Loading CSS on a page is a blocking operation. If asynchronous loading of JavaScript may not be visible to the user, then the slow appearance of styles can drive an impatient guest from the site. How to load CSS as efficiently and seamlessly as possible for users? Nikita Dubko is trying to figure outDarkMeFoDy from the Yandex search interface group in Minsk.- Hello everyone. I'll tell you about the styles. Everyone is talking about TypeScript and TypeScript today. And I will talk about Cascade style script.Shortly about myself. I’m a Belarusian developer - after the film Dudya I’ll say that everywhere. You may have heard my voice in the Web Standards podcast, and if you see typos in the Web Standards news feed, it's probably me too.Little disclaimer. There will be several insanities in the report - treat everything that I say with great criticism. Think about why you can use such techniques, and why you do not need them. Some things will be really crazy. Go.What for?
To begin with - why talk about CSS optimization at all?If you start looking in search engines for fast JS downloads, there are a lot of results. If you look for quick CSS loading, then the top not even displays the CSS that you need.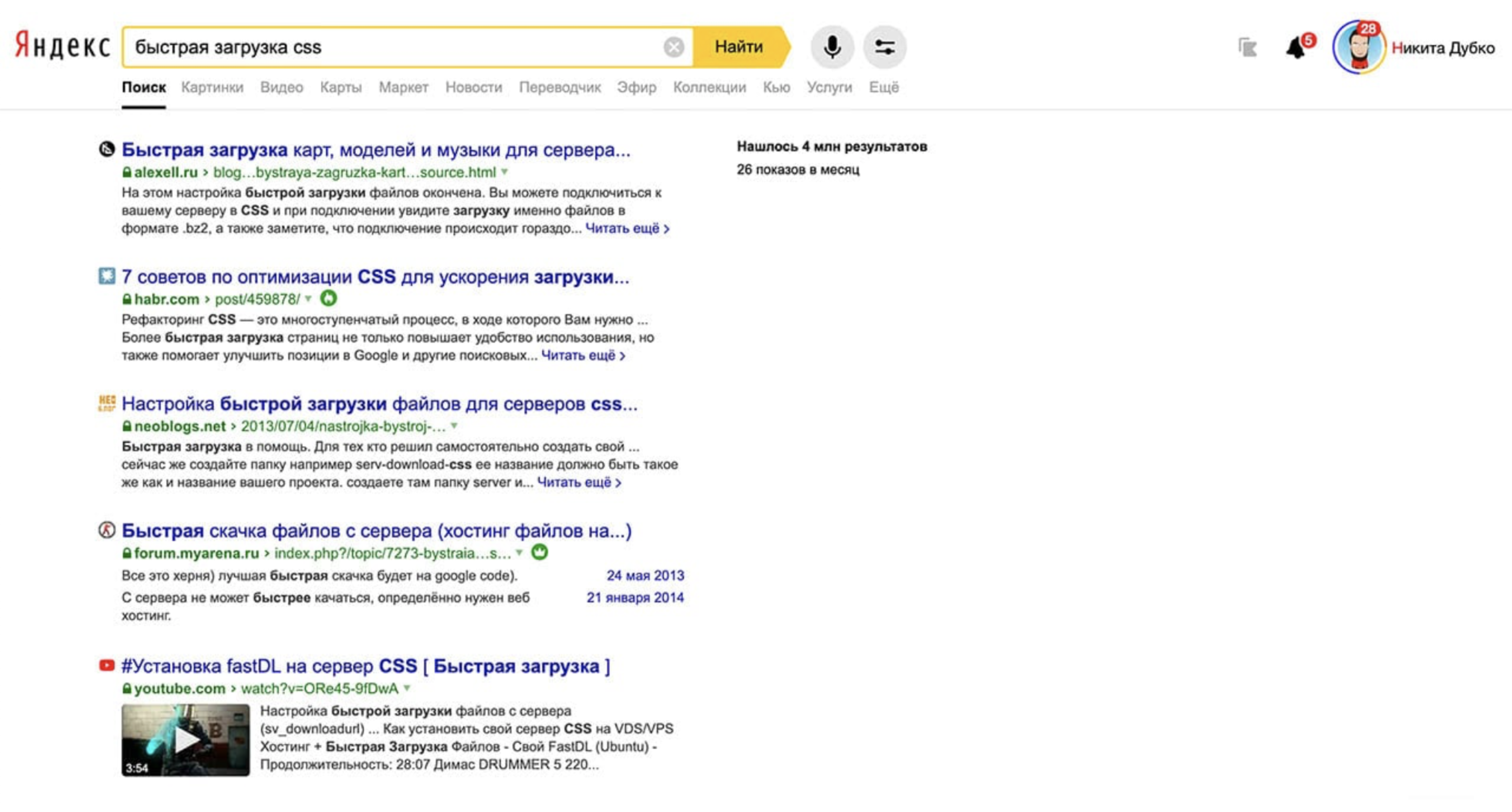 If you look at Google, there are 111 million results about JS, and about CSS just 26 million.So maybe this just doesn't matter? Why talk about it? If you look for JS performance reports, you will find a lot of them. There is about React, about all sorts of other frameworks, about Vanilla, etc. But about CSS, I found only one report. Harry Roberts in 2018 read a cool report about CSS performance. I thought I found a second reportby Roma Dvornova, “Parsim CSS: performance tips & tricks”. But it turned out to be a JS report that parses CSS. Not exactly what we need.It turns out that they don’t think much about CSS. It's a shame.But when I go to the web, I usually see HTML. And I also see CSS that stylizes the page. But I do not see JS. JS is a thing that moves CSS and HTML on a page to make everything look beautiful. This is a script. And if JS doesn't load, it's not as bad as if CSS doesn't load.Errors in JS fall silently into the console. And the average user is unlikely to get into DevTools to look: "Oh, you have it there, a mistake in the console." But if CSS does not load, then you may not see everything you need at all.By the way, there are studies about the fact that the main thing is to make a first impression.38% of users can go to the site, and if they see that it is directly disgusting, they will leave immediately. And 88% will tolerate, use it once, and then they will never return and are unlikely to advise your site.Now that we are all sitting at home, Internet traffic has especially grown. And we need to think about how to efficiently deliver any resources to users.Let's try to count from the point of view of Yandex. If we can optimize every Yandex delivery for 100 ms and give, say, 200 million pages per day (I don’t know the exact number), then this day we will save 0.1 s * 200 million = 232 person-days. Just by optimizing the output for 100 milliseconds. And CSS does that too.Let's play a little detectives and find out how to get the most out of loading styles.
If you look at Google, there are 111 million results about JS, and about CSS just 26 million.So maybe this just doesn't matter? Why talk about it? If you look for JS performance reports, you will find a lot of them. There is about React, about all sorts of other frameworks, about Vanilla, etc. But about CSS, I found only one report. Harry Roberts in 2018 read a cool report about CSS performance. I thought I found a second reportby Roma Dvornova, “Parsim CSS: performance tips & tricks”. But it turned out to be a JS report that parses CSS. Not exactly what we need.It turns out that they don’t think much about CSS. It's a shame.But when I go to the web, I usually see HTML. And I also see CSS that stylizes the page. But I do not see JS. JS is a thing that moves CSS and HTML on a page to make everything look beautiful. This is a script. And if JS doesn't load, it's not as bad as if CSS doesn't load.Errors in JS fall silently into the console. And the average user is unlikely to get into DevTools to look: "Oh, you have it there, a mistake in the console." But if CSS does not load, then you may not see everything you need at all.By the way, there are studies about the fact that the main thing is to make a first impression.38% of users can go to the site, and if they see that it is directly disgusting, they will leave immediately. And 88% will tolerate, use it once, and then they will never return and are unlikely to advise your site.Now that we are all sitting at home, Internet traffic has especially grown. And we need to think about how to efficiently deliver any resources to users.Let's try to count from the point of view of Yandex. If we can optimize every Yandex delivery for 100 ms and give, say, 200 million pages per day (I don’t know the exact number), then this day we will save 0.1 s * 200 million = 232 person-days. Just by optimizing the output for 100 milliseconds. And CSS does that too.Let's play a little detectives and find out how to get the most out of loading styles.Measure!
The very first advice is to always measure everything. There is no point in doing optimizations theoretically. You can assume that optimization works in your case, but real measurements will show that nothing of the kind. This is the most important rule of any optimization. Andrei Prokopyuk from the SERP Velocity team on HolyJS spoke very well about how we do this , I will not repeat myself.What measurement tools are there?- If you want to measure on more or less real devices, slow, not as cool as yours, use WebPageTest . I usually take measurements there.- You have Lighthouse if you use Chromium-based browsers. He, like local measurements, shows quite good things.- If you are sure that you can do everything yourself, go to DevTools, to the Performance tab. It has a lot of details, you can start your own metrics and analyze them. Naturally, in Performance it is necessary to set real conditions. You are sitting on your cool laptop with cool Internet in the office, everything is amazing right here, but they come to you and say: “I'm slow.” And you say: "Everything works for me." Do not do like this.Always try to check how the user in the conditions of the subway or somewhere else will use your site. To do this, you need to set up a very slow Internet. It is also advisable to slow down the CPU, because someone can come to you from some Nokia 3110. He also needs to show the site.Most important: measure on real users. There is such a metric, more precisely, a whole set of metrics - RUM, Real User Monitoring. This is when you measure not what synthetically happens in your code, but metrics on real users in production. For example, from loading a page to an action. An action is, for example, something that works in the browser or even a click on some important element.Remember that you are not developing for robots. Sotka in Lighthouse - it's great, it's really good. So, you fulfill at least the requirements that the Lighthouse sets. But there are real users, and if the user is unable to see the page when heaving in Lighthouse, then you are doing something wrong.
Naturally, in Performance it is necessary to set real conditions. You are sitting on your cool laptop with cool Internet in the office, everything is amazing right here, but they come to you and say: “I'm slow.” And you say: "Everything works for me." Do not do like this.Always try to check how the user in the conditions of the subway or somewhere else will use your site. To do this, you need to set up a very slow Internet. It is also advisable to slow down the CPU, because someone can come to you from some Nokia 3110. He also needs to show the site.Most important: measure on real users. There is such a metric, more precisely, a whole set of metrics - RUM, Real User Monitoring. This is when you measure not what synthetically happens in your code, but metrics on real users in production. For example, from loading a page to an action. An action is, for example, something that works in the browser or even a click on some important element.Remember that you are not developing for robots. Sotka in Lighthouse - it's great, it's really good. So, you fulfill at least the requirements that the Lighthouse sets. But there are real users, and if the user is unable to see the page when heaving in Lighthouse, then you are doing something wrong. There are metrics that are important to focus on. This is First Contentful Paint, when the first content appears on your page with which you can do something, read. This metric is sent in Chromium browsers, you can get it.
There are metrics that are important to focus on. This is First Contentful Paint, when the first content appears on your page with which you can do something, read. This metric is sent in Chromium browsers, you can get it. Recently, you can still look at Largest Contentful Paint. It often happens that you have a media page, and it is important, for example, to look at a photo on it. Then you need this particular metric.
Recently, you can still look at Largest Contentful Paint. It often happens that you have a media page, and it is important, for example, to look at a photo on it. Then you need this particular metric.CSS loading
Let's finally move on to CSS, how CSS is loaded. Receptions have long been known. There is a Critical Rendering Path, a critical rendering path. It is about what the browser does from the moment of sending the request for the resource to the moment the pixels are displayed on the screen of the user. About this, too, there are a bunch of articles and reports. But let's take a quick look at how this browser does it.<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>CSS — </title>
<link rel="stylesheet" href="/main.ac74gsac.css">
</head>
He begins to download HTML, sees tags. He gradually parses them, understands what to do with them. Loads. Came across link. It must be used. But how? First you need to download it. Downloading is slow. When it loads, it starts parsing the page further. <!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>CSS — </title>
<link rel="stylesheet" href="/main.ac74gsac.css">
</head>
<body>
<h1>-!</h1>
</body>
</html>
If it stumbles upon another link, it is blocked again and does not allow execution. Blocks JS, blocks parsing. And until it boots, it does nothing. But then it starts to work further.<link>
Let's dig deeper - what happens when you access the link? Recording where we go is standard. There is a CSS style that lies somewhere. Now it’s fashionable to put all the statics on the CDN.
Recording where we go is standard. There is a CSS style that lies somewhere. Now it’s fashionable to put all the statics on the CDN.Where to go?
First, the browser needs to understand where to go. He sees the URL, and he needs to understand this URL - what is it about? We are used to the fact that the URL is a site identifier.
He sees the URL, and he needs to understand this URL - what is it about? We are used to the fact that the URL is a site identifier.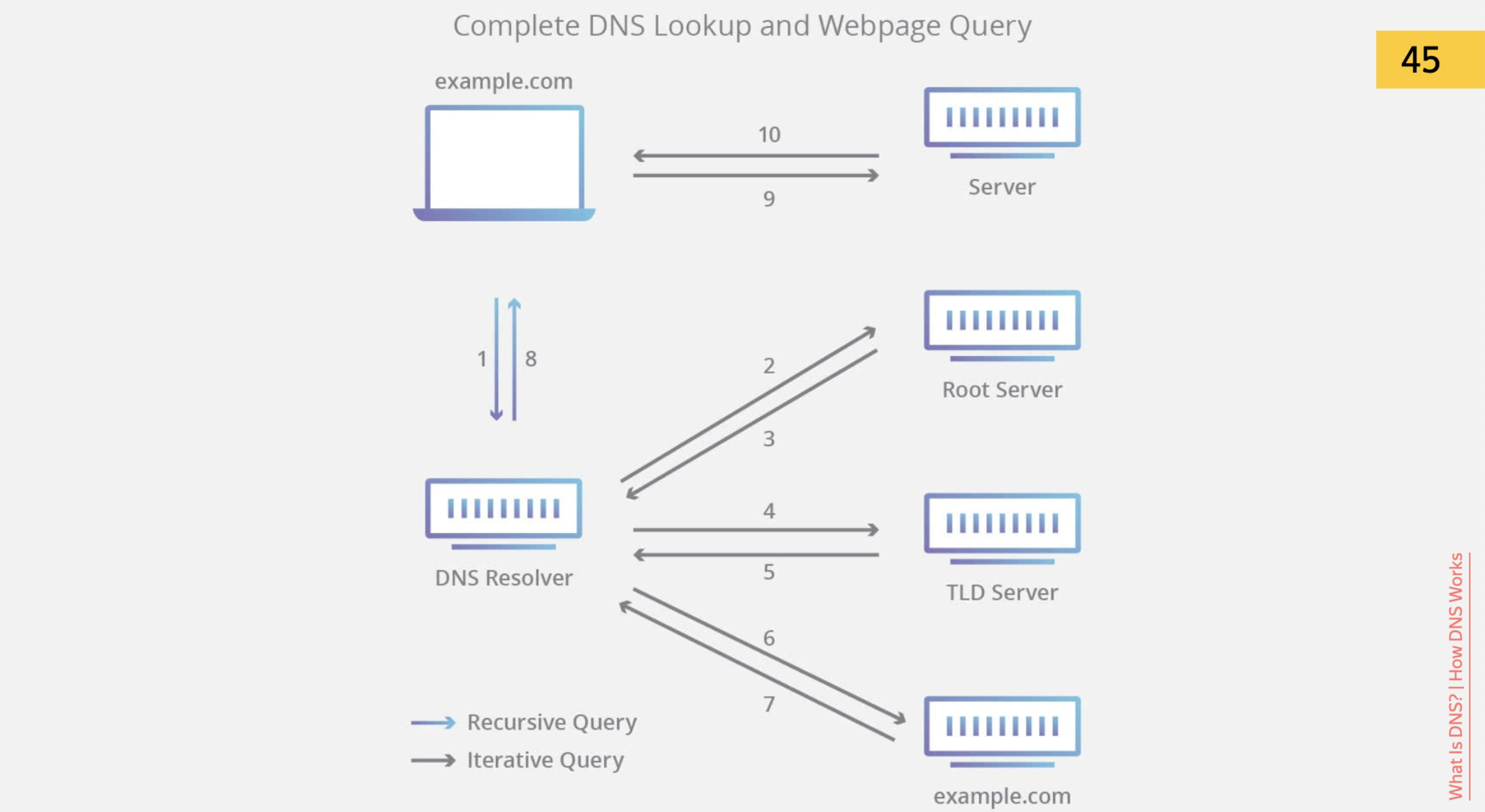 But physically we need to get the IP address of this URL and go to the real physical machine at the IP address.
But physically we need to get the IP address of this URL and go to the real physical machine at the IP address. For your CDN, it will receive a record in DNS and will actually go directly to the IP address. How can one accelerate in this case?
For your CDN, it will receive a record in DNS and will actually go directly to the IP address. How can one accelerate in this case? A crazy idea is to reduce the distance from the user to the DNS server. Take and transplant the user. For example, to display the message: “Sit closer” or “Move closer”.You can immediately specify the IP address in the link. Why do we need to look for DNS, resolve domains, if you can immediately give the result by IP address? This is a crazy way, but in the case of DDoS global DNS servers it can even save you.And we can get rid of getting an IP address.
A crazy idea is to reduce the distance from the user to the DNS server. Take and transplant the user. For example, to display the message: “Sit closer” or “Move closer”.You can immediately specify the IP address in the link. Why do we need to look for DNS, resolve domains, if you can immediately give the result by IP address? This is a crazy way, but in the case of DDoS global DNS servers it can even save you.And we can get rid of getting an IP address. Turning to your index.html or to another file, you already know the domain address where you go. Here is just the case when, instead of storing statics on a separate domain or subdomain, you can put the statics closer to your domain, namely this domain itself. Then DNS does not need to be resolved, it already is.
Turning to your index.html or to another file, you already know the domain address where you go. Here is just the case when, instead of storing statics on a separate domain or subdomain, you can put the statics closer to your domain, namely this domain itself. Then DNS does not need to be resolved, it already is. We figured out where to go. But we can do such things for the browser in advance. If, for example, your style sheet is loaded much later via the DOM tree, you can tell the browser using <link rel = "dns-prefetch"> that "I don’t go there yet, but you’ll warm up the resources, I’ll definitely need them later ".With this entry, you tell the browser to go down and get this DNS. When link appears in the code, the browser will already know the IP address of this domain. You can do such preliminary things. The same thing, for example, before entering the next page, where you will definitely go.Ok, the browser knows where to go. He needs to understand how to go.
We figured out where to go. But we can do such things for the browser in advance. If, for example, your style sheet is loaded much later via the DOM tree, you can tell the browser using <link rel = "dns-prefetch"> that "I don’t go there yet, but you’ll warm up the resources, I’ll definitely need them later ".With this entry, you tell the browser to go down and get this DNS. When link appears in the code, the browser will already know the IP address of this domain. You can do such preliminary things. The same thing, for example, before entering the next page, where you will definitely go.Ok, the browser knows where to go. He needs to understand how to go.How to go
We are watching the protocol. Now, of course, https is a direct requirement. Including search engines will mark your sites not on https with forms as not entirely safe.I found an amazing series of comics about how the board works https. But we are IT people, we love cool complex diagrams, and funny comics are too easy. Here I have formulated in my own words how https works. First you get an SSL certificate from your server. Then you must check the certificate at a certification authority. These are special servers that know what is valid and what is not, and can prompt browsers: “yes, everything is fine here, use this certificate”.Next is the generation of keys for communication between the server and the client, encryption, decryption using different keys. The process is interesting if you look at it in terms of cryptography. But we want to speed up. How?
Here I have formulated in my own words how https works. First you get an SSL certificate from your server. Then you must check the certificate at a certification authority. These are special servers that know what is valid and what is not, and can prompt browsers: “yes, everything is fine here, use this certificate”.Next is the generation of keys for communication between the server and the client, encryption, decryption using different keys. The process is interesting if you look at it in terms of cryptography. But we want to speed up. How? We can again transfer the user closer to the servers. We already have a DNS, now we can put it closer to the certification authority. And to put between these servers will be perfect.You can opt out of https, why do we need it? We spend time getting a certificate, encrypt, decrypt. Not really. This is the most harmful advice in the report, do not do so. https is user data protection, and http / 2 will not work without https, and http / 2 is another way to speed up.There is also OCSP Stapling technology. You can verify a certificate without a certification authority. This is probably closer to DevOps. You need to configure your server in a certain way so that it can cache the response of the Certification Authority and issue to the user: "Believe me, my certificate is really real." Thus, we can save at least the step at which we go to the Certification Authority.But there is a nuance - in Chrome this does not work, and for a long time. But for the user of other browsers, you can speed up this process.I have already said twice that it’s necessary to transplant the user, and the idea is soaring in the air - to move the server closer to the user. I have not discovered anything new for you. This is a CDN, a distributed content delivery network. The idea is that you can use ready-made sidienki, independently create your own infrastructure and put a bunch of servers around the world, as far as money and opportunities allow you. But you need to arrange the server so that a user from Australia goes to Australian servers. Here the speed of light plays on you, the smaller the distance, the faster the electrons pass it.Let's dig deeper. What else is going on in the request? In fact, https is just a wrapper over http. Not just a cool wrapper. And if it’s even deeper, then http is such a request from the TCP / IP family.
We can again transfer the user closer to the servers. We already have a DNS, now we can put it closer to the certification authority. And to put between these servers will be perfect.You can opt out of https, why do we need it? We spend time getting a certificate, encrypt, decrypt. Not really. This is the most harmful advice in the report, do not do so. https is user data protection, and http / 2 will not work without https, and http / 2 is another way to speed up.There is also OCSP Stapling technology. You can verify a certificate without a certification authority. This is probably closer to DevOps. You need to configure your server in a certain way so that it can cache the response of the Certification Authority and issue to the user: "Believe me, my certificate is really real." Thus, we can save at least the step at which we go to the Certification Authority.But there is a nuance - in Chrome this does not work, and for a long time. But for the user of other browsers, you can speed up this process.I have already said twice that it’s necessary to transplant the user, and the idea is soaring in the air - to move the server closer to the user. I have not discovered anything new for you. This is a CDN, a distributed content delivery network. The idea is that you can use ready-made sidienki, independently create your own infrastructure and put a bunch of servers around the world, as far as money and opportunities allow you. But you need to arrange the server so that a user from Australia goes to Australian servers. Here the speed of light plays on you, the smaller the distance, the faster the electrons pass it.Let's dig deeper. What else is going on in the request? In fact, https is just a wrapper over http. Not just a cool wrapper. And if it’s even deeper, then http is such a request from the TCP / IP family.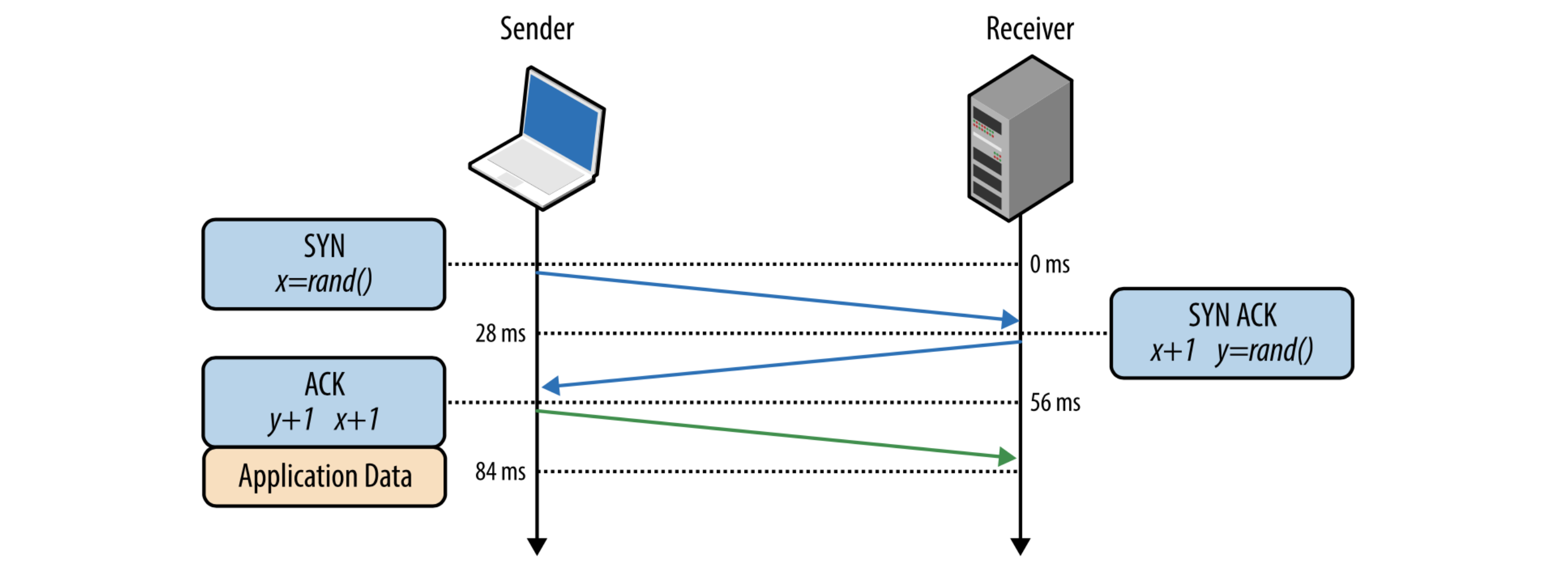 How are packets and bytes sent on the network so that all browsers, clients and servers communicate with each other? The first thing a client / server does over a TCP / IP connection is a handshake.But in 2020, WHO recommends avoiding handshakes. There is such a cool TCP Fast Open technology. You can, at the time of the handshake, avoid the entire chain “Hello, I am a client” - “Hello, I am a server” - “I believe you” - “And I believe you. Go". You can already send useful data at this moment. And if the handshake was successful, then part of the useful data has passed. This is TCP Fast Open.
How are packets and bytes sent on the network so that all browsers, clients and servers communicate with each other? The first thing a client / server does over a TCP / IP connection is a handshake.But in 2020, WHO recommends avoiding handshakes. There is such a cool TCP Fast Open technology. You can, at the time of the handshake, avoid the entire chain “Hello, I am a client” - “Hello, I am a server” - “I believe you” - “And I believe you. Go". You can already send useful data at this moment. And if the handshake was successful, then part of the useful data has passed. This is TCP Fast Open.What to pick up?
Let’s figure out what the client should pick up from the server. The main thing is not the client takes something from the server, but the server gives the data to the client. Then you might think: User-Agent. I can get the User-Agent from the client, find out which browser the user has logged into. Find out approximately if it does not deceive me, this browser..example {
display: -ms-grid;
display: grid;
-webkit-transition: all .5s;
-o-transition: all .5s;
transition: all .5s;
-webkit-user-select: none;
-moz-user-select: none;
-ms-user-select: none;
user-select: none;
background: -webkit-gradient(linear, left top, left bottom, from(white), to(black));
background: -o-linear-gradient(top, white, black);
background: linear-gradient(to bottom, white, black);
}
Let's say he logged in from Firefox. I, as usual, have an assembly in which autoprefixer is corny connected, it has generated a bunch of code for me. Yes, this is a cool approach that everything will work everywhere. But I already know that the user has logged in from Firefox.Why not turn off all the excess? Agree, there are much fewer lines, we send less bytes, this is cool.We have a lite version of SERP, Granny. Vitaly Kharisov talked about hervithar, class report on Web Standards Days. It uses exactly this approach. We can generate several bundles and give them to different clients in different ways. They weigh much less, because Firefox gets its own, WebKit gets its own, and it works, it’s verified.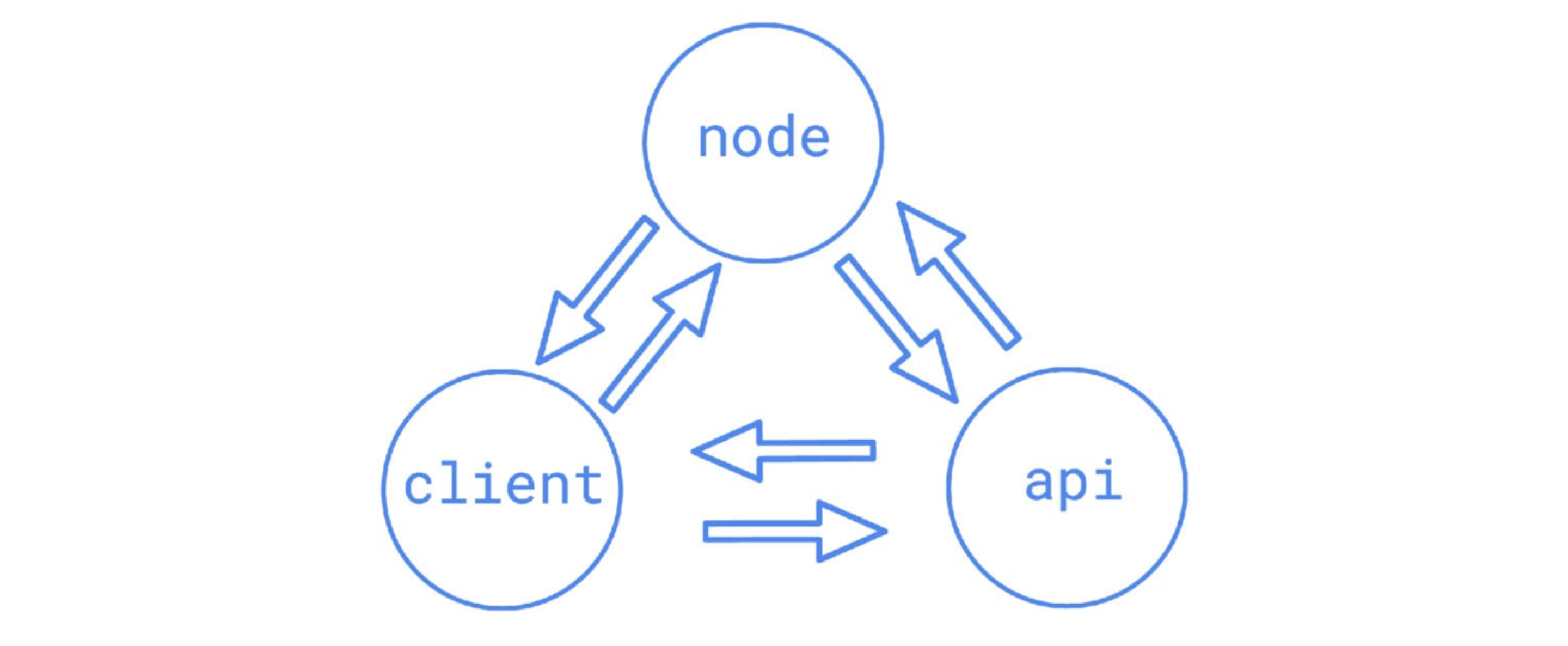 Further. We most likely process user requests, we know that the person is authorized and use some personal information for him. It is logical that we should get something from the database. But not all! There are static things that do not differ for any of the users, they are exactly the same.James Akvuh read a cool report about it“Server-Side Rendering. Do it yourself". What is the point? You already know that you have HTML and some kind of CSS that is the same for all users. Before you go for any data, you can generate the output from this static data, immediately send the most useful in a stream from the server. And after that - go for the data, quickly receive it, convert it into templates and give it to the client. And the user will already see something useful.
Further. We most likely process user requests, we know that the person is authorized and use some personal information for him. It is logical that we should get something from the database. But not all! There are static things that do not differ for any of the users, they are exactly the same.James Akvuh read a cool report about it“Server-Side Rendering. Do it yourself". What is the point? You already know that you have HTML and some kind of CSS that is the same for all users. Before you go for any data, you can generate the output from this static data, immediately send the most useful in a stream from the server. And after that - go for the data, quickly receive it, convert it into templates and give it to the client. And the user will already see something useful.
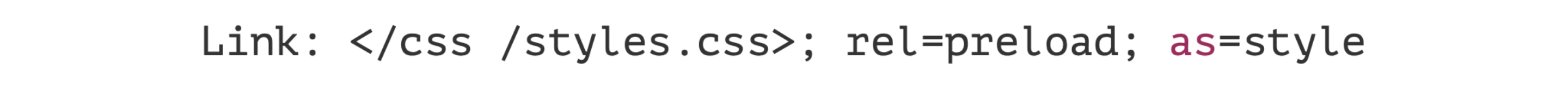 It's not hard. You need to configure a couple of headers on the server, and everything will start working. If the browser does not know this title, nothing will break, this is the most beautiful. Let's dig even further. TCP We already talked about this: a handshake, bytes are sent.
It's not hard. You need to configure a couple of headers on the server, and everything will start working. If the browser does not know this title, nothing will break, this is the most beautiful. Let's dig even further. TCP We already talked about this: a handshake, bytes are sent. Wash your hands after a handshake. But in terms of TCP, we begin to forward bytes, and the algorithms are optimized enough so that the client server does not stand idle.Therefore, a certain data segment is sent first. By default, (this you can change in the settings) it is 1460 bytes. The server does not send information on one segment. He sends windows.The first window is 14600 bytes, ten segments. Then, if the connection is good, he starts to enlarge the windows. If the connection is poor, it may reduce the window. What is important to understand? There is the first window of ten segments, in which you must fit the entire site, if you want. And then there will be a maximum speed of the appearance of content. Vitaliy Kharisov also read a report about this . And yes, it’s possible to fit a site with everything you need into one window if you turn off, for example, JS.An important nuance. When you fill an entire segment, it is one segment. But if you send just one extra byte, the server will still send a whole extra segment.
Wash your hands after a handshake. But in terms of TCP, we begin to forward bytes, and the algorithms are optimized enough so that the client server does not stand idle.Therefore, a certain data segment is sent first. By default, (this you can change in the settings) it is 1460 bytes. The server does not send information on one segment. He sends windows.The first window is 14600 bytes, ten segments. Then, if the connection is good, he starts to enlarge the windows. If the connection is poor, it may reduce the window. What is important to understand? There is the first window of ten segments, in which you must fit the entire site, if you want. And then there will be a maximum speed of the appearance of content. Vitaliy Kharisov also read a report about this . And yes, it’s possible to fit a site with everything you need into one window if you turn off, for example, JS.An important nuance. When you fill an entire segment, it is one segment. But if you send just one extra byte, the server will still send a whole extra segment.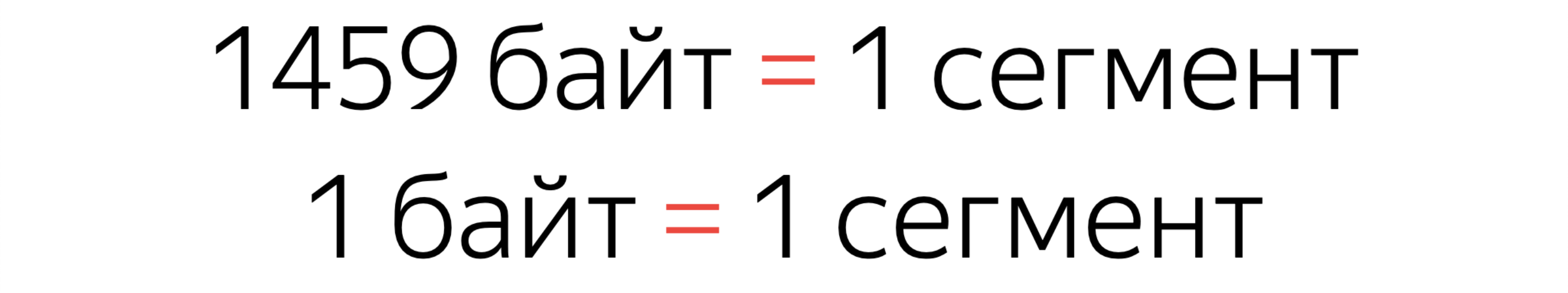 You can do a cool optimization, reduce the output by a whole kilobyte, but you won’t see anything on your measurements - perhaps because of this. Try to do the optimization normally on several segments.Strange: I am a typesetter, and I tell such complex server things. Let's get even closer to real CSS.
You can do a cool optimization, reduce the output by a whole kilobyte, but you won’t see anything on your measurements - perhaps because of this. Try to do the optimization normally on several segments.Strange: I am a typesetter, and I tell such complex server things. Let's get even closer to real CSS.Ship less
So, we send less to the user, fewer segments, comes faster, the user is happy. Minification. She was all set up on her projects. There are a bunch of cool tools, webpack plugins, gulp settings - in general, you'll figure it out for yourself. You can customize it by hand, but it seems only when you are sure that you can compress your CSS cooler than any CSSO.Remember to enable compression. If at least gzip is not turned on in 2020, you are definitely doing something wrong, because this is an ancient compression technique. In general, in 2020, it's time to use brotli. This is a good way to slightly reduce the output in Chromium browsers. Or, if you do not want to support brotli, then at least you can try zopfli.This is a fairly slow compression algorithm for gzip, which simply gives the best compression results and decompresses as fast as regular gzip. Therefore, zopfli needs to be configured wisely and used only when you do not need to output data on the fly. You can configure gzip archivers to be collected during assembly using the zopfli algorithm, and sent statically already, in fact, not going on the fly. This can help you. But also measure the results.
Minification. She was all set up on her projects. There are a bunch of cool tools, webpack plugins, gulp settings - in general, you'll figure it out for yourself. You can customize it by hand, but it seems only when you are sure that you can compress your CSS cooler than any CSSO.Remember to enable compression. If at least gzip is not turned on in 2020, you are definitely doing something wrong, because this is an ancient compression technique. In general, in 2020, it's time to use brotli. This is a good way to slightly reduce the output in Chromium browsers. Or, if you do not want to support brotli, then at least you can try zopfli.This is a fairly slow compression algorithm for gzip, which simply gives the best compression results and decompresses as fast as regular gzip. Therefore, zopfli needs to be configured wisely and used only when you do not need to output data on the fly. You can configure gzip archivers to be collected during assembly using the zopfli algorithm, and sent statically already, in fact, not going on the fly. This can help you. But also measure the results. All these algorithms use some kind of dictionaries: a dictionary is built on the basis of repeating code fragments. But sometimes they say: it is necessary to inline, if we inline, then we get rid of the request. Linking all the CSS in HTML will be very fast. The trick is that gzip works a little more efficiently when you break down styles and HTML, because the dictionaries are different, more efficient.In my case, I just took the bootstrap page, linked bootstrap there and compared the two versions. Gzip over individual resources is 150 bytes less. Yes, the gain is very small. Here, too, you need to measure everything. But in your case, this can, for example, reduce the number of segments by one.How to optimize the code? I'm not talking about minification. Take away what you are not using in the project. Most likely you have code that will never execute on the client. What for?
All these algorithms use some kind of dictionaries: a dictionary is built on the basis of repeating code fragments. But sometimes they say: it is necessary to inline, if we inline, then we get rid of the request. Linking all the CSS in HTML will be very fast. The trick is that gzip works a little more efficiently when you break down styles and HTML, because the dictionaries are different, more efficient.In my case, I just took the bootstrap page, linked bootstrap there and compared the two versions. Gzip over individual resources is 150 bytes less. Yes, the gain is very small. Here, too, you need to measure everything. But in your case, this can, for example, reduce the number of segments by one.How to optimize the code? I'm not talking about minification. Take away what you are not using in the project. Most likely you have code that will never execute on the client. What for?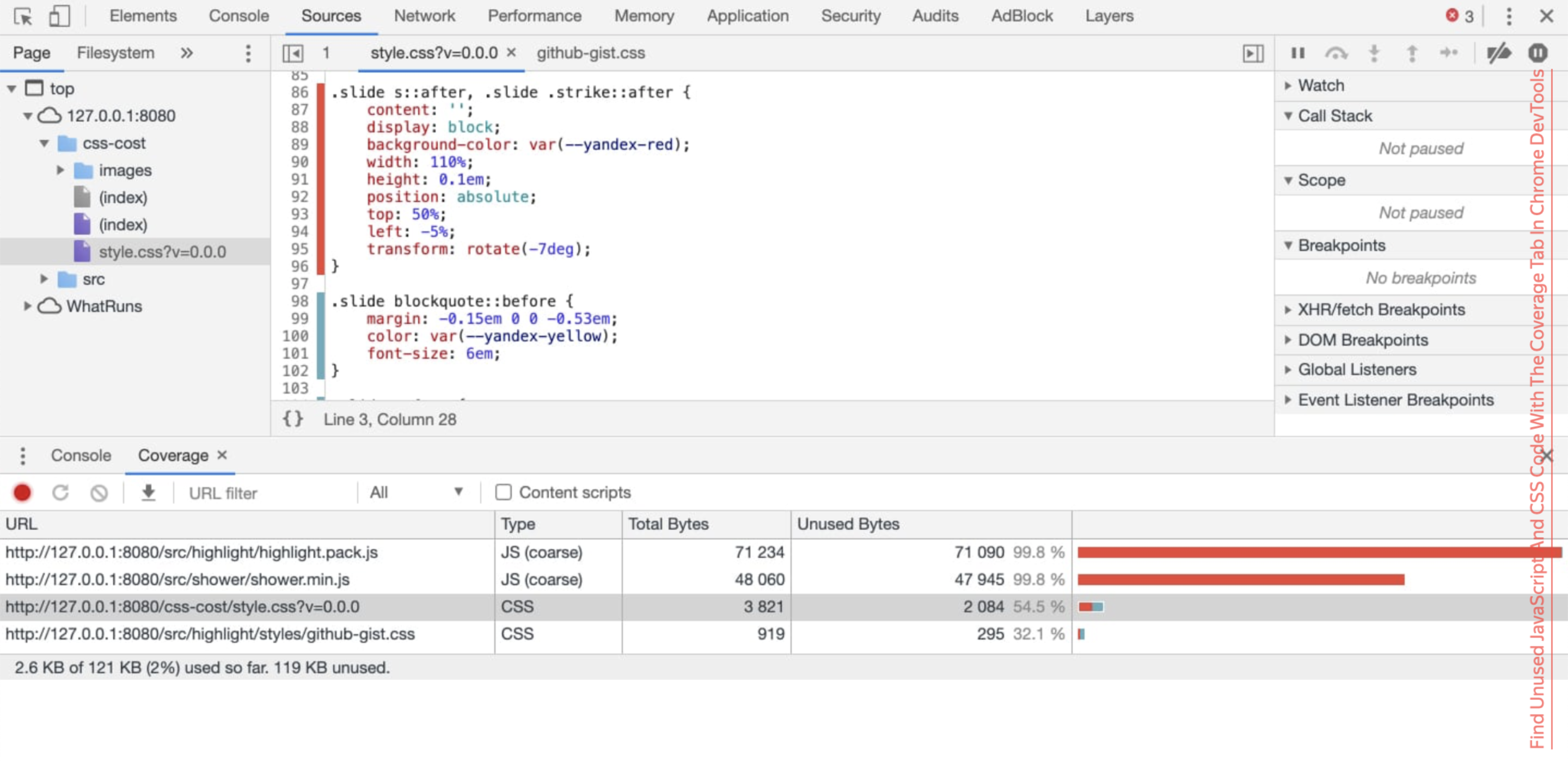 So that you can automate this, special tabs are built into the browser, for example, in Chrome DevTools, this is Coverage, which tells you: "I did not use this CSS or this JS, you can cut it out."But you may have hover, focus, active, something installed using JS. You need to simulate all the possible actions on the site, only then you will be sure that this CSS can be cut. Chris Coyer has a good review article about automatic tools that try to do everything with hover and focus. But he came to the conclusion that it was impossible to automate this. It doesn’t work out yet.There is a good report by Anton Kholkin from Booking.com, where they also tried to remove heaps of legacy code. But they had a peculiarity: a legacy code that came from external projects. It was necessary to remove it. See what interesting solutions they came across.You yourself can try to play with the same Puppeteer, which is like Chrome. You can do tests that automatically pass through everything, try to do hover, focus. And use this same Coverage.My colleague Vitya Khomyakovvictor-homyakovmade my own script , such as finding duplicates and styles on a page. Just take, copy and paste. He will write to you in the console: "this selector, it seems, you do not need." Up to the point that just enter in DevTools. It’s awesome.
So that you can automate this, special tabs are built into the browser, for example, in Chrome DevTools, this is Coverage, which tells you: "I did not use this CSS or this JS, you can cut it out."But you may have hover, focus, active, something installed using JS. You need to simulate all the possible actions on the site, only then you will be sure that this CSS can be cut. Chris Coyer has a good review article about automatic tools that try to do everything with hover and focus. But he came to the conclusion that it was impossible to automate this. It doesn’t work out yet.There is a good report by Anton Kholkin from Booking.com, where they also tried to remove heaps of legacy code. But they had a peculiarity: a legacy code that came from external projects. It was necessary to remove it. See what interesting solutions they came across.You yourself can try to play with the same Puppeteer, which is like Chrome. You can do tests that automatically pass through everything, try to do hover, focus. And use this same Coverage.My colleague Vitya Khomyakovvictor-homyakovmade my own script , such as finding duplicates and styles on a page. Just take, copy and paste. He will write to you in the console: "this selector, it seems, you do not need." Up to the point that just enter in DevTools. It’s awesome.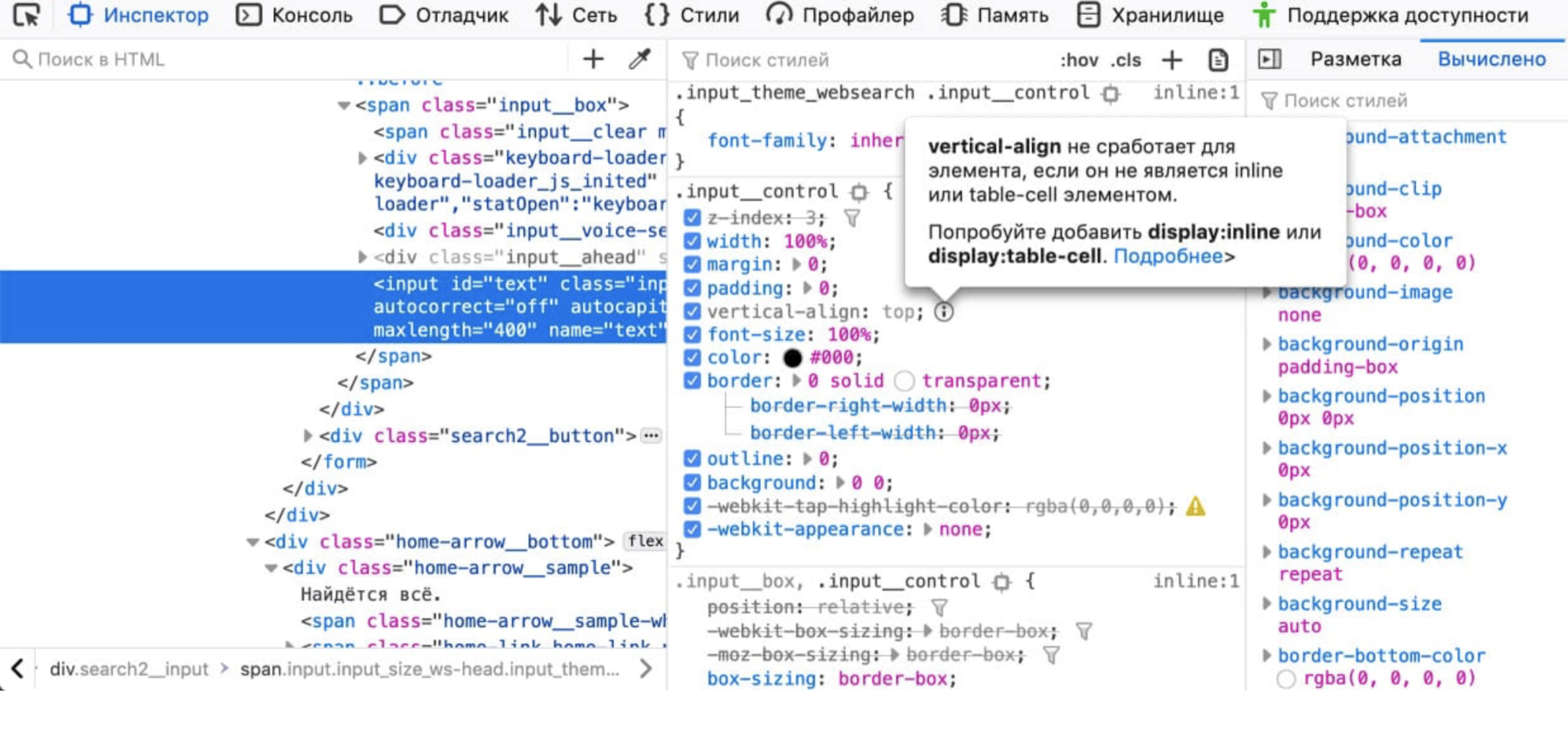 A feature that I really like about the tools of the Firefox developers: an opportunity to see styles that seem to be used, but in fact the browser does not apply them.For example, you can set display: inline, and it seems that this display: inline does not make sense to set sizes. Or vertical-align, it only works for inline or table-cell. So far, I have only seen in Firefox that it can highlight: "you do not need this line."Here, too, you need to be careful: perhaps you use this style to later paste the class. But in my opinion, a cool feature.Ask yourself the question right now: do you need the whole Bootstrap on the project? Place any CSS framework that you use instead of Bootstrap. Most likely, you use Bootstrap for grids and more or less common elements, and half of Bootstrap you do not need.Try using the assembly correctly. Almost all modern CSS frameworks allow you to use source code for assembly and select only what you need. This can drastically reduce the size of the CSS bundle.Do not give away unused. Instead of looking for my legacy, you can use the build-level understanding that this page will not use this CSS.For example, a full BEM stack allows you to make the assembly so that you, already giving the page, can build a tree of all the components of the BEM blocks that will be on the page. BEM allows you to determine that if this block is not on the page, there is no need to load this CSS. Ship only the necessary.Even the guys from Google say : use BEM, it can really help you for optimization.I do not believe that I say it out loud, but in this case CSS-in-JS seems to be a good approach. When you write independent independent components and carefully configure the assembly or determine in runtime which blocks are used and which are not, you can get rid of the problem of finding a legacy code by simply not sending this code to the client. Sounds easy, but discipline is needed. Think about it in advance at the beginning of the project.
A feature that I really like about the tools of the Firefox developers: an opportunity to see styles that seem to be used, but in fact the browser does not apply them.For example, you can set display: inline, and it seems that this display: inline does not make sense to set sizes. Or vertical-align, it only works for inline or table-cell. So far, I have only seen in Firefox that it can highlight: "you do not need this line."Here, too, you need to be careful: perhaps you use this style to later paste the class. But in my opinion, a cool feature.Ask yourself the question right now: do you need the whole Bootstrap on the project? Place any CSS framework that you use instead of Bootstrap. Most likely, you use Bootstrap for grids and more or less common elements, and half of Bootstrap you do not need.Try using the assembly correctly. Almost all modern CSS frameworks allow you to use source code for assembly and select only what you need. This can drastically reduce the size of the CSS bundle.Do not give away unused. Instead of looking for my legacy, you can use the build-level understanding that this page will not use this CSS.For example, a full BEM stack allows you to make the assembly so that you, already giving the page, can build a tree of all the components of the BEM blocks that will be on the page. BEM allows you to determine that if this block is not on the page, there is no need to load this CSS. Ship only the necessary.Even the guys from Google say : use BEM, it can really help you for optimization.I do not believe that I say it out loud, but in this case CSS-in-JS seems to be a good approach. When you write independent independent components and carefully configure the assembly or determine in runtime which blocks are used and which are not, you can get rid of the problem of finding a legacy code by simply not sending this code to the client. Sounds easy, but discipline is needed. Think about it in advance at the beginning of the project. What other option is there? A little crazy. In this code, it seems that style is not needed, because we use a div - the default is already display: block. And let's delete all the defaults? If in your project you know for sure that the HTML markup will never change again - go through the default values that the browser already provides and remove them.Less styles - great! But this is again a crazy idea. CSS doesn't have to know about HTML, because it's a style. It is quite independent, you must connect it to another project, it should work there. And yes, it’s hard to maintain. Change the tag - everything breaks. Crazy idea as promised.Use variables. CSS has very old variables like currentColor.
What other option is there? A little crazy. In this code, it seems that style is not needed, because we use a div - the default is already display: block. And let's delete all the defaults? If in your project you know for sure that the HTML markup will never change again - go through the default values that the browser already provides and remove them.Less styles - great! But this is again a crazy idea. CSS doesn't have to know about HTML, because it's a style. It is quite independent, you must connect it to another project, it should work there. And yes, it’s hard to maintain. Change the tag - everything breaks. Crazy idea as promised.Use variables. CSS has very old variables like currentColor. Often there is a pattern: you want, for example, to make a button whose text and border are the same in color. And by hover we change them both. What for?
Often there is a pattern: you want, for example, to make a button whose text and border are the same in color. And by hover we change them both. What for? There is a currentColor variable that takes a value from color, and you put it, for example, at the border, proxy this property and change only one line by hover, by focus, by active, whatever you want. This seems to be convenient, and the code has become one line less. You can optimize. By the way, in this example, you can not use the border-color task at all, because by default it already takes a value from the color property.It is sometimes very sad to watch how base64 is used. In CSS, it was actively recommended before: use base64 to inject small icons. If it fits in one segment over TCP, it’s good for you.
There is a currentColor variable that takes a value from color, and you put it, for example, at the border, proxy this property and change only one line by hover, by focus, by active, whatever you want. This seems to be convenient, and the code has become one line less. You can optimize. By the way, in this example, you can not use the border-color task at all, because by default it already takes a value from the color property.It is sometimes very sad to watch how base64 is used. In CSS, it was actively recommended before: use base64 to inject small icons. If it fits in one segment over TCP, it’s good for you. But Harry Roberts, tooConducted a classy study on how base64 affects page loading. Yes, there are fewer requests, but such styles are parsed at times slower.Okay, parsing is a very fast operation, the user most likely will not notice. But we have an important metric - the first rendering, so that the user sees something on the page. On mobile phones, the first rendering, according to a study by Harry Roberts, occurs ten times later. Think about whether you need base64? Yes, there are fewer requests, but did it have an effect?And please do not use base64 for SVG. Because SVG is great for using URL-encoder. Julia Bukhvalova has a cool tool: Come in, paste your SVG and it will give out CSS in a ready-to-paste form. You may notice that there is no base64, but some things are escaped that in CSS may not be perceived correctly. It is much more efficient.On average, base64 gives a plus of 30% to the size of what you compress. What for?Use modern technology. We may need to support Internet Explorer - the usual arguments when talking about grids.
But Harry Roberts, tooConducted a classy study on how base64 affects page loading. Yes, there are fewer requests, but such styles are parsed at times slower.Okay, parsing is a very fast operation, the user most likely will not notice. But we have an important metric - the first rendering, so that the user sees something on the page. On mobile phones, the first rendering, according to a study by Harry Roberts, occurs ten times later. Think about whether you need base64? Yes, there are fewer requests, but did it have an effect?And please do not use base64 for SVG. Because SVG is great for using URL-encoder. Julia Bukhvalova has a cool tool: Come in, paste your SVG and it will give out CSS in a ready-to-paste form. You may notice that there is no base64, but some things are escaped that in CSS may not be perceived correctly. It is much more efficient.On average, base64 gives a plus of 30% to the size of what you compress. What for?Use modern technology. We may need to support Internet Explorer - the usual arguments when talking about grids. But think about it: if you don’t have IE support, and you are still typesetting on float or tables, you can use grids to make three-column layout with a 20-pixel gap - this is the distance between the columns. Three lines. Well, five, considering the announcement itself.Try this on a float. And I mean that we change three lines, including the name of the classes, if you touch HTML. I did not find a way to do the same cool on a float. Throw off your decisions. But use modern technology. They allow you to more compactly indicate the markup.
But think about it: if you don’t have IE support, and you are still typesetting on float or tables, you can use grids to make three-column layout with a 20-pixel gap - this is the distance between the columns. Three lines. Well, five, considering the announcement itself.Try this on a float. And I mean that we change three lines, including the name of the classes, if you touch HTML. I did not find a way to do the same cool on a float. Throw off your decisions. But use modern technology. They allow you to more compactly indicate the markup. You can try Atomic CSS. What is it? You write these slightly crazy class names. And after some time you begin to understand that it is you who set the background-color or just color. These are the “features” for CSS. But you have a fixed CSS set that you then use in HTML as an indication of style. And CSS is suddenly getting smaller. For large projects, it really will become smaller, because there are fewer unique styles. But you are growing HTML.
You can try Atomic CSS. What is it? You write these slightly crazy class names. And after some time you begin to understand that it is you who set the background-color or just color. These are the “features” for CSS. But you have a fixed CSS set that you then use in HTML as an indication of style. And CSS is suddenly getting smaller. For large projects, it really will become smaller, because there are fewer unique styles. But you are growing HTML. You can look in the direction of Tailwind CSS, which is now gaining popularity. It is not Atomic CSS, it is about utility classes, similar to Bootstrap, only more utilitarian. You can use a specific set. Enough seems to be enough for you. A set of classes that perform their functions. You can also try, but do not overdo it much.
You can look in the direction of Tailwind CSS, which is now gaining popularity. It is not Atomic CSS, it is about utility classes, similar to Bootstrap, only more utilitarian. You can use a specific set. Enough seems to be enough for you. A set of classes that perform their functions. You can also try, but do not overdo it much. Another crazy idea - why do we need whole class names on the client? Yes, it’s convenient for development and debugging, but let's take all the class names and make them single-letter. It will be less.Here is an article on how to do this. You can configure webpack or another plugin when building. But it didn’t take off from us. We tried.It turned out that gzip is so cool that everything was pretty well optimized for us, and BEM and gzip are awesomely friendly. Because text constructs are repeated to describe blocks and elements in the code.In general, this gave us almost no profit. But if, for example, you don’t have BEM and a bunch of dissimilar classes, you can try.Important: measure. Measure all such experimental pieces. Perhaps now it works for you, and then you slightly changed the architecture of the project, it began to assemble differently and everything slowed down.
Another crazy idea - why do we need whole class names on the client? Yes, it’s convenient for development and debugging, but let's take all the class names and make them single-letter. It will be less.Here is an article on how to do this. You can configure webpack or another plugin when building. But it didn’t take off from us. We tried.It turned out that gzip is so cool that everything was pretty well optimized for us, and BEM and gzip are awesomely friendly. Because text constructs are repeated to describe blocks and elements in the code.In general, this gave us almost no profit. But if, for example, you don’t have BEM and a bunch of dissimilar classes, you can try.Important: measure. Measure all such experimental pieces. Perhaps now it works for you, and then you slightly changed the architecture of the project, it began to assemble differently and everything slowed down.Download it!
So far, I have only talked about how to download a file. We downloaded it. What has the user seen all this time? He saw such an amazing screen. While we were downloading, the screen was blank. We downloaded, and the browser begins six more steps. Be patient a little, I’ll talk about them a little faster than about downloading.
He saw such an amazing screen. While we were downloading, the screen was blank. We downloaded, and the browser begins six more steps. Be patient a little, I’ll talk about them a little faster than about downloading. Let's start with parsing. Parsing is when a browser has downloaded a stream of bytes, and begins to break it into entities that it understands.
Let's start with parsing. Parsing is when a browser has downloaded a stream of bytes, and begins to break it into entities that it understands. For example, he came across import. This again must be downloaded. Read the first piece of the report again? import is a blocking operation. But browsers are smart. They have a Preload Scanner. I said that everything is blocked there, this is not true. Browsers know that, for example, if there are three link tags in a row that follow the style, then when I download the first, you can start downloading the second and third. It cannot parse, because the whole structure of parsing breaks. But download in advance - it can.
For example, he came across import. This again must be downloaded. Read the first piece of the report again? import is a blocking operation. But browsers are smart. They have a Preload Scanner. I said that everything is blocked there, this is not true. Browsers know that, for example, if there are three link tags in a row that follow the style, then when I download the first, you can start downloading the second and third. It cannot parse, because the whole structure of parsing breaks. But download in advance - it can.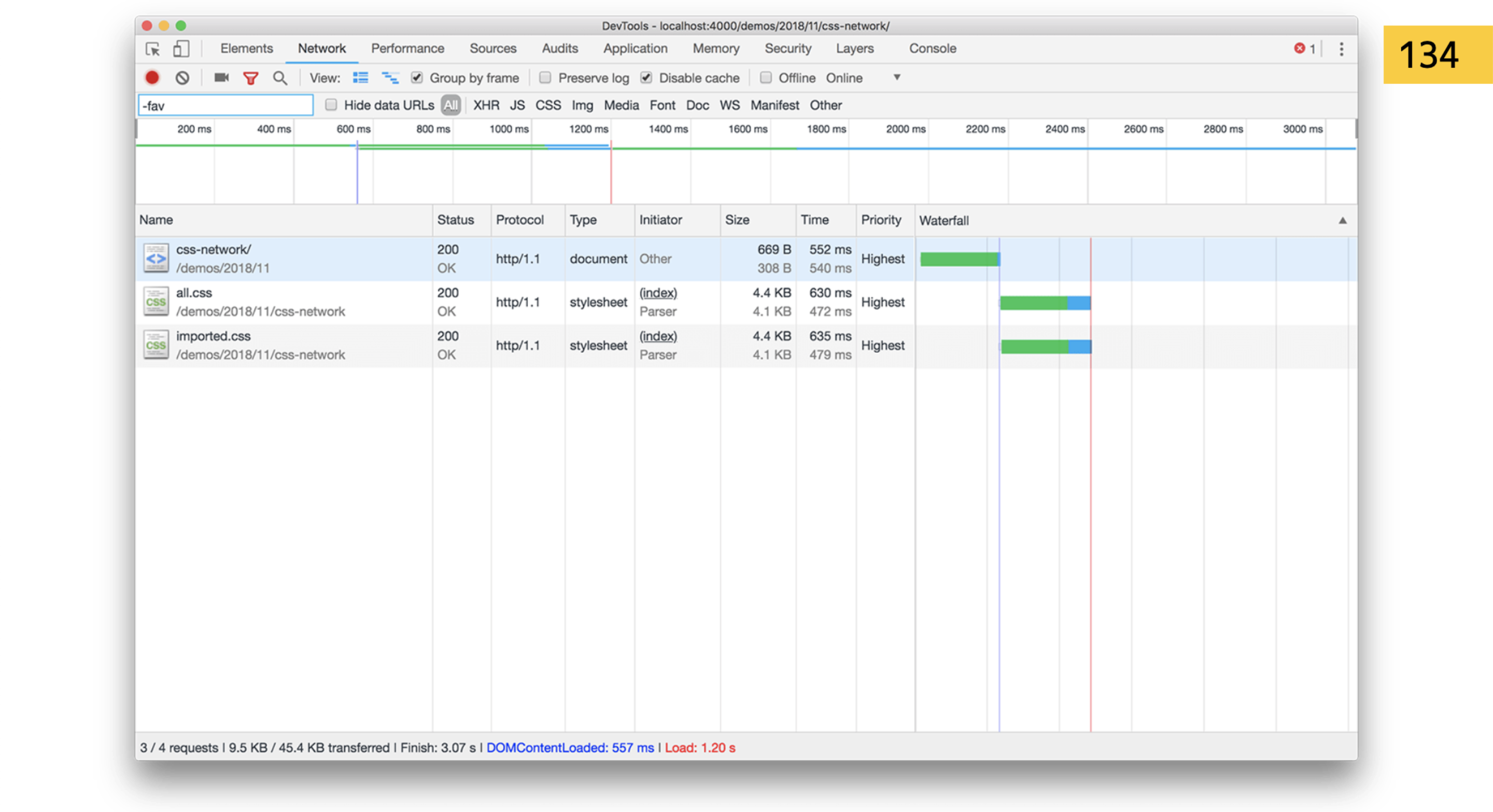 So import is a bad thing. If the styles are consistent in HTML, the browser will see that we will go further for another file.
So import is a bad thing. If the styles are consistent in HTML, the browser will see that we will go further for another file.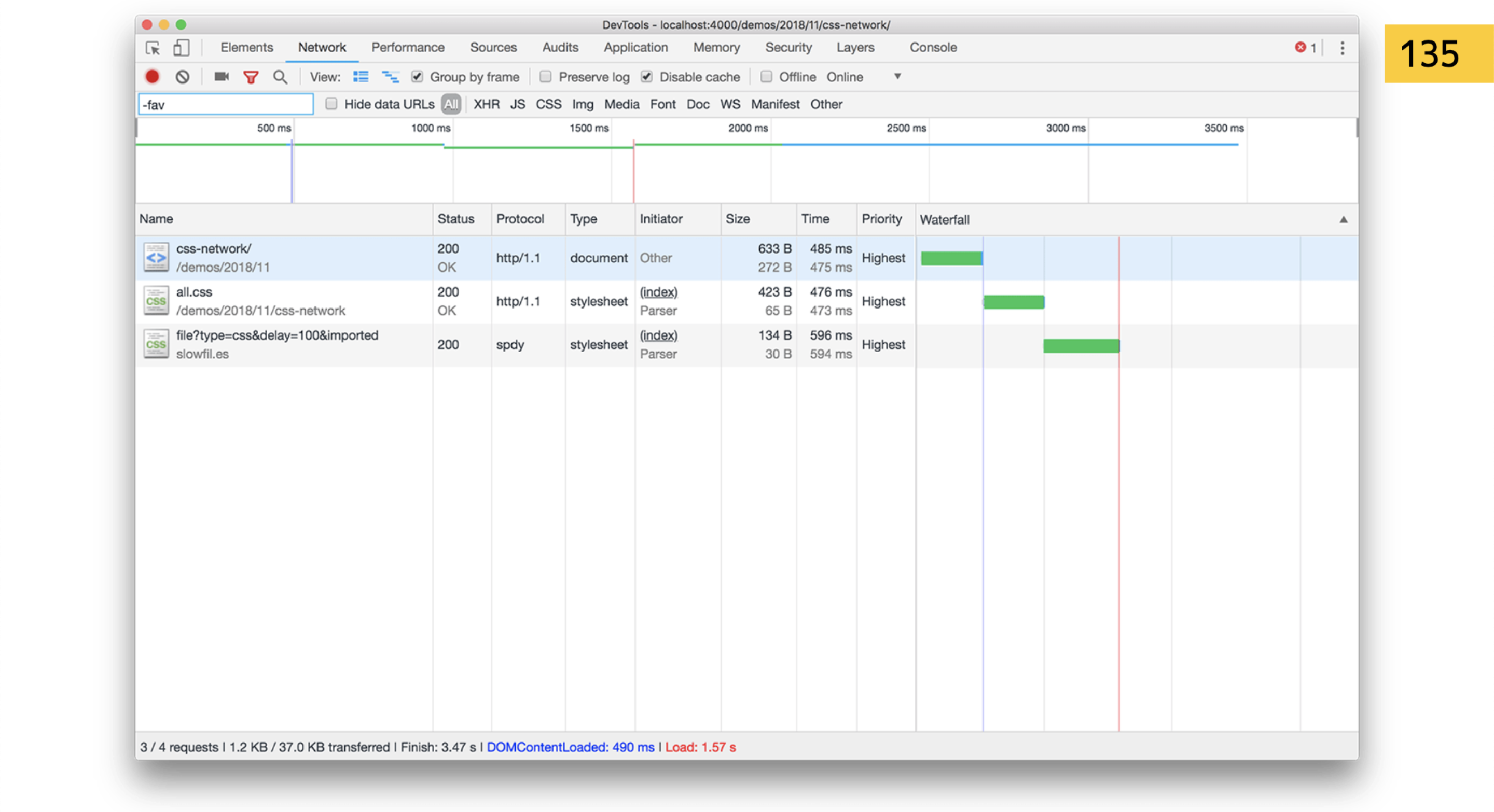 And if you insert it directly into import, it should first download your style.css, then see import in it. He begins to parse this CSS ... Yeah, we block everything in a new way and go for the file! So you can make a cool waterfall with deoptimization on the site.Forget import, or configure so that there is no import after the build. For the dev environment, ok, but not for the user.
And if you insert it directly into import, it should first download your style.css, then see import in it. He begins to parse this CSS ... Yeah, we block everything in a new way and go for the file! So you can make a cool waterfall with deoptimization on the site.Forget import, or configure so that there is no import after the build. For the dev environment, ok, but not for the user. Next we go through the stages of building trees, using Cascade.
Next we go through the stages of building trees, using Cascade.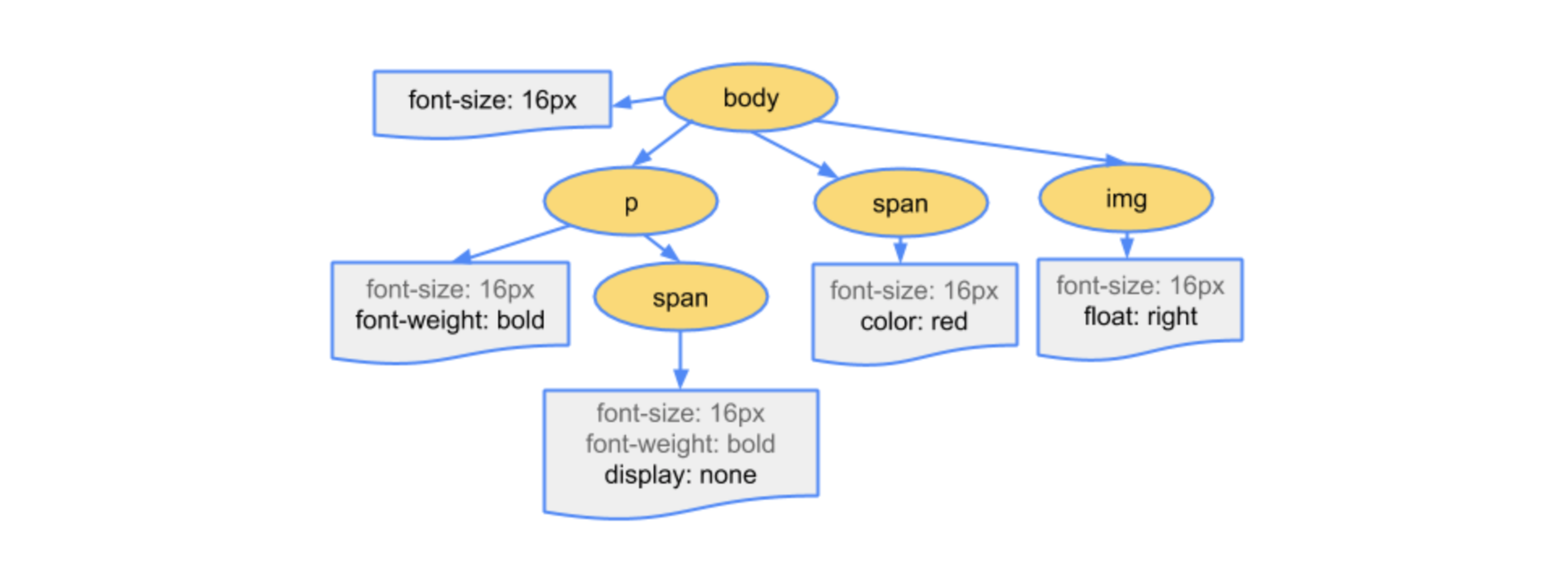 All this is also described for a long time. The CSS Object Model is built - a special tree of how the browser maps tags, classes to styles. He links it all to the DOM and makes these connections very quickly. When you change something, it is enough for him to change it inside the tree.
All this is also described for a long time. The CSS Object Model is built - a special tree of how the browser maps tags, classes to styles. He links it all to the DOM and makes these connections very quickly. When you change something, it is enough for him to change it inside the tree. The larger the selector, the more difficult it is for the browser to draw a tree. He needs to parse the selector, convert it to tree structures. And if you inserted! Important there, then he should take this into account.
The larger the selector, the more difficult it is for the browser to draw a tree. He needs to parse the selector, convert it to tree structures. And if you inserted! Important there, then he should take this into account. It seems like it's time to talk about BEM again. But BEM is not necessary if you know how to use utility classes, if one class is responsible for one functionality and they do not interfere with each other. Then building a tree is very simple. You have a fairly flat structure and then the browser should correctly link it to the DOM.
It seems like it's time to talk about BEM again. But BEM is not necessary if you know how to use utility classes, if one class is responsible for one functionality and they do not interfere with each other. Then building a tree is very simple. You have a fairly flat structure and then the browser should correctly link it to the DOM. If you do this, then they say such selectors slow down CSS parsing. But these are legends long ago, the difference is so small for the browser that in the average project you will not notice it if you optimize selectors with asterisks. But would you like to develop and maintain such code?
If you do this, then they say such selectors slow down CSS parsing. But these are legends long ago, the difference is so small for the browser that in the average project you will not notice it if you optimize selectors with asterisks. But would you like to develop and maintain such code? I used to hear tips: try putting everything in a shortcut. background is a shortcut for a lot of other properties. We put everything in one property, and it becomes optimal.By bytes, yes, it is getting smaller. But if you want to optimize the composition of CSS OM, then the browser will still make all these properties out of background. Browsers for each DOM element build a table of all the properties that it can have. When you look at DevTools computed values, they are not there because the browser calculated them according to your requirement. It stores this in memory, because it is much easier to rewrite one property and everything works.This is also very strange advice, but if you want to make CSS OM faster, you can immediately set all the properties one at a time. That might work. But the size of the bundle will greatly increase. You need to measure. I doubt that it will give a profit, but suddenly!When CSS OM is built, JS is also locked at this point. If building OM CSS takes two seconds, JS fails. Although I can’t imagine how you managed to write so much in CSS that the tree is built for two seconds.
I used to hear tips: try putting everything in a shortcut. background is a shortcut for a lot of other properties. We put everything in one property, and it becomes optimal.By bytes, yes, it is getting smaller. But if you want to optimize the composition of CSS OM, then the browser will still make all these properties out of background. Browsers for each DOM element build a table of all the properties that it can have. When you look at DevTools computed values, they are not there because the browser calculated them according to your requirement. It stores this in memory, because it is much easier to rewrite one property and everything works.This is also very strange advice, but if you want to make CSS OM faster, you can immediately set all the properties one at a time. That might work. But the size of the bundle will greatly increase. You need to measure. I doubt that it will give a profit, but suddenly!When CSS OM is built, JS is also locked at this point. If building OM CSS takes two seconds, JS fails. Although I can’t imagine how you managed to write so much in CSS that the tree is built for two seconds. Further the browser does Layout. This is the location of all the DOM elements, the use of positions. He understands where the element should be located and with what dimensions. It seems that at this stage the user should already see some kind of picture. But he sees everything in the viewport, can look through a limited window. If something is not right from below, he simply won’t see it.
Further the browser does Layout. This is the location of all the DOM elements, the use of positions. He understands where the element should be located and with what dimensions. It seems that at this stage the user should already see some kind of picture. But he sees everything in the viewport, can look through a limited window. If something is not right from below, he simply won’t see it. The idea is called Critical CSS, and it is also quite old. You insert some important things for the first screen at the very beginning of the download. For example, inline in your HTML, get rid of any additional requests. The user sees this screen first, and then download as you like. Most likely, he will start scrolling when you have time to load it.
The idea is called Critical CSS, and it is also quite old. You insert some important things for the first screen at the very beginning of the download. For example, inline in your HTML, get rid of any additional requests. The user sees this screen first, and then download as you like. Most likely, he will start scrolling when you have time to load it. This is done simply. There are tools that automate all this, including plugins for webpack and React. Just search and configure correctly.- github.com/addyosmani/critical- github.com/pocketjoso/penthouse- github.com/anthonygore/html-critical-webpack-plugin- github.com/GoogleChromeLabs/critters
This is done simply. There are tools that automate all this, including plugins for webpack and React. Just search and configure correctly.- github.com/addyosmani/critical- github.com/pocketjoso/penthouse- github.com/anthonygore/html-critical-webpack-plugin- github.com/GoogleChromeLabs/critters Have a good approachfrom Filament Group - how to load asynchronously without blocking CSS. Everything is quite simple.When you put <link rel = preload>, then tell the browser: “I will need this style, but now we are not blocking anything. You download it now, cache it, and when I turn to it, start building CSS OM. ” And you just need to put onload and process that "ok, since I downloaded it, do it rel = stylesheet, enable parsing."A fairly simple approach, but use it wisely too. If you have too much preload, you can do worse.
Have a good approachfrom Filament Group - how to load asynchronously without blocking CSS. Everything is quite simple.When you put <link rel = preload>, then tell the browser: “I will need this style, but now we are not blocking anything. You download it now, cache it, and when I turn to it, start building CSS OM. ” And you just need to put onload and process that "ok, since I downloaded it, do it rel = stylesheet, enable parsing."A fairly simple approach, but use it wisely too. If you have too much preload, you can do worse. You can also play with media expressions. Paste them and tell the browser: "this style is not needed now, but when this media expression works, it will be needed." The browser will also download proactively, but with a lower priority and without blocking.
You can also play with media expressions. Paste them and tell the browser: "this style is not needed now, but when this media expression works, it will be needed." The browser will also download proactively, but with a lower priority and without blocking. Another crazy approach, but not so crazy - when you have http / 2 push. You can embed CSS right in front of the block. Without CSS, your block will not look very good. So why not inline the CSS you need for the next block before this block? This is logical, and http / 2 push will allow you to optimize it.A simple approach. If you expand it, use lazy loading. Why should a user download something that he will not use? You can configure React components so that if it has never hit the page visibility area, why should it download styles for itself?Explore the Intersection Observer API and you may be able to dramatically speed up your page.
Another crazy approach, but not so crazy - when you have http / 2 push. You can embed CSS right in front of the block. Without CSS, your block will not look very good. So why not inline the CSS you need for the next block before this block? This is logical, and http / 2 push will allow you to optimize it.A simple approach. If you expand it, use lazy loading. Why should a user download something that he will not use? You can configure React components so that if it has never hit the page visibility area, why should it download styles for itself?Explore the Intersection Observer API and you may be able to dramatically speed up your page. The last step is drawing and applying to composite layers, gluing them and so on.
The last step is drawing and applying to composite layers, gluing them and so on. The browser creates composite layers in a huge number of cases. In my opinion, only one quarter of the Chromium source code fit here . You can see for yourself when it creates composite layers in the browser code.Video memory is limited, especially on mobile phones. If you bring everything to new layers to optimize animations using will-change: transform or something else, then you may be doing worse.Create fewer layers - exactly as much as you need for the current optimization.Great, we all parsed.
The browser creates composite layers in a huge number of cases. In my opinion, only one quarter of the Chromium source code fit here . You can see for yourself when it creates composite layers in the browser code.Video memory is limited, especially on mobile phones. If you bring everything to new layers to optimize animations using will-change: transform or something else, then you may be doing worse.Create fewer layers - exactly as much as you need for the current optimization.Great, we all parsed.And if I come back?
And what if I return to the page? This is only the first time I went.Returning to the page, I seem to be able to download everything instantly. I already downloaded all the resources, why not use them a second time? If the server does not give the Cache-Control header, the browser will try to cache your file in order to reuse it. You can configure your server by default, say: "cache this file for a whole year." Will not change. But if so, you need to deal with the global cache invalidation issue. But this is the topic of a separate report.Use Service Workers! 2020, it's time, Progressive Web Applications! Kirill Chugainov had a good reportabout how Service Workers can be used for different occasions. In this case, you intercept the CSS request, save it, and if the browser follows this style for the second time, give it away from the cache.But the browser does not promise you anything. You can always face the fact that the browser has run out of memory. He will try to cache, but there is no memory. Caching is not one hundred percent. Always handle such situations.You can try using Local Storage. But he is wildly slow. Downloading a file is sometimes faster than going to the Local Storage API.You can try the built-in browser database. But measure it. Perhaps a trip to JS will take you longer due to a weak processor.You can also tell the browser in advance that you will download something.
If the server does not give the Cache-Control header, the browser will try to cache your file in order to reuse it. You can configure your server by default, say: "cache this file for a whole year." Will not change. But if so, you need to deal with the global cache invalidation issue. But this is the topic of a separate report.Use Service Workers! 2020, it's time, Progressive Web Applications! Kirill Chugainov had a good reportabout how Service Workers can be used for different occasions. In this case, you intercept the CSS request, save it, and if the browser follows this style for the second time, give it away from the cache.But the browser does not promise you anything. You can always face the fact that the browser has run out of memory. He will try to cache, but there is no memory. Caching is not one hundred percent. Always handle such situations.You can try using Local Storage. But he is wildly slow. Downloading a file is sometimes faster than going to the Local Storage API.You can try the built-in browser database. But measure it. Perhaps a trip to JS will take you longer due to a weak processor.You can also tell the browser in advance that you will download something. <link rel> - learn how this attribute works. There is preconnect, prefetch, prerender - I want to talk about it separately. He says: “I am on this page now, and then I will go to the next. Download everything for this page in the background tab and draw. ” Cool stuff. Doesn't work anywhere.
<link rel> - learn how this attribute works. There is preconnect, prefetch, prerender - I want to talk about it separately. He says: “I am on this page now, and then I will go to the next. Download everything for this page in the background tab and draw. ” Cool stuff. Doesn't work anywhere. In a sense, it is supported in IE and Edge. In Chrome, it does not really do this, it does not render. It works like prefetch: downloads these files and caches. Unfortunately, a full-fledged prerender doesn't work anywhere.But you can develop this idea. For example, in the Yandex application - naturally, not using CSS - a prerender is made. When you are looking for something, chances are you can get your results instantly. We can predict where you will go, and in advance by our own methods go and get all the necessary resources.What's next? There were a lot of links. I also advise you to look at an amazing collection of optimization of everything from Vanya Akuloviamakulov. See how to optimize both HTML, and JS, and assembly.And don't forget to tidy up. Now my advice really works, suggesting how to do it quickly, but most likely, after five years, they will even be harmful. There will be some kind of technology that will be incompatible with them. Keep track of this and try to keep your code optimal, including after a while. Thank you for the attention.
In a sense, it is supported in IE and Edge. In Chrome, it does not really do this, it does not render. It works like prefetch: downloads these files and caches. Unfortunately, a full-fledged prerender doesn't work anywhere.But you can develop this idea. For example, in the Yandex application - naturally, not using CSS - a prerender is made. When you are looking for something, chances are you can get your results instantly. We can predict where you will go, and in advance by our own methods go and get all the necessary resources.What's next? There were a lot of links. I also advise you to look at an amazing collection of optimization of everything from Vanya Akuloviamakulov. See how to optimize both HTML, and JS, and assembly.And don't forget to tidy up. Now my advice really works, suggesting how to do it quickly, but most likely, after five years, they will even be harmful. There will be some kind of technology that will be incompatible with them. Keep track of this and try to keep your code optimal, including after a while. Thank you for the attention.