Intro
If you have not overslept the last couple of years, then you, of course, have heard from transformers - architecture from the canonical Attention is all you need . Why are transformers so good? For example, they avoid recurrence, which enables them to efficiently create such a presentation of data into which a lot of contextual information can be pushed, which positively affects the ability to generate texts and the unsurpassed ability to transfer learning.
Transformers launched an avalanche of work on language modeling - a task in which the model selects the next word, taking into account the probabilities of the previous words, that is, learning p(x)where the xcurrent token is. As you might guess, this task does not require markup at all, and therefore you can use huge unannotated arrays of text in it. An already trained language model can generate text, so well that authors sometimes refuse to lay out trained models .
But what if we want to add some “pens” to the text generation? For example, do conditional generation by setting a theme or controlling other attributes. Such a form already requires conditional probability p(x|a), where ais the desired attribute. Interesting? Let's go under the cut!
The authors of the article offer a simple (and therefore Plug and Play) and elegant approach to conditional generation, using a heavy pre-trained language model (hereinafter LM) and several simple classifiers, thereby sampling from a view distribution p(x|a) ∝ p(a|x)p(x). It should be noted that the original LM is not modified in any way. The authors propose two forms of classifiers, called attribute models in the article: BoW for topic control and a linear classifier for tonality control. The authors make a fairly detailed analysis of their key contributions, comparing the ideas and approaches of their method with other articles. One of the most important points is the ease of approach, and here, perhaps, just look at this plate:
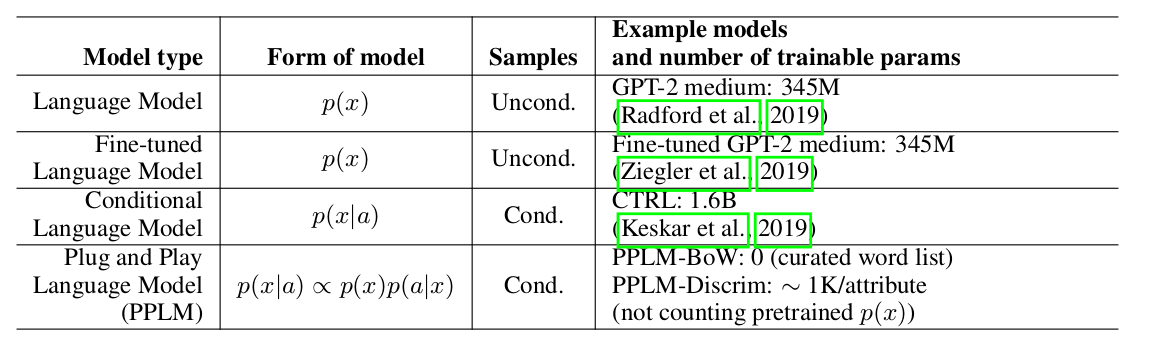
It can be seen that PPLM outperforms all competitors in the number of parameters.
Weighted decoding 2.0
Uber weighted decoding: , . , , . , . , , , .
Uber : , LM, . , , , ( , ) . ( perturb_past — , .
? log-likelihood: p(x) a attribute model p(a|x). , backward pass .
log-likelihood? , :
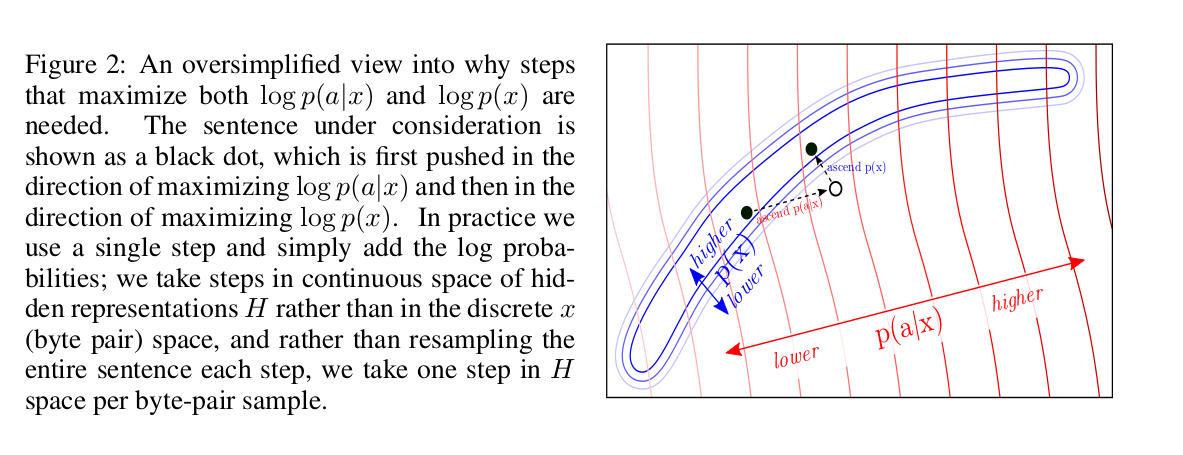
, , LM. , fluency LM.
, :

forward pass LM, p(a|x) — attribute model. backward pass, , attribute model, , . , .
, : “” k k forward backward pass’, n. LM forward pass. , : ( num of iterations=3 gen length=5, ).
, ( colab , ) , , , “the kitten” “military” :
- The kitten is a creature with no real personality, it is just a pet. You can use it as a combat item.
- The kitten that is now being called the "suspected killer" of a woman in a San Diego apartment complex was shot by another person who then shot him, according to authorities.
combat, shot, killer — , military. LM :
- The kitten that escaped a cage has been rescued from a cat sanctuary in Texas.
- The cat, named "Lucky," was found wandering in the back yard of the Humane Society at the time of the incident on Friday.
attribute models
, BoW discriminator. :
p_t+1 — LM, w_i — i- .
Discriminator model , BoW, , , , . , .
, LM, LM weighted decoding CTRL (conditional LM). fluency , , perplexity . PPLM :
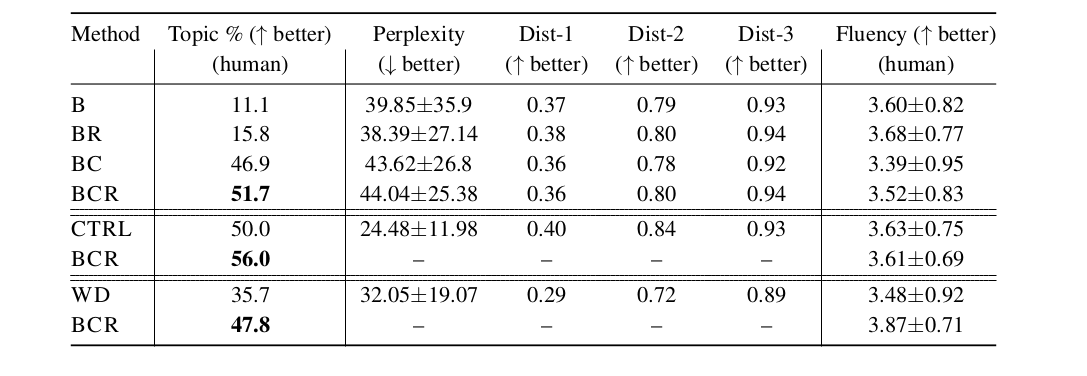
:
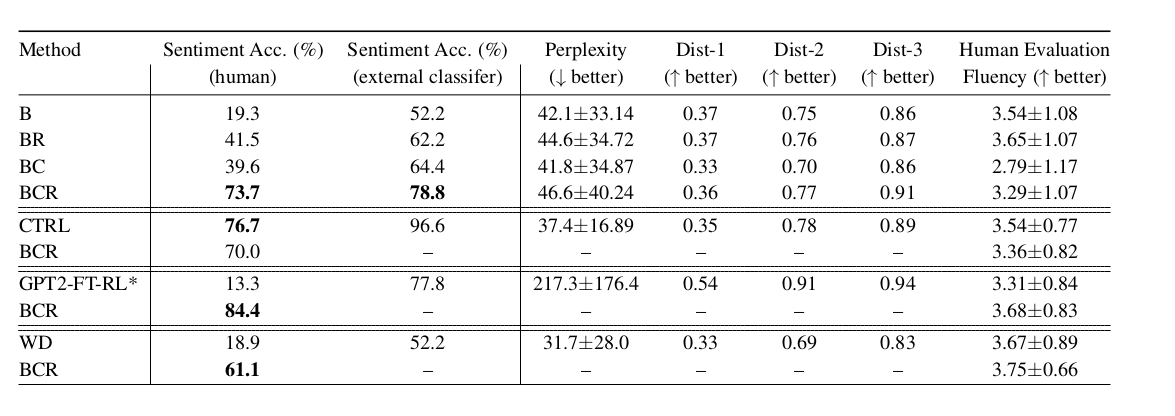
- B — baseline, GPT-2 LM;
- BR — , B,
r , log-likelihood ; - BC — , ;
- BCR — , BC,
r , log-likelihood ; - CTRL — Keskar et al, 2019;
- GPT2-FT-RL — GPT2, fine-tuned RL ;
- WD — weighted decoding,
p(a|x);
— , LM, . , , - :)