 Anyone who encounters machine learning understands that this requires serious computing power. In this article, we will try to apply the algorithm developed in MIT to compress a neural network, which will reduce the dimension of the weights of the trained model and will lead to both faster learning and faster model launch.Neural networks have proven to be an excellent tool for solving a wide variety of tasks, but, unfortunately, their use requires significant computing power, which still may not be in a small business. There are many types of compression of neural networks that can be divided into hardware, low-level, and mathematical, but this article will discuss the method developed at MIT in 2019 and working directly with the neural network itself.This method is called the “Winning Ticket Hypothesis”. In general terms, it sounds like this: Any fully-connected neural network with randomly initialized weights contains a subnet with the same weights, and such a subnet trained separately can be equal in accuracy to the original network.Formal proof and full article can be found here . We are interested in the possibility of practical application. In short, the algorithm is as follows:
Anyone who encounters machine learning understands that this requires serious computing power. In this article, we will try to apply the algorithm developed in MIT to compress a neural network, which will reduce the dimension of the weights of the trained model and will lead to both faster learning and faster model launch.Neural networks have proven to be an excellent tool for solving a wide variety of tasks, but, unfortunately, their use requires significant computing power, which still may not be in a small business. There are many types of compression of neural networks that can be divided into hardware, low-level, and mathematical, but this article will discuss the method developed at MIT in 2019 and working directly with the neural network itself.This method is called the “Winning Ticket Hypothesis”. In general terms, it sounds like this: Any fully-connected neural network with randomly initialized weights contains a subnet with the same weights, and such a subnet trained separately can be equal in accuracy to the original network.Formal proof and full article can be found here . We are interested in the possibility of practical application. In short, the algorithm is as follows:- We create a model, randomly initialize its parameters
- Learning a network of iterations j
- We cut off those network parameters that have the smallest value (the simplest task is to set some threshold value)
- We reset the remaining parameters to their initial values, we get the subnet we need.
In theory, this algorithm needs to be repeated the nth number of steps, but for an example we will carry out only one iteration. Create a simple fully connected network using tensorflow and Keras:import tensorflow as tf
from tensorflow import keras
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(300, activation='relu'),
keras.layers.Dense(150, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='SGD',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
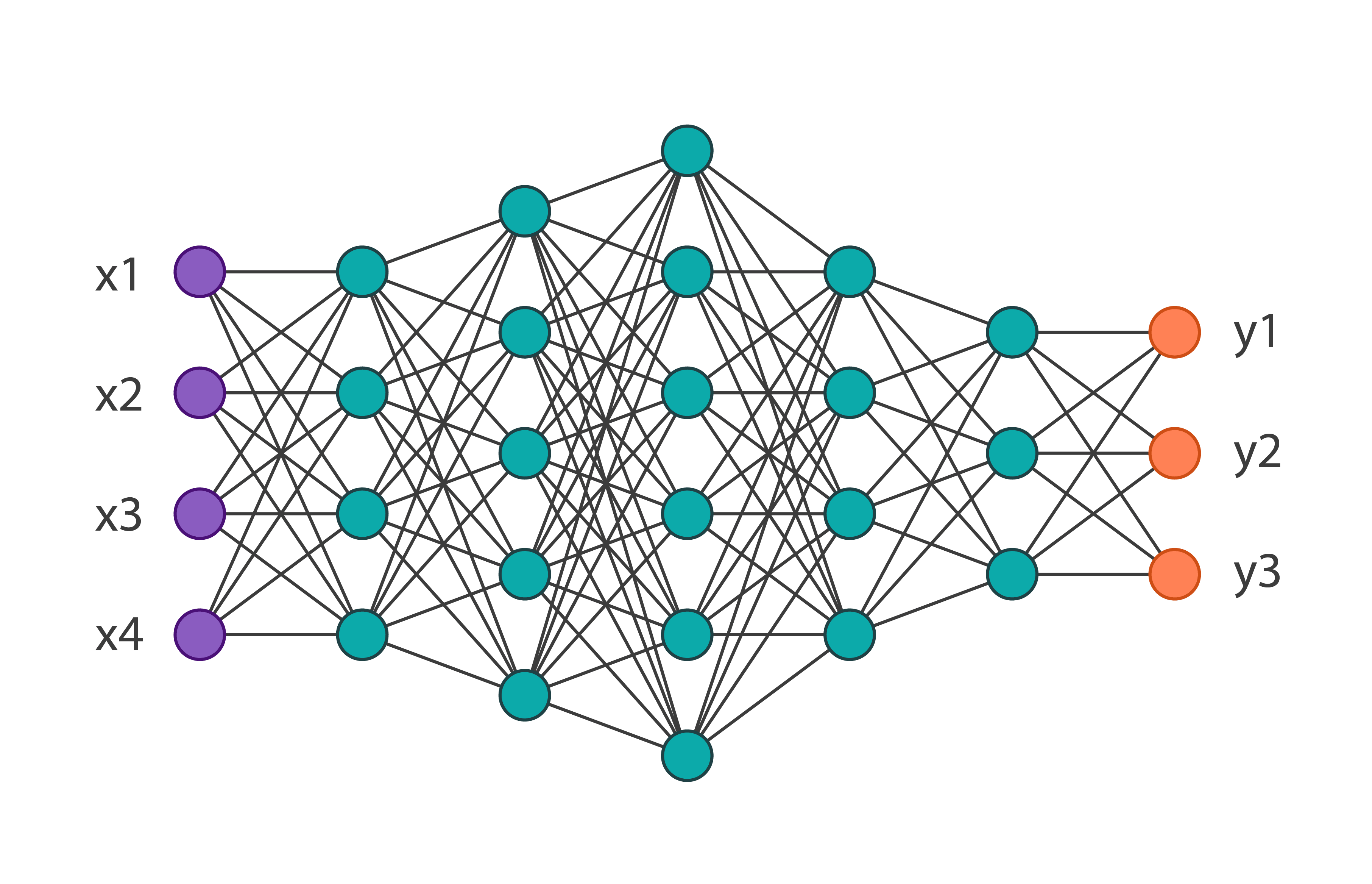
We will get the following network architecture: And we will train it on the MNIST-fashion dataset of 60,000 images. Its accuracy on the verification data will be equal to 0.8594. We apply to the parameters of network 1 iteration of this algorithm. In code, it looks like this:
And we will train it on the MNIST-fashion dataset of 60,000 images. Its accuracy on the verification data will be equal to 0.8594. We apply to the parameters of network 1 iteration of this algorithm. In code, it looks like this:
threshold = 0.001
weights = model.weights
weights = np.asarray(weights)
first_h_layer_weights = weights[1]
second_h_layer_weights = weights[3]
def delete_from_layers(one_d_array, threshold):
index = []
for i in range(one_d_array.shape[0]):
if abs(one_d_array[i]) <= threshold:
index.append(i)
new_layer = np.delete(one_d_array, index)
return new_layer
new_layer_weights = delete_from_layers(second_h_layer_weights, threshold)
Thus, after executing this code, we will get rid of practically unused weights. Two things are worth noting: in this example, the threshold was chosen empirically and this algorithm cannot be applied to the weights of the input and output layers.Having received new weights, it is necessary to redefine the original model, removing the excess. As a result, we get: You can notice that the total number of parameters decreased by almost 2 times, which means that when training the first network, more than half of the parameters were simply unnecessary. At the same time, the accuracy of the subnet is 0.8554, which is slightly lower than the main network. Of course, this example is indicative, usually the network can be reduced by 10-20% of the initial number of parameters. Here, even without applying this algorithm, it is clear that the original architecture was chosen too cumbersome.In conclusion, we can say that this technique is not well developed at the moment, and in real problems, an attempt to optimize the model’s weights in this way can only lengthen the learning process, but the algorithm itself has quite a lot of potential.
You can notice that the total number of parameters decreased by almost 2 times, which means that when training the first network, more than half of the parameters were simply unnecessary. At the same time, the accuracy of the subnet is 0.8554, which is slightly lower than the main network. Of course, this example is indicative, usually the network can be reduced by 10-20% of the initial number of parameters. Here, even without applying this algorithm, it is clear that the original architecture was chosen too cumbersome.In conclusion, we can say that this technique is not well developed at the moment, and in real problems, an attempt to optimize the model’s weights in this way can only lengthen the learning process, but the algorithm itself has quite a lot of potential.