Hello everyone! As you already know, we at SE are engaged in text recognition (and not only) on different documents. Today we would like to talk about another problem when recognizing text on complex backgrounds - about recognizing spaces. In general, we will talk about the name on bank cards, but first, an example with a “ghost” of the letter. As you can see, here, to the right of D, the distortions and background formed a fairly clear . Moreover, if you show this cell separately from everything else, the person (or neural network) will surely say that there is a letter.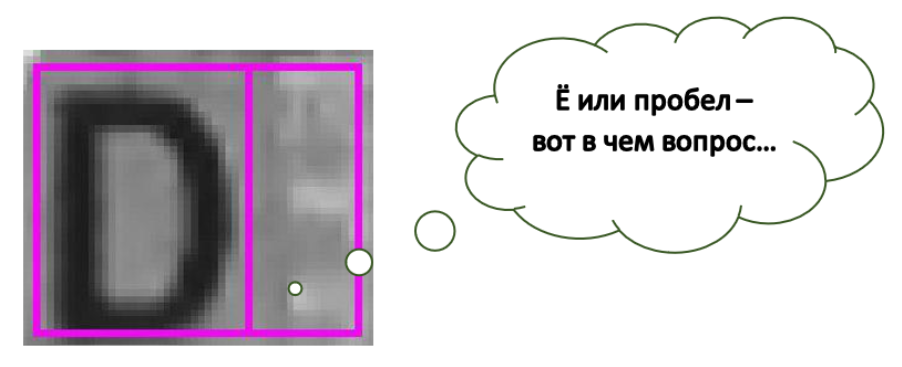 As you can see in the picture, we are working on the original image with complex backgrounds, so our spaces are very diverse. They come in patterns, logos, and sometimes text. For example, VISA or MAESTRO on cards. And we are interested in just such “complex spaces”, and not just white rectangles. And in our systems we consider precisely separately cut rectangles of symbols [1].
As you can see in the picture, we are working on the original image with complex backgrounds, so our spaces are very diverse. They come in patterns, logos, and sometimes text. For example, VISA or MAESTRO on cards. And we are interested in just such “complex spaces”, and not just white rectangles. And in our systems we consider precisely separately cut rectangles of symbols [1].And what is the difficulty?
A space is a symbol without special signs. On complex backgrounds, such as in an image, a separately cut space can be difficult to distinguish even for a person.On the other hand, in essence, a space is different from other characters. If ABIA is recognized in the name instead of ASIA, then there is a chance to fix it with post-processing. But, if A IA arises there, it is unlikely that something will help.Methods not used by us
Often spaces are filtered using statistics calculated from the image. For example, consider the average absolute value of the gradient in the picture or the variance of the intensities of the pixels and divide the pictures into spaces and letters by the threshold value. However, as can be seen from the graphs, such methods are not suitable for gray images with complex backgrounds. And due to the explicit correlation of values, even a combination of these methods will not work.Everyone’s favorite binarization will not help here either. For example, in this picture:So, how can recognition be improved?
Since a person needs an environment of a space in order to see him, it is logical for the network to show at least two neighboring characters. We do not want to increase the input of the recognition network, which, in general, works well (and recognizes many gaps). So we will get another network - simpler. The new network will predict what is in the picture: two spaces, two letters, a space and a letter, or a letter and a space. Accordingly, such a network is used in conjunction with a recognition network. The image shows the architectures used: on the left is the architecture of the recognizing network, on the right is the architecture of the proposed network. The recognition network operates on a picture with one character, and the new one works on a double-width picture containing two adjacent characters.A test?
For testing, we had 4320 lines with names containing 130,149 characters, of which 68,246 spaces. For starters, we have two methods. The basic method: we cut a string into characters and recognize each character individually. New method: we also cut a string of characters, find all the spaces with a new network, and recognize the remaining characters as normal. The table shows that the quality of recognition of spaces, as well as the overall quality, is growing, but the quality of recognition of letters is slightly sagging.However, our core network also recognizes spaces (albeit worse than we would like). And we can try to take advantage of this. Let's look at the errors of both methods. And also - on the quality of the new method based on basic errors and vice versa.For the base method:For the new method:From the last three tables it can be seen that to improve the system it is worth using a balanced combination of network ratings. At the same time, character-by-character quality is interesting, but line-by-line is more interesting.Conclusion
Space - a big problem on the way to 100% quality of recognition of documents =) On the example of spaces it is clearly seen how important it is to look not only at individual characters, but also at their combinations. However, do not immediately grab hold of heavy artillery and learn giant networks that process entire strings. Sometimes just another small network is enough.This post was made using materials from a report from the European Conference on Modeling ECMS 2015 (Bulgaria, Varna): Sheshkus, A. & Arlazarov, VL (2015). Space symbol detection on complex background using visual context.List of sources used1. YS Chernyshova, AV Sheshkus and VV Arlazarov, “Two-step CNN framework for text line recognition in camera-captured images,” IEEE Access, vol. 8, pp. 32587-32600, 2020, DOI: 10.1109 / ACCESS.2020.2974051.