From a Google Blog Editor: Have you ever wondered how Google Cloud Technical Solutions (TSE) engineers handle your technical support calls? The responsibility of the TSE Technical Support Engineers is to detect and resolve the sources of problems identified by users. Some of these problems are quite simple, but sometimes you come across an appeal requiring the attention of several engineers at once. In this article, one of the TSE employees will tell us about one very tricky problem from his recent practice - the case of missing DNS packets. In the course of this story, we will see how the engineers managed to resolve the situation, and what new things they learned in the course of eliminating the error. We hope that this story will not only tell you about a deep-rooted bug, but also provide an understanding of the processes that occur when submitting a request to support Google Cloud. Troubleshooting is both a science and an art. It all starts with building a hypothesis about the cause of the non-standard behavior of the system, after which it is tested for strength. However, before formulating a hypothesis, we must clearly identify and accurately formulate the problem. If the question sounds too vague then you have to analyze everything properly; this is the "art" of troubleshooting.In the context of Google Cloud, such processes are complicated at times, since Google Cloud is struggling to guarantee the privacy of its users. Because of this, TSE engineers have neither access to edit your systems, nor the ability to view configurations as widely as users do. Therefore, to test any of our hypotheses, we (engineers) cannot quickly modify the system.Some users believe that we will fix everything as if the mechanics in the car service, and simply send us the id of the virtual machine, whereas in reality the process proceeds in the format of a conversation: collecting information, generating and confirming (or refuting) hypotheses, and, ultimately, solving problems are built on communication with the client.
Troubleshooting is both a science and an art. It all starts with building a hypothesis about the cause of the non-standard behavior of the system, after which it is tested for strength. However, before formulating a hypothesis, we must clearly identify and accurately formulate the problem. If the question sounds too vague then you have to analyze everything properly; this is the "art" of troubleshooting.In the context of Google Cloud, such processes are complicated at times, since Google Cloud is struggling to guarantee the privacy of its users. Because of this, TSE engineers have neither access to edit your systems, nor the ability to view configurations as widely as users do. Therefore, to test any of our hypotheses, we (engineers) cannot quickly modify the system.Some users believe that we will fix everything as if the mechanics in the car service, and simply send us the id of the virtual machine, whereas in reality the process proceeds in the format of a conversation: collecting information, generating and confirming (or refuting) hypotheses, and, ultimately, solving problems are built on communication with the client.Issue under consideration
Today we have a story with a good ending. One of the reasons for the successful solution of the proposed case is a very detailed and accurate description of the problem. Below you can see a copy of the first ticket (edited, in order to hide confidential information): This message has a lot of useful information for us:
This message has a lot of useful information for us:- Specified VM
- The problem is indicated - DNS does not work
- It is indicated where the problem manifests itself - VM and container
- The steps that the user took to identify the problem are indicated.
The appeal was registered as “P1: Critical Impact - Service Unusable in production”, which means constant monitoring of the situation 24/7 according to the “Follow the Sun” scheme (the link can be read in more detail about the priorities of user calls ), with the transfer of it from one technical support team to the other at each timezone shift. In fact, by the time the problem reached our team in Zurich, she managed to circumnavigate the globe. By this time, the user took measures to reduce the consequences, however, he was afraid of a repetition of the situation on the production, since the main reason was still not found.By the time the ticket reached Zurich, we already had the following information on hand:- Content
/etc/hosts - Content
/etc/resolv.conf - Conclusion
iptables-save - The
ngreppcap file compiled by the command
With this data, we were ready to begin the “investigation” and troubleshooting phase.Our first steps
First of all, we checked the logs and status of the metadata server and made sure that it works correctly. The metadata server responds with IP address 169.254.169.254 and, among other things, is responsible for controlling domain names. We also double-checked that the firewall works correctly with VM and does not block packets.It was some strange problem: the nmap test refuted our main hypothesis about the loss of UDP packets, so we mentally deduced several more options and ways to check them:- Do packets disappear selectively? => Check iptables rules
- Is the MTU too small ? => Check output
ip a show - Does the problem affect only UDP packets or TCP? => Drive away
dig +tcp - Are generated dig packets returned? => Drive away
tcpdump - Does libdns work correctly? => Drive away
straceto verify packet transfer in both directions
Here we decide to phone the user to troubleshoot live.During the call, we manage to verify several things:- After several checks, we exclude iptables rules from the list of reasons.
- We check network interfaces and routing tables, and double-check the MTU
- We find that
dig +tcp google.com(TCP) is working as it should, but dig google.com(UDP) is not working - Having
tcpdumprun while it works dig, we find that UDP packets are being returned - We run
strace dig google.comand see how dig correctly calls sendmsg()and recvms(), however, the second is interrupted by timeout
Unfortunately, the shift is about to end and we are forced to transfer the problem to the next time zone. The appeal, however, aroused interest in our team, and a colleague suggests creating the source DNS packet with the Python module scrapy.from scapy.all import *
answer = sr1(IP(dst="169.254.169.254")/UDP(dport=53)/DNS(rd=1,qd=DNSQR(qname="google.com")),verbose=0)
print ("169.254.169.254", answer[DNS].summary())
This fragment creates a DNS packet and sends the request to the metadata server.The user runs the code, the DNS response is returned, and the application receives it, which confirms the absence of a problem at the network level.After the next "round-the-world trip", the appeal returns to our team, and I completely translate it onto myself, believing that it will be more convenient for the user if the appeal ceases to circle from place to place.In the meantime, the user kindly agrees to provide a snapshot of the system image. This is very good news: the ability to test the system yourself significantly speeds up troubleshooting, because you no longer need to ask the user to run commands, send me results and analyze them, I can do everything myself!Colleagues are beginning to envy me a little. At lunch, we discuss the appeal, but no one has any idea what is going on. Fortunately, the user himself has already taken mitigation measures and is in no hurry, so we have time to prepare the problem. And since we have an image, we can conduct any tests that interest us. Fine!Going back a step
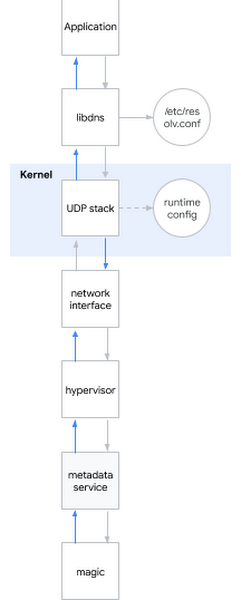
One of the most popular questions in an interview for a systems engineer is: “What happens when you ping www.google.com ?” The question is posh, because the candidate needs to be described from the shell to the user space, to the core of the system and further to the network. I smile: sometimes interview questions are also useful in real life ...I decide to apply this eychar question to the current problem. Roughly speaking, when you try to determine the DNS name, the following happens:- The application calls the system library, for example libdns
- libdns checks the system configuration which DNS server it should use (in the diagram it is 169.254.169.254, metadata server)
- libdns uses system calls to create a UDP socket (SOKET_DGRAM) and send UDP packets with a DNS request in both directions
- Using the sysctl interface, you can configure the kernel-level UDP stack
- The kernel interacts with the hardware to transmit packets over the network through a network interface
- The hypervisor catches and passes the packet to the metadata server when it comes in contact with it
- The metadata server determines the DNS name by its witchcraft and returns the answer in the same way
 Let me remind you which hypotheses we have already managed to consider:Hypothesis: Broken libraries
Let me remind you which hypotheses we have already managed to consider:Hypothesis: Broken libraries- Test 1: run strace in the system, check that dig causes the correct system calls
- Result: correct system calls are called
- Test 2: through srapy to check if we can determine the names bypassing the system libraries
- Result: we can
- Test 3: run rpm –V on the libdns package and md5sum library files
- Result: the library code is completely identical to the code in the working operating system
- Test 4: mount the image of the user's root system on the VM without this behavior, run chroot, see if DNS works
- Result: DNS is working correctly
Conclusion based on tests: the problem is not in librariesHypothesis: There is an error in the DNS settings- Test 1: check tcpdump and see if DNS packets are sent and returned correctly after running dig
- Result: packets are transmitted correctly
- Test 2: recheck on the server
/etc/nsswitch.confand/etc/resolv.conf - Result: everything is correct
Test-Based Conclusion: The Problem Is Not in DNS ConfigurationHypothesis: Kernel Damaged- Test: install a new kernel, verify the signature, restart
- Result: similar behavior
Conclusion based on tests: the kernel is not damagedHypothesis: incorrect behavior of the user network (or the network interface of the hypervisor)- Test 1: check the firewall settings
- Result: the firewall passes DNS packets on both the host and GCP
- Test 2: intercept traffic and track the correctness of the transfer and return of DNS queries
- Result: tcpdump acknowledges receipt of return packets by the host
Test-based conclusion: the problem is not in the networkHypothesis: metadata server does not work- Test 1: check metadata server logs for anomalies
- Result: there are no anomalies in the logs
- Test 2: bypass the metadata server through
dig @8.8.8.8 - Result: permission is violated even without using a metadata server
Test-based conclusion: the problem is not in the metadata serverBottom line: we tested all the subsystems except the runtime settings!Diving into the kernel runtime settings
To configure the kernel runtime, you can use the command line options (grub) or the sysctl interface. I looked in /etc/sysctl.confand think only, I found a few custom settings. Feeling as if I had grabbed onto something, I dismissed all non-network or non-tcp settings, remaining from the mountain settings net.core. Then I turned to the place where the VM has the host permissions and began to apply one after another, one after another settings with a broken VM, until I reached the criminal:net.core.rmem_default = 2147483647
Here it is, a DNS-breaking configuration! I found an instrument of crime. But why is this happening? I still needed a motive.Setting the base size of the DNS packet buffer occurs through net.core.rmem_default. A typical value varies somewhere within 200KiB, however if your server receives a lot of DNS packets, you can increase the size of the buffer. If the buffer is full at the moment a new package arrives, for example, because the application does not process it fast enough, then you will begin to lose packets. Our client correctly increased the buffer size because he was afraid of data loss, because he used the application for collecting metrics through DNS packets. The value that he set was the maximum possible: 2 31 -1 (if you set 2 31 , the kernel will return “INVALID ARGUMENT”).Suddenly, I realized why nmap and scapy worked correctly: they used raw sockets! Raw sockets are different from regular sockets: they work bypassing iptables, and they are not buffered!But why is “too large a buffer” causing problems? It obviously does not work as intended.At this point, I could reproduce the problem on multiple cores and multiple distributions. The problem has already manifested itself in the 3.x kernel and now also manifested itself in the 5.x kernel.Indeed, at startupsysctl -w net.core.rmem_default=$((2**31-1))
DNS has stopped working.I began to search for working values through a simple binary search algorithm and found that the system works with 2147481343, however this number was a meaningless set of numbers for me. I invited the client to try this number, and he replied that the system worked with google.com, but still gave an error with other domains, so I continued my investigation.I installed dropwatch , a tool that I should have used before: it shows where exactly the package gets in the kernel. The function was guilty udp_queue_rcv_skb. I downloaded the kernel sources and added several functions printk to track where the package gets specifically. I quickly found the right conditionif, and for some time simply stared at him, because it was then that everything finally came together in a whole picture: 2 31 -1, a meaningless number, an idle domain ... It was a piece of code in __udp_enqueue_schedule_skb:if (rmem > (size + sk->sk_rcvbuf))
goto uncharge_drop;
Note:rmem has type intsize is of type u16 (unsigned sixteen bit int) and stores the packet sizesk->sk_rcybuf is of type int and stores the size of the buffer, which by definition is equal to the value in net.core.rmem_default
When sk_rcvbufapproaching 2 31 , summing the packet size can lead to integer overflow . And since it is an int, its value becomes negative, so the condition becomes true when it should be false (more about this can be found by reference ).The error is corrected in a trivial way: by casting to unsigned int. I applied the patch and restarted the system, after which the DNS started working again.Taste of victory
I forwarded my findings to the client and sent the LKML kernel patch. I am satisfied: every piece of the puzzle came together into a single whole, I can precisely explain why we observed what we observed, and most importantly, we were able to find a solution to the problem through working together!It is worth recognizing that the case turned out to be rare, and fortunately, such complex calls are rarely received from users from us.
