In complex ERP-systems, many entities have a hierarchical nature , when homogeneous objects line up in an ancestor-descendant relationship tree - this is the organizational structure of the enterprise (all these branches, departments and work groups), and the product catalog, and work areas, and geography points of sale, ... In fact, there is not a single sphere of business automation where at least some hierarchy would not be the result. But even if you do not work “for business,” you can still easily come across hierarchical relationships. Trite, even your family tree or floor scheme of the premises in the shopping center is the same structure. There are many ways to store such a tree in a DBMS, but today we will focus on only one option:
CREATE TABLE hier(
id
integer
PRIMARY KEY
, pid
integer
REFERENCES hier
, data
json
);
CREATE INDEX ON hier(pid);
And while you peer into the depths of the hierarchy, it patiently waits for how [naive] your "naive" ways of working with such a structure will turn out.Let's analyze the typical emerging tasks, their implementation in SQL and try to improve their performance.#1. How deep is the rabbit hole?
Let’s take, for definiteness, that this structure will reflect the subordination of departments in the structure of the organization: departments, divisions, sectors, branches, working groups ... whatever you call them.First, we generate our 'tree' of 10K elementsINSERT INTO hier
WITH RECURSIVE T AS (
SELECT
1::integer id
, '{1}'::integer[] pids
UNION ALL
SELECT
id + 1
, pids[1:(random() * array_length(pids, 1))::integer] || (id + 1)
FROM
T
WHERE
id < 10000
)
SELECT
pids[array_length(pids, 1)] id
, pids[array_length(pids, 1) - 1] pid
FROM
T;
Let's start with the simplest task - to find all employees who work within a specific sector, or in terms of a hierarchy - to find all descendants of a node . It would also be nice to get the “depth” of the descendant ... All this may be necessary, for example, to build some kind of complex selection from the list of IDs of these employees .Everything would be fine if these descendants there are only a couple of levels and quantitatively within a dozen, but if there are more than 5 levels, and there are already dozens of descendants, there may be problems. Let's see how the traditional “down the tree” search options are written (and work). But first, we determine which of the nodes will be the most interesting for our research.The "deepest" subtrees:WITH RECURSIVE T AS (
SELECT
id
, pid
, ARRAY[id] path
FROM
hier
WHERE
pid IS NULL
UNION ALL
SELECT
hier.id
, hier.pid
, T.path || hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T ORDER BY array_length(path, 1) DESC;
id | pid | path
---------------------------------------------
7624 | 7623 | {7615,7620,7621,7622,7623,7624}
4995 | 4994 | {4983,4985,4988,4993,4994,4995}
4991 | 4990 | {4983,4985,4988,4989,4990,4991}
...
The "widest" subtrees:...
SELECT
path[1] id
, count(*)
FROM
T
GROUP BY
1
ORDER BY
2 DESC;
id | count
------------
5300 | 30
450 | 28
1239 | 27
1573 | 25
For these queries, we used a typical recursive JOIN :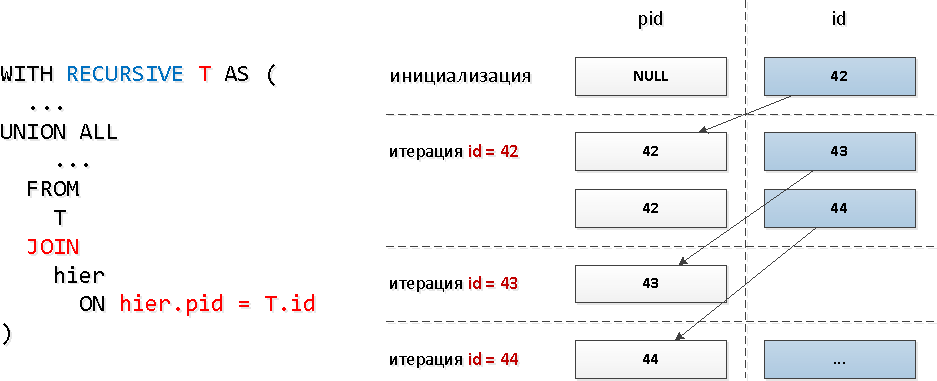 Obviously, with such a query model, the number of iterations will coincide with the total number of descendants (and there are several dozen of them), and this can take quite substantial resources, and, as a result, time.Let's check on the "widest" subtree:
Obviously, with such a query model, the number of iterations will coincide with the total number of descendants (and there are several dozen of them), and this can take quite substantial resources, and, as a result, time.Let's check on the "widest" subtree:WITH RECURSIVE T AS (
SELECT
id
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T;
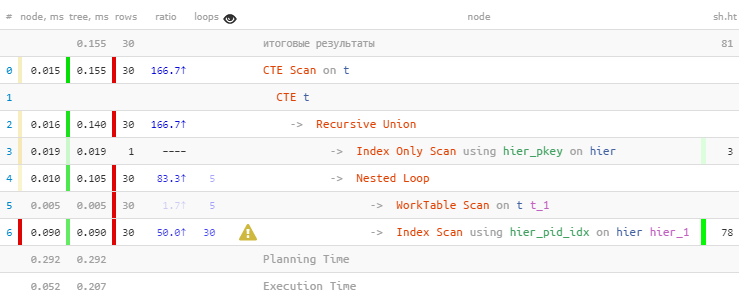 [look at explain.tensor.ru]As expected, we found all 30 entries. But they spent 60% of the whole time on this - because they did 30 searches on the index. And less - is it possible?
[look at explain.tensor.ru]As expected, we found all 30 entries. But they spent 60% of the whole time on this - because they did 30 searches on the index. And less - is it possible?Mass proofreading by index
And for each node, do we need to make a separate index request? It turns out that no - we can read from the index on several keys at once with one call= ANY(array) .And in each such group of identifiers we can take all the IDs found in the previous step by "nodes". That is, at each next step we will immediately search for all the descendants of a certain level at once .But, it’s bad luck, in a recursive selection, you cannot refer to yourself in a sub-query , but we just need to somehow select exactly what was found at the previous level ... It turns out that you cannot make a sub-query to the entire sample, but to its specific field - can. And this field can also be an array - which is what we need to useANY.It sounds a little wild, but on the diagram - everything is simple.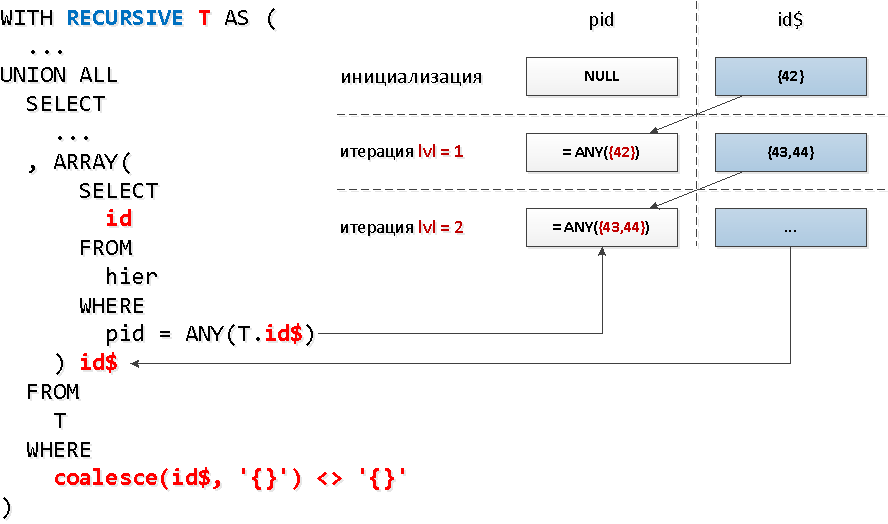
WITH RECURSIVE T AS (
SELECT
ARRAY[id] id$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
ARRAY(
SELECT
id
FROM
hier
WHERE
pid = ANY(T.id$)
) id$
FROM
T
WHERE
coalesce(id$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T;
 [look at explain.tensor.ru]And here the most important thing is not even winning 1.5 times in time , but that we subtracted fewer buffers, since we have only 5 calls to the index instead of 30!An additional bonus is the fact that after the final unnest identifiers will remain ordered by “levels”.
[look at explain.tensor.ru]And here the most important thing is not even winning 1.5 times in time , but that we subtracted fewer buffers, since we have only 5 calls to the index instead of 30!An additional bonus is the fact that after the final unnest identifiers will remain ordered by “levels”.Node tag
The next consideration that will help improve productivity is that “leaves” cannot have children , that is, they don’t need to look down for anything. In the formulation of our task, this means that if we went along the chain of departments and reached the employee, then there is no need to search further on this branch.Let's introduce an additional booleanfield into our table , which will tell us right away whether this particular entry in our tree is a “node” —that is , if it can have any children at all.ALTER TABLE hier
ADD COLUMN branch boolean;
UPDATE
hier T
SET
branch = TRUE
WHERE
EXISTS(
SELECT
NULL
FROM
hier
WHERE
pid = T.id
LIMIT 1
);
Fine! It turns out that only a little more than 30% of all tree elements have descendants.Now LATERALwe’ll apply a slightly different mechanics - connecting to the recursive part through , which will allow us to immediately access the fields of the recursive “table”, and use the aggregate function with the filtering condition based on the node to reduce the set of keys: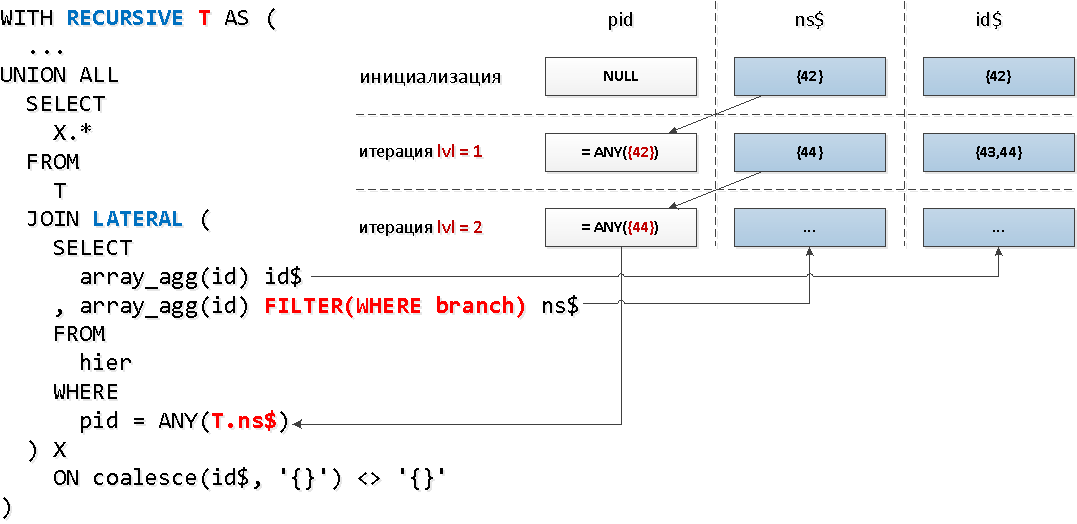
WITH RECURSIVE T AS (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
X.*
FROM
T
JOIN LATERAL (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
pid = ANY(T.ns$)
) X
ON coalesce(T.ns$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T;
 [look at explain.tensor.ru]We were able to reduce another appeal to the index and won more than 2 times in terms of the amount deducted.
[look at explain.tensor.ru]We were able to reduce another appeal to the index and won more than 2 times in terms of the amount deducted.# 2 Back to the roots
This algorithm will be useful if you need to collect records for all elements “up the tree”, while maintaining information about which source sheet (and with which indicators) caused it to fall into the sample — for example, to generate a summary report with aggregation to nodes.The further should be taken exclusively as proof-of-concept, since the request is very cumbersome. But if it dominates your database - it is worth considering the use of such techniques.Let's start with a couple of simple statements:- It is better to read the same record from the database only once .
- Entries from the database are more efficiently read in a "bundle" than individually.
Now let's try to design the query we need.Step 1
Obviously, at the initialization of the recursion (where without it!) We will have to subtract the entries of the leaves themselves from the set of source identifiers:WITH RECURSIVE tree AS (
SELECT
rec
, id::text chld
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
...
If it seemed strange to someone that the “set” is stored in a string, not an array, then there is a simple explanation. For strings, there is a built-in aggregating “gluing” function string_agg, but for arrays, no. Although it is not difficult to implement it yourself .Step 2
Now we would get a set of section IDs that will need to be subtracted further. Almost always, they will be duplicated in different records of the source set - so we would group them , while maintaining information about the source leaves.But here three troubles await us:- The "sub-recursive" part of a query cannot contain aggregate functions c
GROUP BY. - A call to a recursive “table” cannot be in a nested subquery.
- A query in the recursive part cannot contain a CTE.
Fortunately, all of these problems are quite easily bypassed. Let's start from the end.CTE in the recursive part
This is not how it works:WITH RECURSIVE tree AS (
...
UNION ALL
WITH T (...)
SELECT ...
)
And so it works, brackets decide!WITH RECURSIVE tree AS (
...
UNION ALL
(
WITH T (...)
SELECT ...
)
)
Nested query for recursive "table"
Hmm ... A call to a recursive CTE cannot be in a subquery. But it can be inside the CTE! A sub-request can already refer to this CTE!GROUP BY inside recursion
It’s unpleasant, but ... We also have a simple way to simulate GROUP BY using DISTINCT ONwindow functions!SELECT
(rec).pid id
, string_agg(chld::text, ',') chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
GROUP BY 1
And so it works!SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
Now we see why the numeric ID turned into text - so that they can be glued together with a comma!Step 3
For the finale, we have nothing left:- we read records of "sections" on a set of grouped IDs
- match the subtracted sections with the “sets” of source sheets
- “Expand” the set string using
unnest(string_to_array(chld, ',')::integer[])
WITH RECURSIVE tree AS (
SELECT
rec
, id::text chld
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
(
WITH prnt AS (
SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
)
, nodes AS (
SELECT
rec
FROM
hier rec
WHERE
id = ANY(ARRAY(
SELECT
id
FROM
prnt
))
)
SELECT
nodes.rec
, prnt.chld
FROM
prnt
JOIN
nodes
ON (nodes.rec).id = prnt.id
)
)
SELECT
unnest(string_to_array(chld, ',')::integer[]) leaf
, (rec).*
FROM
tree;
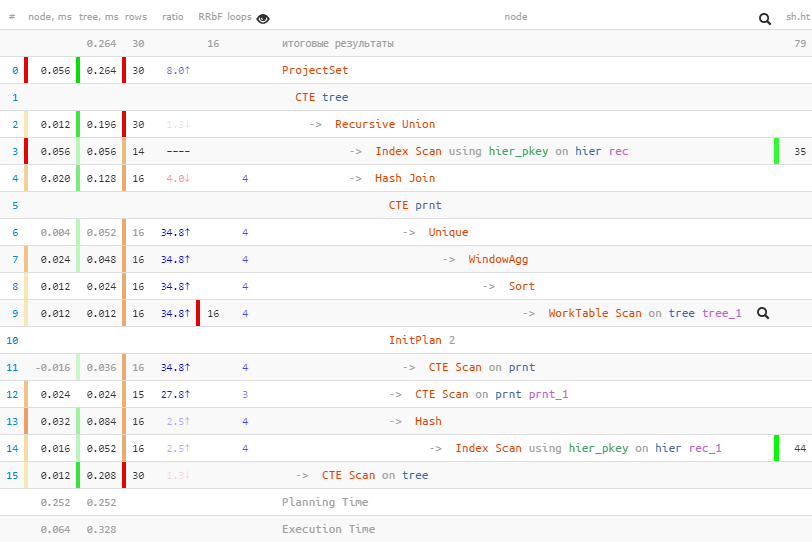 [ explain.tensor.ru]
[ explain.tensor.ru]