NiFi is gaining more and more popularity and with every new release it gets more and more tools for working with data. Nevertheless, it may be necessary to have your own tool to solve a specific problem. Apache Nifi has over 300 processors in its base package. Nifi processor It is the main building block for creating dataflow in the NiFi ecosystem. Processors provide an interface through which NiFi provides access to the flowfile, its attributes, and content. Own custom processor will save power, time and user attention, because instead of many simple processor elements, only one will be displayed in the interface and only one will be executed (well, or how much you write). Like standard processors, a custom processor allows you to perform various operations and process the contents of a flowfile. Today we’ll talk about standard tools for expanding functionality.
It is the main building block for creating dataflow in the NiFi ecosystem. Processors provide an interface through which NiFi provides access to the flowfile, its attributes, and content. Own custom processor will save power, time and user attention, because instead of many simple processor elements, only one will be displayed in the interface and only one will be executed (well, or how much you write). Like standard processors, a custom processor allows you to perform various operations and process the contents of a flowfile. Today we’ll talk about standard tools for expanding functionality.ExecuteScript
ExecuteScript is a universal processor that is designed to implement business logic in a programming language (Groovy, Jython, Javascript, JRuby). This approach allows you to quickly get the desired functionality. To provide access to NiFi components in a script, it is possible to use the following variables:Session : a variable of type org.apache.nifi.processor.ProcessSession. The variable allows you to perform operations with flowfile, such as create (), putAttribute () and Transfer (), as well as read () and write ().Context : org.apache.nifi.processor.ProcessContext. It can be used to get processor properties, relationships, controller services, and StateManager.REL_SUCCESS : Relationship "success".REL_FAILURE : Failure RelationshipDynamic Properties : Dynamic properties defined in ExecuteScript are passed to the script engine as variables, set as a PropertyValue. This allows you to get the value of the property, convert the value to the appropriate data type, for example, logical, etc.For use, just select Script Engineand specify the location of the file Script Filewith our script or the script itself Script Body.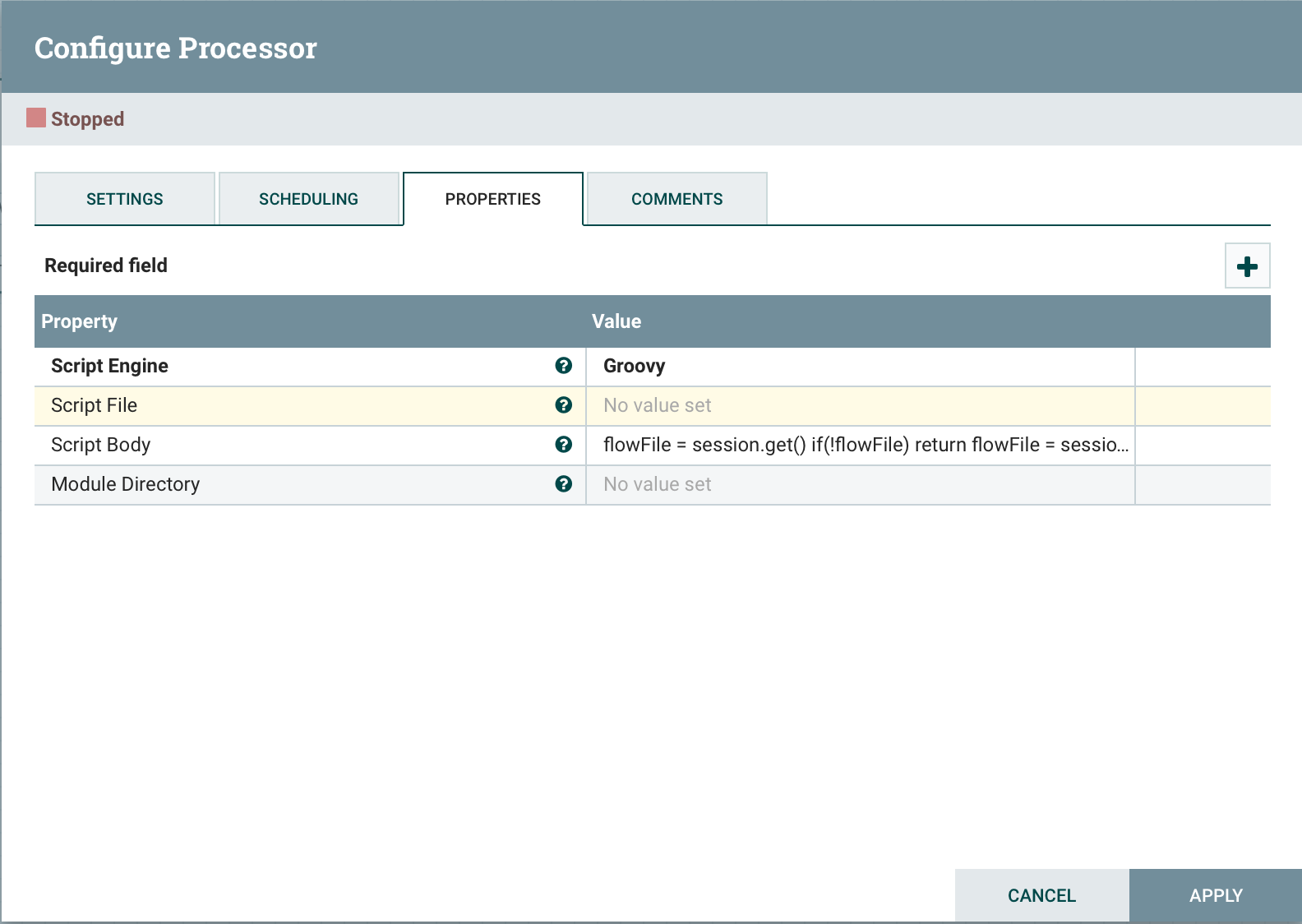 Let's look at a couple of examples:get one stream file from the queue
Let's look at a couple of examples:get one stream file from the queueflowFile = session.get()
if(!flowFile) return
Generate a new FlowFileflowFile = session.create()
// Additional processing here
Add Attribute to FlowFileflowFile = session.get()
if(!flowFile) return
flowFile = session.putAttribute(flowFile, 'myAttr', 'myValue')
Extract and process all attributes.flowFile = session.get() if(!flowFile) return
flowFile.getAttributes().each { key,value ->
// Do something with the key/value pair
}
Loggerlog.info('Found these things: {} {} {}', ['Hello',1,true] as Object[])
You can use advanced features in ExecuteScript, more about this can be found in the article ExecuteScript Cookbook.ExecuteGroovyScript
ExecuteGroovyScript has the same functionality as ExecuteScript, but instead of a zoo of valid languages, you can use only one - groovy. The main advantage of this processor is its more convenient use of service services. In addition to the standard set of variables Session, Context, etc. You can define dynamic properties with the CTL and SQL prefix. Starting with version 1.11, support for RecordReader and Record Writer appeared. All properties are HashMap, which uses the "Service Name" as the key, and the value is a specific object depending on the property:RecordWriter HashMap<String,RecordSetWriterFactory>
RecordReader HashMap<String,RecordReaderFactory>
SQL HashMap<String,groovy.sql.Sql>
CTL HashMap<String,ControllerService>
This information already makes life easier. we can look into the sources or find documentation for a particular class.Working with the databaseIf we define the SQL.DB property and bind DBCPService, then we will access the property from the code. SQL.DB.rows('select * from table') The processor automatically accepts a connection from the dbcp service before execution and processes the transaction. Database transactions are automatically rolled back when an error occurs and are committed if successful. In ExecuteGroovyScript, you can intercept start and stop events by implementing the appropriate static methods.
The processor automatically accepts a connection from the dbcp service before execution and processes the transaction. Database transactions are automatically rolled back when an error occurs and are committed if successful. In ExecuteGroovyScript, you can intercept start and stop events by implementing the appropriate static methods.import org.apache.nifi.processor.ProcessContext
...
static onStart(ProcessContext context){
// your code
}
static onStop(ProcessContext context){
// your code
}
REL_SUCCESS << flowFile
InvokeScriptedProcessor
Another interesting processor. To use it, you need to declare a class that implements the implements interface and define a processor variable. You can define any PropertyDescriptor or Relationship, also access the parent ComponentLog and define the methods void onScheduled (ProcessContext context) and void onStopped (ProcessContext context). These methods will be called when a scheduled start event occurs in NiFi (onScheduled) and when it stops (onScheduled).class GroovyProcessor implements Processor {
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
Logic must be implemented in the method void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) @Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) throw s ProcessException {
final ProcessSession session = sessionFactory.createSession(); def
flowFile = session.create()
if (!flowFile) return
// your code
try
{ session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
It is unnecessary to describe all the methods declared in the interface, so let's get around one abstract class in which we declare the following method:abstract void executeScript(ProcessContext context, ProcessSession session)
The method we will call invoid onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory)
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.components.ValidationContext import org.apache.nifi.components.ValidationResult import org.apache.nifi.logging.ComponentLog
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.ProcessSessionFactory import org.apache.nifi.processor.Processor
import org.apache.nifi.processor.ProcessorInitializationContext import org.apache.nifi.processor.Relationship
import org.apache.nifi.processor.exception.ProcessException
abstract class BaseGroovyProcessor implements Processor {
public ComponentLog log
public Set<Relationship> relationships;
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr final ProcessSession session = sessionFactory.createSession();
try {
executeScript(context, session);
session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
abstract void executeScript(ProcessContext context, ProcessSession session) thro
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null }
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
Now we declare a successor class BaseGroovyProcessorand describe our executeScript, we also add Relationship RELSUCCESS and RELFAILURE.import org.apache.commons.lang3.tuple.Pair
import org.apache.nifi.expression.ExpressionLanguageScope import org.apache.nifi.processor.util.StandardValidators import ru.rt.nifi.common.BaseGroovyProcessor
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.dbcp.DBCPService
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.exception.ProcessException import org.quartz.CronExpression
import java.sql.Connection
import java.sql.PreparedStatement import java.sql.ResultSet
import java.sql.SQLException import java.sql.Statement
class InvokeScripted extends BaseGroovyProcessor {
public static final REL_SUCCESS = new Relationship.Builder()
.name("success")
.description("If the cache was successfully communicated with it will be rou
.build()
public static final REL_FAILURE = new Relationship.Builder()
.name("failure")
.description("If unable to communicate with the cache or if the cache entry
.build()
@Override
void executeScript(ProcessContext context, ProcessSession session) throws Proces def flowFile = session.create()
if (!flowFile) return
try {
// your code
session.transfer(flowFile, REL_SUCCESS)
} catch(ProcessException | SQLException e) {
session.transfer(flowFile, REL_FAILURE)
log.error("Unable to execute SQL select query {} due to {}. No FlowFile
}
}
}
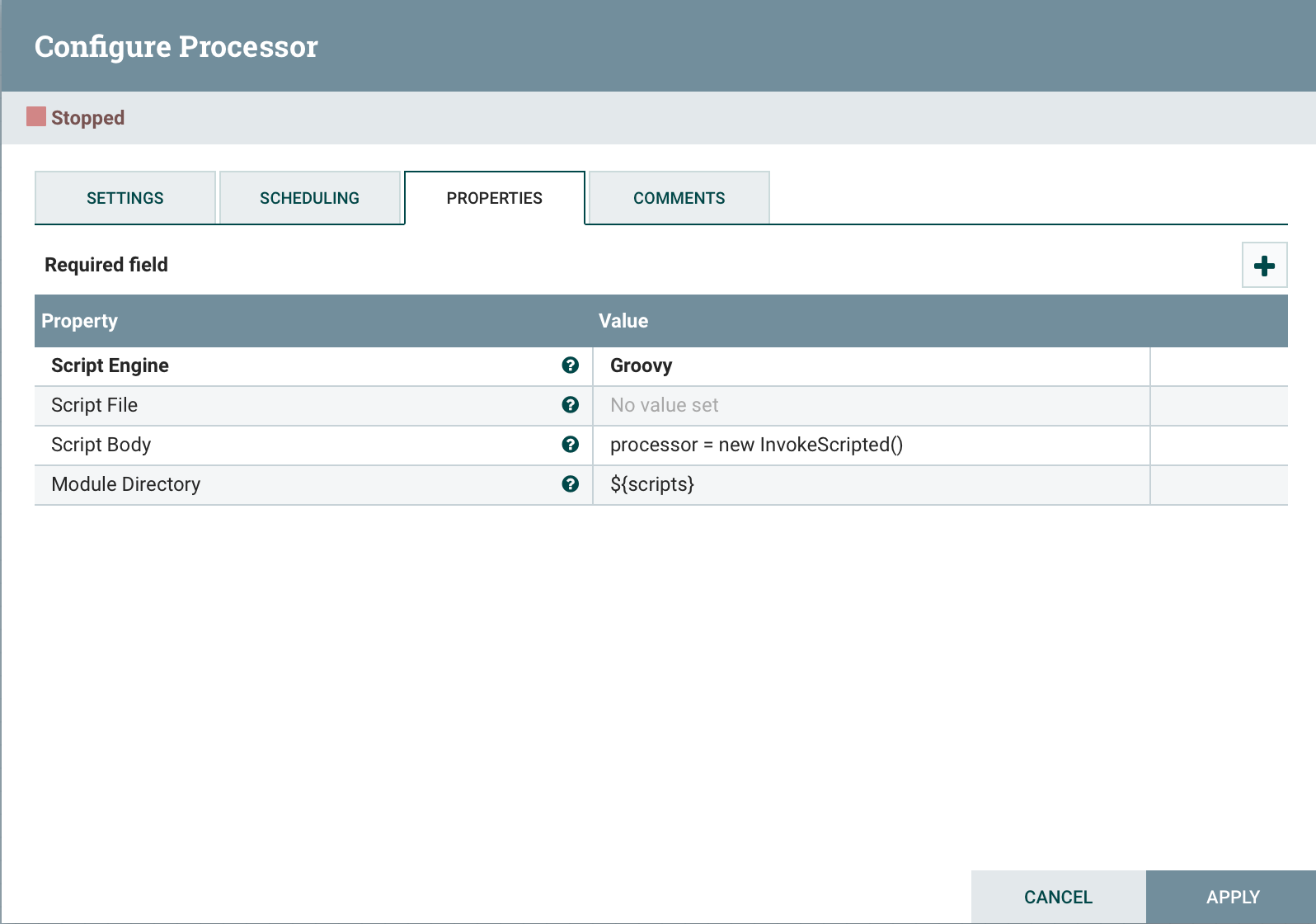 Add to the end of the code.
Add to the end of the code. processor = new InvokeScripted()This approach is similar to creating a custom processor.Conclusion
Creating a custom processor is not the easiest thing - for the first time you will have to work hard to figure it out, but the benefits of this action are undeniable.Post prepared by Rostelecom Data Management Team