenderlo, comenzamos a analizar cómo se transmiten los datos dentro del servidor Zabbix: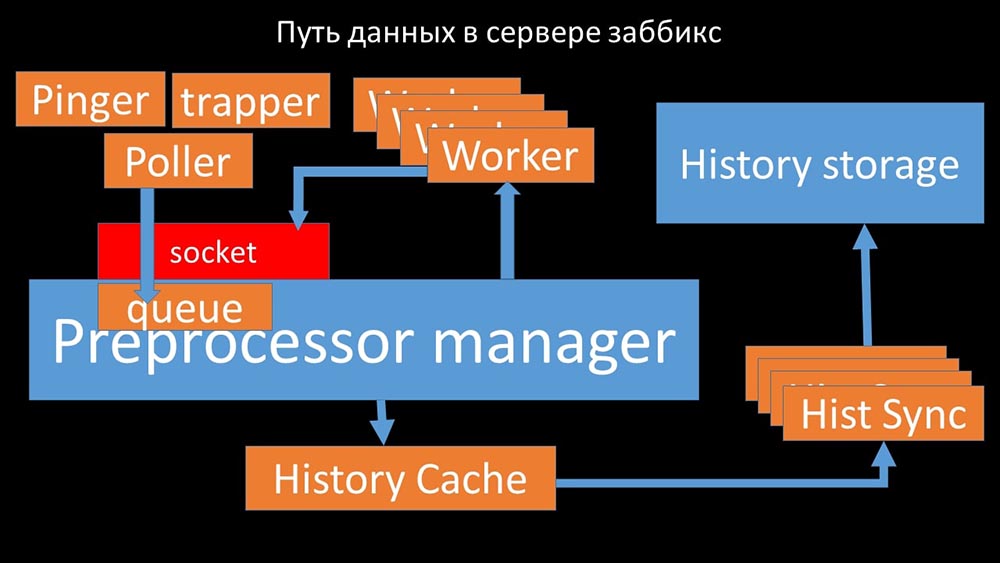 Imagen genial, ¿verdad? Veamos paso a paso para aclarar más o menos. Hay flujos y servicios responsables de recopilar datos:
Imagen genial, ¿verdad? Veamos paso a paso para aclarar más o menos. Hay flujos y servicios responsables de recopilar datos: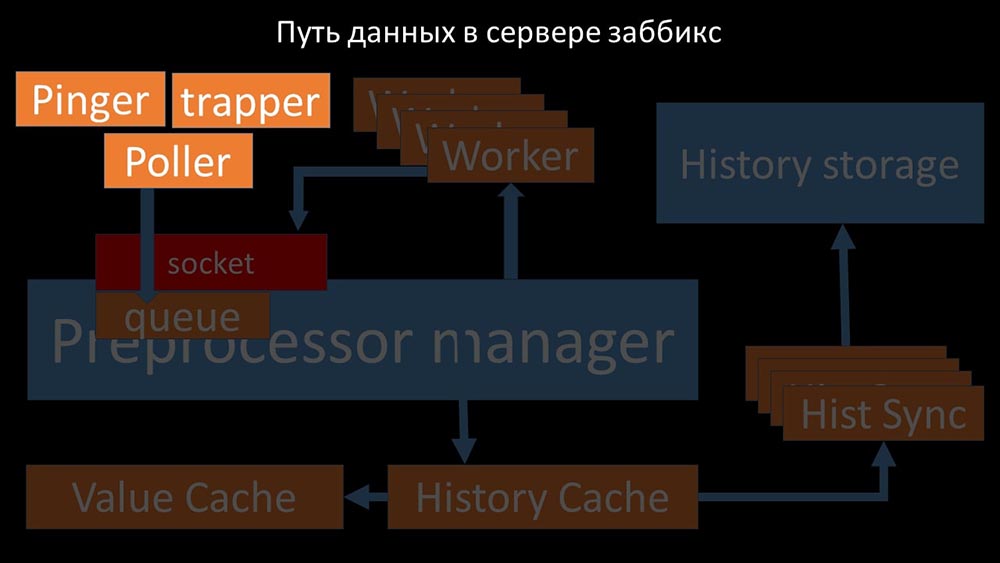 transfieren las métricas recopiladas a través del socket al administrador del preprocesador, donde se ponen en cola:
transfieren las métricas recopiladas a través del socket al administrador del preprocesador, donde se ponen en cola: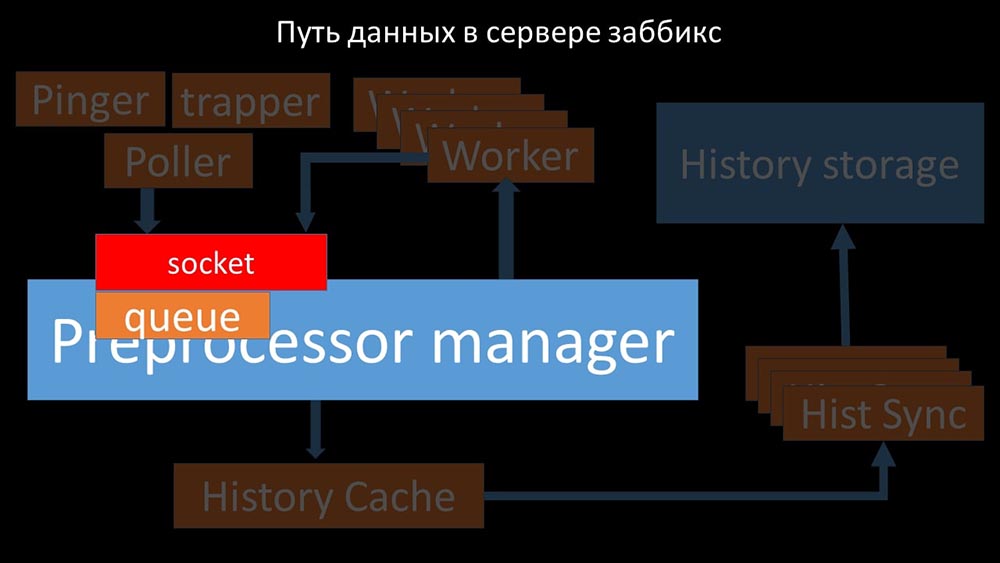 Preprocessor-manager "transfiere datos a sus trabajadores que ejecutan las instrucciones de preprocesamiento y los devuelven a través del mismo socket:
Preprocessor-manager "transfiere datos a sus trabajadores que ejecutan las instrucciones de preprocesamiento y los devuelven a través del mismo socket: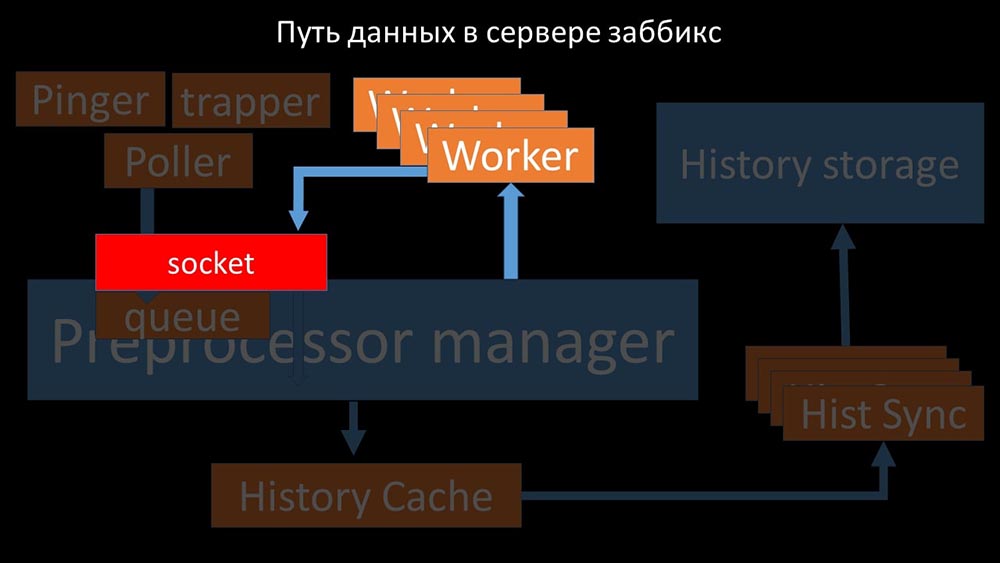 después de eso, el preprocesador -manager los guarda en el caché del historial:
después de eso, el preprocesador -manager los guarda en el caché del historial: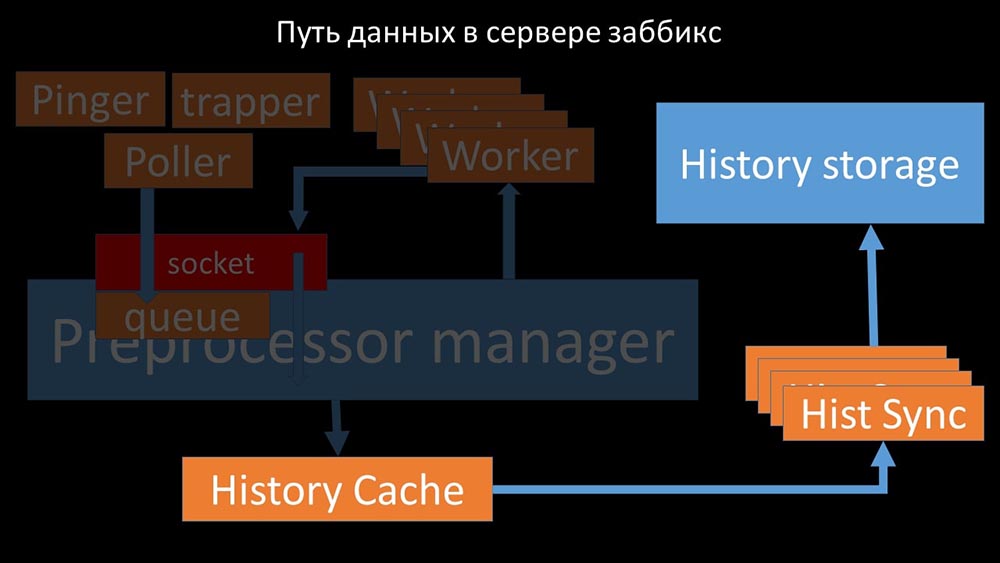 A partir de ahí, son recogidos por los hundidores del historial que realizan muchas funciones: por ejemplo, calcular disparadores, llenar el caché de valores y, lo más importante, guardar métricas en el almacén de historial. En general, el proceso es complejo y muy confuso.
A partir de ahí, son recogidos por los hundidores del historial que realizan muchas funciones: por ejemplo, calcular disparadores, llenar el caché de valores y, lo más importante, guardar métricas en el almacén de historial. En general, el proceso es complejo y muy confuso. MM: - Lo primero que vimos es que la mayoría de los hilos compiten por el llamado "caché de configuración" (un área de memoria donde se almacenan todas las configuraciones del servidor). Las secuencias responsables de la recopilación de datos realizan una gran cantidad de bloqueos:
MM: - Lo primero que vimos es que la mayoría de los hilos compiten por el llamado "caché de configuración" (un área de memoria donde se almacenan todas las configuraciones del servidor). Las secuencias responsables de la recopilación de datos realizan una gran cantidad de bloqueos: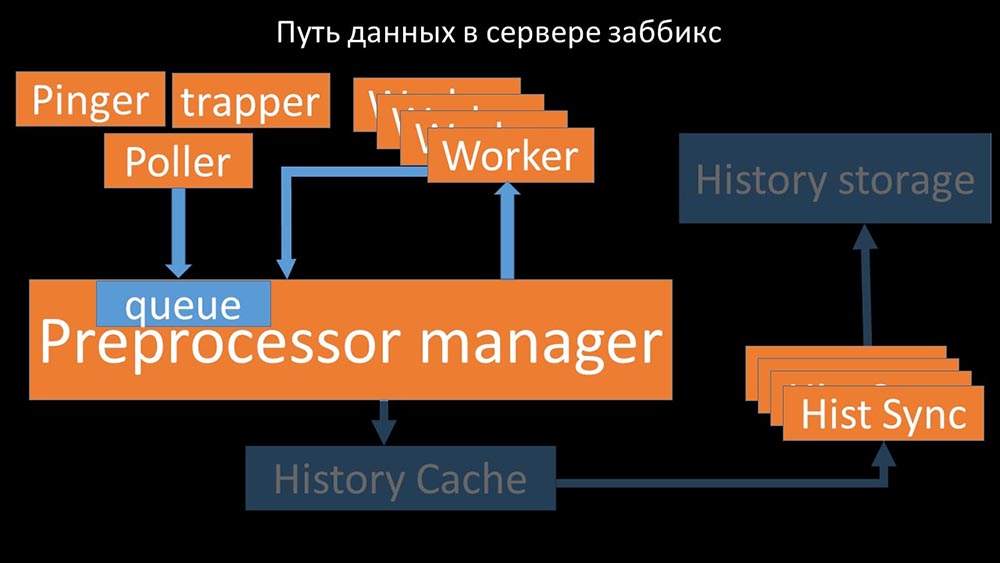 ... ya que la configuración almacena no solo métricas con sus parámetros, sino también colas, de las cuales los encuestadores toman información sobre qué hacer a continuación. Cuando hay muchos encuestadores, y uno bloquea la configuración, el resto espera solicitudes:
... ya que la configuración almacena no solo métricas con sus parámetros, sino también colas, de las cuales los encuestadores toman información sobre qué hacer a continuación. Cuando hay muchos encuestadores, y uno bloquea la configuración, el resto espera solicitudes:
Los encuestadores no deben entrar en conflicto
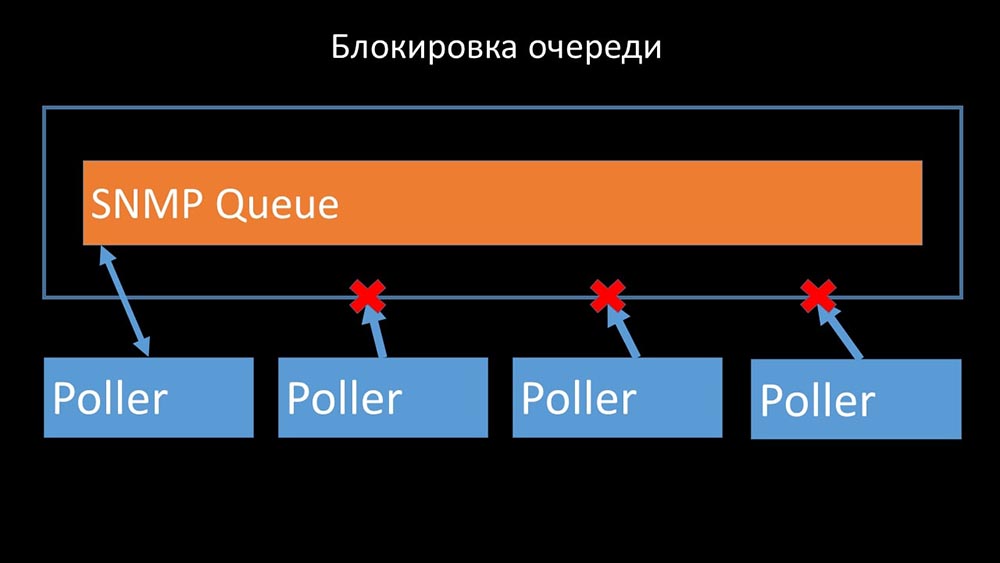 Por lo tanto, lo primero que hicimos fue dividir la cola en 4 partes y permitir que los encuestadores bloqueen de manera segura estas colas, estas partes al mismo tiempo:
Por lo tanto, lo primero que hicimos fue dividir la cola en 4 partes y permitir que los encuestadores bloqueen de manera segura estas colas, estas partes al mismo tiempo: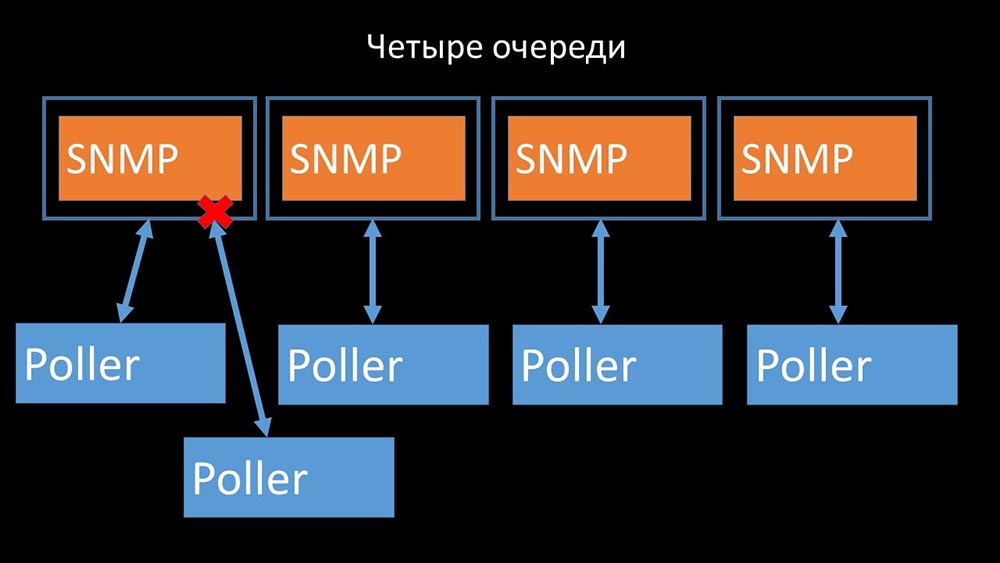 esto eliminó la competencia por la caché de configuración y la velocidad de los encuestadores aumentó significativamente. Pero luego nos enfrentamos con el hecho de que el gerente del preprocesador comenzó a acumular una cola de trabajo:
esto eliminó la competencia por la caché de configuración y la velocidad de los encuestadores aumentó significativamente. Pero luego nos enfrentamos con el hecho de que el gerente del preprocesador comenzó a acumular una cola de trabajo:
El administrador del preprocesador debería poder priorizar
Esto sucedió cuando le faltaba productividad. Entonces todo lo que podía hacer era solicitudes acumulan a partir de los procesos de recolección de datos y su memoria intermedia hasta que se come toda la memoria y se bloquea: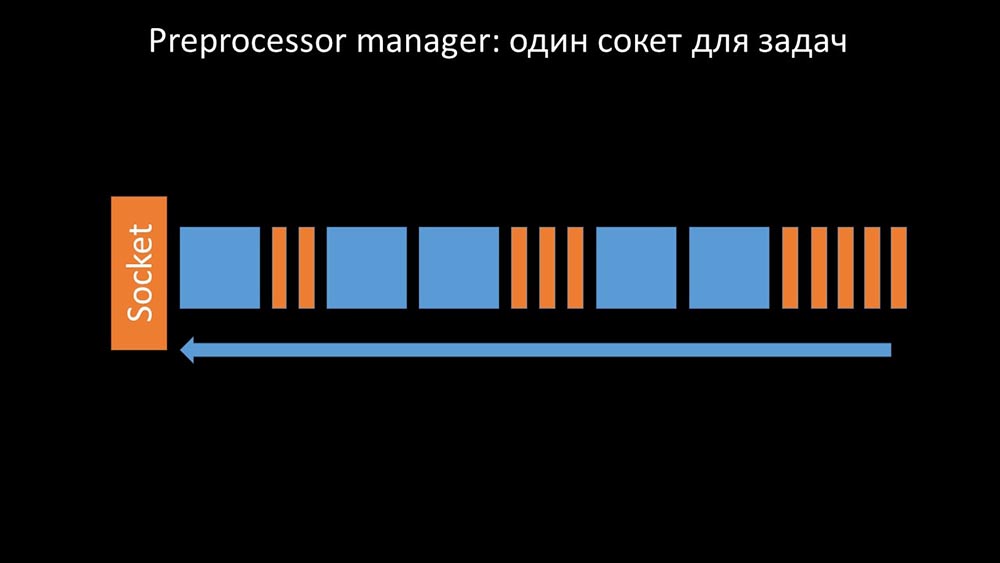 Para resolver este problema, hemos añadido una segunda toma, que fue asignado específicamente para los trabajadores:
Para resolver este problema, hemos añadido una segunda toma, que fue asignado específicamente para los trabajadores: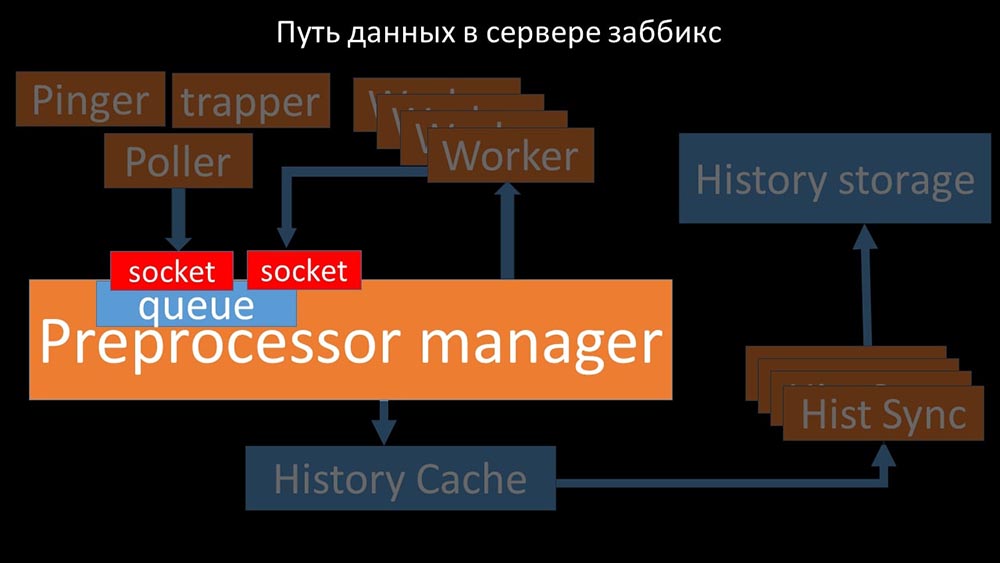 Por lo tanto , el administrador del preprocesador tuvo la oportunidad de priorizar su trabajo y, en caso de que el buffer crezca, la tarea es reducir la velocidad de la comida, dando a los trabajadores la oportunidad de recoger este buffer:
Por lo tanto , el administrador del preprocesador tuvo la oportunidad de priorizar su trabajo y, en caso de que el buffer crezca, la tarea es reducir la velocidad de la comida, dando a los trabajadores la oportunidad de recoger este buffer: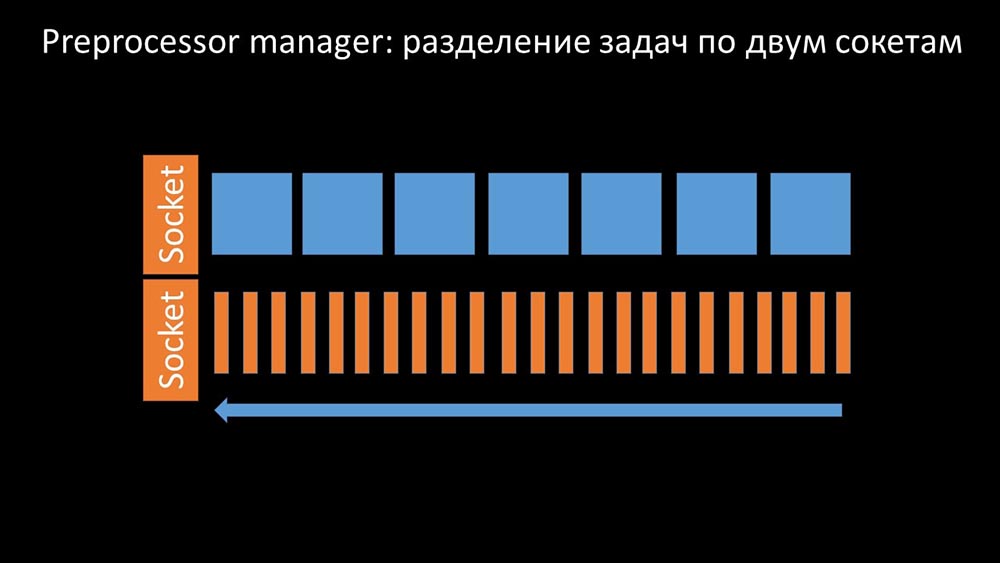 Entonces descubrimos que una de las razones de la desaceleración era porque los trabajadores mismos estaban compitiendo por recurso vital para su trabajo. Registramos este problema con una corrección de errores, y en las nuevas versiones de Zabbix ya se ha resuelto:
Entonces descubrimos que una de las razones de la desaceleración era porque los trabajadores mismos estaban compitiendo por recurso vital para su trabajo. Registramos este problema con una corrección de errores, y en las nuevas versiones de Zabbix ya se ha resuelto: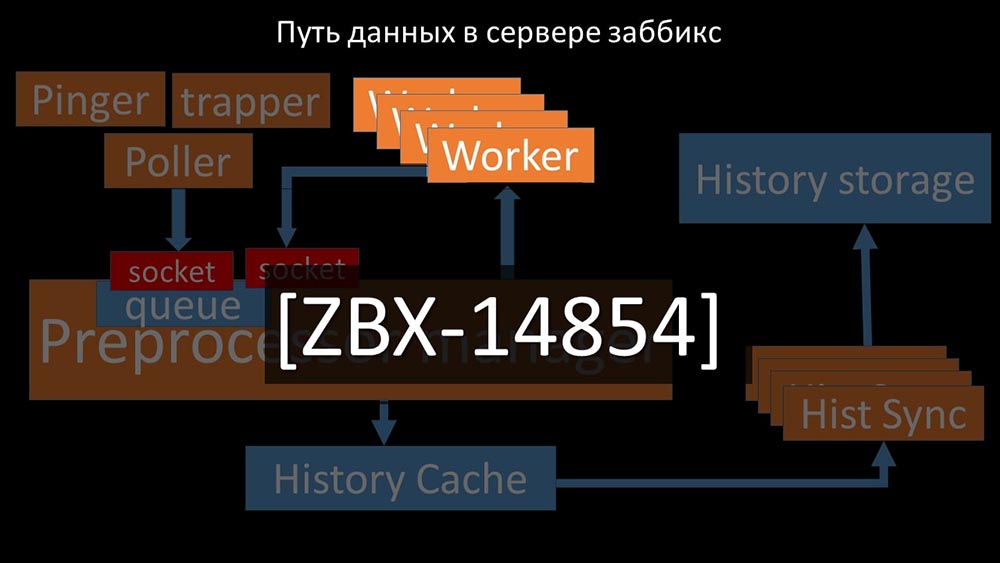
Aumentamos el número de tomas: obtenemos el resultado
Además, el administrador del preprocesador se convirtió en un enlace estrecho, ya que es un hilo único. Se basaba en la velocidad del núcleo, dando una velocidad máxima de aproximadamente 70 mil métricas por segundo: por lo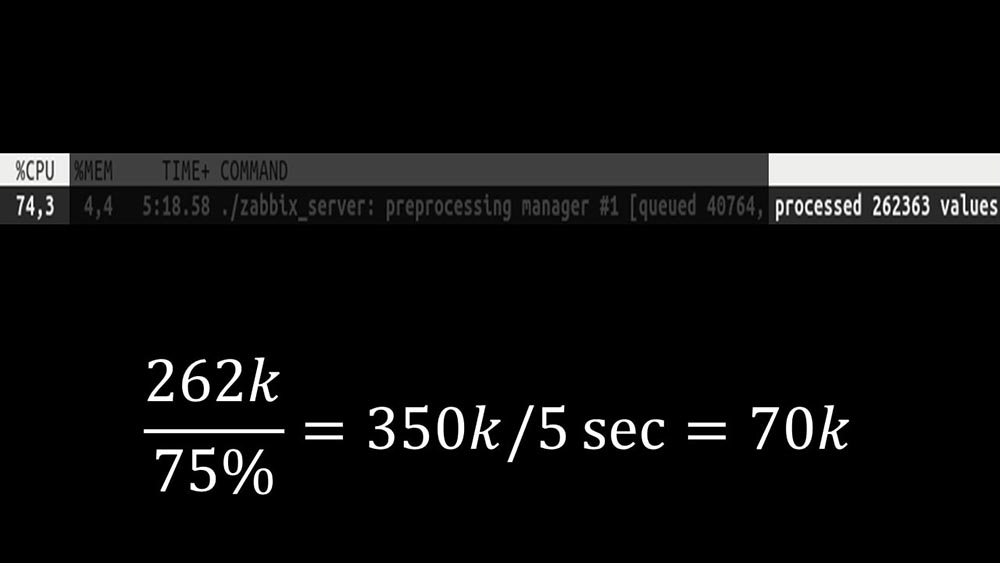 tanto, hicimos cuatro, con cuatro conjuntos de enchufes, trabajadores:
tanto, hicimos cuatro, con cuatro conjuntos de enchufes, trabajadores: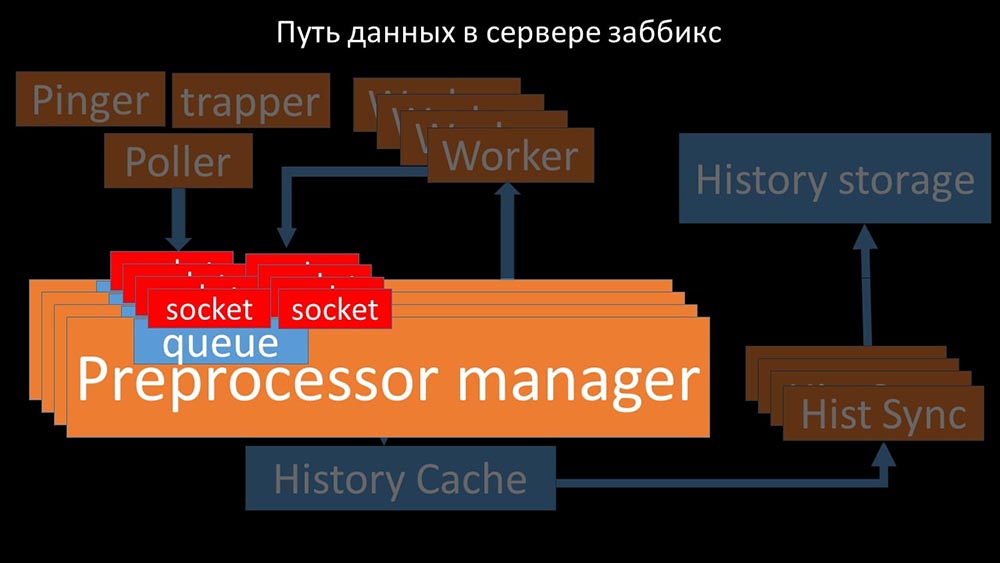 y esto nos permitió aumentar la velocidad a aproximadamente 130 mil métricas: la
y esto nos permitió aumentar la velocidad a aproximadamente 130 mil métricas: la no linealidad del crecimiento se explica por el hecho de que había competencia por el caché cuentos. Para él, compitieron 4 gerentes de preprocesadores y sincronizadores históricos. En este punto, recibimos aproximadamente 130 mil métricas por segundo en una máquina de prueba, utilizándolas en aproximadamente un 95% en el procesador: hace
no linealidad del crecimiento se explica por el hecho de que había competencia por el caché cuentos. Para él, compitieron 4 gerentes de preprocesadores y sincronizadores históricos. En este punto, recibimos aproximadamente 130 mil métricas por segundo en una máquina de prueba, utilizándolas en aproximadamente un 95% en el procesador: hace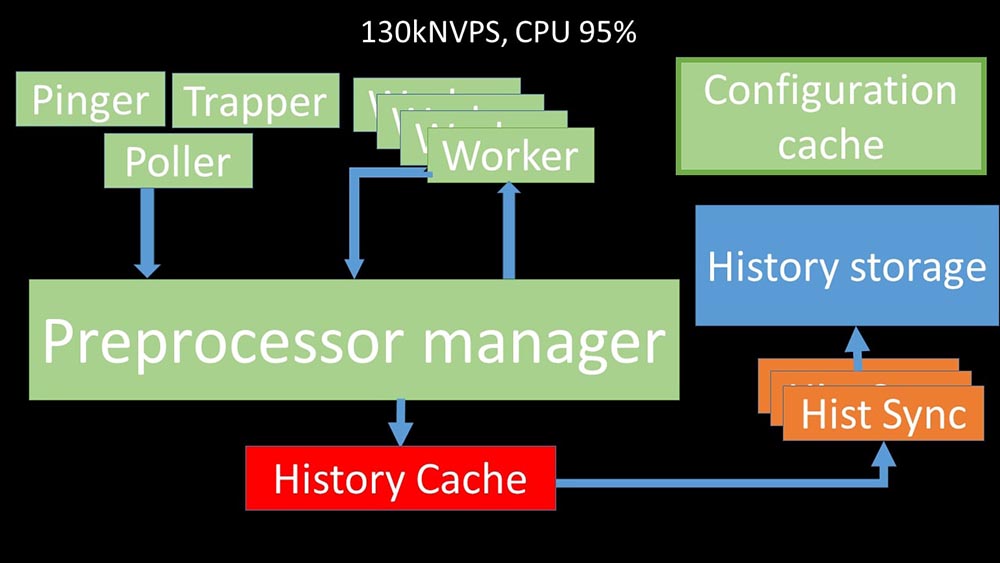 aproximadamente 2.5 meses
aproximadamente 2.5 mesesEl rechazo de la comunidad snmp aumentó los NVP una vez y media
MM: - Max, ¡necesito una nueva máquina de prueba! Ya no encajamos en el actual.MCH: - ¿Y qué es ahora?MM: - Ahora - 130k NVPs y un procesador "estante".MCH: - ¡Guau! ¡Frio! Espera, tengo dos preguntas. Según mis cálculos, nuestra necesidad está en la región de 15-20 mil métricas por segundo. ¿Por qué necesitamos más?MM: - Quiero terminar el trabajo hasta el final. Quiero ver cuánto podemos sacar de este sistema.MCH: - Pero ...MM: - Pero es inútil para los negocios.MCH: - Ya veo. Y la segunda pregunta: lo que tenemos ahora, ¿podemos apoyarnos sin la ayuda de un desarrollador?MM:- No creo. Cambiar la caché de configuración es un problema. Se ocupa de los cambios en la mayoría de los hilos y es difícil de mantener. Lo más probable es que apoyarla sea muy difícil.MCH: - Entonces necesitas algún tipo de alternativa.MM: - Existe tal opción. Podemos cambiar a núcleos rápidos, mientras abandonamos el nuevo sistema de bloqueo. Aún obtenemos el rendimiento de 60-80 mil métricas. En este caso, podemos dejar el resto del código. Clickhouse, el sondeo asíncrono funcionará. Y será fácil de mantener.MCH: ¡Genial! Propongo detenerme en esto.Después de optimizar el lado del servidor, finalmente pudimos ejecutar el nuevo código en el productivo. Abandonamos parte de los cambios a favor de cambiar a una máquina con núcleos rápidos y minimizar la cantidad de cambios en el código. También simplificamos la configuración y, si es posible, abandonamos las macros en los elementos de datos, ya que son la fuente de bloqueos adicionales. Por ejemplo, el rechazo de la macro snmp-community, que a menudo se encuentra en la documentación y los ejemplos, en nuestro caso nos permitió acelerar adicionalmente las NVP aproximadamente 1.5 veces.Después de dos días en producción.
Por ejemplo, el rechazo de la macro snmp-community, que a menudo se encuentra en la documentación y los ejemplos, en nuestro caso nos permitió acelerar adicionalmente las NVP aproximadamente 1.5 veces.Después de dos días en producción.Eliminar ventanas emergentes del historial de incidentes
MCH: - Misha, usamos el sistema durante dos días, y todo funciona. ¡Pero solo cuando todo funciona! Habíamos planeado trabajar con la transferencia de un segmento suficientemente grande de la red, y nuevamente con nuestras manos verificamos que había aumentado, que no lo había hecho.MM: - ¡No puede ser! Revisamos todo 10 veces. El servidor procesa incluso la inaccesibilidad completa de la red al instante.MCH: - Sí, entiendo todo: servidor, base, superior, austat, registros - todo es rápido ... Pero miramos la interfaz web, y ahí tenemos el procesador "en el estante" en el servidor y esto: MM: - Ya veo. Miremos la web. Descubrimos que en una situación en la que había una gran cantidad de incidentes activos, la mayoría de los widgets operativos comenzaron a funcionar muy lentamente:
MM: - Ya veo. Miremos la web. Descubrimos que en una situación en la que había una gran cantidad de incidentes activos, la mayoría de los widgets operativos comenzaron a funcionar muy lentamente: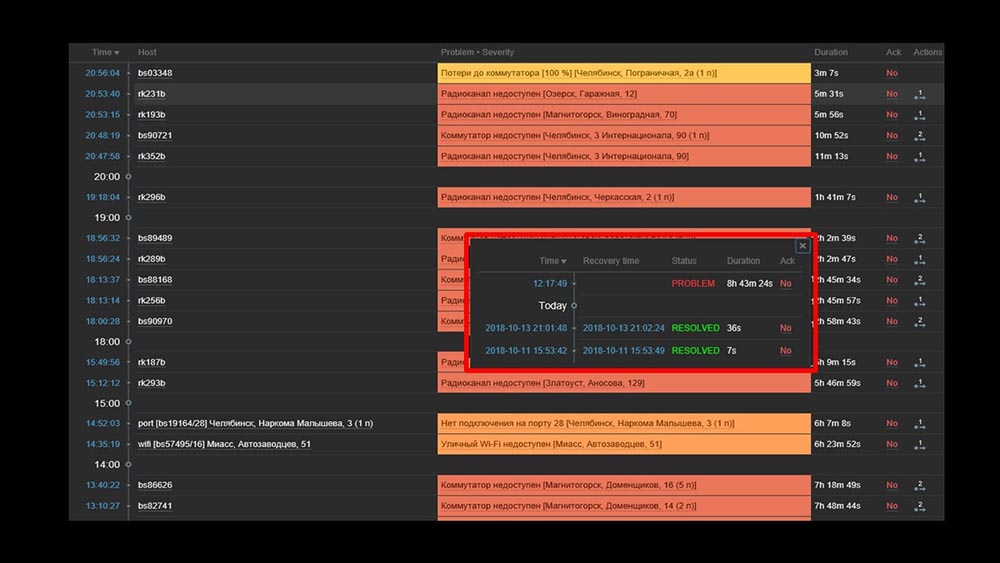 La razón de esto fue la generación de ventanas emergentes con un historial de incidentes que se generan para cada elemento de la lista. Por lo tanto, nos negamos a generar estas ventanas (comentamos 5 líneas en el código), y esto resolvió nuestros problemas.El tiempo de carga del widget, incluso cuando es completamente inaccesible, se redujo de unos pocos minutos a lo aceptable para nosotros de 10 a 15 segundos, y el historial aún se puede ver haciendo clic en el tiempo:
La razón de esto fue la generación de ventanas emergentes con un historial de incidentes que se generan para cada elemento de la lista. Por lo tanto, nos negamos a generar estas ventanas (comentamos 5 líneas en el código), y esto resolvió nuestros problemas.El tiempo de carga del widget, incluso cuando es completamente inaccesible, se redujo de unos pocos minutos a lo aceptable para nosotros de 10 a 15 segundos, y el historial aún se puede ver haciendo clic en el tiempo: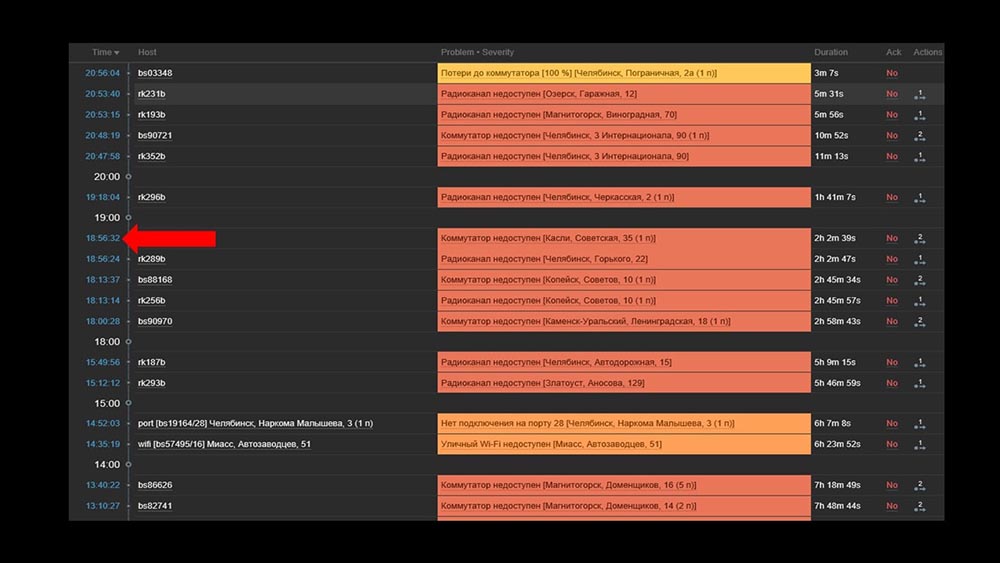 Después del trabajo. Hace 2 mesesMCH: - Misha, ¿te vas? Tenemos que hablar.MM: - No voy a hacerlo. ¿Otra vez algo con Zabbix?MCH: - ¡Oh no, relájate! Solo quería decir: todo funciona, ¡gracias! Cerveza conmigo.
Después del trabajo. Hace 2 mesesMCH: - Misha, ¿te vas? Tenemos que hablar.MM: - No voy a hacerlo. ¿Otra vez algo con Zabbix?MCH: - ¡Oh no, relájate! Solo quería decir: todo funciona, ¡gracias! Cerveza conmigo.Zabbix es efectivo
Zabbix es un sistema y una función bastante versátiles y ricos. Se puede utilizar para pequeñas instalaciones de fábrica, pero con el crecimiento de las necesidades, debe optimizarse. Para almacenar un gran archivo de métricas, use el almacenamiento apropiado:- Puede utilizar las herramientas integradas en forma de integración con Elastixerch o cargar el historial en archivos de texto (disponible desde la cuarta versión);
- Puede aprovechar nuestra experiencia e integración con Clickhouse.
Para aumentar drásticamente la velocidad de recopilación de métricas, recójalas de forma asíncrona y transfiéralas a través de la interfaz de trapper al servidor Zabbix; o puede usar el parche para los buscadores asíncronos de Zabbix.Zabbix está escrito en C y es bastante efectivo. La solución de varios lugares arquitectónicos estrechos permite aumentar aún más su productividad y, en nuestra experiencia, recibir más de 100 mil métricas en una máquina de un solo procesador.
El mismo parche de Zabbix
MM: - Quiero agregar un par de puntos. El informe actual completo, todas las pruebas, los números se dan para la configuración que se utiliza con nosotros. Ahora estamos tomando alrededor de 20 mil métricas por segundo. Si está tratando de entender si esto funcionará para usted, puede comparar. Lo que hablaron hoy está publicado en GitHub como un parche: github.com/miklert/zabbix El parche incluye:
El parche incluye:- integración completa con Clickhouse (servidor Zabbix y frontend);
- resolver problemas con el administrador del preprocesador;
- sondeo asincrónico.
El parche es compatible con todas las versiones 4, incluidos los lts. Lo más probable, con cambios mínimos, funcionará en la versión 3.4.Gracias por la atención.Preguntas
Pregunta de la audiencia (en adelante - A): - ¡Buenas tardes! Dígame, ¿tiene planes para una interacción intensiva con el equipo de Zabbix o tienen ellos con usted para que esto no sea un parche, sino el comportamiento normal de Zabbix?MM: - Sí, ciertamente comprometeremos parte de los cambios. Algo será, algo quedará en el parche.R: Muchas gracias por el excelente informe. Dígame, por favor, después de aplicar el parche, el soporte del lado de Zabbix permanecerá y ¿cómo continuar actualizando a versiones superiores? ¿Será posible actualizar Zabbix después de su parche a 4.2, 5.0?MM:- No puedo decir sobre el soporte. Si yo fuera el soporte técnico de Zabbix, probablemente diría que no, porque este es el código de otra persona. En cuanto a la base de código 4.2, nuestra posición es esta: "Iremos con el tiempo, y seremos actualizados en la próxima versión". Por lo tanto, durante algún tiempo cargaremos el parche en versiones actualizadas. Ya dije en el informe: el número de cambios con las versiones todavía es bastante pequeño. Creo que la transición de 3.4 a 4 nos llevó, al parecer, unos 15 minutos. Algo ha cambiado allí, pero no es muy importante.R: - ¿Entonces planea mantener su parche y puede ponerlo en producción de manera segura, en el futuro recibiendo actualizaciones de alguna manera?MM: - Lo recomendamos encarecidamente. Esto nos resuelve muchos problemas.MCH:- Una vez más, me gustaría enfatizar que los cambios que no se relacionan con la arquitectura y no se relacionan con bloqueos, colas, son modulares, están en módulos separados. Incluso por sí solos con cambios menores, se pueden mantener con bastante facilidad.MM: - Si los detalles son interesantes, entonces "Clickhouse" utiliza la llamada biblioteca de historial. No está vinculado: esta es una copia del soporte de Elastic, es decir, es configurable. El sondeo solo cambia a los encuestadores. Creemos que esto funcionará durante mucho tiempo.A: Muchas gracias. Pero dime, ¿hay alguna documentación de los cambios realizados? MM:- La documentación es un parche. Obviamente, con la introducción de "Clickhouse", con la introducción de nuevos tipos de sondeos, surgen nuevas opciones de configuración. El enlace de la última diapositiva tiene una breve descripción de cómo usarlo.
MM:- La documentación es un parche. Obviamente, con la introducción de "Clickhouse", con la introducción de nuevos tipos de sondeos, surgen nuevas opciones de configuración. El enlace de la última diapositiva tiene una breve descripción de cómo usarlo.Acerca de reemplazar fping con nmap
A: - ¿Cómo finalmente implementaste esto? ¿Puedes dar ejemplos específicos: son tus tirantes y un script externo? ¿Qué es lo que finalmente verifica tantos hosts tan rápidamente? ¿Cómo se obtienen estos hosts? ¿Nmap necesita alimentarlos de alguna manera, obtenerlos de alguna parte, ponerlos, comenzar algo? ...MM:- Frio. Pregunta muy correcta! El punto es este. Modificamos la biblioteca (ping ICMP, parte de Zabbix) para verificaciones ICMP, que indican el número de paquetes - unidad (1), y el código intenta usar nmap. Es decir, este es el trabajo interno de Zabbix, se ha convertido en el trabajo interno del pinger. En consecuencia, no se requiere sincronización o uso de un trampero. Esto se hizo deliberadamente para dejar el sistema coherente y no participar en la sincronización de dos sistemas básicos: qué verificar, completar a través del sondeo y si el relleno se ha roto en nosotros? Esto es mucho más simple.A: - ¿Funciona también para un proxy?MM: - Sí, pero no lo comprobamos. El código de sondeo es el mismo tanto en Zabbix como en el servidor. Deberia trabajar. Destaco nuevamente: el rendimiento del sistema es tal que no necesitamos un proxy.MCH: - La respuesta correcta a la pregunta es: "¿Por qué necesita un proxy con dicho sistema?" Solo por NAT'a o para monitorear a través de un canal lento algunos ...R: - Y usas Zabbix como alérgeno, si lo entiendo correctamente. ¿O los gráficos (dónde está la capa de archivo) que dejó para otro sistema, como Grafana? ¿O no estás usando esta funcionalidad?MM: - Lo enfatizaré una vez más: hemos hecho una integración total. Vertimos la historia en "Clickhouse", pero al mismo tiempo cambiamos la interfaz php. Php-frontend va a "Clickhouse" y hace todos los gráficos desde allí. Al mismo tiempo, para ser honesto, tenemos una parte que se construye a partir del mismo "Clickhouse", a partir de los mismos datos de Zabbix, datos en otros sistemas de visualización gráfica.MCH: - En "Grafan" también.¿Cómo se tomó la decisión de asignar recursos?
A: - Comparte un poco de cocina interior. ¿Cómo se tomó la decisión de asignar recursos para el procesamiento serio del producto? Estos son, en general, ciertos riesgos. Y dígame, en el contexto del hecho de que va a admitir nuevas versiones: ¿cómo se justifica esta decisión desde el punto de vista de la administración?MM: - Aparentemente, no contamos muy bien el drama de la historia. Nos encontramos en una situación en la que había que hacer algo, y seguimos esencialmente dos comandos paralelos:- Uno estaba involucrado en el lanzamiento de un sistema de monitoreo utilizando nuevos métodos: monitoreo como servicio, un conjunto estándar de soluciones de código abierto que combinamos y luego intentamos cambiar el proceso comercial para trabajar con el nuevo sistema de monitoreo.
- Paralelamente, tuvimos un programador entusiasta que estaba haciendo esto (sobre sí mismo). Dio la casualidad de que ganó.
A: - ¿Y cuál es el tamaño del equipo?MCH: - Ella está frente a ti.A: - Es decir, como siempre, ¿se necesita un apasionado?MM: - No sé lo que es un apasionado.A: - En este caso, aparentemente, usted. Muchas gracias, eres genial.MM: Gracias.Sobre parches para Zabbix
R: - Para un sistema que usa proxies (por ejemplo, en algunos sistemas distribuidos), ¿es posible que usted decida adaptar y parchear, por ejemplo, sondeos, proxies y parcialmente el preprocesador del propio Zabbix; y su interacción? ¿Es posible optimizar los desarrollos existentes para un sistema con múltiples servidores proxy?MM: - Sé que el servidor Zabbix se ensambla utilizando un proxy (se compila y se obtiene el código). No probamos esto en el producto. No estoy seguro de esto, pero, en mi opinión, el administrador del preprocesador no se usa en el proxy. La tarea del proxy es tomar un conjunto de métricas de Zabbix, completarlas (también escribe la configuración, la base de datos local) y devolverlo al servidor de Zabbix. Luego, el servidor mismo realizará el preprocesamiento cuando lo reciba.El interés por los poderes es comprensible. Verificaremos esto. Este es un tema interesante.R: - La idea era esta: si puede parchear los pollers, se pueden parchear en proxies e parchear la interacción con el servidor, y el preprocesador se puede adaptar para estos propósitos solo en el servidor.MM: Creo que todo es aún más simple. Usted toma el código, aplica el parche, luego lo configura según lo necesite: recopile los servidores proxy (por ejemplo, con ODBC) y distribuya el código parcheado a los sistemas. Donde sea necesario: recopile proxies, donde sea necesario: servidor.R: - Además, ¿no tendrá que parchear la transmisión del proxy al servidor, lo más probable?MCH: - No, es estándar.MM:- En realidad, una de las ideas no sonó. Siempre mantuvimos un equilibrio entre una explosión de ideas y la cantidad de cambios, la facilidad de soporte.Un poco de publicidad :)
Gracias por estar con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes? Apóyenos haciendo un pedido o recomendando a sus amigos VPS basado en la nube para desarrolladores desde $ 4.99 , un análogo único de servidores de nivel básico que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2697 v3 (6 núcleos) 10GB DDR4 480GB SSD 1Gbps desde $ 19 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).Dell R730xd 2 veces más barato en el centro de datos Equinix Tier IV en Amsterdam? ¡Solo tenemos 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV desde $ 199 en los Países Bajos!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - ¡desde $ 99! Lea sobre Cómo construir un edificio de infraestructura. clase c con servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo? Source: https://habr.com/ru/post/undefined/
All Articles