Hi, my name is Alexander Vasin, I’m a backend developer in Edadil. The idea of this material began with the fact that I wanted to parse the introductory assignment ( Ya.Disk ) into the Yandex Backend Development School. I began to describe all the subtleties of the choice of certain technologies, the testing methodology ... It turned out to be no analysis at all, but a very detailed guide on how to write backends in Python. From the initial idea there were only requirements for the service, on the example of which it is convenient to disassemble tools and technologies. As a result, I woke up on a hundred thousand characters. Exactly so much was required to consider everything in great detail. So, the program for the next 100 kilobytes: how to build a service backend, from the choice of tools to the deployment. TL; DR: Here is a GitHub rep with application, and who loves (real) longreads - please, under cat.We will develop and test the REST API service in Python, pack it in a lightweight Docker container and deploy it using Ansible.
TL; DR: Here is a GitHub rep with application, and who loves (real) longreads - please, under cat.We will develop and test the REST API service in Python, pack it in a lightweight Docker container and deploy it using Ansible.You can implement the REST API service in different ways using different tools. The described solution is not the only right one, I chose the implementation and tools based on my personal experience and preferences.
What do we do?
Imagine that an online gift store plans to launch an action in different regions. For a sales strategy to be effective, market analysis is needed. The store has a supplier who regularly sends (for example, by mail) data unloading with information about residents.Let's develop a Python REST API service that will analyze the data provided and identify the demand for gifts from residents of different age groups in different cities by month.We implement the following handlers in the service:POST /imports
Adds a new upload with data;
GET /imports/$import_id/citizens
Returns the residents of the specified discharge;
PATCH /imports/$import_id/citizens/$citizen_id
Changes information about the resident (and his relatives) in the specified unloading;
GET /imports/$import_id/citizens/birthdays
, ( ), ;
GET /imports/$import_id/towns/stat/percentile/age
50-, 75- 99- ( ) .
?
So, we are writing a service in Python using familiar frameworks, libraries and DBMS.In 4 lectures of the video course, various DBMSs and their features are described. For my implementation, I chose the PostgreSQL DBMS , which has established itself as a reliable solution with excellent documentation in Russian , a strong Russian community (you can always find the answer to a question in Russian), and even free courses . The relational model is quite versatile and well understood by many developers. Although the same thing could be done on any NoSQL DBMS, in this article we will consider PostgreSQL.The main objective of the service - data transmission over the network between the database and clients - does not imply a large load on the processor, but requires the ability to process multiple requests at one time. In 10 lectures considered asynchronous approach. It allows you to efficiently serve multiple clients within the same OS process (unlike, for example, the pre-fork model used in Flask / Django, which creates several processes for processing requests from users, each of them consumes memory, but is idle most of the time ) Therefore, as a library for writing the service, I chose asynchronous aiohttp . The 5th lecture of the video course tells that SQLAlchemy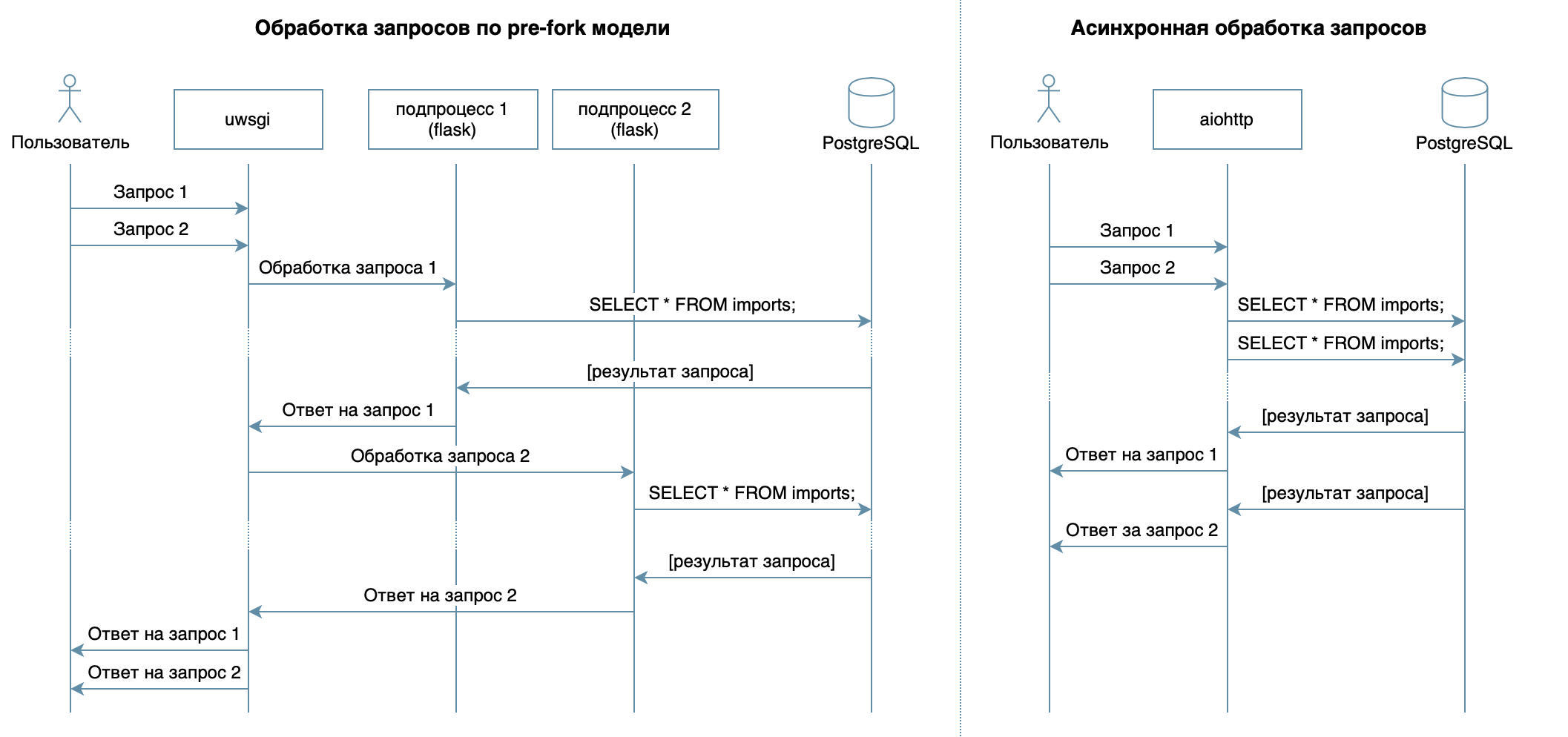 allows you to decompose complex queries into parts, reuse them, generate queries with a dynamic set of fields (for example, the PATCH processor allows partial updating of a resident with arbitrary fields) and focus directly on business logic. The asyncpg driver can handle these requests and transfer the data the fastest , and asyncpgsa will help them make friends .My favorite tool for managing the state of the database and working with migrations is Alembic . By the way, I recently talked about it in Moscow Python .The logic of validation was succinctly described by Marshmallow schemes (including checks for family ties). Using the aiohttp-spec moduleI linked aiohttp-handlers and schemes for data validation, and the bonus was to generate documentation in Swagger format and display it in a graphical interface .For writing tests, I chose
allows you to decompose complex queries into parts, reuse them, generate queries with a dynamic set of fields (for example, the PATCH processor allows partial updating of a resident with arbitrary fields) and focus directly on business logic. The asyncpg driver can handle these requests and transfer the data the fastest , and asyncpgsa will help them make friends .My favorite tool for managing the state of the database and working with migrations is Alembic . By the way, I recently talked about it in Moscow Python .The logic of validation was succinctly described by Marshmallow schemes (including checks for family ties). Using the aiohttp-spec moduleI linked aiohttp-handlers and schemes for data validation, and the bonus was to generate documentation in Swagger format and display it in a graphical interface .For writing tests, I chose pytest, more about it in 3 lectures .To debug and profile this project, I used the PyCharm debugger ( lecture 9 ).In 7 lecture describes how to any computer Docker (or even on different OS) can run packaged without having to adjust the application environment for starting and easy to install / update / delete the application on the server.For the deployment, I chose Ansible. It allows you to declaratively describe the desired state of the server and its services, works via ssh and does not require special software.Development
I decided to give the Python package a name analyzerand use the following structure: In the file
In the file analyzer/__init__.pyI posted general information about the package: description ( docstring ), version, license, developer contacts.It can be viewed with the help built-in$ python
>>> import analyzer
>>> help(analyzer)
Help on package analyzer:
NAME
analyzer
DESCRIPTION
REST API, .
PACKAGE CONTENTS
api (package)
db (package)
utils (package)
DATA
__all__ = ('__author__', '__email__', '__license__', '__maintainer__',...
__email__ = 'alvassin@yandex.ru'
__license__ = 'MIT'
__maintainer__ = 'Alexander Vasin'
VERSION
0.0.1
AUTHOR
Alexander Vasin
FILE
/Users/alvassin/Work/backendschool2019/analyzer/__init__.py
The package has two input points - the REST API service ( analyzer/api/__main__.py) and the database state management utility ( analyzer/db/__main__.py). Files are called __main__.pyfor a reason - firstly, such a name attracts attention, it makes it clear that the file is an entry point.Secondly, thanks to this approach to entry points python -m:
$ python -m analyzer.api --help
$ python -m analyzer.db --help
Why do you need to start with setup.py?
Looking ahead, we’ll think about how to distribute the application: it can be packaged in a zip (as well as wheel / egg-) archive, an rpm package, a pkg file for macOS and installed on a remote computer, a virtual machine, MacBook or Docker- container.The main purpose of the file setup.pyis to describe the package with the application for . The file must contain general information about the package (name, version, author, etc.), but also in it you can specify the modules required for work, “extra” dependencies (for example, for testing), entry points (for example, executable commands ) and requirements for the interpreter. Setuptools plugins allow you to collect artifact from the described package. There are built-in plugins: zip, egg, rpm, macOS pkg. The remaining plugins are distributed via PyPI: wheel ,distutils/setuptoolsxar , pex .In the bottom line, describing one file, we get great opportunities. That is why the development of a new project must begin with setup.py.In the function, setup()dependent modules are indicated by a list:setup(..., install_requires=["aiohttp", "SQLAlchemy"])
But I described the dependencies in separate files requirements.txtand requirements.dev.txtwhose contents are used in setup.py. It seems more flexible to me, plus there is a secret: later it will allow you to build a Docker image faster. Dependencies will be set as a separate step before installing the application itself, and when rebuilding the Docker container, it will be cached.To be setup.pyable to read the dependencies from the files requirements.txtand requirements.dev.txt, the function is written:def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
It is worth noting that setuptoolswhen the default assembly source distribution includes only the assembly files .py, .c, .cppand .h. To a dependency file requirements.txtand requirements.dev.txthit the bag, they should be clearly specified in the file MANIFEST.in.setup.py entirelyimport os
from importlib.machinery import SourceFileLoader
from pkg_resources import parse_requirements
from setuptools import find_packages, setup
module_name = 'analyzer'
module = SourceFileLoader(
module_name, os.path.join(module_name, '__init__.py')
).load_module()
def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
setup(
name=module_name,
version=module.__version__,
author=module.__author__,
author_email=module.__email__,
license=module.__license__,
description=module.__doc__,
long_description=open('README.rst').read(),
url='https://github.com/alvassin/backendschool2019',
platforms='all',
classifiers=[
'Intended Audience :: Developers',
'Natural Language :: Russian',
'Operating System :: MacOS',
'Operating System :: POSIX',
'Programming Language :: Python',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.8',
'Programming Language :: Python :: Implementation :: CPython'
],
python_requires='>=3.8',
packages=find_packages(exclude=['tests']),
install_requires=load_requirements('requirements.txt'),
extras_require={'dev': load_requirements('requirements.dev.txt')},
entry_points={
'console_scripts': [
'{0}-api = {0}.api.__main__:main'.format(module_name),
'{0}-db = {0}.db.__main__:main'.format(module_name)
]
},
include_package_data=True
)
You can install the project in development mode using the following command (in editable mode, Python will not install the entire package in a folder site-packages, but only create links, so any changes made to the package files will be visible immediately):
pip install -e '.[dev]'
pip install -e .
How to specify dependency versions?
It’s great when developers are actively working on their packages - bugs are being actively fixed in them, new functionality appears and feedback can be obtained faster. But sometimes changes in dependent libraries are not backward compatible and can lead to errors in your application if you do not think about it beforehand.For each dependent package, you can specify a specific version, for example aiohttp==3.6.2. Then the application will be guaranteed to be built specifically with those versions of the dependent libraries with which it was tested. But this approach has a drawback - if developers fix a critical bug in a dependent package that does not affect backward compatibility, this fix will not get into the application.There is an approach to versioning Semantic Versioning, which suggests submitting the version in the format MAJOR.MINOR.PATCH:MAJOR - increases when backward incompatible changes are added;MINOR - Increases when adding new functionality with support for backward compatibility;PATCH - increases when adding bug fixes with backward compatibility support.
If a dependent package follows this approach (of which the authors are usually reported in the README and CHANGELOG files), it is sufficient to fix the value of MAJOR, MINORand to limit the minimum value for PATCH-version: >= MAJOR.MINOR.PATCH, == MAJOR.MINOR.*.Such a requirement can be implemented using the ~ = operator . For example, it aiohttp~=3.6.2will allow PIP to install for aiohttpversion 3.6.3, but not 3.7.If you specify the interval of dependency versions, this will give one more advantage - there will be no version conflicts between dependent libraries.If you are developing a library that requires a different dependency package, then allow for it not one specific version, but an interval. Then it will be much easier for the users of your library to use it (all of a sudden their application requires the same dependency package, but of a different version).Semantic Versioning is just an agreement between authors and consumers of packages. It does not guarantee that authors write code without bugs and cannot make a mistake in the new version of their package.Database
We design the scheme
The description of the POST / imports handler provides an example of unloading with information about residents:Upload Example{
"citizens": [
{
"citizen_id": 1,
"town": "",
"street": " ",
"building": "1675",
"apartment": 7,
"name": " ",
"birth_date": "26.12.1986",
"gender": "male",
"relatives": [2]
},
{
"citizen_id": 2,
"town": "",
"street": " ",
"building": "1675",
"apartment": 7,
"name": " ",
"birth_date": "01.04.1997",
"gender": "male",
"relatives": [1]
},
{
"citizen_id": 3,
"town": "",
"street": " ",
"building": "2",
"apartment": 11,
"name": " ",
"birth_date": "23.11.1986",
"gender": "female",
"relatives": []
},
...
]
}
The first thought was to store all the information about the resident in one table citizens, where the relationship would be represented by a field relativesin the form of a list of integers .But this method has several disadvantagesGET /imports/$import_id/citizens/birthdays , , citizens . relatives UNNEST.
, 10- :
SELECT
relations.citizen_id,
relations.relative_id,
date_part('month', relatives.birth_date) as relative_birth_month
FROM (
SELECT
citizens.import_id,
citizens.citizen_id,
UNNEST(citizens.relatives) as relative_id
FROM citizens
WHERE import_id = 1
) as relations
INNER JOIN citizens as relatives ON
relations.import_id = relatives.import_id AND
relations.relative_id = relatives.citizen_id
relatives PostgreSQL, : relatives , . ( ) .
Further, I decided to bring all the data required for work to a third normal form , and the following structure was obtained:
- The imports table consists of an automatically incrementing column
import_id. It is needed to create a foreign key check in the table citizens.
- The citizens table stores scalar data about the resident (all fields except information about family relationships).
A pair ( import_id, citizen_id) is used as the primary key , guaranteeing the uniqueness of residents citizen_idwithin the framework import_id.
A foreign key citizens.import_id -> imports.import_idensures that the field citizens.import_idcontains only existing unloads.
- relations .
( ): citizens relations .
(import_id, citizen_id, relative_id) , import_id citizen_id c relative_id.
: (relations.import_id, relations.citizen_id) -> (citizens.import_id, citizens.citizen_id) (relations.import_id, relations.relative_id) -> (citizens.import_id, citizens.citizen_id), , citizen_id relative_id .
This structure ensures the integrity of the data using PostgreSQL tools , it allows you to efficiently get residents with relatives from the database, but is subject to a race condition when updating information about residents with competitive queries (we will take a closer look at the PATCH handler implementation).Describe the schema in SQLAlchemy
In Chapter 5, I talked about how to create queries using SQLAlchemy, you need to describe the database schema using special objects: tables are described using sqlalchemy.Tableand are bound to a registry sqlalchemy.MetaDatathat stores all the meta-information about the database. By the way, the registry MetaDatais capable of not only storing the meta-information described in Python, but also representing the real state of the database in the form of SQLAlchemy objects.This feature also allows Alembic to compare conditions and generate a migration code automatically.By the way, each database has its own default constraints naming scheme. So that you don’t waste time naming new constraints or searching / recalling what constraint you are about to remove, SQLAlchemy suggests using naming conventions naming patterns . They can be defined in the registry MetaData.Create a MetaData registry and pass naming patterns to it
from sqlalchemy import MetaData
convention = {
'all_column_names': lambda constraint, table: '_'.join([
column.name for column in constraint.columns.values()
]),
'ix': 'ix__%(table_name)s__%(all_column_names)s',
'uq': 'uq__%(table_name)s__%(all_column_names)s',
'ck': 'ck__%(table_name)s__%(constraint_name)s',
'fk': 'fk__%(table_name)s__%(all_column_names)s__%(referred_table_name)s',
'pk': 'pk__%(table_name)s'
}
metadata = MetaData(naming_convention=convention)
If you specify naming patterns, Alembic will use them during the automatic generation of migrations and will name all constraints according to them. In the future, the created registry MetaDatawill be required to describe the tables:We describe the database schema with SQLAlchemy objects
from enum import Enum, unique
from sqlalchemy import (
Column, Date, Enum as PgEnum, ForeignKey, ForeignKeyConstraint, Integer,
String, Table
)
@unique
class Gender(Enum):
female = 'female'
male = 'male'
imports_table = Table(
'imports',
metadata,
Column('import_id', Integer, primary_key=True)
)
citizens_table = Table(
'citizens',
metadata,
Column('import_id', Integer, ForeignKey('imports.import_id'),
primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('town', String, nullable=False, index=True),
Column('street', String, nullable=False),
Column('building', String, nullable=False),
Column('apartment', Integer, nullable=False),
Column('name', String, nullable=False),
Column('birth_date', Date, nullable=False),
Column('gender', PgEnum(Gender, name='gender'), nullable=False),
)
relations_table = Table(
'relations',
metadata,
Column('import_id', Integer, primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('relative_id', Integer, primary_key=True),
ForeignKeyConstraint(
('import_id', 'citizen_id'),
('citizens.import_id', 'citizens.citizen_id')
),
ForeignKeyConstraint(
('import_id', 'relative_id'),
('citizens.import_id', 'citizens.citizen_id')
),
)
Customize Alembic
When the database schema is described, it is necessary to generate migrations, but for this you first need to configure Alembic, which is also discussed in Chapter 5 .To use the command alembic, you must perform the following steps:- Install Package:
pip install alembic - Initialize Alembic:
cd analyzer && alembic init db/alembic.
This command will create a configuration file analyzer/alembic.iniand a folder analyzer/db/alembicwith the following contents:
env.py- Called every time you start Alembic. Connects to Alembic registry sqlalchemy.MetaDatawith a description of the desired state of the database and contains instructions for starting migrations.
script.py.mako - the template on the basis of which migrations are generated.versions - the folder in which Alembic will search (and generate) migrations.
- Specify the database address in the alembic.ini file:
; analyzer/alembic.ini
[alembic]
sqlalchemy.url = postgresql://user:hackme@localhost/analyzer
- Specify a description of the desired state of the database (registry
sqlalchemy.MetaData) so that Alembic can generate migrations automatically:
from analyzer.db import schema
target_metadata = schema.metadata
Alembic is configured and can already be used, but in our case this configuration has several disadvantages:- The utility
alembicsearches alembic.iniin the current working directory. You alembic.inican specify the path to the command line argument, but this is inconvenient: I want to be able to call the command from any folder without additional parameters. - To configure Alembic to work with a specific database, you need to change the file
alembic.ini. It would be much more convenient to specify the database settings for the environment variable and / or a command line argument, for example --pg-url. - The name of the utility
alembicdoes not correlate very well with the name of our service (and the user may actually not have Python at all and know nothing about Alembic). It would be much more convenient for the end user if all executable commands of the service had a common prefix, for example analyzer-*.
These problems are solved with a small wrapper. analyzer/db/__main__.py:- Alembic uses a standard module to process command line arguments
argparse. It allows you to add an optional argument --pg-urlwith a default value from an environment variable ANALYZER_PG_URL.
The codeimport os
from alembic.config import CommandLine, Config
from analyzer.utils.pg import DEFAULT_PG_URL
def main():
alembic = CommandLine()
alembic.parser.add_argument(
'--pg-url', default=os.getenv('ANALYZER_PG_URL', DEFAULT_PG_URL),
help='Database URL [env var: ANALYZER_PG_URL]'
)
options = alembic.parser.parse_args()
config = Config(file_=options.config, ini_section=options.name,
cmd_opts=options)
config.set_main_option('sqlalchemy.url', options.pg_url)
exit(alembic.run_cmd(config, options))
if __name__ == '__main__':
main()
- The path to the file
alembic.inican be calculated relative to the location of the executable file, and not the current working directory of the user.
The codeimport os
from alembic.config import CommandLine, Config
from pathlib import Path
PROJECT_PATH = Path(__file__).parent.parent.resolve()
def main():
alembic = CommandLine()
options = alembic.parser.parse_args()
if not os.path.isabs(options.config):
options.config = os.path.join(PROJECT_PATH, options.config)
config = Config(file_=options.config, ini_section=options.name,
cmd_opts=options)
alembic_location = config.get_main_option('script_location')
if not os.path.isabs(alembic_location):
config.set_main_option('script_location',
os.path.join(PROJECT_PATH, alembic_location))
exit(alembic.run_cmd(config, options))
if __name__ == '__main__':
main()
When the utility for managing the state of the database is ready, it can be registered setup.pyas an executable command with a name understandable to the end user, for example analyzer-db:Register an executable command in setup.pyfrom setuptools import setup
setup(..., entry_points={
'console_scripts': [
'analyzer-db = analyzer.db.__main__:main'
]
})
After reinstalling the module, a file will be generated env/bin/analyzer-dband the command analyzer-dbwill become available:$ pip install -e '.[dev]'
We generate migrations
To generate migrations, two states are required: desired (which we described with SQLAlchemy objects) and real (the database, in our case, is empty).I decided that the easiest way to raise Postgres with Docker was to add a command make postgresthat runs a container with PostgreSQL on port 5432 in the background:Raise PostgreSQL and generate migration$ make postgres
...
$ analyzer-db revision --message="Initial" --autogenerate
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'imports'
INFO [alembic.autogenerate.compare] Detected added table 'citizens'
INFO [alembic.autogenerate.compare] Detected added index 'ix__citizens__town' on '['town']'
INFO [alembic.autogenerate.compare] Detected added table 'relations'
Generating /Users/alvassin/Work/backendschool2019/analyzer/db/alembic/versions/d5f704ed4610_initial.py ... done
Alembic generally does a good job of the routine work of generating migrations, but I would like to draw attention to the following:- The user data types specified in the created tables are created automatically (in our case -
gender), but the code to delete them is downgradenot generated. If you apply, roll back, and then apply the migration again, this will cause an error because the specified data type already exists.
Delete the gender data type in the downgrade methodfrom alembic import op
from sqlalchemy import Column, Enum
GenderType = Enum('female', 'male', name='gender')
def upgrade():
...
op.create_table('citizens', ...,
Column('gender', GenderType, nullable=False))
...
def downgrade():
op.drop_table('citizens')
GenderType.drop(op.get_bind())
- In the method,
downgradesome actions can sometimes be removed (if we delete the whole table, you can not delete its indexes separately):
for instancedef downgrade():
op.drop_table('relations')
op.drop_index(op.f('ix__citizens__town'), table_name='citizens')
op.drop_table('citizens')
op.drop_table('imports')
When the migration is fixed and ready, we apply it:$ analyzer-db upgrade head
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> d5f704ed4610, Initial
application
Before you begin creating handlers, you must configure the aiohttp application.If you look at aiohttp quickstart, you can write something like thisimport logging
from aiohttp import web
def main():
logging.basicConfig(level=logging.DEBUG)
app = web.Application()
app.router.add_route(...)
web.run_app(app)
This code raises a number of questions and has a number of disadvantages:- How to configure the application? At a minimum, you must specify the host and port for connecting clients, as well as information for connecting to the database.
I really like to solve this problem with the help of the module ConfigArgParse: it extends the standard one argparseand allows using command line arguments, environment variables (indispensable for configuring Docker containers) and even configuration files (as well as combining these methods) for configuration. Using ConfigArgParseit, you can also validate the values of application configuration parameters.
An example of processing parameters using ConfigArgParsefrom aiohttp import web
from configargparse import ArgumentParser, ArgumentDefaultsHelpFormatter
from analyzer.utils.argparse import positive_int
parser = ArgumentParser(
auto_env_var_prefix='ANALYZER_',
formatter_class=ArgumentDefaultsHelpFormatter
)
parser.add_argument('--api-address', default='0.0.0.0',
help='IPv4/IPv6 address API server would listen on')
parser.add_argument('--api-port', type=positive_int, default=8081,
help='TCP port API server would listen on')
def main():
args = parser.parse_args()
app = web.Application()
web.run_app(app, host=args.api_address, port=args.api_port)
if __name__ == '__main__':
main()
, ConfigArgParse, argparse, ( -h --help). :
$ python __main__.py --help
usage: __main__.py [-h] [--api-address API_ADDRESS] [--api-port API_PORT]
If an arg is specified in more than one place, then commandline values override environment variables which override defaults.
optional arguments:
-h, --help show this help message and exit
--api-address API_ADDRESS
IPv4/IPv6 address API server would listen on [env var: ANALYZER_API_ADDRESS] (default: 0.0.0.0)
--api-port API_PORT TCP port API server would listen on [env var: ANALYZER_API_PORT] (default: 8081)
- — , «» . , .
os.environ.clear(), Python (, asyncio?), , ConfigArgParser.
import os
from typing import Callable
from configargparse import ArgumentParser
from yarl import URL
from analyzer.api.app import create_app
from analyzer.utils.pg import DEFAULT_PG_URL
ENV_VAR_PREFIX = 'ANALYZER_'
parser = ArgumentParser(auto_env_var_prefix=ENV_VAR_PREFIX)
parser.add_argument('--pg-url', type=URL, default=URL(DEFAULT_PG_URL),
help='URL to use to connect to the database')
def clear_environ(rule: Callable):
"""
,
rule
"""
for name in filter(rule, tuple(os.environ)):
os.environ.pop(name)
def main():
args = parser.parse_args()
clear_environ(lambda i: i.startswith(ENV_VAR_PREFIX))
app = create_app(args)
...
if __name__ == '__main__':
main()
- stderr/ .
9 , logging.basicConfig() stderr.
, . aiomisc.
aiomiscimport logging
from aiomisc.log import basic_config
basic_config(logging.DEBUG, buffered=True)
- , ? ,
fork , (, Windows ).
import os
from sys import argv
import forklib
from aiohttp.web import Application, run_app
from aiomisc import bind_socket
from setproctitle import setproctitle
def main():
sock = bind_socket(address='0.0.0.0', port=8081, proto_name='http')
setproctitle(f'[Master] {os.path.basename(argv[0])}')
def worker():
setproctitle(f'[Worker] {os.path.basename(argv[0])}')
app = Application()
run_app(app, sock=sock)
forklib.fork(os.cpu_count(), worker, auto_restart=True)
if __name__ == '__main__':
main()
- - ? , ( — ) ,
nobody. — .
import os
import pwd
from aiohttp.web import run_app
from aiomisc import bind_socket
from analyzer.api.app import create_app
def main():
sock = bind_socket(address='0.0.0.0', port=8085, proto_name='http')
user = pwd.getpwnam('nobody')
os.setgid(user.pw_gid)
os.setuid(user.pw_uid)
app = create_app(...)
run_app(app, sock=sock)
if __name__ == '__main__':
main()
create_app, .
All successful handler responses will be returned in JSON format. It would also be convenient for clients to receive information about errors in a serialized form (for example, to see which fields did not pass validation).The documentation aiohttpoffers a method json_responsethat takes an object, serializes it in JSON, and returns a new object aiohttp.web.Responsewith a header Content-Type: application/jsonand serialized data inside.How to serialize data using json_responsefrom aiohttp.web import Application, View, run_app
from aiohttp.web_response import json_response
class SomeView(View):
async def get(self):
return json_response({'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
But there is another way: aiohttp allows you to register an arbitrary serializer for a specific type of response data in the registry aiohttp.PAYLOAD_REGISTRY. For example, you can specify a serializer aiohttp.JsonPayloadfor objects of type Mapping .In this case, it will be enough for the handler to return an object Responsewith the response data in the parameter body. aiohttp will find a serializer that matches the data type and serialize the response.In addition to the fact that serialization of objects is described in one place, this approach is also more flexible - it allows you to implement very interesting solutions (we will consider one of the use cases in the handler GET /imports/$import_id/citizens).How to serialize data using aiohttp.PAYLOAD_REGISTRYfrom types import MappingProxyType
from typing import Mapping
from aiohttp import PAYLOAD_REGISTRY, JsonPayload
from aiohttp.web import run_app, Application, Response, View
PAYLOAD_REGISTRY.register(JsonPayload, (Mapping, MappingProxyType))
class SomeView(View):
async def get(self):
return Response(body={'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
It is important to understand that json_response, like aiohttp.JsonPayload, they use a standard method json.dumpsthat cannot serialize complex data types, for example, datetime.dateor asyncpg.Record( asyncpgreturns records from the database as instances of this class). Moreover, some complex objects may contain others: in one record from the database there may be a type field datetime.date.Python developers have addressed this problem: the method json.dumpsallows you to use the argument defaultto specify a function that is called when it is necessary to serialize an unfamiliar object. The function is expected to cast an unfamiliar object to a type that can serialize the json module.How to extend JsonPayload to serialize arbitrary objectsimport json
from datetime import date
from functools import partial, singledispatch
from typing import Any
from aiohttp.payload import JsonPayload as BaseJsonPayload
from aiohttp.typedefs import JSONEncoder
@singledispatch
def convert(value):
raise NotImplementedError(f'Unserializable value: {value!r}')
@convert.register(Record)
def convert_asyncpg_record(value: Record):
"""
,
asyncpg
"""
return dict(value)
@convert.register(date)
def convert_date(value: date):
"""
date —
.
..
"""
return value.strftime('%d.%m.%Y')
dumps = partial(json.dumps, default=convert)
class JsonPayload(BaseJsonPayload):
def __init__(self,
value: Any,
encoding: str = 'utf-8',
content_type: str = 'application/json',
dumps: JSONEncoder = dumps,
*args: Any,
**kwargs: Any) -> None:
super().__init__(value, encoding, content_type, dumps, *args, **kwargs)
Handlers
aiohttp allows you to implement handlers with asynchronous functions and classes. Classes are more extensible: firstly, the code belonging to one handler can be placed in one place, and secondly, classes allow you to use inheritance to get rid of code duplication (for example, each handler requires a database connection).Handler Base Classfrom aiohttp.web_urldispatcher import View
from asyncpgsa import PG
class BaseView(View):
URL_PATH: str
@property
def pg(self) -> PG:
return self.request.app['pg']
Since it is difficult to read one large file, I decided to split the handlers into files. Small files encourage weak connectivity, and if, for example, there are ring imports inside handlers, it means that something may be wrong with the composition of entities.POST / imports
The input handler receives json with data about residents. The maximum allowable request size in aiohttp is controlled by the option client_max_sizeand is 2 MB by default . If the limit is exceeded, aiohttp will return an HTTP response with a status of 413: Request Entity Too Large Error.At the same time, the correct json with the longest lines and numbers will weigh ~ 63 megabytes, so the restrictions on the size of the request need to be expanded.Next, you need to check and deserialize the data . If they are incorrect, you need to return an HTTP response 400: Bad Request.I needed two schemes Marhsmallow. The first one CitizenSchema, checks the data of each individual resident, and also deserializes the happy birthday string into the object datetime.date:- Data type, format and availability of all required fields;
- Lack of unfamiliar fields;
- Date of birth must be indicated in the format
DD.MM.YYYYand cannot be of any significance from the future - The list of relatives of each resident must contain unique identifiers of residents existing in this upload.
The second scheme ImportSchema,, checks the unloading as a whole:citizen_id each resident within the unloading should be unique;- Family ties should be two-way (if resident # 1 has a resident # 2 in the list of relatives, then resident # 2 must also have a relative # 1).
If the data is correct, they must be added to the database with a new unique one import_id.To add data, you will need to perform several queries in different tables. In order to avoid partially partially added data in the database in case of an error or exception (for example, when disconnecting a client that did not receive a full response, aiohttp will throw a CancelledError exception ), you must use a transaction .It is necessary to add data to tables in parts , since in one query to PostgreSQL there can be no more than 32,767 arguments. There are citizens9 fields in the table . Accordingly, for 1 request, only 32,767 / 9 = 3,640 rows can be inserted into this table, and in one upload there can be up to 10,000 inhabitants.GET / imports / $ import_id / citizens
The handler returns all residents for unloading with the specified import_id. If the specified upload does not exist , you must return the 404: Not Found HTTP response. This behavior seems to be common for handlers that need an existing unload, so I pulled the verification code into a separate class.Base class for handlers with unloadsfrom aiohttp.web_exceptions import HTTPNotFound
from sqlalchemy import select, exists
from analyzer.db.schema import imports_table
class BaseImportView(BaseView):
@property
def import_id(self):
return int(self.request.match_info.get('import_id'))
async def check_import_exists(self):
query = select([
exists().where(imports_table.c.import_id == self.import_id)
])
if not await self.pg.fetchval(query):
raise HTTPNotFound()
To get a list of relatives for each resident, you will need to perform LEFT JOINfrom table citizensto table relations, aggregating the field relations.relative_idgrouped by import_idand citizen_id.If the resident has no relatives, then he LEFT JOINwill return the relations.relative_idvalue for him in the field NULLand, as a result of aggregation, the list of relatives will look like [NULL].To fix this incorrect value, I used the array_remove function .The database stores the date in a format YYYY-MM-DD, but we need a format DD.MM.YYYY.Technically, you can format the date either with an SQL query or on the Python side at the time of serializing the response with json.dumps(asyncpg returns the value of the field birth_dateas an instance of the classdatetime.date)I chose serialization on the Python side, given that it birth_dateis the only object datetime.datein the project with a single format (see the section “Serializing Data” ).Despite the fact that two requests are executed in the handler (checking for the existence of an unloading and a request for a list of residents), it is not necessary to use a transaction . By default, PostgreSQL uses the isolation level, READ COMMITTEDand even within one transaction all changes to other, successfully completed transactions will be visible (adding new rows, changing existing ones).The largest upload in a text view can take ~ 63 megabytes - this is quite a lot, especially considering that several requests for receiving data may arrive at the same time. There is a rather interesting way to get data from the database using the cursor and send it to the client in parts .To do this, we need to implement two objects:- A
SelectQuerytype object AsyncIterablethat returns records from the database. At the first call, it connects to the database, opens a transaction and creates a cursor; during further iteration, it returns records from the database. It is returned by the handler.
SelectQuery Codefrom collections import AsyncIterable
from asyncpgsa.transactionmanager import ConnectionTransactionContextManager
from sqlalchemy.sql import Select
class SelectQuery(AsyncIterable):
"""
, PostgreSQL
, ,
"""
PREFETCH = 500
__slots__ = (
'query', 'transaction_ctx', 'prefetch', 'timeout'
)
def __init__(self, query: Select,
transaction_ctx: ConnectionTransactionContextManager,
prefetch: int = None,
timeout: float = None):
self.query = query
self.transaction_ctx = transaction_ctx
self.prefetch = prefetch or self.PREFETCH
self.timeout = timeout
async def __aiter__(self):
async with self.transaction_ctx as conn:
cursor = conn.cursor(self.query, prefetch=self.prefetch,
timeout=self.timeout)
async for row in cursor:
yield row
- A serializer
AsyncGenJSONListPayloadthat can iterate over asynchronous generators, serialize data from an asynchronous generator to JSON and send data to clients in parts. It is registered aiohttp.PAYLOAD_REGISTRYas a serializer of objects AsyncIterable.
AsyncGenJSONListPayload Codeimport json
from functools import partial
from aiohttp import Payload
dumps = partial(json.dumps, default=convert, ensure_ascii=False)
class AsyncGenJSONListPayload(Payload):
"""
AsyncIterable,
JSON
"""
def __init__(self, value, encoding: str = 'utf-8',
content_type: str = 'application/json',
root_object: str = 'data',
*args, **kwargs):
self.root_object = root_object
super().__init__(value, content_type=content_type, encoding=encoding,
*args, **kwargs)
async def write(self, writer):
await writer.write(
('{"%s":[' % self.root_object).encode(self._encoding)
)
first = True
async for row in self._value:
if not first:
await writer.write(b',')
else:
first = False
await writer.write(dumps(row).encode(self._encoding))
await writer.write(b']}')
Further, in the handler it will be possible to create an object SelectQuery, pass an SQL query and a function to it to open the transaction, and return it to Response body:Handler code
from aiohttp.web_response import Response
from aiohttp_apispec import docs, response_schema
from analyzer.api.schema import CitizensResponseSchema
from analyzer.db.schema import citizens_table as citizens_t
from analyzer.utils.pg import SelectQuery
from .query import CITIZENS_QUERY
from .base import BaseImportView
class CitizensView(BaseImportView):
URL_PATH = r'/imports/{import_id:\d+}/citizens'
@docs(summary=' ')
@response_schema(CitizensResponseSchema())
async def get(self):
await self.check_import_exists()
query = CITIZENS_QUERY.where(
citizens_t.c.import_id == self.import_id
)
body = SelectQuery(query, self.pg.transaction())
return Response(body=body)
aiohttpit detects a registered aiohttp.PAYLOAD_REGISTRYserializer AsyncGenJSONListPayloadfor objects of type in the registry AsyncIterable. Then the serializer will iterate over the object SelectQueryand send data to the client. At the first call, the object SelectQueryreceives a connection to the database, opens a transaction and creates a cursor; during further iteration, it will receive data from the database with the cursor and return them line by line.This approach allows not to allocate memory for the entire amount of data with each request, but it has a peculiarity: the application will not be able to return the corresponding HTTP status to the client if an error occurs (after all, the HTTP status, headers have already been sent to the client, and data is being written).If an exception occurs, there is nothing left but to disconnect. An exception, of course, can be secured, but the client will not be able to understand exactly what error occurred.On the other hand, a similar situation may arise even if the processor receives all the data from the database, but the network blinks while transmitting data to the client - no one is safe from this.PATCH / imports / $ import_id / citizens / $ citizen_id
The handler receives the identifier of the unload import_id, the resident citizen_id, as well as json with the new data about the resident. In the case of a non-existent unloading or a resident , an HTTP response must be returned 404: Not Found.The data transmitted by the client must be verified and deserialized . If they are incorrect, you must return an HTTP response 400: Bad Request. I implemented a Marshmallow scheme PatchCitizenSchemathat checks:- The type and format of the data for the specified fields.
- Date of birth. It must be specified in a format
DD.MM.YYYYand cannot be of significance from the future. - A list of relatives of each resident. It must have unique identifiers for residents.
The existence of the relatives indicated in the field relativescan not be checked separately: when a relationsnon-existent resident is added to the table, PostgreSQL will return an error ForeignKeyViolationErrorthat can be processed and the HTTP status can be returned 400: Bad Request.What status should be returned if the client sent incorrect data for a non-existent resident or unloading ? It is semantically more correct to check first the existence of the unloading and the resident (if there is none, return 404: Not Found) and only then whether the client has sent the correct data (if not, return 400: Bad Request). In practice, it is often cheaper to check the data first, and only if they are correct, access the database.Both options are acceptable, but I decided to choose a cheaper second option, since in any case the result of the operation is an error that does not affect anything (the client will correct the data and then also find out that the resident does not exist).If the data is correct, it is necessary to update the information about the resident in the database . In the handler, you will need to make several queries to different tables. If an error or exception occurs, the changes to the database must be undone, so queries must be performed in a transaction .The method PATCH allows you to transfer only some fields for a resident.The handler must be written in such a way that it does not crash when accessing data that the client did not specify, and also does not execute queries on tables in which the data has not changed.If the client specified the field relatives, it is necessary to obtain a list of existing relatives. If it has changed, determine which records from the table relativesmust be deleted and which ones to add in order to bring the database into line with the client’s request. By default, PostgreSQL uses transaction isolation READ COMMITTED. This means that as part of the current transaction, changes will be visible to existing (as well as new ones) records of other completed transactions. This can lead to a race condition between competitive requests .Suppose there is an unloading with residents#1. #2, #3without kinship. The service receives two simultaneous requests to change resident # 1: {"relatives": [2]}and {"relatives": [3]}. aiohttp will create two handlers that simultaneously receive the current state of the resident from PostgreSQL.Each handler will not detect a single related relationship and will decide to add a new relationship with the specified relative. As a result, resident # 1 has the same field as relatives [2,3]. This behavior cannot be called obvious. There are two options expected to decide the outcome of the race: to complete only the first request, and for the second to return an HTTP response
This behavior cannot be called obvious. There are two options expected to decide the outcome of the race: to complete only the first request, and for the second to return an HTTP response409: Conflict(so that the client repeats the request), or to execute requests in turn (the second request will be processed only after the first is completed).The first option can be implemented by turning on isolation modeSERIALIZABLE. If during the processing of the request someone already managed to change and commit the data, an exception will be thrown, which can be processed and the corresponding HTTP status returned.The disadvantage of this solution - a large number of locks in PostgreSQL, SERIALIZABLEwill throw an exception, even if competitive queries change the records of residents from different unloadings.You can also use the recommendation lock mechanism . If you obtain such a lock on import_id, competitive requests for different unloadings will be able to run in parallel.To process competitive requests in one upload, you can implement the behavior of any of the options: the function pg_try_advisory_xact_locktries to obtain a lock andit returns the boolean result immediately (if it was not possible to get the lock - an exception can be thrown), but it pg_advisory_xact_lockwaits until theresource becomes available for blocking (in this case, the requests will be executed sequentially, I settled on this option).As a result, the handler must return the current information about the updated resident . It was possible to limit ourselves to returning data from his request to the client (since we are returning a response to the client, it means that there were no exceptions and all requests were successfully completed). Or - use the RETURNING keyword in queries that modify the database and generate a response from the results. But both of these approaches would not allow us to see and test the case with the race of states.There were no high load requirements for the service, so I decided to request all the data about the resident again and return to the client an honest result from the database.GET / imports / $ import_id / citizens / birthdays
The handler calculates the number of gifts that each resident of the unloading will get to his relatives (first order). The number is grouped by month for upload with the specified import_id. In the case of a non-existent upload , an HTTP response must be returned 404: Not Found.There are two implementation options:- Get data for residents with relatives from the database, and on the Python side, aggregate data by month and generate lists for those months for which there is no data in the database.
- Compile a json request in the database and add stubs for the missing months.
I settled on the first option - visually it looks more understandable and supported. The number of birthdays in a given month can be obtained by making JOINfrom the table with family ties ( relations.citizen_id- the resident for whom we consider the birthdays of relatives) into the table citizens(containing the date of birth from which you want to get the month).Month values must not contain leading zeros. The month obtained from the field birth_dateusing the function date_partmay contain a leading zero. To remove it, I performed castto integerin the SQL query.Despite the fact that the handler needs to fulfill two requests (check the existence of unloading and get information about birthdays and gifts), a transaction is not required .By default, PostgreSQL uses READ COMMITTED mode, in which all new (added by other transactions) and existing (modified by other transactions) records are visible in the current transaction after they are successfully completed.For example, if a new upload is added at the time of receiving the data, it will not affect the existing ones. If at the time of receiving the data a request to change the resident is fulfilled, either the data will not be visible yet (if the transaction changing the data has not been completed), or the transaction will complete completely and all changes will be immediately visible. The integrity obtained from the database will not be violated.GET / imports / $ import_id / towns / stat / percentile / age
The handler calculates the 50th, 75th and 99th percentiles of the ages (full years) of residents by city in the sample with the specified import_id. In the case of a non-existent upload , an HTTP response must be returned 404: Not Found.Despite the fact that the processor executes two requests (checking for the existence of unloading and obtaining a list of residents), it is not necessary to use a transaction .There are two implementation options:- Get the age of residents from the database, grouped by city, and then on the Python side calculate the percentiles using numpy (which is specified as a reference in the task) and round up to two decimal places.
- PostgreSQL: percentile_cont , SQL-, numpy .
The second option requires transferring less data between the application and PostgreSQL, but it does not have a very obvious pitfall: in PostgreSQL, rounding is mathematical, ( SELECT ROUND(2.5)returns 3), and in Python - accounting, to the nearest integer ( round(2.5)returns 2).To test the handler, the implementation must be the same in both PostgreSQL and Python (implementing a function with mathematical rounding in Python looks easier). It is worth noting that when calculating percentiles, numpy and PostgreSQL may return slightly different numbers, but taking into account rounding, this difference will not be noticeable.Testing
What needs to be checked in this application? Firstly, that the handlers meet the requirements and perform the required work in an environment as close as possible to the combat environment. Secondly, migrations that change the state of the database work without errors. Thirdly, there are a number of auxiliary functions that could also be correctly covered by tests.I decided to use the pytest framework because of its flexibility and ease of use. It offers a powerful mechanism for preparing the environment for tests - fixtures , that is, functions with a decoratorpytest.mark.fixturewhose names can be specified by the parameter in the test. If pytest detects a parameter with a fixture name in the test annotation, it will execute this fixture and pass the result in the value of this parameter. And if the fixture is a generator, then the test parameter will take the value returned yield, and after the test finishes, the second part of the fixture will be executed, which can clear resources or close connections.For most tests, we need a PostgreSQL database. To isolate tests from each other, you can create a separate database before each test, and delete it after execution.Create a fixture database for each testimport os
import uuid
import pytest
from sqlalchemy import create_engine
from sqlalchemy_utils import create_database, drop_database
from yarl import URL
from analyzer.utils.pg import DEFAULT_PG_URL
PG_URL = os.getenv('CI_ANALYZER_PG_URL', DEFAULT_PG_URL)
@pytest.fixture
def postgres():
tmp_name = '.'.join([uuid.uuid4().hex, 'pytest'])
tmp_url = str(URL(PG_URL).with_path(tmp_name))
create_database(tmp_url)
try:
yield tmp_url
finally:
drop_database(tmp_url)
def test_db(postgres):
"""
, PostgreSQL
"""
engine = create_engine(postgres)
assert engine.execute('SELECT 1').scalar() == 1
engine.dispose()
The sqlalchemy_utils module did a great job of this task , taking into account the features of different databases and drivers. For example, PostgreSQL does not allow execution CREATE DATABASEin a transaction block. When creating a database, it sqlalchemy_utilstranslates psycopg2(which usually executes all requests in a transaction) into autocommit mode.Another important feature: if at least one client is connected to PostgreSQL, the database cannot be deleted, but sqlalchemy_utilsdisconnects all clients before deleting the database. The database will be successfully deleted even if some test with active connections to it hangs.We need PostgreSQL in different states: for testing migrations, we need a clean database, while handlers require that all migrations be applied. You can programmatically change the state of a database using Alembic commands; they require the Alembic configuration object to call them.Create a fixture Alembic configuration objectfrom types import SimpleNamespace
import pytest
from analyzer.utils.pg import make_alembic_config
@pytest.fixture()
def alembic_config(postgres):
cmd_options = SimpleNamespace(config='alembic.ini', name='alembic',
pg_url=postgres, raiseerr=False, x=None)
return make_alembic_config(cmd_options)
Please note that fixtures alembic_confighave a parameter postgres- pytestallows not only to indicate the dependence of the test on fixtures, but also the dependencies between fixtures.This mechanism allows you to flexibly separate logic and write very concise and reusable code.Handlers
Testing handlers requires a database with created tables and data types. To apply migrations, you must programmatically call the upgrade Alembic command. To call it, you need an object with the Alembic configuration, which we have already defined with fixtures alembic_config. The database with migrations looks like a completely independent entity, and it can be represented as a fixture:from alembic.command import upgrade
@pytest.fixture
async def migrated_postgres(alembic_config, postgres):
upgrade(alembic_config, 'head')
return postgres
When there are many migrations in the project, their application for each test may take too much time. To speed up the process, you can create a database with migrations once and then use it as a template .In addition to the database for testing handlers, you will need a running application, as well as a client configured to work with this application. To make the application easy to test, I put its creation into a function create_appthat takes parameters to run: a database, a port for the REST API, and others.Arguments for launching the application can also be represented as a separate fixture. To create them, you will need to determine the free port for running the test application and the address to the migrated temporary database.To determine the free port, I used the fixture aiomisc_unused_portfrom the aiomisc package.A standard fixture aiohttp_unused_portwould also be fine, but it returns a function to determine free ports, while it aiomisc_unused_portimmediately returns the port number. For our application, we need to determine only one free port, so I decided not to write an extra line of code with a call aiohttp_unused_port.@pytest.fixture
def arguments(aiomisc_unused_port, migrated_postgres):
return parser.parse_args(
[
'--log-level=debug',
'--api-address=127.0.0.1',
f'--api-port={aiomisc_unused_port}',
f'--pg-url={migrated_postgres}'
]
)
All tests with handlers imply requests to the REST API; work directly with the application is aiohttpnot required. Therefore, I made one fixture that launches the application and using the factory aiohttp_clientcreates and returns a standard test client connected to the application aiohttp.test_utils.TestClient.from analyzer.api.app import create_app
@pytest.fixture
async def api_client(aiohttp_client, arguments):
app = create_app(arguments)
client = await aiohttp_client(app, server_kwargs={
'port': arguments.api_port
})
try:
yield client
finally:
await client.close()
Now, if you specify fixture in the test parameters api_client, the following will happen:postgres ( migrated_postgres).alembic_config Alembic, ( migrated_postgres).migrated_postgres ( arguments).aiomisc_unused_port ( arguments).arguments ( api_client).api_client .- .
api_client .postgres .
Fixtures can avoid code duplication, but in addition to preparing the environment in the tests, there is another potential place where there will be a lot of the same code - application requests.First, making a request, we expect to get a certain HTTP status. Secondly, if the status is as expected, then before working with the data, you need to make sure that they have the correct format. It is easy to make a mistake here and write a handler that does the correct calculations and returns the correct result, but does not pass automatic validation due to the incorrect response format (for example, forget to wrap the answer in a dictionary with a key data). All of these checks could be done in one place.In the moduleanalyzer.testing I have prepared for each handler a helper function that checks the status of HTTP, as well as the response format using Marshmallow.GET / imports / $ import_id / citizens
I decided to start with a handler that returns residents, because it is very useful for checking the results of other handlers that change the state of the database.I intentionally did not use code that adds data to the database from the handler POST /imports, although it is not difficult to make it into a separate function. The handler code has the property to change, and if there is any error in the code that adds to the database, there is a chance that the test will stop working as intended and implicitly for developers will stop showing errors.For this test, I defined the following test data sets:- Unloading with several relatives. Checks that for each resident a list with identifiers of relatives will be correctly formed.
- Unloading with one resident without relatives. Checks that the field
relativesis an empty list (due LEFT JOINto the SQL query, the list of relatives may be equal [None]). - Unloading with a resident who is a relative of himself.
- Empty unloading. Checks that the handler allows adding empty unloading and does not crash with an error.
To run the same test separately at each upload, I used another very powerful pytest mechanism - parameterization . This mechanism allows you to wrap the test function in the decorator pytest.mark.parametrizeand describe in it what parameters the test function should take for each individual test case.How to parameterize a testimport pytest
from analyzer.utils.testing import generate_citizen
datasets = [
[
generate_citizen(citizen_id=1, relatives=[2, 3]),
generate_citizen(citizen_id=2, relatives=[1]),
generate_citizen(citizen_id=3, relatives=[1])
],
[
generate_citizen(relatives=[])
],
[
generate_citizen(citizen_id=1, name='', gender='male',
birth_date='17.02.2020', relatives=[1])
],
[],
]
@pytest.mark.parametrize('dataset', datasets)
async def test_get_citizens(api_client, dataset):
"""
4 ,
"""
So, the test will add the upload to the database, then, using a request to the handler, it will receive information about the residents and compare the reference upload with the received one. But how do you compare residents?Each resident consists of scalar fields and a field relatives- a list of identifiers of relatives. A list in Python is an ordered type, and when comparing the order of the elements of each list does matter, but when comparing lists with siblings, the order should not matter.If you bring relativesto the set before the comparison, then when comparing it does not work out to find a situation where one of the inhabitants in the field relativeshas duplicates. If you sort the list with the identifiers of relatives, this will circumvent the problem of different order of identifiers of relatives, but at the same time detect duplicates.When comparing two lists with residents, one may encounter a similar problem: technically, the order of residents in the unloading is not important, but it is important to detect if there are two residents with the same identifiers in one unloading and not in the other. So in addition to organizing the list with relatives, relatives for each resident need to arrange the residents in each unloading.Since the task of comparing residents will arise more than once, I implemented two functions: one for comparing two residents, and the second for comparing two lists with residents:Compare residentsfrom typing import Iterable, Mapping
def normalize_citizen(citizen):
"""
"""
return {**citizen, 'relatives': sorted(citizen['relatives'])}
def compare_citizens(left: Mapping, right: Mapping) -> bool:
"""
"""
return normalize_citizen(left) == normalize_citizen(right)
def compare_citizen_groups(left: Iterable, right: Iterable) -> bool:
"""
,
"""
left = [normalize_citizen(citizen) for citizen in left]
left.sort(key=lambda citizen: citizen['citizen_id'])
right = [normalize_citizen(citizen) for citizen in right]
right.sort(key=lambda citizen: citizen['citizen_id'])
return left == right
To make sure that this handler does not return residents of other unloadings, I decided to add an additional unloading with one inhabitant before each test.POST / imports
I defined the following datasets for testing the handler:- Correct data, expected to be successfully added to the database.
- ( ).
. , , insert , . - ( , ).
, .
- .
, . :)
, aiohttp PostgreSQL 32 767 ( ).
- Empty unloading
The handler should take into account such a case and not fall, trying to perform empty insert into the table with the inhabitants.
- Data with errors, expect an HTTP response of 400: Bad Request.
- Date of birth is incorrect (future tense).
- citizen_id is not unique within the upload.
- A kinship is indicated incorrectly (there is only from one resident to another, but there is no feedback).
- The resident has a non-existent relative in the unloading.
- Family ties are not unique.
If the processor worked successfully and the data was added, you need to get the residents added to the database and compare them with the standard upload. To get residents, I used the already tested handler GET /imports/$import_id/citizens, and for comparison, a function compare_citizen_groups.PATCH / imports / $ import_id / citizens / $ citizen_id
Validation of data is in many ways similar to that described in the handler POST /importswith a few exceptions: there is only one resident and the client can pass only those fields that he wants .I decided to use the following sets with incorrect data to verify that the handler will return an HTTP response 400: Bad request:- The field is specified, but has an incorrect data type and / or format
- The date of birth is incorrect (future time).
- The field
relativescontains a relative that does not exist in the unloading.
It is also necessary to verify that the handler correctly updates information about the resident and his relatives.To do this, create an upload with three inhabitants, two of whom are relatives, and send a request with new values for all scalar fields and a new relative identifier in the field relatives.To make sure that the handler distinguishes between residents of different unloadings before the test (and, for example, does not change residents with the same identifiers from another unloading), I created an additional unloading with three residents who have the same identifiers.The handler must save the new values of the scalar fields, add a new specified relative and remove the relationship with an old, not specified relative. All changes in kinship should be bilateral. There should not be changes in other unloadings.Since such a handler may be subject to race conditions (this was discussed in the Development section), I added two additional tests . One reproduces the problem with the race state (extends the handler class and removes the lock), the second proves that the problem with the race state is not reproduced.GET / imports / $ import_id / citizens / birthdays
To test this handler, I selected the following datasets:- An unloading in which a resident has one relative in one month and two relatives in another.
- Unloading with one resident without relatives. Checks that the handler does not take it into account in the calculations.
- Empty unloading. Checks that the handler will not fail and will return the correct dictionary with 12 months in the response.
- Unloading with a resident who is a relative of himself. Checks that a resident will buy a gift for the month of his birth.
The handler must return all months in the response, even if there are no birthdays in these months. To avoid duplication, I made a function to which you can pass the dictionary so that it complements it with values for missing months.To make sure that the handler distinguishes between residents of different unloadings, I added an additional unloading with two relatives. If the handler mistakenly uses them in the calculations, the results will be incorrect and the handler will fall with an error.GET / imports / $ import_id / towns / stat / percentile / age
The peculiarity of this test is that the results of its work depend on the current time: the age of the inhabitants is calculated based on the current date. To ensure that the test results do not change over time, the current date, dates of birth of residents and expected results must be recorded. This will make it easy to reproduce any, even edge cases.What is the best fix date? The handler uses the PostgreSQL function to calculate the age of residents AGE, which takes the first parameter as the date for which it is necessary to calculate the age and the second as the base date (defined by a constant TownAgeStatView.CURRENT_DATE).We replace the base date in the handler with the test timefrom unittest.mock import patch
import pytz
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
@patch('analyzer.api.handlers.TownAgeStatView.CURRENT_DATE', new=CURRENT_DATE)
async def test_get_ages(...):
...
For testing the handler, I selected the following data sets (for all residents I indicated one city, because the handler aggregates the results by city):- , ( — 364 ). , .
- , ( — ). — , , 1 .
- . .
The numpybenchmark for calculating percentiles - with linear interpolation, and the benchmark results for testing I calculated for them.You also need to round the fractional percentile values to two decimal places. If you used PostgreSQL for rounding in the handler, and Python for calculating the reference data, you might notice that rounding in Python 3 and PostgreSQL can give different results .for instance# Python 3
round(2.5)
> 2
-- PostgreSQL
SELECT ROUND(2.5)
> 3
The fact is that Python uses bank rounding to the nearest even , and PostgreSQL uses mathematical (half-up). In case calculations and rounding are performed in PostgreSQL, it would be correct to use mathematical rounding in tests as well.At first I described data sets with dates of birth in a text format, but it was inconvenient to read a test in this format: each time I had to calculate the age of each inhabitant in my mind in order to remember what a particular data set was checking. Of course, you could get by with the comments in the code, but I decided to go a little further and wrote a function age2datethat allows you to describe the date of birth in the form of age: the number of years and days.For example, like thisimport pytz
from analyzer.utils.testing import generate_citizen
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
def age2date(years: int, days: int = 0, base_date=CURRENT_DATE) -> str:
birth_date = copy(base_date).replace(year=base_date.year - years)
birth_date -= timedelta(days=days)
return birth_date.strftime(BIRTH_DATE_FORMAT)
generate_citizen(birth_date='17.02.2009')
generate_citizen(birth_date=age2date(years=11))
To make sure that the handler distinguishes between residents of different unloadings, I added an additional unload with one resident from another city: if the handler mistakenly uses it, an extra city will appear in the results and the test will break.An interesting fact: when I wrote this test on February 29, 2020, I suddenly stopped generating unloads with residents due to a bug in Faker (2020 is a leap year, and other years that Faker chose were not always leap years in them too was not February 29th). Remember to record dates and test edge cases!
Migrations
The migration code at first glance seems obvious and least error prone, why test it? This is a very dangerous error: the most insidious mistakes of migrations can manifest themselves at the most inopportune moment. Even if they do not spoil the data, they can cause unnecessary downtime.The initial migration existing in the project changes the structure of the database, but does not change the data. What common mistakes can be protected from such migrations?downgrade ( , , ).
, (--): , — .
- C .
- ( ).
Most of these errors will be detected by the stairway test . His idea - to use a single migration, consistently performing the methods upgrade, downgrade, upgradefor each migration. Such a test is enough to be added to the project once, it does not require support and will serve faithfully.But if the migration, in addition to the structure, would change the data, then it would be necessary to write at least one separate test, checking that the data correctly changes in the method upgradeand returns to the initial state in downgrade. Just in case: a project with examples of testing different migrations , which I prepared for a report about Alembic in Moscow Python.Assembly
The final artifact that we are going to deploy and which we want to get as a result of the assembly is a Docker image. To build, you must select the base image with Python. The official image python:latestweighs ~ 1 GB and, if used as a base image, the image with the application will be huge. There are images based on the Alpine OS , the size of which is much smaller. But with a growing number of installed packages, the size of the final image will grow, and as a result, even the image collected on the basis of Alpine will not be so small. I chose snakepacker / python as the base image - it weighs a bit more than Alpine images, but is based on Ubuntu, which offers a huge selection of packages and libraries.Another wayreduce the size of the image with the application - do not include in the final image the compiler, libraries and files with headers for the assembly, which are not required for the application to work.To do this, you can use the multi-stage assembly of Docker:- Using a “heavy” image
snakepacker/python:all(~ 1 GB, ~ 500 MB compressed), create a virtual environment, install all the dependencies and the application package in it. This image is needed exclusively for assembly, it can contain a compiler, all the necessary libraries and files with headers.
FROM snakepacker/python:all as builder
RUN python3.8 -m venv /usr/share/python3/app
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/*
- We copy the finished virtual environment into a “light” image
snakepacker/python:3.8(~ 100 MB, compressed ~ 50 MB), which contains only the interpreter of the required version of Python.
Important: in a virtual environment, absolute paths are used, so it must be copied to the same address at which it was assembled in the collector container.
FROM snakepacker/python:3.8 as api
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
CMD ["analyzer-api"]
To reduce the time it takes to build the image , the application dependent modules can be installed before it is installed in the virtual environment. Then Docker will cache them and will not reinstall if they have not changed.Dockerfile entirely
FROM snakepacker/python:all as builder
RUN python3.8 -m venv /usr/share/python3/app
RUN /usr/share/python3/app/bin/pip install -U pip
COPY requirements.txt /mnt/
RUN /usr/share/python3/app/bin/pip install -Ur /mnt/requirements.txt
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/* \
&& /usr/share/python3/app/bin/pip check
FROM snakepacker/python:3.8 as api
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
CMD ["analyzer-api"]
For ease of assembly, I added a command make uploadthat collects the Docker image and uploads it to hub.docker.com.Ci
Now that the code is covered with tests and we can build a Docker image, it's time to automate these processes. The first thing that comes to mind: run tests for creating pool requests, and when adding changes to the master branch, collect a new Docker image and upload it to the Docker Hub (or GitHub Packages , if you are not going to distribute the image publicly).I solved this problem with GitHub Actions . To do this, it was necessary to create a YAML file in a folder .github/workflowsand describe in it a workflow (with two tasks: testand publish), which I named CI.The task testis executed every time workflow is started CI, using servicespicks up a container with PostgreSQL, waits for it to become available, and launches pytestin the container snakepacker/python:all.The task publishis performed only if the changes have been added to the branch masterand if the task testwas successful. It collects the source distribution by the container snakepacker/python:all, then collects and loads the Docker image with docker/build-push-action@v1.Full description of workflowname: CI
# Workflow
# - master
on:
push:
branches: [ master ]
pull_request:
branches: [ master ]
jobs:
# workflow
test:
runs-on: ubuntu-latest
services:
postgres:
image: docker://postgres
ports:
- 5432:5432
env:
POSTGRES_USER: user
POSTGRES_PASSWORD: hackme
POSTGRES_DB: analyzer
steps:
- uses: actions/checkout@v2
- name: test
uses: docker://snakepacker/python:all
env:
CI_ANALYZER_PG_URL: postgresql://user:hackme@postgres/analyzer
with:
args: /bin/bash -c "pip install -U '.[dev]' && pylama && wait-for-port postgres:5432 && pytest -vv --cov=analyzer --cov-report=term-missing tests"
# Docker-
publish:
# master
if: github.event_name == 'push' && github.ref == 'refs/heads/master'
# , test
needs: test
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: sdist
uses: docker://snakepacker/python:all
with:
args: make sdist
- name: build-push
uses: docker/build-push-action@v1
with:
username: ${{ secrets.REGISTRY_LOGIN }}
password: ${{ secrets.REGISTRY_TOKEN }}
repository: alvassin/backendschool2019
target: api
tags: 0.0.1, latest
Now, when adding changes to the master in the Actions tab on GitHub, you can see the launch of tests, the assembly and loading of the Docker image: And when creating a pool request in the master branch, the results of the task will also be displayed in it
And when creating a pool request in the master branch, the results of the task will also be displayed in it test:
Deploy
To deploy the application on the provided server, you need to install Docker, Docker Compose, start the containers with the application and PostgreSQL and apply the migrations.These steps can be automated using Ansible's configuration management system. It is written in Python, does not require special agents (connects directly via ssh), uses jinja templates and allows declaratively describe the desired state in YAML files. The declarative approach allows you not to think about the current state of the system and the actions necessary to bring the system to the desired state. All this work rests on the shoulders of Ansible modules.Ansible allows you to group logically related tasks into roles and then reuse them. We will need two roles:docker(installs and configures Docker) and analyzer(installs and configures the application).The roledocker adds a repository with Docker to the system, installs and configures packages docker-ceand docker-compose.Optionally, you can set the REST API to automatically resume after a server reboot. Ubuntu allows you to solve this problem with the help of an initialization system systemd. It controls units representing various resources (daemons, sockets, mount points, and others). To add a new unit to systemd, you must describe its configuration in a separate .service file and place this file in one of the special folders, for example, in /etc/systemd/system. Then the unit can be launched, as well as enable autoload for it.Packagedocker-ceduring installation, it will automatically create a file with the unit configuration - you only need to make sure that it is running and turns on when the system starts. For Docker Compose docker-compose@.servicewill be created by Ansible. The symbol @in the name indicates to systemd that the unit is a template. This allows you to start the service docker-composewith a parameter - for example, with the name of our service, which will be substituted instead of %iin the unit configuration file:[Unit]
Description=%i service with docker compose
Requires=docker.service
After=docker.service
[Service]
Type=oneshot
RemainAfterExit=true
WorkingDirectory=/etc/docker/compose/%i
ExecStart=/usr/local/bin/docker-compose up -d --remove-orphans
ExecStop=/usr/local/bin/docker-compose down
[Install]
WantedBy=multi-user.target
The role willanalyzer generate a file from the template docker-compose.ymlat the address /etc/docker/compose/analyzer, register the application as an automatically launched service in systemdand apply the migration. When the roles are ready, you need to describe the playbook.---
- name: Gathering facts
hosts: all
become: yes
gather_facts: yes
- name: Install docker
hosts: docker
become: yes
gather_facts: no
roles:
- docker
- name: Install analyzer
hosts: api
become: yes
gather_facts: no
roles:
- analyzer
The list of hosts, as well as the variables used in the roles, can be specified in the inventory file hosts.ini.[api]
130.193.51.154
[docker:children]
api
[api:vars]
analyzer_image = alvassin/backendschool2019
analyzer_pg_user = user
analyzer_pg_password = hackme
analyzer_pg_dbname = analyzer
After all the Ansible files are ready, run it:$ ansible-playbook -i hosts.ini deploy.yml
About stress testing, , . , -
. : , — , 10 . , (, , CI-): .
, , , 10 . ? , , . , , .
RPS, : . , ,
import_id,
POST /imports . .
, Python 3,
Locust.
,
locustfile.py locust. - .
Locust . , .
self.round .
locustfile.py
import logging
from http import HTTPStatus
from locust import HttpLocust, constant, task, TaskSet
from locust.exception import RescheduleTask
from analyzer.api.handlers import (
CitizenBirthdaysView, CitizensView, CitizenView, TownAgeStatView
)
from analyzer.utils.testing import generate_citizen, generate_citizens, url_for
class AnalyzerTaskSet(TaskSet):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.round = 0
def make_dataset(self):
citizens = [
generate_citizen(citizen_id=1, relatives=[2]),
generate_citizen(citizen_id=2, relatives=[1]),
*generate_citizens(citizens_num=9998, relations_num=1000,
start_citizen_id=3)
]
return {citizen['citizen_id']: citizen for citizen in citizens}
def request(self, method, path, expected_status, **kwargs):
with self.client.request(
method, path, catch_response=True, **kwargs
) as resp:
if resp.status_code != expected_status:
resp.failure(f'expected status {expected_status}, '
f'got {resp.status_code}')
logging.info(
'round %r: %s %s, http status %d (expected %d), took %rs',
self.round, method, path, resp.status_code, expected_status,
resp.elapsed.total_seconds()
)
return resp
def create_import(self, dataset):
resp = self.request('POST', '/imports', HTTPStatus.CREATED,
json={'citizens': list(dataset.values())})
if resp.status_code != HTTPStatus.CREATED:
raise RescheduleTask
return resp.json()['data']['import_id']
def get_citizens(self, import_id):
url = url_for(CitizensView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens')
def update_citizen(self, import_id):
url = url_for(CitizenView.URL_PATH, import_id=import_id, citizen_id=1)
self.request('PATCH', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/{citizen_id}',
json={'relatives': [i for i in range(3, 10)]})
def get_birthdays(self, import_id):
url = url_for(CitizenBirthdaysView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/birthdays')
def get_town_stats(self, import_id):
url = url_for(TownAgeStatView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/towns/stat/percentile/age')
@task
def workflow(self):
self.round += 1
dataset = self.make_dataset()
import_id = self.create_import(dataset)
self.get_citizens(import_id)
self.update_citizen(import_id)
self.get_birthdays(import_id)
self.get_town_stats(import_id)
class WebsiteUser(HttpLocust):
task_set = AnalyzerTaskSet
wait_time = constant(1)
100 c , , :

, ( — 95 , — ). .

— Ansible ~20.15 ~20.30 Locust.

What else can be done?
Profiling the application showed that about a quarter of the total query execution time is spent on JSON serialization and deserialization: there are a lot of data sent and received from the service. These processes can be significantly accelerated using the orjson library , but the service will have to be prepared a bit - orjsonit is not a drop-in replacement for the standard module. jsonUsually, production requires several copies of the service to ensure fault tolerance and cope with the load. To manage a group of services, you need a tool that shows whether a copy of the service is "alive". This problem can be solved by a handler /healththat polls all the resources required for work, in our case, a database. IfSELECT 1executed in less than a second, then the service is alive. If not, you need to pay attention to it.When an application works very intensively with a network, uvloop can coolly increase performance.An important factor is the readability of the code. One of my colleagues, Yuri Shikanov, wrote a gray module combining several tools for automatic verification and execution of code, which is easy to add to a pre-commitGit hook, set up with a single configuration file or environment variables. Gray allows you to sort imports ( isort ), optimizes python expressions according to new versions of the language ( pyupgrade ), adds commas at the end of function calls, imports, lists, etc. (add-trailing-comma ), and also quotes to a single form ( unify ).* * *
That's all for me: we developed, covered with tests, assembled and deployed the service, and also carried out load testing.Acknowledgments
I would like to express my deep gratitude to the guys who took the time to take part in writing this article, to review the code, to introduce my ideas and comments: to Maria Zelenova zelma, Vladimir Solomatin leenr, Anastasia Semenova morkov, Yuri Shikanov dizballanze, Mikhail Shushpanov mishush, Pavel Mosein pavkazzz and especially to Dmitry Orlov orlovdl.