Or the good old dynamic programming without these of your neural networks.A year and a half ago, I happened to participate in a corporate competition (for the purpose of entertainment) in writing a bot for the game Lode Runner. 20 years ago, I diligently solved all the problems of dynamic programming in the corresponding course, but pretty much forgot everything and had no experience in programming game bots. Little time was allocated, I had to remember, experiment on the go and independently step on the rake. But, all of a sudden, everything worked out very well, so I decided to somehow systematize the material and not drown the reader with matan.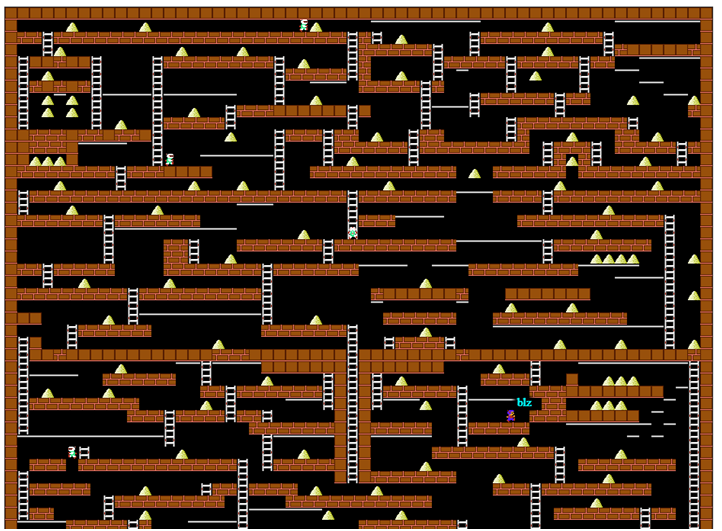 Game screen from Codenjoy project serverTo begin with, we will describe the rules of the game a little : the player moves horizontally along the floor or through pipes, knows how to climb up and down stairs, falls if there is no floor under him. He can also cut a hole to the left or to the right of himself, but not every surface can be cut through - conditionally a “wooden” floor is possible, and concrete - not.Monsters run after the player, fall into the cut holes and die in them. But most importantly, the player must collect gold, for the first gold collected he receives 1 profit point, for the N-th he receives N points. After the death, the total profit remains, but for the first gold they again give 1 point. This suggests that the main thing is to stay alive for as long as possible, and to collect gold is somehow secondary.Since there are places on the map that the player cannot get out of himself, a free suicide was introduced into the game, which randomly put the player somewhere, but in fact broke the whole game - suicide did not interrupt the growth in the value of the gold found. But we will not abuse this feature.All examples from the game will be given in a simplified display, which was used in the program logs:
Game screen from Codenjoy project serverTo begin with, we will describe the rules of the game a little : the player moves horizontally along the floor or through pipes, knows how to climb up and down stairs, falls if there is no floor under him. He can also cut a hole to the left or to the right of himself, but not every surface can be cut through - conditionally a “wooden” floor is possible, and concrete - not.Monsters run after the player, fall into the cut holes and die in them. But most importantly, the player must collect gold, for the first gold collected he receives 1 profit point, for the N-th he receives N points. After the death, the total profit remains, but for the first gold they again give 1 point. This suggests that the main thing is to stay alive for as long as possible, and to collect gold is somehow secondary.Since there are places on the map that the player cannot get out of himself, a free suicide was introduced into the game, which randomly put the player somewhere, but in fact broke the whole game - suicide did not interrupt the growth in the value of the gold found. But we will not abuse this feature.All examples from the game will be given in a simplified display, which was used in the program logs:
Bit of theory
To implement the bot using some kind of mathematics, we need to set some objective function that describes the achievements of the bot and find him actions that maximize it. For example, for collecting gold we get +100, for death -100500, so no collection of gold will kill the possible death.A separate question, and on what exactly do we determine the objective function, i.e. What is the state of the game? In the simplest case, the player’s coordinates are enough, but in ours everything is much more complicated:- player’s coordinates
- the coordinates of all the holes pierced by all players
- the coordinates of all the gold on the map (or the coordinates of recently eaten gold)
- coordinates of all other players
It looks scary. Therefore, let's simplify the task a bit and until we remember the gold we eat (we will return to this later), we also will not remember the coordinates of other players and monsters.Thus, the current state of the game is:- player’s coordinates
- coordinates of all pits
Player actions change state in an understandable way:- Motion commands change one of the corresponding coordinates
- Pit digging team add one new pit
- Falling a player without a support reduces the vertical coordinate
- The inaction of the player standing on the support does not change the state
Now we need to understand how to maximize the function itself. One of the venerable classic methods for calculating the game N moves ahead is dynamic programming. It’s impossible to do without formulas, therefore I will give them in a simplified form. You will have to introduce a lot of notation first.For simplicity, we will keep the time report from the current move, i.e. the current move is t = 0.We denote the state of the game during the course of t by.Lots of will denote all valid actions of the bot (in a specific state, but for simplicity we will not write the state index), through we denote a specific action on the course t (we omit the index).condition Under the influence goes into state .Win when action a is in state we denote it as . When calculating it, we assume that if we ate gold, then it is equal to G = 100, if they died, then D = -100500, otherwise 0.Letthis is the payoff function for the optimal game of a bot that is in state x at time t. Then we just need to find an action that maximizes.Now we write the first formula, which is very important and at the same time almost correct:
Or for an arbitrary point in time
It looks pretty clumsy, but the meaning is simple - the optimal solution for the current move consists of the optimal solution for the next move and the gain in the current move. This is Bellman's crookedly formulated optimality principle. We don’t know anything about the optimal values in step 1, but if we knew them, we would find an action that maximizes the function by simply iterating over all the actions of the bot. The beauty of recurrence relations is that we can find, applying the optimality principle to it, expressing it in exactly the same formula through . We can also easily express the payoff function at any step.It would seem that the problem is solved, but here we are faced with the problem that if at each step we had to sort through 6 player actions, then at the N step of recursion we would have to sort through 6 ^ N options, which for N = 8 is already a pretty decent number ~ 1.6 million cases. On the other hand, we have gigahertz microprocessors that have nothing to do, and it seems that they will completely cope with the task, and we will limit the search depth to them with exactly 8 moves.And so, our planning horizon is 8 moves, but where to get the values? And here we just come up with the idea that we are able to somehow analyze the prospects of the position, and assign to it some value based on their highest considerations. Let bewhere this is a function of the strategy, in the simplest version it is just a matrix from which we select the value according to the geometrical coordinates of the bot. We can say that the first 8 moves it was a tactic, and then the strategy begins. In fact, no one restricts us in choosing a strategy, and we will deal with it later, but for now, in order not to become like an owl from a joke about hares and hedgehogs, we will move on to tactics.General scheme
And so, we decided on the algorithm. At each step, we solve the optimization problem, find the optimal action for the step, complete it, after which the game proceeds to the next step.It is necessary to solve a new problem at every step, because with each course of the game the task changes a bit, new gold appears, someone eats someone, the players move ...But do not think that our ingenious algorithm can provide for everything. After solving the optimization problem, you must definitely add a handler that will check for unpleasant situations:- Standing bot in place for a long time
- Continuous walking left-right
- Lack of income too long
All this may require a radical change of strategy, suicide, or some other action outside the framework of the optimizing algorithm. The nature of these situations may be different. Sometimes the contradictions between strategy and tactics lead to the bot freezing in place at a point that it seems strategically important to him, which was discovered by ancient botanists called Buridanov Donkey. Your opponents can freeze and close your short road to the coveted gold - we will deal with all this later.
Your opponents can freeze and close your short road to the coveted gold - we will deal with all this later.The fight against procrastination
Consider the simple case when one gold is located to the right of the bot and there are no more gold cells in a radius of 8. What step will the bot take, guided by our formula? In fact - absolutely any. For example, all these solutions give exactly the same result even for three moves:- step left - step right - step right
- step to the right - inaction - inaction
- inaction - inaction - step right
All three options give one win equal to 100, the bot can choose the option with inaction, at the next step solve the same problem again, choose the inaction again ... And stand still forever. We need to modify the formula for calculating winnings in order to stimulate the bot to act as early as possible:
we multiplied the future gain in the next step by the “inflation coefficient” E, which must be chosen less than 1. We can safely experiment with values of 0.95 or 0.9. But do not choose it too small, for example, with a value of E = 0.5, the gold eaten on the 8th move will bring only 0.39 points.And so, we rediscovered the principle of "Do not put off until tomorrow what you can eat today."Safety
Gathering gold is certainly good, but you still need to think about security. We have two tasks:- Teach the bot to dig holes if the monster is in a suitable position
- Teach the bot to run away from monsters
But we don’t tell the bot what to do, we set the value of the profit function and the optimizing algorithm will choose the appropriate steps. A separate problem is that we do not calculate exactly where a monster can be on a particular move. Therefore, for simplicity, we assume that the monsters are in place, and we just do not need to approach them.If they begin to approach us, the bot will itself start to run away from them, because it will be fined for being too close to them (sort of self-isolation). And so, we introduce two rules:- If we come to the monster at a distance d and d <= 3, then a fine of 100,500 * (4-d) / 4 is imposed on us
- If the monster came close enough, is on the same line with us and there is a hole between us, then we get some profit P
The concept of "approached the monster at a distance d" we will open a little later, but for now, let's move on to the strategy.We go around the graphs
Mathematically, the problem of optimal gold circumvention is a long-solved problem of a traveling salesman, the solution of which is not a pleasure. But before you solve such problems, you need to think about a simple question - but how do you find the distance between two points in the game? Or in a slightly more useful form: for a given gold and for any point on the map, find the minimum number of moves for which the player will reach the point from gold. For some time we will forget about digging holes and jumping into them, we will leave only natural movements per 1 cell. Only we will walk in the opposite direction - from gold and across the map.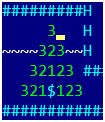 In the first step, we select all the cells from which we can get into gold in one move and assign them to 1. In the second step, we select all the cells from which we fall into ones in one step and assign them to 2. The picture shows the case for 3 steps. Now let's try to write it all down formally, in a form suitable for programming.We will need:
In the first step, we select all the cells from which we can get into gold in one move and assign them to 1. In the second step, we select all the cells from which we fall into ones in one step and assign them to 2. The picture shows the case for 3 steps. Now let's try to write it all down formally, in a form suitable for programming.We will need:- The two-dimensional numerical array distance [x, y], in which we will store the result. Initially, for gold coordinates, it contains 0, for the remaining points -1.
- The oldBorder array, in which we will store the points from which we will move, initially it has one point with gold coordinates
- Array newBorder, in which we will store the points found in the current step
- For each point p from oldBorder we find all points p_a, from which we can reach p in one step (more precisely, we just take all possible steps from p in the opposite direction, for example, flying upwards in the absence of support) and distance [p_a] = - 1
- We place each such point p_a in the array newBorder, at distance [p_a] we write the iteration number
- After all points are completed:
- Swap the arrays of oldBorder and newBorder, after which we clear newBorder
- If oldBorder is empty, then finish the algorithm, otherwise go to step 1.
Same thing in pseudo code:iter=1;
newBorder.clear();
distance.fill(-1);
distance[gold]=0;
oldBorder.push(gold);
while(oldBorder.isNotEmpty()) {
for (p: oldBorder){
for (p_a: backMove(p)) {
if (distance[p_a]==-1) {
newBorder.push(p_a);
distance[p_a]=iter;
}
}
}
Swap(newBorder, oldBorder);
newBorder.clear();
iter++;
}
At the output of the algorithm, we will have a distance map with the value of the distance from each point of the entire field of the game to gold. Moreover, for points from which gold is unattainable, the distance value is -1. Mathematicians call such a walk around the game field (which forms a graph with vertices at points in the field and edges connecting the vertices accessible in one move) “walk the graph in width”. If we implemented recursion, rather than two arrays of borders, this would be called “going around the graph in depth”, but since the depth can be quite large (several hundred), I advise you to avoid recursive algorithms when traversing graphs.The real algorithm will be a little more complicated due to digging a hole and jumping into it - it turns out that in 4 moves we move one cell sideways and two down (since moving in the opposite direction, then up), but a slight modification of the algorithm solves the problem.I supplemented the picture with numbers, including taking into account digging a hole and jumping into it: What does this remind us of?
What does this remind us of? The smell of gold! And our bot will go for this smell, like Rocky for cheese (but at the same time it does not lose its brains and dodges monsters, and even digs holes for them). Let's make him a simple greedy strategy:
The smell of gold! And our bot will go for this smell, like Rocky for cheese (but at the same time it does not lose its brains and dodges monsters, and even digs holes for them). Let's make him a simple greedy strategy:- For each gold, we construct a distance map and find the distance to the player.
- Choose the gold closest to the player and take his card to calculate the strategy
- For each cell of the map, denote by d its distance to gold, then the strategic value
Where this is some imaginary value of gold, it is desirable that it be valued several times less than the present, and this is an inflation coefficient <1, because the further the imaginary gold is, the cheaper it is. The ratio of the coefficients E andconstitutes an unsolved problem of the millennium and leaves room for creativity.Do not think that our bot will always run to the nearest gold. Suppose we have one gold on the left at a distance of 5 cells and then void, and on the right two gold at a distance of 6 and 7. Since real gold is more valuable than imagined, the bot will go to the right.Before moving on to more interesting strategies, we’ll make another improvement. In the game, gravity pulls the player down, and he can only go up the stairs. So, the gold that is higher should be valued higher. If the height is reported from the top line down, then you can multiply the value of gold (with vertical y coordinate) by. For coefficient the new term “vertical inflation rate” was coined, at least it is not used by economists and reflects the essence well.Complicating Strategies
With one gold sorted out, you need to do something with all the gold, and I would not want to attract heavy mathematics. There is a very elegant, simple and incorrect (in the strict sense) solution - if one gold creates a “field” of value around itself, then let's just add all the value fields from all the cells with gold into one matrix and use it as a strategy. Yes, this is not an optimal solution, but several units of gold in the middle distance can be more valuable than one close one.However, a new solution creates new problems - a new value matrix may contain local maxima, near which there is no gold. Because our bot can get into them and does not want to go out, it means that we need to add a handler that checks that the bot is at the local maximum of the strategy and remains in place according to the results of the move. And now we have a tool to combat freezes - cancel this strategy by N moves and temporarily return to the strategy of the nearest gold.It's pretty funny to watch how a stuck bot changes its strategy and starts to go down continuously, eating all the nearest gold, on the lower floors of the map the bot comes to its senses and tries to climb up. A sort of Dr. Jekyll and Mr. Hyde.Strategy disagrees with tactics
Here our bot comes to gold under the floor: It already falls into the optimizing algorithm, it remains to take 3 steps to the right, cut a hole on the right and jump into it, and then gravity will do everything by itself. Something like this:
It already falls into the optimizing algorithm, it remains to take 3 steps to the right, cut a hole on the right and jump into it, and then gravity will do everything by itself. Something like this: But the bot freezes in place. Debugging showed that there was no mistake: the bot decided that the optimal strategy was to wait for one move, and then go along the specified route and take gold at the last analyzed step. In the first case, it receives a gain from the received gold and a gain from imaginary gold (at the last analyzed iteration it is just in the cell where the gold was), and in the second - only from real gold (although a turn earlier), but the gain there’s no longer any strategy, because the place under the gold is rotten and not promising. Well, in the next move he again decides to take a break one move, we have already sorted out such problems.I had to modify the strategy - since we memorized all the gold that was eaten at the stage of analysis, subtracting the value cards of the eaten gold from the total matrix of strategic value, thus, the strategy took into account the achievement of tactics (it was possible to calculate value differently - adding matrices only for whole gold, but it is computationally more complicated, because there is much more gold on the map than we can eat in 8 moves).But this did not end our torment. Suppose that the matrix of strategic value has a local maximum and the bot approached it for 7 moves. Will the bot go to it to freeze? No, because for any route in which the bot gets to the local maximum in 8 moves, the win will be the same. Good old procrastination. The reason for which is that the strategic gain does not depend on the moment in which we find ourselves in the cell. The first thing that comes to mind is to fine the bot for a simple one, but this does not help in any way from senseless walking left / right. It is necessary to treat the root cause - to take into account the strategic gain at each turn (as the difference between the strategic value of the new and current states), reducing it over time by a factor.Those. introduce an additional term in the expression for winning:
But the bot freezes in place. Debugging showed that there was no mistake: the bot decided that the optimal strategy was to wait for one move, and then go along the specified route and take gold at the last analyzed step. In the first case, it receives a gain from the received gold and a gain from imaginary gold (at the last analyzed iteration it is just in the cell where the gold was), and in the second - only from real gold (although a turn earlier), but the gain there’s no longer any strategy, because the place under the gold is rotten and not promising. Well, in the next move he again decides to take a break one move, we have already sorted out such problems.I had to modify the strategy - since we memorized all the gold that was eaten at the stage of analysis, subtracting the value cards of the eaten gold from the total matrix of strategic value, thus, the strategy took into account the achievement of tactics (it was possible to calculate value differently - adding matrices only for whole gold, but it is computationally more complicated, because there is much more gold on the map than we can eat in 8 moves).But this did not end our torment. Suppose that the matrix of strategic value has a local maximum and the bot approached it for 7 moves. Will the bot go to it to freeze? No, because for any route in which the bot gets to the local maximum in 8 moves, the win will be the same. Good old procrastination. The reason for which is that the strategic gain does not depend on the moment in which we find ourselves in the cell. The first thing that comes to mind is to fine the bot for a simple one, but this does not help in any way from senseless walking left / right. It is necessary to treat the root cause - to take into account the strategic gain at each turn (as the difference between the strategic value of the new and current states), reducing it over time by a factor.Those. introduce an additional term in the expression for winning:
the value of the objective function on the latter is generally taken to be zero: . Since the gain is depreciated with each move by multiplying by a coefficient, this will make our bot gain faster strategic gain and eliminate the observed problem.Untested strategy
I have not tested this strategy in practice, but it looks promising.- Since we know all the distances between the points of gold, and the distances between the gold and the player, we can find the player-N chain of gold cells (where N is small, for example 5 or 6) with the shortest length. Even the simplest search of time is enough.
- Select the first gold in this chain and use its value field as a strategy matrix.
In this case, it is desirable to make close the cost of real and the cost of imaginary gold so that the bot does not rush into the basement to the nearest gold.Final improvements
After we have learned to “spread out” on the map, let's do a similar “spreading” from each monster for several moves and find all the cells in which the monster may end up, along with the number of moves for which it will make it. This will allow the player to crawl through the pipe over the monster’s head completely safely.And the last moment - when calculating the strategy and the imaginary value of gold, we did not take into account the position of the other players, simply “erasing” them when analyzing the map. It turns out that individual hanging shells can block access to entire regions, so an additional handler was added - to track freezing opponents and replace them with concrete blocks during analysis.Implementation Features
Since the main algorithm is recursive, we must be able to quickly change state objects and return them to their original ones for further modification. I used java, a language with garbage collection, trying out millions of changes related to creating short-lived objects can cause several garbage collections in one turn of the game, which can be fatal in terms of speed. Therefore, one must be extremely careful in the data structures used, I used only arrays and lists. Well, or use the Valgala project at your own peril and risk :)Source Code and Game Server
The source code can be found here on the github . Do not judge strictly, much has been done in haste. The codenjoy game server will provide the infrastructure for launching bots and monitoring the game. At the time of creation, the revision was relevant, revision 1.0.26 was used.You can start the server with the following line:call mvn -DMAVEN_OPTS=-Xmx1024m -Dmaven.test.skip=true clean jetty:run-war -Dcontext=another-context -Ploderunner
The project itself is extremely curious, provides games for every taste.Conclusion
If you have read all this to the end without preliminary preparation and understood everything, then you are a rare fellow.