 The effect of bloating tables and indexes (bloat) is widely known and is present not only in Postgres. There are ways to deal with it “out of the box” like VACUUM FULL or CLUSTER, but they lock tables during operation and therefore cannot always be used.The article will have a bit of theory about how bloat occurs, how to deal with it, about deferred constraints, and about the problems that they bring to the use of the pg_repack extension.This article is based on my presentation at PgConf.Russia 2020.
The effect of bloating tables and indexes (bloat) is widely known and is present not only in Postgres. There are ways to deal with it “out of the box” like VACUUM FULL or CLUSTER, but they lock tables during operation and therefore cannot always be used.The article will have a bit of theory about how bloat occurs, how to deal with it, about deferred constraints, and about the problems that they bring to the use of the pg_repack extension.This article is based on my presentation at PgConf.Russia 2020.Why bloat occurs
Postgres is based on the multi-version model ( MVCC ). Its essence is that each row in the table can have several versions, while transactions see no more than one of these versions, but not necessarily the same one. This allows multiple transactions to work simultaneously and have virtually no effect on each other.Obviously, all these versions need to be stored. Postgres works with memory page by page and the page is the minimum amount of data that can be read from disk or written. Let's look at a small example to understand how this happens.Suppose we have a table in which we have added several records. In the first page of the file where the table is stored, new data has appeared. These are live versions of strings that are available to other transactions after a commit (for simplicity, we will assume that the Read Committed isolation level).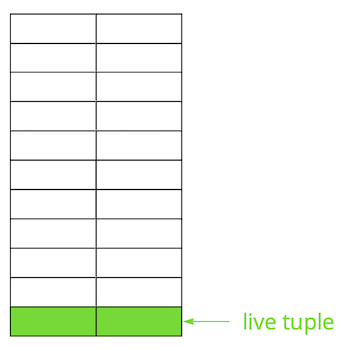 Then we updated one of the entries and thereby marked the old version as irrelevant.
Then we updated one of the entries and thereby marked the old version as irrelevant.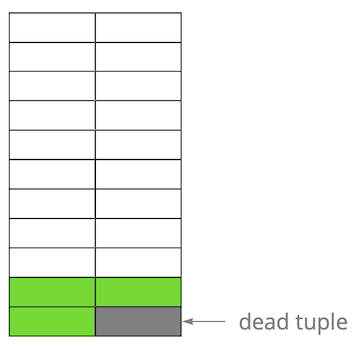 Step by step, updating and deleting the version of the lines, we got a page in which about half of the data is “garbage”. This data is not visible to any transaction.
Step by step, updating and deleting the version of the lines, we got a page in which about half of the data is “garbage”. This data is not visible to any transaction.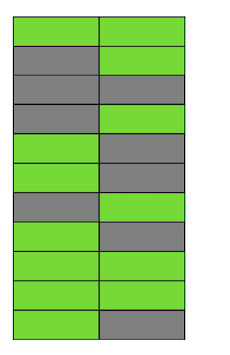 Postgres has a VACUUM mechanism, which cleans up irrelevant versions and frees up space for new data. But if it is not configured aggressively enough or is busy working in other tables, then the “junk data” remains, and we have to use additional pages for new data.So in our example, at some point in time, the table will consist of four pages, but there will be only half the live data in it. As a result, when accessing the table, we will read much more data than necessary.
Postgres has a VACUUM mechanism, which cleans up irrelevant versions and frees up space for new data. But if it is not configured aggressively enough or is busy working in other tables, then the “junk data” remains, and we have to use additional pages for new data.So in our example, at some point in time, the table will consist of four pages, but there will be only half the live data in it. As a result, when accessing the table, we will read much more data than necessary.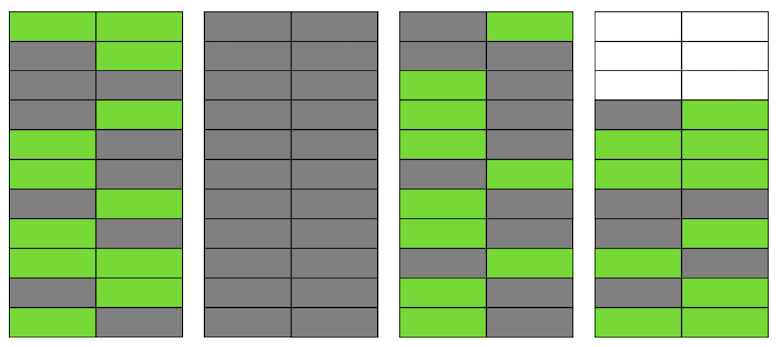 Even if VACUUM now deletes all irrelevant versions of strings, the situation will not improve dramatically. We will have free space in the pages or even whole pages for new lines, but we will continue to read more data than necessary.By the way, if a completely blank page (the second in our example) were at the end of the file, then VACUUM could trim it. But now she is in the middle, so nothing can be done with her.
Even if VACUUM now deletes all irrelevant versions of strings, the situation will not improve dramatically. We will have free space in the pages or even whole pages for new lines, but we will continue to read more data than necessary.By the way, if a completely blank page (the second in our example) were at the end of the file, then VACUUM could trim it. But now she is in the middle, so nothing can be done with her.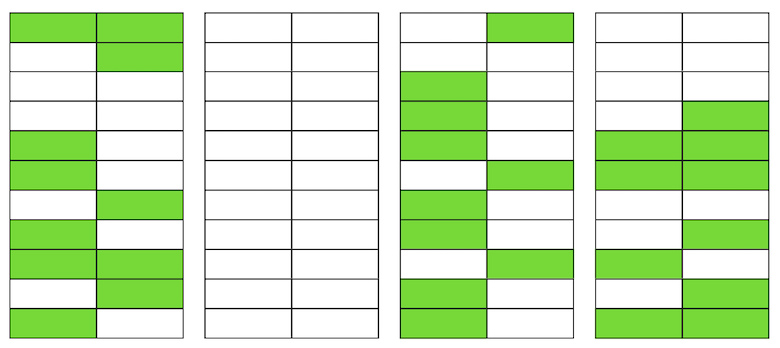 When the number of such blank or very flat pages becomes large, which is called bloat, it begins to affect performance.Everything described above is the mechanics of bloat occurrence in tables. In indexes, this happens in much the same way.
When the number of such blank or very flat pages becomes large, which is called bloat, it begins to affect performance.Everything described above is the mechanics of bloat occurrence in tables. In indexes, this happens in much the same way.Do I have a bloat?
There are several ways to determine if you have a bloat. The idea of the first is to use internal Postgres statistics, which contains approximate information about the number of rows in tables, the number of “live” rows, etc. On the Internet, you can find many variations of ready-made scripts. We took as a basis a script from PostgreSQL Experts, which can evaluate bloat tables along with toast and bloat btree indexes. In our experience, its error is 10-20%.Another way is to use the pgstattuple extension , which allows you to look inside the pages and get both estimated and accurate bloat values. But in the second case, you have to scan the entire table.A small bloat value, up to 20%, we consider acceptable. It can be considered as an analogue of fillfactor for tables and indexes . At 50% and above, performance problems may begin.Ways to deal with bloat
There are several ways to deal with bloat out of the box in Postgres, but they are far from always suitable for everyone.Set AUTOVACUUM so that bloat does not occur . And more precisely, to keep it at an acceptable level for you. This seems to be “captain's” advice, but in reality this is not always easy to achieve. For example, you are actively developing with regular changes to the data schema or some kind of data migration is occurring. As a result, your load profile can change frequently and, as a rule, it can be different for different tables. This means that you need to constantly work a bit ahead of the curve and adjust AUTOVACUUM to the changing profile of each table. But it’s obvious that this is not easy.Another common reason that AUTOVACUUM does not have time to process tables is the presence of lengthy transactions that prevent it from clearing data due to the fact that it is available to these transactions. The recommendation here is also obvious - get rid of hanging transactions and minimize the time of active transactions. But if the load on your application is a hybrid of OLAP and OLTP, then at the same time you can have many frequent updates and short requests, as well as lengthy operations - for example, building a report. In such a situation, it is worth thinking about spreading the load to different bases, which will allow for finer tuning of each of them.Another example - even if the profile is uniform, but the database is under very high load, even the most aggressive AUTOVACUUM may not cope, and a bloat will occur. Scaling (vertical or horizontal) is the only solution.But what about the situation when you configured AUTOVACUUM, but the bloat continues to grow. VACUUM FULLCommandrebuilds the contents of tables and indexes and leaves only relevant data in them. To eliminate bloat, it works perfectly, but during its execution, an exclusive lock on the table (AccessExclusiveLock) is captured, which will not allow queries to this table, even selects. If you can afford to stop your service or part of it for a while (from tens of minutes to several hours, depending on the size of the database and your hardware), then this option is the best. Unfortunately, we do not have time to run VACUUM FULL during the scheduled maintenance, so this method does not suit us. CLUSTERCommandit also rebuilds the contents of tables, as does VACUUM FULL, at the same time it allows you to specify the index according to which the data will be physically ordered on disk (but in the future the order is not guaranteed). In certain situations, this is a good optimization for a number of queries - with reading several records by index. The disadvantage of the command is the same as that of VACUUM FULL - it locks the table during operation.The REINDEX command is similar to the previous two, but rebuilds a specific index or all indexes on the table. Locks are slightly weaker: ShareLock to the table (prevents modifications, but allows you to select) and AccessExclusiveLock to the rebuildable index (blocks requests using this index). However, in version 12 of Postgres, the CONCURRENTLY parameter, which allows you to rebuild the index without blocking the parallel addition, modification or deletion of records.In earlier versions of Postgres, you can achieve a result similar to REINDEX CONCURRENTLY with CREATE INDEX CONCURRENTLY . It allows you to create an index without strict blocking (ShareUpdateExclusiveLock, which does not interfere with parallel queries), then replace the old index with a new one and delete the old index. This eliminates bloat indexes without interfering with your application. It is important to consider that when rebuilding indexes there will be an additional load on the disk subsystem.Thus, if there are ways for indexes to eliminate bloat “hot”, then for tables there are none. Here various external extensions come into play : pg_repack(formerly pg_reorg), pgcompact , pgcompacttable and others. In the framework of this article, I will not compare them and will only talk about pg_repack, which, after some refinement, we use at home.How pg_repack works
Suppose we have a very normal table for ourselves - with indexes, restrictions, and, unfortunately, with bloat. The first step is pg_repack creates a log table to store data about all changes during operation. The trigger will replicate these changes to each insert, update, and delete. Then a table is created that is similar to the original in structure, but without indexes and restrictions, so as not to slow down the process of inserting data.Next, pg_repack transfers data from the old to the new table, automatically filtering all irrelevant rows, and then creates indexes for the new table. During the execution of all these operations, changes are accumulated in the log table.The next step is to transfer the changes to the new table. The migration is performed in several iterations, and when less than 20 entries remain in the log table, pg_repack captures a strict lock, transfers the latest data and replaces the old table with the new one in the Postgres system tables. This is the only and very short point in time when you cannot work with the table. After that, the old table and the table with the logs are deleted and space is freed up in the file system. The process is completed.In theory, everything looks great, what in practice? We tested pg_repack without load and under load, and checked its operation in case of a premature stop (in other words, Ctrl + C). All tests were positive.We went to the prod - and then everything went wrong as we expected.The first pancake on prod
On the first cluster, we received an error about violating a unique restriction:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
This restriction had the auto-generated name index_16508 - it was created by pg_repack. By the attributes included in its composition, we determined “our” restriction, which corresponds to it. The problem turned out to be that this is not quite an ordinary restriction, but a deferred constraint , i.e. its verification is performed later than the sql command, which leads to unexpected consequences.Deferred constraints: why are they needed and how do they work
A bit of theory about deferred constraints.Consider a simple example: we have a car reference table with two attributes - the name and order of the car in the directory.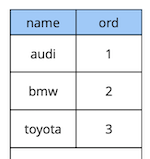
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique
);
Let's say we needed to swap the first and second cars. The solution "in the forehead" is to update the first value to the second, and the second to the first:begin;
update cars set ord = 2 where name = 'audi';
update cars set ord = 1 where name = 'bmw';
commit;
But when executing this code, we expectedly get a violation of the constraint, because the order of the values in the table is unique:[23305] ERROR: duplicate key value violates unique constraint “uk_cars”
Detail: Key (ord)=(2) already exists.
How to do it differently? Option one: add an additional replacement of the value by an order that is guaranteed not to exist in the table, for example, “-1”. In programming, this is called “exchanging the values of two variables through the third.” The only drawback of this method is the additional update.Option two: redesign the table to use a floating-point data type for the order value instead of integers. Then, when updating the value from 1, for example, to 2.5, the first record will automatically “stand up” between the second and third. This solution works, but there are two limitations. Firstly, it will not work for you if the value is used somewhere in the interface. Secondly, depending on the accuracy of the data type, you will have a limited number of possible inserts before recalculating the values of all records.Option three: make the restriction deferred so that it is checked only at the time of the commit:create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique deferrable initially deferred
);
Since the logic of our initial request ensures that all values are unique by the time of the commit, it will succeed.The above example is, of course, very synthetic, but it reveals the idea. In our application, we use deferred constraints to implement logic that is responsible for resolving conflicts while simultaneously working with common widget objects on the board. Using such restrictions allows us to make application code a little easier.In general, depending on the type of constraint in Postgres, there are three levels of granularity for checking them: row level, transaction, and expression.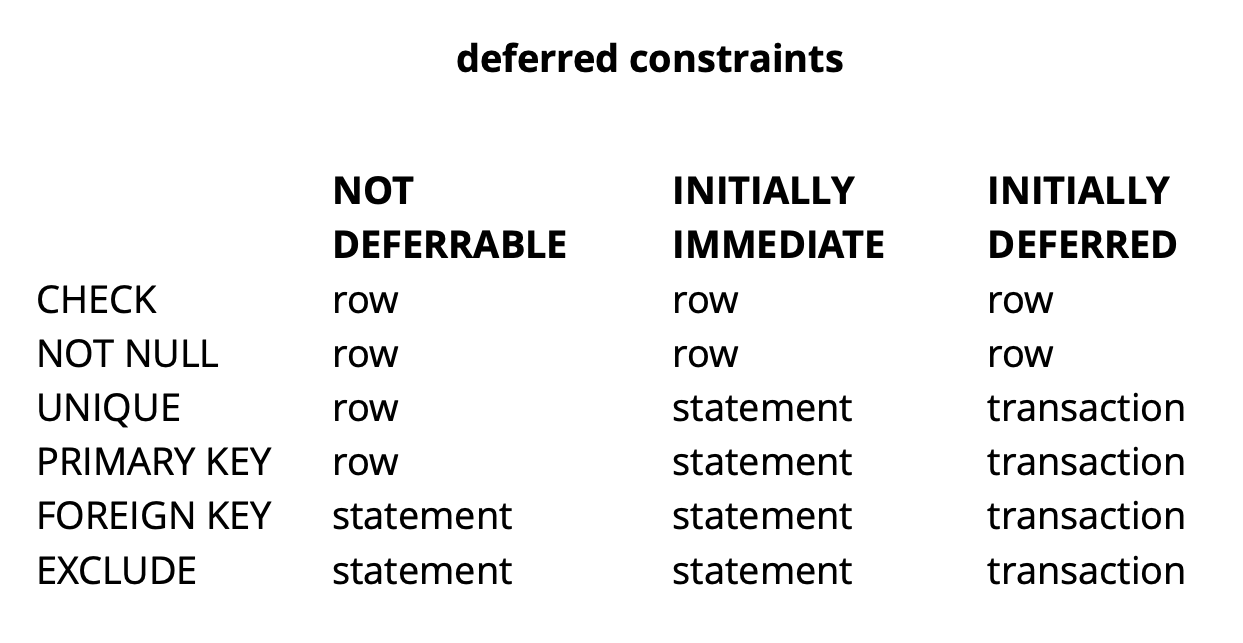 Source: begriffsCHECK and NOT NULL are always checked at the row level, for other restrictions, as can be seen from the table, there are different options. Read more here .To summarize briefly, pending restrictions in some situations give more readable code and fewer commands. However, you have to pay for this by complicating the debug process, since the moment the error occurred and the moment you find out about it are separated in time. Another possible problem is that the scheduler cannot always build the optimal plan if a delayed constraint is involved in the request.
Source: begriffsCHECK and NOT NULL are always checked at the row level, for other restrictions, as can be seen from the table, there are different options. Read more here .To summarize briefly, pending restrictions in some situations give more readable code and fewer commands. However, you have to pay for this by complicating the debug process, since the moment the error occurred and the moment you find out about it are separated in time. Another possible problem is that the scheduler cannot always build the optimal plan if a delayed constraint is involved in the request.Refinement pg_repack
We figured out what pending restrictions are, but how are they related to our problem? Recall the error we previously received:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
It occurs at the time of copying data from the log table to the new table. It looks weird because the data in the log table is committed along with the data in the original table. If they satisfy the constraints of the original table, then how can they violate the same constraints in the new?As it turned out, the root of the problem lies in the previous step of pg_repack, which creates only indexes, but not restrictions: the old table had a unique constraint, and the new one created a unique index instead. It is important to note here that if the restriction is normal and not deferred, then the unique index created instead of it is equivalent to this restriction, because Postgres unique constraints are implemented by creating a unique index. But in the case of a deferred constraint, the behavior is not the same, because the index cannot be deferred and is always checked at the time the sql command is executed.Thus, the essence of the problem lies in the “postponement” of the check: in the original table it occurs at the time of the commit, and in the new one - at the time of the sql command execution. So we need to make sure that the checks are performed the same way in both cases: either always deferred, or always immediately.So what ideas did we have?
It is important to note here that if the restriction is normal and not deferred, then the unique index created instead of it is equivalent to this restriction, because Postgres unique constraints are implemented by creating a unique index. But in the case of a deferred constraint, the behavior is not the same, because the index cannot be deferred and is always checked at the time the sql command is executed.Thus, the essence of the problem lies in the “postponement” of the check: in the original table it occurs at the time of the commit, and in the new one - at the time of the sql command execution. So we need to make sure that the checks are performed the same way in both cases: either always deferred, or always immediately.So what ideas did we have?Create an index similar to deferred
The first idea is to perform both checks in immediate mode. This may give rise to several false positive triggers of the restriction, but if there are few of them, then this should not affect the work of users, since for them such conflicts are a normal situation. They occur, for example, when two users start simultaneously editing the same widget, and the client of the second user does not have time to get information that the widget is already locked for editing by the first user. In this situation, the server refuses the second user, and its client rolls back the changes and blocks the widget. A little later, when the first user finishes editing, the second will receive information that the widget is no longer locked, and will be able to repeat its action.To ensure that checks are always in emergency mode, we created a new index similar to the original deferred constraint:CREATE UNIQUE INDEX CONCURRENTLY uk_tablename__immediate ON tablename (id, index);
DROP INDEX CONCURRENTLY uk_tablename__immediate;
On the test environment, we received only a few expected errors. Success! We again launched pg_repack on the prod and got 5 errors on the first cluster in an hour of work. This is an acceptable result. However, already on the second cluster, the number of errors increased many times and we had to stop pg_repack.Why did it happen? The probability of an error depends on how many users work simultaneously with the same widgets. Apparently, at that moment with the data stored on the first cluster, there were much fewer competitive changes than on the rest, i.e. we were just “lucky."The idea did not work. At that moment, we saw two other solution options: rewrite our application code to abandon pending restrictions, or “teach” pg_repack to work with them. We have chosen the second.Replace indexes in new table with deferred constraints from source table
The purpose of the revision was obvious - if the original table has a deferred constraint, then for the new one you need to create such a constraint, not an index.To test our changes, we wrote a simple test:- table with deferred restriction and one record;
- insert data in the loop that conflict with the existing record;
- make update - the data no longer conflicts;
- commit change.
create table test_table
(
id serial,
val int,
constraint uk_test_table__val unique (val) deferrable initially deferred
);
INSERT INTO test_table (val) VALUES (0);
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (0) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;
The original version of pg_repack always crashed on the first insert, the revised version worked without errors. Fine.We go to the prod and again we get an error in the same phase of copying data from the log table to the new one:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Classic situation: everything works on test environments, but not on prod ?!APPLY_COUNT and the joint of two batches
We started analyzing the code literally line by line and found an important point: data is transferred from the log table to the new one with batches, the APPLY_COUNT constant indicated the size of the batches:for (;;)
{
num = apply_log(connection, table, APPLY_COUNT);
if (num > MIN_TUPLES_BEFORE_SWITCH)
continue;
...
}
The problem is that the data of the original transaction, in which several operations can potentially violate the restriction, can be transferred to the joint of two batches during the transfer - half of the teams will be commited in the first match and the other half in the second. And here's how lucky: if the teams in the first batch do not violate anything, then everything is fine, but if they violate - an error occurs.APPLY_COUNT is equal to 1000 entries, which explains why our tests were successful - they did not cover the case of “junction of batches”. We used two commands - insert and update, so exactly 500 transactions of two teams were always placed in the batch and we did not experience problems. After adding the second update, our edit stopped working:FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (1) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;
So, the next task is to make sure that the data from the source table that changed in one transaction falls into the new table also within the same transaction.Refusal of Butching
And again we had two solutions. First: let's completely abandon the batching and do the data transfer in one transaction. In favor of this solution was its simplicity - the required code changes were minimal (by the way, in older versions then pg_reorg worked just that way). But there is a problem - we are creating a long transaction, and this, as was said earlier, is a threat to the emergence of a new bloat.The second solution is more complicated, but probably more correct: create a column in the log table with the identifier of the transaction that added the data to the table. Then, when copying data, we will be able to group them by this attribute and ensure that the related changes will be transferred together. A batch will be formed from several transactions (or one large one) and its size will vary depending on how much data has changed in these transactions. It is important to note that since the data of different transactions fall into the log table in random order, it will not be possible to read it sequentially, as it was before. seqscan for every request filtered by tx_id is too expensive, you need an index, but it will slow down the method due to the overhead of updating it. In general, as always, you need to sacrifice something.So, we decided to start with the first option, as a simpler one. First, it was necessary to understand whether a long transaction would be a real problem. Since the main data transfer from the old table to the new one also occurs in one long transaction, the question has transformed into “how much will we increase this transaction?” The duration of the first transaction depends mainly on the size of the table. The duration of the new one depends on how many changes accumulate in the table during the data transfer, i.e. from the intensity of the load. The pg_repack run occurred during the minimum load on the service, and the amount of change was incomparably small compared to the original table size. We decided that we can neglect the time of the new transaction (for comparison, this is an average of 1 hour and 2-3 minutes).The experiments were positive. Running on prod too. For clarity, a picture with the size of one of the bases after the run: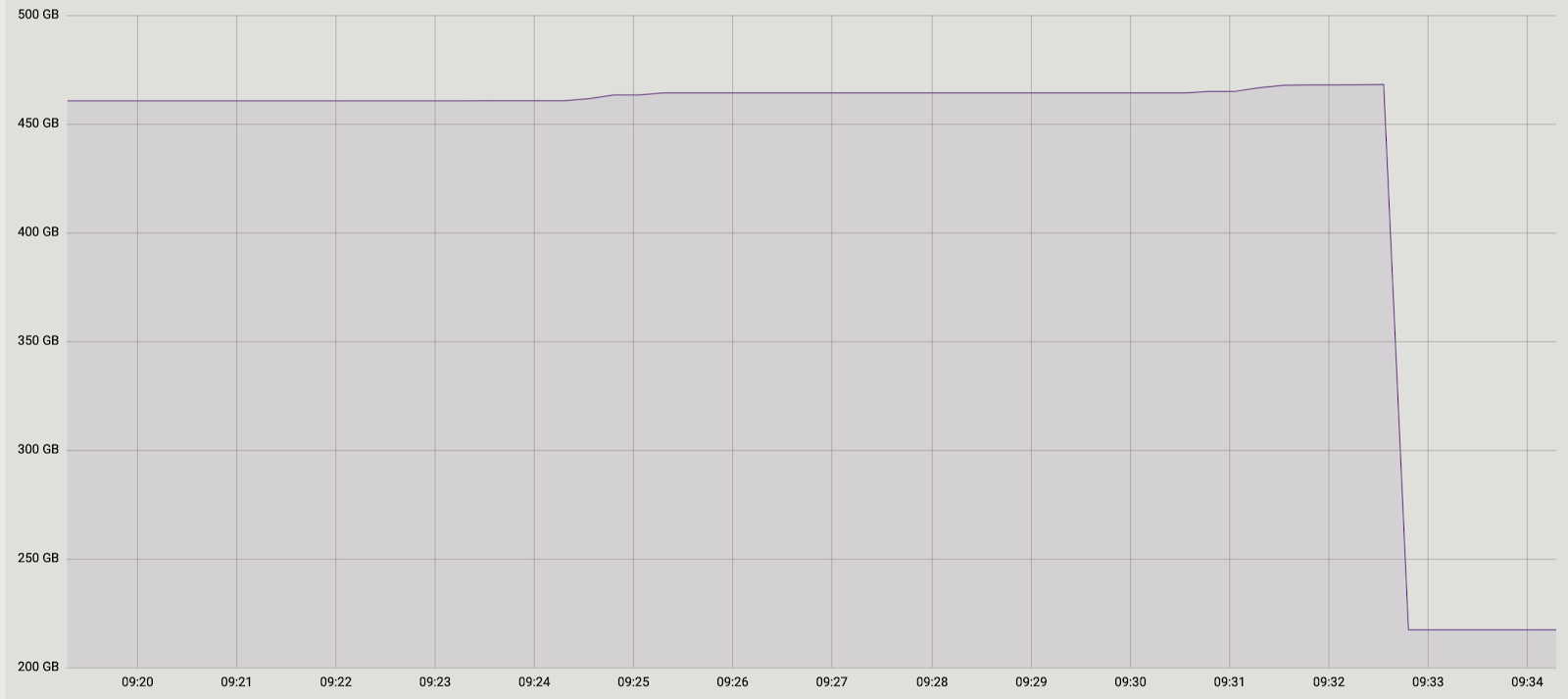 Since this solution completely suited us, we did not try to implement the second, but we are considering discussing it with the developers of the extension. Unfortunately, our current revision is not yet ready for publication, since we have solved the problem only with unique pending restrictions, and for a full-fledged patch it is necessary to make support of other types. We hope to be able to do this in the future.Perhaps you have a question, why did we get involved in this story with the completion of pg_repack, and did not, for example, use its analogues? At some point, we also thought about this, but the positive experience of using it earlier, on tables without pending restrictions, motivated us to try to understand the essence of the problem and fix it. In addition, to use other solutions, it also takes time to conduct tests, so we decided that first we would try to fix the problem in it, and if we realized that we could not do it in a reasonable amount of time, then we would begin to consider analogues.
Since this solution completely suited us, we did not try to implement the second, but we are considering discussing it with the developers of the extension. Unfortunately, our current revision is not yet ready for publication, since we have solved the problem only with unique pending restrictions, and for a full-fledged patch it is necessary to make support of other types. We hope to be able to do this in the future.Perhaps you have a question, why did we get involved in this story with the completion of pg_repack, and did not, for example, use its analogues? At some point, we also thought about this, but the positive experience of using it earlier, on tables without pending restrictions, motivated us to try to understand the essence of the problem and fix it. In addition, to use other solutions, it also takes time to conduct tests, so we decided that first we would try to fix the problem in it, and if we realized that we could not do it in a reasonable amount of time, then we would begin to consider analogues.findings
What we can recommend based on our own experience:- Monitor your bloat. Based on monitoring data, you can understand how well autovacuum is configured.
- Set AUTOVACUUM to keep bloat at a reasonable level.
- bloat “ ”, . – .
- – , .