Nube catastrófica: cómo funciona
Hola Habr!Después de las vacaciones de Año Nuevo, reiniciamos una nube resistente a desastres basada en dos sitios. Hoy le diremos cómo funciona y le mostraremos qué sucede con las máquinas virtuales del cliente cuando los elementos individuales del clúster fallan y todo el sitio se cae (spoiler: todo está bien con ellos). Almacenamiento en la nube a prueba de desastres en el sitio OST.
Almacenamiento en la nube a prueba de desastres en el sitio OST.Lo que hay dentro
Bajo el capó del clúster se encuentran servidores Cisco UCS con hipervisor VMware ESXi, dos sistemas de almacenamiento INFINIDAT InfiniBox F2240, equipos de red Cisco Nexus y conmutadores Brocade SAN. El clúster se divide en dos sitios: OST y NORD, es decir, en cada centro de datos un conjunto idéntico de equipos. En realidad, esto lo hace catastrófico.Dentro de una plataforma, los elementos principales también están duplicados (hosts, conmutadores SAN, tarjeta de red).Dos sitios están conectados por caminos dedicados de fibra óptica, también reservados.Algunas palabras sobre el almacenamiento. La primera nube resistente a desastres que creamos en NetApp. INFINIDAT fue elegido aquí, y he aquí por qué:- Opción de replicación activa-activa. Permite que la máquina virtual permanezca operativa incluso si uno de los sistemas de almacenamiento falla por completo. Te contaré más sobre la replicación más adelante.
- Tres controladores de disco para una mayor resistencia del sistema. Usualmente hay dos.
- Solución lista Nos llegó un rack ya ensamblado, que solo necesita estar conectado a la red y configurado.
- Atento soporte técnico. Los ingenieros de INFINIDAT analizan constantemente los registros y eventos de los sistemas de almacenamiento, instalan nuevas versiones en el firmware y ayudan con la configuración.
Aquí hay algunas fotos de desembalaje:

Como funciona
La nube ya es resistente dentro de sí misma. Protege al cliente de fallas individuales de hardware y software. Catastrófico ayudará a proteger contra fallas masivas dentro del mismo sitio: por ejemplo, fallas del sistema de almacenamiento (o clúster SDS, que sucede a menudo :)), errores masivos en la red de almacenamiento y más. Bueno y lo más importante: una nube de este tipo se salva cuando todo un sitio se vuelve inaccesible debido a incendios, apagones, captura de asaltantes, aterrizajes alienígenas.En todos estos casos, las máquinas virtuales del cliente continúan ejecutándose, y he aquí por qué.El esquema de clúster está diseñado para que cualquier host ESXi con máquinas virtuales cliente pueda acceder a cualquiera de los dos sistemas de almacenamiento. Si falla el almacenamiento en el sitio OST, las máquinas virtuales continuarán funcionando: los hosts en los que trabajan accederán al almacenamiento en NORD para obtener datos. Así es como se ve el diagrama de conexión en el clúster.Esto es posible debido al hecho de que se configura un enlace entre conmutadores entre las fábricas SAN de los dos sitios: el conmutador SAN Fabric OST SAN está conectado al conmutador SAN Fabric NORD de forma similar a los conmutadores SAN SAN Fabric B.Bueno, para que todas estas complejidades de las fábricas SAN tengan sentido, la replicación Active-Active se configura entre los dos sistemas de almacenamiento: la información se escribe casi simultáneamente en los sistemas de almacenamiento local y remoto, RPO = 0. Resulta que en un SHD los datos originales se almacenan, en el otro, su réplica. Los datos se replican en el nivel de volumen de almacenamiento y los datos de VM (sus discos, archivo de configuración, archivo de intercambio, etc.) ya están almacenados en ellos.El host ESXi ve el volumen primario y su réplica como un único dispositivo de almacenamiento. Hay 24 rutas desde el host ESXi a cada dispositivo de disco:12 rutas lo asocian con el almacenamiento local (rutas óptimas) y las 12 restantes con el remoto (rutas no óptimas). En una situación normal, ESXi accede a los datos en el almacenamiento local utilizando rutas "óptimas". Si este sistema de almacenamiento falla, ESXi pierde sus rutas óptimas y cambia a las "no óptimas". Así es como se ve en el diagrama.
Así es como se ve el diagrama de conexión en el clúster.Esto es posible debido al hecho de que se configura un enlace entre conmutadores entre las fábricas SAN de los dos sitios: el conmutador SAN Fabric OST SAN está conectado al conmutador SAN Fabric NORD de forma similar a los conmutadores SAN SAN Fabric B.Bueno, para que todas estas complejidades de las fábricas SAN tengan sentido, la replicación Active-Active se configura entre los dos sistemas de almacenamiento: la información se escribe casi simultáneamente en los sistemas de almacenamiento local y remoto, RPO = 0. Resulta que en un SHD los datos originales se almacenan, en el otro, su réplica. Los datos se replican en el nivel de volumen de almacenamiento y los datos de VM (sus discos, archivo de configuración, archivo de intercambio, etc.) ya están almacenados en ellos.El host ESXi ve el volumen primario y su réplica como un único dispositivo de almacenamiento. Hay 24 rutas desde el host ESXi a cada dispositivo de disco:12 rutas lo asocian con el almacenamiento local (rutas óptimas) y las 12 restantes con el remoto (rutas no óptimas). En una situación normal, ESXi accede a los datos en el almacenamiento local utilizando rutas "óptimas". Si este sistema de almacenamiento falla, ESXi pierde sus rutas óptimas y cambia a las "no óptimas". Así es como se ve en el diagrama. El esquema de un clúster resistente a los desastres.Todas las redes de clientes se establecen en ambos sitios a través de una fábrica de redes común. Provider Edge (PE) se ejecuta en cada sitio, en el que se terminan las redes de clientes. Las PE se combinan en un solo grupo. Si PE falla en un sitio, todo el tráfico se redirige al segundo sitio. Gracias a esto, las máquinas virtuales del sitio sin PE permanecen disponibles en la red para el cliente.Veamos ahora qué pasará con las máquinas virtuales del cliente en caso de varias fallas. Comencemos con las opciones más livianas y terminemos con las más serias: el fracaso de todo el sitio. En los ejemplos, el sitio principal será OST y la copia de seguridad, con réplicas de datos, será NORD.
El esquema de un clúster resistente a los desastres.Todas las redes de clientes se establecen en ambos sitios a través de una fábrica de redes común. Provider Edge (PE) se ejecuta en cada sitio, en el que se terminan las redes de clientes. Las PE se combinan en un solo grupo. Si PE falla en un sitio, todo el tráfico se redirige al segundo sitio. Gracias a esto, las máquinas virtuales del sitio sin PE permanecen disponibles en la red para el cliente.Veamos ahora qué pasará con las máquinas virtuales del cliente en caso de varias fallas. Comencemos con las opciones más livianas y terminemos con las más serias: el fracaso de todo el sitio. En los ejemplos, el sitio principal será OST y la copia de seguridad, con réplicas de datos, será NORD.¿Qué le sucede a una máquina virtual cliente si ...
El enlace de replicación falla. Se detiene la replicación entre los sistemas de almacenamiento de los dos sitios.ESXi solo funcionará con dispositivos de disco locales (a lo largo de las rutas óptimas).Las máquinas virtuales siguen funcionando. Hay una brecha ISL (Inter-Switch Link). El caso es poco probable. A menos que algún excavador loco desenterre varias rutas ópticas a la vez, que pasan por rutas independientes y son llevadas a los sitios a través de diferentes entradas. Pero de todos modos. En este caso, los hosts ESXi pierden la mitad de sus rutas y solo pueden acceder a su almacenamiento local. Se recopilan réplicas, pero los hosts no podrán acceder a ellas.Las máquinas virtuales funcionan normalmente.
Hay una brecha ISL (Inter-Switch Link). El caso es poco probable. A menos que algún excavador loco desenterre varias rutas ópticas a la vez, que pasan por rutas independientes y son llevadas a los sitios a través de diferentes entradas. Pero de todos modos. En este caso, los hosts ESXi pierden la mitad de sus rutas y solo pueden acceder a su almacenamiento local. Se recopilan réplicas, pero los hosts no podrán acceder a ellas.Las máquinas virtuales funcionan normalmente. Rechaza un cambio de SAN en uno de los sitios.Los hosts ESXi pierden algunas de sus rutas de almacenamiento. En este caso, los hosts en el sitio donde falló el conmutador funcionarán solo a través de su propio HBA.Al mismo tiempo, las máquinas virtuales continúan funcionando normalmente.
Rechaza un cambio de SAN en uno de los sitios.Los hosts ESXi pierden algunas de sus rutas de almacenamiento. En este caso, los hosts en el sitio donde falló el conmutador funcionarán solo a través de su propio HBA.Al mismo tiempo, las máquinas virtuales continúan funcionando normalmente. Todos los conmutadores SAN en uno de los sitios fallan. Digamos que tal desastre ocurrió en el sitio OST. En este caso, los hosts ESXi en este sitio perderán todas las rutas a sus dispositivos de disco. El mecanismo estándar VMware vSphere HA entra en juego: reiniciará todas las máquinas virtuales de la plataforma OST en NORD después de un máximo de 140 segundos.Las máquinas virtuales que se ejecutan en los hosts del sitio NORD funcionan normalmente.
Todos los conmutadores SAN en uno de los sitios fallan. Digamos que tal desastre ocurrió en el sitio OST. En este caso, los hosts ESXi en este sitio perderán todas las rutas a sus dispositivos de disco. El mecanismo estándar VMware vSphere HA entra en juego: reiniciará todas las máquinas virtuales de la plataforma OST en NORD después de un máximo de 140 segundos.Las máquinas virtuales que se ejecutan en los hosts del sitio NORD funcionan normalmente.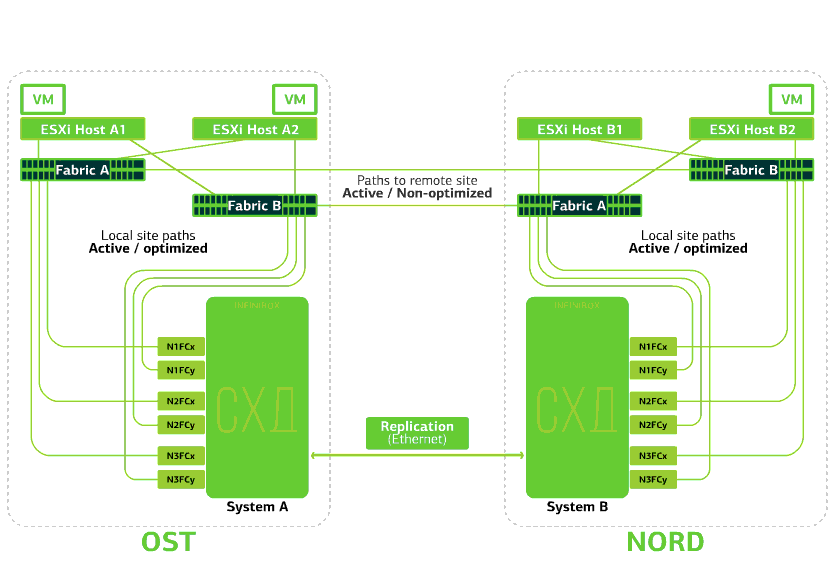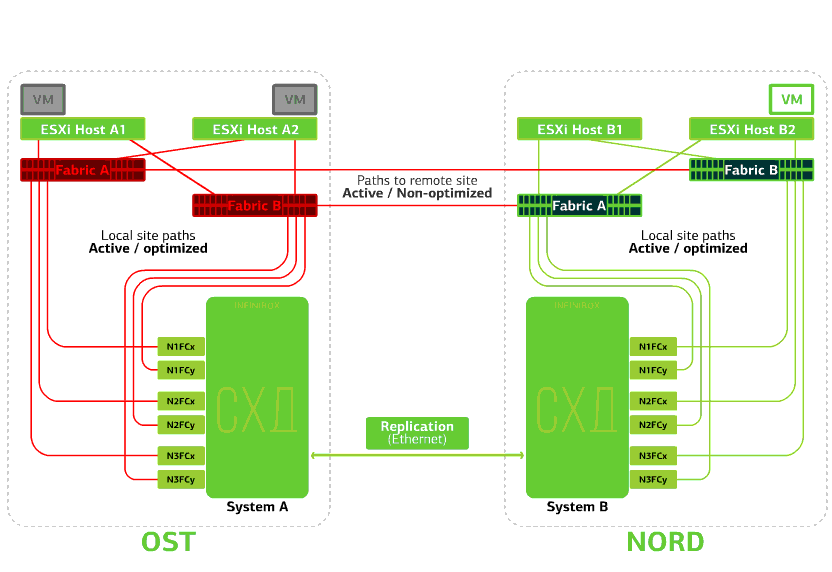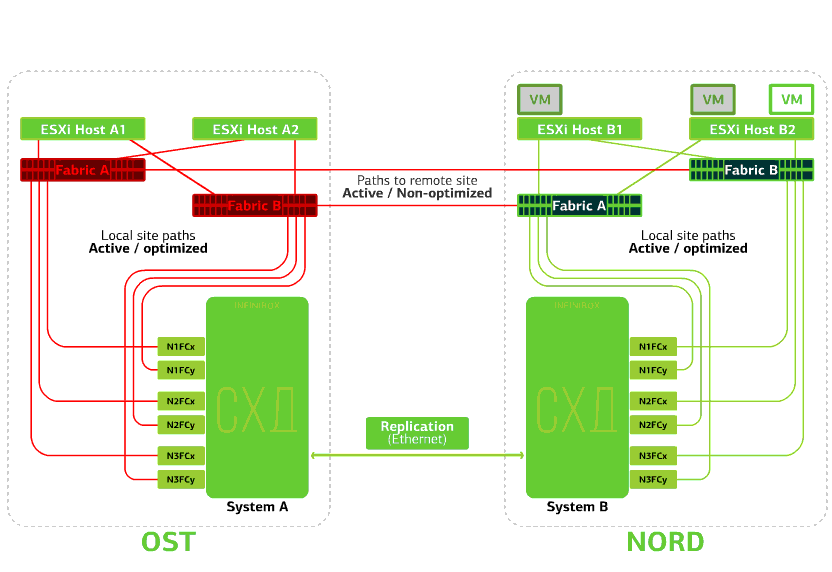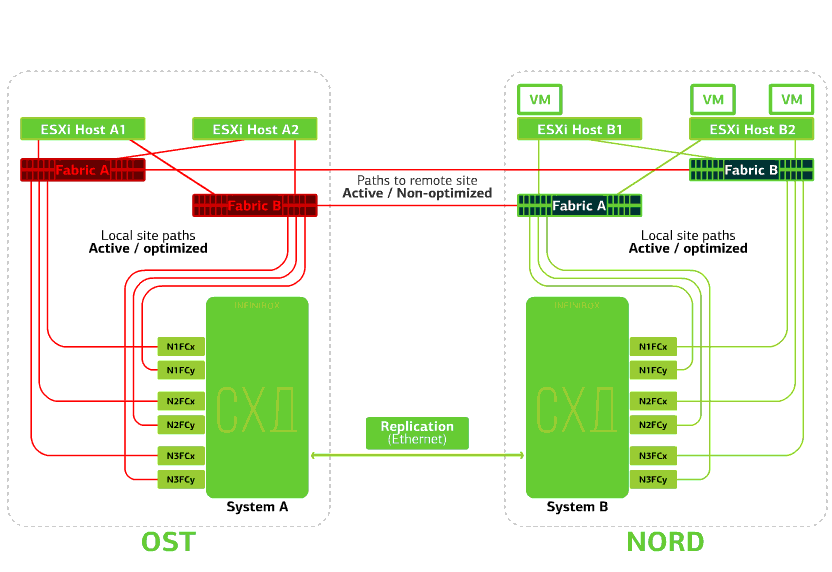 Rechaza el host ESXi en un sitio.Aquí el mecanismo vSphere HA funciona de nuevo: las máquinas virtuales de un host fallido se reinician en otros hosts, en el mismo sitio o en un sitio remoto. El tiempo de reinicio de la máquina virtual es de hasta 1 minuto.Si todos los hosts ESXi de la plataforma OST fallan, no hay opciones: las máquinas virtuales se reinician en otra. El tiempo de reinicio es el mismo.
Rechaza el host ESXi en un sitio.Aquí el mecanismo vSphere HA funciona de nuevo: las máquinas virtuales de un host fallido se reinician en otros hosts, en el mismo sitio o en un sitio remoto. El tiempo de reinicio de la máquina virtual es de hasta 1 minuto.Si todos los hosts ESXi de la plataforma OST fallan, no hay opciones: las máquinas virtuales se reinician en otra. El tiempo de reinicio es el mismo.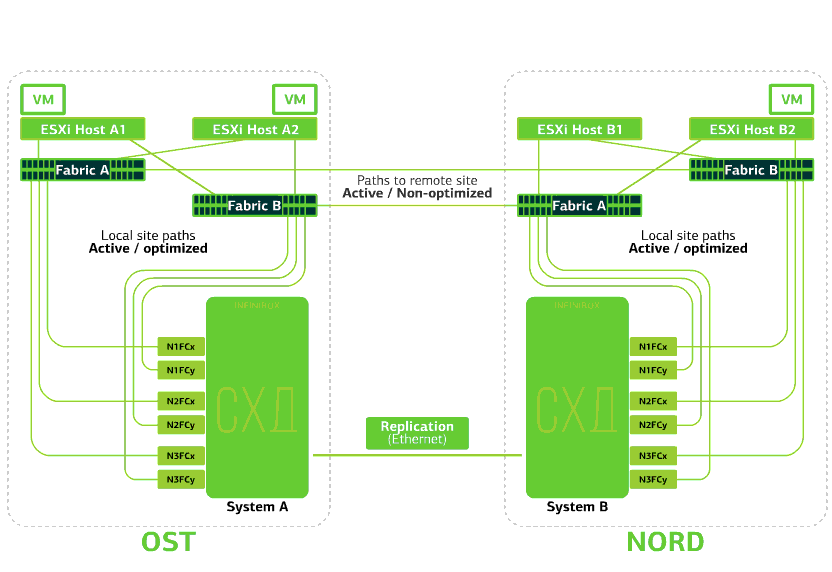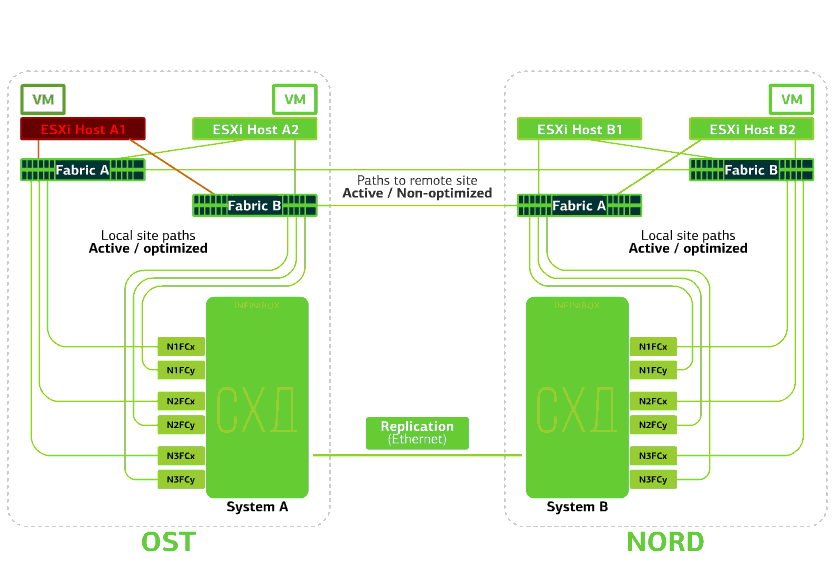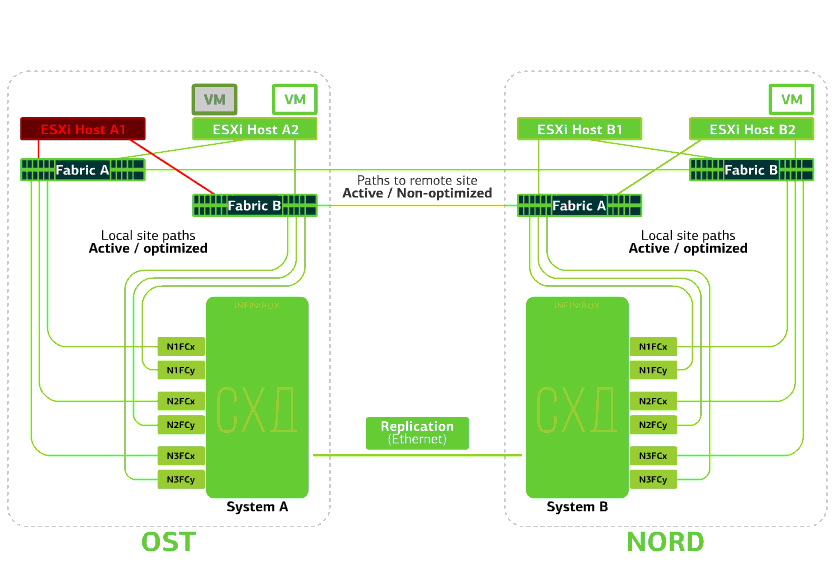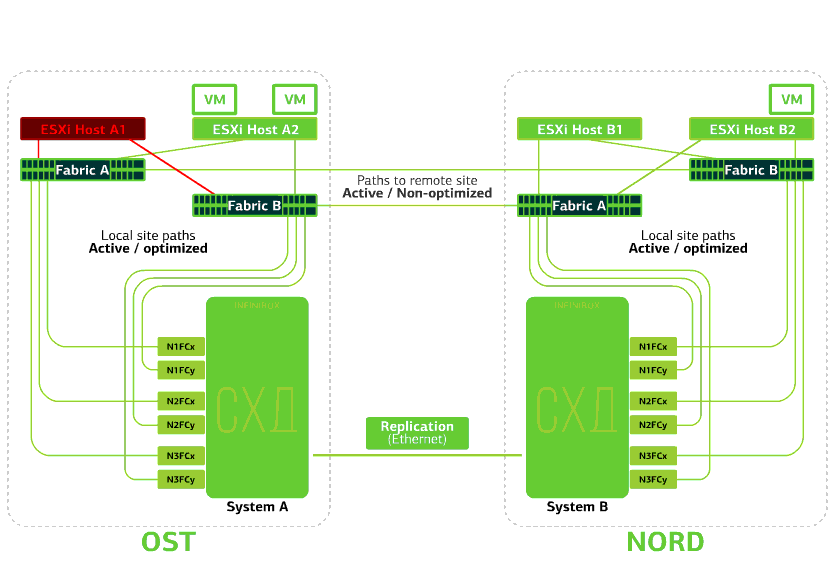 Rechaza el almacenamiento en el mismo sitio. Digamos que el sistema de almacenamiento se negó en el sitio OST. Luego, los hosts OST ESXi cambian para trabajar con réplicas de almacenamiento en NORD. Una vez que el sistema de almacenamiento fallido vuelve al sistema, se produce una replicación forzada, los hosts OST ESXi volverán a ponerse en contacto con el sistema de almacenamiento local.Las máquinas virtuales han estado funcionando todo este tiempo.
Rechaza el almacenamiento en el mismo sitio. Digamos que el sistema de almacenamiento se negó en el sitio OST. Luego, los hosts OST ESXi cambian para trabajar con réplicas de almacenamiento en NORD. Una vez que el sistema de almacenamiento fallido vuelve al sistema, se produce una replicación forzada, los hosts OST ESXi volverán a ponerse en contacto con el sistema de almacenamiento local.Las máquinas virtuales han estado funcionando todo este tiempo. Falla uno de los sitios.En este caso, todas las máquinas virtuales se reiniciarán en el sitio de respaldo a través del mecanismo vSphere HA. Tiempo de reinicio de VM: 140 segundos. En este caso, todas las configuraciones de red de la máquina virtual se guardarán y permanecerán disponibles para el cliente a través de la red.Para reiniciar las máquinas en el sitio de copia de seguridad sin problemas, cada sitio está medio lleno. La segunda mitad es la reserva en caso de que todas las máquinas virtuales se muevan desde el segundo sitio lesionado.
Falla uno de los sitios.En este caso, todas las máquinas virtuales se reiniciarán en el sitio de respaldo a través del mecanismo vSphere HA. Tiempo de reinicio de VM: 140 segundos. En este caso, todas las configuraciones de red de la máquina virtual se guardarán y permanecerán disponibles para el cliente a través de la red.Para reiniciar las máquinas en el sitio de copia de seguridad sin problemas, cada sitio está medio lleno. La segunda mitad es la reserva en caso de que todas las máquinas virtuales se muevan desde el segundo sitio lesionado.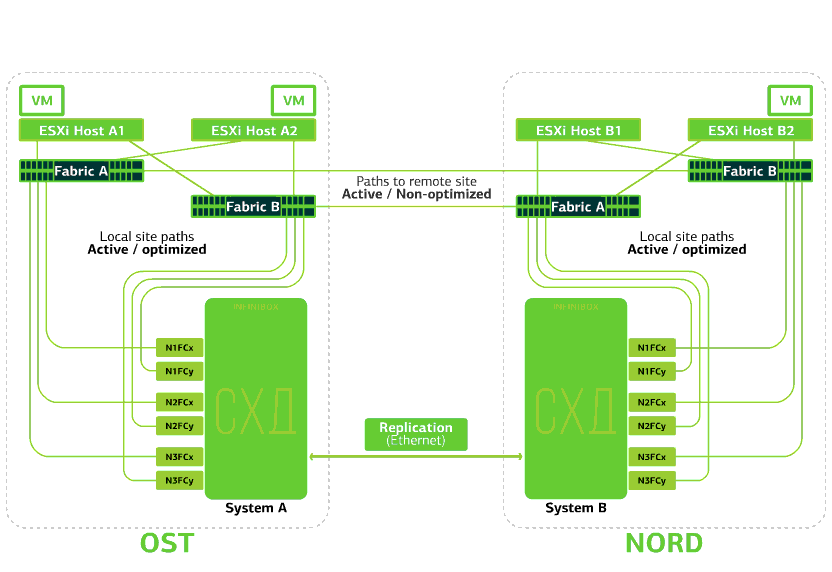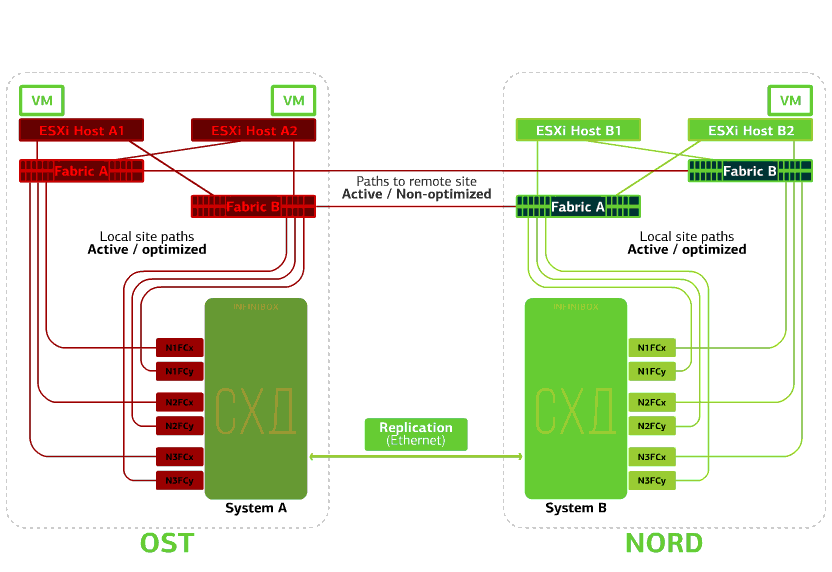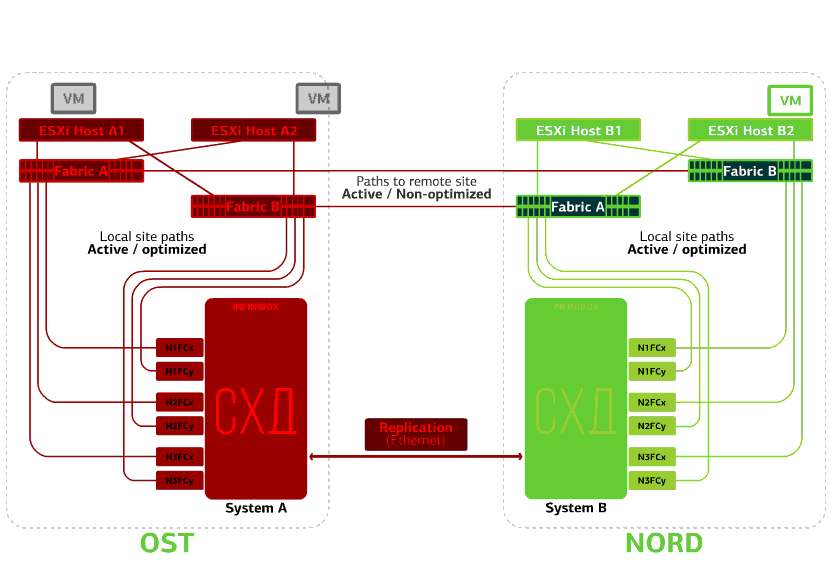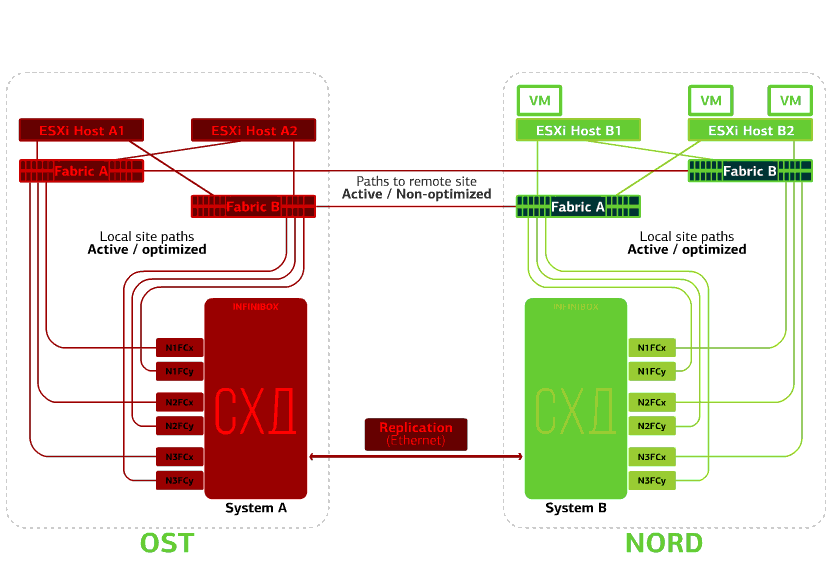 Una nube a prueba de desastres basada en dos centros de datos protege contra tales fallas.Este placer no es barato porque, además de los recursos principales, necesita una reserva en el segundo sitio. Por lo tanto, colocan los servicios críticos para el negocio en una nube de este tipo, cuyo largo tiempo de inactividad genera grandes pérdidas financieras y de reputación, o si los reguladores o los reglamentos internos de la compañía imponen requisitos de tolerancia a desastres en el sistema de información.Fuentes:
Una nube a prueba de desastres basada en dos centros de datos protege contra tales fallas.Este placer no es barato porque, además de los recursos principales, necesita una reserva en el segundo sitio. Por lo tanto, colocan los servicios críticos para el negocio en una nube de este tipo, cuyo largo tiempo de inactividad genera grandes pérdidas financieras y de reputación, o si los reguladores o los reglamentos internos de la compañía imponen requisitos de tolerancia a desastres en el sistema de información.Fuentes:- www.infinidat.com/sites/default/files/resource-pdfs/DS-INFBOX-190331-US_0.pdf
- support.infinidat.com/hc/en-us/articles/207057109-InfiniBox-best-practices-guides
Source: https://habr.com/ru/post/undefined/
All Articles