Once, a colleague shared his thoughts about the API for distributed computing clusters, and I jokingly answered: “Obviously, an ideal API would be a simple call telefork()so that your process wakes up on each cluster machine, returning the value of the instance ID.” But in the end, this idea took possession of me. I could not understand why it is so stupid and simple, much simpler than any API for remote work, and why computer systems do not seem to be capable of such. I also seemed to understand how this can be implemented, and I already had a good name, which is the most difficult part of any project. So I got to work.Over the first weekend, he made a basic prototype, and the second weekend brought a demo that couldWhat does it look like
I implemented the code as a Rust library, but theoretically you can wrap the program in the C API and then run through the FFI bindings to teleport even the Python process. The implementation is only about 500 lines of code (plus 200 lines of comments):use telefork::{telefork, TeleforkLocation};
fn main() {
let args: Vec<String> = std::env::args().collect();
let destination = args.get(1).expect("expected arg: address of teleserver");
let mut stream = std::net::TcpStream::connect(destination).unwrap();
match telefork(&mut stream).unwrap() {
TeleforkLocation::Child(val) => {
println!("I teleported to another computer and was passed {}!", val);
}
TeleforkLocation::Parent => println!("Done sending!"),
};
}
I also wrote a helper called yoyoteleforks to the server, performs the transmitted closure, and then teleforks back. This creates the illusion that you can easily run a piece of code on a remote server, for example, with much greater processing power.
let scene = create_scene();
let mut backbuffer = vec![Vec3::new(0.0, 0.0, 0.0); width * height];
telefork::yoyo(destination, || {
render_scene(&scene, width, height, &mut backbuffer);
});
save_png_file(width, height, &backbuffer);
Linux process anatomy
Let's see what the process looks like in Linux (on which the mother host OS is running telefork):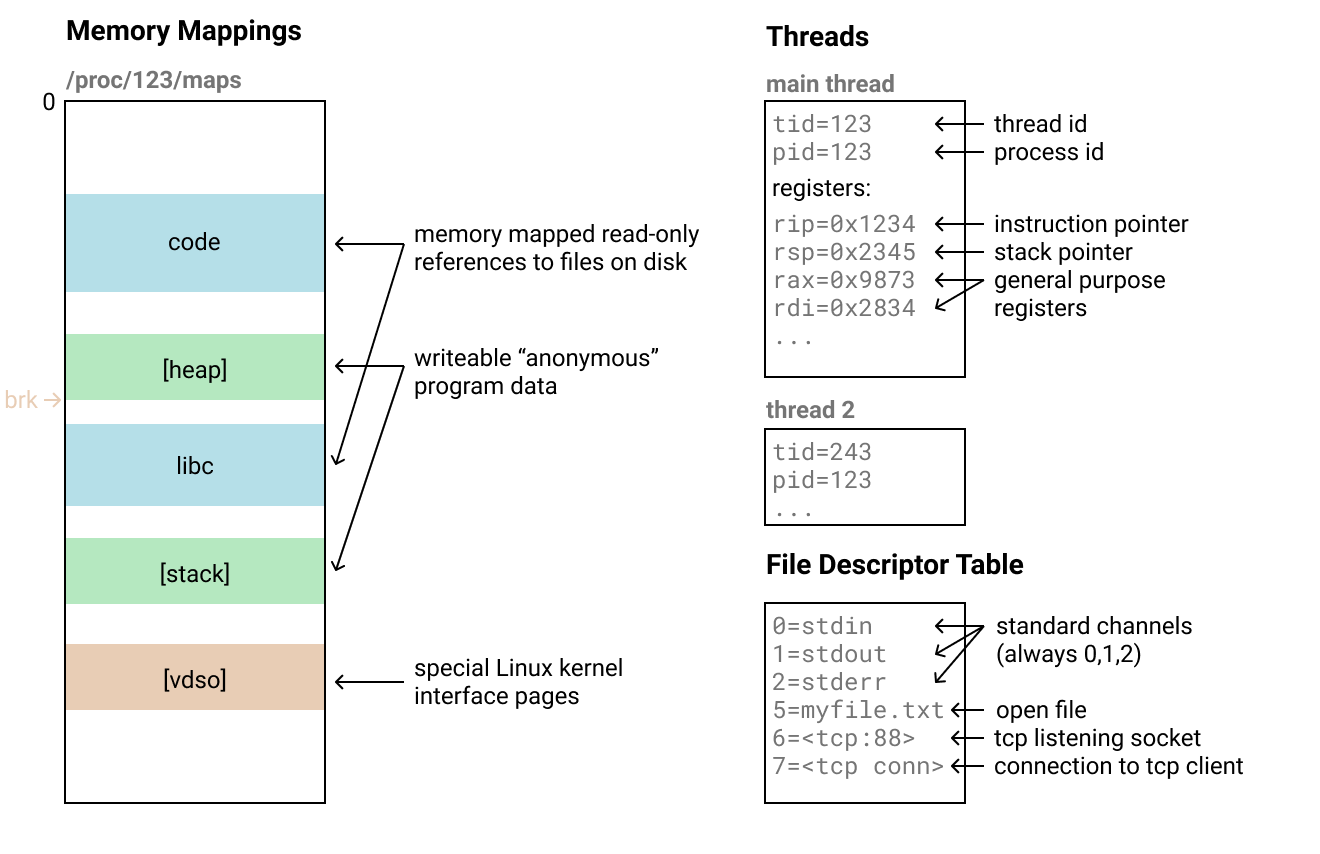
- (memory mappings): , . «» 4 .
/proc/<pid>/maps. , , .
- : , . , , - , , , . , .
- : , . - , . , , , TCP-, .
- . stdin/stdout/stderr, 0, 1 2.
- , , , .
- Miscellaneous : There are some other parts of the process state that vary in replication complexity. But in most cases, they do not matter, for example, brk (heap pointer). Some of them can be restored only with the help of strange tricks or special system calls like PR_SET_MM_MAP , which complicates the recovery.
Thus, the basic implementation teleforkcan be done with a simple mapping of memory and registers of the main threads. This should be enough for simple programs that mainly perform calculations without interacting with OS resources, such as files (in principle, for teleportation it is enough to open the file in the system and close it before calling telefork).How to telefork a process
I was not the first to think about re-creating processes on another machine. So, the rr debugging and recording debugger does very similar things . I sent a few questions to the author of this program @rocallahan , and he told me about the CRIU system for “hot” migration of containers between hosts. CRIU can transfer the Linux process to another system, supports the recovery of all kinds of file descriptors and other states, however, the code is really complex and uses many system calls that require special kernel assemblies and root permissions. Using the link from the CRIU wiki page, I found DMTCP created for snapshots of distributed tasks on supercomputers so that they can be restarted later, and this programThe code turned out to be simpler .These examples did not force me to abandon attempts to implement my own system, since these are extremely complex programs that require special runners and infrastructure, and I wanted to implement the simplest possible teleportation of processes as a library call. So I studied the fragments of the source code rr, CRIU, DMTCP, and some ptrace examples - and put together my own procedure telefork. My method works in its own way, it is a mishmash of various techniques.To teleport a process, you need to do some work in the original process that calls telefork, and some work on the side of the function call, which receives the streaming process on the server and recreates it from the stream (functiontelepad) They can happen at the same time, but all serialization can also be done before downloading, for example, dropping it to a file, and later downloading it.The following is a simplified overview of both processes. If you want to understand in detail, I suggest reading the source code . It is contained in one file and tightly commented out to read in order and understand how everything works.Submitting a process using telefork
The function teleforkreceives a stream with write capability, by which it transfers the entire state of its process.- «» . , , . fork .
- .
/proc/<pid>/maps , . proc_maps crate.
- . DMTCP, , , . ,
[vdso], , , .
- . , , process_vm_readv , .
- Transfer Registers . I use the option
PTRACE_GETREGSfor the ptrace system call . It allows you to get all the values of the register of the child process. Then I just write them in a message on the channel.
Running system calls in a child process
To turn the target process into a copy of the incoming process, you will need to force the process to execute a bunch of system calls on itself, without access to any code, because we deleted everything. We make remote system calls using ptrace , a universal system call for manipulating and checking other processes:- syscall. syscall , . ,
process_vm_readv [vdso] , , , syscall Linux, . , [vdso].
- ,
PTRACE_SETREGS. syscall, rax Linux, rdi, rsi, rdx, r10, r8, r9.
- Take one step using the parameter
PTRACE_SINGLESTEPto execute the syscall command.
- Read the registers with
PTRACE_GETREGSto restore the syscall return value and see if it succeeded.
Process acceptance in telepad
Using this and the already described primitives, we can recreate the process:- Fork a frozen child process . Similar to sending, but this time we need a child process that we can manipulate to turn it into a clone of the transferred process.
- Check memory allocation cards . This time we need to know all the existing memory allocation cards in order to remove them and make room for the incoming process.
- . ,
munmap.
- .
mremap, .
- .
mmap , process_vm_writev .
- .
PTRACE_SETREGS , , rax. raise(SIGSTOP), . , telepad.
- An arbitrary value is used so that the telefork server can transfer the file descriptor of the TCP connection that the process entered, and can send data back or, in case
yoyo, teleport back to the same connection.
- Restart the process with the new content using
PTRACE_DETACH.
More competent implementation
Some parts of my telefork implementation are not perfectly designed. I know how to fix them, but in the current form I like the system, and sometimes they are really difficult to fix. Here are some interesting examples:- (vDSO).
mremap vDSO , DMTCP, , . vDSO, . - , CPU glibc vDSO . , vDSO, syscall, rr, vDSO vDSO .
brk . DMTCP, , brk , brk . , , — PR_SET_MM_MAP, .
- . Rust « », , FS GS, , , -
glibc pid tid, . CRIU, PID TID .
- . , , , / , / FUSE. , TCP-, DMTCP CRIU ,
perf_event_open.
- .
fork() Unix , , .
I think you already understood that with the right low-level interfaces, you can implement some crazy things that seemed impossible to someone. Here are some thoughts on how to develop the basic ideas of telefork. Although much of the above can probably be fully implemented only on a completely new or fixed kernel:- Cluster telefork . The initial source of inspiration for telefork was the idea of streaming a process to all machines in a computing cluster. It may even turn out to implement UDP multicast or peer-to-peer methods to speed up distribution across the entire cluster. You probably also want to have communication primitives.
- . CRIU , -
userfaultfd. , SIGSEGV mmap. , , — .
- ! , .
userfaultfd userfaultfd, , , MESI, . , , . — , . , , , . : syscall, -, syscall, . , . , , , . , , . , , ( , ) , .
I really like it a lot, because here is an example of one of my favorite techniques - diving into a lesser-known layer of abstraction, which relatively easily fulfills what we thought was almost impossible. Teleporting computations may seem impossible or very difficult. You might think that it would require methods such as serializing the entire state, copying the binary executable to the remote machine, and launching it there with special command line flags to reload the state. But no, everything is much simpler. Under your favorite programming language lies an abstraction layer where you can choose a fairly simple subset of functions - and over the weekend implement teleportation of most pure calculations in any programming language in 500 lines of code. I thinkthat such diving to another level of abstraction often leads to simpler and more universal solutions. Another of my projects like this one isNumderline .At first glance, such projects seem to be extreme hacks, and to a large extent it is. They do things like nobody expects, and when they break, they do it at the level of abstraction, at which similar programs should not work — for example, your file descriptors mysteriously disappear. But sometimes you can correctly set the level of abstraction and encode any possible situations, so that in the end everything will work smoothly and magically. I think the good examples here are rr (although telefork managed to sack it) and cloud migration of virtual machines in real time (in fact, telefork at the hypervisor level).I also like to present these things as ideas for alternative ways of working computer systems. Why are our cluster computing APIs so much more complicated than a simple program that translates functions into a cluster? Why is network system programming so much more complicated than multithreaded? Of course, you can give all sorts of good reasons, but they are usually based on how difficult it is to make an example of existing systems. Or maybe with the right abstraction or with sufficient effort, everything will work easily and seamlessly? Fundamentally, there is nothing impossible.
