I’ll explain the title of the article right away. Initially, it was planned to give good, reliable advice on accelerating the use of reflexion using a simple but realistic example, but during benchmarking it turned out that reflection does not work as slowly as I thought, LINQ works slower than dreamed of in nightmares. But in the end it turned out that I also made a mistake in the measurements ... Details of this life story under the cut and in the comments. Since the example is quite everyday and implemented in principle, as is usually done in the enterprise, it turned out to be quite interesting, as it seems to me, a demonstration of life: there was no noticeable effect on the speed of the main subject of the article due to external logic: Moq, Autofac, EF Core, etc. "Strapping".I started my work under the impression of this article: Why is Reflection slowAs you can see, the author suggests using compiled delegates instead of directly invoking reflection type methods as a great way to greatly speed up the application. There is, of course, IL emission, but I would like to avoid it, since this is the most labor-intensive way to complete the task, which is fraught with errors.Considering that I always adhered to a similar opinion about the speed of reflection, I did not intend to cast particular doubt on the conclusions of the author.I often encounter the naive use of reflection in an enterprise. Type is taken. Property information is taken. The SetValue method is called, and everyone is happy. The value flew into the target field, everyone is happy. People who are very clever - siniors and team leaders - write their extensions on object, basing on such a naive implementation of "universal" mappers of one type in another. The essence of this is usually: we take all the fields, we take all the properties, iterate over them: if the names of the type members coincide, we execute SetValue. We periodically catch exceptions on misses where one of the types did not find some property, but there is also a way out that achieves performance. Try / catch.I saw people reinventing parsers and mappers without being fully armed with information on how the bikes invented before them work. I saw people hide their naive implementations behind strategies, behind interfaces, behind injections, as if this would excuse the subsequent bacchanalia. From such implementations I turned my nose. In fact, I did not measure the real performance leak, and if possible, I simply changed the implementation to a more “optimal” one, if my hands reached. Because the first measurements, which are discussed below, I was seriously embarrassed.I think many of you, when reading Richter or other ideologists, have come up with the quite fair assertion that reflection in code is a phenomenon that has an extremely negative effect on application performance.The reflection call forces the CLR to go around the assembly in search of the right one, pull up its metadata, parse it, etc. In addition, reflection during sequence traversal leads to the allocation of a large amount of memory. We spend memory, the CLR uncovers the HZ and freezes raced. It should be noticeably slow, believe me. The huge amounts of memory of modern production servers or cloud machines do not save from high processing delays. In fact, the more memory, the higher the likelihood that you WILL NOTICE how the HZ works. Reflection is, in theory, an extra red rag for him.Nevertheless, we all use both IoC containers and date mappers, the principle of which is also based on reflection, however, questions about their performance usually do not arise. No, not because the introduction of dependencies and abstracting from models of external limited context is so necessary things that we have to sacrifice performance in any case. Everything is simpler - it really does not greatly affect performance.The fact is that the most common frameworks that are based on reflection technology use all kinds of tricks to work with it more optimally. This is usually a cache. Usually these are Expressions and delegates compiled from the expression tree. The same auto-mapper holds a competitive dictionary, matching types with functions that they can convert to one another without calling reflection.How is this achieved? In fact, this is no different from the logic that the platform itself uses to generate JIT code. When you first call a method, it compiles (and, yes, this process is not fast), with subsequent calls, control is transferred to the already compiled method, and there will be no special performance drawdowns.In our case, you can also use JIT compilation and then use the compiled behavior with the same performance as its AOT counterparts. In this case, expressions will come to our aid.Briefly, we can formulate the principle in question as follows: Thefinal result of the reflection should be cached in the form of a delegate containing a compiled function. It also makes sense to cache all the necessary objects with information about types in fields of your type that are stored outside objects — the worker.There is logic in this. Common sense tells us that if something can be compiled and cached, then this should be done.Looking ahead, it should be said that the cache in working with reflection has its advantages, even if you do not use the proposed method for compiling expressions. Actually, here I am simply repeating the theses of the author of the article to which I refer above.Now about the code. Let's look at an example that is based on my recent pain that I had to face in serious production of a serious credit organization. All entities are fictitious so that no one would guess.There is a certain entity. Let it be Contact. There are letters with a standardized body, from which the parser and hydrator create these same contacts. A letter arrived, we read it, disassembled the key-value pairs, created a contact, saved it in the database.This is elementary. Suppose a contact has the name, age, and contact number of the property. These data are transmitted in a letter. Also, the business wants support to be able to quickly add new keys for mapping entity properties to pairs in the body of the letter. In case someone imprinted in the template or if prior to release it would be necessary to urgently start mapping from a new partner, adjusting to the new format. Then we can add a new mapping correlation as a cheap datafix. That is, a life example.We implement, create tests. Works.I will not give the code: there were a lot of source codes, and they are available on GitHub by the link at the end of the article. You can download them, torture them beyond recognition and measure them, as it would affect your case. I will give only the code of two template methods that distinguish the hydrator, which should have been fast from the hydrator, which should have been slow.The logic is as follows: the template method receives the pairs formed by the base parser logic. The LINQ level is a parser and the basic logic of the hydrator, making a request to the db context and matching keys with pairs from the parser (for these functions there is a code without LINQ for comparison). Next, the pairs are transferred to the main hydration method and the values of the pairs are set to the corresponding properties of the entity.“Fast” (Fast prefix in benchmarks): protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var setterMapItem in _proprtySettersMap)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == setterMapItem.Key);
setterMapItem.Value(contact, correlation?.Value);
}
return contact;
}
As we can see, a static collection with property setters is used - compiled lambdas that call the setter entity. Generated by the following code: static FastContactHydrator()
{
var type = typeof(Contact);
foreach (var property in type.GetProperties())
{
_proprtySettersMap[property.Name] = GetSetterAction(property);
}
}
private static Action<Contact, string> GetSetterAction(PropertyInfo property)
{
var setterInfo = property.GetSetMethod();
var paramValueOriginal = Expression.Parameter(property.PropertyType, "value");
var paramEntity = Expression.Parameter(typeof(Contact), "entity");
var setterExp = Expression.Call(paramEntity, setterInfo, paramValueOriginal).Reduce();
var lambda = (Expression<Action<Contact, string>>)Expression.Lambda(setterExp, paramEntity, paramValueOriginal);
return lambda.Compile();
}
In general, it is clear. We go around the properties, create delegates for them that call the setters, and save them. Then we call when necessary."Slow" (Slow prefix in benchmarks): protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var property in _properties)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == property.Name);
if (correlation?.Value == null)
continue;
property.SetValue(contact, correlation.Value);
}
return contact;
}
Here we immediately go around the properties and call SetValue directly.For clarity and as a reference, I implemented a naive method that writes the values of their correlation pairs directly to the entity fields. The prefix is Manual.Now we take BenchmarkDotNet and we study productivity. And suddenly ... (spoiler is not the right result, details are below)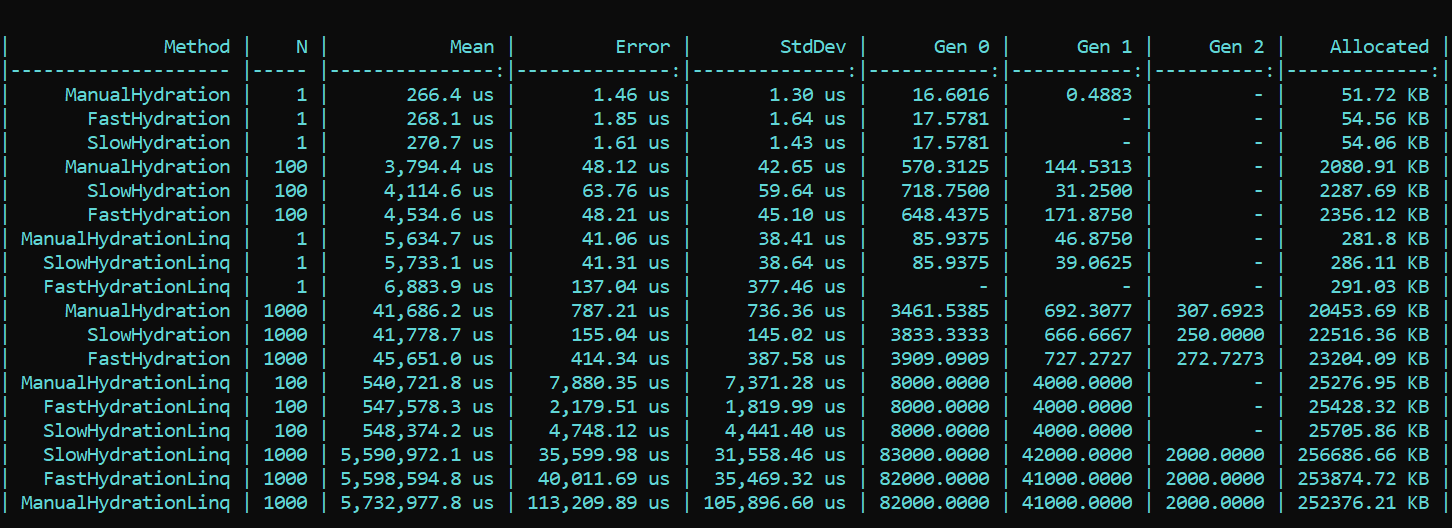 What do we see here? Methods that triumphantly wear the Fast prefix turn out to be slower in almost all passes than methods with the Slow prefix. This is true for allocation, and for speed. On the other hand, the beautiful and elegant implementation of mapping using LINQ methods designed for this purpose, on the contrary, greatly eats up performance. The difference in orders. The trend does not change with a different number of passes. The difference is only in scale. With LINQ 4 to 200 times slower, there is more debris at about the same scale.UPDATEDI could not believe my eyes, but more importantly, neither my eyes nor my code was believed by our colleague - Dmitry Tikhonov 0x1000000. Having rechecked my solution, he brilliantly discovered and pointed out an error that I missed due to a number of changes in the implementation. After fixing the found bug in the Moq setup, all the results fell into place. According to the results of the retest, the main trend does not change - LINQ affects the performance is still stronger than reflection. However, it’s nice that work with compiling Expressions is not in vain, and the result is visible both in allocation and in runtime. The first run, when static fields are initialized, is naturally slower in the “fast” method, but the situation changes further.Here is the result of the retest:
What do we see here? Methods that triumphantly wear the Fast prefix turn out to be slower in almost all passes than methods with the Slow prefix. This is true for allocation, and for speed. On the other hand, the beautiful and elegant implementation of mapping using LINQ methods designed for this purpose, on the contrary, greatly eats up performance. The difference in orders. The trend does not change with a different number of passes. The difference is only in scale. With LINQ 4 to 200 times slower, there is more debris at about the same scale.UPDATEDI could not believe my eyes, but more importantly, neither my eyes nor my code was believed by our colleague - Dmitry Tikhonov 0x1000000. Having rechecked my solution, he brilliantly discovered and pointed out an error that I missed due to a number of changes in the implementation. After fixing the found bug in the Moq setup, all the results fell into place. According to the results of the retest, the main trend does not change - LINQ affects the performance is still stronger than reflection. However, it’s nice that work with compiling Expressions is not in vain, and the result is visible both in allocation and in runtime. The first run, when static fields are initialized, is naturally slower in the “fast” method, but the situation changes further.Here is the result of the retest: Conclusion: when using reflection in an enterprise, resorting to tricks is not particularly required - LINQ will gobble up performance more strongly. However, in highly loaded methods requiring optimization, one can preserve reflection in the form of initializers and delegate compilers, which will then provide “fast” logic. So you can maintain the flexibility of reflection, and the speed of the application.A code with a benchmark is available here. Everyone can double-check my words:HabraReflectionTestsPS: the code uses IoC in the tests, and the explicit design in the benchmarks. The fact is that in the final implementation, I compartment all factors that can affect performance and make noise.PPS: Thanks to Dmitry Tikhonov @ 0x1000000for detecting my error in the Moq setup, which affected the first measurements. If any of the readers have enough karma, like it, please. The man stopped, the man read, the man double-checked and indicated an error. I think this is worthy of respect and sympathy.PPPS: thanks to that meticulous reader who got to the bottom of style and design. I am for uniformity and convenience. The diplomacy of the presentation leaves much to be desired, but I took into account the criticism. I ask for the shell.
Conclusion: when using reflection in an enterprise, resorting to tricks is not particularly required - LINQ will gobble up performance more strongly. However, in highly loaded methods requiring optimization, one can preserve reflection in the form of initializers and delegate compilers, which will then provide “fast” logic. So you can maintain the flexibility of reflection, and the speed of the application.A code with a benchmark is available here. Everyone can double-check my words:HabraReflectionTestsPS: the code uses IoC in the tests, and the explicit design in the benchmarks. The fact is that in the final implementation, I compartment all factors that can affect performance and make noise.PPS: Thanks to Dmitry Tikhonov @ 0x1000000for detecting my error in the Moq setup, which affected the first measurements. If any of the readers have enough karma, like it, please. The man stopped, the man read, the man double-checked and indicated an error. I think this is worthy of respect and sympathy.PPPS: thanks to that meticulous reader who got to the bottom of style and design. I am for uniformity and convenience. The diplomacy of the presentation leaves much to be desired, but I took into account the criticism. I ask for the shell.