Note perev. : Although this review does not claim to be a carefully designed technical comparison of existing solutions for the permanent storage of data in Kubernetes, it can be a good starting point for administrators who are relevant to this issue. The most attention was paid to the Piraeus solution, familiarity with which will benefit not only Linstor lovers, but also those who have not heard of these projects. This is an unscientific overview of storage solutions for Kubernetes. Problem statement: requires the ability to create a Persistent Volume on the disks of the node, the data of which will be saved in case of damage or restart of the node.The motivation for this comparison is the need to migrate the company's server fleet from multiple dedicated bare metal servers to the Kubernetes cluster.My company is a Brazilian startup Escavador with huge computing needs (mainly CPU) and a very limited budget. We develop NLP solutions for structuring legal data.
This is an unscientific overview of storage solutions for Kubernetes. Problem statement: requires the ability to create a Persistent Volume on the disks of the node, the data of which will be saved in case of damage or restart of the node.The motivation for this comparison is the need to migrate the company's server fleet from multiple dedicated bare metal servers to the Kubernetes cluster.My company is a Brazilian startup Escavador with huge computing needs (mainly CPU) and a very limited budget. We develop NLP solutions for structuring legal data. Due to the crisis with COVID-19, the Brazilian real fell to a record low against the US dollarOur national currency is actually very underestimated, so the average salary of a senior developer is only 2000 USD per month. Thus, we cannot afford the luxury of spending significant amounts on cloud services. When I last made the calculations, [thanks to using my servers] we saved 75% compared to what I would have to pay for AWS. In other words, another developer can be hired for the money saved - I think that this is a much more rational use of funds.Inspired by a series of publications from Vito Botta, I decided to create a K8s cluster using Rancher (and so far so good ...). Vito also performed an excellent analysis of various storage solutions. The clear winner was Linstor (he even singled it out inspecial league ). Spoiler: I agree with him.For some time I have been following the traffic around Kubernetes, but only recently decided to participate in it. This is due primarily to the fact that the provider has a new line of Ryzen processors. And then I was very surprised to see that many solutions are still in development or immature state (especially for bare metal clusters: VM virtualization, MetalLB, etc.). Vaults on bare metal are still in their mature stages, although they are represented by a multitude of commercial and Open Source solutions. I decided to compare the main promising and free solutions (simultaneously testing one commercial product in order to understand what I'm losing). Range of
Due to the crisis with COVID-19, the Brazilian real fell to a record low against the US dollarOur national currency is actually very underestimated, so the average salary of a senior developer is only 2000 USD per month. Thus, we cannot afford the luxury of spending significant amounts on cloud services. When I last made the calculations, [thanks to using my servers] we saved 75% compared to what I would have to pay for AWS. In other words, another developer can be hired for the money saved - I think that this is a much more rational use of funds.Inspired by a series of publications from Vito Botta, I decided to create a K8s cluster using Rancher (and so far so good ...). Vito also performed an excellent analysis of various storage solutions. The clear winner was Linstor (he even singled it out inspecial league ). Spoiler: I agree with him.For some time I have been following the traffic around Kubernetes, but only recently decided to participate in it. This is due primarily to the fact that the provider has a new line of Ryzen processors. And then I was very surprised to see that many solutions are still in development or immature state (especially for bare metal clusters: VM virtualization, MetalLB, etc.). Vaults on bare metal are still in their mature stages, although they are represented by a multitude of commercial and Open Source solutions. I decided to compare the main promising and free solutions (simultaneously testing one commercial product in order to understand what I'm losing). Range of Storage Solutions at CNCF LandscapeBut first of all, I want to warn you that I am new to K8s.For experiments, 4 workers were used with the following configuration: Ryzen 3700X processor, 64 GB ECC memory, NVMe 2 TB in size. Benchmarks were made using the image
Storage Solutions at CNCF LandscapeBut first of all, I want to warn you that I am new to K8s.For experiments, 4 workers were used with the following configuration: Ryzen 3700X processor, 64 GB ECC memory, NVMe 2 TB in size. Benchmarks were made using the image sotoaster/dbench:latest(on fio) with the flag O_DIRECT.Longhorn
I really liked Longhorn. It is fully integrated with Rancher and you can install it through Helm with one click.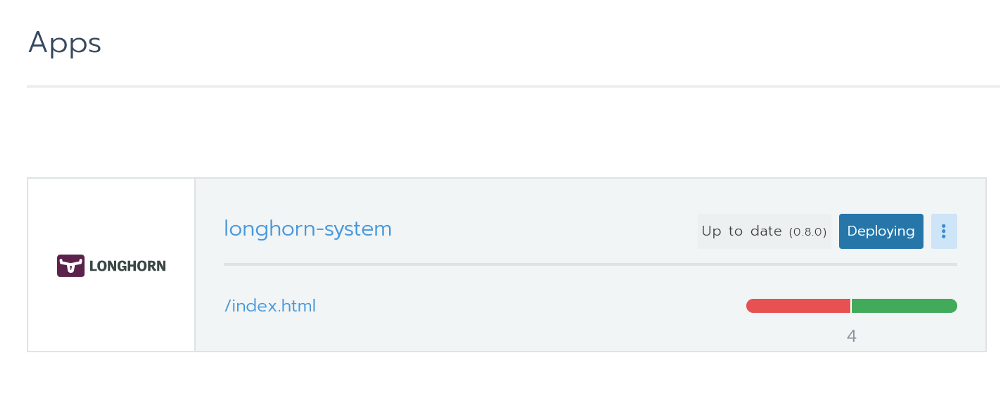 Installing Longhorn from RancherThis is an open source tool with the status of a sandbox project from the Cloud Native Computing Foundation (CNCF). Its development is funded by Rancher - a fairly successful company with a well-known [eponymous] product.
Installing Longhorn from RancherThis is an open source tool with the status of a sandbox project from the Cloud Native Computing Foundation (CNCF). Its development is funded by Rancher - a fairly successful company with a well-known [eponymous] product. An excellent graphical interface is also available - everything can be done from it. With performance, everything is in order. The project is still in beta, which is confirmed by issues on GitHub.When testing, I launched a benchmark using 2 replicas and Longhorn 0.8.0:
An excellent graphical interface is also available - everything can be done from it. With performance, everything is in order. The project is still in beta, which is confirmed by issues on GitHub.When testing, I launched a benchmark using 2 replicas and Longhorn 0.8.0:- Random read / write, IOPS: 28.2k / 16.2k;
- Read / write bandwidth: 205 Mb / s / 108 Mb / s;
- Average read / write latency (usec): 593.27 / 644.27;
- Sequential read / write: 201 Mb / s / 108 Mb / s;
- Mixed random read / write, IOPS: 14.7k / 4904.
Openebs
This project also has CNCF sandbox status. With a large number of stars on GitHub, it looks like a very promising solution. In his review, Vito Botta complained about insufficient performance. Here is what the Mayadata CEO answered him:Information is very outdated. OpenEBS used to support 3, but now it supports 4 engines, if you enable dynamic provisioning and localPV orchestration, which can run at NVMe speeds. In addition, the MayaStor engine is now open and is already receiving positive reviews (although it has alpha status).
On the OpenEBS project page there is such an explanation on its status:OpenEBS — Kubernetes. OpenEBS sandbox- CNCF 2019- , - (local, nfs, zfs, nvme) on-premise, . OpenEBS - stateful- — Litmus Project, — OpenEBS. OpenEBS production 2018 ; 2,5 docker pull'.
It has many engines, and the last one seems quite promising in terms of performance: “MayaStor - alpha engine with NVMe over Fabrics”. Alas, I did not test it because of the alpha version status.In tests, version 1.8.0 was used on the jiva engine. In addition, I previously checked cStor, but did not save the results, which, however, turned out to be slightly slower than jiva. For the benchmark, a Helm chart was installed with all the default settings and the Storage Class, standardly created by Helm ( openebs-jiva-default), was used. Performance turned out to be the worst of all the solutions considered (I would be grateful for advice on improving it).OpenEBS 1.8.0 with jiva engine (3 replicas?):- Random read / write, IOPS: 2182/1527;
- Read / write bandwidth: 65.0 Mb / s / 41.9 Mb / s;
- / (usec): 1825.49 / 2612.87;
- /: 95.5 / / 37.8 /;
- /, IOPS: 2607 / 856.
. Evan Powell, OpenEBS ( , StackStorm Nexenta):, Bruno! OpenEBS . Jiva, ARM overhead' . Bloomberg DynamicLocal PV OpenEBS. Elastic , . , OpenEBS Director (https://account.mayadata.io/signup). — , .
StorageOS
This is a commercial solution that is free when using up to 110 GB of space. A free developer license can be obtained by registering through the product user interface; It gives up to 500 GB of space. In Rancher, it is listed as a partner, so the installation using Helm was easy and carefree.The user is offered a basic control panel. Testing of this product was limited because it is commercial and does not suit us in value. But still I wanted to see what commercial projects are capable of.The test uses the existing Storage Class called “Fast” (Template 0.2.19, 1 Master + 0 Replica?). The results were amazing. They significantly exceeded previous solutions.- Random read / write, IOPS: 117k / 90.4k;
- Read / write bandwidth: 2124 Mb / s / 457 Mb / s;
- Average read / write latency (usec): 63.44 / 86.52;
- Sequential read / write: 1907 Mb / s / 448 Mb / s;
- Mixed random read / write, IOPS: 81.9k / 27.3k.
Piraeus (based on Linstor)
License: GPLv3The already mentioned Vito Botta eventually settled on Linstor, which was an additional reason to try this solution. At first glance, the project looks rather strange. There are almost no stars on GitHub, an unusual name and it does not even exist on CNCF Landscape. But upon closer inspection, everything is not so scary, because:- DRBD is used as the basic replication mechanism (in fact, it was developed by the same people). At the same time, DRBD 8.x has been part of the official Linux kernel for more than 10 years. And we are talking about technology that has been honed for over 20 years.
- Media is controlled by LINSTOR, also a mature technology from the same company. The first version of Linstor-server appeared on GitHub in February 2018. It is compatible with various technologies / systems such as Proxmox, OpenNebula and OpenStack.
- Apparently, Linbit is actively developing the project, constantly introducing new features and improvements into it. The 10th version of DRBD still has alpha status , but it already boasts some unique features, such as erasure coding (similar to the functionality from RAID5 / 6 - approx. Transl.) .
- The company takes certain measures to become one of the CNCF projects.
Okay, the project looks convincing enough to entrust him with its precious data. But is he able to replay alternatives? Let's get a look.Installation
Vito talks about installing Linstor here . However, in the comments, one of the Linstor developers recommends a new project called Piraeus. As I understand it, Piraeus is becoming the Linbit Open Source project, which combines everything related to K8s. The team is working on the appropriate operator , but for now, Piraeus can be installed using this YAML file:kubectl apply -f https://raw.githubusercontent.com/bratao/piraeus/master/deploy/all.yaml
Attention! You pick up configs from my personal repository. Check out the official repository! I updated the version of the images to solve the error that occurs when using in Ubuntu.The official Piraeus repository is available here .You can also use the kvaps repository (it seems even more dynamic than the official piraeus repository): https://github.com/kvaps/kube-linstor (take this opportunity to say hello to Andreykvaps- approx. perev.) . All nodes work after installation
All nodes work after installationAdministration
Administration is carried out using the command line. Access to it is possible from the command shell of the piraeus-controller node. The controller node is running linstor-server. It is an abstraction layer over drbd, capable of managing the entire fleet of nodes. The screenshot below shows some useful commands for the most popular tasks, for example:
The controller node is running linstor-server. It is an abstraction layer over drbd, capable of managing the entire fleet of nodes. The screenshot below shows some useful commands for the most popular tasks, for example:linstor node list - display a list of connected nodes and their status;linstor volume list - show a list of created volumes and their location;linstor node info - show the capabilities of each node.
 Linstor Commands Acomplete list of commands is available in the official documentation: User´s Guide LINSTOR .In the event of situations like split brain, drbd can be accessed directly through the nodes.
Linstor Commands Acomplete list of commands is available in the official documentation: User´s Guide LINSTOR .In the event of situations like split brain, drbd can be accessed directly through the nodes.Disaster Recovery
I did my best to drop my cluster, including hard reset on nodes. But linstor was surprisingly tenacious.Drbd perfectly recognizes a problem called split brain. In my situation, the secondary node fell out of replication.Split brain — , - , - Primary, «» . , . , , .
Split brain DRBD , , Heartbeat.
Details can be found in drbd 's official documentation . The secondary node fell out of replication.In my case, to solve the problem, I dropped the secondary data and started synchronization with the primary node. Since I prefer graphical interfaces, I used the drbdtop utility for this. With its help, you can visually monitor the status and execute commands within nodes.I needed to go into the console on the problem node piraues (it was
The secondary node fell out of replication.In my case, to solve the problem, I dropped the secondary data and started synchronization with the primary node. Since I prefer graphical interfaces, I used the drbdtop utility for this. With its help, you can visually monitor the status and execute commands within nodes.I needed to go into the console on the problem node piraues (it was worker2-gpu): Go to the nodeThere I installed drdbtop. Download this utility here:
Go to the nodeThere I installed drdbtop. Download this utility here:wget https://github.com/LINBIT/drbdtop/releases/download/v0.2.2/drbdtop-linux-amd64
chmod +x drbdtop-linux-amd64
./drbdtop-linux-amd64
 Running drbdtop utilityTake a look at the bottom panel. There are commands on it that can be used to fix the split brain:
Running drbdtop utilityTake a look at the bottom panel. There are commands on it that can be used to fix the split brain: After that, the nodes are connected and synchronized automatically.
After that, the nodes are connected and synchronized automatically.How to increase the speed?
By default, Piraeus / Linstor / drbd show excellent performance (you can see this below). The default settings are reasonable and safe. However, the write speed was rather weak. Since the servers in my case are scattered across different data centers (although physically they are relatively close), I decided to try to tune their performance.The starting point for optimization is defining a replication protocol. By default, Protocol C is used, which waits for write confirmation on the remote secondary node. The following is a description of the possible protocols:- Protocol A — . , , TCP- . , TCP . .
- Protocol B — . , , .
- Protocol C ( ) — . .
Because of this, in Linstor I also use the asynchronous protocol (it supports synchronous / semi-synchronous / asynchronous replication). You can enable it with the following command:linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 1085760 --rcvbuf-size 1085760 --c-max-rate 4194304 --c-fill-target 1048576
The result of its implementation will be the activation of the asynchronous protocol and an increase in the buffer up to 1 MB. It is relatively safe. Or you can use the following command (it ignores disk flushes and significantly increases the buffer):linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 10485760 --rcvbuf-size 10485760 --disk-barrier no --disk-flushes no --c-max-rate 4194304 --c-fill-target 1048576
Note that if the primary node fails, a small portion of the data may not reach the replicas.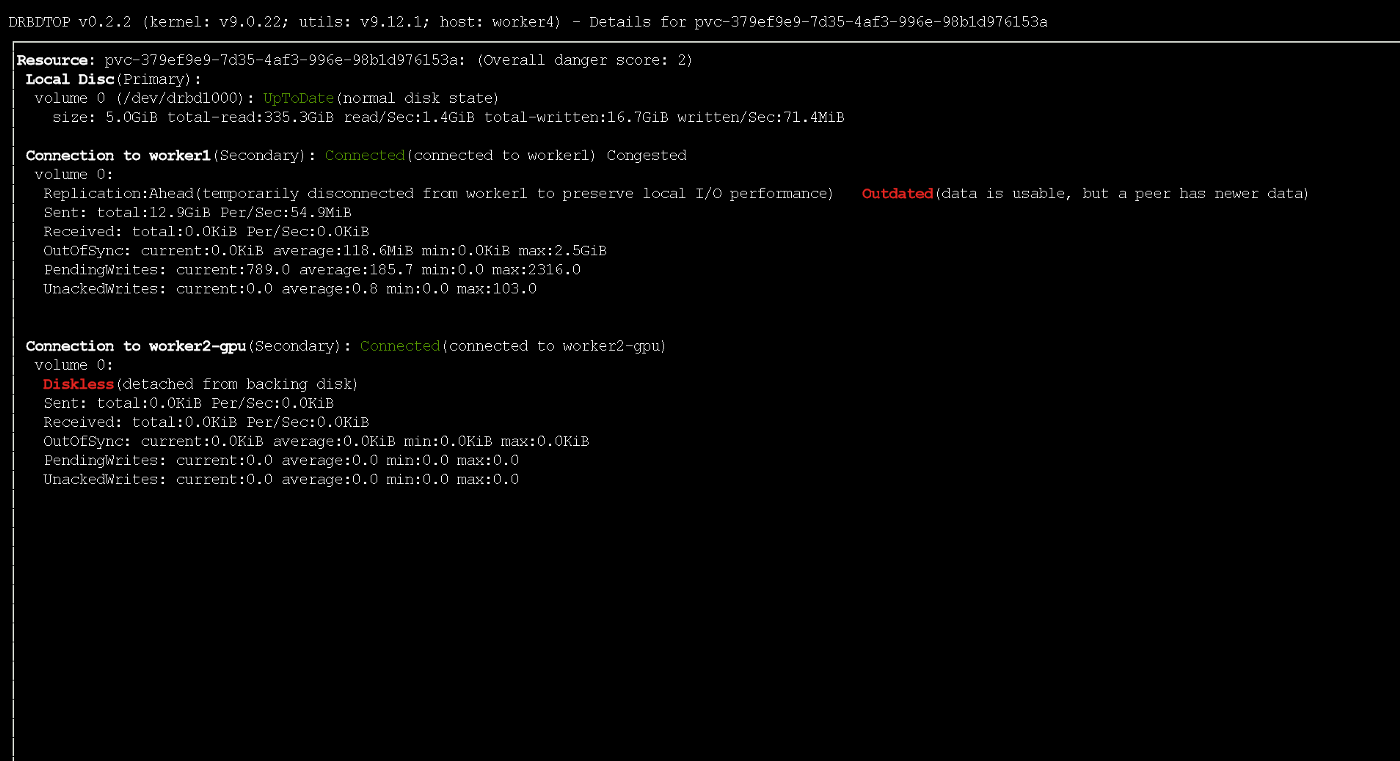 During active recording, the node temporarily received outdated status using the ASYNC protocol
During active recording, the node temporarily received outdated status using the ASYNC protocolTesting
All benchmarks were conducted using the following Job:kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: dbench
spec:
storageClassName: STORAGE_CLASS
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
---
apiVersion: batch/v1
kind: Job
metadata:
name: dbench
spec:
template:
spec:
containers:
- name: dbench
image: sotoaster/dbench:latest
imagePullPolicy: IfNotPresent
env:
- name: DBENCH_MOUNTPOINT
value: /data
- name: FIO_SIZE
value: 1G
volumeMounts:
- name: dbench-pv
mountPath: /data
restartPolicy: Never
volumes:
- name: dbench-pv
persistentVolumeClaim:
claimName: dbench
backoffLimit: 4
The delay between the machines is as follows: ttl=61 time=0.211 ms. The measured throughput between them was 943 Mbps. All nodes are running Ubuntu 18.04. Results ( table on sheetsu.com )
As can be seen from the table, Piraeus and StorageOS showed the best results. The leader was Piraeus with two replicas and an asynchronous protocol.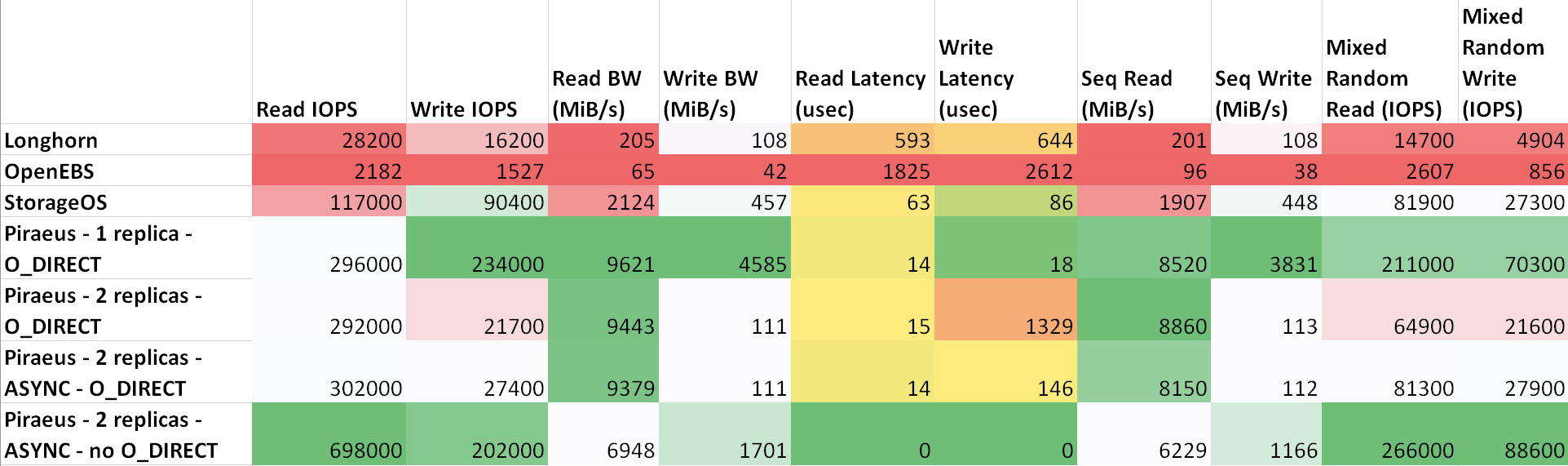
findings
I made a simple and perhaps not too correct comparison of some storage solutions in Kubernetes.Most of all I liked Longhorn because of its nice GUI and integration with Rancher. However, the results are not inspiring. Obviously, developers primarily focus on security and correctness, leaving speed for later.For some time now I have been using Linstor / Piraeus in the production environments of some projects. So far, everything was fine: disks were created and deleted, nodes were restarted without downtime ...In my opinion, Piraeus is quite ready for use in production, but needs to be improved. I wrote about some bugs in the project channel in Slack, but in response they only advised me to teach Kubernetes (and this is correct, since I still do not understand it well). After a little correspondence, I still managed to convince the authors that there was a bug in their init script. Yesterday, after updating the kernel and rebooting, the node refused to boot. It turned out that compiling the script that integrates the drbd module into the kernel failed . Rollback to the previous kernel version solved the problem.That’s all, in general. Given that they implemented it on top of drbd, it turned out to be a very reliable solution with excellent performance. In case of any problems, you can directly contact drbd management and fix it. On the Internet there are many questions and examples on this topic.If I did something wrong, if something can be improved or you need help, contact me on Twitter or on GitHub .PS from the translator
Read also in our blog: