En un artículo anterior, examinamos el mecanismo de atención, un método extremadamente común en los modelos modernos de aprendizaje profundo que puede mejorar los indicadores de rendimiento de las aplicaciones de traducción automática neural. En este artículo, veremos Transformer, un modelo que utiliza el mecanismo de atención para aumentar la velocidad de aprendizaje. Además, para una serie de tareas, los transformadores superan el modelo de traducción automática neuronal de Google. Sin embargo, la mayor ventaja de los transformadores es su alta eficiencia en condiciones de paralelización. Incluso Google Cloud recomienda usar Transformer como modelo cuando se trabaja en Cloud TPU . Intentemos averiguar en qué consiste el modelo y qué funciones realiza.
El modelo Transformer se propuso por primera vez en el artículo Atención es todo lo que necesita . Una implementación en TensorFlow está disponible como parte del paquete Tensor2Tensor , además, un grupo de investigadores de PNL de Harvard creó una anotación guía del artículo con una implementación en PyTorch . En esta misma guía, trataremos de enunciar de manera más simple y consistente las ideas y conceptos principales, lo cual, esperamos, ayudará a las personas que no tienen un conocimiento profundo del área temática a comprender este modelo.
Revisión de alto nivel
Veamos el modelo como una especie de caja negra. En las aplicaciones de traducción automática, acepta una oración en un idioma como entrada y muestra una oración en otro.

, , , .
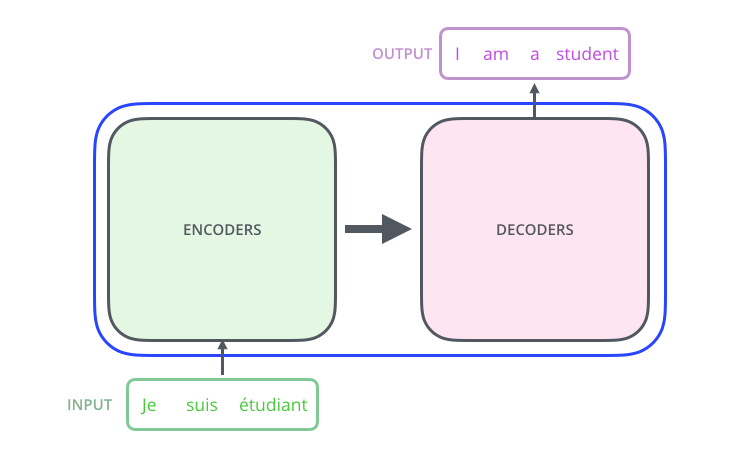
– ; 6 , ( 6 , ). – , .
, . :
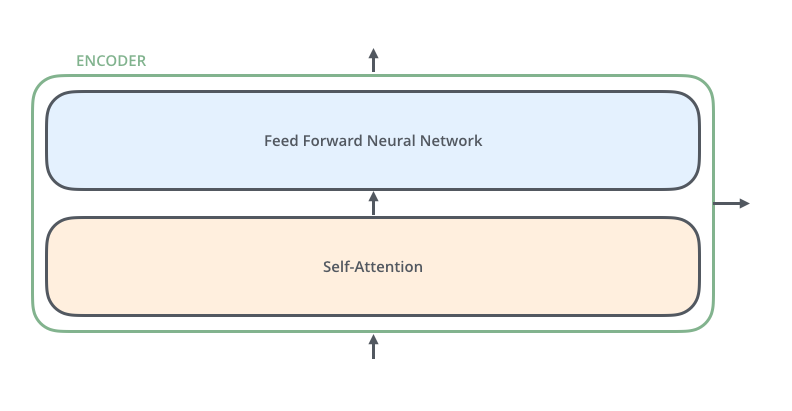
, , (self-attention), . .
(feed-forward neural network). .
, , ( , seq2seq).
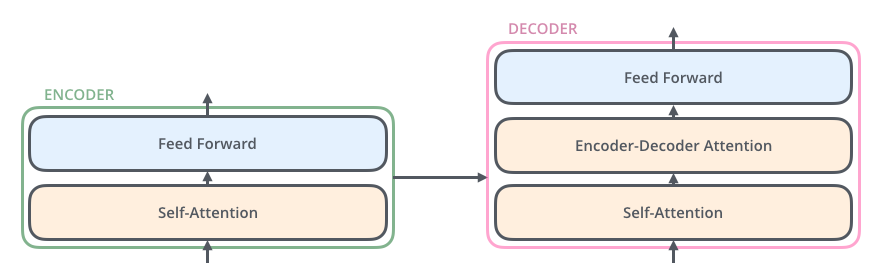
, , /, , .
NLP-, , , (word embeddings).

512. .
. , , : 512 ( , – ). , , , , .
, .
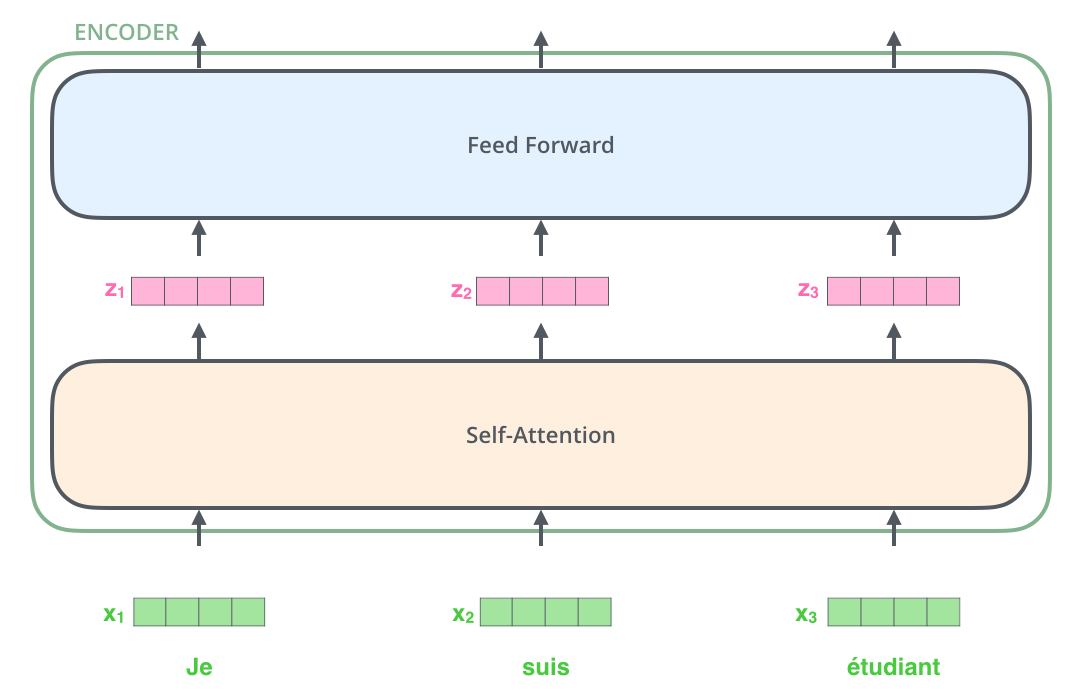
: . , , , .
, .
!
, , – , , , .
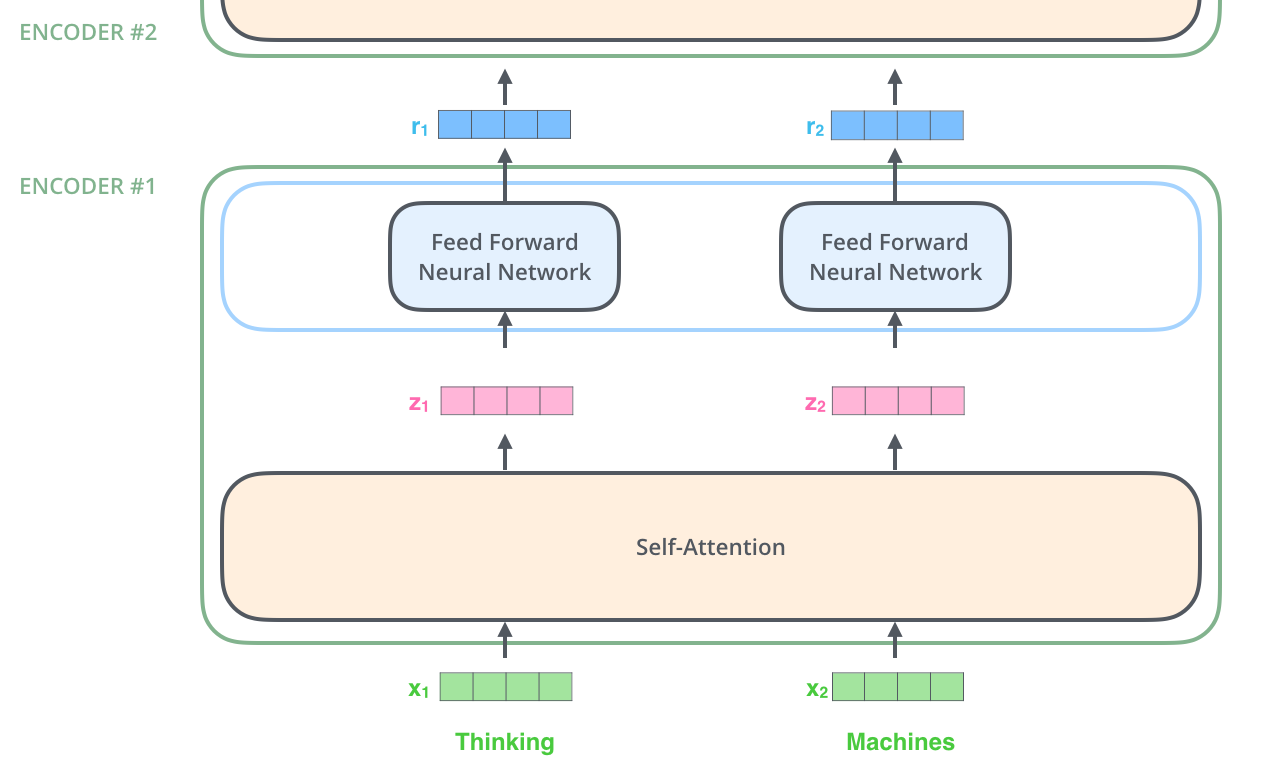
. , .
, « » -, . , «Attention is All You Need». , .
– , :
”The animal didn't cross the street because it was too tired”
«it» ? (street) (animal)? .
«it», , «it» «animal».
( ), , .
(RNN), , RNN /, , . – , , «» .

«it» #5 ( ), «The animal» «it».
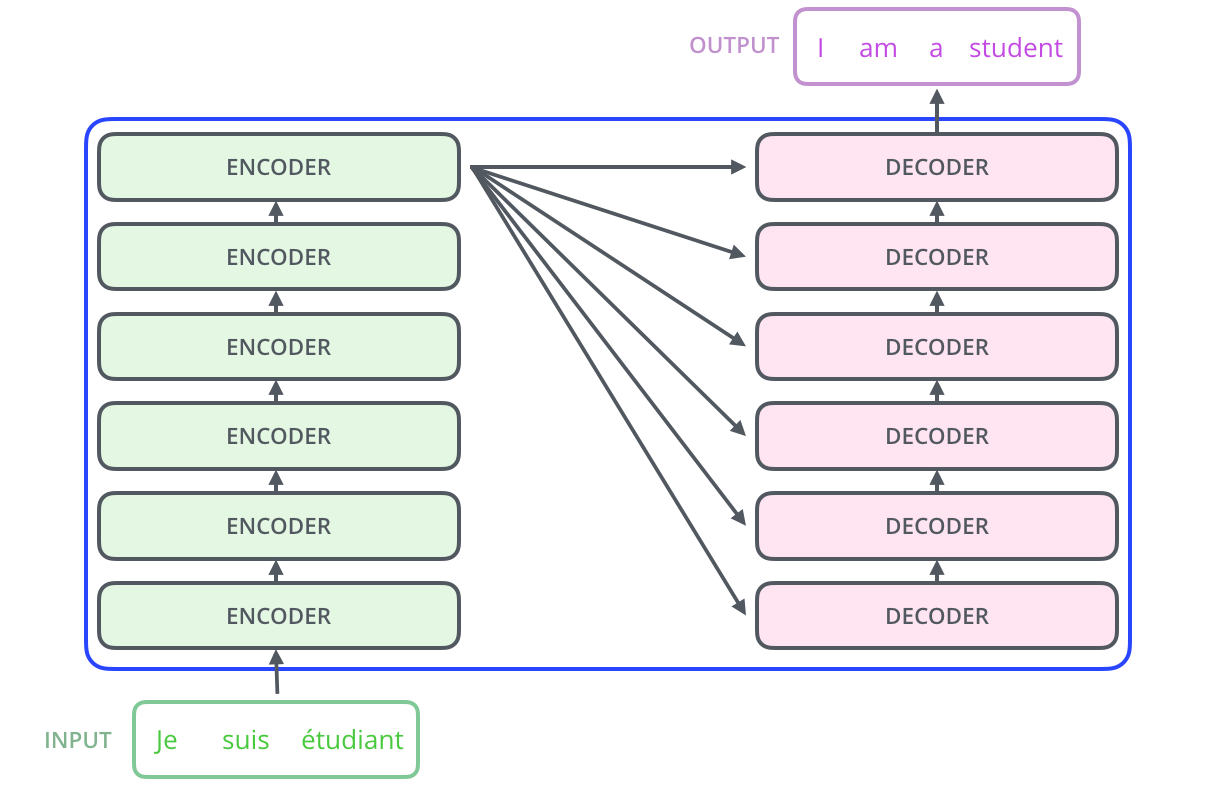
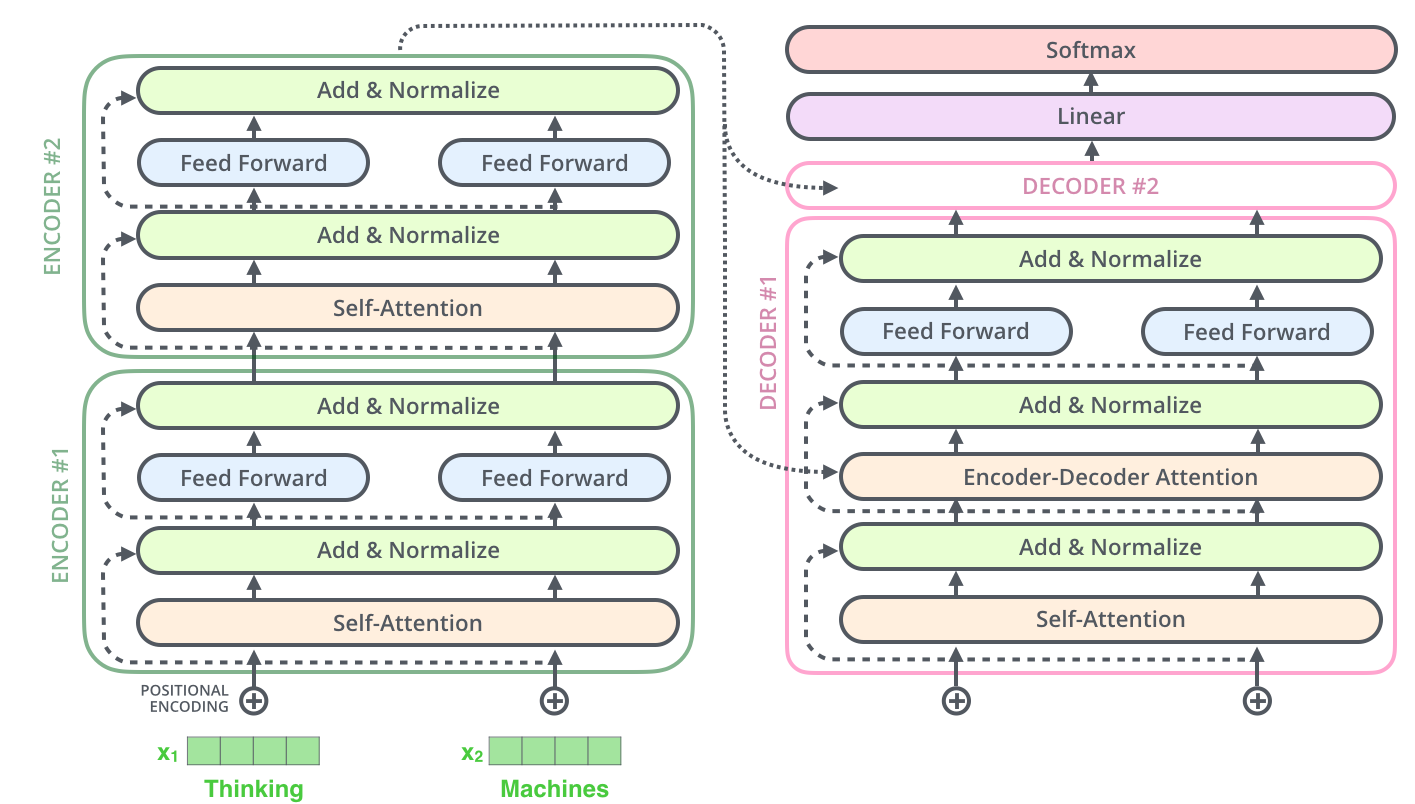
Tensor2Tensor, , .
, , , .
– ( – ): (Query vector), (Key vector) (Value vector). , .
, , . 64, / 512. , (multi-head attention) .
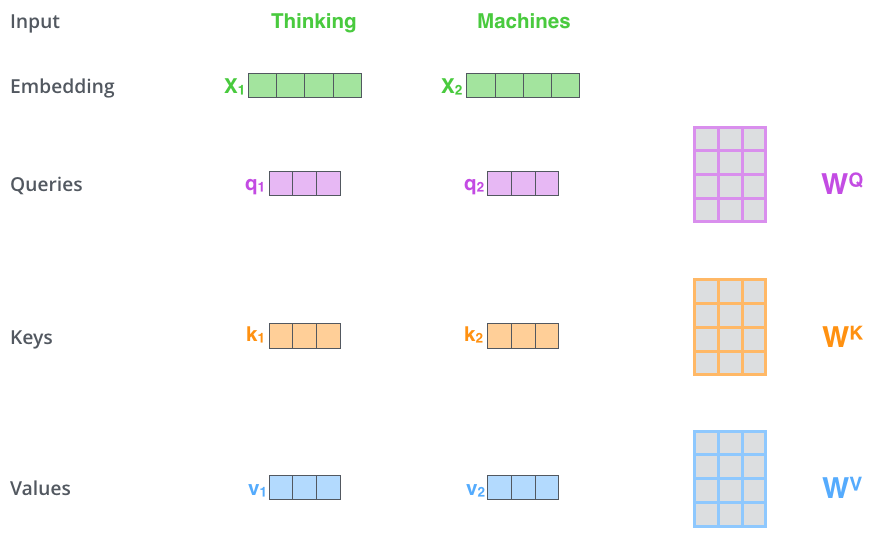
x1 WQ q1, «», . «», «» «» .
«», «» «»?
, . , , , .
– (score). , – «Thinking». . , .
. , #1, q1 k1, — q1 k2.
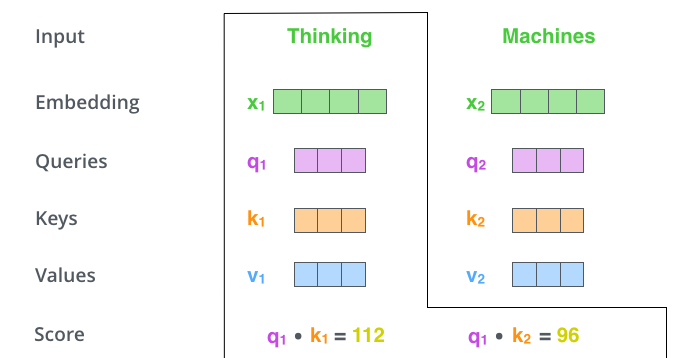
– 8 ( , – 64; , ), (softmax). , 1.
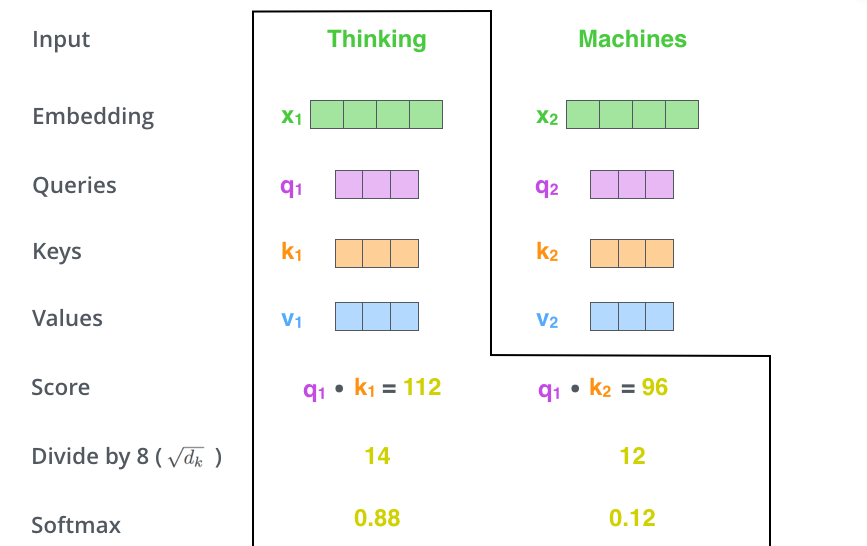
- (softmax score) , . , -, , .
– - ( ). : , , ( , , 0.001).
– . ( ).
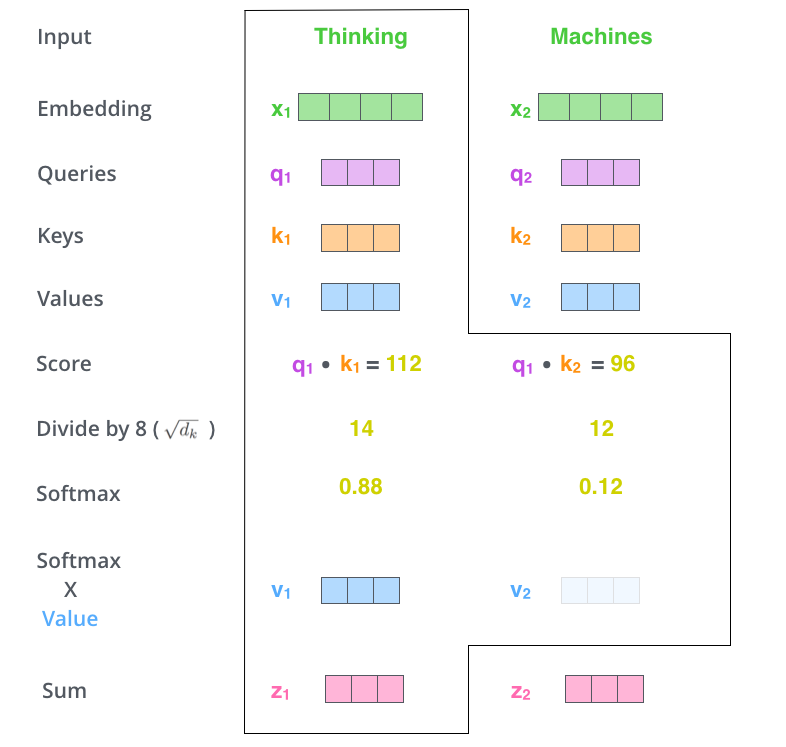
. , . , , . , , .
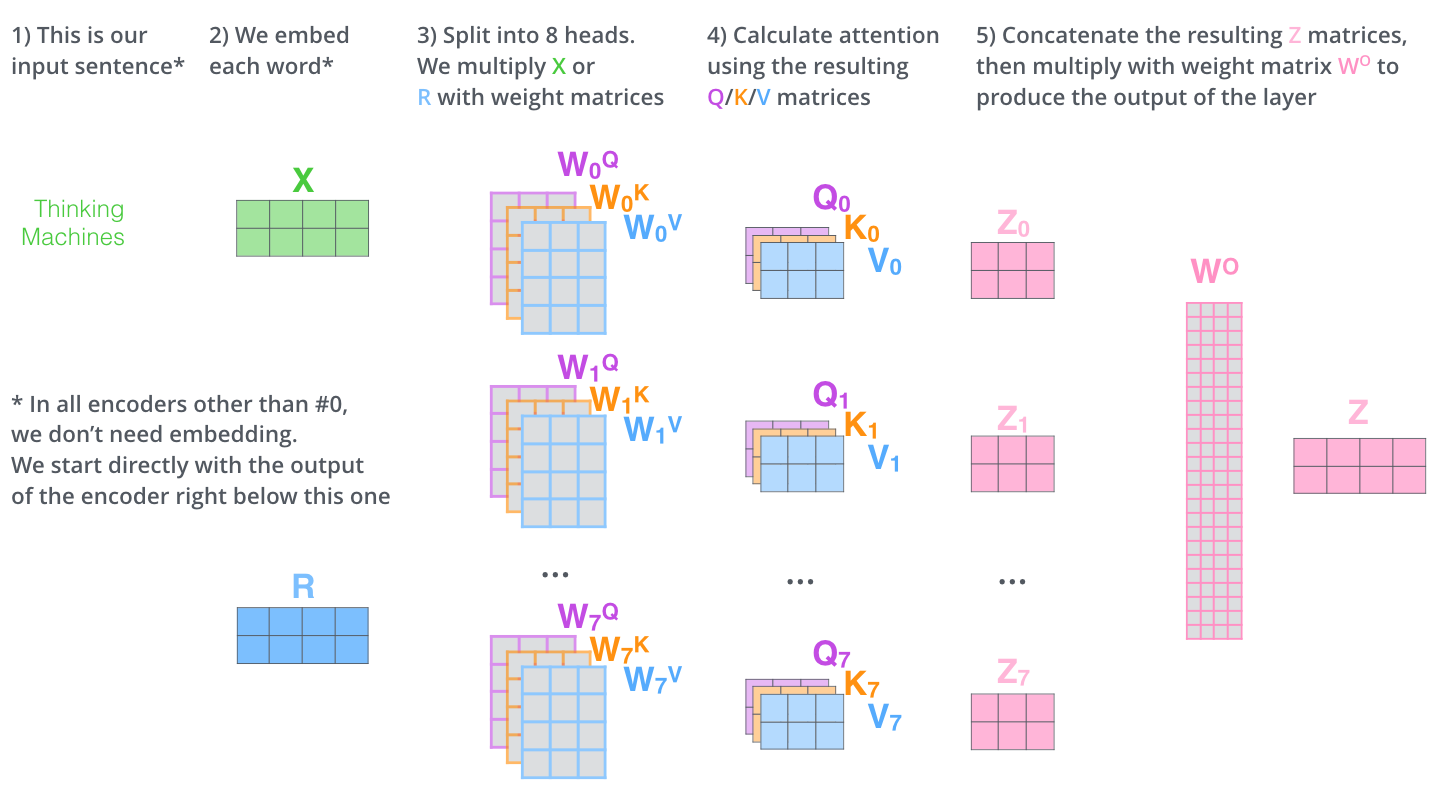
– , . X , (WQ, WK, WV).

. (512, 4 ) q/k/v (64, 3 ).
, , 2-6 .
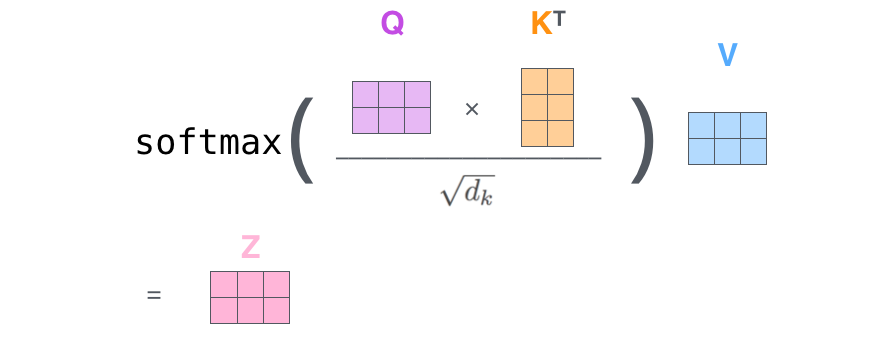
.
, (multi-head attention). :
- . , , z1 , . «The animal didn’t cross the street because it was too tired», , «it».
- « » (representation subspaces). , , // ( 8 «» , 8 /). . ( /) .
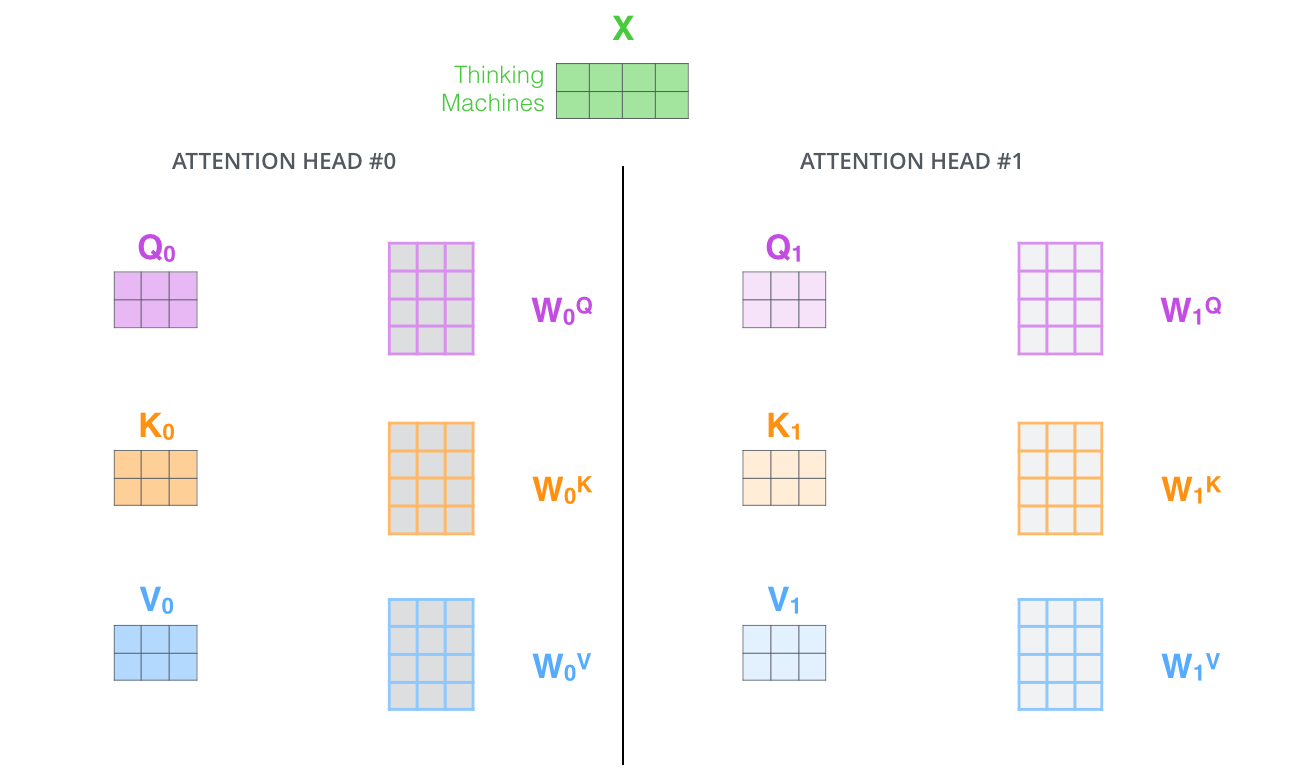
, WQ/WK/WV «», Q/K/V . , WQ/WK/WV Q/K/V .
, , 8 , 8 Z .
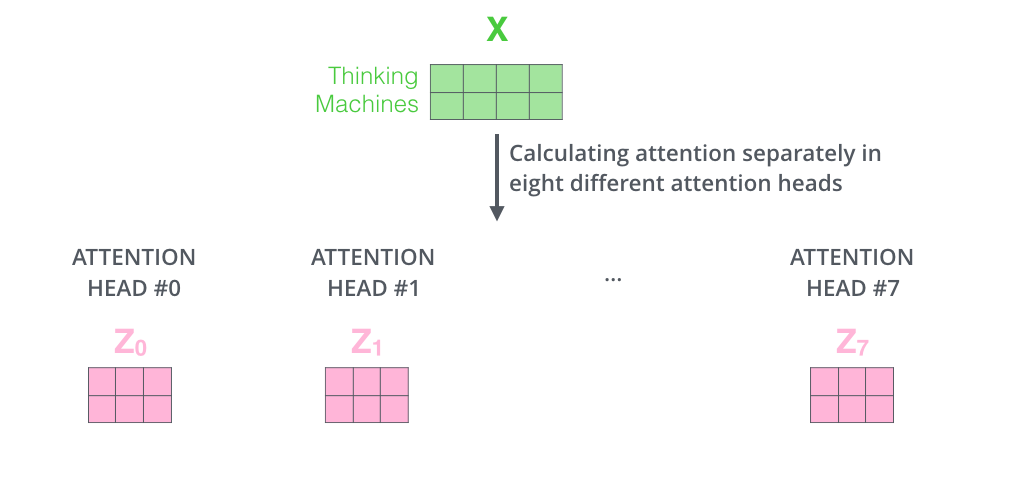
. , 8 – ( ), Z .
? WO.
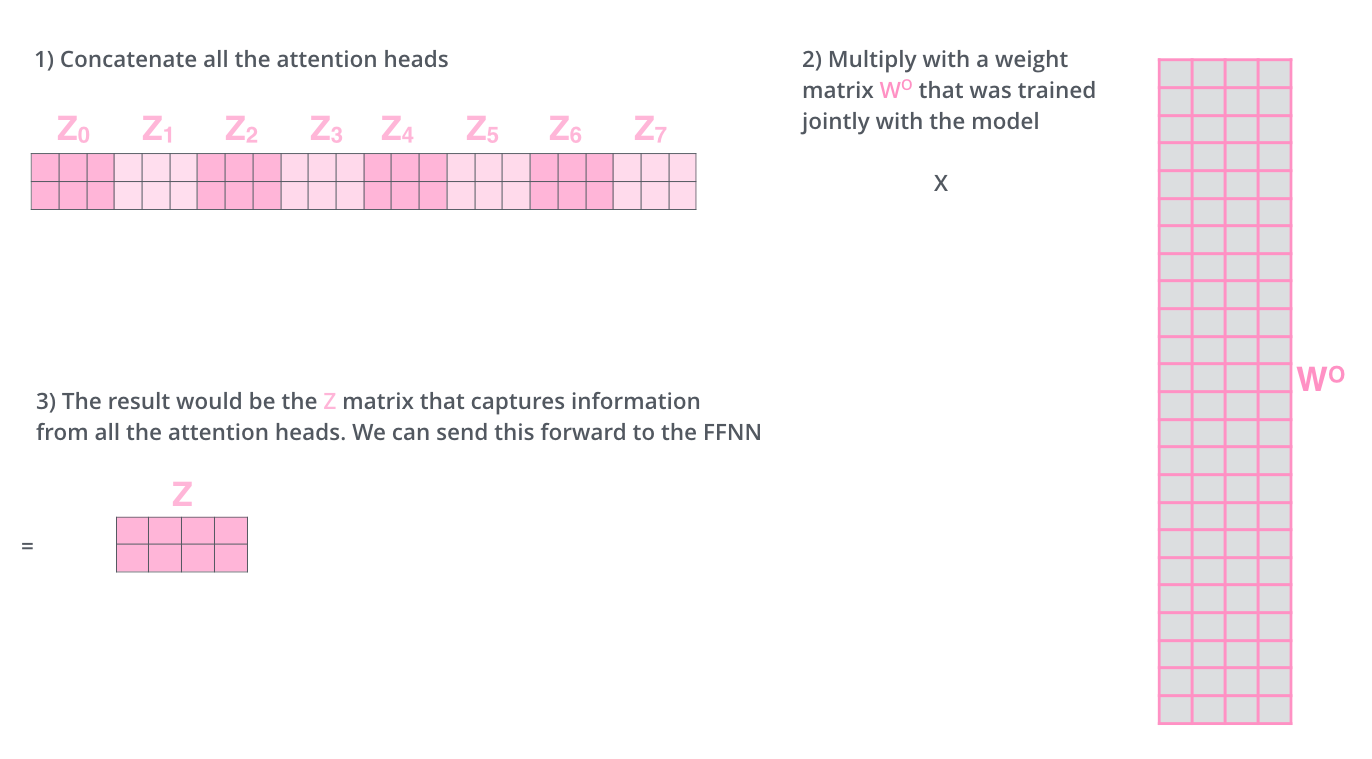
, , . , . , .
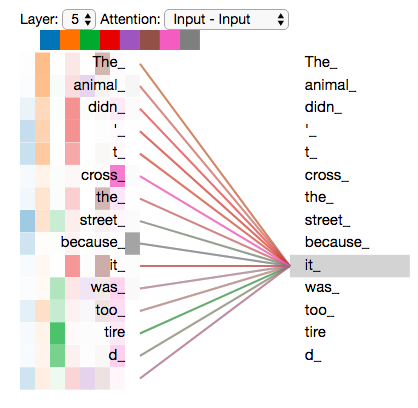
, «» , , , «» «it» :

«it», «» «the animal», — «tired». , «it» «animal» «tired».
«» , , .
— .
. , . , Q/K/V .
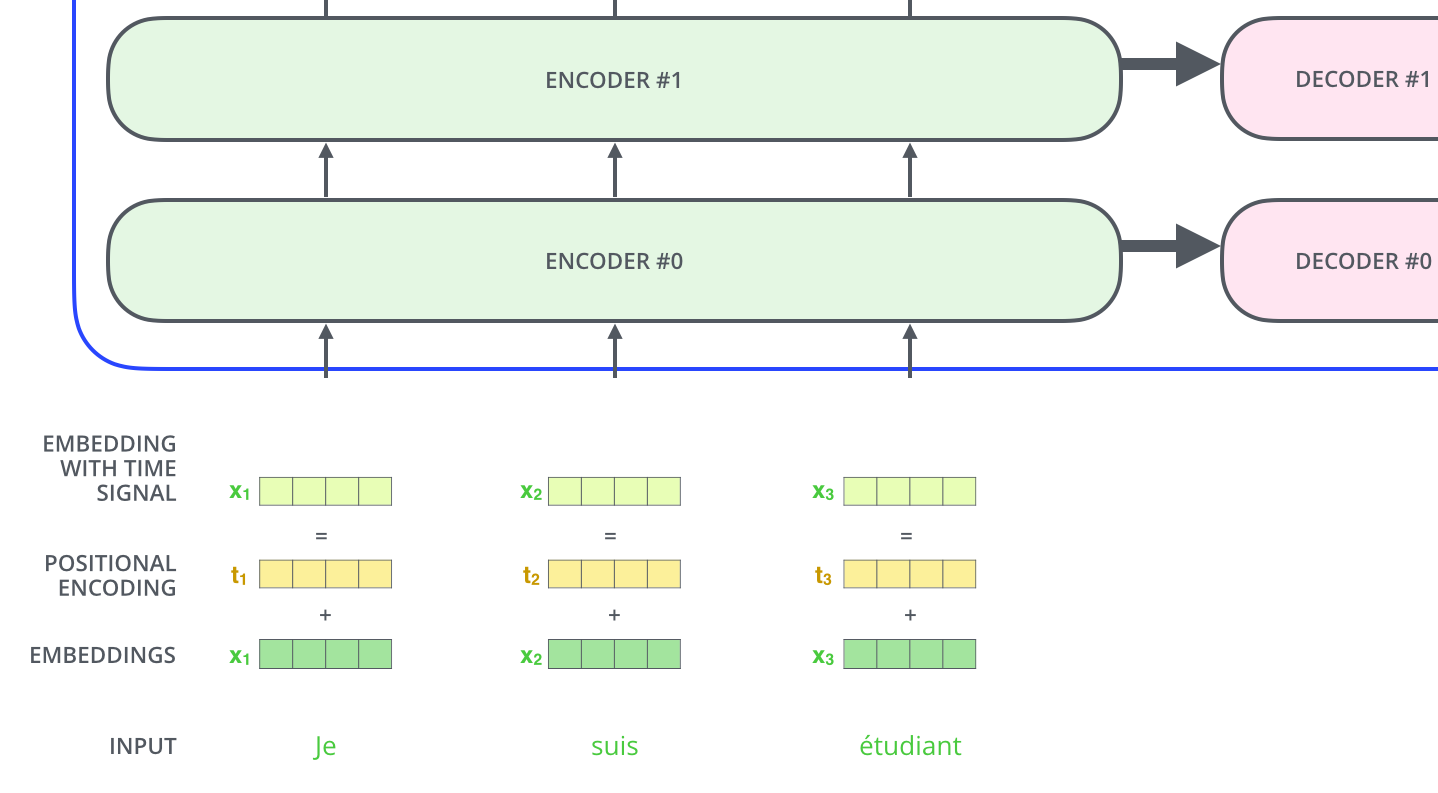
, , , .
, 4, :
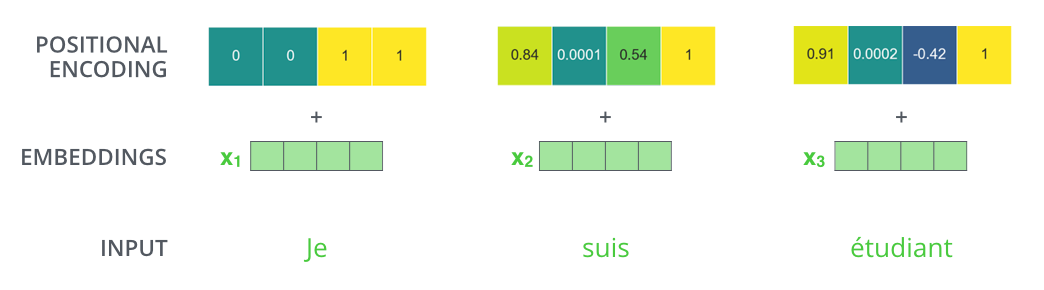
?
: , , , — .. 512 -1 1. , .
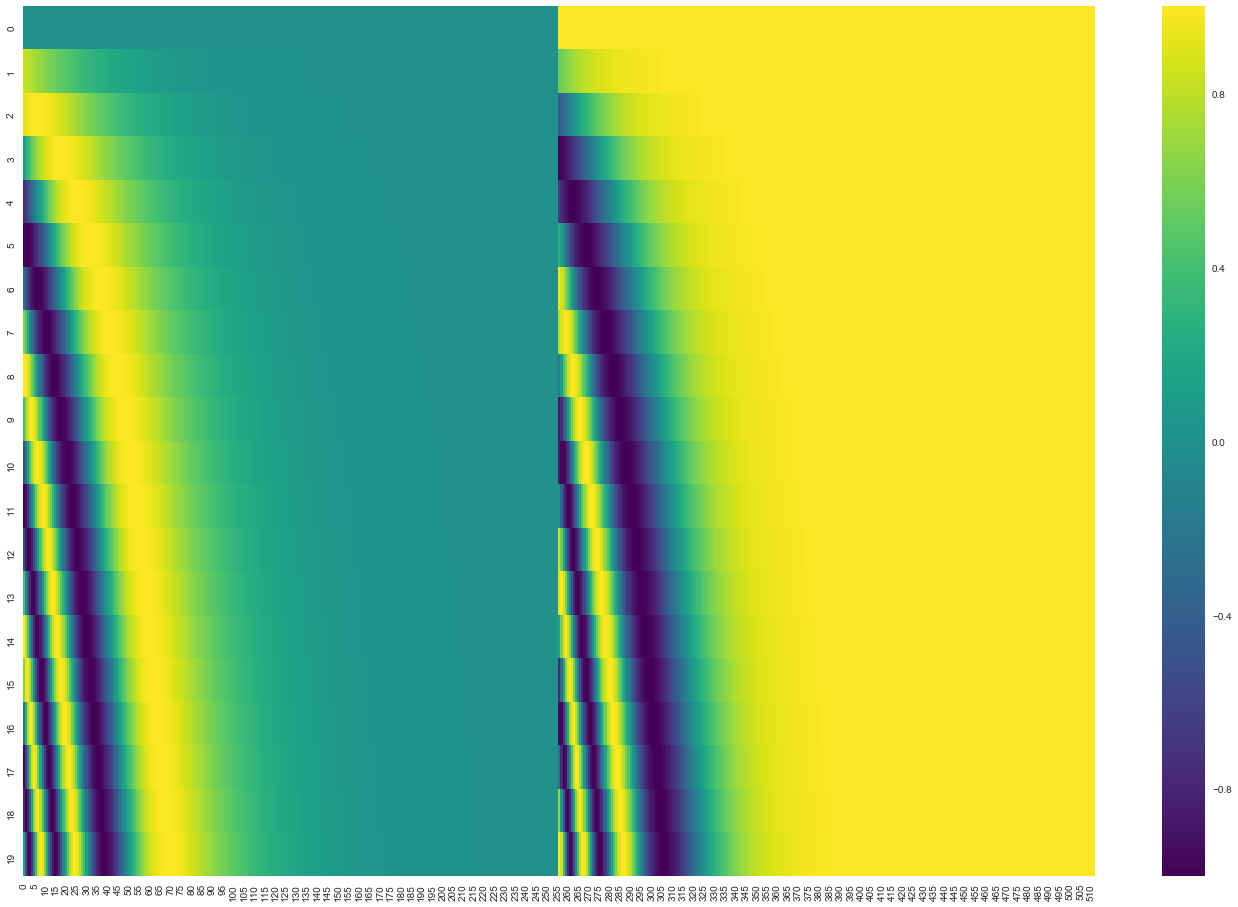
20 () 512 (). , : ( ), – ( ). .
( 3.5). get_timing_signal_1d(). , , (, , , ).
, , , , ( , ) , (layer-normalization step).
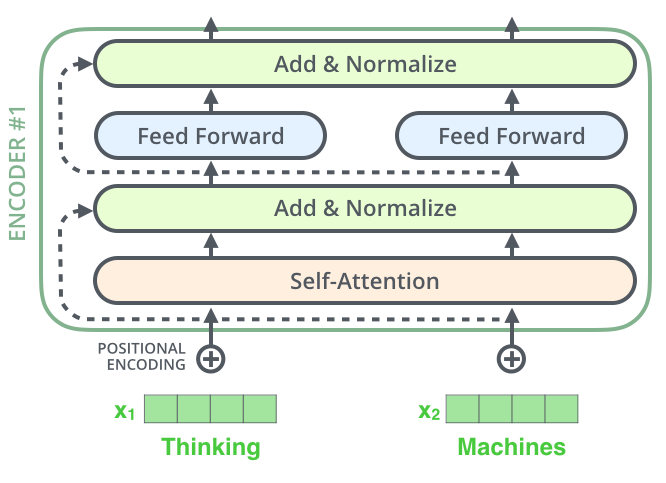
, , :
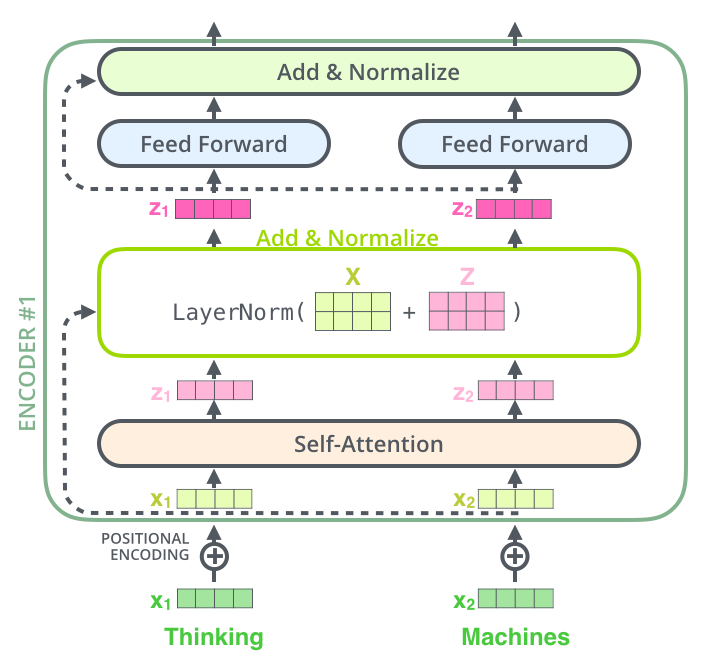
. , :
, , , . , .
. K V. «-» , :
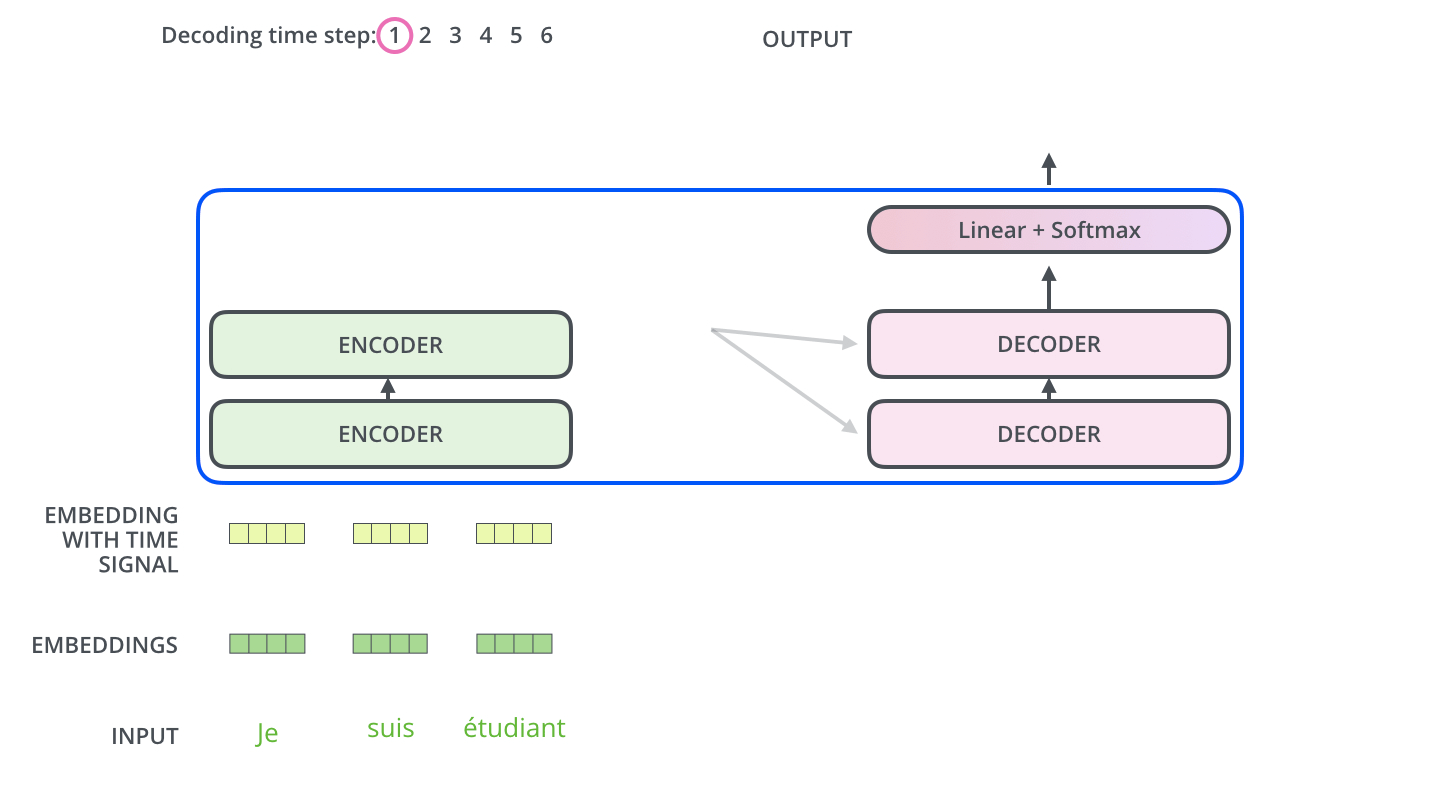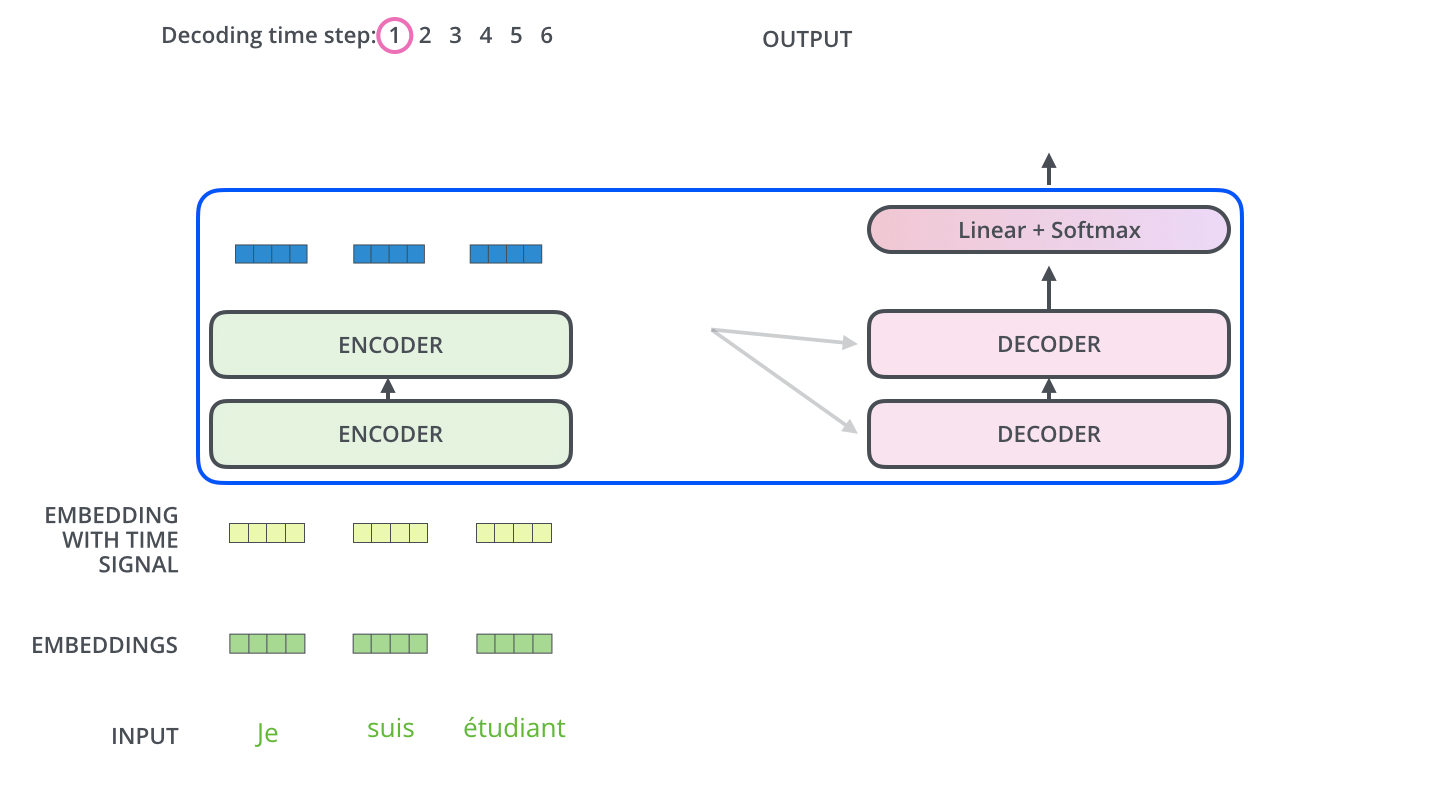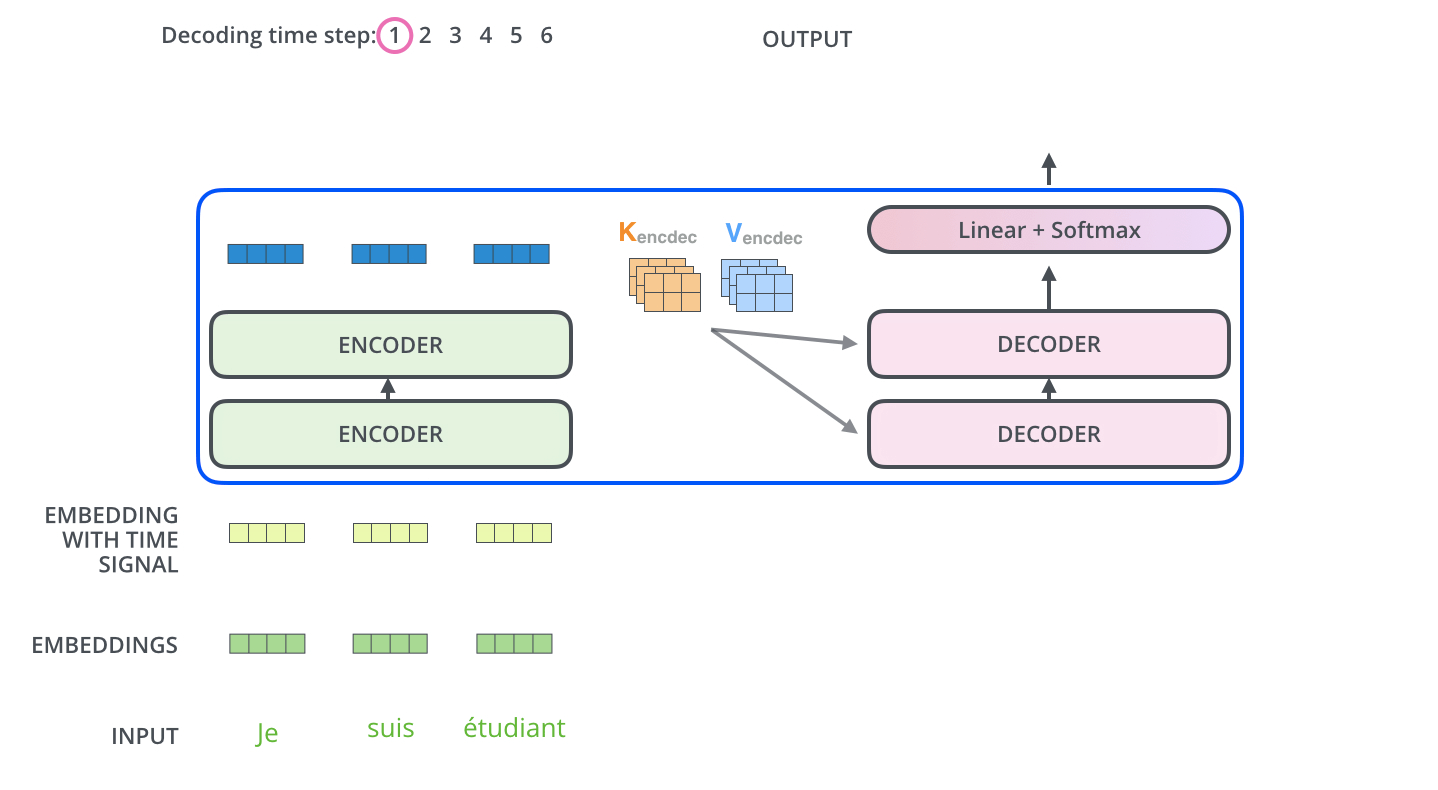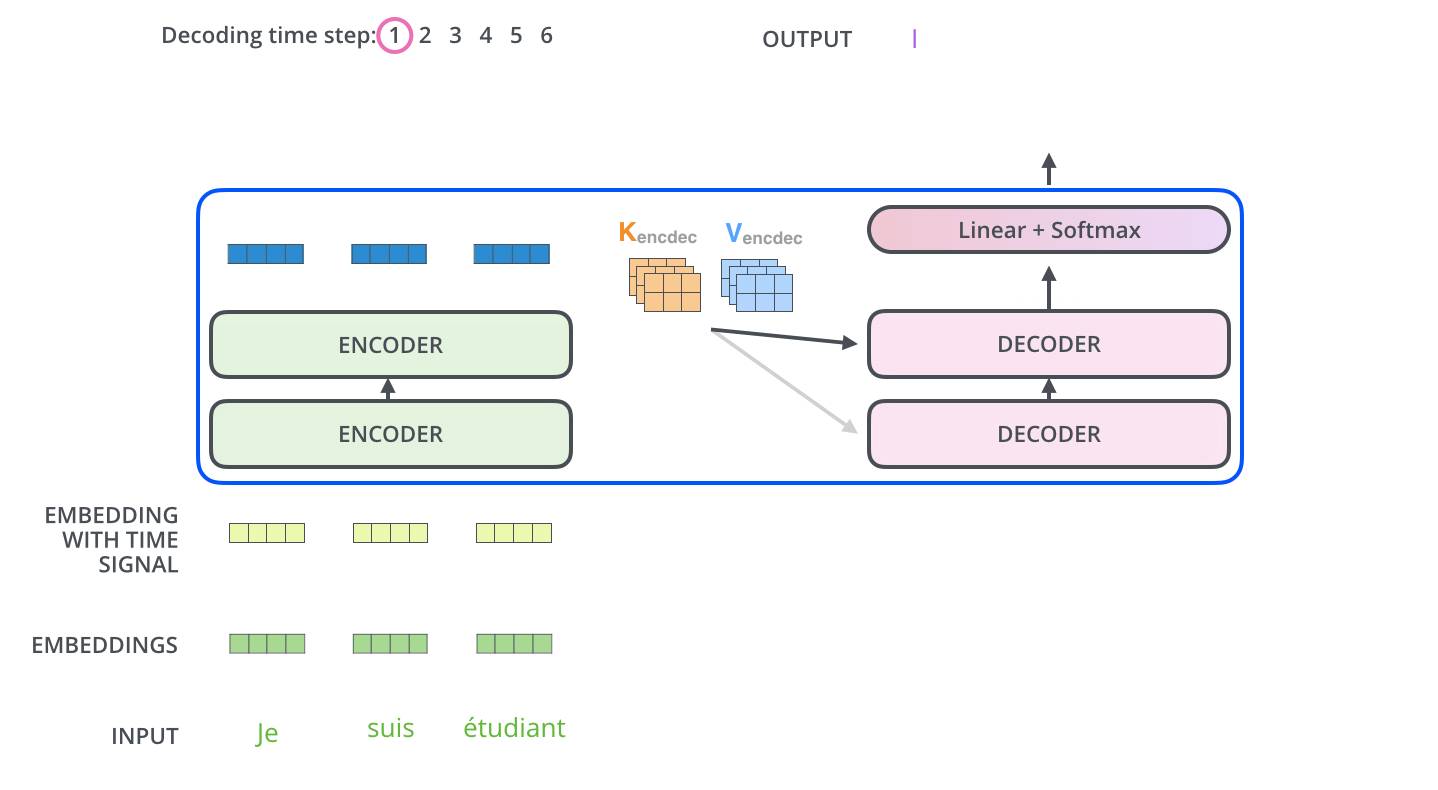
. ( – ).
, , . , , . , , , .
.
. ( –inf) .
«-» , , , , .
. ? .
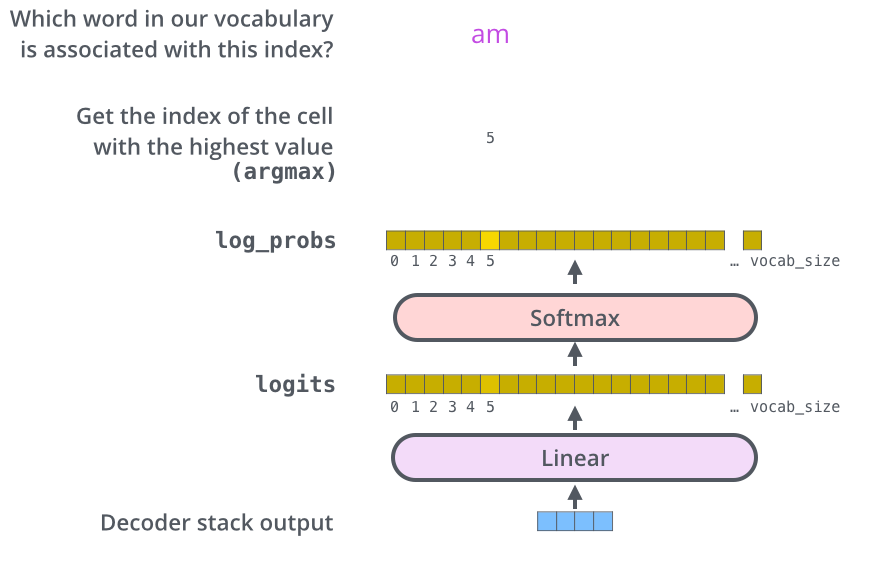
– , , , , (logits vector).
10 (« » ), . , 10 000 – . .
( , 1). .
, , .
, , , , .
, . .. , .
, 6 («a», «am», «i», «thanks», «student» «<eos>» (« »).
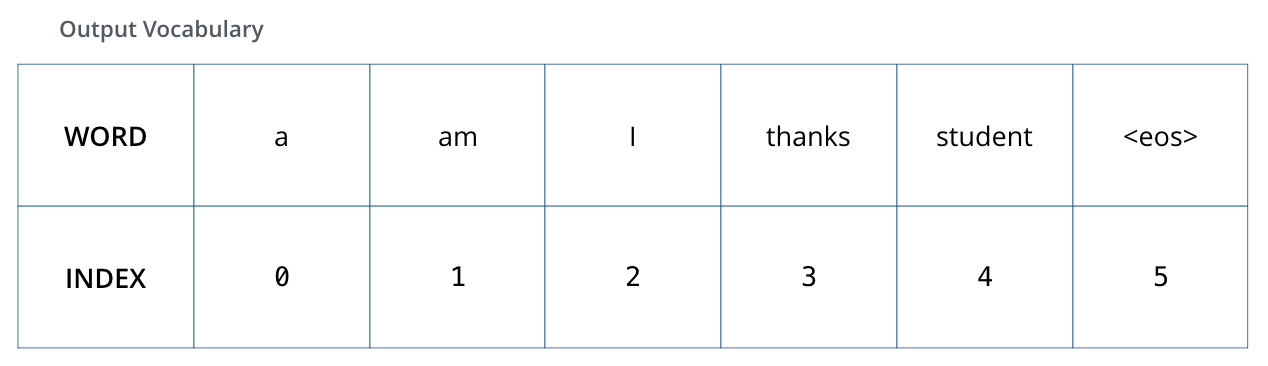
.
, (, one-hot-). , «am», :
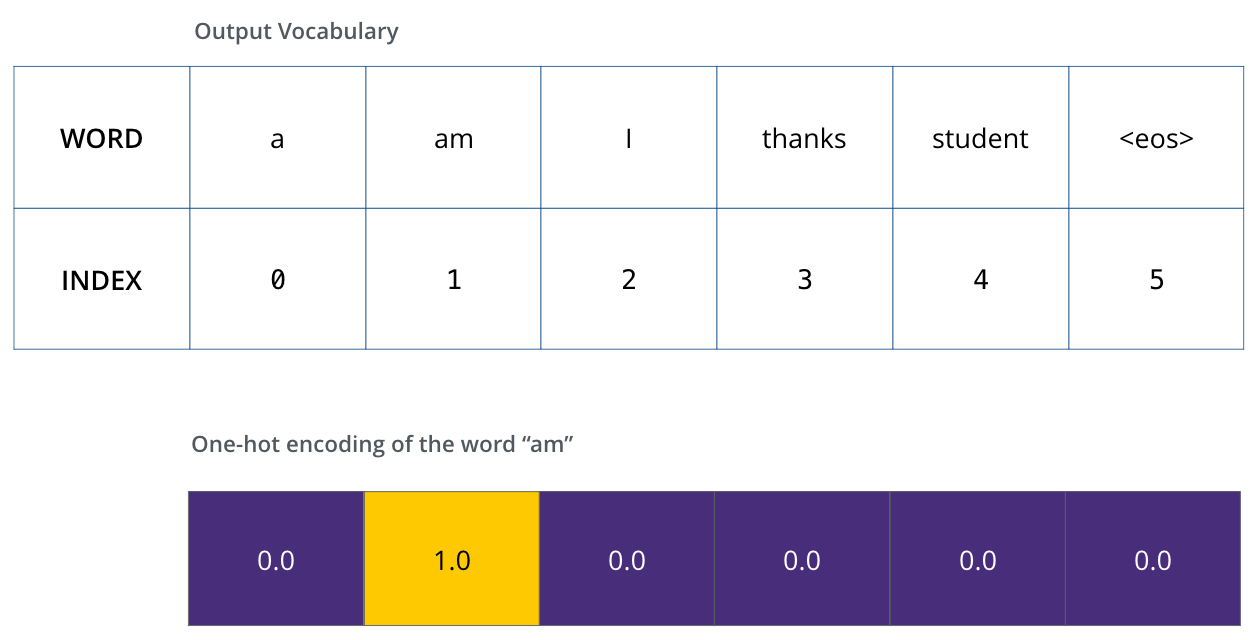
: one-hot- .
(loss function) – , , , .
, . – «merci» «thanks».
, , , «thanks». .. , .
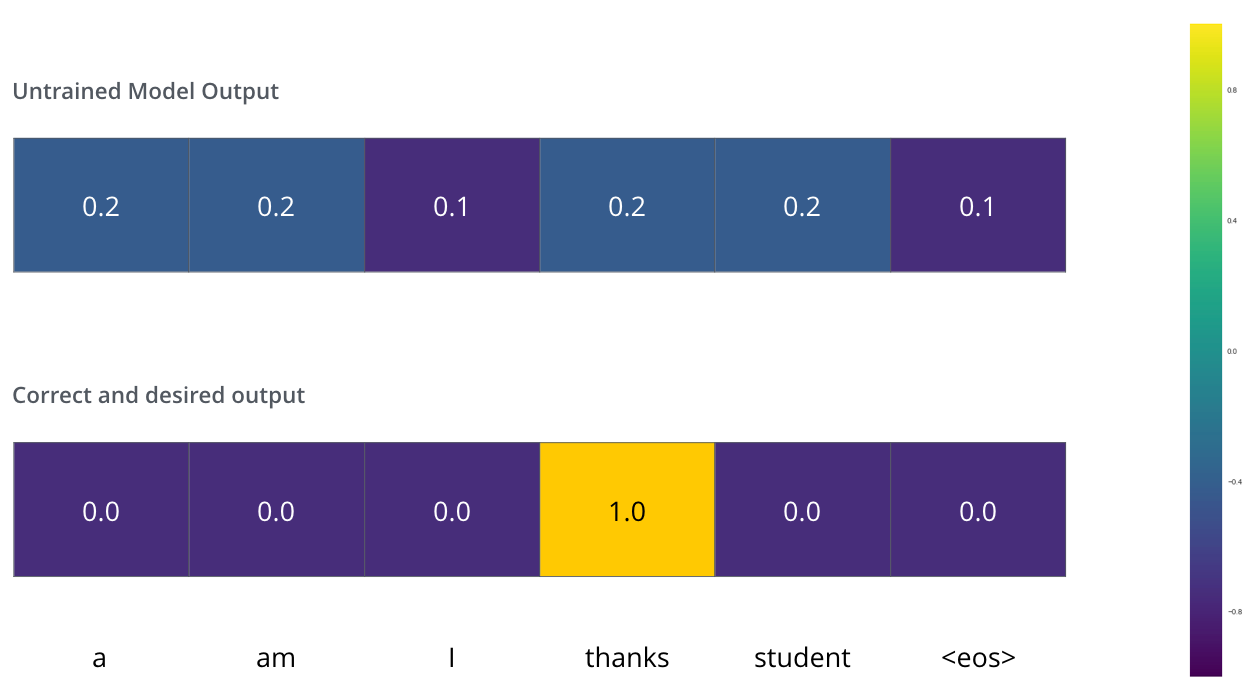
() , /. , , , .
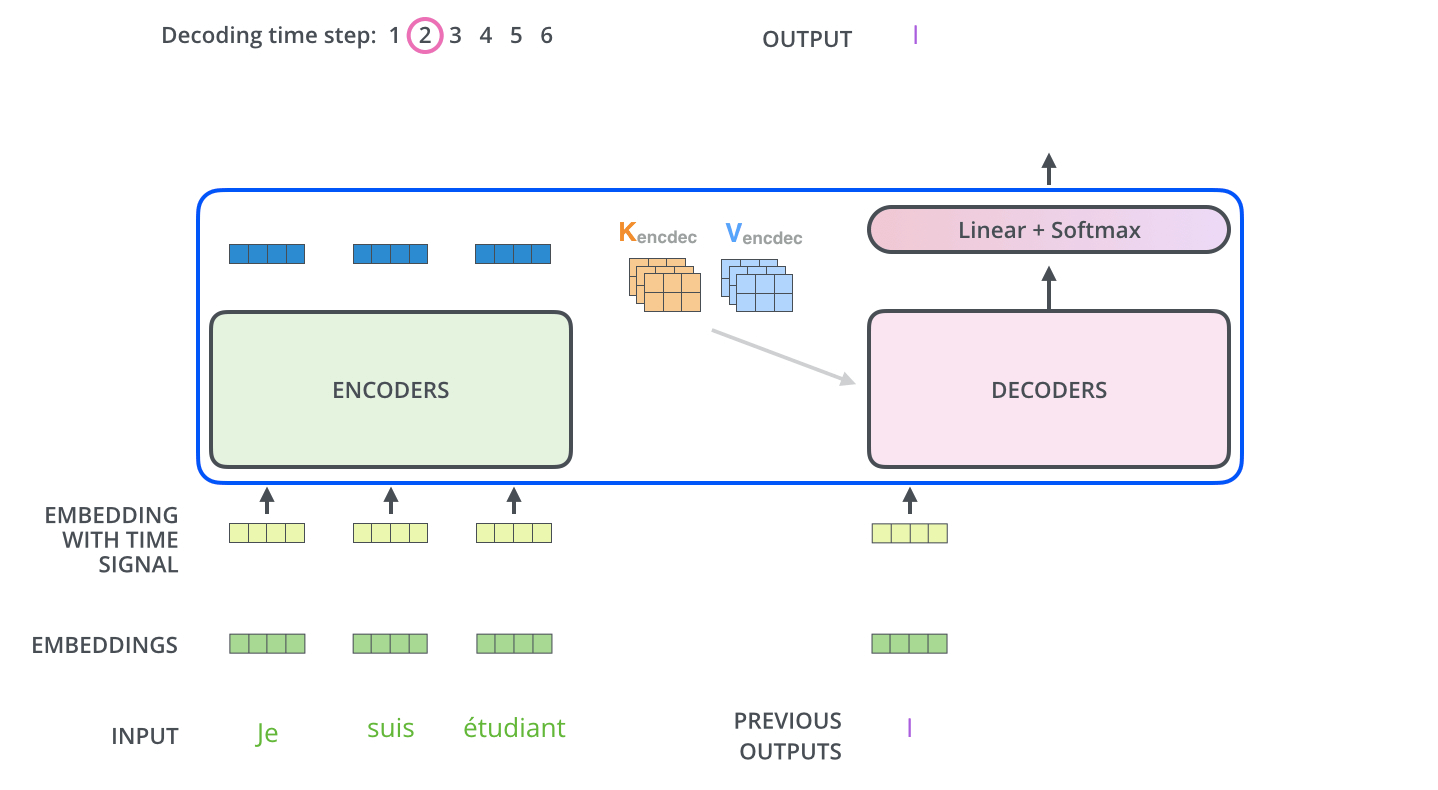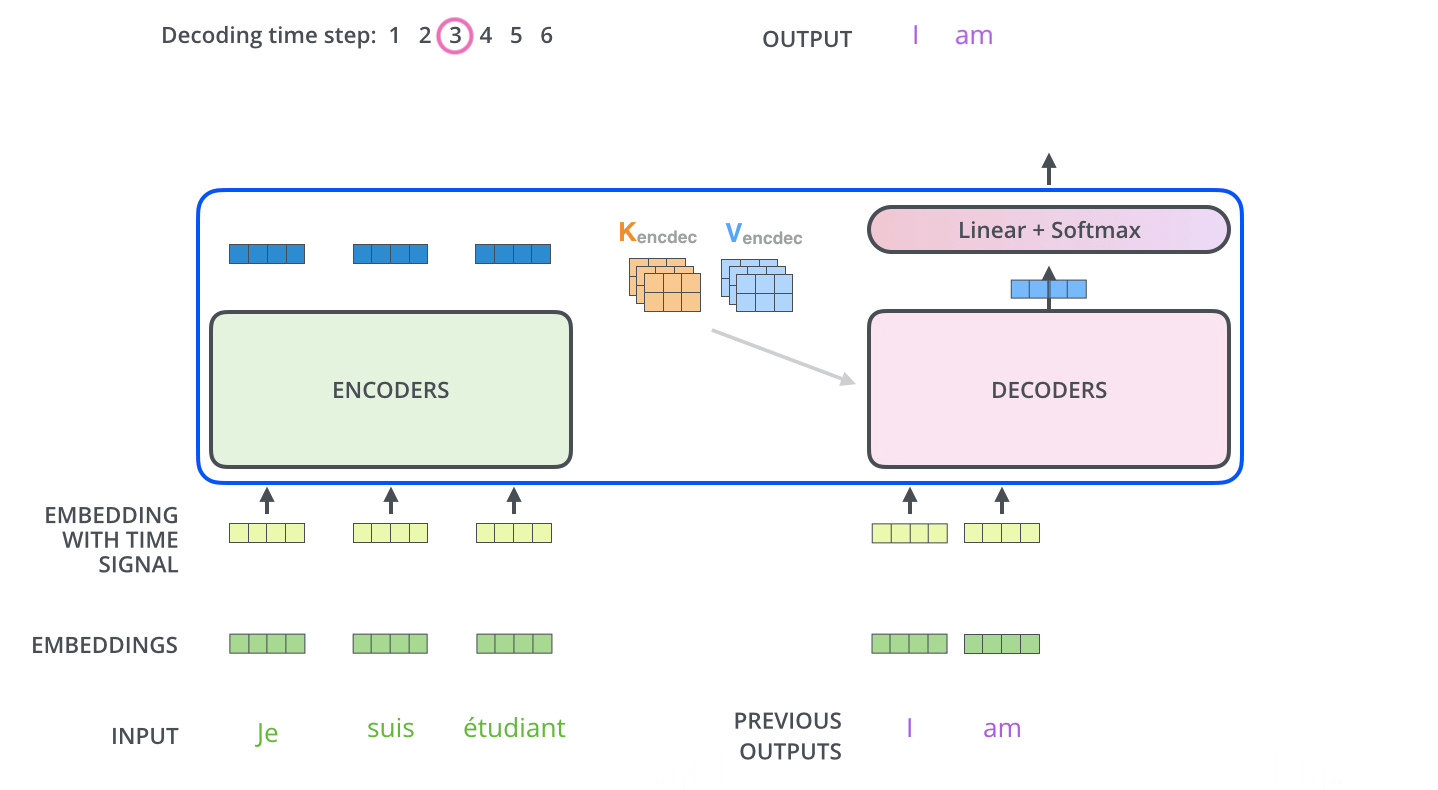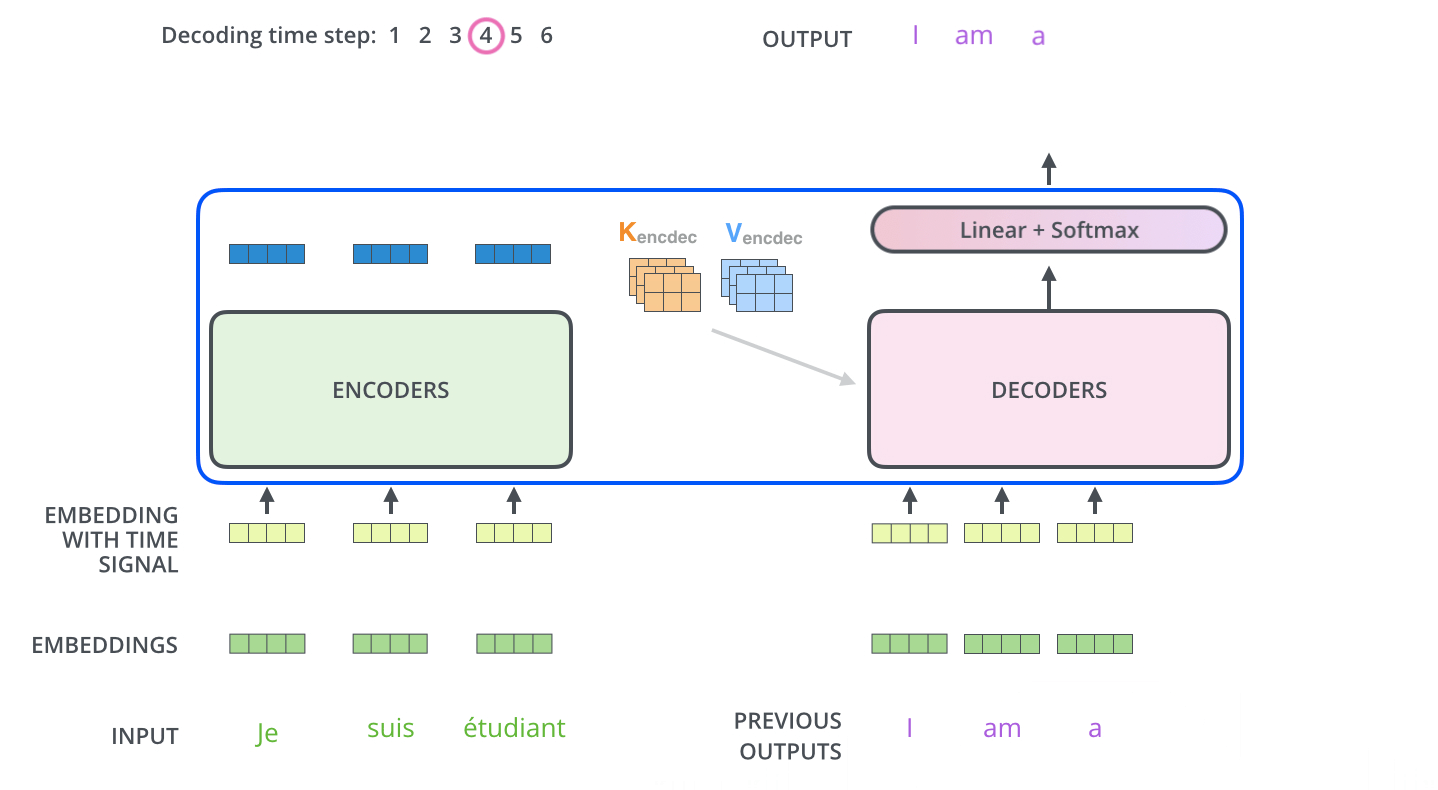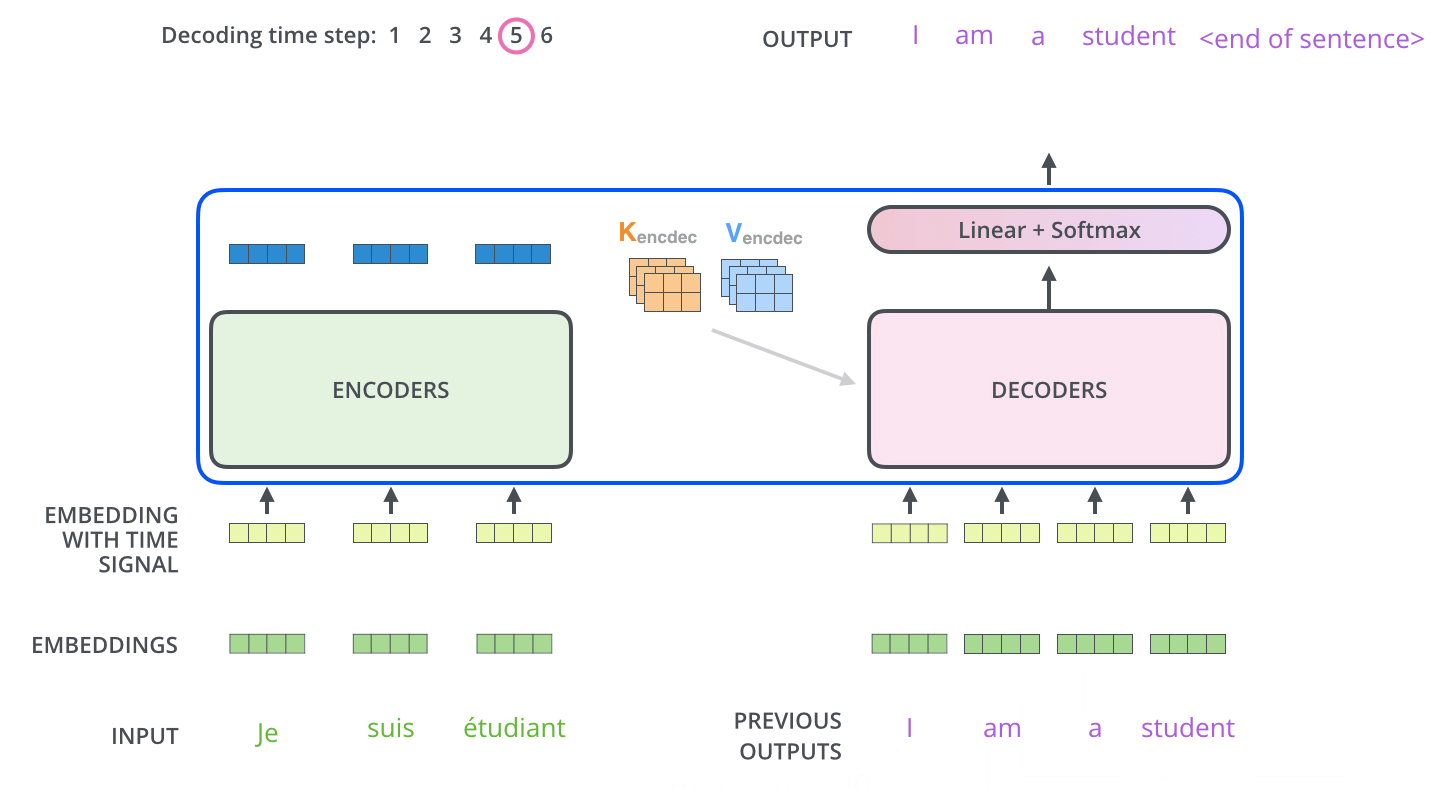
? . , . -.
, . . , «je suis étudiant» – «I am a student». , , , :
- (6 , – 3000 10000);
- , «i»;
- , «am»;
- .. , .
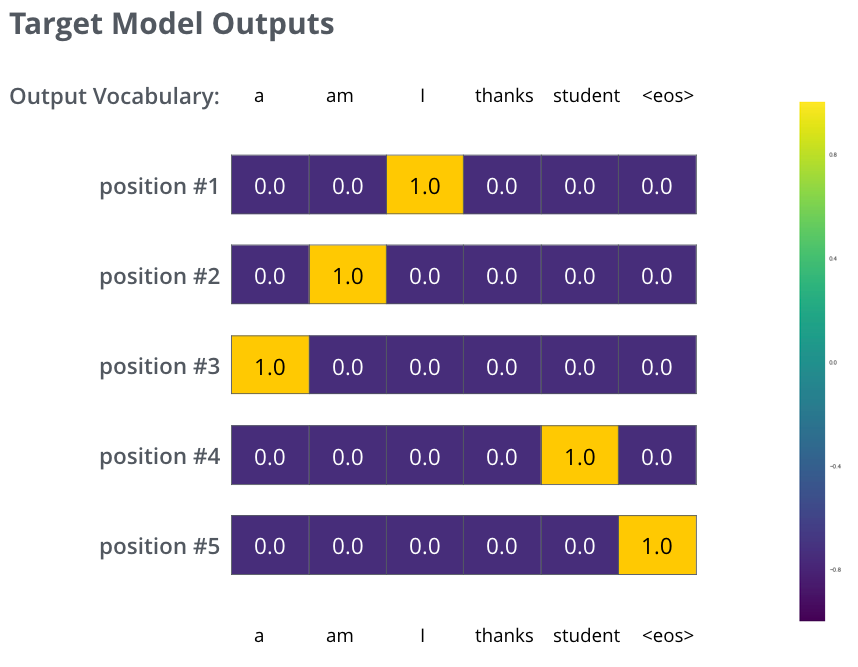
, :
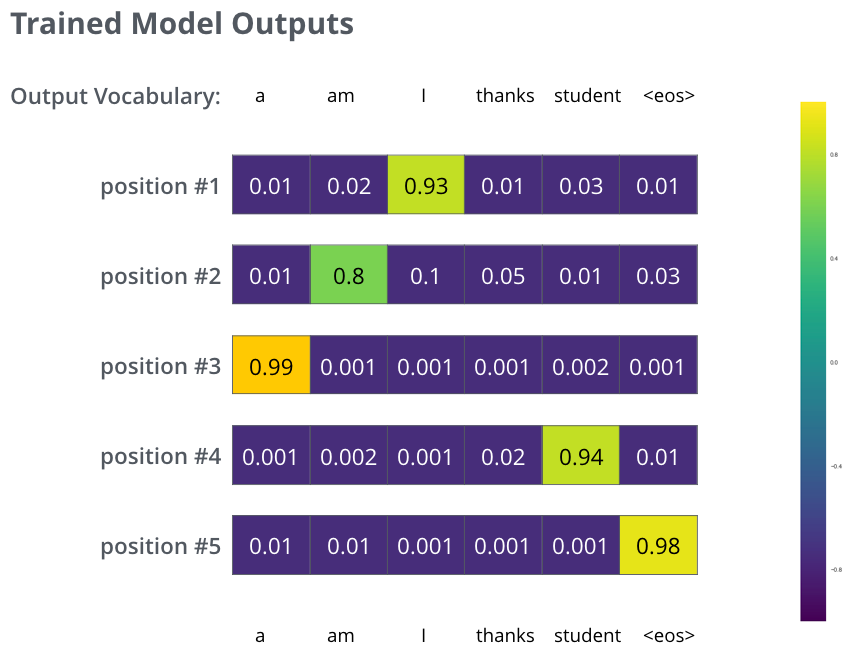
, . , , (.: ). , , , – , .
, , , , . , (greedy decoding). – , , 2 ( , «I» «a») , , : , «I», , , «a». , , . #2 #3 .. « » (beam search). (beam_size) (.. #1 #2), - (top_beams) ( ). .
, . , :
:
Autores