Accessing the GPU from Java reveals tremendous power. It describes how the GPU works and how to access from Java.GPU programming is a sky-high world for Java programmers. This is understandable since normal Java tasks are not suitable for the GPU. However, GPUs have teraflops of performance, so let's explore their capabilities.In order to make the topic accessible, I will spend some time explaining the architecture of the GPU along with a little history that will facilitate an immersion in iron programming.Once I was shown the differences between the GPU and the CPU computing, I will show how to use the GPU in the Java world. Finally, I will describe the main frameworks and libraries available for writing Java code and running them on the GPU, and I will give some code examples.A bit of background
The GPU was first popularized by NVIDIA in 1999. It is a special processor designed to process graphic data before it is transferred to the display. In many cases, this allows some computation to offload the CPU, thereby freeing up CPU resources that speed up these unloaded computations. The result is that large input can be processed and presented at a higher output resolution, making the visual presentation more attractive and the frame rate smoother.The essence of 2D / 3D processing is mainly in the manipulation of matrices, this can be controlled using a distributed approach. What will be an effective approach for image processing? To answer this, let's compare the standard CPU architecture (shown in Figure 1.) and the GPU.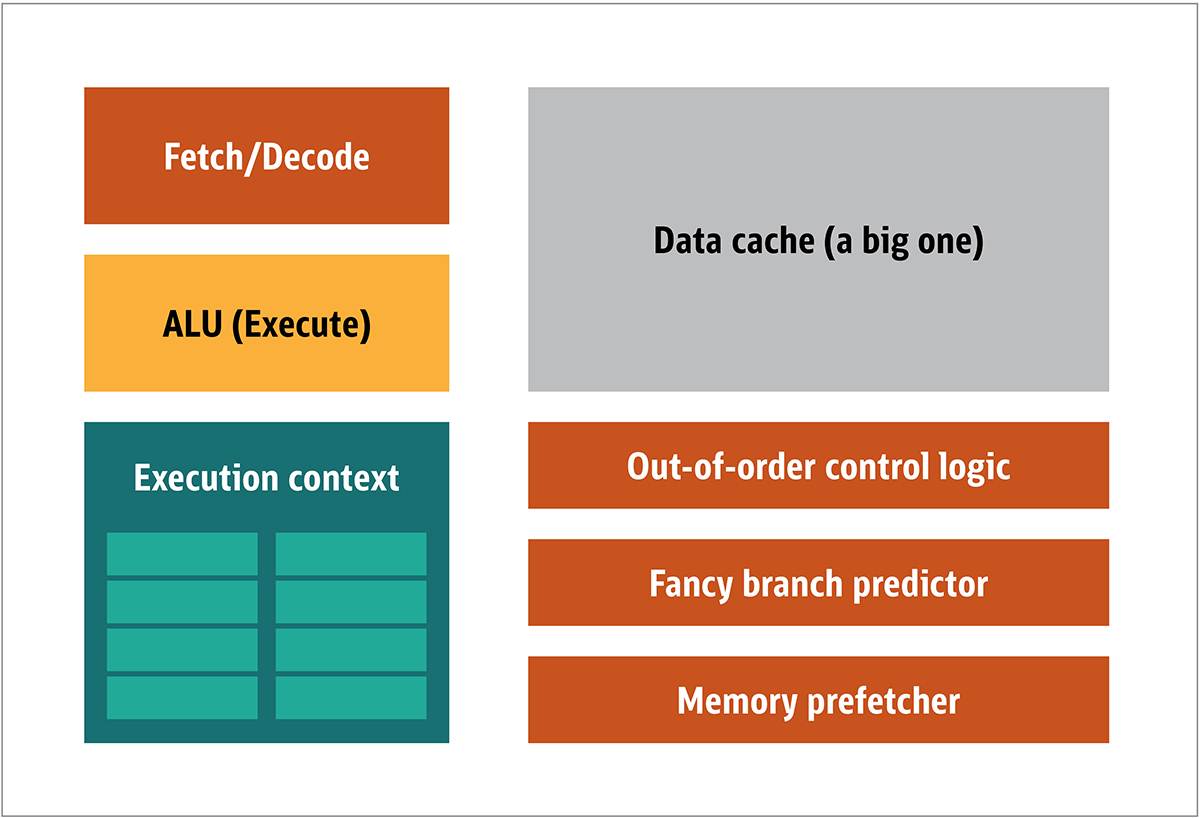 Fig. 1. CPU Architecture BlocksIn the CPU, the actual processing elements - registers, arithmetic logic unit (ALU) and execution contexts - are just small parts of the entire system. To speed up irregular payments coming in an unpredictable order, there is a large, fast, and expensive cache; various types of collectors; and branch predictors.You do not need all this on the GPU, because the data is received in a predictable manner, and the GPU performs a very limited set of operations on the data. Thus, it is possible to make them very small and an inexpensive processor with a block architecture similar to this one is shown in Fig. 2.
Fig. 1. CPU Architecture BlocksIn the CPU, the actual processing elements - registers, arithmetic logic unit (ALU) and execution contexts - are just small parts of the entire system. To speed up irregular payments coming in an unpredictable order, there is a large, fast, and expensive cache; various types of collectors; and branch predictors.You do not need all this on the GPU, because the data is received in a predictable manner, and the GPU performs a very limited set of operations on the data. Thus, it is possible to make them very small and an inexpensive processor with a block architecture similar to this one is shown in Fig. 2.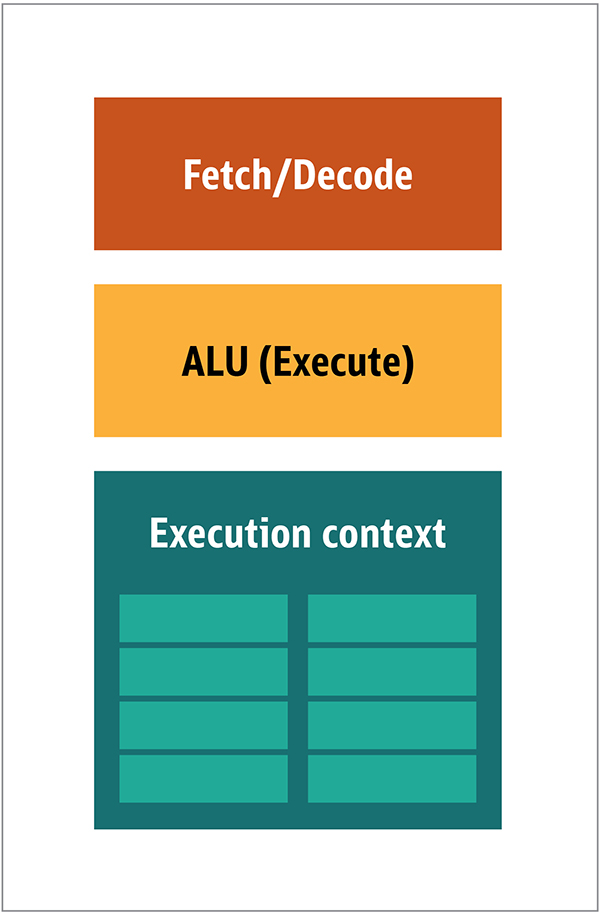 Fig. 2. Block architecture for a simple GPU coreBecause such processors are cheaper and the processed data in them in parallel chunks, it is simple to make many of them work in parallel. It is designed with reference to multiple instructions, multiple data or MIMD (pronounced "mim-dee").The second approach is based on the fact that often a single instruction is applied to multiple pieces of data. This is known as a single instruction, multiple data or SIMD (pronounced “sim-dee”). In this design, a single GPU contains multiple ALUs and execution contexts, small areas transferred to shared context data, as shown in Figure 3.
Fig. 2. Block architecture for a simple GPU coreBecause such processors are cheaper and the processed data in them in parallel chunks, it is simple to make many of them work in parallel. It is designed with reference to multiple instructions, multiple data or MIMD (pronounced "mim-dee").The second approach is based on the fact that often a single instruction is applied to multiple pieces of data. This is known as a single instruction, multiple data or SIMD (pronounced “sim-dee”). In this design, a single GPU contains multiple ALUs and execution contexts, small areas transferred to shared context data, as shown in Figure 3.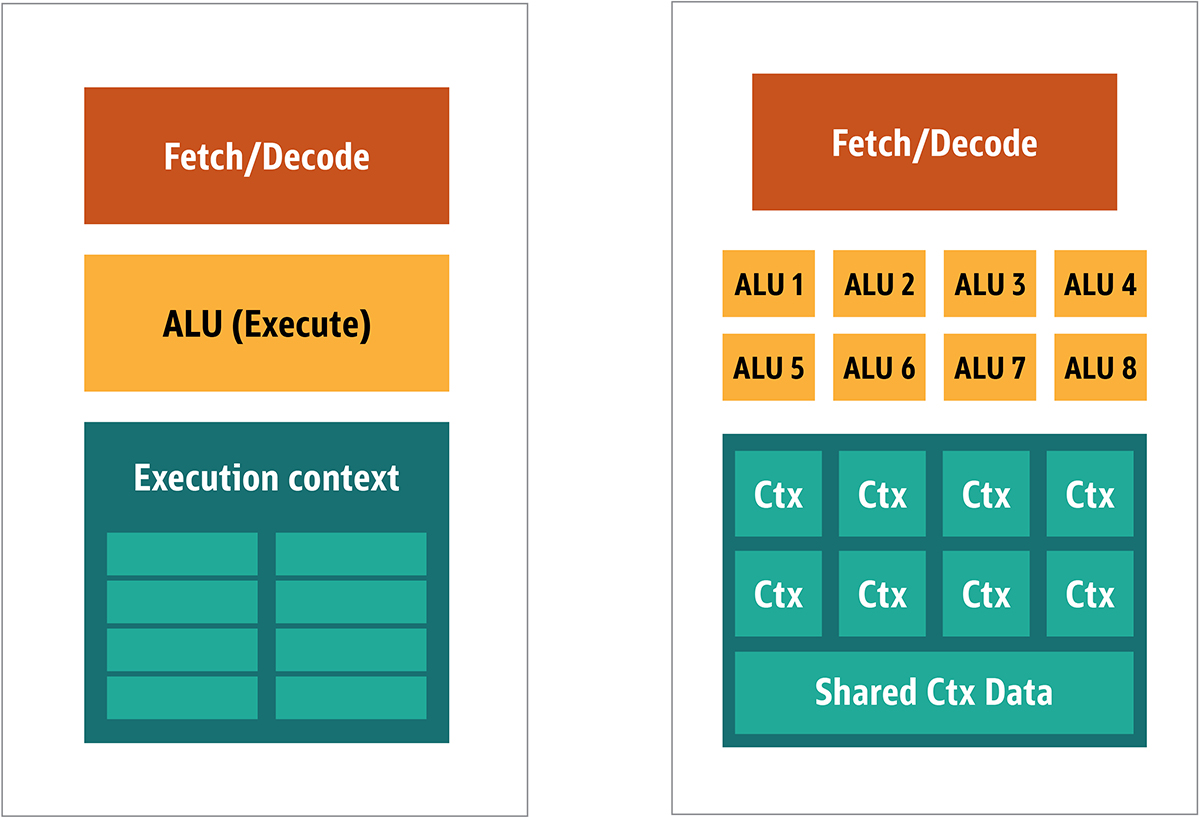 Fig. 3. Comparison of the MIMD-style architecture of the GPU blocks (from the left), with the SIMD design (from the right)Mixing SIMD and MIMD processing provides the maximum bandwidth that I will bypass. In this design, you have multiple SIMD processors running in parallel, as in Figure 4.
Fig. 3. Comparison of the MIMD-style architecture of the GPU blocks (from the left), with the SIMD design (from the right)Mixing SIMD and MIMD processing provides the maximum bandwidth that I will bypass. In this design, you have multiple SIMD processors running in parallel, as in Figure 4. Fig. 4. Working multiple SIMD processors in parallel; there are 16 cores with 128 ALUsSince you have a bunch of small, simple processors, you can program them to get a special effect in the output.
Fig. 4. Working multiple SIMD processors in parallel; there are 16 cores with 128 ALUsSince you have a bunch of small, simple processors, you can program them to get a special effect in the output.Running programs on the GPU
Most of the early graphic effects in games were really hard-coded small programs running on the GPU and applied to data streams from the CPU.This was obvious, even when hard-coded algorithms were insufficient, especially in game design, where visual effects are one of the main magical directions. In response, big sellers opened access to the GPU, and then third-party developers could program them.A typical approach was to write a small program called shaders in a special language (usually a subspecies of C) and compile them using special compilers for the desired architecture. The term shaders was chosen because shaders are often used to control light and shadow effects, but this does not mean that they can control other special effects.Each GPU vendor had its own programming language and infrastructure to create shaders for their architecture. On this approach, many platforms have been created.The main ones are:- DirectCompute: Microsoft's private shader language / API that are part of Direct3D, starting with DirectX 10.
- AMD FireStream: Private ATI / Radeon technologies that are outdated by AMD.
- OpenACC: Multi-Vendor Consortium, Parallel Computing Solution
- ++ AMP: Microsoft C++
- CUDA: Nvidia,
- OpenL: , Apple, Khronos Group
Most of the time, working with the GPU is low-level programming. In order to make this a bit more understandable for developers, for coding, several abstractions were provided. The most famous is DirectX, from Microsoft, and OpenGL, from the Khronos Group. These are APIs for writing high-level code, which can then be simplified for the GPU, more semantically, for the programmer.As far as I know, there is no Java infrastructure for DirectX, but there is a good solution for OpenGL. JSR 231 started in 2002 and is addressed to GPU programmers, but it was abandoned in 2008 and only supports OpenGL 2.0.OpenGL support continues in the independent JOCL project (which also supports OpenCL) and is available to the audience. Thus, the famous Minecraft game was written using JOCL.GPGPU coming
So far, Java and the GPU have had no common ground, although they should be. Java is often used in enterprises, in data science, and in the financial sector, where there is a lot of computing and where a lot of computing power is needed. This is how the idea of general-purpose GPU (GPGPU) is. The idea of using the GPU along this path began when the manufacturers of video adapters began giving access to the program frame buffer, allowing developers to read the contents. Some hackers have determined that they can use the full power of the GPU for universal computing.The recipe was like this:- Encode data as a raster array.
- Write shaders to handle them.
- Send them both to the graphics card.
- Get result from frame buffer
- Decode data from a raster array.
This is a very simple explanation. I'm not sure if this will work in production, but it really works.Then, numerous studies from the Stanford Institute began to simplify the use of GPUs. In 2005, they made BrookGPU, which was a small ecosystem that included a programming language, compiler, and runtime.BrookGPU compiled programs written in the Brook thread programming language, which was an ANSI C variant. It can target OpenGL v1.3 +, DirectX v9 + or AMD Close to Metal for the server computing part, and it runs on Microsoft Windows and Linux. For debugging, BrookGPU can also simulate a virtual graphics card on the CPU.However, this did not take off, due to the equipment available at that time. In the GPGPU world, you need to copy data to the device (in this context, the device refers to the GPU and the device on which it is located), wait for the GPU to calculate the data, and then copy the data back to the control program. This creates a lot of delays. And in the mid-2000s, when the project was under active development, these delays also excluded the intensive use of the GPU for basic computing.However, many companies have seen the future in this technology. Several developers of video adapters began to provide GPGPUs with their proprietary technologies, and other formed alliances provided less basic, versatile programming models that worked on a large amount of hardware.Now that I’ve told you everything, let's check out the two most successful GPU computing technologies - OpenCL and CUDA - see also how Java works with them.OpenCL and Java
Like other infrastructure packages, OpenCL provides a basic implementation in C. This is technically available using the Java Native Interface (JNI) or Java Native Access (JNA), but this approach will be too difficult for most developers.Fortunately, this work has already been done by several libraries: JOCL, JogAmp, and JavaCL. Unfortunately, JavaCL has become a dead project. But the JOCL project is alive and very adapted. I will use it for the following examples.But first I have to explain what OpenCL is. I mentioned earlier that OpenCL provides a very basic model suitable for programming all kinds of devices - not just GPUs and CPUs, but even DSP processors and FPGAs.Let's look at the simplest example: folding vectors is probably the brightest and simplest example. You have two arrays of numbers for addition and one for the result. You take an element from the first array and an element from the second array, and then you put the sum into the array of results, as shown in Fig. 5.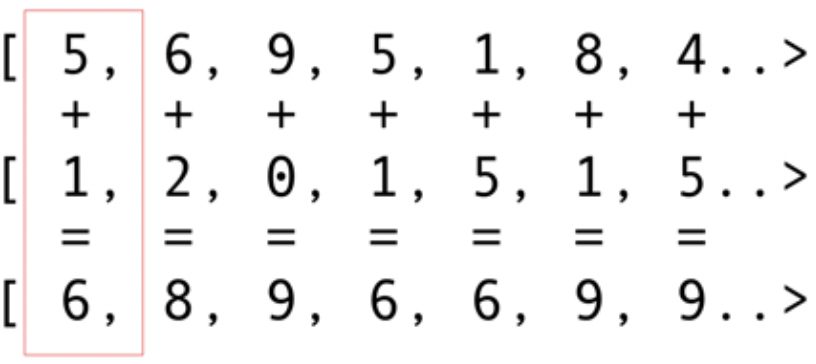 Fig. 5. Adding the elements of two arrays and storing the sum in the resulting arrayAs you can see, the operation is very consistent and nonetheless distributed. You can push each addition operation into different core GPUs. This means that if you have 2048 cores, like on the Nvidia 1080, you can perform 2048 addition operations at the same time. This means that here the potential teraflops of computer power are waiting for you. This code for an array of 10 million numbers is taken from the JOCL website:
Fig. 5. Adding the elements of two arrays and storing the sum in the resulting arrayAs you can see, the operation is very consistent and nonetheless distributed. You can push each addition operation into different core GPUs. This means that if you have 2048 cores, like on the Nvidia 1080, you can perform 2048 addition operations at the same time. This means that here the potential teraflops of computer power are waiting for you. This code for an array of 10 million numbers is taken from the JOCL website:public class ArrayGPU {
private static String programSource =
"__kernel void "+
"sampleKernel(__global const float *a,"+
" __global const float *b,"+
" __global float *c)"+
"{"+
" int gid = get_global_id(0);"+
" c[gid] = a[gid] + b[gid];"+
"}";
public static void main(String args[])
{
int n = 10_000_000;
float srcArrayA[] = new float[n];
float srcArrayB[] = new float[n];
float dstArray[] = new float[n];
for (int i=0; i<n; i++)
{
srcArrayA[i] = i;
srcArrayB[i] = i;
}
Pointer srcA = Pointer.to(srcArrayA);
Pointer srcB = Pointer.to(srcArrayB);
Pointer dst = Pointer.to(dstArray);
final int platformIndex = 0;
final long deviceType = CL.CL_DEVICE_TYPE_ALL;
final int deviceIndex = 0;
CL.setExceptionsEnabled(true);
int numPlatformsArray[] = new int[1];
CL.clGetPlatformIDs(0, null, numPlatformsArray);
int numPlatforms = numPlatformsArray[0];
cl_platform_id platforms[] = new cl_platform_id[numPlatforms];
CL.clGetPlatformIDs(platforms.length, platforms, null);
cl_platform_id platform = platforms[platformIndex];
cl_context_properties contextProperties = new cl_context_properties();
contextProperties.addProperty(CL.CL_CONTEXT_PLATFORM, platform);
int numDevicesArray[] = new int[1];
CL.clGetDeviceIDs(platform, deviceType, 0, null, numDevicesArray);
int numDevices = numDevicesArray[0];
cl_device_id devices[] = new cl_device_id[numDevices];
CL.clGetDeviceIDs(platform, deviceType, numDevices, devices, null);
cl_device_id device = devices[deviceIndex];
cl_context context = CL.clCreateContext(
contextProperties, 1, new cl_device_id[]{device},
null, null, null);
cl_command_queue commandQueue =
CL.clCreateCommandQueue(context, device, 0, null);
cl_mem memObjects[] = new cl_mem[3];
memObjects[0] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcA, null);
memObjects[1] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcB, null);
memObjects[2] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_WRITE,
Sizeof.cl_float * n, null, null);
cl_program program = CL.clCreateProgramWithSource(context,
1, new String[]{ programSource }, null, null);
CL.clBuildProgram(program, 0, null, null, null, null);
cl_kernel kernel = CL.clCreateKernel(program, "sampleKernel", null);
CL.clSetKernelArg(kernel, 0,
Sizeof.cl_mem, Pointer.to(memObjects[0]));
CL.clSetKernelArg(kernel, 1,
Sizeof.cl_mem, Pointer.to(memObjects[1]));
CL.clSetKernelArg(kernel, 2,
Sizeof.cl_mem, Pointer.to(memObjects[2]));
long global_work_size[] = new long[]{n};
long local_work_size[] = new long[]{1};
CL.clEnqueueNDRangeKernel(commandQueue, kernel, 1, null,
global_work_size, local_work_size, 0, null, null);
CL.clEnqueueReadBuffer(commandQueue, memObjects[2], CL.CL_TRUE, 0,
n * Sizeof.cl_float, dst, 0, null, null);
CL.clReleaseMemObject(memObjects[0]);
CL.clReleaseMemObject(memObjects[1]);
CL.clReleaseMemObject(memObjects[2]);
CL.clReleaseKernel(kernel);
CL.clReleaseProgram(program);
CL.clReleaseCommandQueue(commandQueue);
CL.clReleaseContext(context);
}
private static String getString(cl_device_id device, int paramName) {
long size[] = new long[1];
CL.clGetDeviceInfo(device, paramName, 0, null, size);
byte buffer[] = new byte[(int)size[0]];
CL.clGetDeviceInfo(device, paramName, buffer.length, Pointer.to(buffer), null);
return new String(buffer, 0, buffer.length-1);
}
}
This code is not like Java code, but it is. I will explain the code further; don't spend a lot of time on it now, because I will briefly discuss complex solutions.The code will be documented, but let's do a little walkthrough. As you can see, the code is very similar to the code in C. This is normal because JOCL is just OpenCL. In the beginning, here is some code in the line, and this code is the most important part: It is compiled using OpenCL and then sent to the video card, where it is executed. This code is called Kernel. Do not confuse this term with OC Kernel; This is the device code. This code is written in a subset of C.After kernel comes Java code to install and configure the device, split the data, and create the appropriate memory buffers for the resulting data.To summarize: here is the “host code”, which is usually a language binding (in our case, in Java), and the “device code”. You always highlight what will work on the host and what should work on the device, because the host controls the device.The preceding code should show the GPU equivalent to "Hello World!" As you can see, most of it is huge.Let's not forget about SIMD features. If your device supports SIMD extension, you can make arithmetic code faster. For an example, let's take a look at kernel matrix multiplication code. This code is in a simple Java line in the application.__kernel void MatrixMul_kernel_basic(int dim,
__global float *A,
__global float *B,
__global float *C){
int iCol = get_global_id(0);
int iRow = get_global_id(1);
float result = 0.0;
for(int i=0; i< dim; ++i)
{
result +=
A[iRow*dim + i]*B[i*dim + iCol];
}
C[iRow*dim + iCol] = result;
}
Technically, this code will work on pieces of data that were installed for you by the OpenCL framework, with the instructions that you called in the preparatory part.If your video card supports SIMD instructions and can process a vector of four floating-point numbers, small optimizations can turn the previous code into the following:#define VECTOR_SIZE 4
__kernel void MatrixMul_kernel_basic_vector4(
size_t dim,
const float4 *A,
const float4 *B,
float4 *C)
{
size_t globalIdx = get_global_id(0);
size_t globalIdy = get_global_id(1);
float4 resultVec = (float4){ 0, 0, 0, 0 };
size_t dimVec = dim / 4;
for(size_t i = 0; i < dimVec; ++i) {
float4 Avector = A[dimVec * globalIdy + i];
float4 Bvector[4];
Bvector[0] = B[dimVec * (i * 4 + 0) + globalIdx];
Bvector[1] = B[dimVec * (i * 4 + 1) + globalIdx];
Bvector[2] = B[dimVec * (i * 4 + 2) + globalIdx];
Bvector[3] = B[dimVec * (i * 4 + 3) + globalIdx];
resultVec += Avector[0] * Bvector[0];
resultVec += Avector[1] * Bvector[1];
resultVec += Avector[2] * Bvector[2];
resultVec += Avector[3] * Bvector[3];
}
C[dimVec * globalIdy + globalIdx] = resultVec;
}
With this code you can double the performance.Cool. You have just opened the GPU for the Java world! But as a Java developer, do you really want to do all this dirty work, with C code, and working with such low-level details? I do not want. But now that you have some knowledge of how the GPU is used, let's look at another solution that is different from the JOCL code that I just presented.CUDA and Java
CUDA is Nvidia's solution to this programming issue. CUDA provides many more ready-to-use libraries for standard GPU operations, such as matrices, histograms, and even deep neural networks. A list of libraries has already appeared with a bunch of ready-made solutions. This is all from the JCuda project:- JCublas: everything for matrices
- JCufft: Fast Fourier Transform
- JCurand: Everything for Random Numbers
- JCusparse: rare matrices
- JCusolver: factorization of numbers
- JNvgraph: everything for graphs
- JCudpp: CUDA library of primitive parallel data and some sorting algorithms
- JNpp: GPU image processing
- JCudnn: deep neural network library
I am considering using JCurand, which generates random numbers. You can use this from Java code without another special Kernel language. For example:...
int n = 100;
curandGenerator generator = new curandGenerator();
float hostData[] = new float[n];
Pointer deviceData = new Pointer();
cudaMalloc(deviceData, n * Sizeof.FLOAT);
curandCreateGenerator(generator, CURAND_RNG_PSEUDO_DEFAULT);
curandSetPseudoRandomGeneratorSeed(generator, 1234);
curandGenerateUniform(generator, deviceData, n);
cudaMemcpy(Pointer.to(hostData), deviceData,
n * Sizeof.FLOAT, cudaMemcpyDeviceToHost);
System.out.println(Arrays.toString(hostData));
curandDestroyGenerator(generator);
cudaFree(deviceData);
...
It uses a GPU to create a large number of random numbers of very high quality, based on very strong math.In JCuda, you can also write generic CUDA code and call it from Java by calling some JAR file in your classpath. See the JCuda documentation for great examples.Stay above low level code
It all looks great, but there is too much code, too much installation, too many different languages to run it all. Is there a way to use the GPU at least partially?What if you don’t want to think about all this OpenCL, CUDA, and other unnecessary things? What if you only want to program in Java and not think about everything that is not obvious? Aparapi project can help. Aparapi is based on a "parallel API." I think of it as some part of Hibernate for GPU programming that uses OpenCL under the hood. Let's take a look at an example of vector addition.public static void main(String[] _args) {
final int size = 512;
final float[] a = new float[size];
final float[] b = new float[size];
for (int i = 0; i < size; i++){
a[i] = (float) (Math.random() * 100);
b[i] = (float) (Math.random() * 100);
}
final float[] sum = new float[size];
Kernel kernel = new Kernel(){
@Override public void run() {
I int gid = getGlobalId();
sum[gid] = a[gid] + b[gid];
}
};
kernel.execute(Range.create(size));
for(int i = 0; i < size; i++) {
System.out.printf("%6.2f + %6.2f = %8.2f\n", a[i], b[i], sum[i])
}
kernel.dispose();
}
Here is pure Java code (taken from the Aparapi documentation), also here and there, you can see a certain term Kernel and getGlobalId. You still need to understand how to program the GPU, but you can use the GPGPU approach in a more Java-like manner. Moreover, Aparapi provides an easy way to use OpenGL context to the OpenCL layer - thereby allowing the data to remain completely on the graphics card - and thereby avoid memory latency issues.If you need to do a lot of independent calculations, look at Aparapi. There are many examples of how to use parallel computing.In addition, there is some project called TornadoVM - it automatically transfers the appropriate calculations from the CPU to the GPU, thus providing mass optimization out of the box.findings
There are many applications where GPUs can bring some advantages, but you could say that there are still some obstacles. However, Java and the GPU can do great things together. In this article, I only touched on this extensive topic. I intended to show various high and low level options for accessing the GPU from Java. Exploring this area will provide tremendous performance benefits, especially for complex tasks that require multiple calculations that can be performed in parallel.Source Link