 The Internet is full of articles on N-gram-based language models. At the same time, there are quite few libraries ready for work.There are KenLM , SriLM and IRSTLM . They are popular and used in many large projects. But there are problems:
The Internet is full of articles on N-gram-based language models. At the same time, there are quite few libraries ready for work.There are KenLM , SriLM and IRSTLM . They are popular and used in many large projects. But there are problems:- Libraries are old, not developing.
- Poor support for the Russian language.
- Only work with clean, specially prepared text
- Poor support for UTF-8. For example, SriLM with the tolower flag breaks the encoding.
KenLM
stands out a bit from the list . It is regularly supported and has no problems with UTF-8, but it is also demanding on the quality of the text.Once I needed a library to build a language model. After many trial and error, I came to the conclusion that preparing a dataset for teaching a language model is too complicated and a long process. Especially if it's Russian ! But I wanted to somehow automate everything.In his research, he started from the SriLM library . I’ll note right away that this is not a code borrow or SriLM fork . All code is written completely from scratch.A small text example:
! .
The lack of a space between sentences is a fairly common typo. Such an error is difficult to find in a large amount of data, while it breaks the tokenizer.After processing, the following N-gram will appear in the language model:
-0.3009452 !
Of course, there are many other problems, typos, special characters, abbreviations, various mathematical formulas ... All this must be handled correctly.ANYKS LM ( ALM )
The library only supports Linux , MacOS X, and FreeBSD operating systems . I do not have Windows and no support is planned.Short description of functionality
- Support for UTF-8 without third-party dependencies.
- Support for data formats: Arpa, Vocab, Map Sequence, N-grams, Binary alm dictionary.
- : Kneser-Nay, Modified Kneser-Nay, Witten-Bell, Additive, Good-Turing, Absolute discounting.
- , , , .
- , N-, N- , N-.
- — N-, .
- : , -.
- N- — N-, backoff .
- N- backoff-.
- , : , , , , Python3.
- « », .
- 〈unk〉 .
- N- Python3.
- , .
- . : , , .
- Unlike other language models, ALM is guaranteed to collect all N-grams from text, regardless of their length (except for Modified Kneser-Nay). There is also the possibility of compulsory registration of all rare N-grams, even if they met only 1 time.
Of the standard language model formats, only the ARPA format is supported . Honestly, I see no reason to support the entire zoo in all kinds of formats.The ARPA format is case sensitive and this is also a definite problem.Sometimes it’s useful to know only the presence of specific data in the N-gram. For example, you need to understand the presence of numbers in the N-gram, and their meaning is not so important.Example:
, 2
As a result, the N-gram gets into the language model:
-0.09521468 2
The specific number, in this case, does not matter. Sale in the store can go 1 and 3 and as many days as you like.To solve this problem, ALM uses class tokenization.Supported Tokens
Standard:〈s〉 - Token of the beginning of the sentence〈/s〉 - Token of the end of the sentence〈unk〉 - Token of an unknown wordNon-standard:〈url〉 - Token of the url address〈num〉 - Token of numbers (Arabic or Roman)〈date〉 - Date token (July 18, 2004 | 07/18/2004)〈time〉 - Time Token (15:44:56)〈abbr〉 - Abbreviation Token (1st | 2nd | 20th)〉anum〉 - Pseudo -Token numbers (T34 | 895-M-86 | 39km)〈math〉 - Token of mathematical operations (+ | - | = | / | * | ^)〈range〉 - Token of the range of numbers (1-2 | 100-200 | 300- 400)〈aprox〉- An approximate number token (~ 93 | ~ 95.86 | 10 ~ 20)〈score〉 - A numeric account token (4: 3 | 01:04)〈dimen〉 - Overall token (200x300 | 1920x1080)〈fract〉 - A fraction fraction token (5/20 | 192/864)〈punct〉 - Punctuation character token (. | ... |, |! |? |: |;)〈Specl〉 - Special character token (~ | @ | # | No. |% | & | $ | § | ±)〈isolat〉 - Isolation symbol token ("| '|" | "|„ | “|` | (|) | [|] | {|})Of course, support for each of the tokens can be disabled if such N-grams are needed.Ifyou need to process other tags (for example, you need to find country names in the text), ALM supports connection of external scripts in Python3.An example of a token detection script:
def init():
"""
:
"""
def run(token, word):
"""
:
@token
@word
"""
if token and (token == "<usa>"):
if word and (word.lower() == ""): return "ok"
elif token and (token == "<russia>"):
if word and (word.lower() == ""): return "ok"
return "no"
Such a script adds two more tags to the list of standard tags: 〈usa〉 and 〈russia〉 .In addition to the token detection script, there is support for a preprocessing script for processed words. This script can change the word before adding the word to the language model.An example of a word-processing script:
def init():
"""
:
"""
def run(word, context):
"""
:
@word
@context
"""
return word
Such an approach can be useful if it is necessary to assemble a language model consisting of lemmas or stemms .Language Model Text Formats Supported by ALM
ARPA:
\data\
ngram 1=52
ngram 2=68
ngram 3=15
\1-grams:
-1.807052 1- -0.30103
-1.807052 2 -0.30103
-1.807052 3~4 -0.30103
-2.332414 -0.394770
-3.185530 -0.311249
-3.055896 -0.441649
-1.150508 </s>
-99 <s> -0.3309932
-2.112406 <unk>
-1.807052 T358 -0.30103
-1.807052 VII -0.30103
-1.503878 -0.39794
-1.807052 -0.30103
-1.62953 -0.30103
...
\2-grams:
-0.29431 1-
-0.29431 2
-0.29431 3~4
-0.8407791 <s>
-1.328447 -0.477121
...
\3-grams:
-0.09521468
-0.166590
...
\end\
ARPA is the standard text format for the natural language language model used by Sphinx / CMU and Kaldi .NGRAMS:
\data\
ad=1
cw=23832
unq=9390
ngram 1=9905
ngram 2=21907
ngram 3=306
\1-grams:
<s> 2022 | 1
<num> 117 | 1
<unk> 19 | 1
<abbr> 16 | 1
<range> 7 | 1
</s> 2022 | 1
244 | 1
244 | 1
11 | 1
762 | 1
112 | 1
224 | 1
1 | 1
86 | 1
978 | 1
396 | 1
108 | 1
77 | 1
32 | 1
...
\2-grams:
<s> <num> 7 | 1
<s> <unk> 1 | 1
<s> 84 | 1
<s> 83 | 1
<s> 57 | 1
82 | 1
11 | 1
24 | 1
18 | 1
31 | 1
45 | 1
97 | 1
71 | 1
...
\3-grams:
<s> <num> </s> 3 | 1
<s> 6 | 1
<s> 4 | 1
<s> 2 | 1
<s> 3 | 1
2 | 1
</s> 2 | 1
2 | 1
2 | 1
2 | 1
2 | 1
2 | 1
</s> 2 | 1
</s> 3 | 1
2 | 1
...
\end\
Ngrams - non-standard text format of the language model, is a modification of the ARPA format .Description:- ad - Number of documents in the enclosure
- cw - The number of words in all documents in the corpus
- unq - Number of unique words collected
VOCAB:
\data\
ad=1
cw=23832
unq=9390
\words:
33 244 | 1 | 0.010238 | 0.000000 | -3.581616
34 11 | 1 | 0.000462 | 0.000000 | -6.680889
35 762 | 1 | 0.031974 | 0.000000 | -2.442838
40 12 | 1 | 0.000504 | 0.000000 | -6.593878
330344 47 | 1 | 0.001972 | 0.000000 | -5.228637
335190 17 | 1 | 0.000713 | 0.000000 | -6.245571
335192 1 | 1 | 0.000042 | 0.000000 | -9.078785
335202 22 | 1 | 0.000923 | 0.000000 | -5.987742
335206 7 | 1 | 0.000294 | 0.000000 | -7.132874
335207 29 | 1 | 0.001217 | 0.000000 | -5.711489
2282019644 1 | 1 | 0.000042 | 0.000000 | -9.078785
2282345502 10 | 1 | 0.000420 | 0.000000 | -6.776199
2282416889 2 | 1 | 0.000084 | 0.000000 | -8.385637
3009239976 1 | 1 | 0.000042 | 0.000000 | -9.078785
3009763109 1 | 1 | 0.000042 | 0.000000 | -9.078785
3013240091 1 | 1 | 0.000042 | 0.000000 | -9.078785
3014009989 1 | 1 | 0.000042 | 0.000000 | -9.078785
3015727462 2 | 1 | 0.000084 | 0.000000 | -8.385637
3025113549 1 | 1 | 0.000042 | 0.000000 | -9.078785
3049820849 1 | 1 | 0.000042 | 0.000000 | -9.078785
3061388599 1 | 1 | 0.000042 | 0.000000 | -9.078785
3063804798 1 | 1 | 0.000042 | 0.000000 | -9.078785
3071212736 1 | 1 | 0.000042 | 0.000000 | -9.078785
3074971025 1 | 1 | 0.000042 | 0.000000 | -9.078785
3075044360 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123271427 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123322362 1 | 1 | 0.000042 | 0.000000 | -9.078785
3126399411 1 | 1 | 0.000042 | 0.000000 | -9.078785
…
Vocab is a non-standard text dictionary format in the language model.Description:- oc - case occurrence
- dc - occurrence in documents
- tf - (term frequency — ) — . , , : [tf = oc / cw]
- idf - (inverse document frequency — ) — , , : [idf = log(ad / dc)]
- tf-idf - : [tf-idf = tf * idf]
- wltf - , : [wltf = 1 + log(tf * dc)]
MAP:
1:{2022,1,0}|42:{57,1,0}|279603:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|320749:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|351283:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|379815:{3,1,0}
1:{2022,1,0}|42:{57,1,0}|26122748:{3,1,0}
1:{2022,1,0}|44:{6,1,0}
1:{2022,1,0}|48:{1,1,0}
1:{2022,1,0}|51:{11,1,0}|335967:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|371327:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|40260976:{7,1,0}
1:{2022,1,0}|65:{68,1,0}|34:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|3277:{3,1,0}
1:{2022,1,0}|65:{68,1,0}|278003:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|320749:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|11353430797:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|34270133320:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|51652356484:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|66967237546:{2,1,0}
1:{2022,1,0}|2842:{11,1,0}|42:{7,1,0}
…
Map - the contents of the file, has a purely technical meaning. Used in conjunction with the vocab file , you can combine several language models, modify, store, distribute and export to any format ( arpa , ngrams , binary alm ).Helper Text File Formats Supported by ALM
Often, when assembling a language model, typos occur in the text, which are replacing letters (with visually similar letters of another alphabet).ALM solves this problem with a file with similar-looking letters.p
c
o
t
k
e
a
h
x
b
m
If, when teaching a language model, transferring files with a list of first-level domains and abbreviations, then ALM can help with more accurate detection of the 〈url〉 and 〈abbr〉 class tags .Abbreviations List File:
…
Domain Zone List File:
ru
su
cc
net
com
org
info
…
For more accurate detection of the 〈url〉 token , you should add your first-level domain zones (all domain zones from the example are already pre-installed) .Binary container of the ALM language model
To build a binary container for the language model, you need to create a JSON file with a description of your parameters.JSON options:
{
"aes": 128,
"name": "Name dictionary",
"author": "Name author",
"lictype": "License type",
"lictext": "License text",
"contacts": "Contacts data",
"password": "Password if needed",
"copyright": "Copyright author"
}
Description:- aes - AES encryption size (128, 192, 256) bits
- name - Dictionary name
- author - Dictionary author
- lictype - Type of license
- lictext - License text
- contacts - Author contact details
- password - Encryption password (if required), encryption is performed only when setting a password
- copyright - Copyright of the dictionary owner
All parameters are optional except the name of the container.ALM Library Examples
Tokenizer Operation
The tokenizer receives text at the input, and generates JSON at the output.$ echo 'Hello World?' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
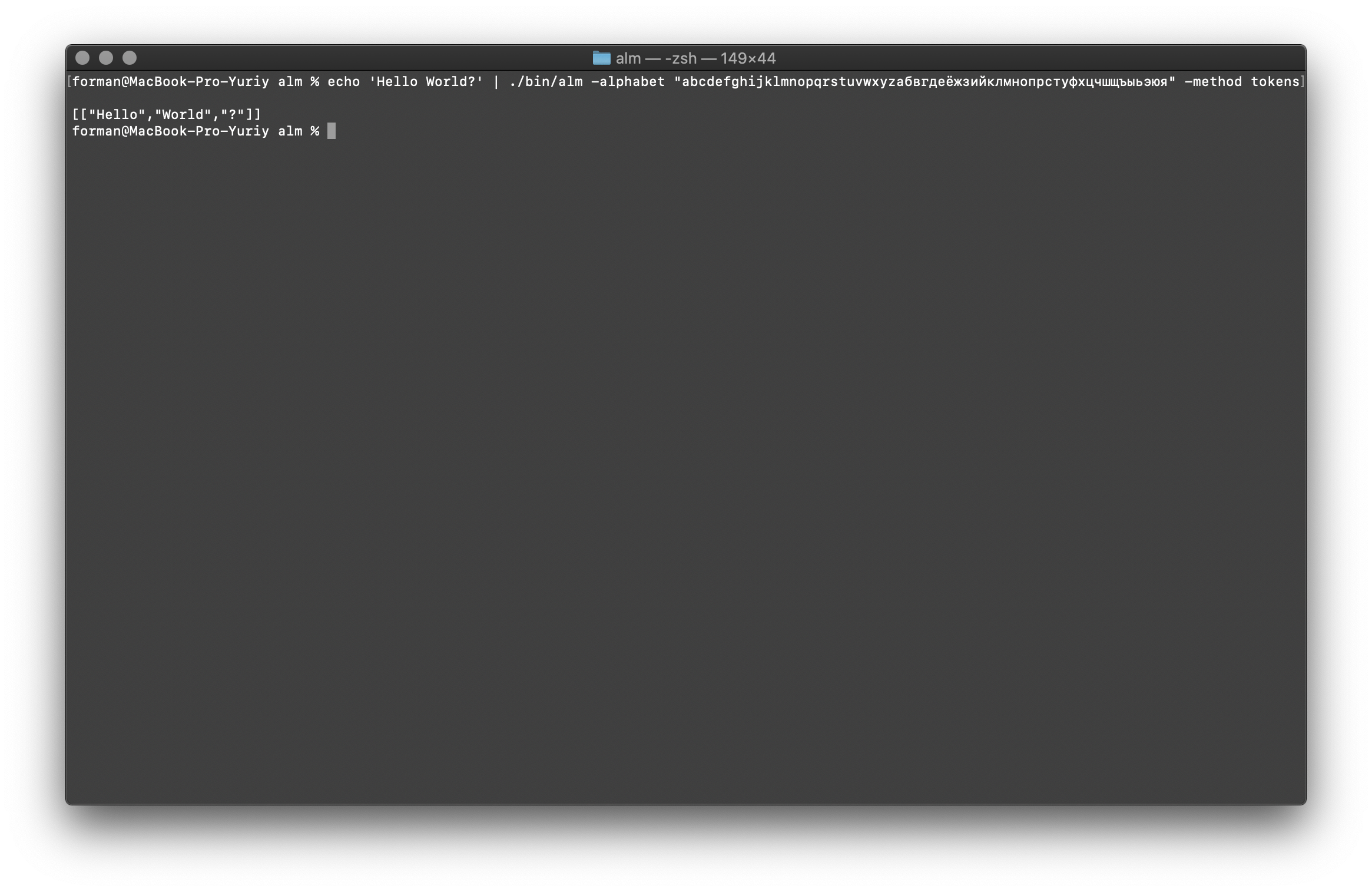 Test:
Test:Hello World?
Result:[
["Hello","World","?"]
]
Let's try something harder ...$ echo ' ??? ....' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
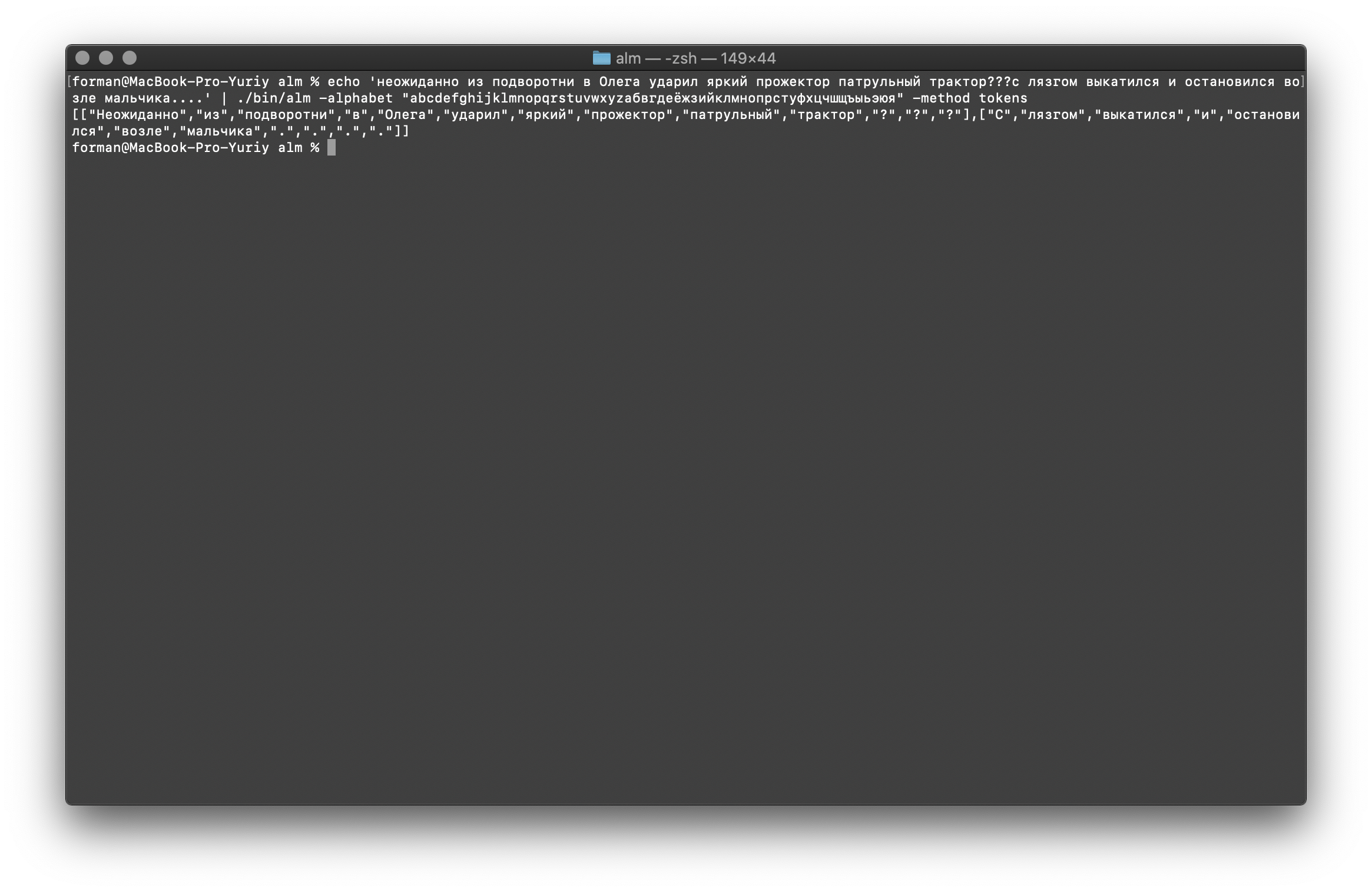 Test:
Test: ??? ....
Result:[
[
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"?",
"?",
"?"
],[
"",
"",
"",
"",
"",
"",
"",
".",
".",
".",
"."
]
]
As you can see, the tokenizer worked correctly and fixed the basic errors.Change the text a bit and see the result.$ echo ' ... .' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
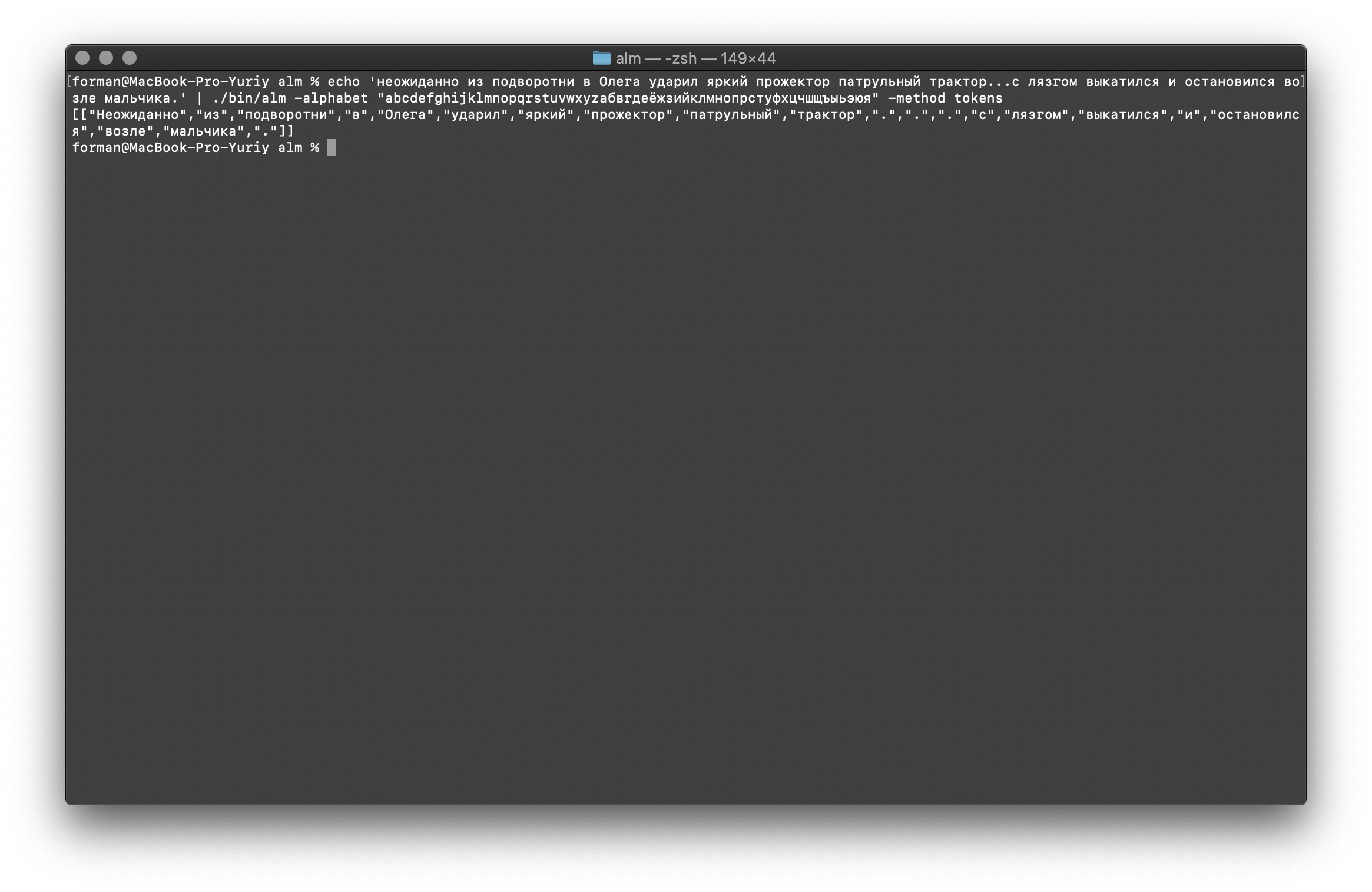 Test:
Test: ... .
Result:[
[
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
".",
".",
".",
"",
"",
"",
"",
"",
"",
"",
"."
]
]
As you can see, the result has changed. Now try something else.$ echo ' 5–7 . : 1 . ( +37–38°), 5–10 . – ( +12–15°) ..»| |()' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Test:
Test: 5–7 . : 1 . ( +37–38°), 5–10 . – ( +12–15°) ..»| |()
Result:[
[
"",
"",
"",
"",
"5–7",
".",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
":",
"1",
".",
"",
"",
"(",
"+37–38°",
")",
",",
"",
"5–10",
".",
"–",
"",
"",
"(",
"+12–15°",
")",
"",
"..",
"»",
"|",
"|",
"(",
")"
]
]
Combine everything back into text
First, restore the first test.$ echo '[["Hello","World","?"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
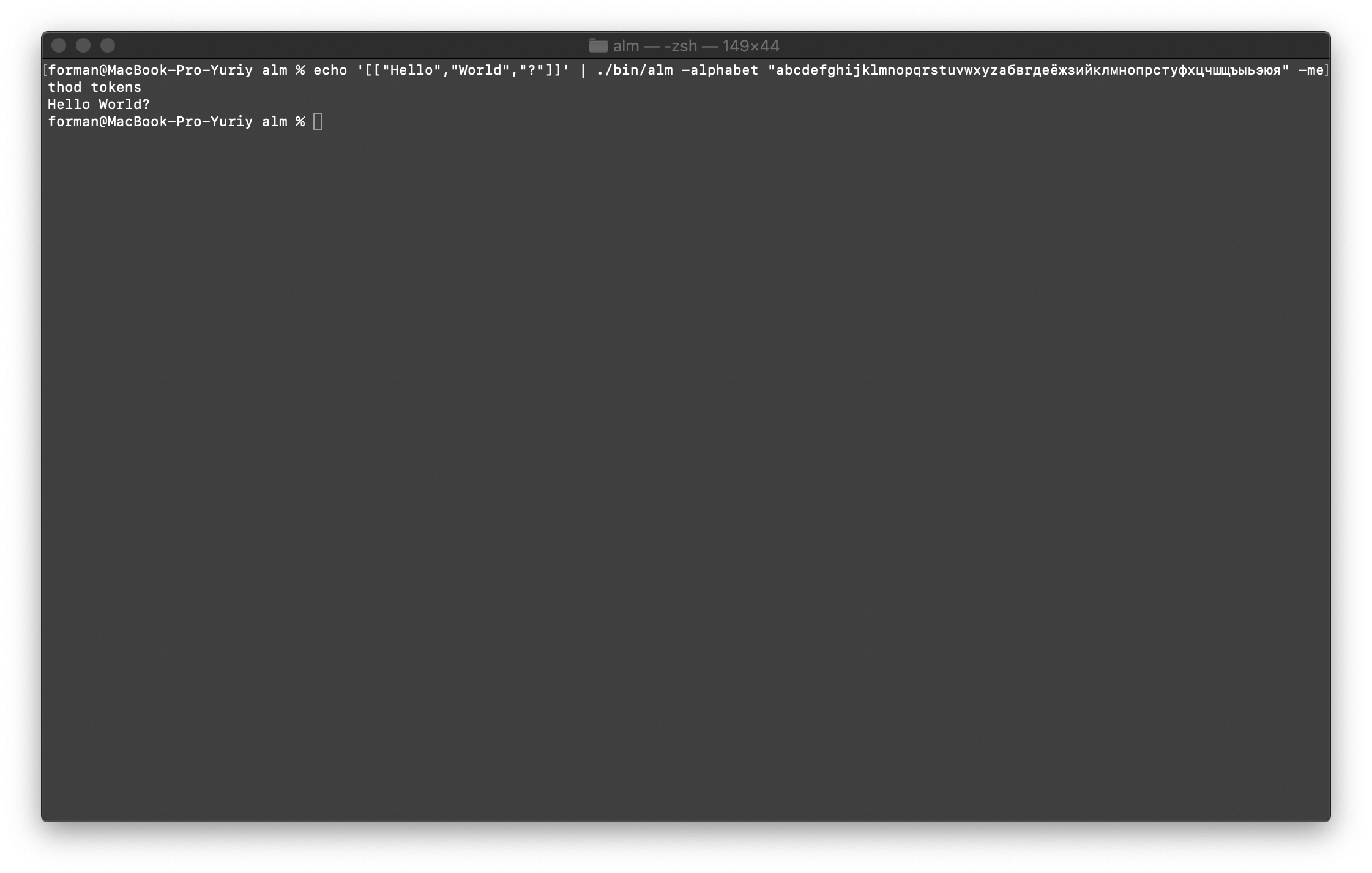 Test:
Test:[["Hello","World","?"]]
Result:Hello World?
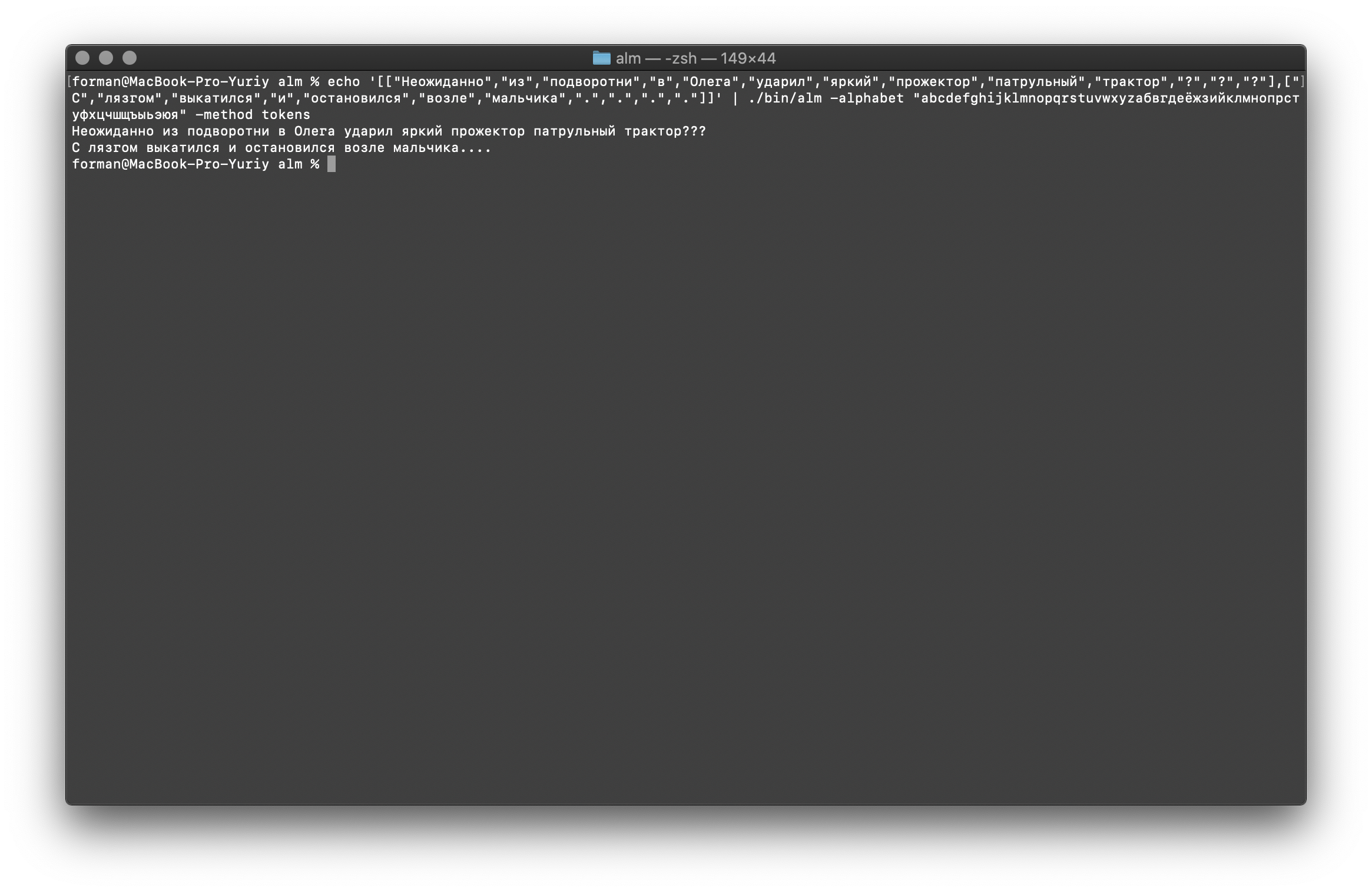
We will now restore the more complex test.$ echo '[["","","","","","","","","","","?","?","?"],["","","","","","","",".",".",".","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Test:
Test:[["","","","","","","","","","","?","?","?"],["","","","","","","",".",".",".","."]]
Result: ???
….
As you can see, the tokenizer was able to restore the initially broken text.Continue on.$ echo '[["","","","","","","","","","",".",".",".","","","","","","","","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Test:
Test:[["","","","","","","","","","",".",".",".","","","","","","","","."]]
Result: ... .
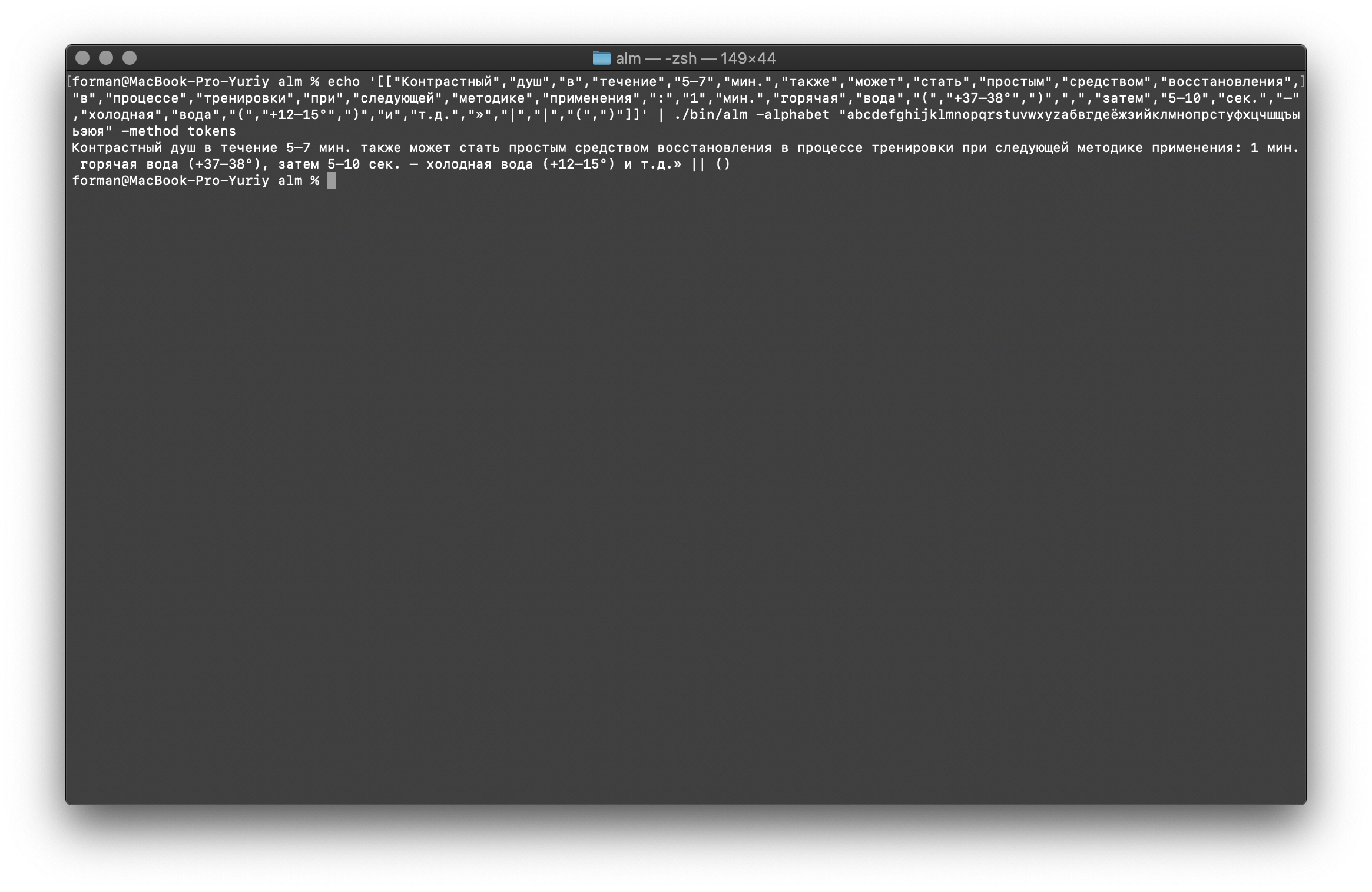
And finally, check the most difficult option.$ echo '[["","","","","5–7",".","","","","","","","","","","","","","",":","1",".","","","(","+37–38°",")",",","","5–10",".","–","","","(","+12–15°",")","","..","»","|","|","(",")"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Test:
Test:[["","","","","5–7",".","","","","","","","","","","","","","",":","1",".","","","(","+37–38°",")",",","","5–10",".","–","","","(","+12–15°",")","","..","»","|","|","(",")"]]
Result: 5–7 . : 1 . (+37–38°), 5–10 . – (+12–15°) ..» || ()
As can be seen from the results, the tokenizer can fix most of the errors in the design of the text.Language model training
$ ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -size 3 -smoothing wittenbell -method train -debug 1 -w-arpa ./lm.arpa -w-map ./lm.map -w-vocab ./lm.vocab -w-ngram ./lm.ngrams -allow-unk -interpolate -corpus ./text.txt -threads 0 -train-segments
I will describe the assembly parameters in more detail.- size - The size of the length of N-grams (the size is set to 3 grams )
- smoothing - Smoothing algorithm (algorithm selected by Witten-Bell )
- method - Method of work (method specified training )
- debug - Debug mode (learning status indicator is set)
- w-arpa — ARPA
- w-map — MAP
- w-vocab — VOCAB
- w-ngram — NGRAM
- allow-unk — 〈unk〉
- interpolate —
- corpus — . ,
- threads - Use multithreading for training (0 - for training, all available processor cores will be given,> 0 the number of cores participating in the training)
- train-segments - The training building will be evenly segmented across all cores
More information can be obtained using the [-help] flag .
Perplexity calculation
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method ppl -debug 2 -r-arpa ./lm.arpa -confidence -threads 0
 Test:
Test: ??? ….
Result:info: <s> <punct> <punct> <punct> </s>
info: p( | <s> ) = [2gram] 0.00209192 [ -2.67945500 ] / 0.99999999
info: p( | ...) = [3gram] 0.91439744 [ -0.03886500 ] / 1.00000035
info: p( | ...) = [3gram] 0.86302624 [ -0.06397600 ] / 0.99999998
info: p( | ...) = [3gram] 0.98003368 [ -0.00875900 ] / 1.00000088
info: p( | ...) = [3gram] 0.85783547 [ -0.06659600 ] / 0.99999955
info: p( | ...) = [3gram] 0.95238819 [ -0.02118600 ] / 0.99999897
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( <punct> | ...) = [3gram] 0.78127873 [ -0.10719400 ] / 1.00000031
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 13 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.18477000 ppl= 1.99027067 ppl1= 2.09848266
info: <s> <punct> <punct> <punct> <punct> </s>
info: p( | <s> ) = [2gram] 0.00809597 [ -2.09173100 ] / 0.99999999
info: p( | ...) = [3gram] 0.19675329 [ -0.70607800 ] / 0.99999972
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.98007204 [ -0.00874200 ] / 0.99999931
info: p( | ...) = [3gram] 0.85785325 [ -0.06658700 ] / 1.00000018
info: p( | ...) = [3gram] 0.81482810 [ -0.08893400 ] / 1.00000027
info: p( | ...) = [3gram] 0.93507404 [ -0.02915400 ] / 1.00000058
info: p( <punct> | ...) = [3gram] 0.76391493 [ -0.11695500 ] / 0.99999971
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 11 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.57026500 ppl= 2.40356248 ppl1= 2.60302678
info: 2 sentences, 24 words, 0 OOVs
info: 0 zeroprobs, logprob= -8.75503500 ppl= 2.23975957 ppl1= 2.31629103
info: work time shifting: 0 seconds
I think there is nothing special to comment on, so we will continue further.Context Existence Check
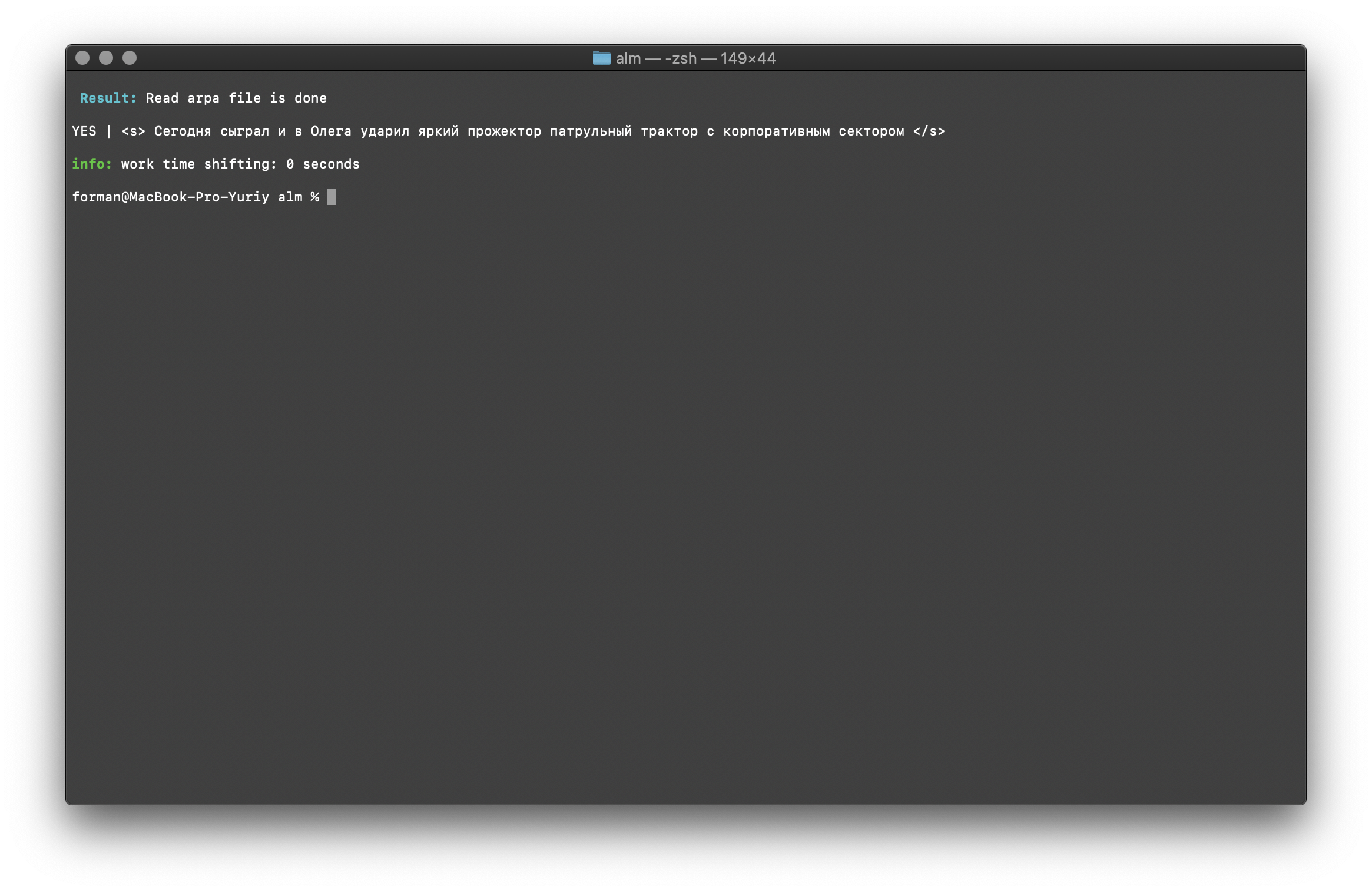
$ echo "<s> </s>" | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method checktext -debug 1 -r-arpa ./lm.arpa -confidence
 Test:
Test:<s> </s>
Result:YES | <s> </s>
The result shows that the text being checked has the correct context in terms of the assembled language model.Flag [ -confidence ] - means that the language model will be loaded as it was built, without overtokenization.Word case correction
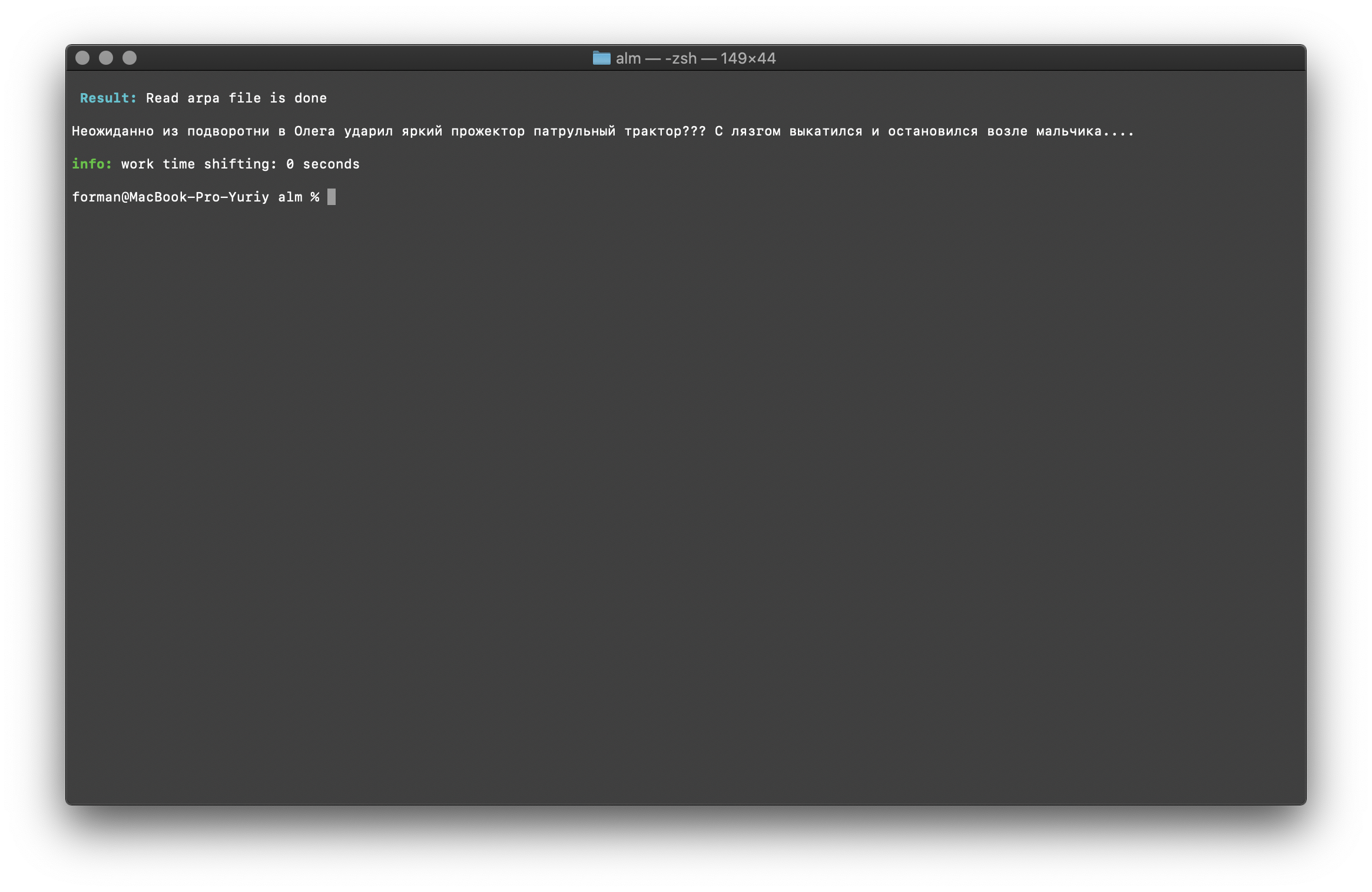
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method fixcase -debug 1 -r-arpa ./lm.arpa -confidence
 Test:
Test: ??? ....
Result: ??? ....
Registers in the text are restored taking into account the context of the language model.The libraries described above for working with statistical language models are case sensitive. For example, the N-gram “ in Moscow tomorrow will rain ” is not the same as the N-gram “ in Moscow will rain tomorrow ”, these are completely different N-grams. But what if the case is required to be case-sensitive and, at the same time, duplicating the same N-grams is irrational? ALM represents all N-grams in lower case. This eliminates the possibility of duplication of N-grams. ALM also maintains its ranking of word registers in each N-gram. When exporting to the text format of a language model, registers are restored depending on their rating.Checking the number of N-grams
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -debug 1 -r-arpa ./lm.arpa -confidence
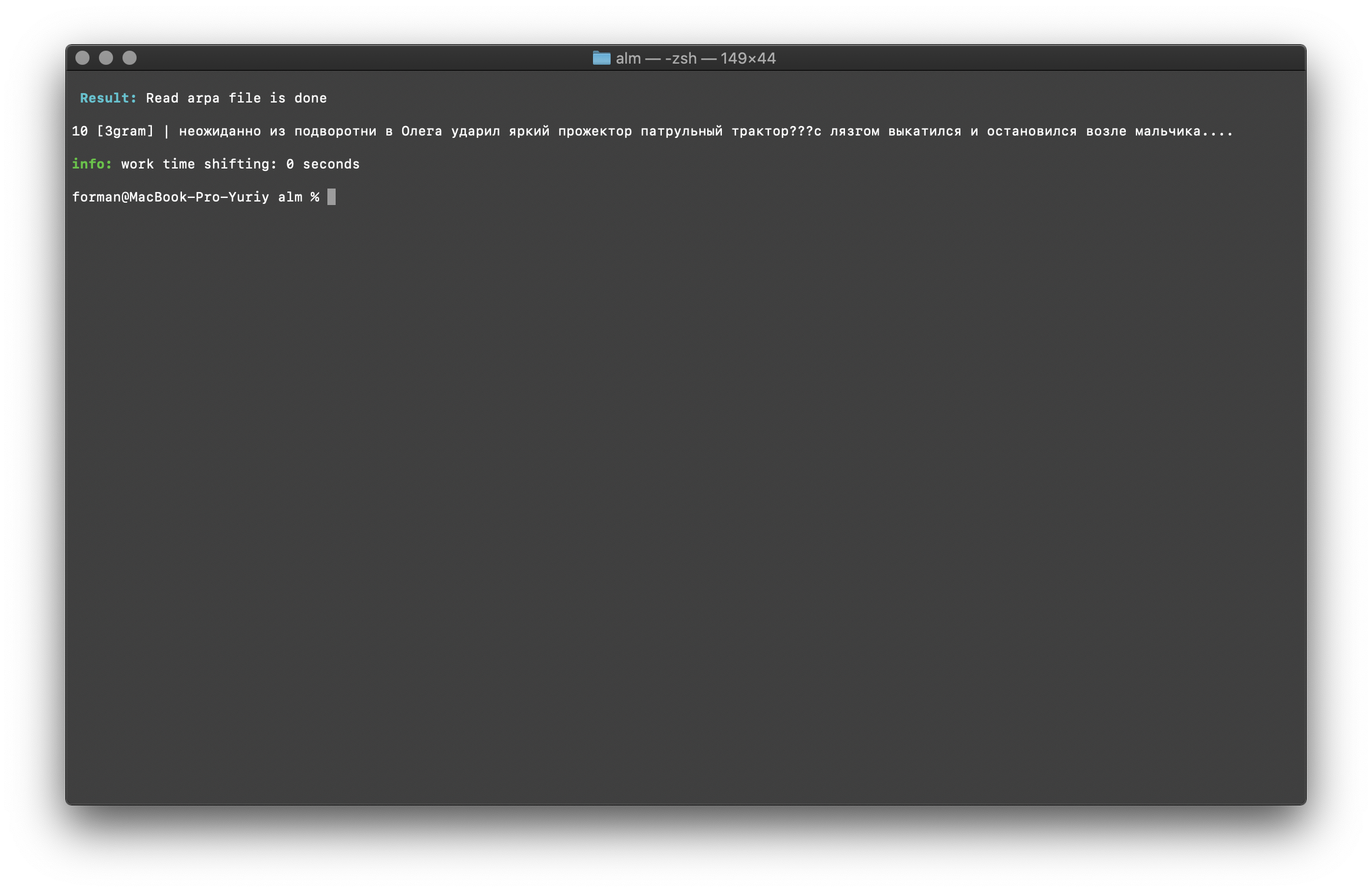 Test:
Test: ??? ....
Result:10 [3gram] |
N- , .
Checking the number of N-grams is performed by the size of the N-gram in the language model. There is also the opportunity to check for bigrams and trigrams .Bigram Check
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -ngrams bigram -debug 1 -r-arpa ./lm.arpa -confidence
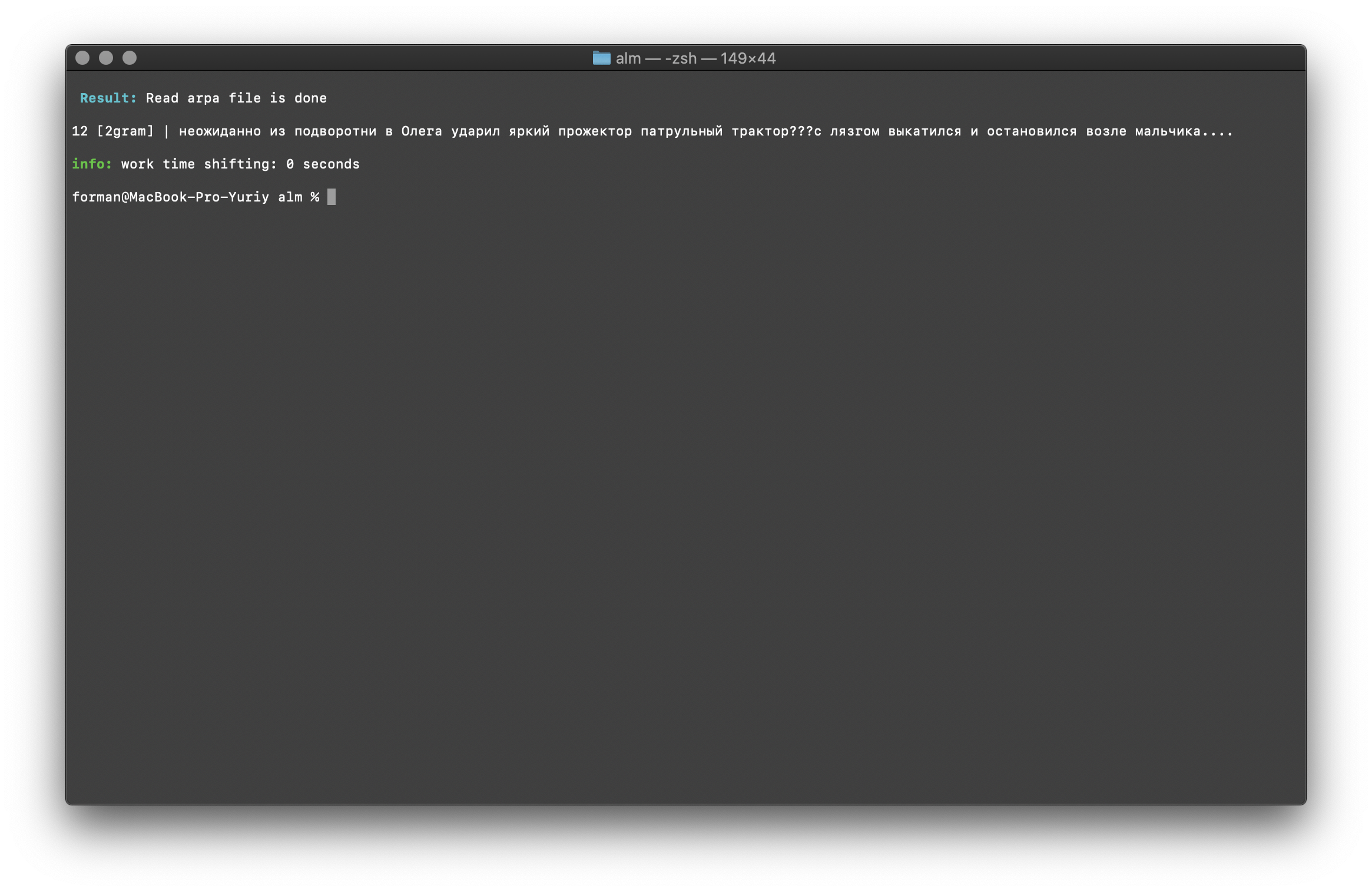 Test:
Test: ??? ....
Result:12 [2gram] | ??? ….
Trigram Check
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -ngrams trigram -debug 1 -r-arpa ./lm.arpa -confidence
Test: ??? ....
Result:10 [3gram] | ??? ….
Search for N-grams in text
$ echo " " | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method find -debug 1 -r-arpa ./lm.arpa -confidence
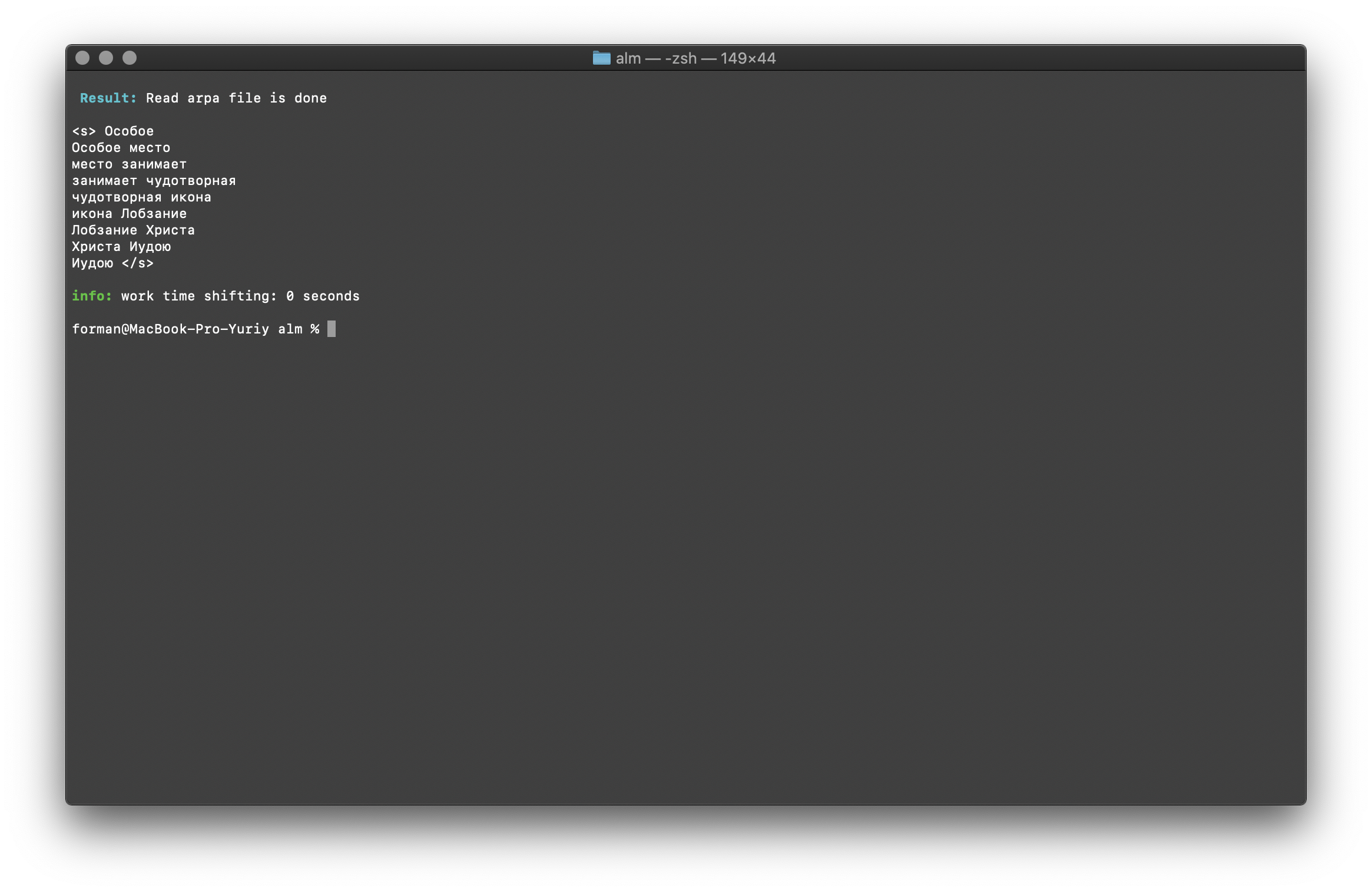 Test:
Test:
Result:<s>
</s>
A list of N-grams that are found in the text. There is nothing special to explain here.Environment variables
All parameters can be passed through environment variables. Variables begin with the prefix ALM_ and must be written in upper case. Otherwise, the variable names correspond to the application parameters.If both application parameters and environment variables are specified, then application parameters are given priority.$ export $ALM_SMOOTHING=wittenbell
$ export $ALM_W-ARPA=./lm.arpa
Thus, the assembly process can be automated. For example, through BASH scripts.Conclusion
I understand that there are more promising technologies like RnnLM or Bert . But I am sure that statistical N-gram models will be relevant for a long time.This work took a lot of time and effort. He was engaged in the library in his spare time from basic work, at night and on weekends. The code did not cover the tests, errors and bugs are possible. I will be grateful for testing. I am also open to suggestions for improvement and new library functionality. ALM is distributed under the MIT license , which allows you to use it with almost no restrictions.Hope to get comments, criticism, suggestions.Project site Projectrepository